Prompt Human Input AI Message Tool Response N回目ステップ System Prompt Human Input AI Message Tool Response N+1回目ステップ AI Message Tool Response Tool実行後、LLMに 返す前にそれまでの 内容を要約し、要約版 をLLMに渡す System Prompt それまでの Tool実行 結果などの 要約 System Prompt それまでの Tool実行 結果などの 要約 AI Message Tool Response N+2回目ステップ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
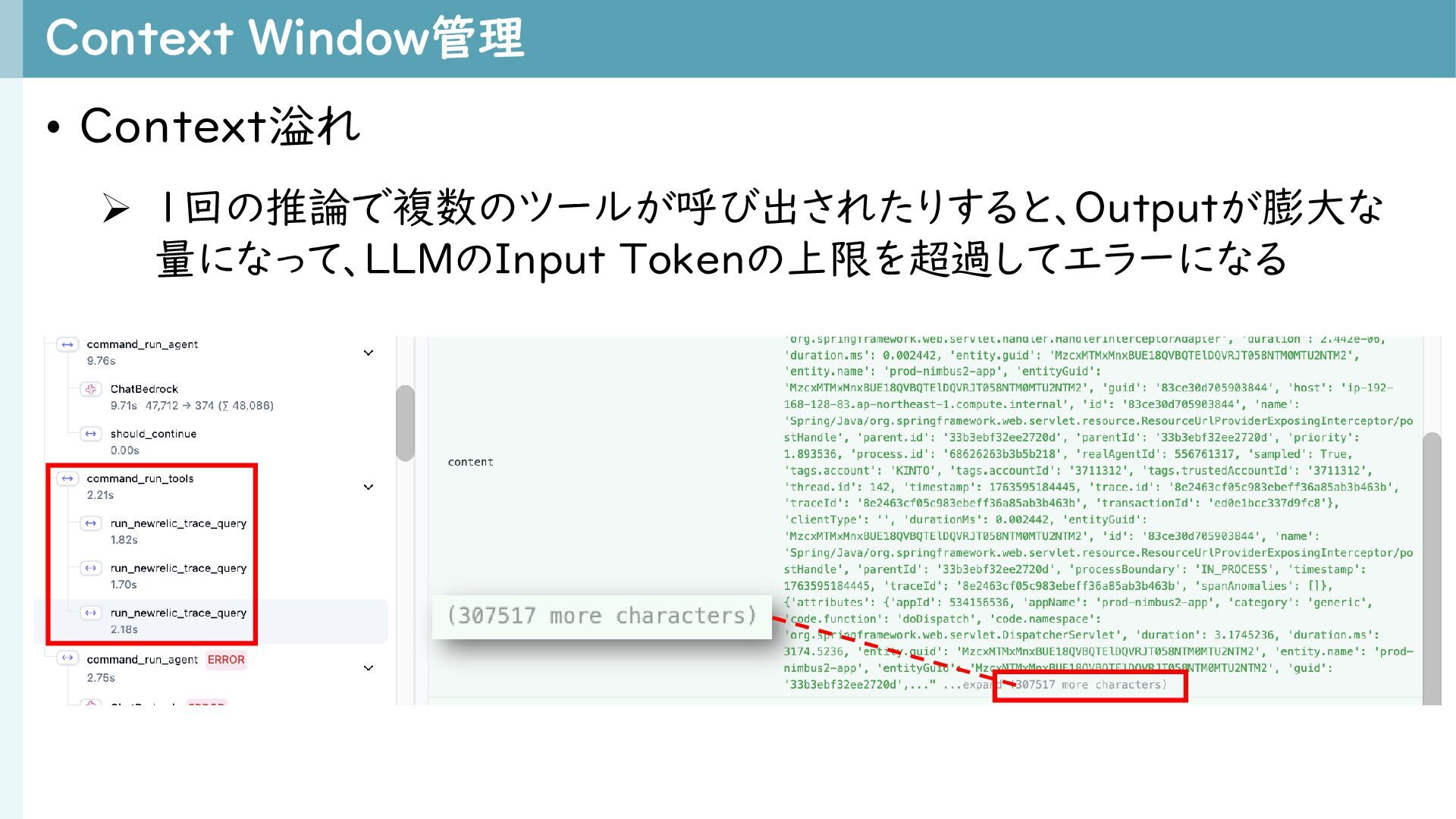{kind=link}
{kind=link}
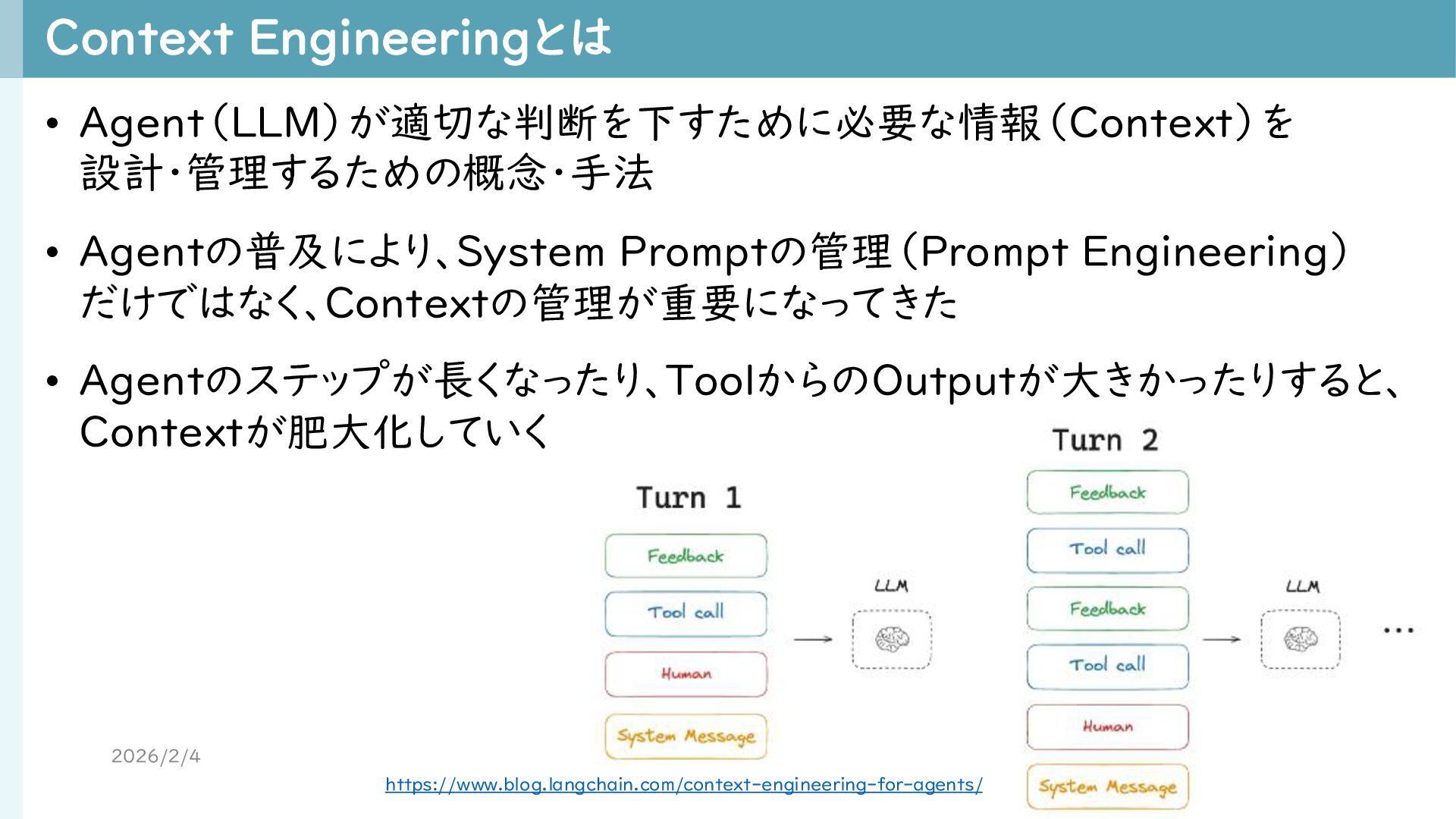{kind=link}
{kind=link}
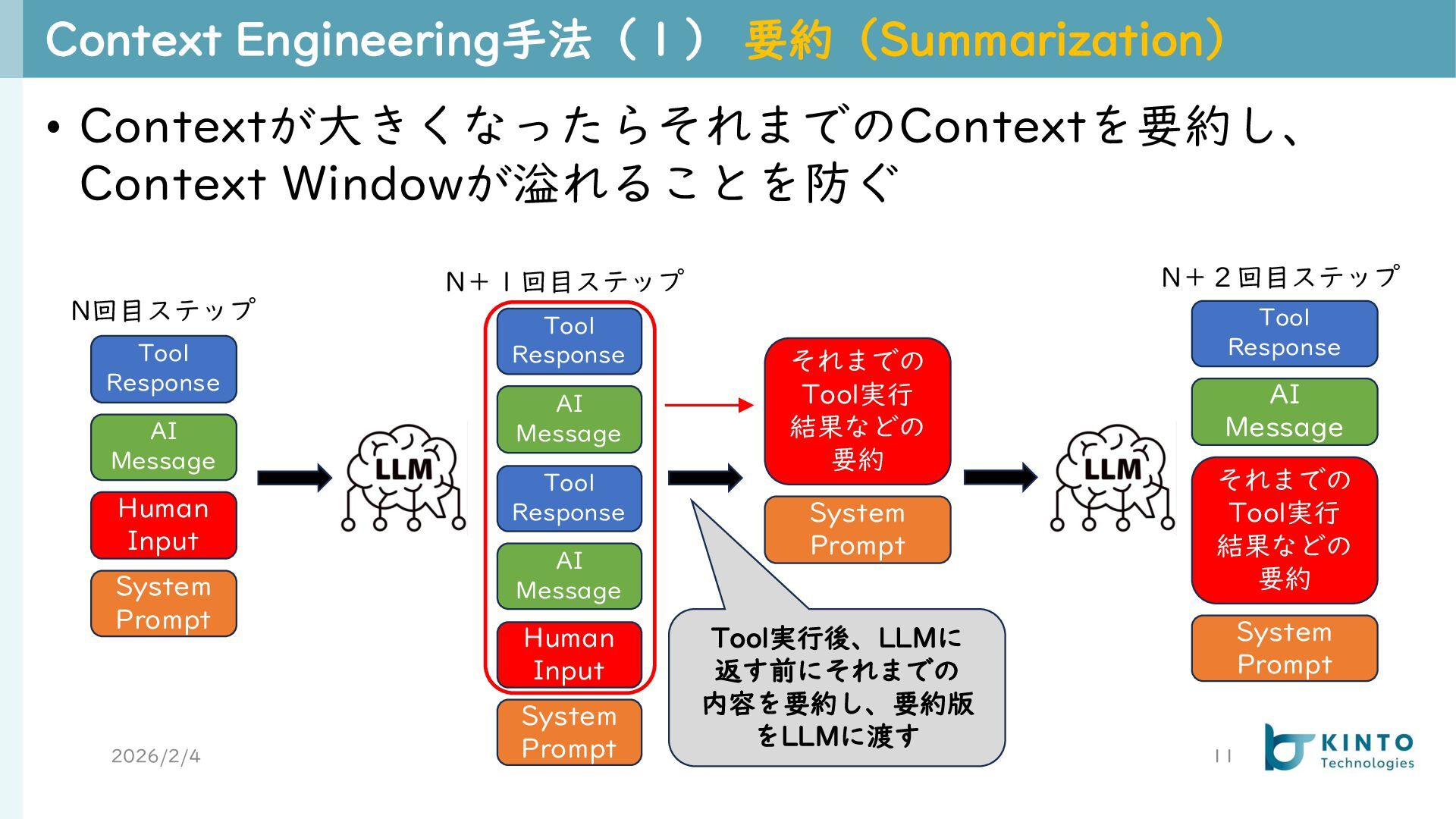{kind=link}
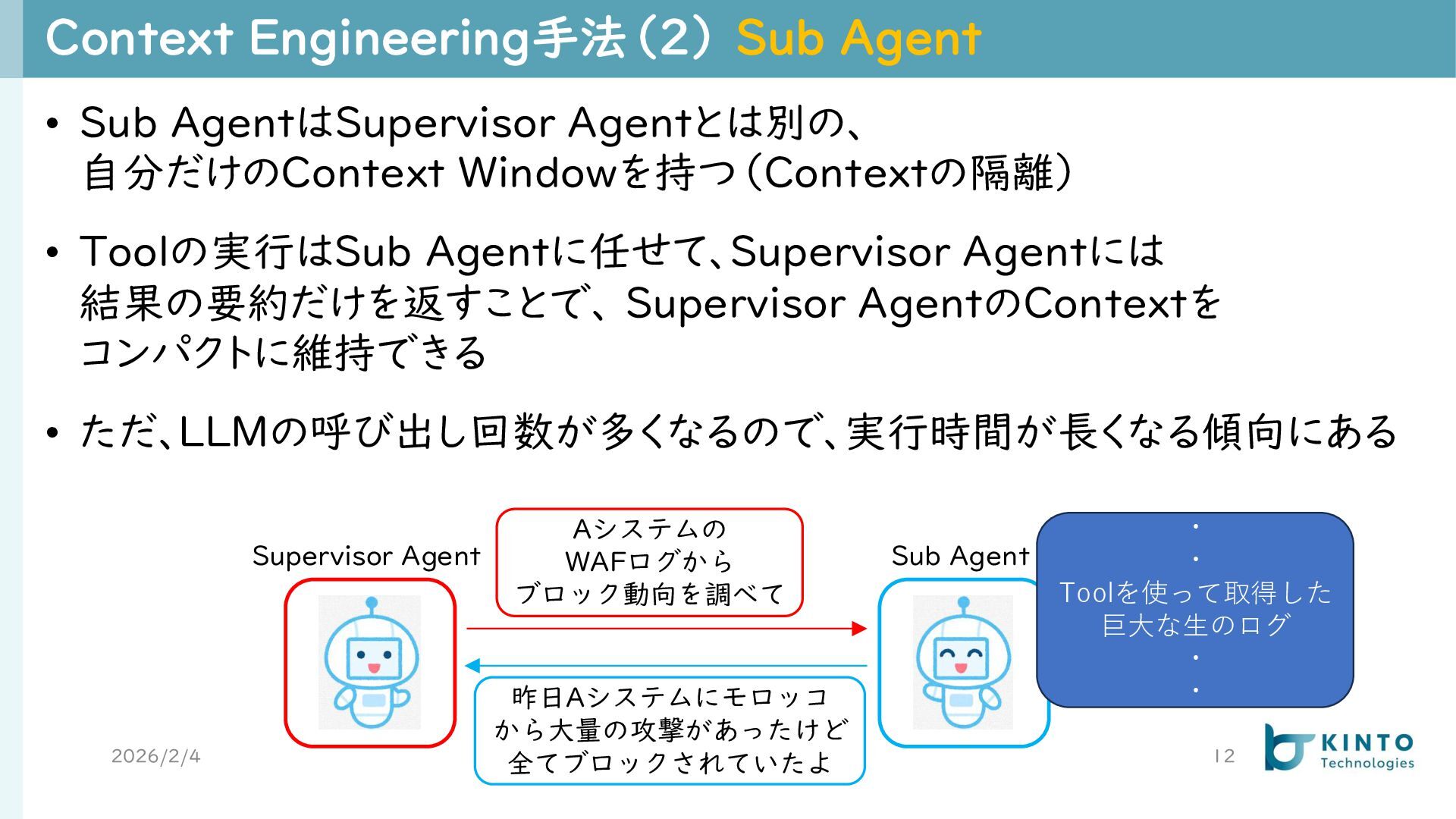{kind=link}
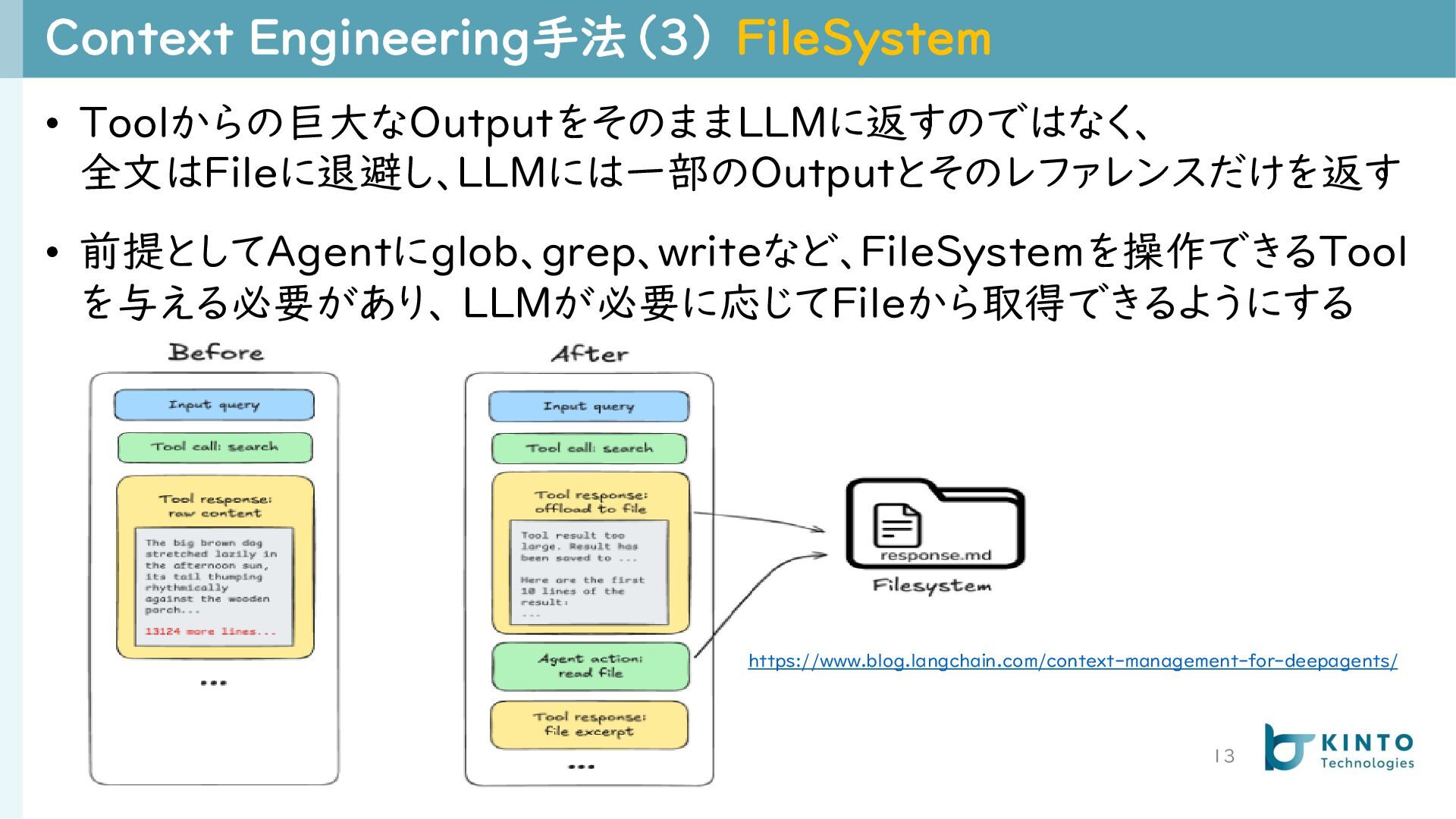{kind=link}
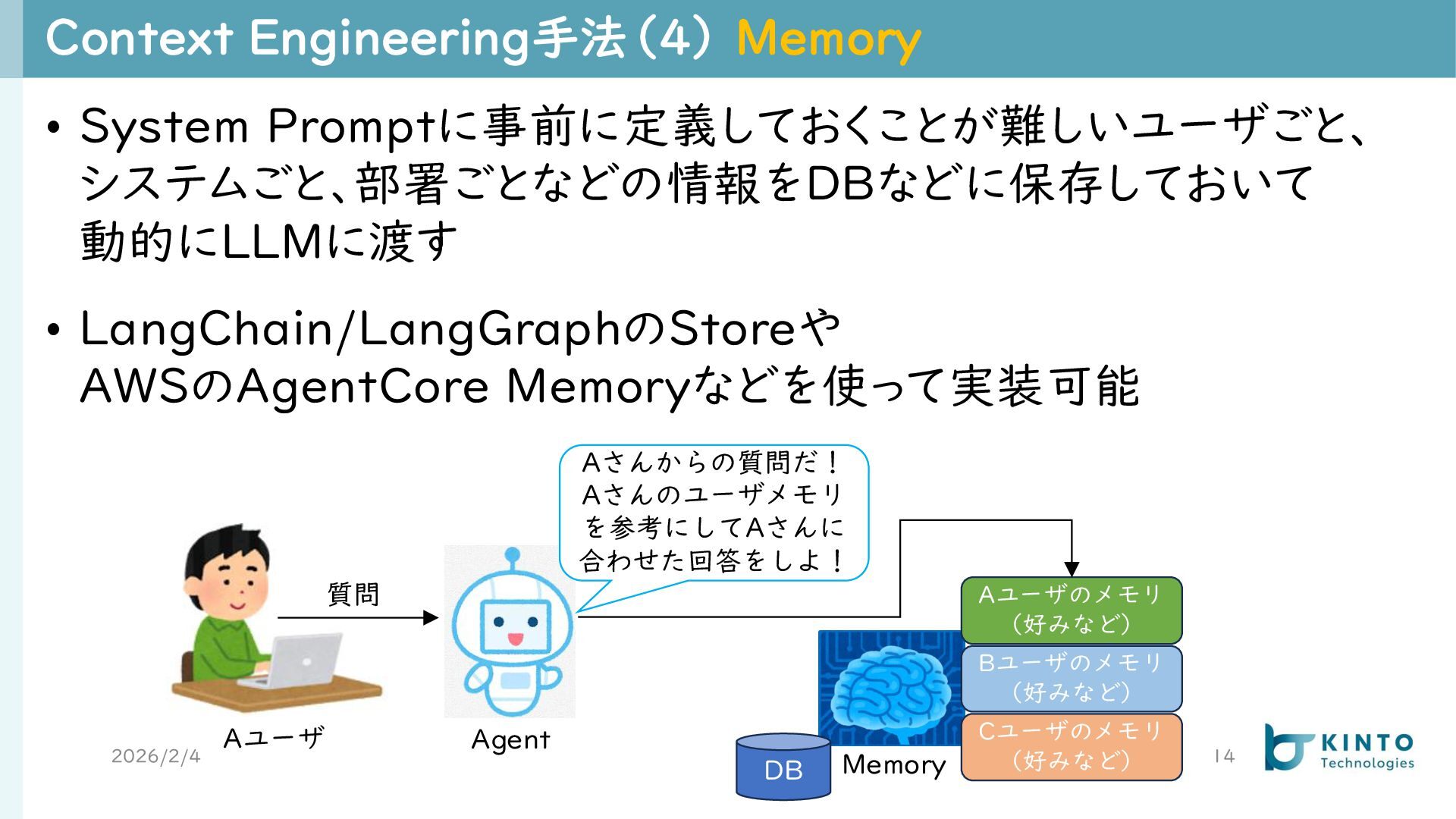{kind=link}
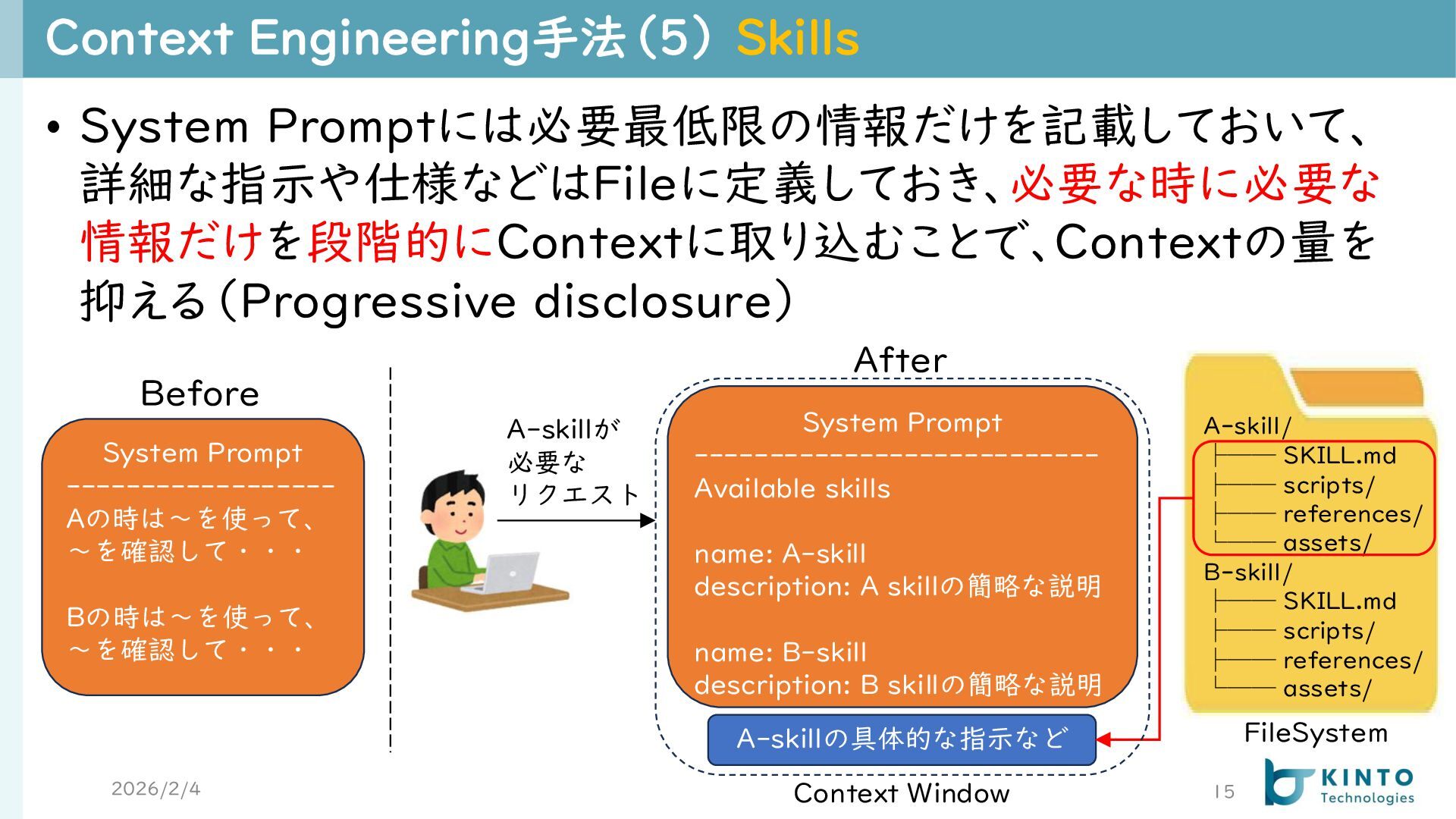{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}