A brief introduction to AI for Fintech Research, the joint lab between ING Bank and TU Delft. https://twitter.com/Ai4Fintech
The slide deck has also been used in the MOOC "AI in Practice" -- https://www.edx.org/course/ai-in-practice-preparing-for-ai
FinTech refers to the innovation of financial services ("fin") by means of digital technology ("tech"). Naturally, artficial intelligence, ("AI"), plays a key role in this innovation.
To take advantage of the full potential of AI for Fintech, Dutch bank ING and Delft University of Technology have set up a five year collaboration, called "AI for Fintech Research", or AFR for short.
Within AFR, dozens of researchers, engineers, educators, innovators, and students work together to bring the application of AI in the FinTech domain to the next level.
To understand the challenges and opportunities of AI in the fintech domain, we distinguish several key characteristics of the financial sector.
First, the field of finance is inherently data rich. Even the smallest financial activity, such as making a payment or transferring money, is essentially a data processing activity. Every type of financial activity, generates its own bits of data.
This data is not just rich and diverse: there is also lots of it. Online payments alone generate millions of transactions per day.
Clearly, this high volume of data and its rich nature makes finance an ideal domain for the application of artificial intelligence: There is lots of data to learn from, and modern machine learning algorithms are good at just that.
A related characteristic of the financial sector is that it is intrinsically software intensive. The rich data must be processed in high volumes, and all this processing is done by different software applications. These systems are complex not just by themselves, but also because many of them are tightly connected. This calls for sound software engineering practices in order to create reliable, scalable, and secure software systems.
Furthermore, the field of finance is rapidly evolving. This means that new software solutions need to be created continuously. It also means that existing software systems need to be adjusted over and over again. This calls for a very high level of agility of the software development organization.
This makes software development in finance a highly challenging effort. Here, again, we can call AI to the rescue, and see how the application of artificial intelligence in the development process itself can help to meet the demands of the finance domain.
Next, finance is not just about numbers, but ultimately about people and society.Software systems, also if driven by AI, should be intelligible to end users. The underlying AI should respect ethical norms, and must be fair. Financial systems collectively must be auditable and traceable, since society critically depends on such systems. To that end, they must meet the many regulatory constrains imposed by national governments or international agreements. Clearly, such societal aspects of FinTech systems place important constraints on the adoption of AI in the FinTech domain.
With these characteristics in mind, we arrived at three main directions within AI for Fintech Research, relating to (1) data analytics, (2) software analytics, and (3) human aspects.
While it is great that finance is rich in data, this also brings its own set of problems. Data will be consumed from many, many different sources. These different databases will have all sorts of relationships and dependencies, sometimes explicit, but often implicit. For example, columns from different databases may represent very similar entities. On top of that, the semantics of columns and dependencies may evolve over time.
If we want to such heterogeneous data in AI applications, we may very well run into trouble. For that reason, within AFR, we address data integration challenge explicitly. We work on the automated discovery of relationships in data, integrating different data sources. We formulate this discovery process as a learning process, and indeed, explore the use of machine learning to discover semantic data relationships in large heterogeneous, evolving data sets.
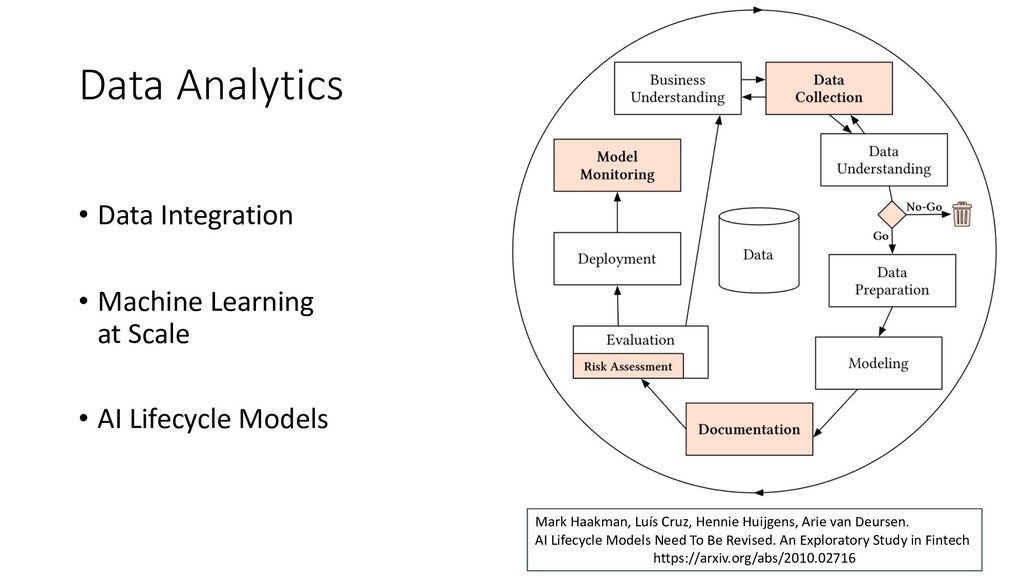
A different set of challenges is brought by the actual deployment of ML-applications. For classical applications, modern continuous delivery pipelines automate testing, deployment, and operational monitoring. This is substantially more challenging for ML applications. In particular if models are re-trained and re-deployed frequently, full automation of all relevant deployment tasks is needed. This includes monitoring and optimization of ML models in production, as well as data quality validation. For models requiring explainability, verification will be necessary, not just of outputs but also of the revised explanations.
Together with ING, we are exploring this so-called life cycle of ML models in the fintech domain. The picture on the slide shows a number of the relavant steps, such as data preparation. It is based on the classical CRISP-DM blue print for data mining processes, but extended with steps related to risk assessment, model monitoring, and governance.
The software intensive nature of the financial sector opens an additional opportunity to apply AI techniques. Software engineering processes themselves produce a trove of data that can be used to improve the effectiveness and efficiency of these processes. Example data includes issues, log data, source code repositories, feature descriptions, etc.
Thanks to the abundance of data, it becomes increasingly viable to apply machine learning techniques (such as random forests, logistic regression, or neural networks) to use historic development information to support current development activities.
Within AFR, we particularly focus on using software analytics to improve the predictability of the actual delivery "epics", that is, of coherent collections of features.
Another set of AI techniques that can be used to support software engineering processes includes evolutionary algorithms. When using such algorithms, software engineering problems are reformulated as search problems. For example, the generation of test cases can also be viewed as a search process for an optimal test suite that meets certain quality criteria, such as sufficient coverage of key parts in the code. A well-known, open source, tool to support this is EvoSuite, which can generate JUnit test suites for Java classes using evolutionary computing.
Within AFR, we are exploring the use of such search-based software engineering techniques for additional applications, such as test data generation, security testing, and crash reproduction.
Often, search-based techniques are combined with other machine learning techniques: In the image on the slide we see a behavioral model learned from execution traces, which we subsequently use to guide the search process for crash-inducing test cases.
To understand the importance of human aspects in the design of trustworthy AI system, the framework as proposed by Shneiderman, as shown on the slide, is helpful. Shneiderman emphasizes that the design and implementation of trustworthy, human-centered AI systems, requires governance structures at three different levels:
First, at the systems level, it calls for sound software engineering principles.
Second, at the organization level, it demands a strong culture of safety and fairness
Third, at the industry level, it requies external certification and regulation.
These governance structures also shape the application of AI in fintech organizations.
At the systems level, we have just seen how AFR leverages the use of AI to optimize software engineering processes. This will also include learning from actual user interaction data, for instance in the context of A/B testing.
At the industry level, the FinTech domain is strongly determined by regulations and national and international laws. Here AI on the one hand poses a substantial challenge: Regulations typically require clear audit trails, calling for explainable AI instead of black box machine learning models.
On the other hand, AI also offers unique possibilities: Many regulations are highly documentation centric: Regulatory processes such a KYC -- "Know Your Customer" require that banks collect all sorts of documentation about their customers, in order to prevent, for example, illegal money laundering activities. Here the recent advances in natural language processing offer unique possibilities to support these document-centric regulatory processes.
As we have seen, the domain of fintech deals with data-rich, software-intensive, human-centered systems. This poses a number of exciting opportunities for the application of AI techniques. Within AI for Fintech Research we are exploring such opportunities, in a collaboration between ING Bank and Delft University of Technology.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}