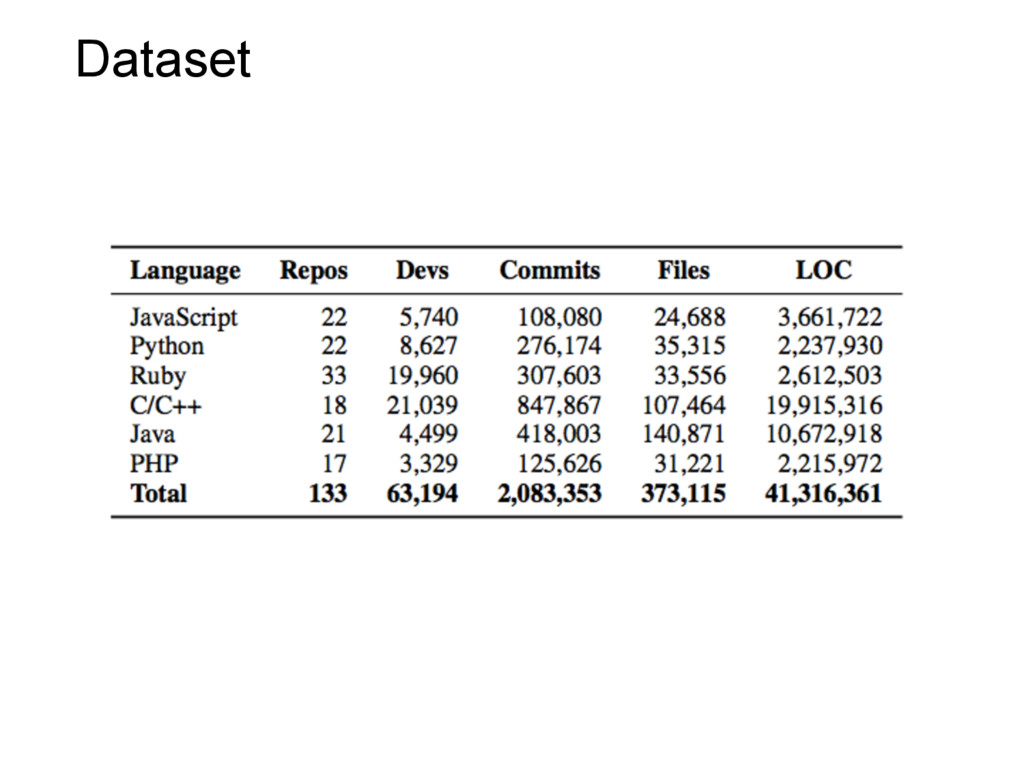
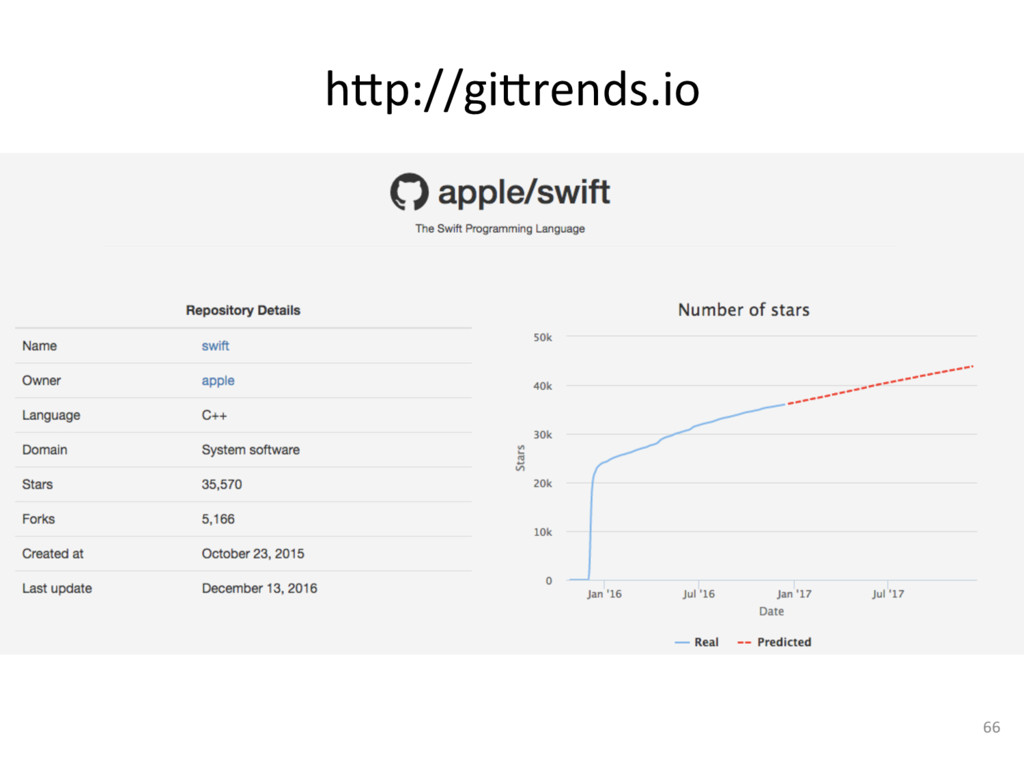
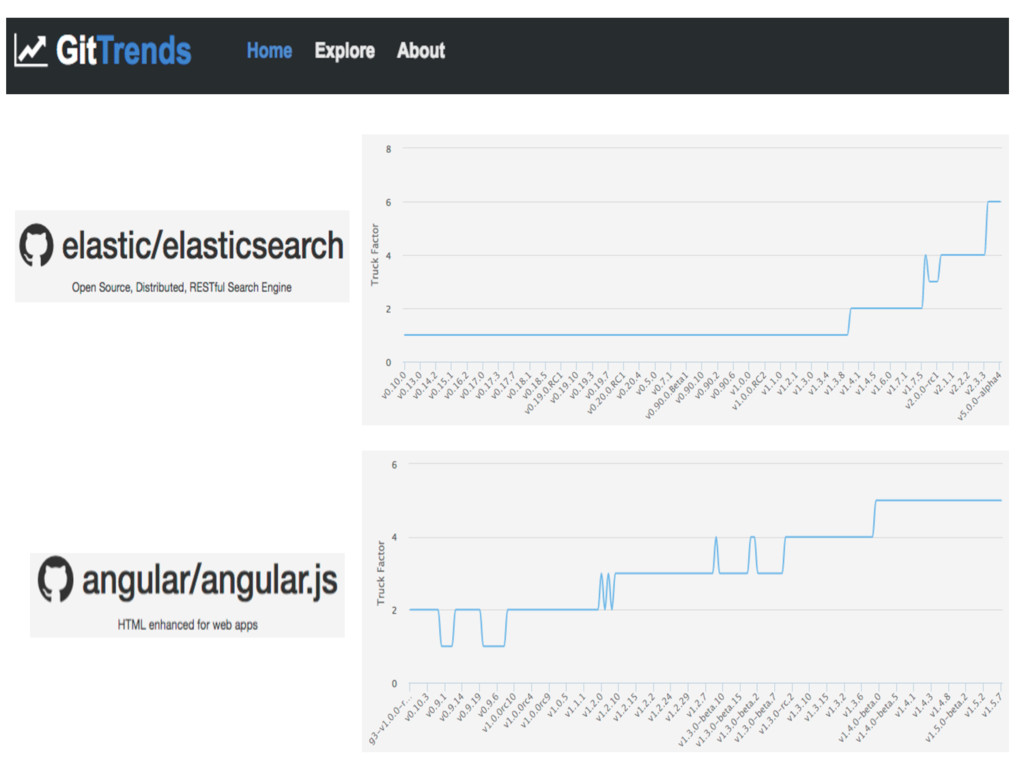
GitHub has in recent years become the world’s largest collection of open source software, with around 9 million users and 17 million public repositories. These numbers make GitHub an invaluable source of data for large-scale research in empirical software engineering. In this talk, we describe recent research conducted in our group, using GitHub data. For example, we are using GitHub to understand and predict the popularity of open source projects, to understand the motivations behind refactoring, to assess the concentration of knowledge in software teams, and to measure code authorship.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Why we refactor? [In theory]](https://files.speakerdeck.com/presentations/dfb1b6bb37ee486c8ddb13890226b2b1/slide_4.jpg){kind=link}
![Why we refactor? [In theory] Kim et al. An](https://files.speakerdeck.com/presentations/dfb1b6bb37ee486c8ddb13890226b2b1/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
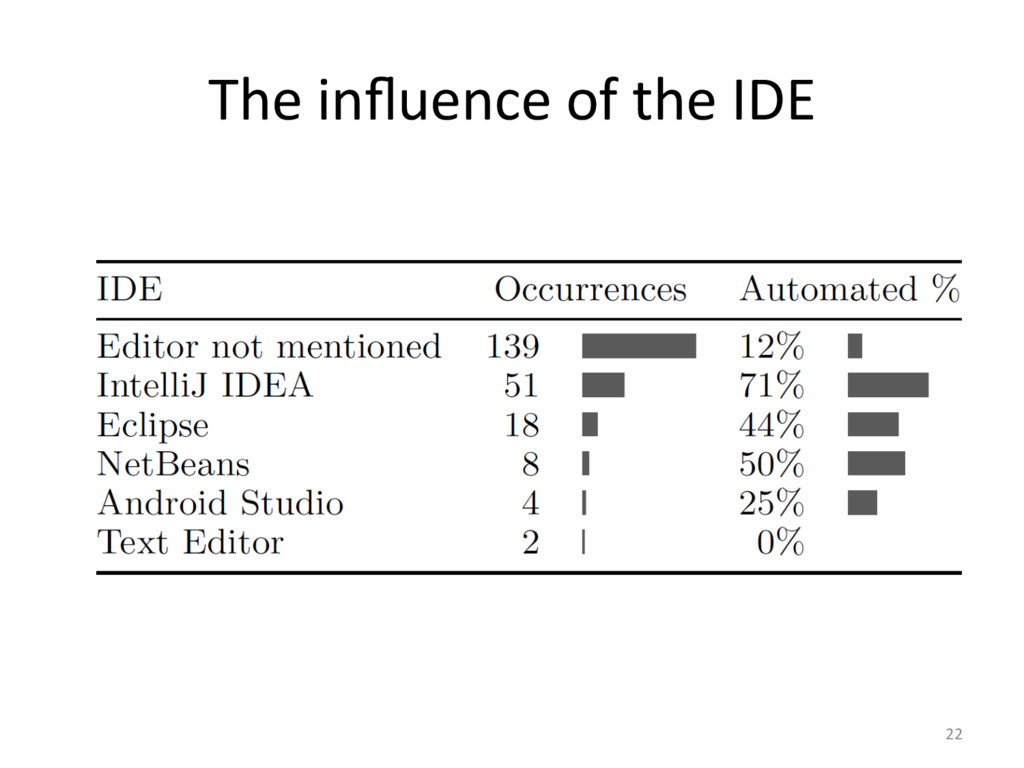{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
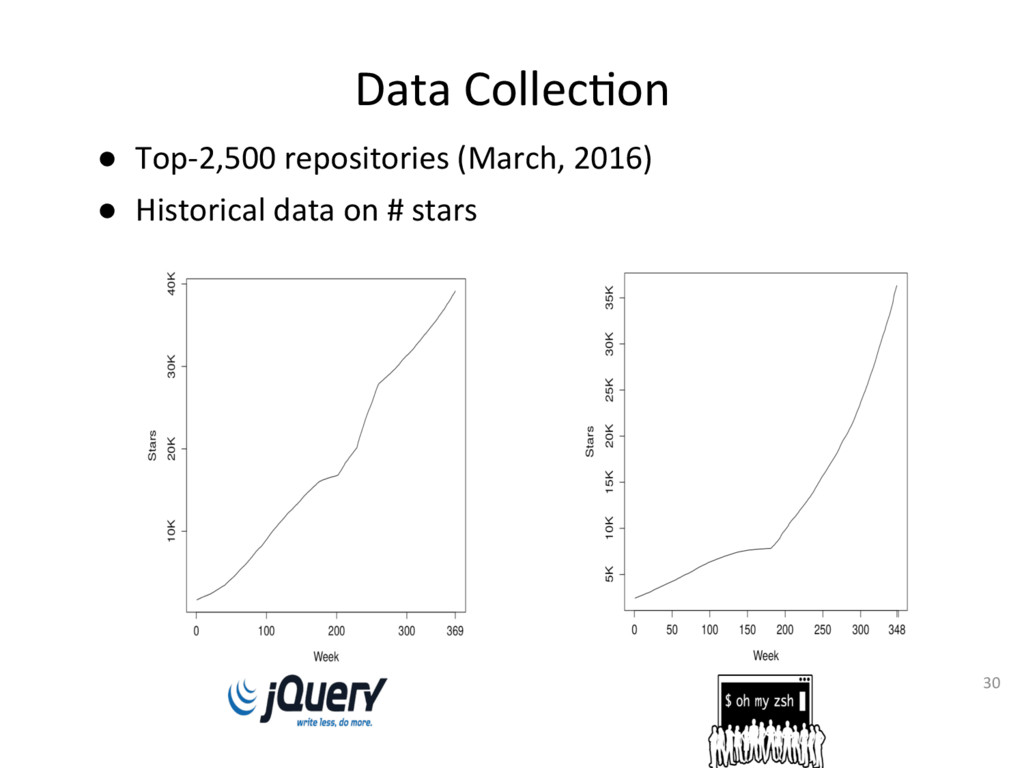{kind=link}
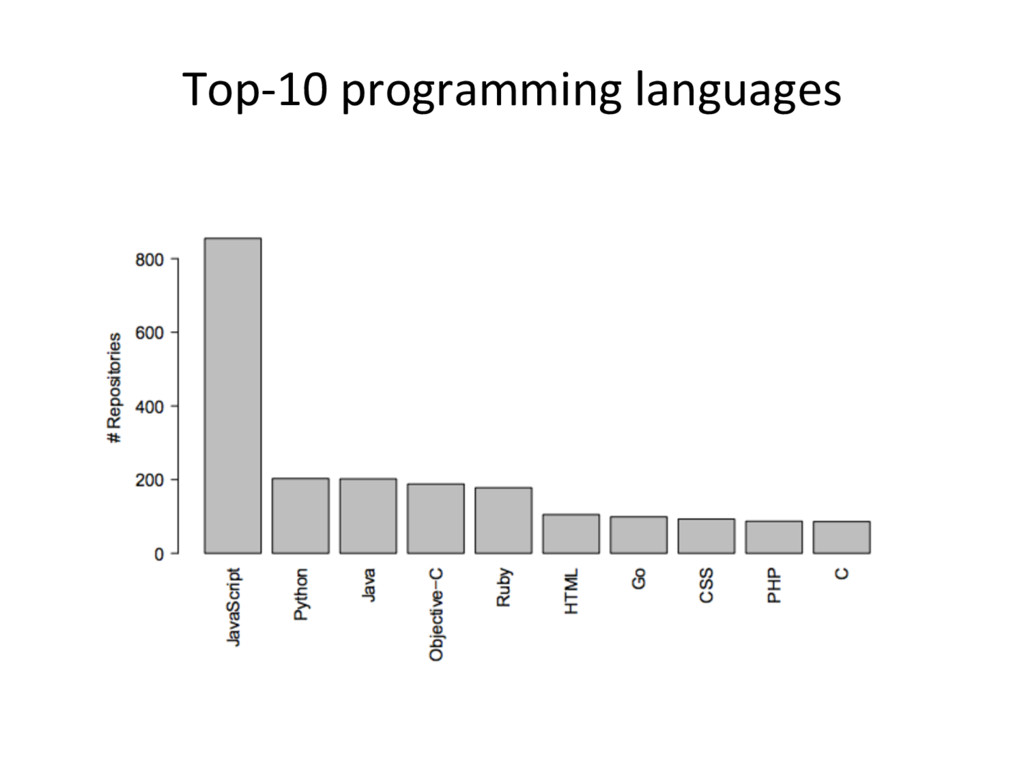{kind=link}
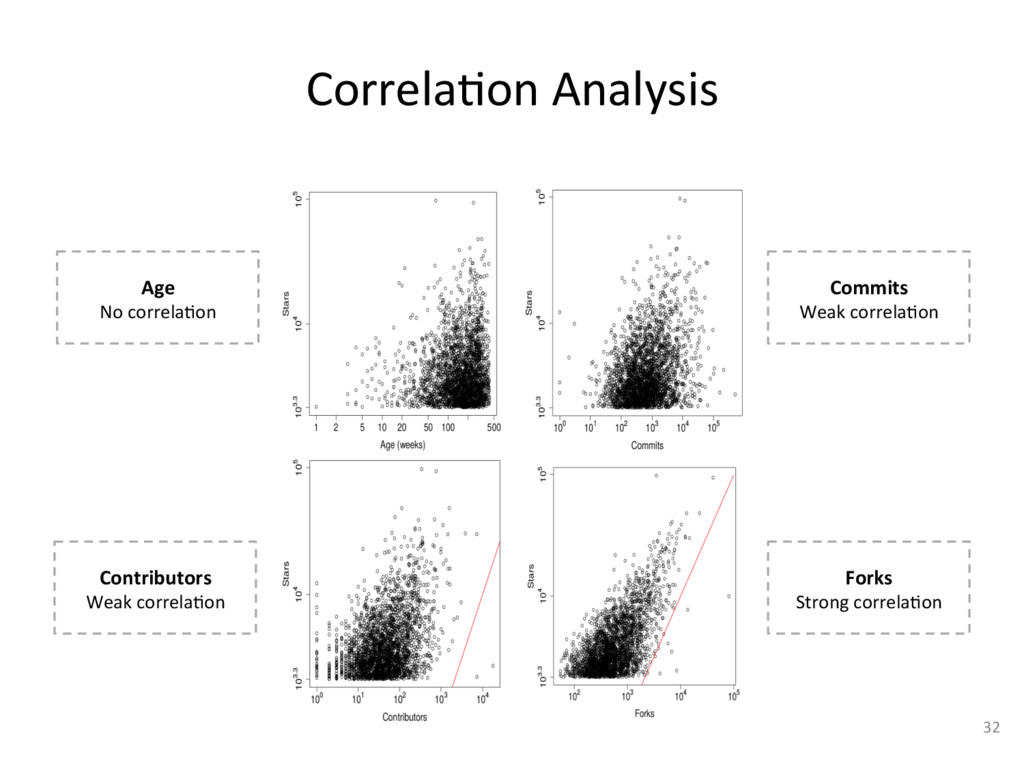{kind=link}
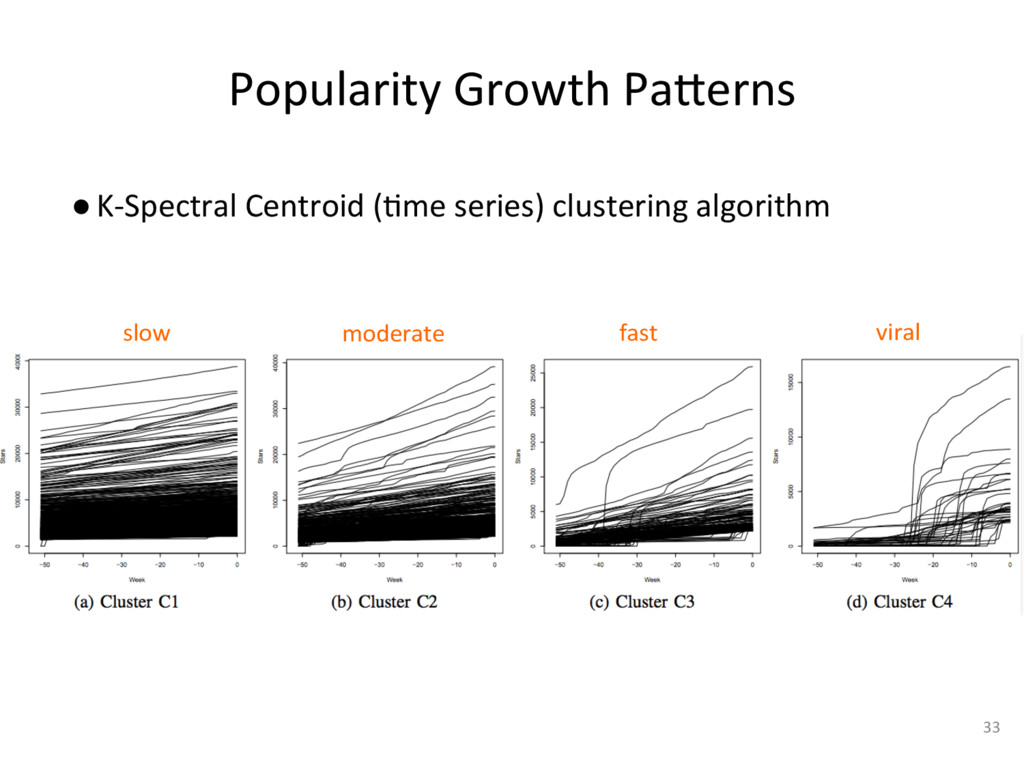{kind=link}
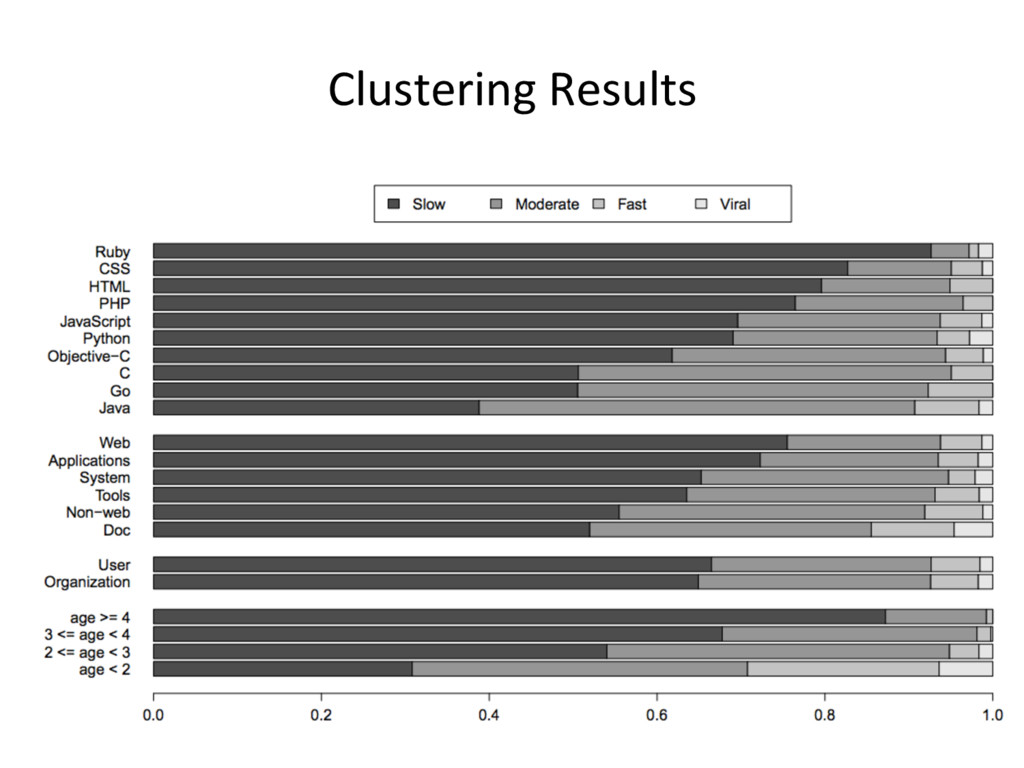{kind=link}
{kind=link}
{kind=link}
{kind=link}
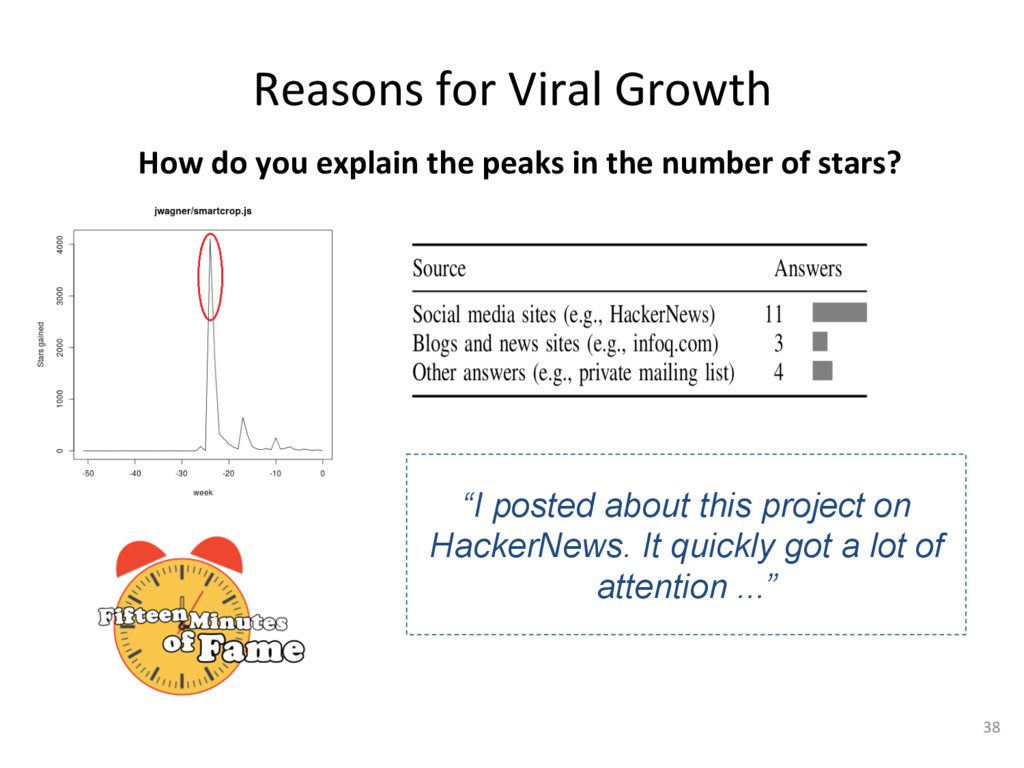{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
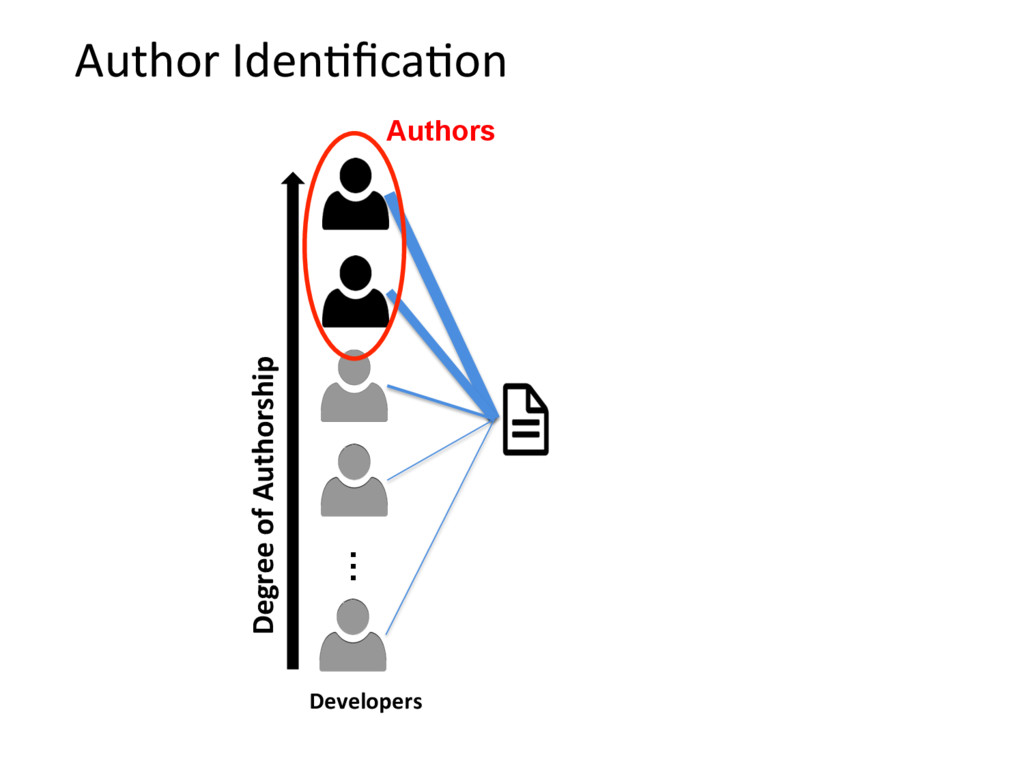{kind=link}
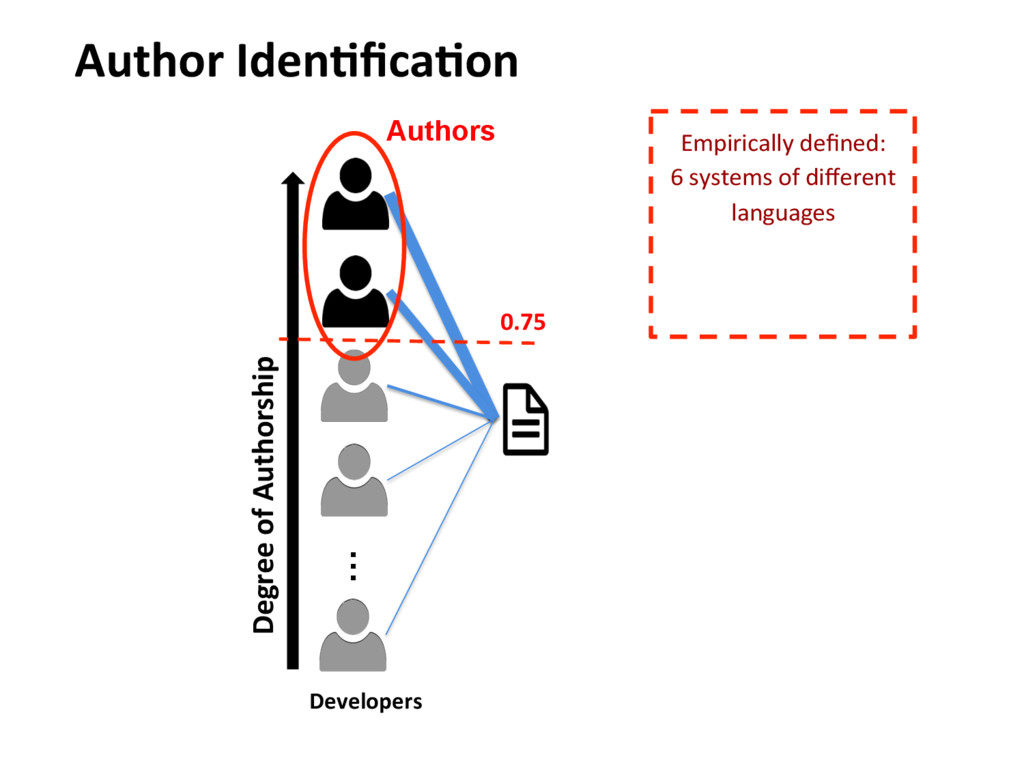{kind=link}
{kind=link}
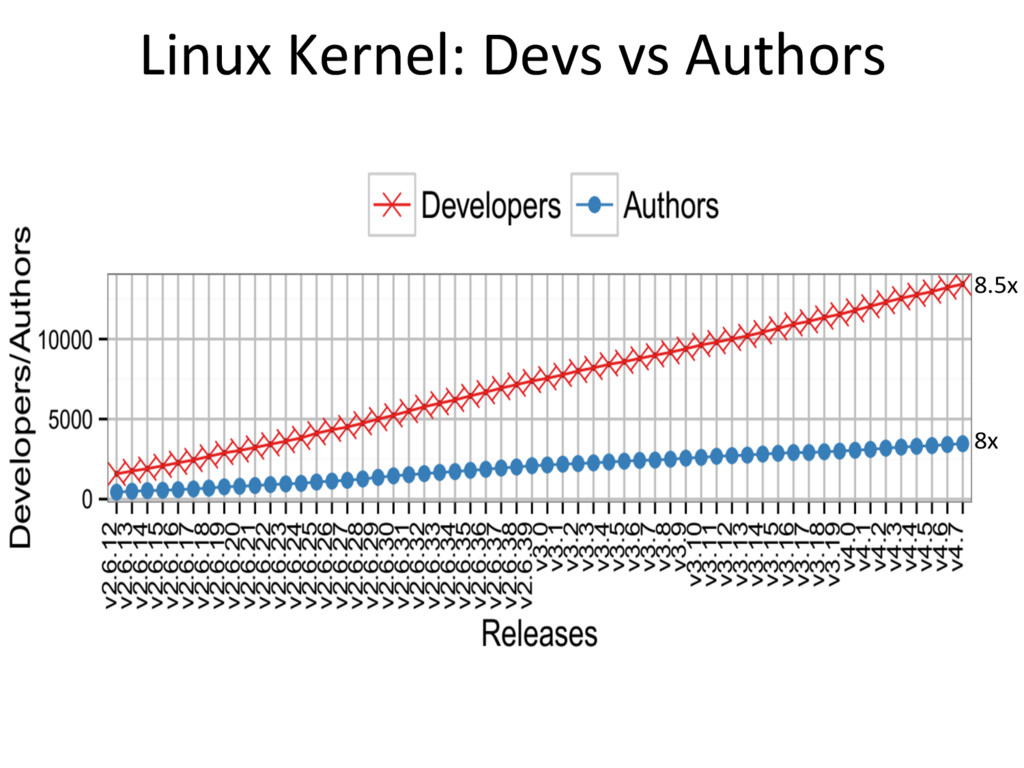{kind=link}
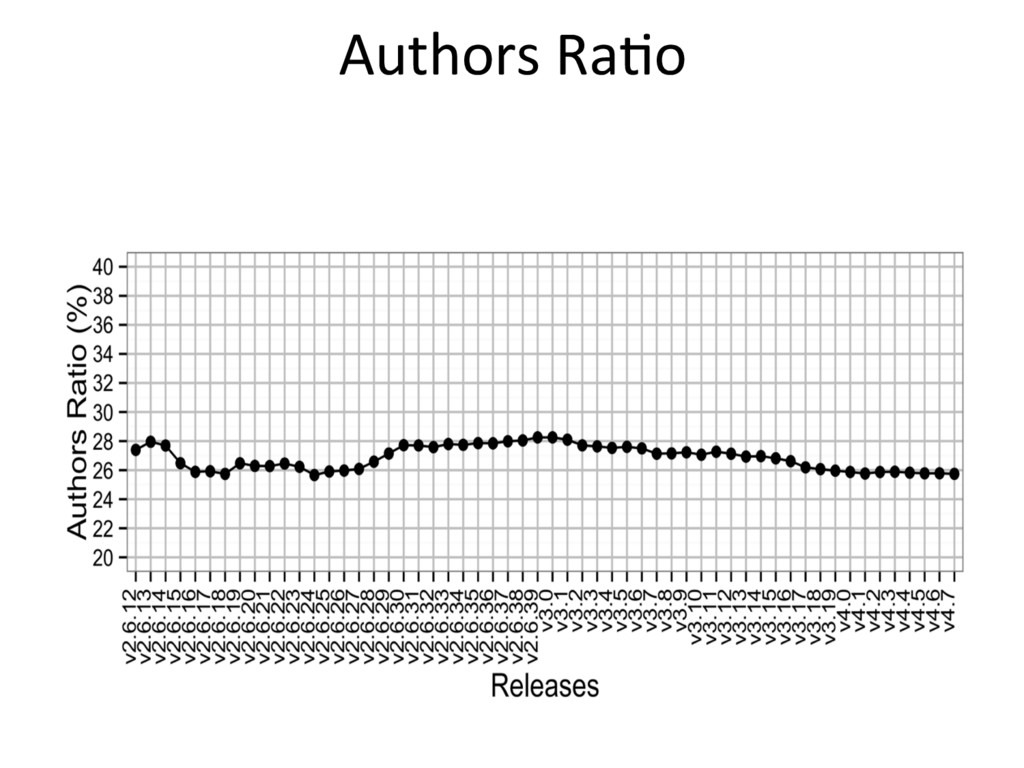{kind=link}
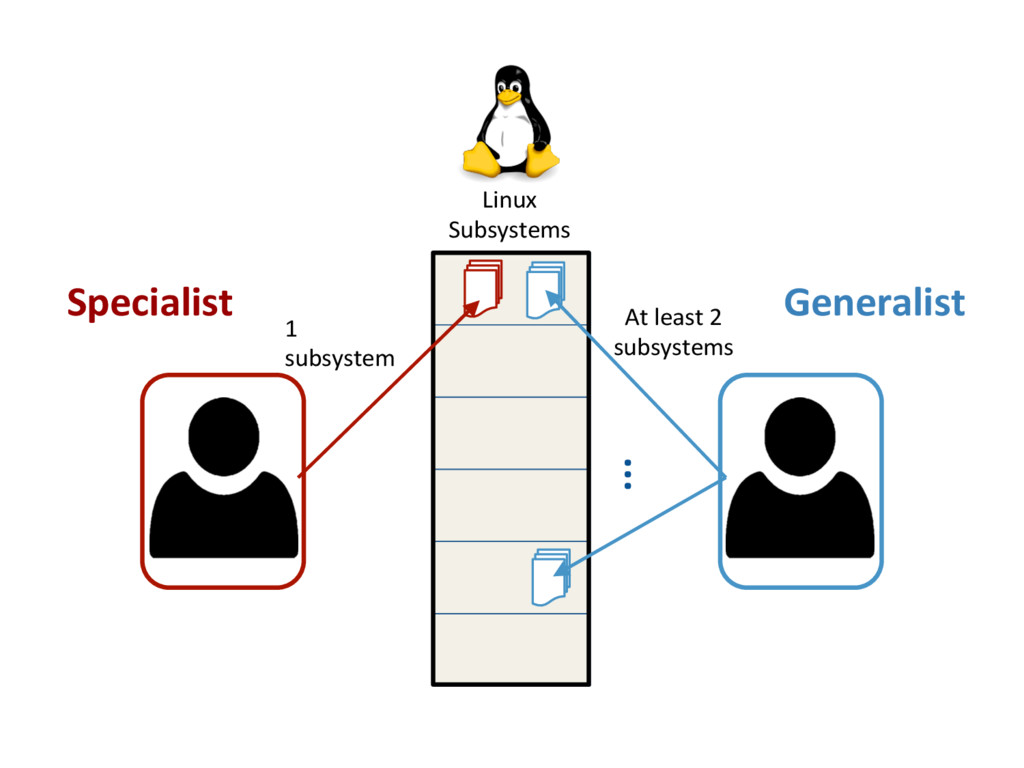{kind=link}
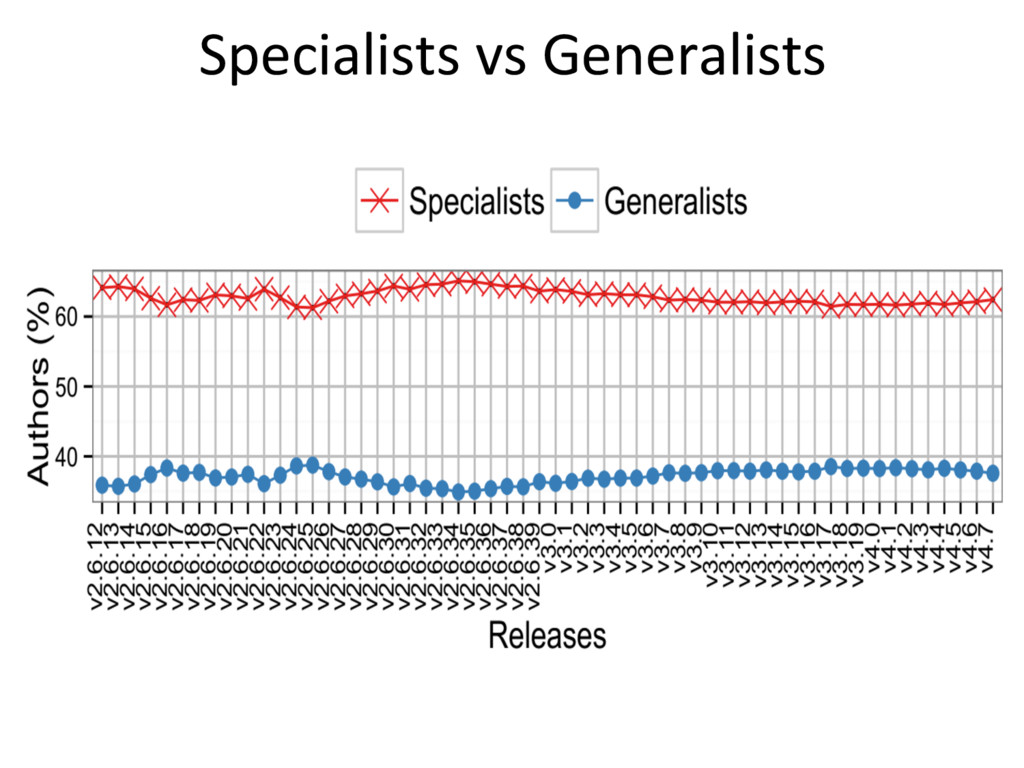{kind=link}
{kind=link}
{kind=link}
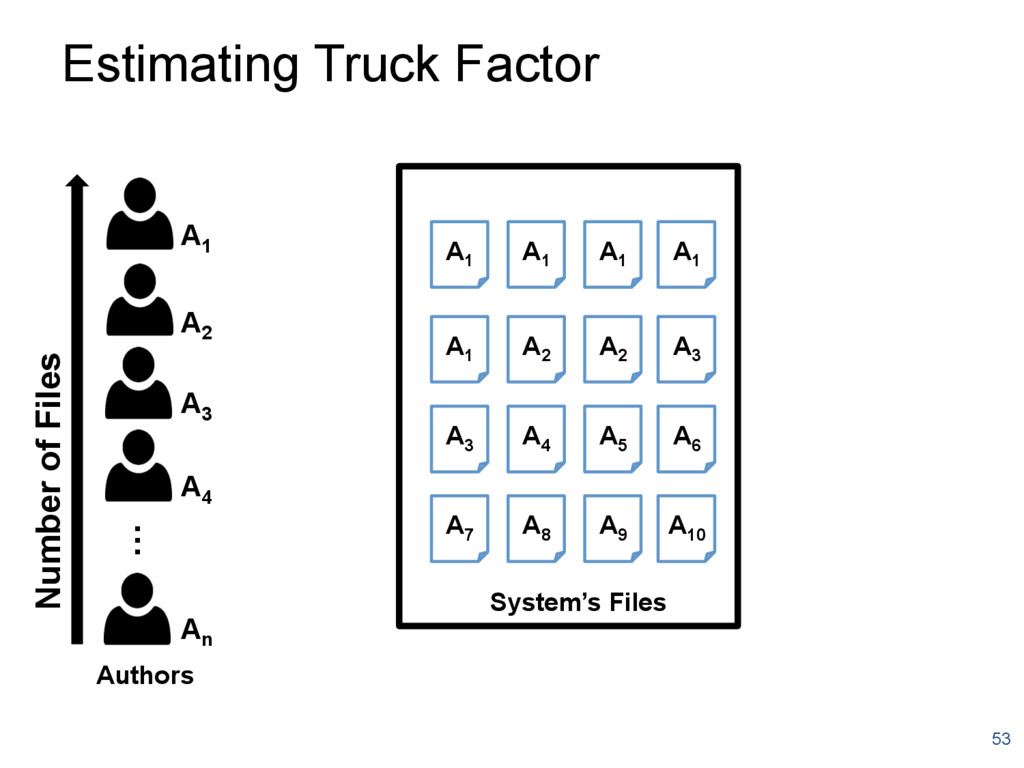{kind=link}
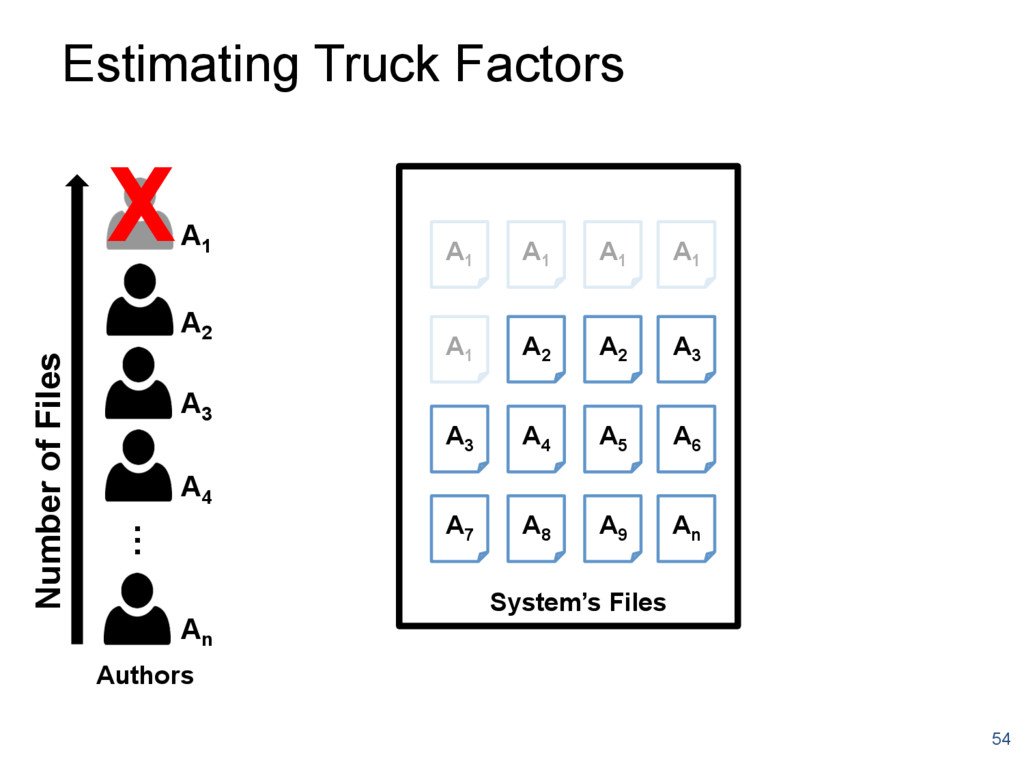{kind=link}
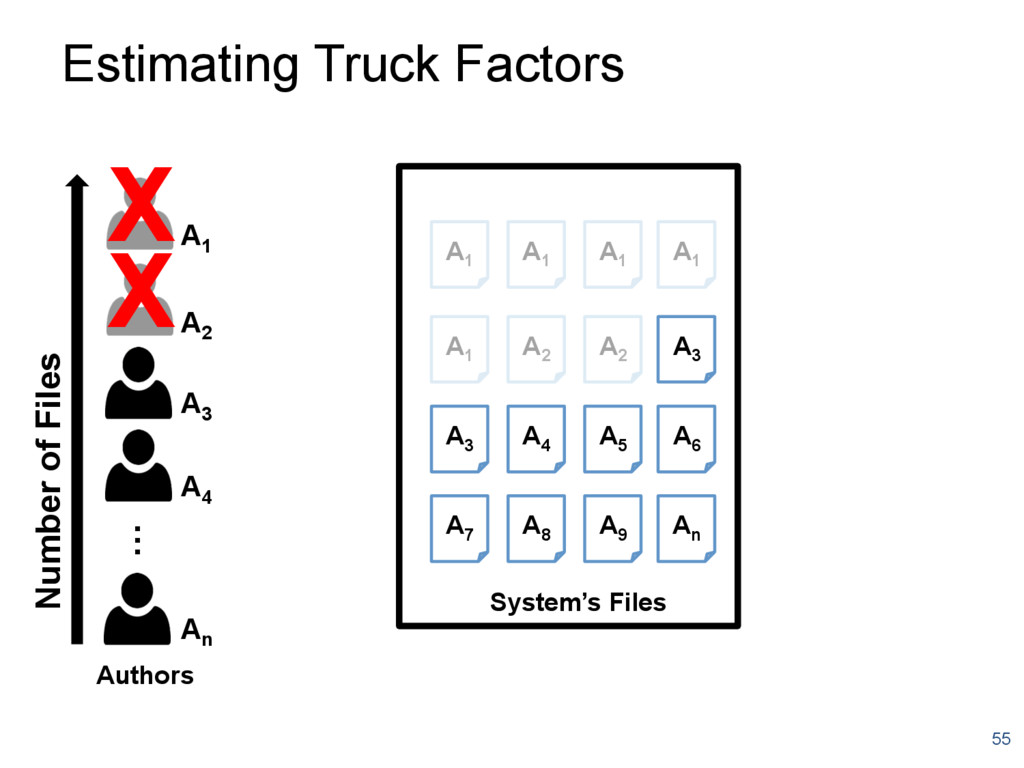{kind=link}
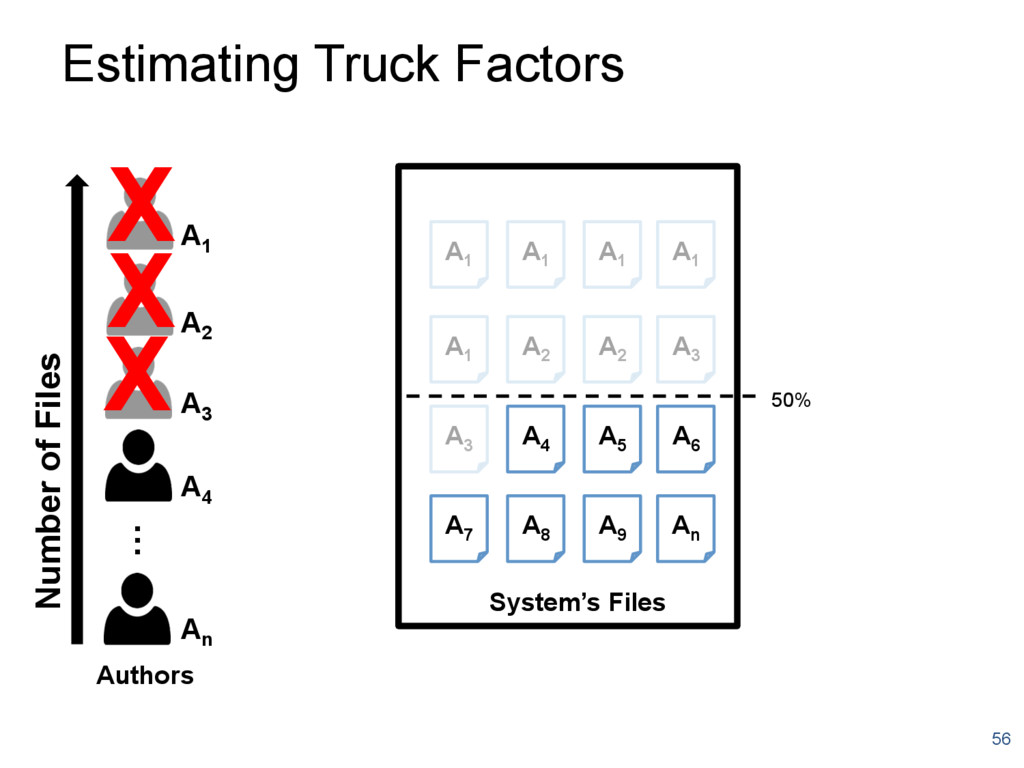{kind=link}
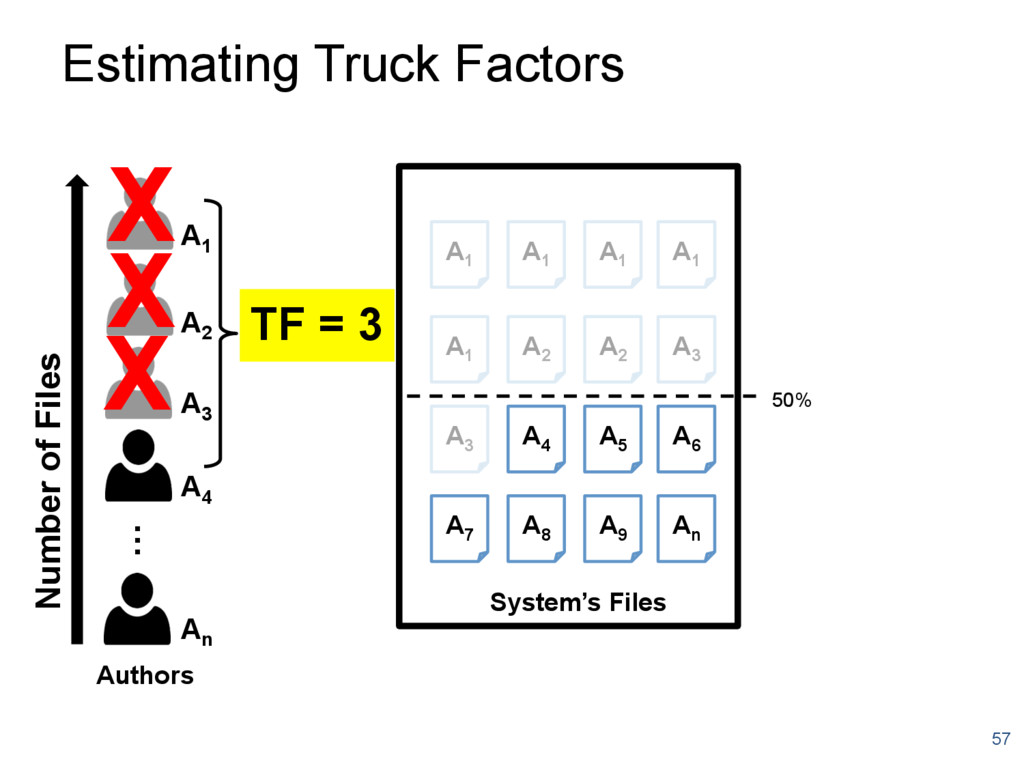{kind=link}
{kind=link}
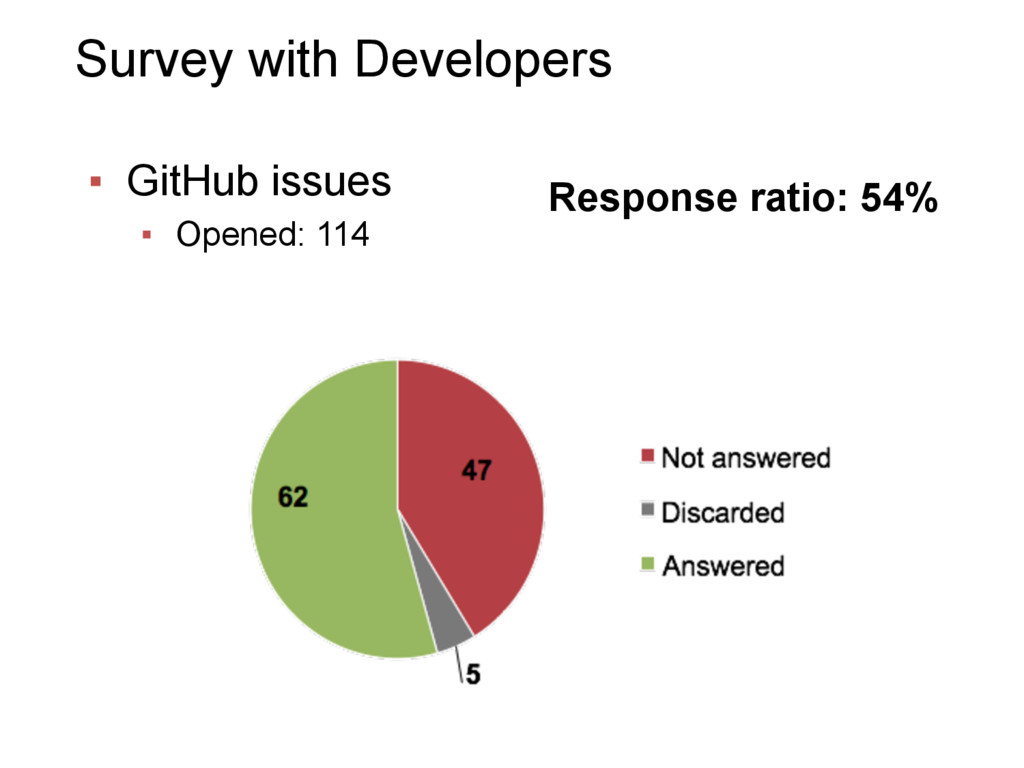
{kind=link}
{kind=link}
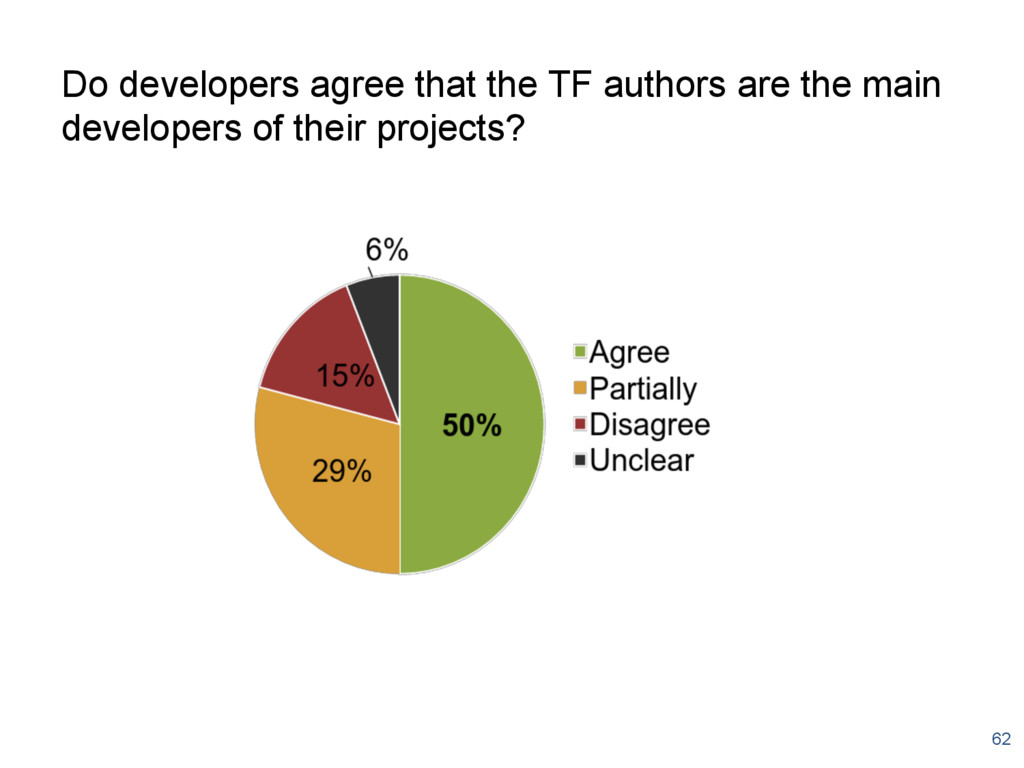
{kind=link}
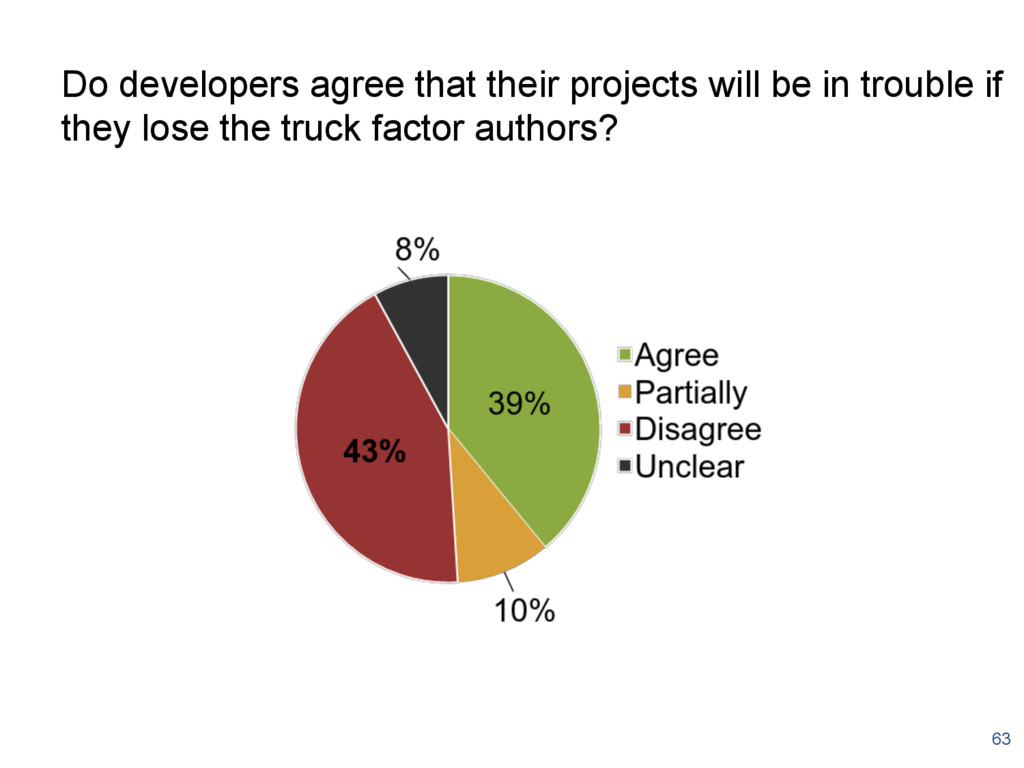
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}