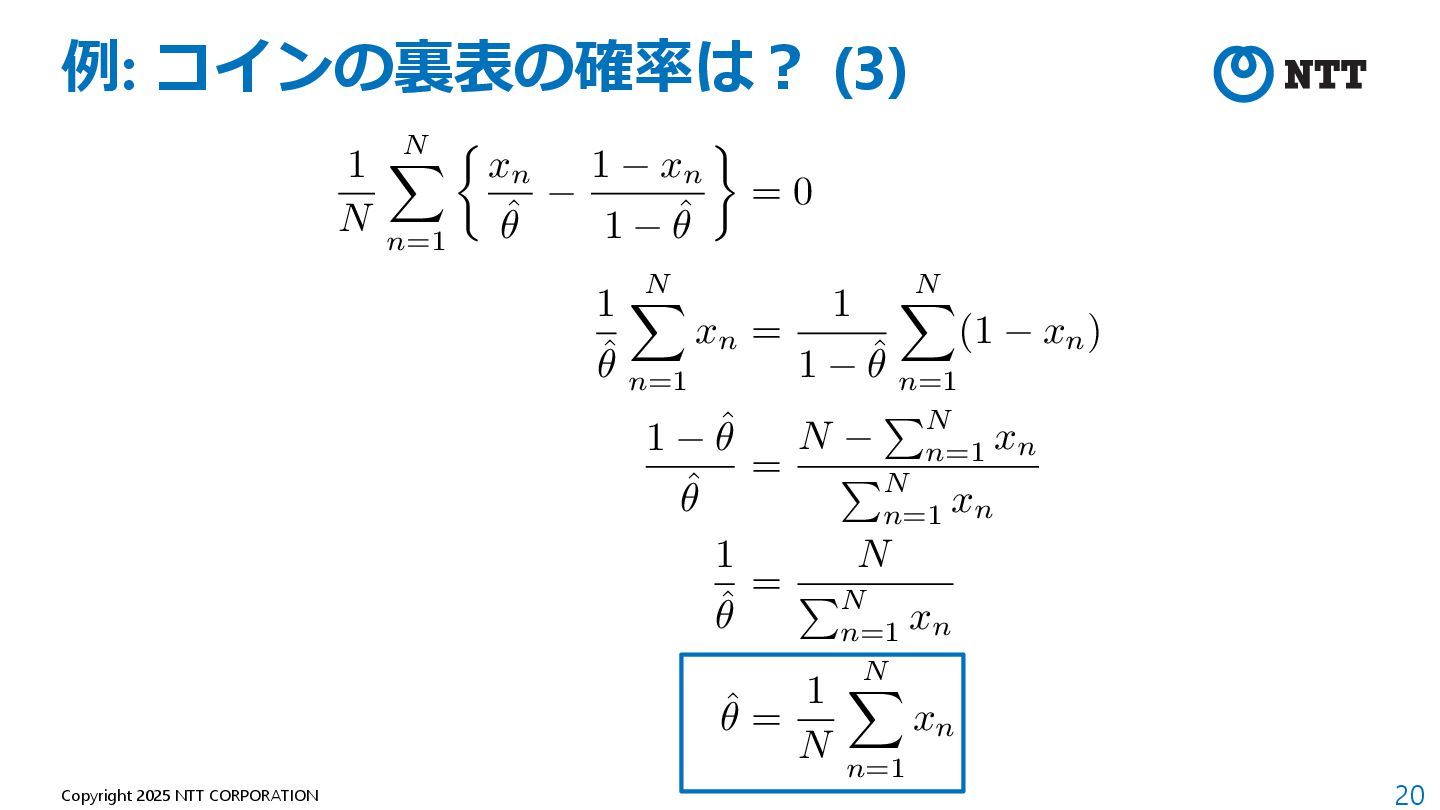
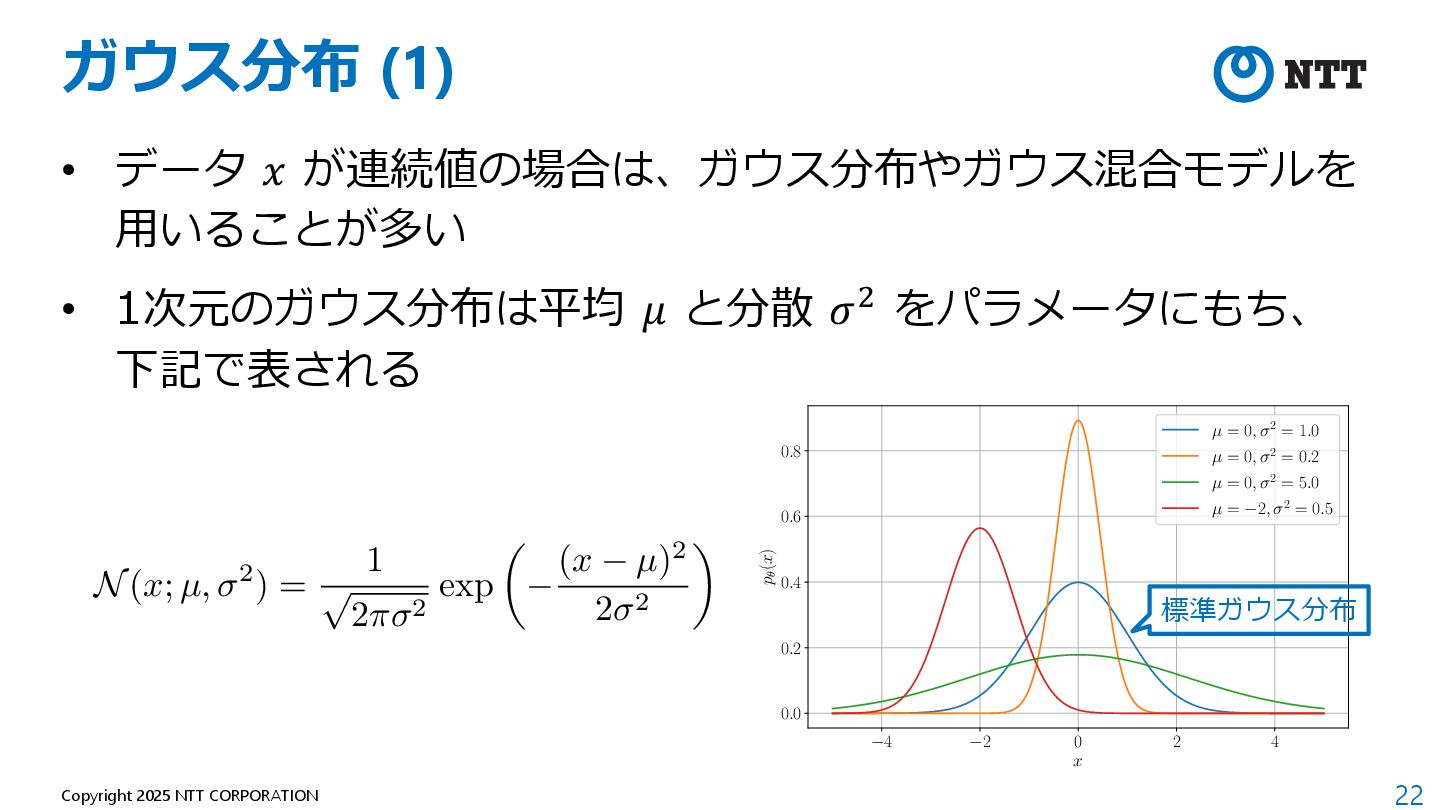
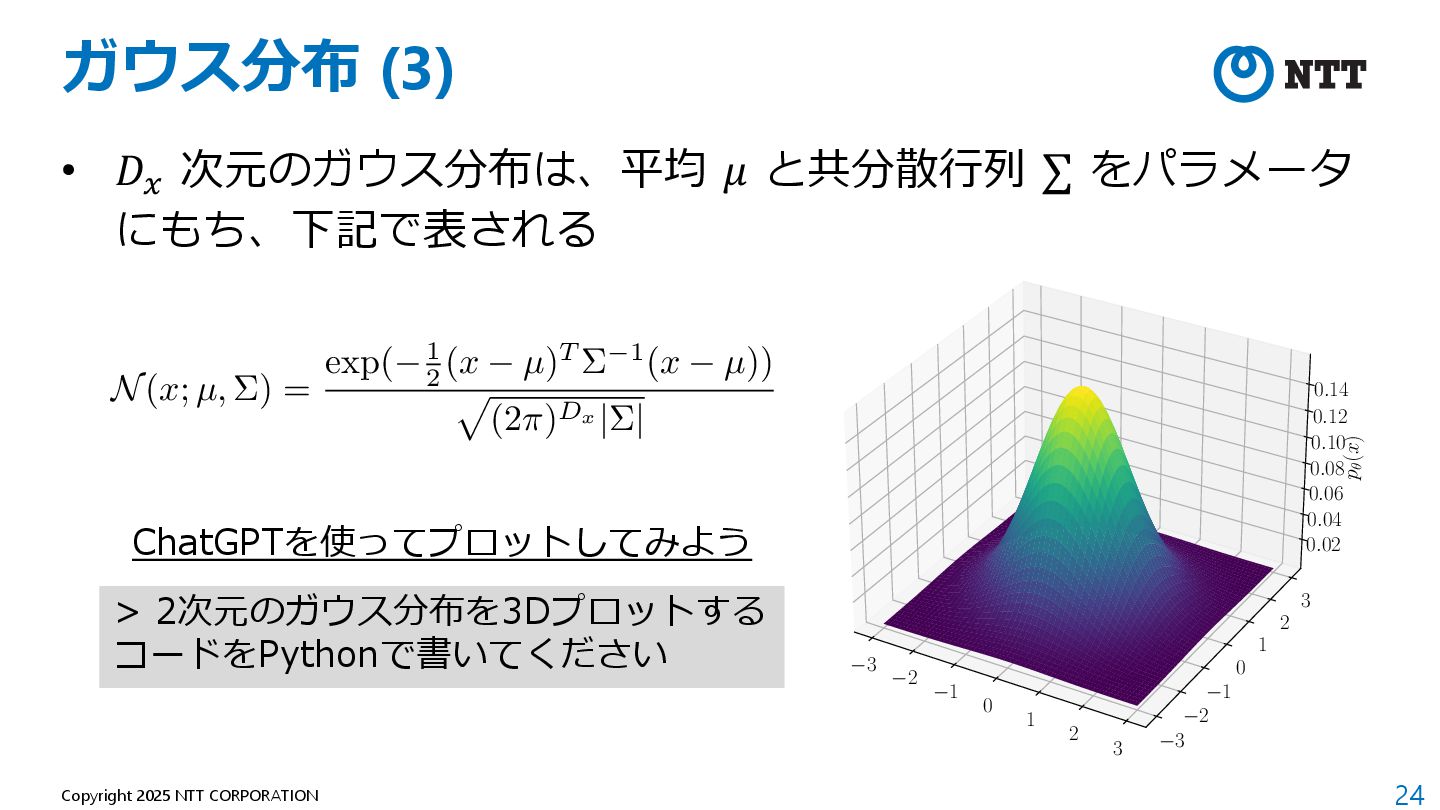
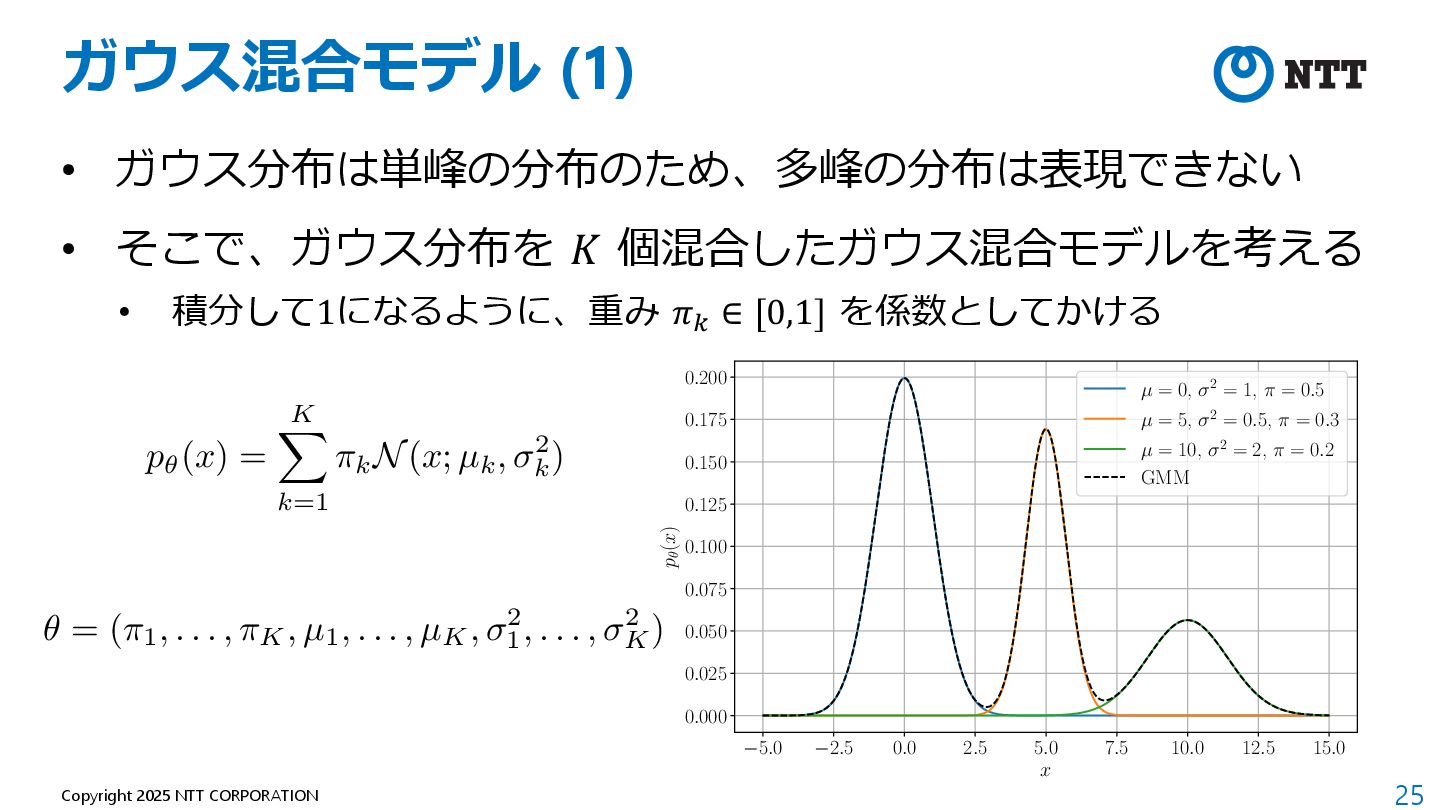
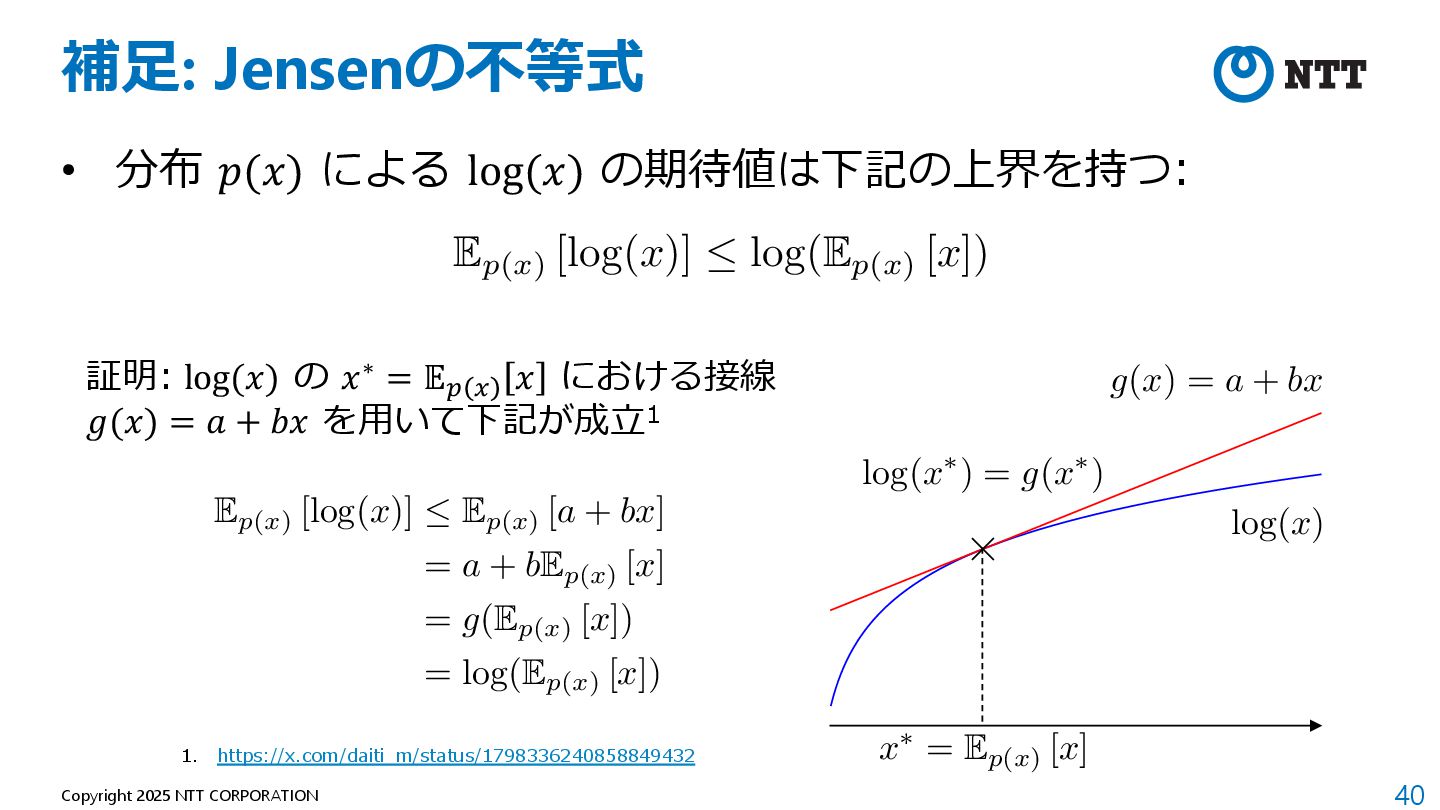
したがって、上記の最⼩化は下記で書き換えられる 定数 (⽣成モデルに関係ない値) 定数を除き、最⼩化を最⼤化に データセットを⽤いて近似 <latexit sha1_base64="kFPFWdBThJaNI6SLjm+pPUKthis=">AAADpnicnVLLbtNAFL2uebTh0dBuKrGJiFrSikZjhNoKCakCFkg8+iJNpbo1Y3fijOqX7EmU4PoH+AEWXYHEAvEZbPgBFv0E1GWRkBAL7thDKURQxFj23HvmnnOPR9eOPJ4IQg60If3M2XPnh0dKFy5eujxavjK2noSd2GENJ/TCeMOmCfN4wBqCC49tRDGjvu2xpr17T543uyxOeBg8Ff2IbfnUDXiLO1QgZJX3TZ+KduynDx9ltWg7nclqvem9vchKTdFmgsp0euqOyQNhpbO4tUQ/205V8INgeqFbOU6U4k7Wm/0n3sleJ8glq1wldZKvymBgqKAKai2H5a9gwg6E4EAHfGAQgMDYAwoJPptgAIEIsS1IEYsx4vk5gwxKyO1gFcMKiugufl3MNhUaYC41k5ztYBcP3xiZFZgkH8lbckQ+kHfkE/n2R60015Be+rjbBZdF1uiLibUvp7J83AW0f7L+6llACxZyrxy9Rzki/8Ip+N3nL4/Wbq9OplPkNTlE/6/IAXmPfxB0PztvVtjqPqpL/fvIKu4wxuix8rCEigwRmclbmME+Zl7jok/ZMVN37CJ+4xj7X0UKvQHFApNjYvw+FIPB+s26MVefW7lVXbyrBmYYrsI1qOFUzMMiPIBlaICjadp1jWiGXtOf6A29WZQOaYozDr8s/dl3mXnkfA==</latexit> KL(p⇤(x)||p✓(x)) = Z 1 1 p⇤(x) log p⇤(x)dx Z 1 1 p⇤(x) log p✓(x)dx <latexit sha1_base64="YSdoxOtWeF/RDSW5OY9vHDy6hjI=">AAADynicnVJLaxRBEK7J+IjrI6teBC+Ly4bdoEuPSBQhENSDkKh5bRLIJEPPpHe2ybzs6V127czNk3/AgycFD+KP8ODFP+AhP0E8RhDEgzWPJGwWDdjDdFd9Vd9X1U3ZkcdjScieNqafOn3m7Pi50vkLFy9NlC9fWY3DrnBYywm9UKzbNGYeD1hLcumx9Ugw6tseW7N3HqbxtR4TMQ+DFTmI2KZP3YC3uUMlQlb5k+nzwFKm7DBJE9OnsiN8NTef1KMtNZXU+43d3egwjm5jcgaz+kcUHkhL3cKjLQfJliqMA7bphW5lSOCgxnbSN2Pus+fDcm1BHWUk6mlixl3fUsGMgaroHRfCUNIoWeUqaZJsVUYNozCqUKyFsPwLTNiGEBzogg8MApBoe0Ahxm8DDCAQIbYJCjGBFs/iDBIoIbeLWQwzKKI7uLvobRRogH6qGWdsB6t4+AtkVqBGvpIPZJ98IR/JN/L7r1oq00h7GeBp51wWWROvri3/PJHl4ymhc8T6Z88S2nAv65Vj71GGpLdwcn7vxev95ftLNTVJ3pHv2P9bskc+4w2C3g/n/SJbeoPqqf4jZOVvKNB6UvTwDBUZIqmXvsIU1jGzHBf7TCsmxRu7iN88xP5XkUJ/RDHH0jExjg/FqLF6u2lMN6cX71RnHxQDMw7X4QbUcSruwiw8hgVogaPVtDltRWvp87rQB7rKU8e0gnMVhpb+8g9fZPVv</latexit> min ✓ KL(p⇤(x)||p✓(x)) = max ✓ Z 1 1 p⇤(x) log p✓(x)dx ' max ✓ 1 N N X n=1 log p✓(xn)
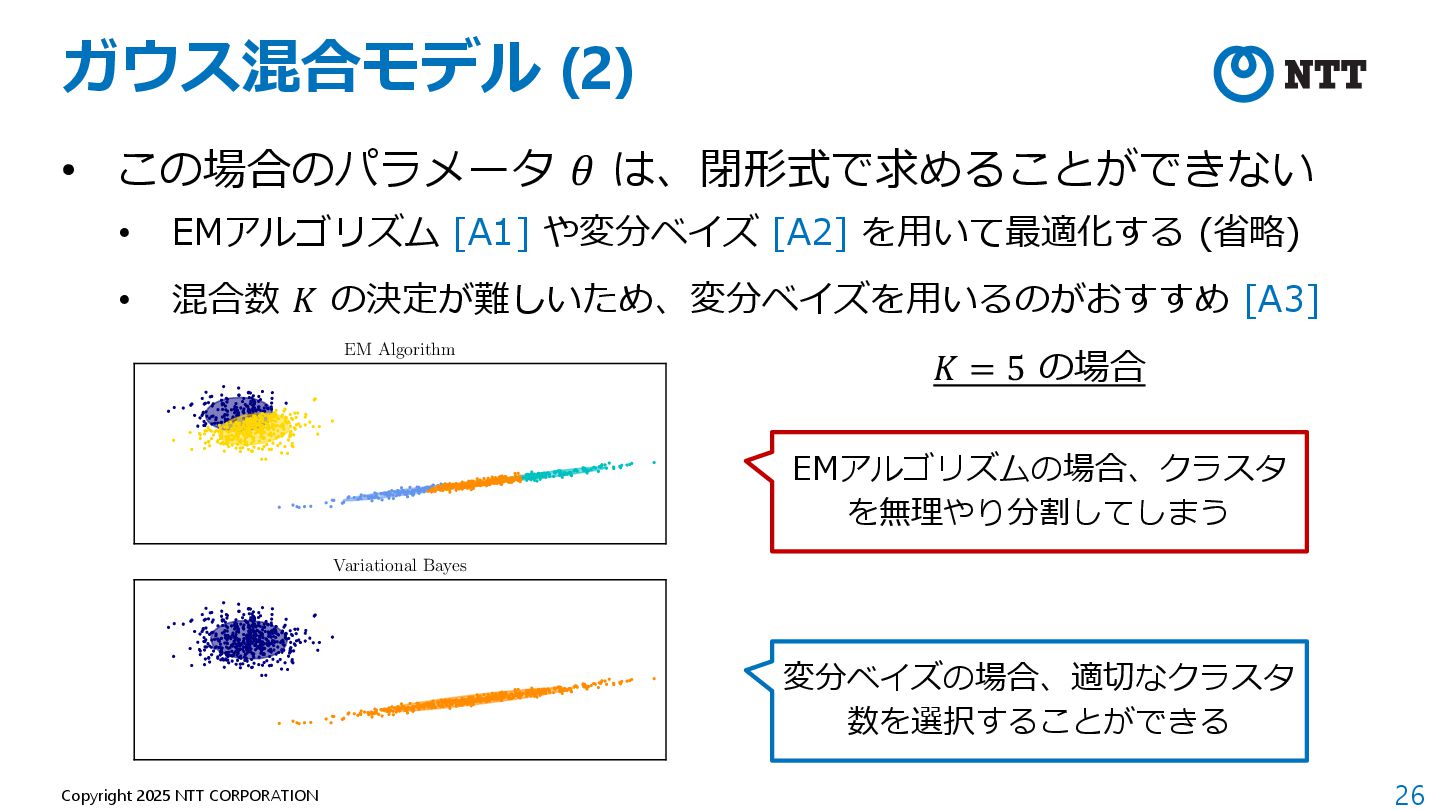
https://en.wikipedia.org/wiki/Expectation%E2%80%93maximization_algorithm 2. Blei, David M., and Michael I. Jordan. "Variational inference for Dirichlet process mixtures." (2006): 121-143. 3. "2.1. Gaussian mixture models", https://scikit-learn.org/stable/modules/mixture.html
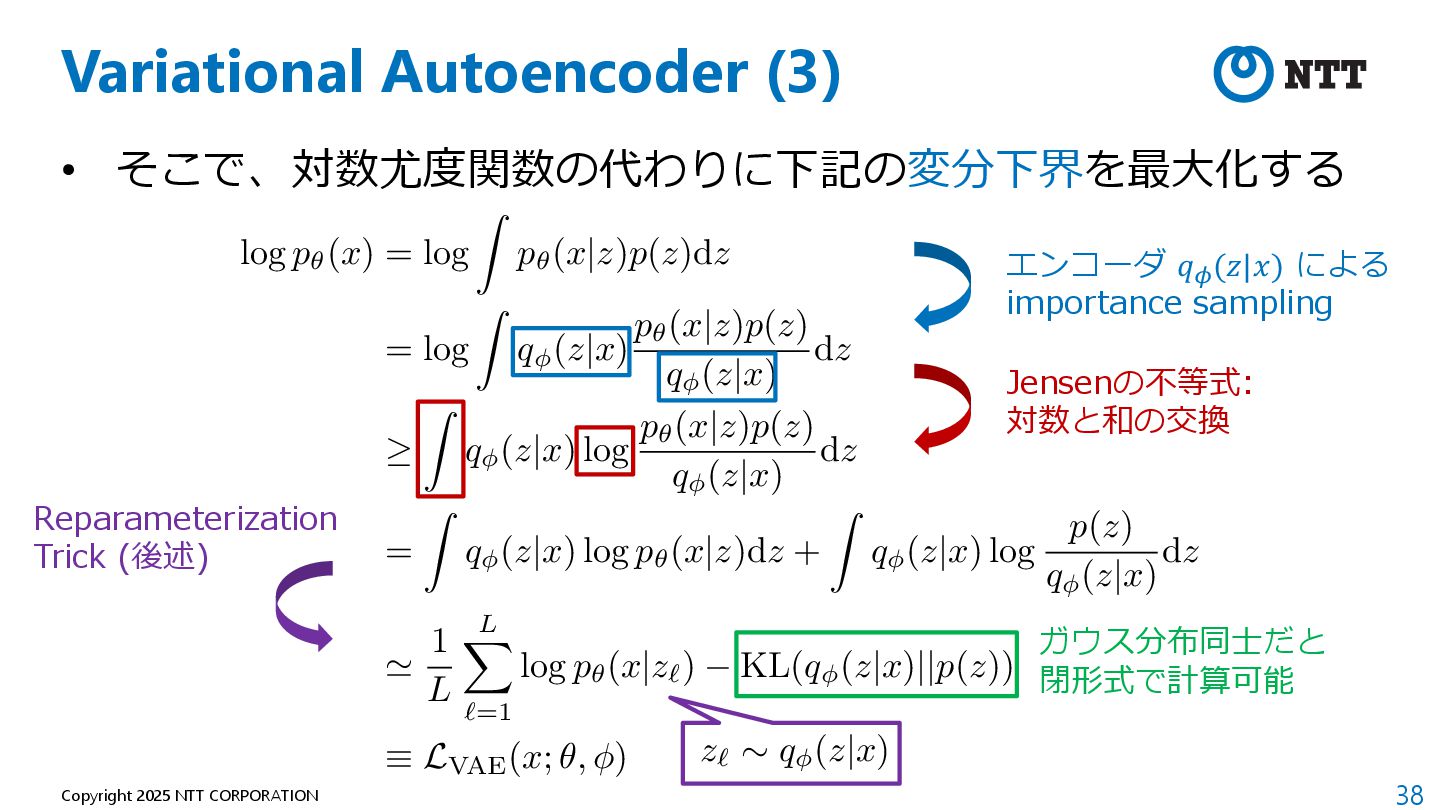
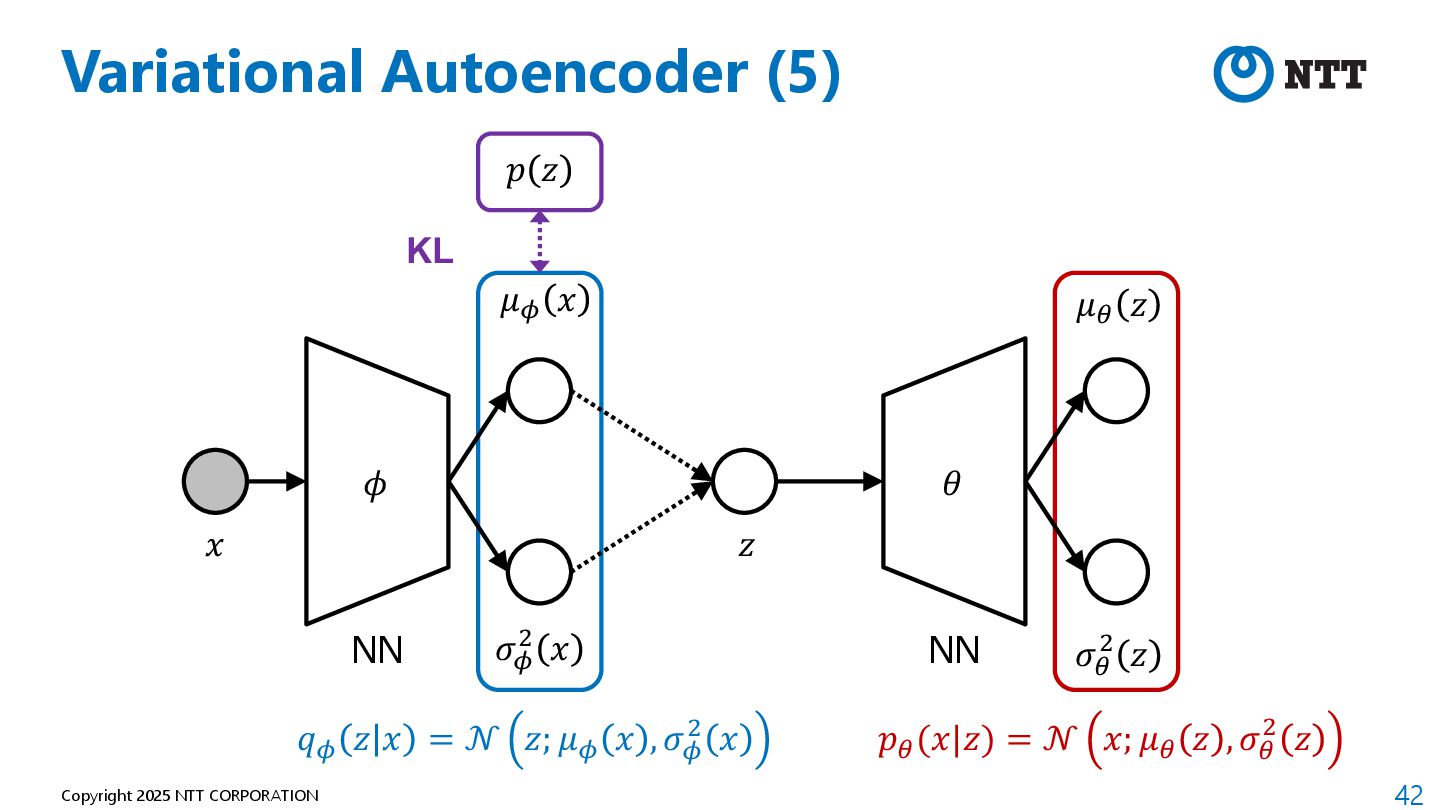
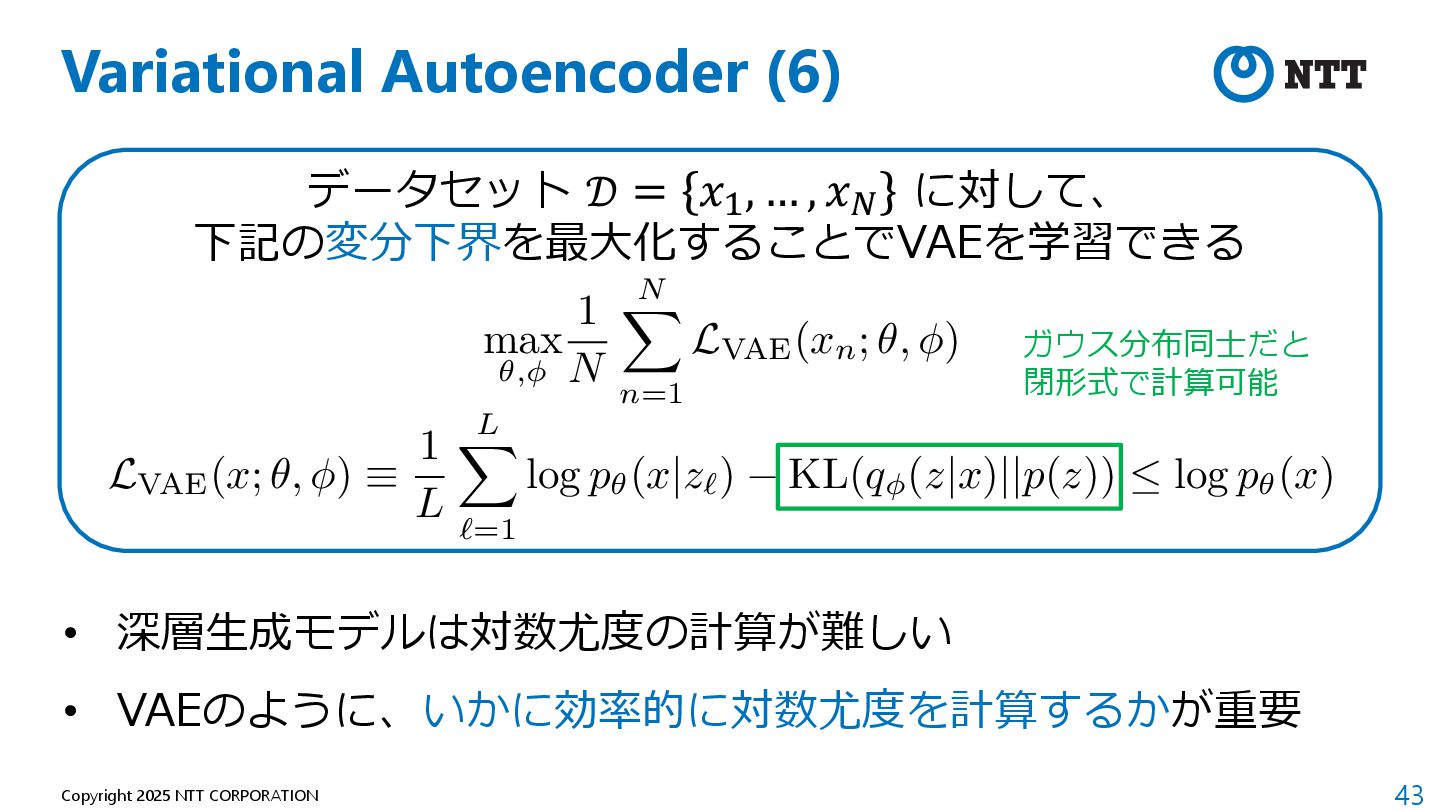
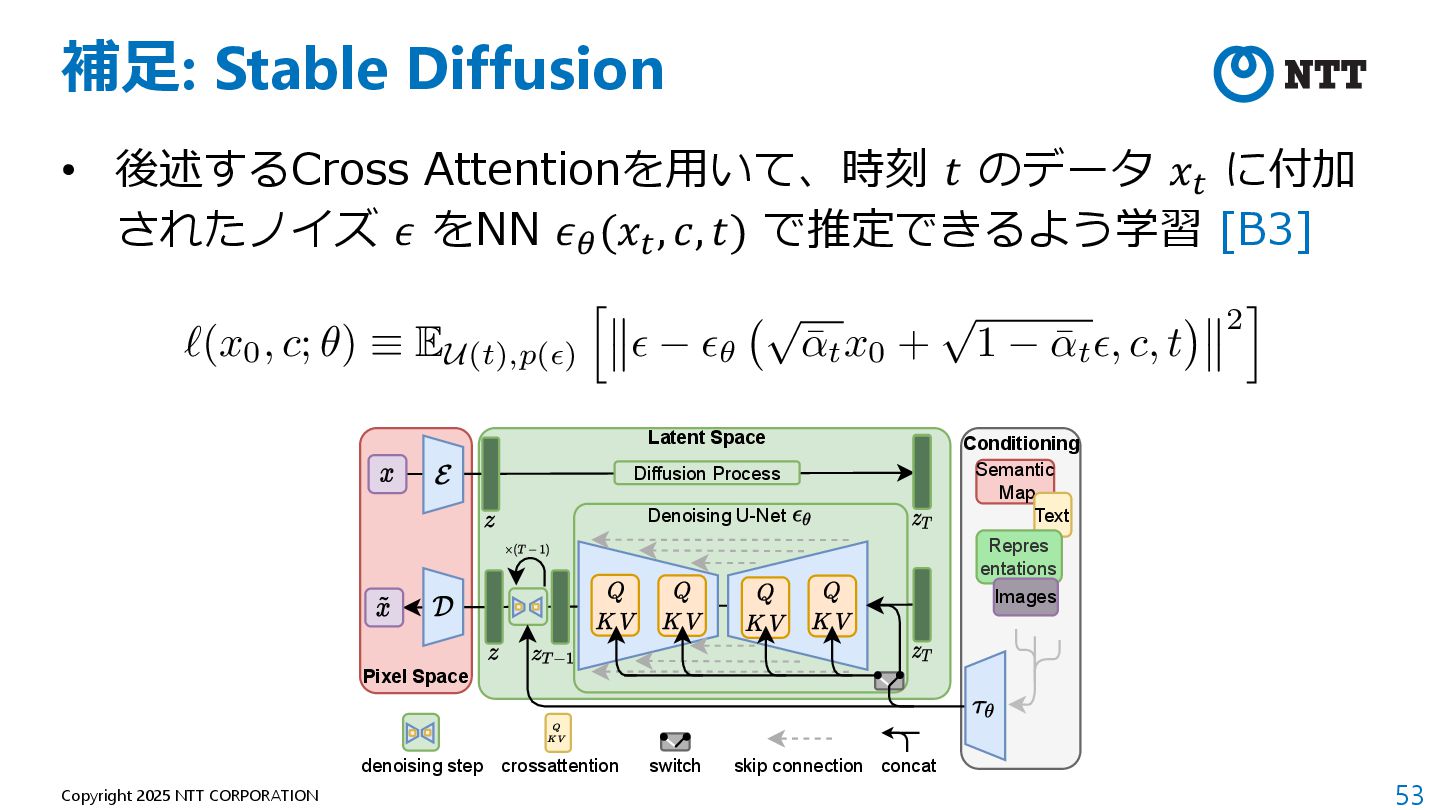
P., and Max Welling. "Auto-encoding variational bayes." arXiv preprint arXiv:1312.6114 (2013). 2. Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in neural information processing systems 33 (2020): 6840-6851. 3. Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022. 4. Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
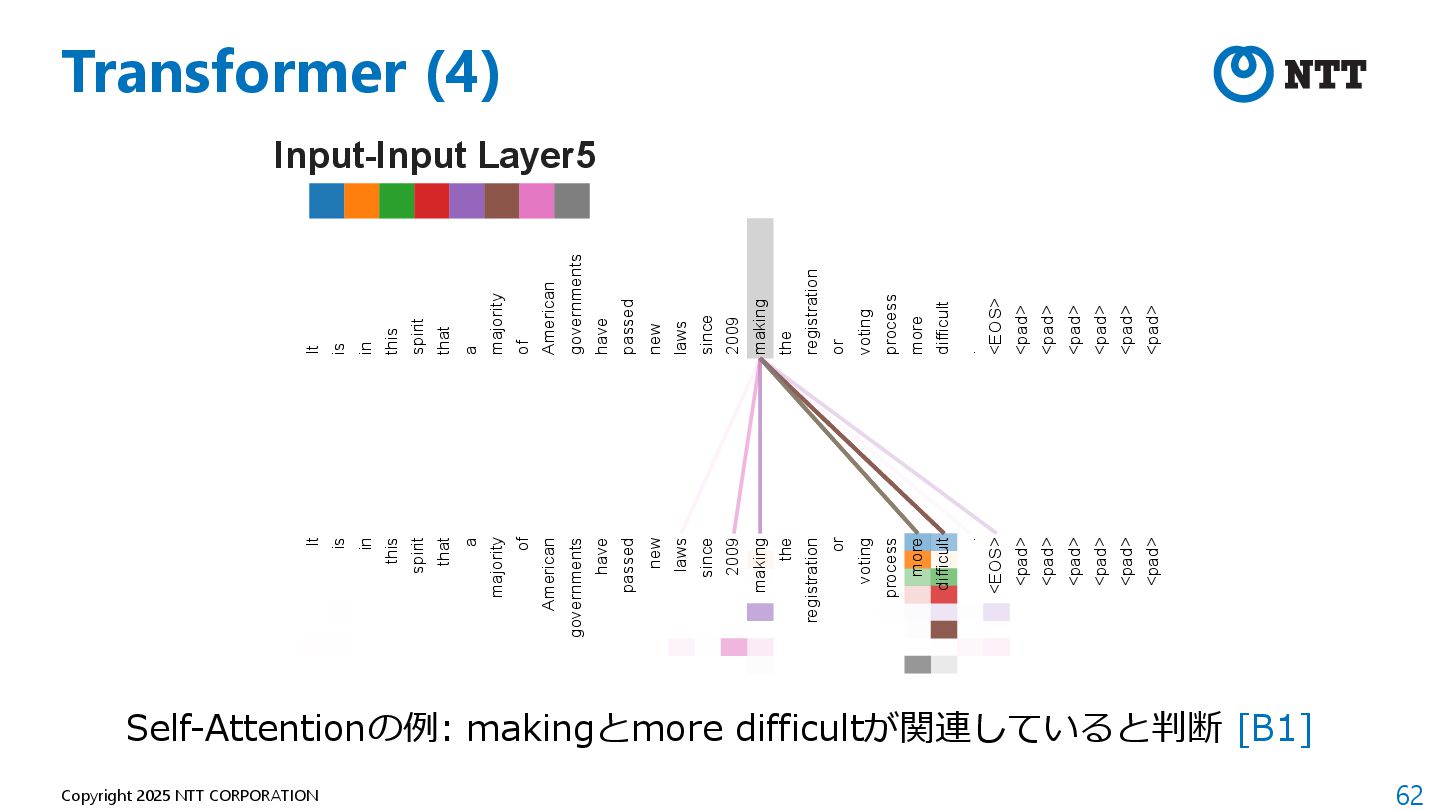
is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult . <EOS> <pad> <pad> <pad> <pad> <pad> <pad> It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult . <EOS> <pad> <pad> <pad> <pad> <pad> <pad> Self-Attentionの例: makingとmore difficultが関連していると判断 [B1]
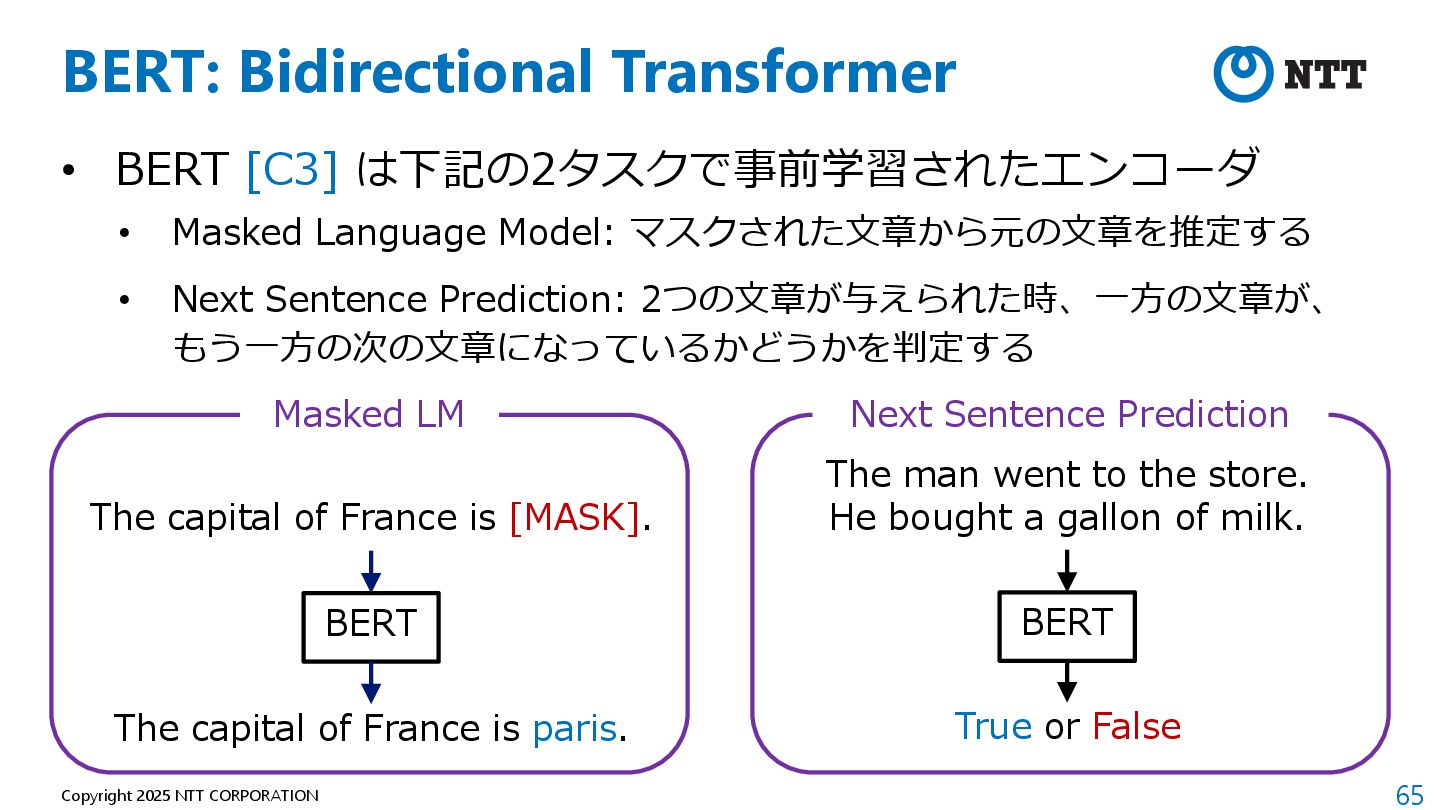
[C3] は下記の2タスクで事前学習されたエンコーダ • Masked Language Model: マスクされた⽂章から元の⽂章を推定する • Next Sentence Prediction: 2つの⽂章が与えられた時、⼀⽅の⽂章が、 もう⼀⽅の次の⽂章になっているかどうかを判定する BERT The capital of France is [MASK]. The capital of France is paris. Masked LM The man went to the store. He bought a gallon of milk. BERT True or False Next Sentence Prediction
• BERTはMasked Language Modelという、マスクされたトークンから元 のトークンを推定するタスクで事前学習されており、⽂書校正は得意 BERT The capital of France is [MASK]. The capital of France is paris. Masked Language Model
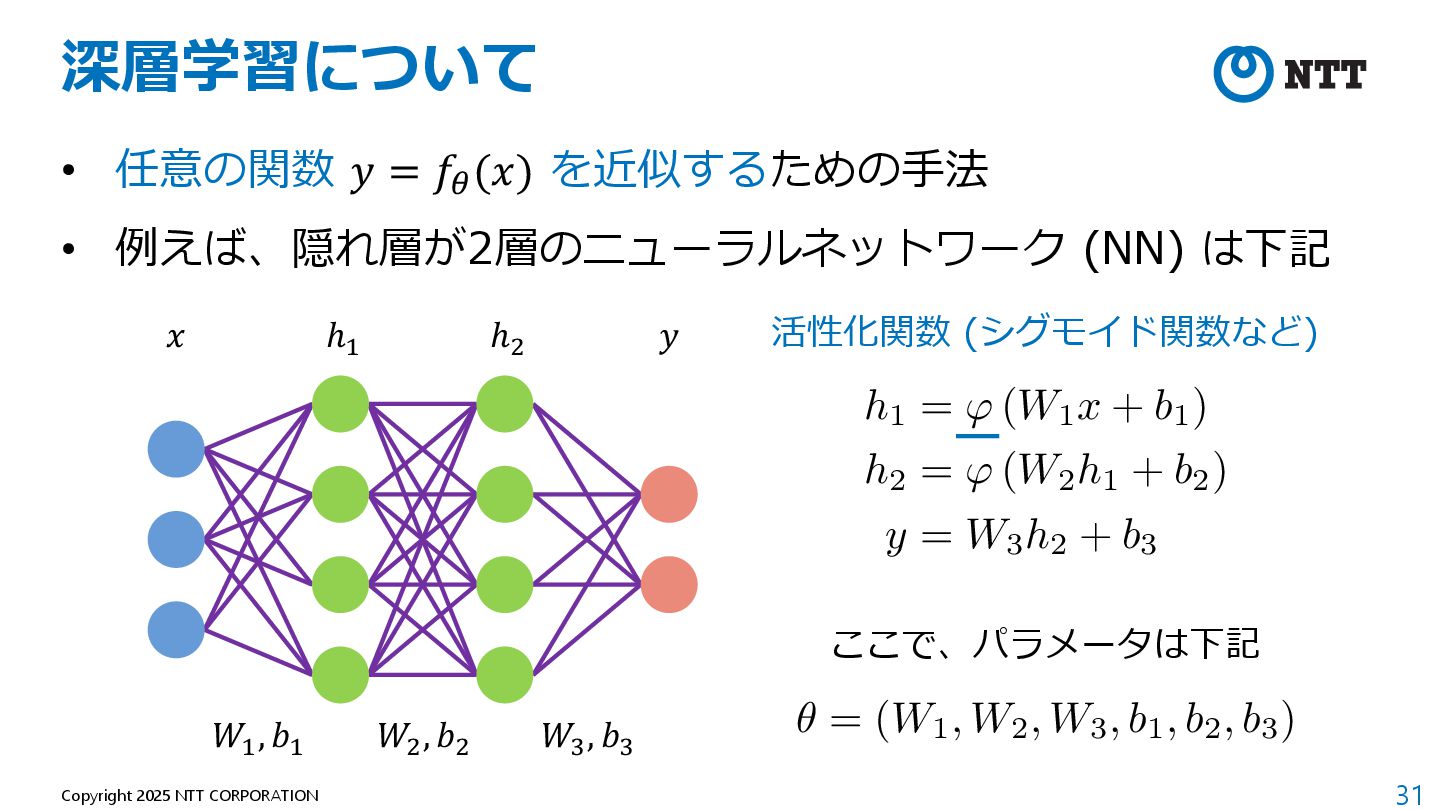
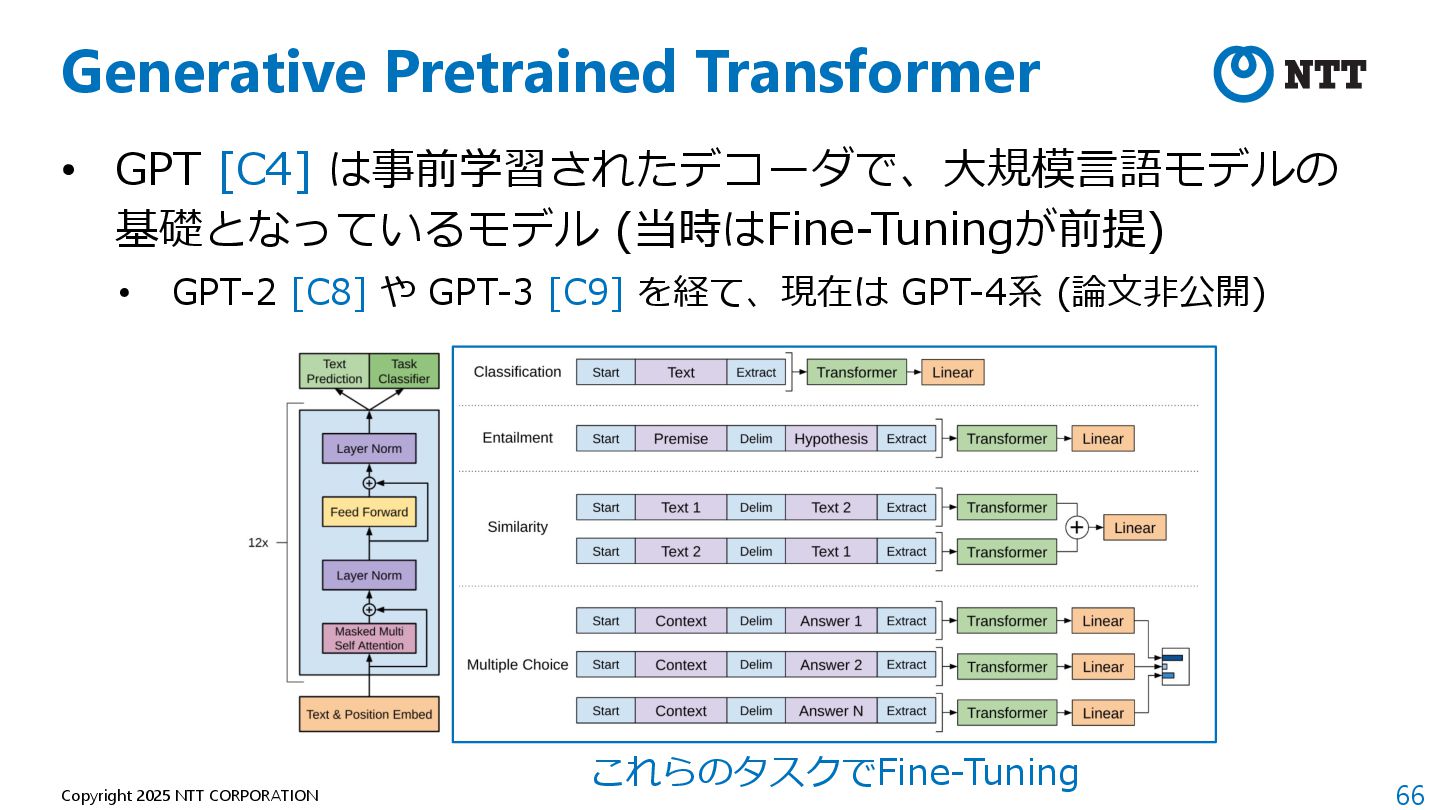
et al. "Attention is all you need." Advances in neural information processing systems 30 (2017). 2. Howard, Jeremy, and Sebastian Ruder. "Universal language model fine-tuning for text classification." arXiv preprint arXiv:1801.06146 (2018). 3. Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018). 4. Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018). 5. "論⽂解説 Attention Is All You Need (Transformer)", https://deeplearning.hatenablog.com/entry/transformer 6. "Transformer: A Novel Neural Network Architecture for Language Understanding", https://research.google/blog/transformer-a-novel-neural-network-architecture-for- language-understanding/
do you embezzle money? 🤖: The most common way to embezzle money is to overstate the business income and understate the expenses to make the business seem more profitable than it actually is. For example … 具体的な⽅法を答えてしまう 例: ⾔語モデルに横領の仕⽅を聞いた時 [D4]
et al. "Training language models to follow instructions with human feedback." Advances in neural information processing systems 35 (2022): 27730-27744. 2. Rafailov, Rafael, et al. "Direct preference optimization: Your language model is secretly a reward model." Advances in Neural Information Processing Systems 36 (2023): 53728- 53741. 3. Takahashi, Hiroshi, et al. "Positive-Unlabeled Diffusion Models for Preventing Sensitive Data Generation." The Thirteenth International Conference on Learning Representations. 4. Bai, Yuntao, et al. "Training a helpful and harmless assistant with reinforcement learning from human feedback." arXiv preprint arXiv:2204.05862 (2022). 5. Bradley, Ralph Allan, and Milton E. Terry. "Rank analysis of incomplete block designs: I. The method of paired comparisons." Biometrika 39.3/4 (1952): 324-345. 6. Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
et al. "Diffusion model alignment using direct preference optimization." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. 8. Ethayarajh, Kawin, et al. "Model alignment as prospect theoretic optimization." Forty-first International Conference on Machine Learning. 2024. 9. Heng, Alvin, and Harold Soh. "Selective amnesia: A continual learning approach to forgetting in deep generative models." Advances in Neural Information Processing Systems 36 (2023): 17170-17194. 10. Kiryo, Ryuichi, et al. "Positive-unlabeled learning with non-negative risk estimator." Advances in neural information processing systems 30 (2017).
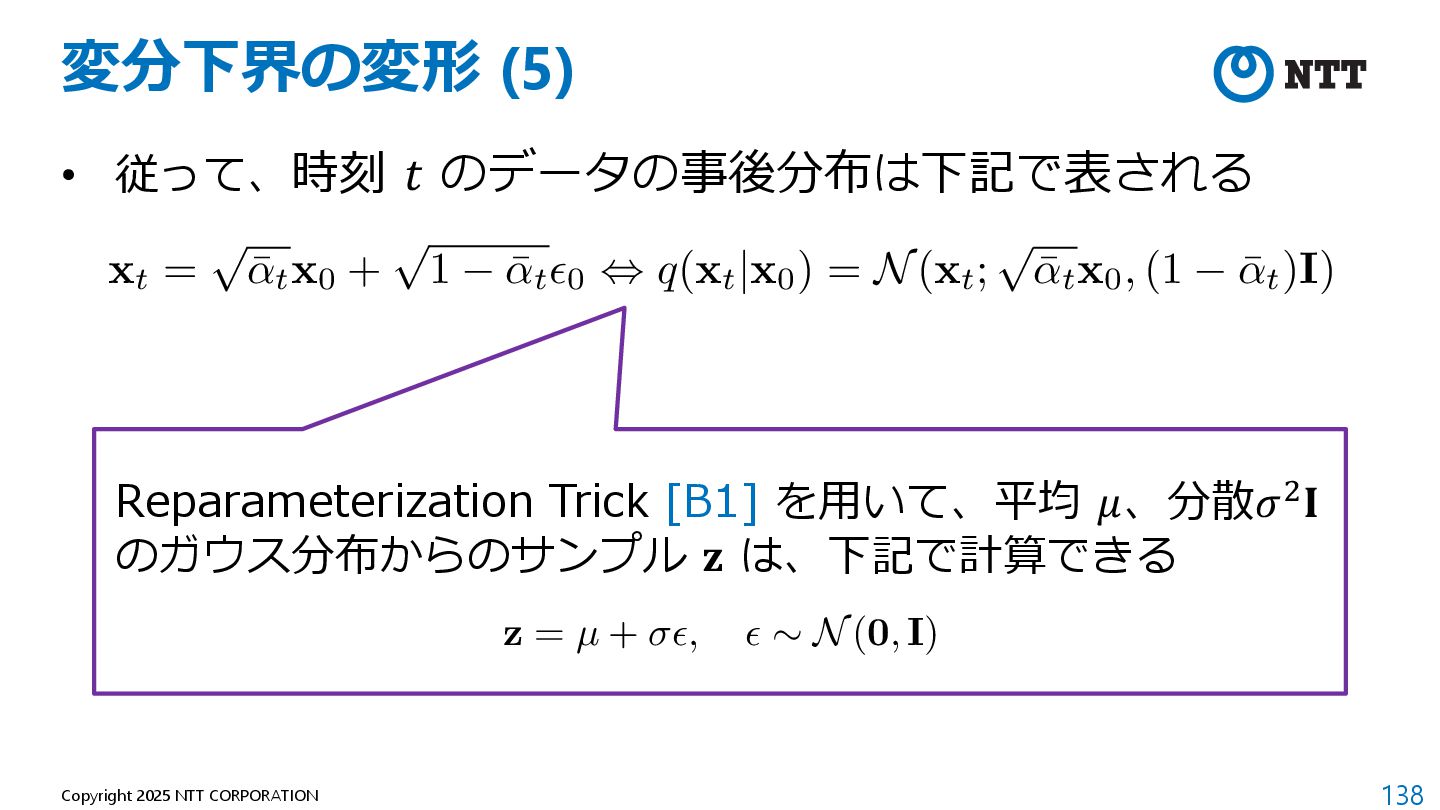
の⽬的関数 • 実験的には、簡略化した⽬的関数でノイズを推定するのが最も良いらしい <latexit sha1_base64="Y6OEqliYpbHx3RGzfa5WvBlGo+A=">AAAEL3icnVJNaxNBGH6360eN1qZ6EbwEQ0uiSZgUqaKX4gd4UOyHSQuZGGbXSXbpZnednYTWZX6AHvXgwZOCB/Hkb/DiHxDpRbwWjxW8KPjuzlrbhio4y86887zv87zPDGOFnhtJQjaNMfPQ4SNHx4/ljp+YODmZnzrVjIKBsHnDDrxArFos4p7r84Z0pcdXQ8FZ3/L4irV2PcmvDLmI3MC/JzdC3u6znu92XZtJhDr5n1XaZ9KxmRffVqU0trrxuurERF2l0uGSlWdoKIJQBjprxTcxu8NqqJIsV8IS5WHkeiiJxLKiHu/KVjrTJheysDtdpQ6T8W8kEUv7aFKJRg8FZi0mYsq80GFYIJXaa+2CrqpXR+t2NapIKtyeI8t60U7ux7NK79u5Tr5IaiQdhdGgngVFyMZCMGVMAIUHEIANA+gDBx8kxh4wiPBrQR0IhIi1IUZMYOSmeQ4KcsgdYBXHCoboGs493LUy1Md9ohmlbBu7ePgLZBZgmnwkb8g2+UDeki3y40CtONVIvGzgamkuDzuTT84sf/8nq4+rBOcP66+eJXThcurVRe9hiiSnsDV/+Oj59vKVpel4hrwiX9H/S7JJ3uMJ/OE3+/UiX3qB6on+DWTpOxQY3ck83EVFjkiyS27hPPahaU0PfSYdVXbHPcQrO9j/KjJYH1HU2MG3ZmOUnJdjL4Wvqb7/7YwGzdlafa42t3ixOH8te1fjcBbOQQnfziWYh1uwAA2wDdt4bDw1npnvzE/mZ/OLLh0zMs5p2DPMrV8CXxhI</latexit> L(x0; ✓) / E U(t),p(✏0) h ✏0 ˆ ✏✓ p ¯ ↵tx0 + p 1 ¯ ↵t✏0, t 2 i
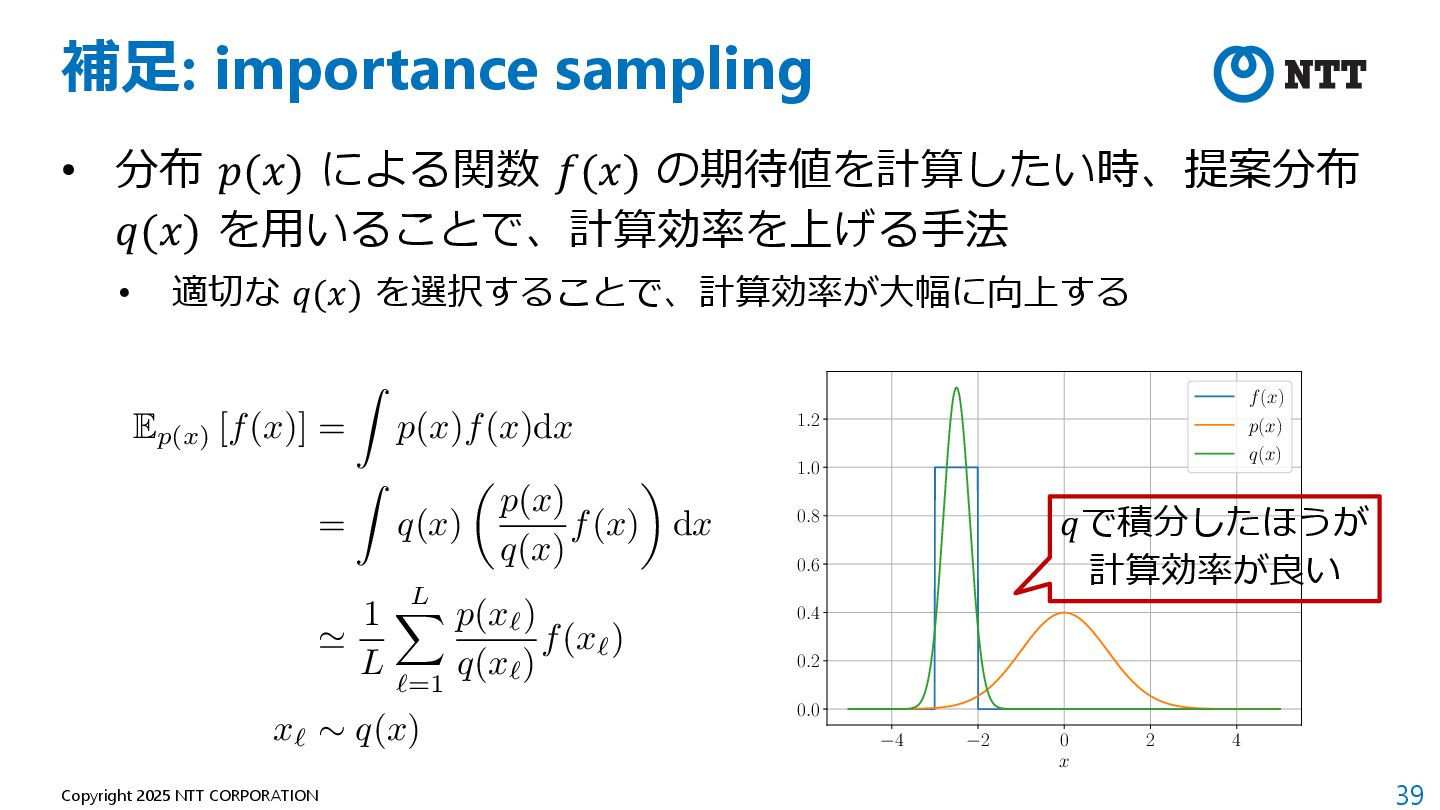
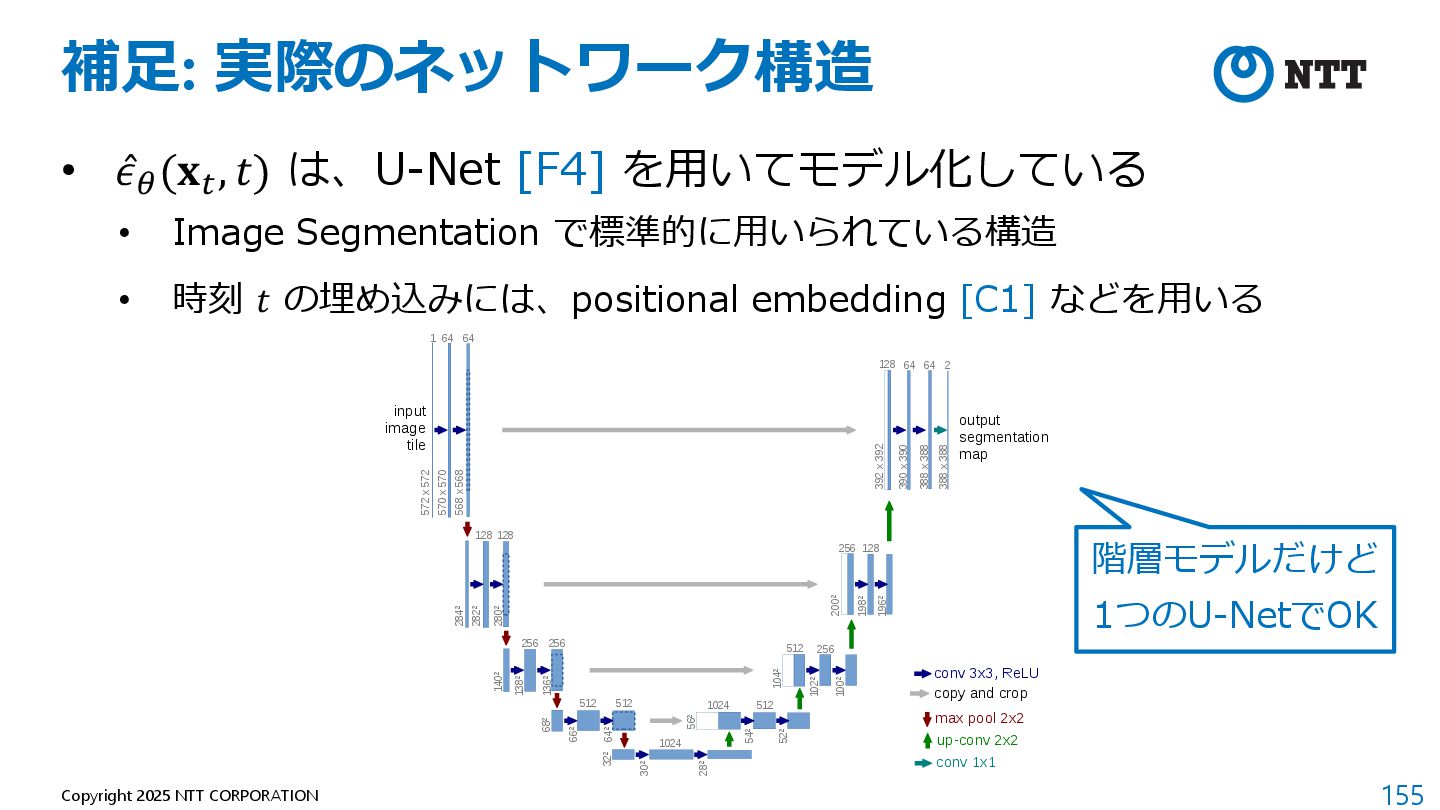
"Understanding diffusion models: A unified perspective." arXiv preprint arXiv:2208.11970 (2022). 2. Efron, Bradley. "Tweedieʼs formula and selection bias." Journal of the American Statistical Association 106.496 (2011): 1602-1614. 3. Song, Yang, and Stefano Ermon. "Generative modeling by estimating gradients of the data distribution." Advances in neural information processing systems 32 (2019). 4. Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer International Publishing, 2015.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![32 Copyright 2025 NTT CORPORATION 補⾜: シグモイド関数 [0,1] でバウンドされた⾮線形関数 °10](https://files.speakerdeck.com/presentations/2e6db105a0764c729e25dfbc411b2aaf/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![45 Copyright 2025 NTT CORPORATION 拡散モデル (1) • 拡散モデル [B2]](https://files.speakerdeck.com/presentations/2e6db105a0764c729e25dfbc411b2aaf/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![50 Copyright 2025 NTT CORPORATION 拡散モデル (6) 拡散モデルで⽣成したCelebAとCIFAR10 (2020年時点) [B2]](https://files.speakerdeck.com/presentations/2e6db105a0764c729e25dfbc411b2aaf/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
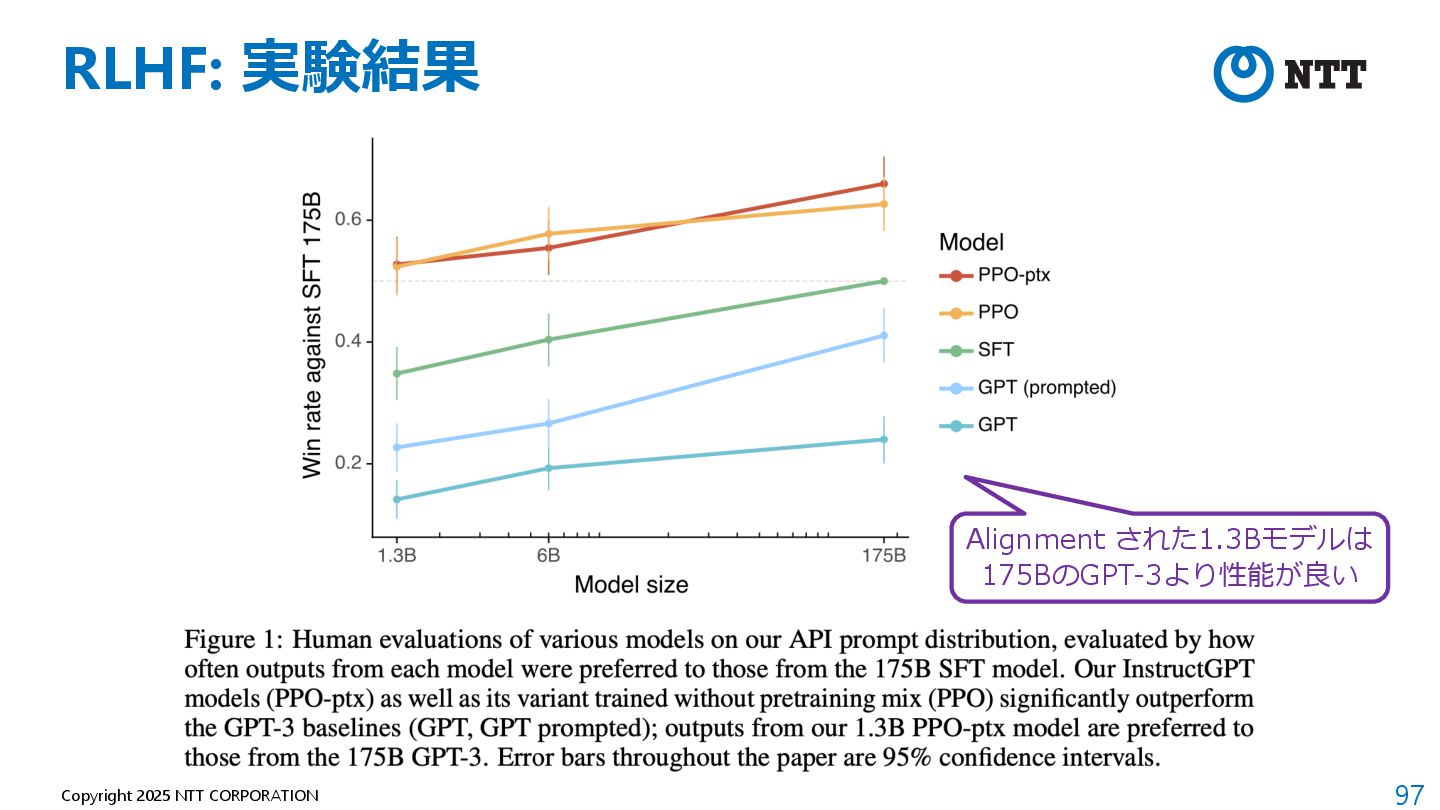
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
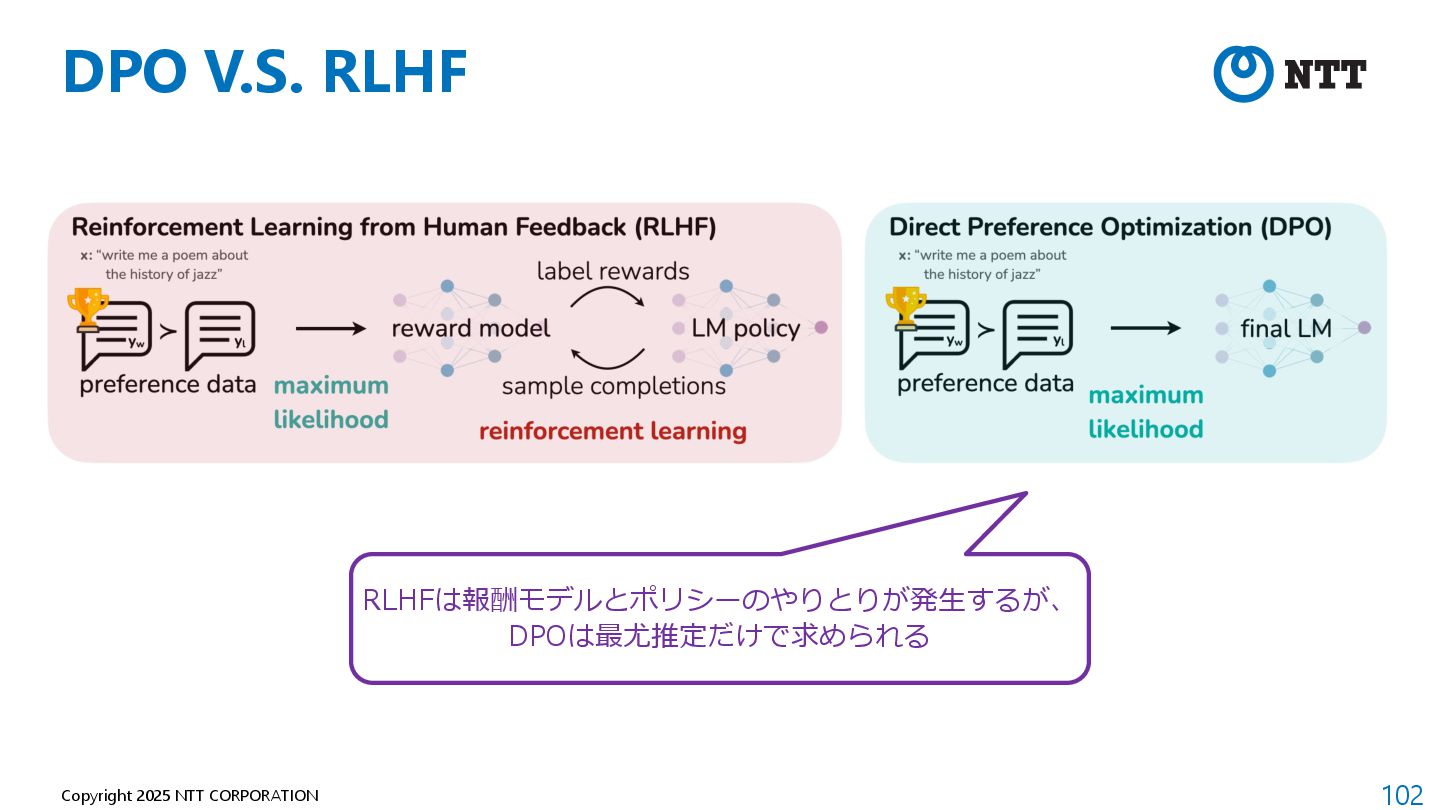
{kind=link}
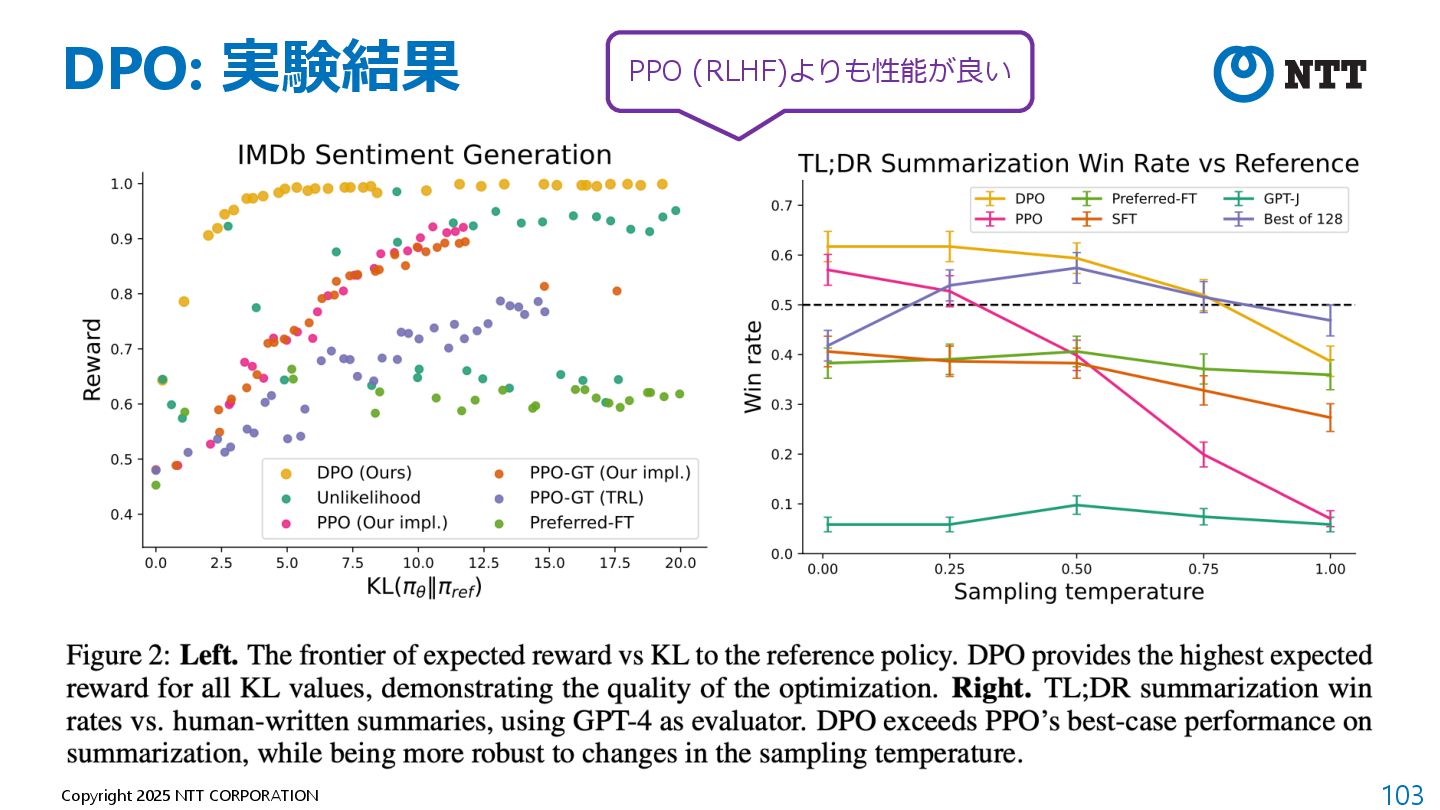
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
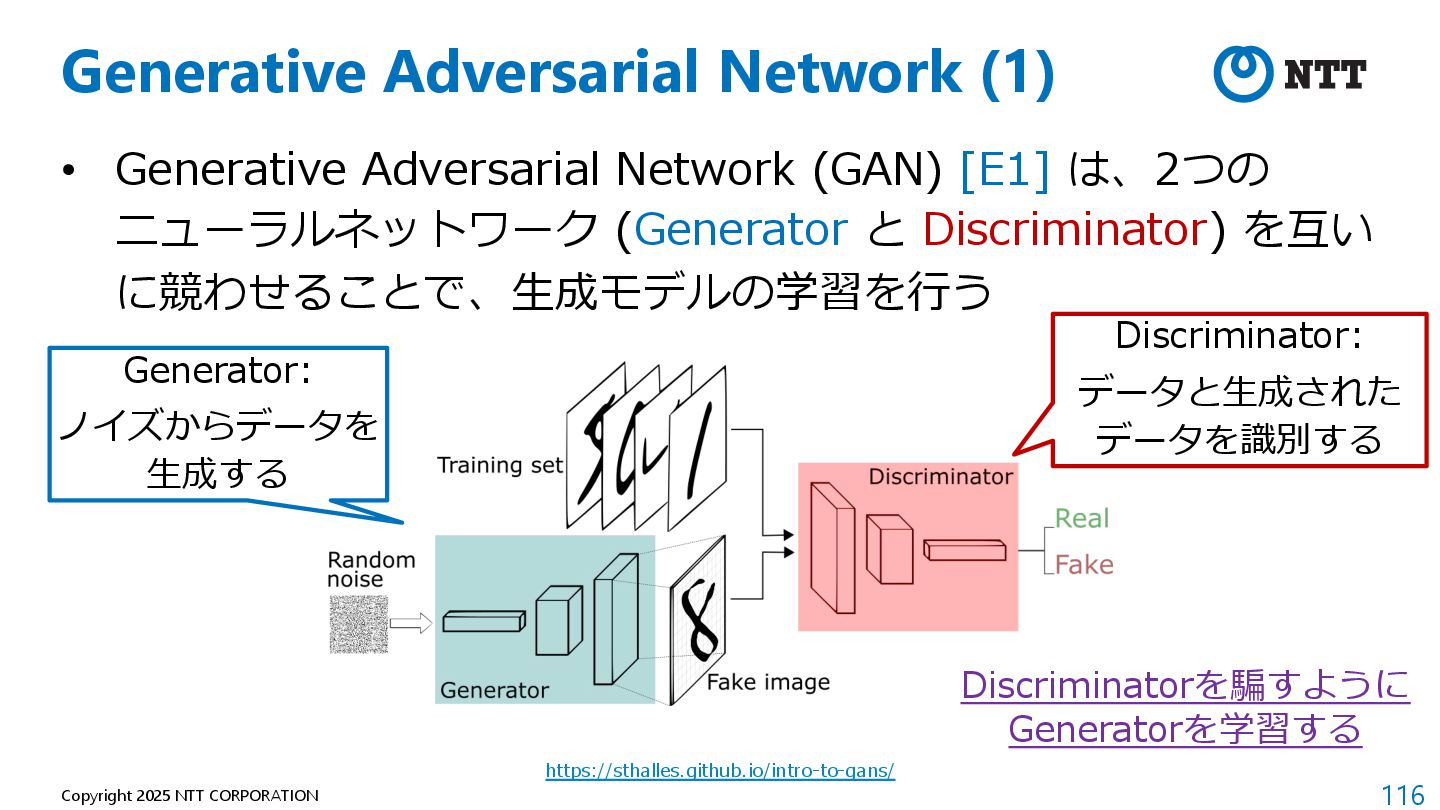
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![127 Copyright 2025 NTT CORPORATION 概要 • 拡散モデルの⾮常に分かりやすいレビュー論⽂である [F1] に](https://files.speakerdeck.com/presentations/2e6db105a0764c729e25dfbc411b2aaf/slide_127.jpg){kind=link}
![128 Copyright 2025 NTT CORPORATION 拡散モデル (1) • 拡散モデル [B2]](https://files.speakerdeck.com/presentations/2e6db105a0764c729e25dfbc411b2aaf/slide_128.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![147 Copyright 2025 NTT CORPORATION ノイズの推定 (4) • この⽬的関数を簡略化したものが、DDPM [B2]](https://files.speakerdeck.com/presentations/2e6db105a0764c729e25dfbc411b2aaf/slide_147.jpg){kind=link}
{kind=link}
![149 Copyright 2025 NTT CORPORATION スコアの推定 (1) • Tweedieの公式 [F2]](https://files.speakerdeck.com/presentations/2e6db105a0764c729e25dfbc411b2aaf/slide_149.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}