This talk discusses questions such as: How not to fail with your 99%-accuracy model in production? Which metrics should be checked and when? How do you control live predictions? What to do if your model accuracy is degrading? Using some live examples, we will cover the main quality assurance steps that can be applied alongside model development and deployment, and we present the practices of unit testing and results monitoring for production.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
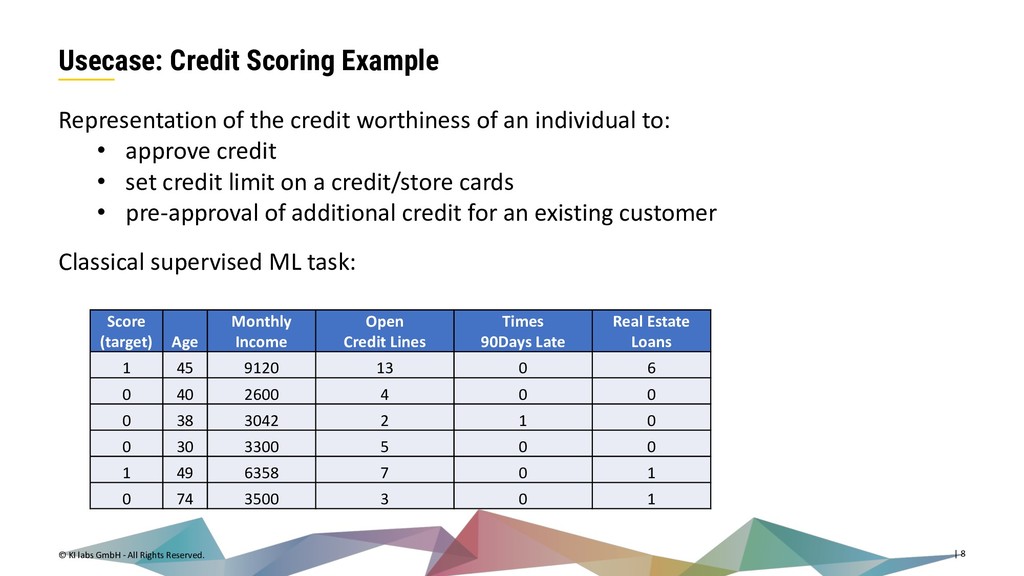{kind=link}
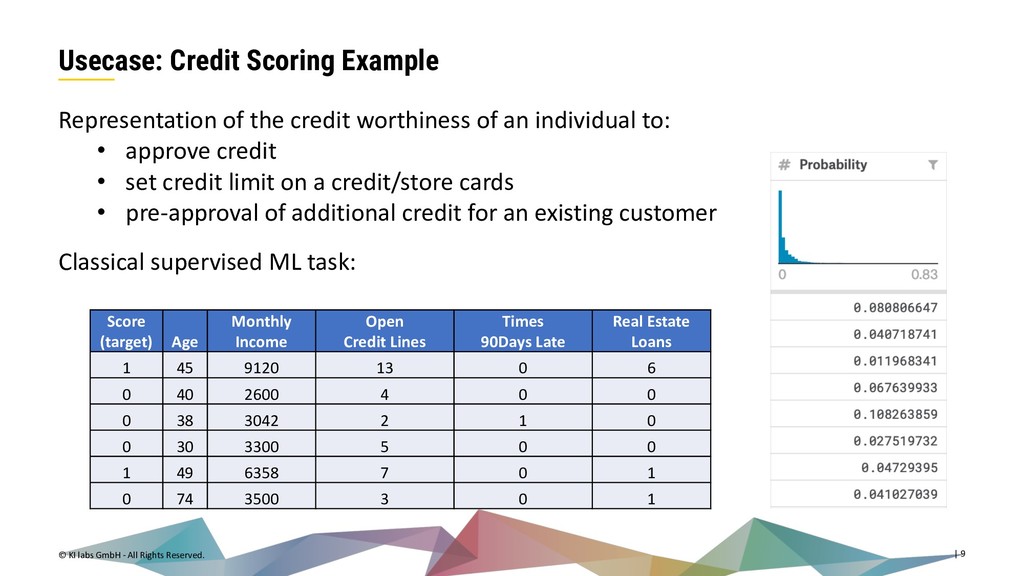{kind=link}
{kind=link}
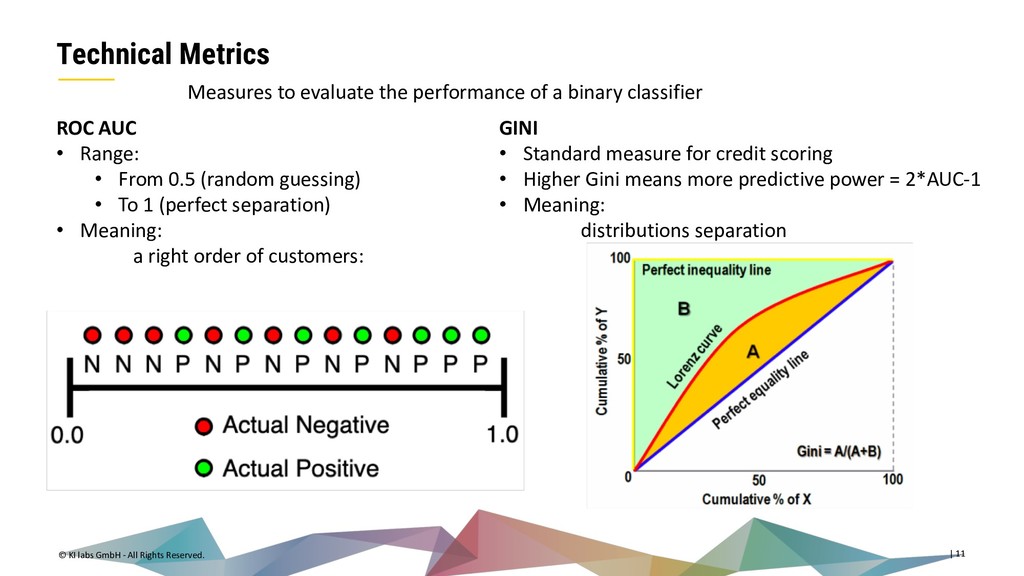{kind=link}
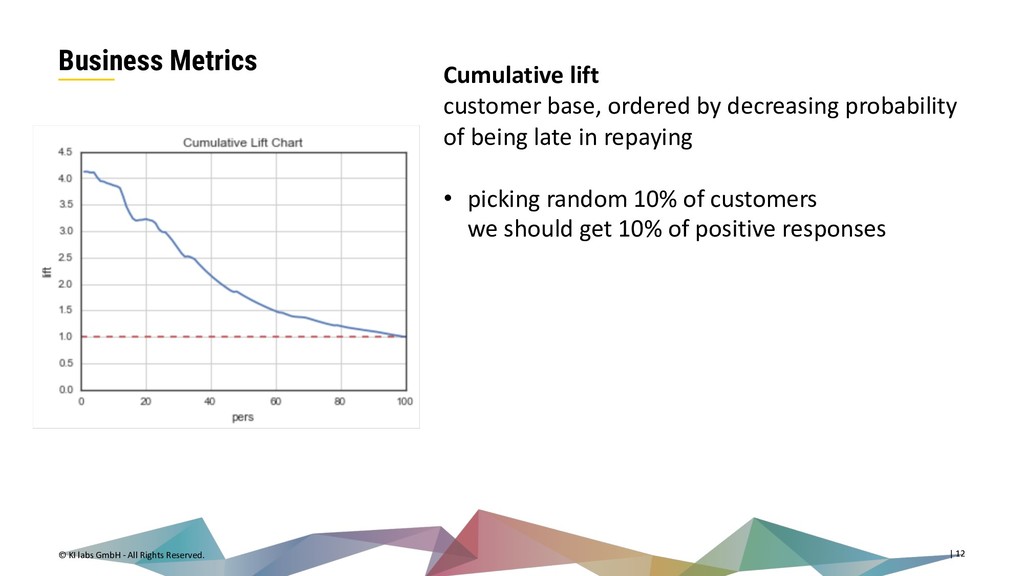{kind=link}
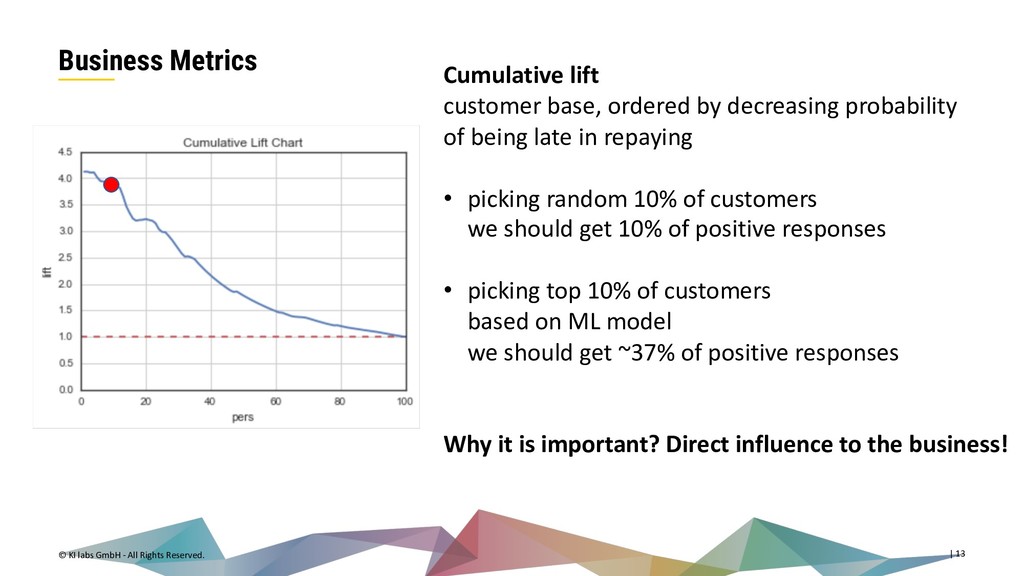{kind=link}
{kind=link}
{kind=link}
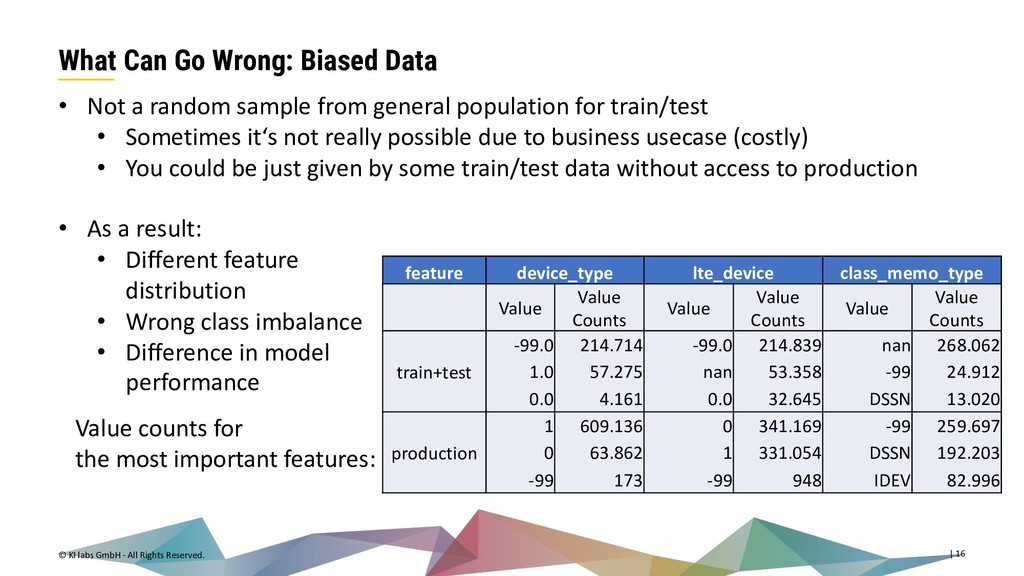{kind=link}
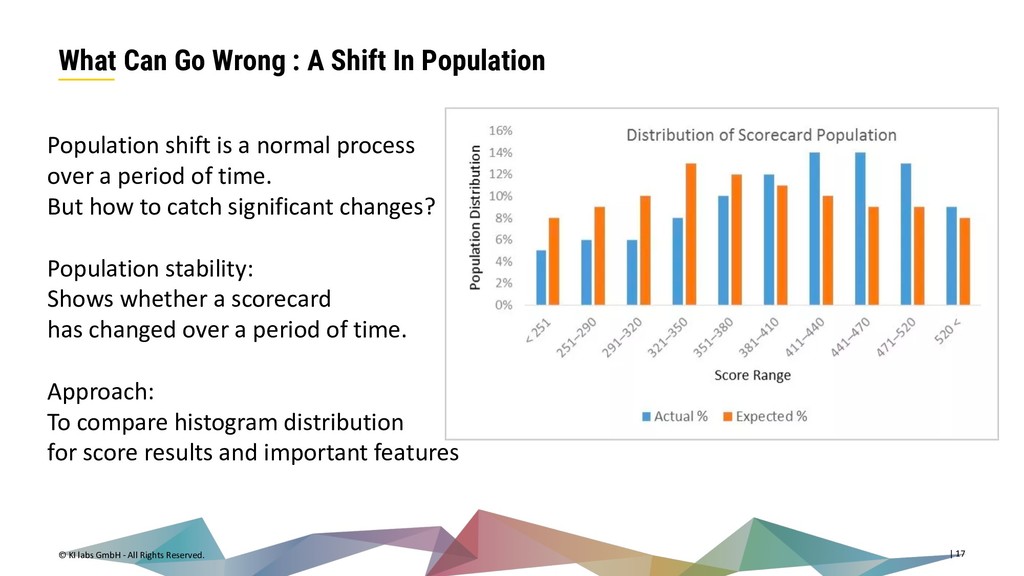{kind=link}
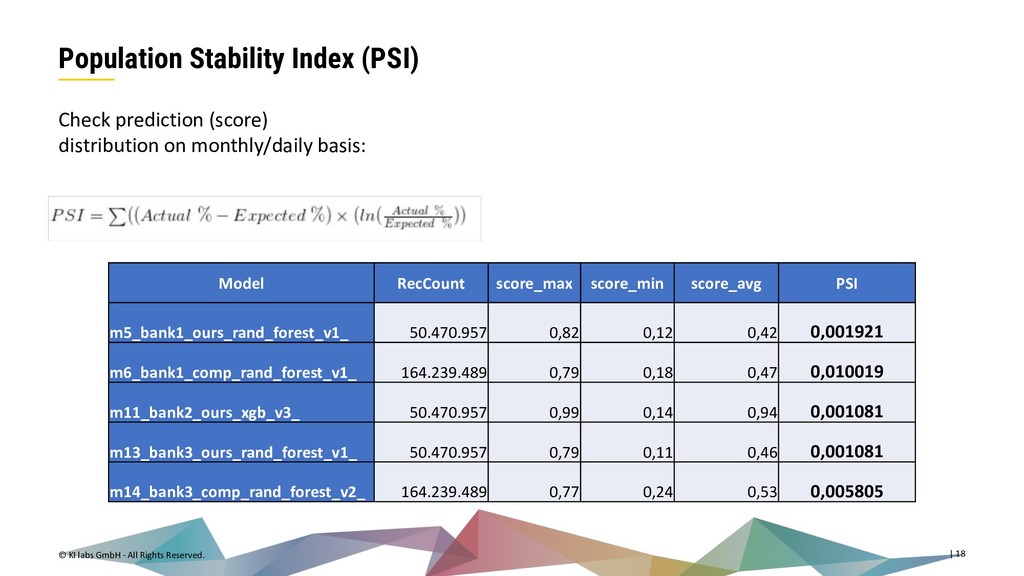{kind=link}
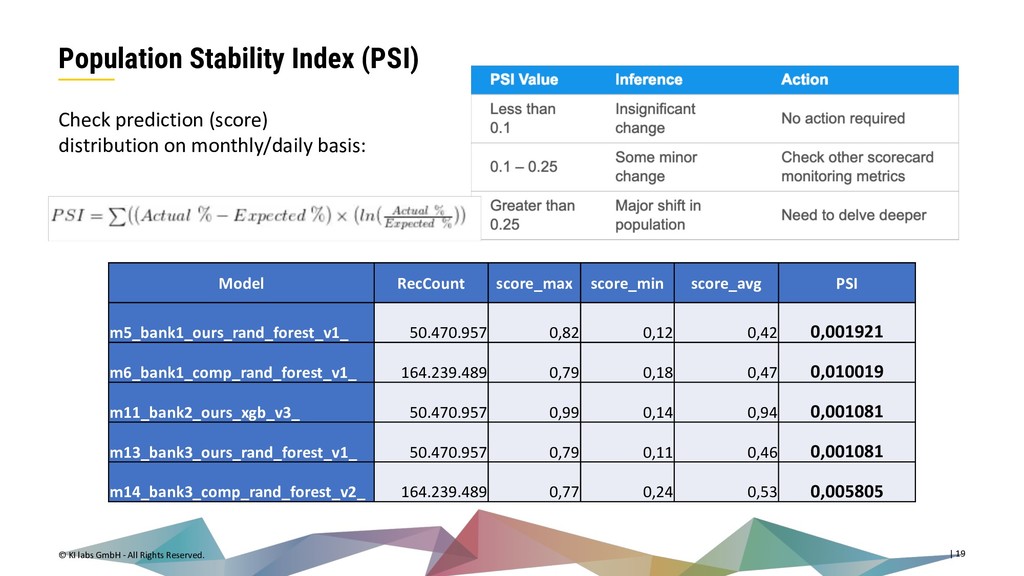{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
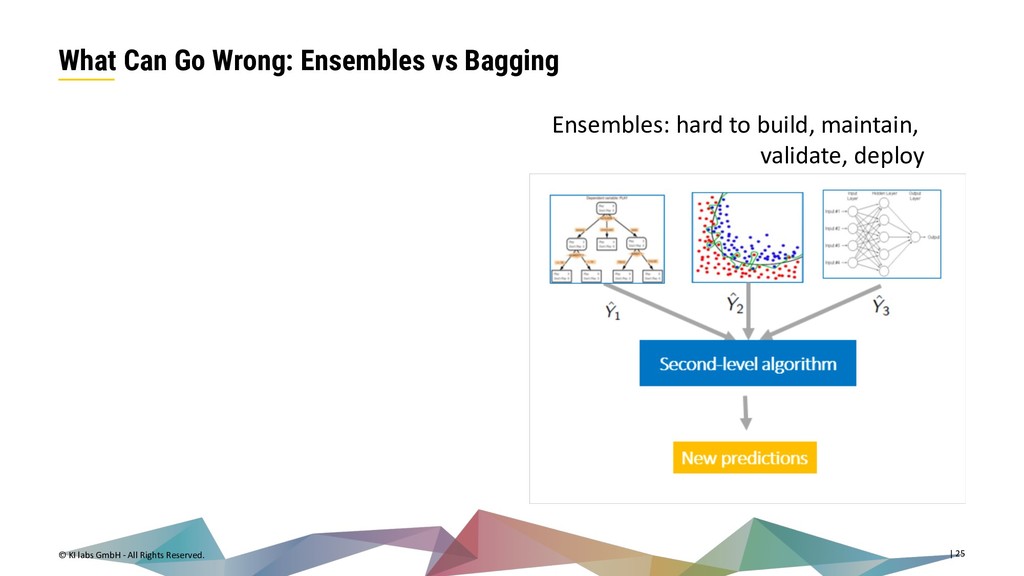{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}