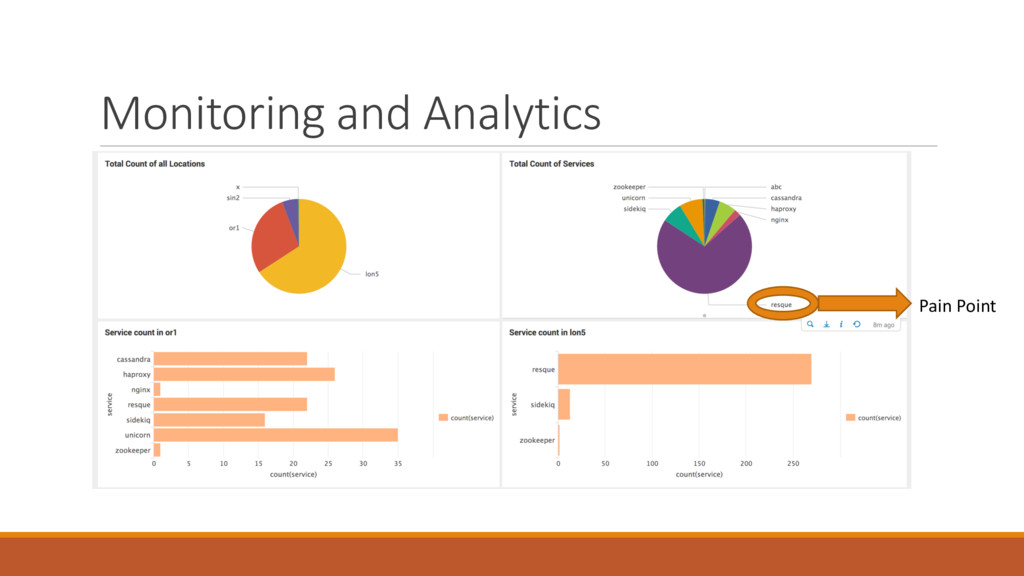
Managing modern Product Infrastructure and applications is daunting because the bigger the infrastructure, more complicated the operational challenges you face. Things break, daemons die, services stop, clusters fall – not to mention writing the root cause analysis (RCA) documents and runbooks on how to fix the same problem in the future. If you keep on adding monitoring, you end up having a huge pile of alerts and failures every day.
To ensure availability of product as you scale, either you automate or you die. This is where Auto- Remediation comes into picture.
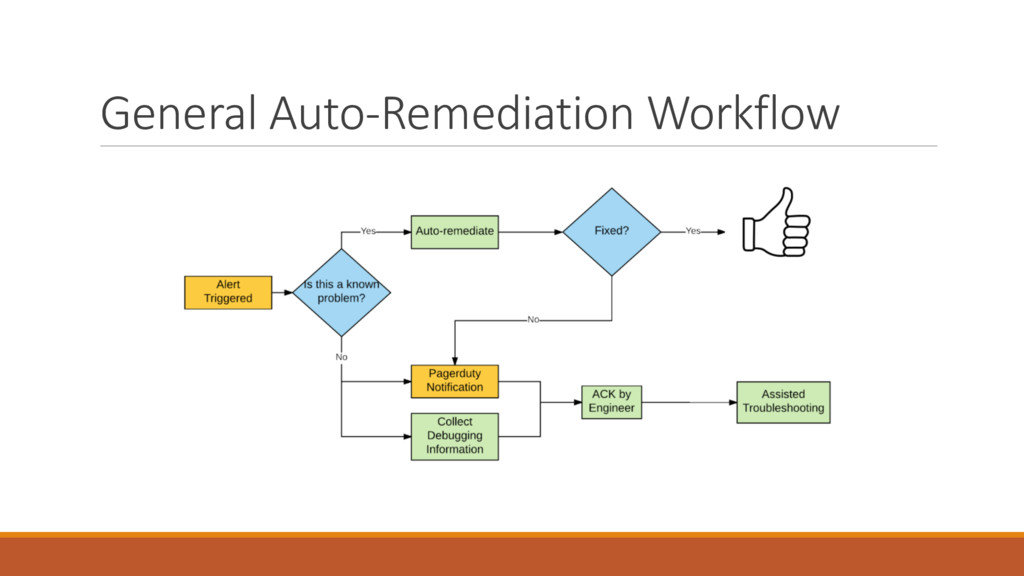
Auto-Remediation, or Self-Healing, is a workflow which triggers and responds to alerts or events by executing actions that can prevent or fix the problem.
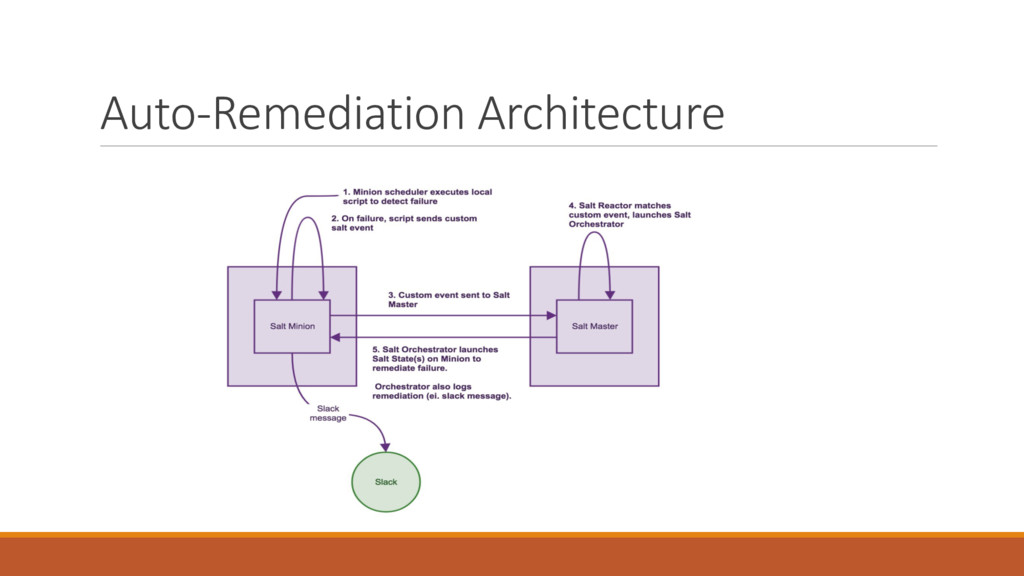
The simplest example of auto-remediation is restarting a service (let’s say apache) when it’s down. Imagine an automated action that is triggered by a monitoring system to restart the service and prevent the application outage. In addition, it creates a task and sends a notification so that the engineer can find the root cause during business hours, and there is no need to do it in the middle of the night. Furthermore, the event-driven automation can be used for assisted troubleshooting, so when you get an alert it includes related logs, monitoring metrics/graphs, and so on.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Office Email - [email protected] Personal Email - [email protected] Phone -](https://files.speakerdeck.com/presentations/fec24698b2854cf1805efdeabef992ab/slide_21.jpg){kind=link}
{kind=link}