Dealing with computer vision competition on Kaggle
In this talk we will discuss how to start dealing with computer vision challenges: GPU-resources, which competition to choose, what tutorial to take before start and how to improve your score
https://www.meetup.com/Kaggle-Munich/events/248986846/
• Data Science & Data Analysis, 5+ years (industry and academia) • Currently: Senior Data Scientist, KI-Labs • Previous: Senior Data Scientist, VEON (Telecom)
(from10mb In ML up to 300gb in CV) • Complicate submission (up to 2gb) • High entity level for knowlege • High entity level for hardware (GPU) • Complicate Project structure (engineering skills) • Much more interesting than stacking xgboosts ensembles!
CV knowledge (1-4 lecture of fast.ai course / cs231 lectures) • Check public kernels/github and understand task and solution pipeline • Complete simple bencmark & Submit prediction (not easy) 2. Improve knowledge and score: • Check solution from previous similar competition • Try to understand it as deep as you can (this is rigth time to finish with fast.ai, read some chapters from DL book, classic articles, etc ) • Improove your current solution • Don‘t forget about kaggle tricks & liks :)
a big dataset (to feed the images to pytorch efficiently) 2. Finetuning pretrained models (inception-resnet-v2 resnet50). 3. Use OCR to add semantics to the models. 4 Nvidia 1080ti GPU devbox
Resnet- 152 • Out of fold prediction (averaging, 2nd layer) • Decrise learning rate for epochs 1..5: lr = 0.001, 6: lr = 0.0001, 7: lr = 0.00001 • Increase batch size for epochs • Test Time Augmentation (5-10 random trasforming + averaging) • Hard negative sampling (rebalance to minimize false detection) • Decrease image size, use random crops + random flips for augmentation • Ensembles: Averaging (arifm, geom), 2nd layer
weights from Imagenet (increase channels from 512 to 5k), there were not frozen layers, the augmentation was disabled. • as soon as the validation score stopped growing, we added augmentation and doubled batch size – score began to grow sharply. But, after a while the growth stopped • repeated this procedure again and again
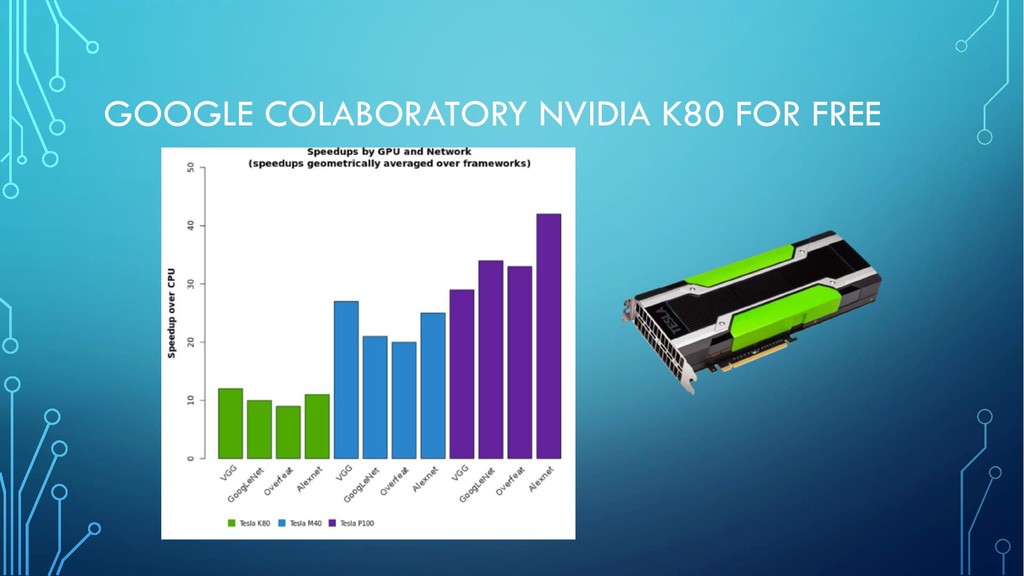
need only google account • Easy map google drive • Looks like usual Jupyter notebook (ssh-access also possible) • Submit prediction straight from colaboratory (kaggle-api) • VM creates for 12 hours (use checkpoints to save&load and continue) • Don‘t forget to set GPU in hardware accelerator!
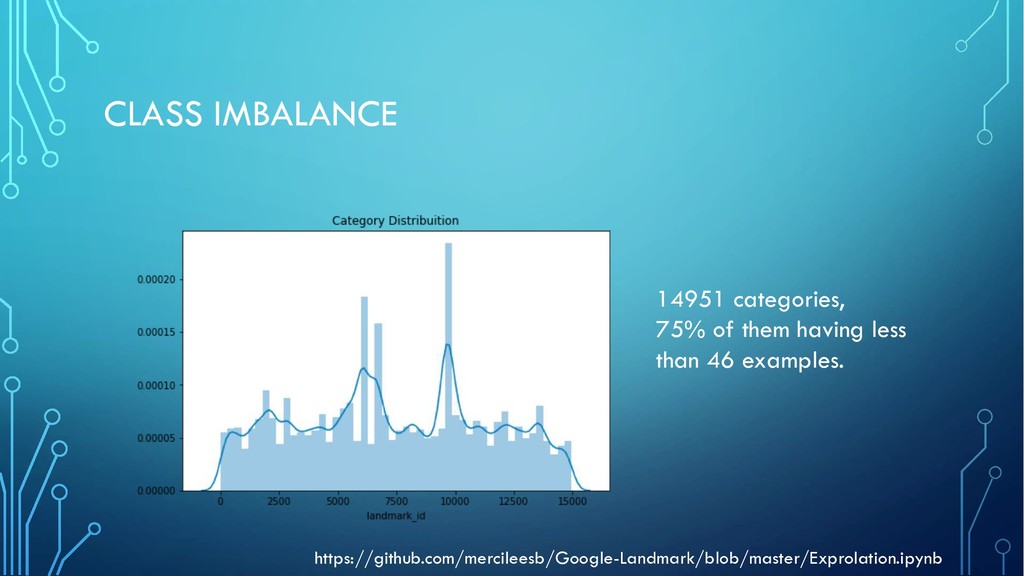
etc. Original data: 300GB Task: predict a space-delimited list of index images that depict the same landmarks as the query sample_submission.csv.zip > 100MB
Networks for Visual Recognition - Stanford by Fei-Fei Li, Andrej Karpathy http://vision.stanford.edu/teaching/cs231n/syllabus.html • Colab tutorial&mout Google Drive: https://medium.com/deep-learning-turkey/google-colab-free-gpu-tutorial-e113627b9f5d • Use Tensor Board in Colab: https://stackoverflow.com/a/48468512/1334157 • List of competitions to join (not only kaggle) https://github.com/iphysresearch/DataSciComp#active-competitons-to-join • Using Transfer Learning with Pre-Trained Keras Models to Distinguish Dog Breeds https://www.kaggle.com/gaborfodor/dog-breed-pretrained-keras-models-lb-0-3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}