Norway • Worked with search at FAST (now Microsoft) for 10 years • 5 years in R&D building FAST Enterprise Search Platform in Oslo, Norway • 5 years in Services doing solution delivery, sales, etc. in Tokyo, Japan • Founded ΞςΟϦΧגࣜձࣾ in 2009 • We help companies innovate using new technologies and good ideas • We do information retrieval, natural language processing and big data • We are based in Tokyo, but we have clients everywhere • Newbie Lucene & Solr Committer • Mostly been working on Japanese language support (Kuromoji) so far • Please write me on [email protected] or [email protected]
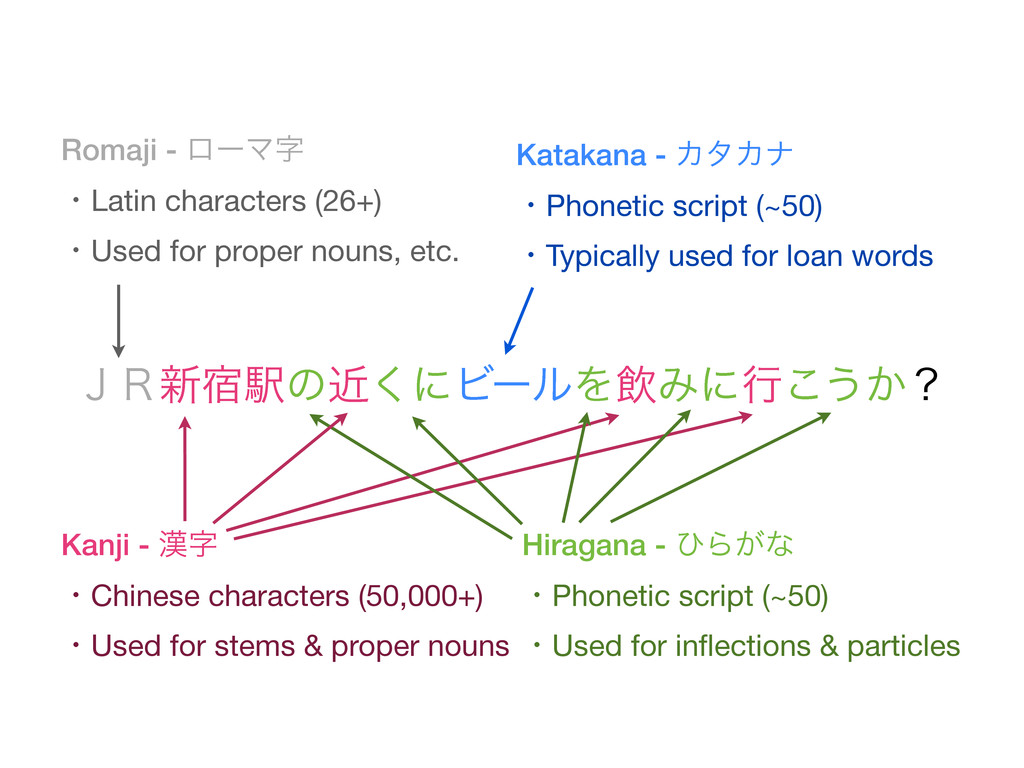
• • change of semantics! means ‘post town’, ‘relay station’ or ‘stage’ • Does not preserve meaning well and often changes semantics • Impacts on ranking - search precision (many false positives) Generates many terms per document or query Impacts on index size and search performance Sometimes appropriate for certain search applications Compliance, e-commerce with non product names, ...
• • change of semantics! means ‘post town’, ‘relay station’ or ‘stage’ • Does not preserve meaning well and often changes semantics • Impacts on ranking - search precision (many false positives) • Also generates many terms per document or query • Impacts on index size and performance Sometimes appropriate for certain search applications Compliance, e-commerce with non product names, ...
• • change of semantics! means ‘post town’, ‘relay station’ or ‘stage’ • Does not preserve meaning well and often changes semantics • Impacts on ranking - search precision (many false positives) • Also generates many terms per document or query • Impacts on index size and performance • Still sometimes appropriate for certain search applications • Compliance, e-commerce with special product names, ...
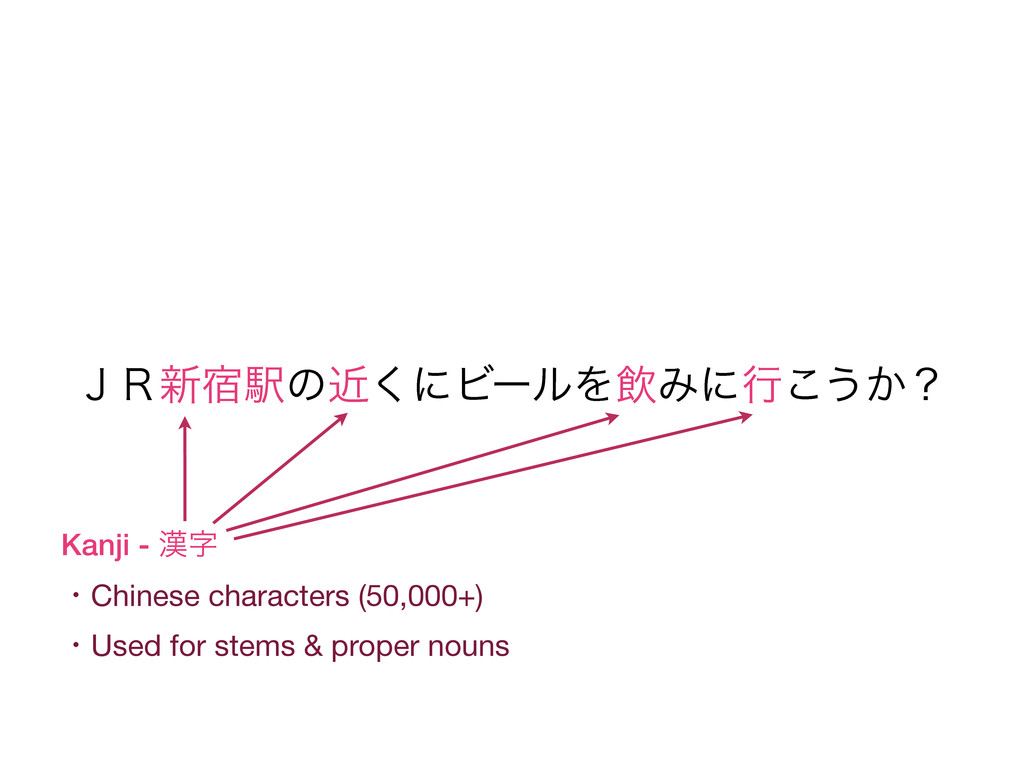
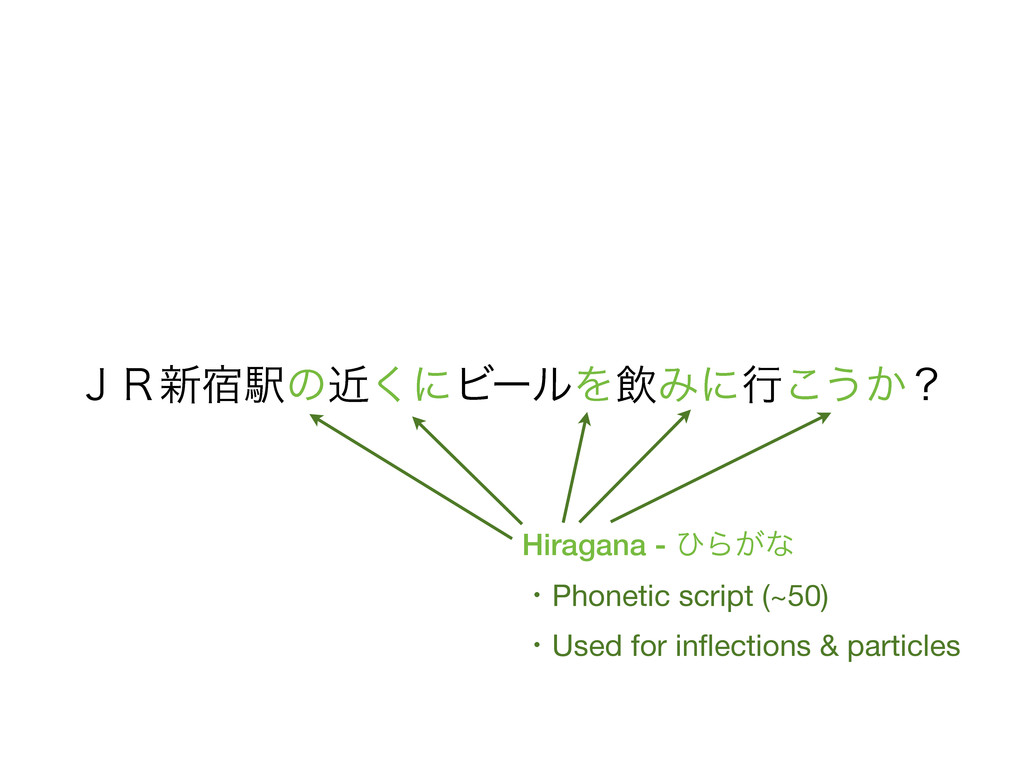
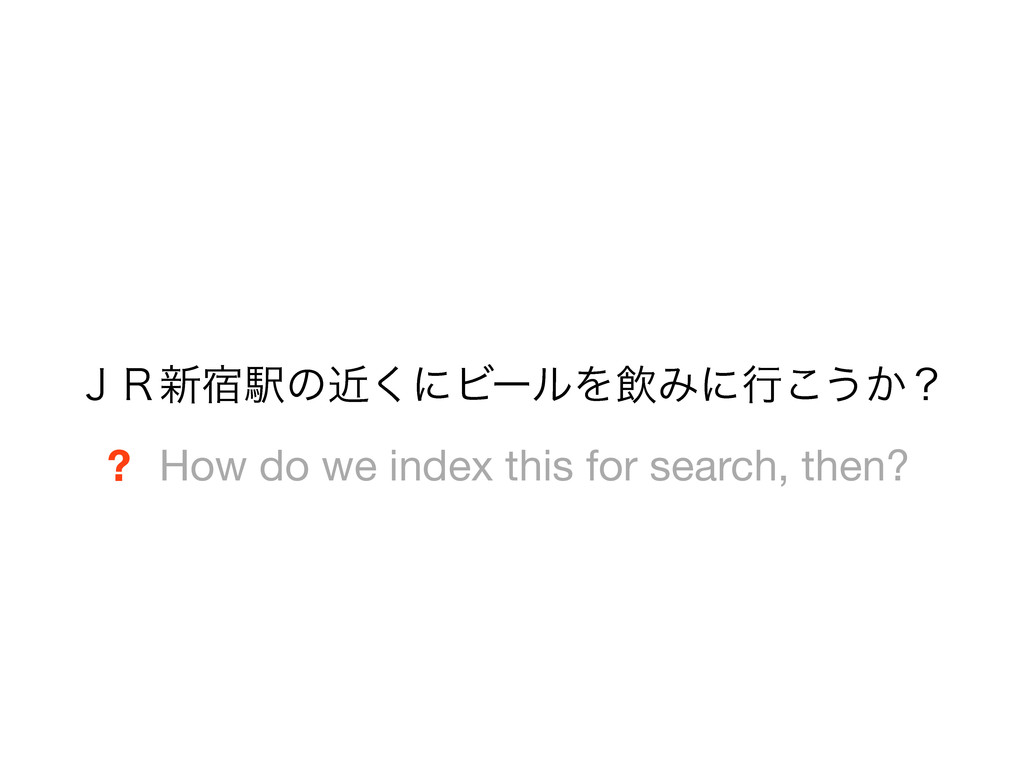
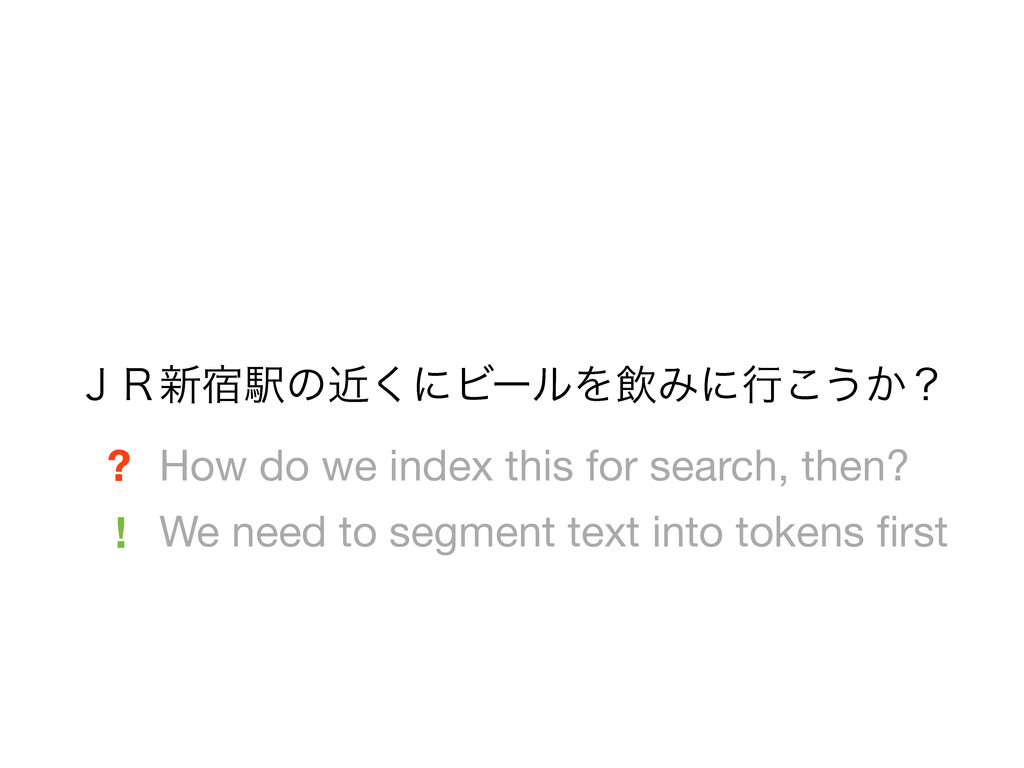
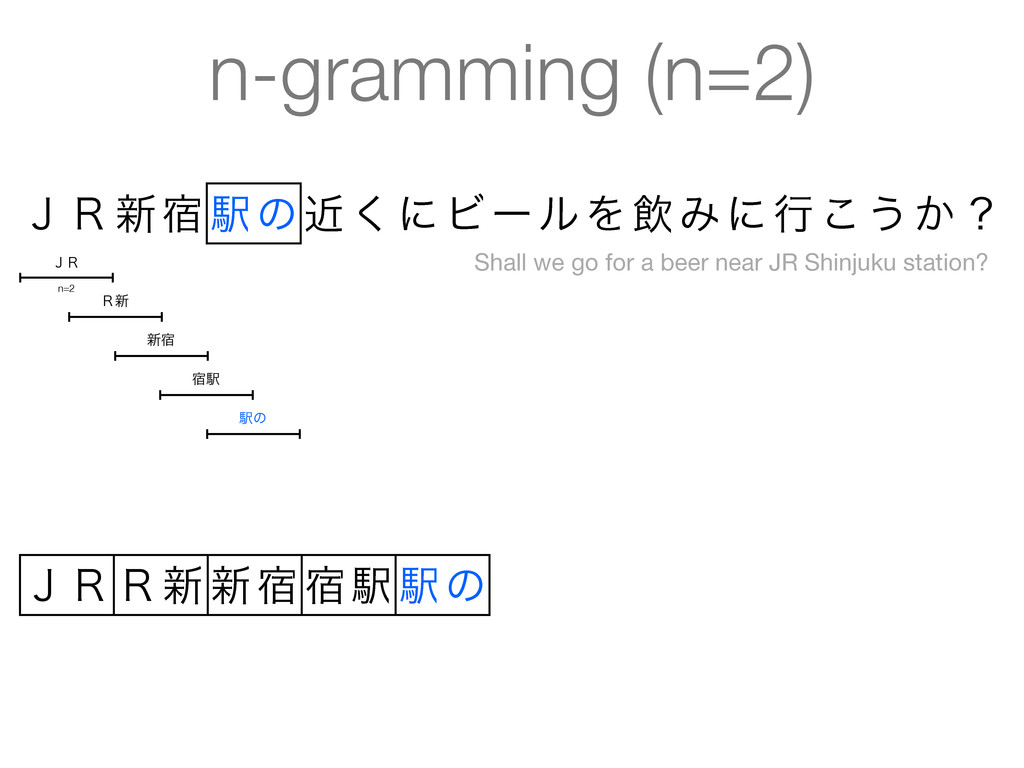
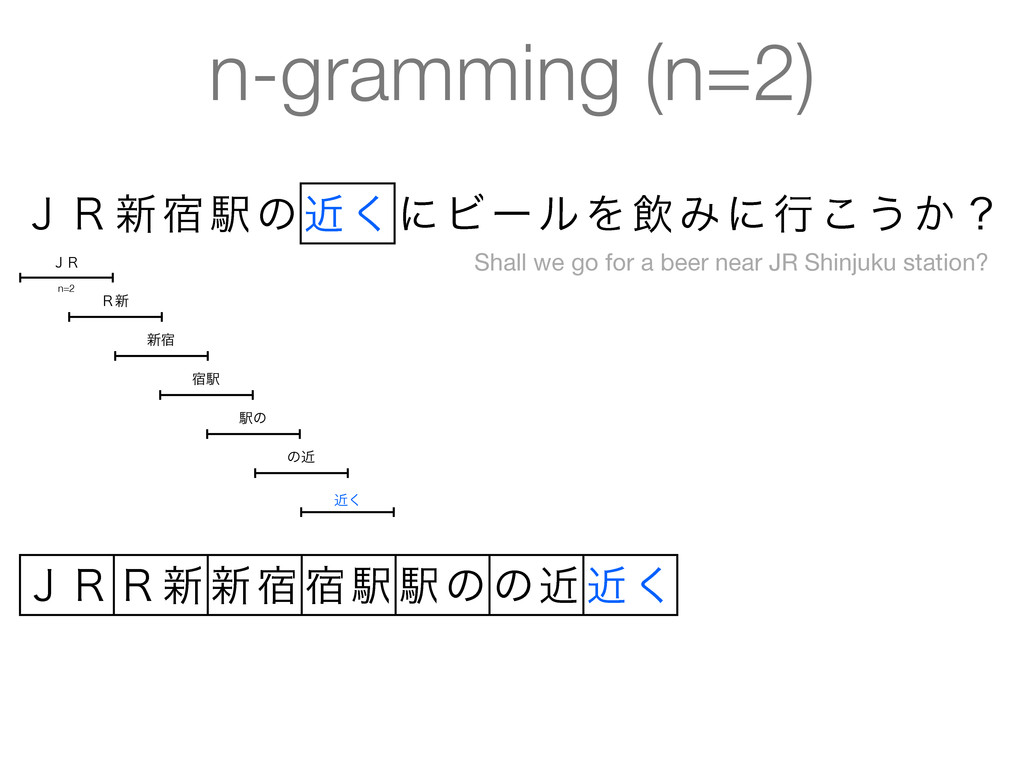
beer near JR Shinjuku station? • Tokens reflect what a Japanese speaker consider as words • Machine-learned statistical approach • CRFs decoded using Viterbi • Also does part-of-speech tagging, readings for kanji, etc. • Several statistical models available with high accuracy (F > 0.97) • Models/dictionaries are available as IPADIC, UniDic, ... • • • • • • • • • • • • • •
beer near JR Shinjuku station? • Tokens reflect what a Japanese speaker consider as words • Machine-learned statistical approach • Conditional Random Fields (CRFs) decoded using Viterbi • Also does part-of-speech tagging, readings for kanji, etc. • Several statistical models available with high accuracy (F > 0.97) • Models/dictionaries are available as IPADIC, UniDic, ... • • • • • • • • • • • • • •
beer near JR Shinjuku station? • Tokens reflect what a Japanese speaker consider as words • Machine-learned statistical approach • Conditional Random Fields (CRFs) decoded using Viterbi • Also does part-of-speech tagging, readings for kanji, etc. • Several statistical models available with high accuracy (F > 0.97) • Models/dictionaries are available as IPADIC, UniDic, ... • • • • • • • • • • • • • •
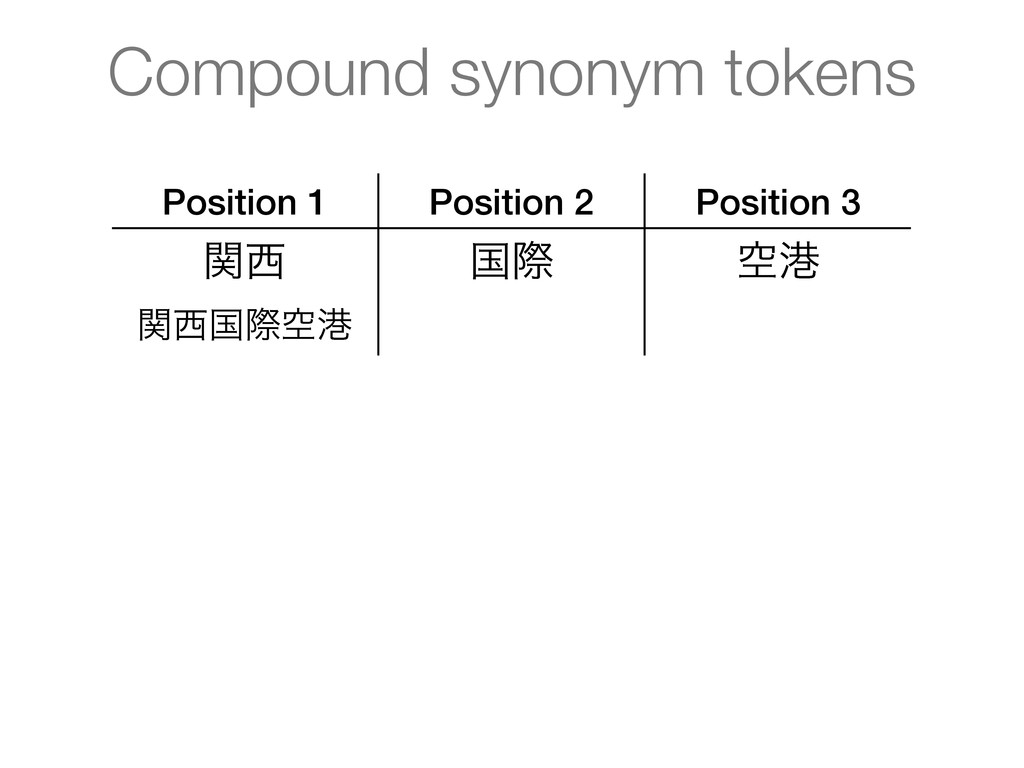
into tokens with very high accuracy • Token attributes for part-of-speech, base form, readings, etc. • Compound segmentation with compound synonyms • Segmentation is customisable using user dictionaries
• Token attributes for part-of-speech, base form, readings, etc. • Compound segmentation with compound synonyms • Segmentation is customisable using user dictionaries JapaneseBaseFormFilter Adjective and verb lemmatisation (by reduction) Feature summary / text_ja analyzer chain
• Token attributes for part-of-speech, base form, readings, etc. • Compound segmentation with compound synonyms • Segmentation is customisable using user dictionaries JapaneseBaseFormFilter Adjective and verb lemmatisation (by reduction) JapanesePartOfSpeechStopFilter Stop-words removal based on part-of-speech tags See example/solr/conf/lang/stoptags_ja.txt Feature summary / text_ja analyzer chain
• Token attributes for part-of-speech, base form, readings, etc. • Compound segmentation with compound synonyms • Segmentation is customisable using user dictionaries JapaneseBaseFormFilter Adjective and verb lemmatisation (by reduction) JapanesePartOfSpeechStopFilter Stop-words removal based on part-of-speech tags See example/solr/conf/lang/stoptags_ja.txt CJKWidthFilter Character width normalisation (fast Unicode NFKC subset) Feature summary / text_ja analyzer chain
• Token attributes for part-of-speech, base form, readings, etc. • Compound segmentation with compound synonyms • Segmentation is customisable using user dictionaries JapaneseBaseFormFilter Adjective and verb lemmatisation (by reduction) JapanesePartOfSpeechStopFilter Stop-words removal based on part-of-speech tags See example/solr/conf/lang/stoptags_ja.txt CJKWidthFilter Character width normalisation (fast Unicode NFKC subset) StopFilter Stop-words removal See example/solr/conf/lang/stopwords_ja.txt Feature summary / text_ja analyzer chain
• Token attributes for part-of-speech, base form, readings, etc. • Compound segmentation with compound synonyms • Segmentation is customisable using user dictionaries JapaneseBaseFormFilter Adjective and verb lemmatisation (by reduction) JapanesePartOfSpeechStopFilter Stop-words removal based on part-of-speech tags See example/solr/conf/lang/stoptags_ja.txt CJKWidthFilter Character width normalisation (fast Unicode NFKC subset) StopFilter Stop-words removal See example/solr/conf/lang/stopwords_ja.txt JapaneseKatakanaStemFilter Normalises common katakana spelling variations Feature summary / text_ja analyzer chain
• Token attributes for part-of-speech, base form, readings, etc. • Compound segmentation with compound synonyms • Segmentation is customisable using user dictionaries JapaneseBaseFormFilter Adjective and verb lemmatisation (by reduction) JapanesePartOfSpeechStopFilter Stop-words removal based on part-of-speech tags See example/solr/conf/lang/stoptags_ja.txt CJKWidthFilter Character width normalisation (fast Unicode NFKC subset) StopFilter Stop-words removal See example/solr/conf/lang/stopwords_ja.txt JapaneseKatakanaStemFilter Normalises common katakana spelling variations LowerCaseFilter Lowercases Feature summary / text_ja analyzer chain
Japanese English ؔࠃࡍۭߓ Kansai International Airport γχΞιϑτΣΞΤϯδχΞ Senior Software Engineer These are one word in Japanese, so searching for ۭߓ (airport) doesn’t match !
need to segment the compounds, too ? ! Japanese English ؔࠃࡍۭߓ Kansai International Airport γχΞιϑτΣΞΤϯδχΞ Senior Software Engineer These are one word in Japanese, so searching for ۭߓ (airport) doesn’t match !
ࠃࡍ ۭߓ ؔࠃࡍۭߓ • Segment the compounds into its part • Good for recall - we can also search and match ۭߓ (airport) • We keep the compound itself as a synonym • Good for precision with an exact hit because of IDF • Approach benefits both precision and recall for overall good ranking • JapaneseTokenizer actually returns a graph of tokens
ࠃࡍ ۭߓ ؔࠃࡍۭߓ • Segment the compounds into its parts • Good for recall - we can also search and match ۭߓ (airport) • We keep the compound itself as a synonym • Good for precision with an exact hit because of IDF • Approach benefits both precision and recall for overall good ranking • JapaneseTokenizer actually returns a graph of tokens
ࠃࡍ ۭߓ ؔࠃࡍۭߓ • Segment the compounds into its parts • Good for recall - we can also search and match ۭߓ (airport) • We keep the compound itself as a synonym • Good for precision with an exact hit because of IDF • Approach benefits both precision and recall for overall good ranking • JapaneseTokenizer actually returns a graph of tokens
ࠃࡍ ۭߓ ؔࠃࡍۭߓ • Segment the compounds into its parts • Good for recall - we can also search and match ۭߓ (airport) • We keep the compound itself as a synonym • Good for precision with an exact hit because of IDF • Approach benefits both precision and recall for overall good ranking • JapaneseTokenizer actually returns a graph of tokens
̍ ̎ ̏ Input text ̴̴̡̲̈́̽ ŜŦŜū ̍ ̎ ̏ CJKWidthFilter Lucene ΧλΧφ 1 2 3 half-width full-width half-width Use CJKWidthFilter to normalise them (Unicode NFKC subset) ! How do we deal with character widths? ?
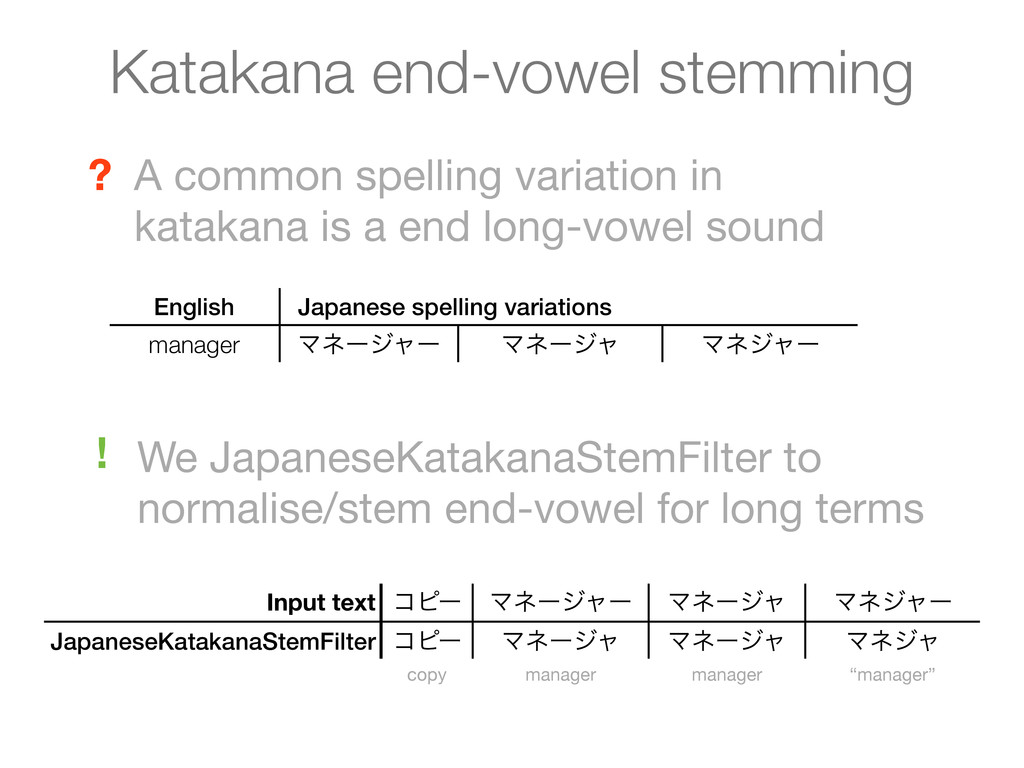
Japanese spelling variations manager Ϛωʔδϟʔ Ϛωʔδϟ Ϛωδϟʔ Input text ίϐʔ Ϛωʔδϟʔ Ϛωʔδϟ Ϛωδϟʔ JapaneseKatakanaStemFilter ίϐʔ Ϛωʔδϟ Ϛωʔδϟ Ϛωδϟ copy manager manager “manager” We JapaneseKatakanaStemFilter to normalise/stem end-vowel for long terms ! A common spelling variation in katakana is a end long-vowel sound ?
hoc segmentation, i.e. to override default model • File format is simple and there’s no need to assign weights, etc. before using them • Example custom dictionary: # Custom segmentation and POS entry for long entries ؔࠃࡍۭߓ,ؔ ࠃࡍ ۭߓ,ΧϯαΠ ίΫαΠ Ϋί,ΧελϜ໊ࢺ # Custom reading and POS former sumo wrestler Asashoryu ே੨ཾ,ே੨ཾ,ΞαγϣϦϡ,ΧελϜਓ໊
search mode for katakana compounds • Improved unknown word segmentation • Some performance improvements • CharFilters for various character normalisations • Dates and numbers • Repetition marks (odoriji) • Japanese spell-checker • Robert and Koji almost got this into 3.6, but it got postponed because of API changes being necessary
into Lucene and always reviewing my patches quickly and for friendly help Michael McCandless Thanks for streaming Viterbi and synonym compounds Uwe Schindler Thanks for performance improvements + being the policeman Simon Willnauer Thanks for doing the Kuromoji code donation process so well Gaute Lambertsen & Gerry Hocks Thanks for presentation feedback and being great colleagues
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}