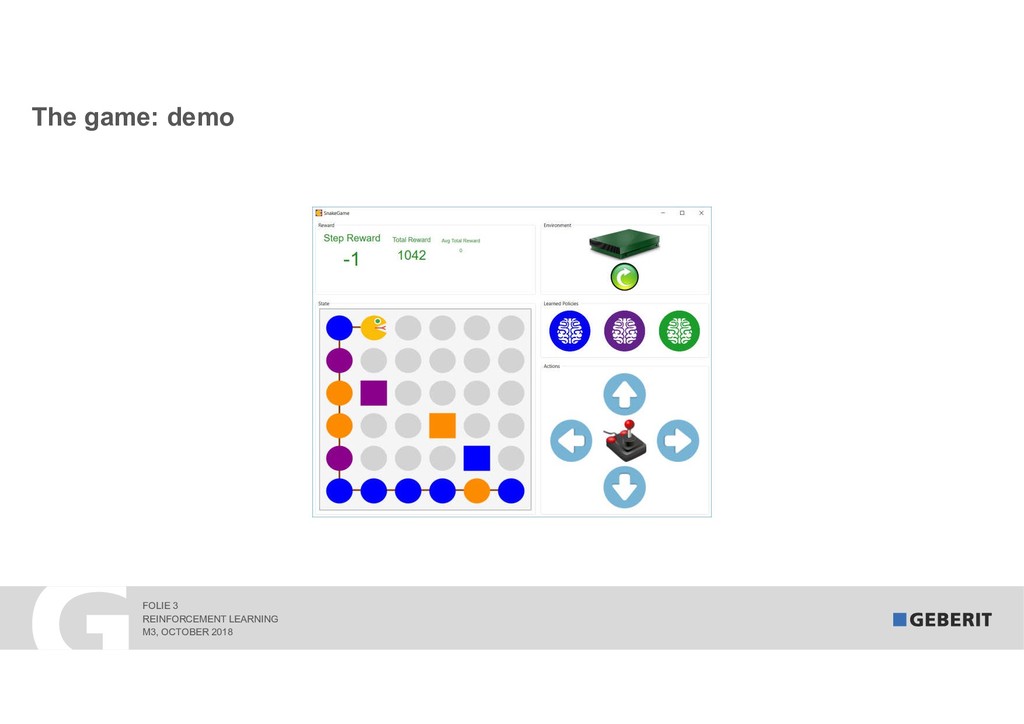
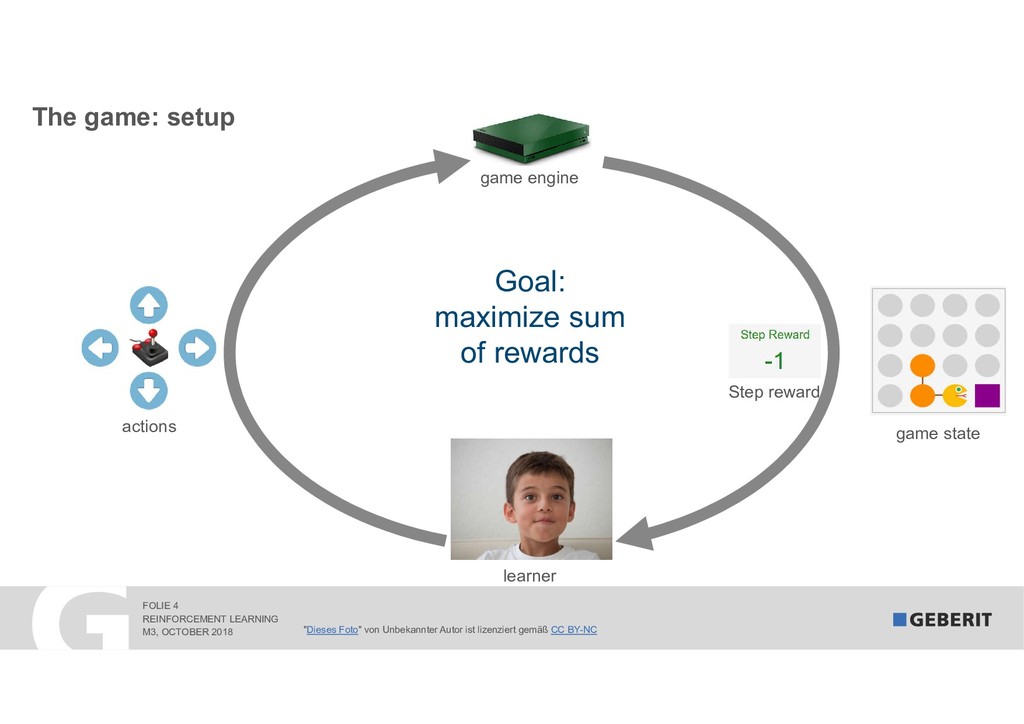
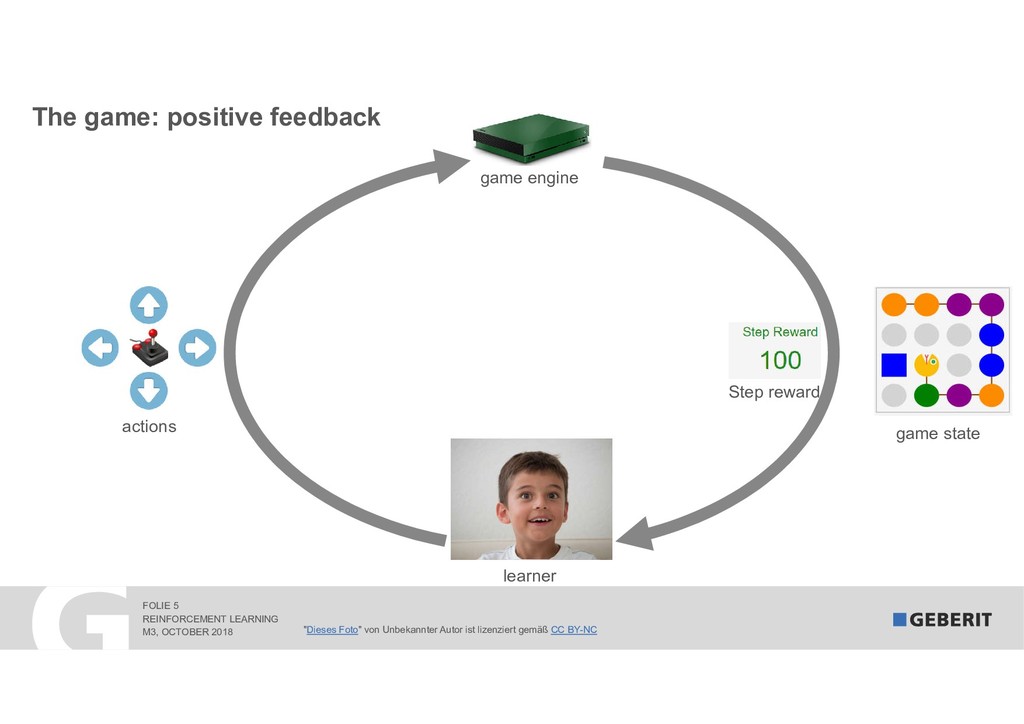
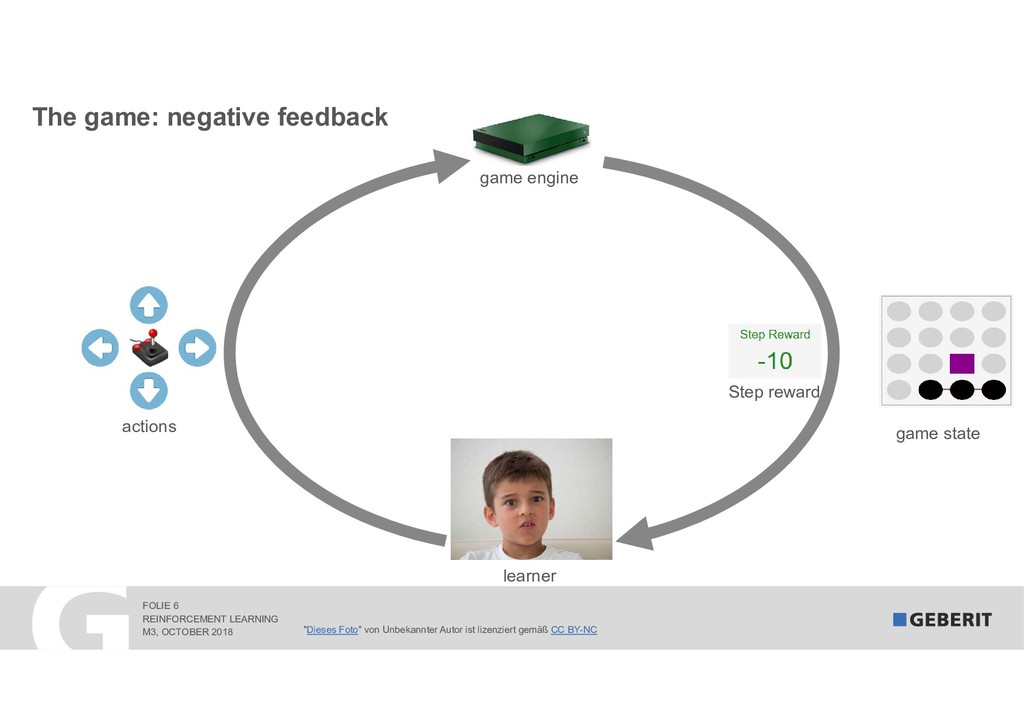
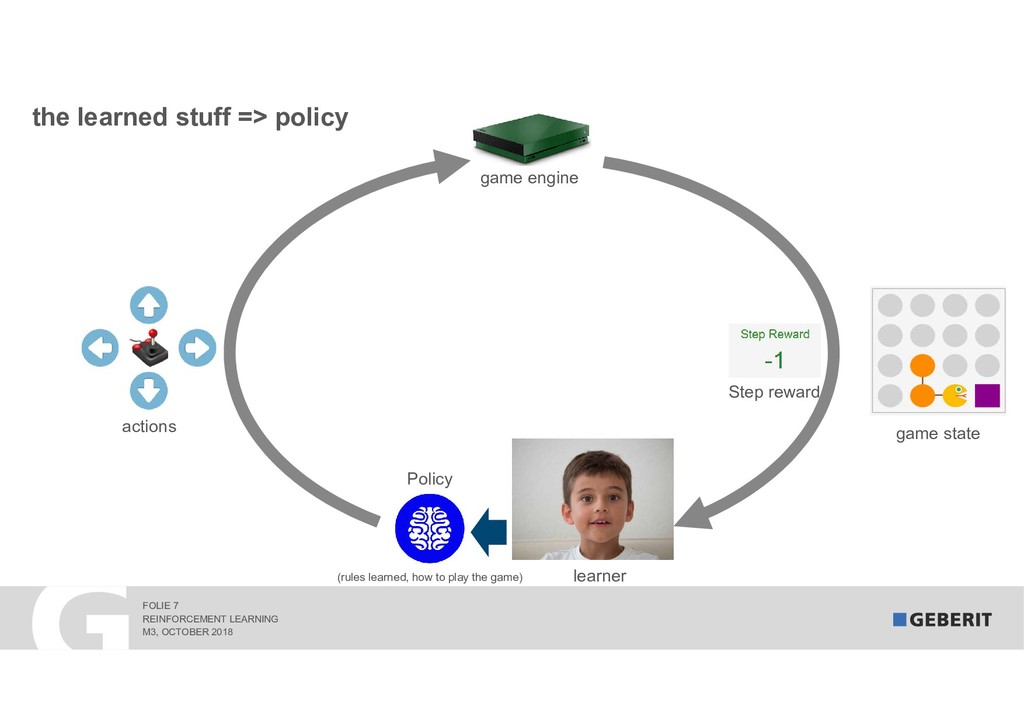
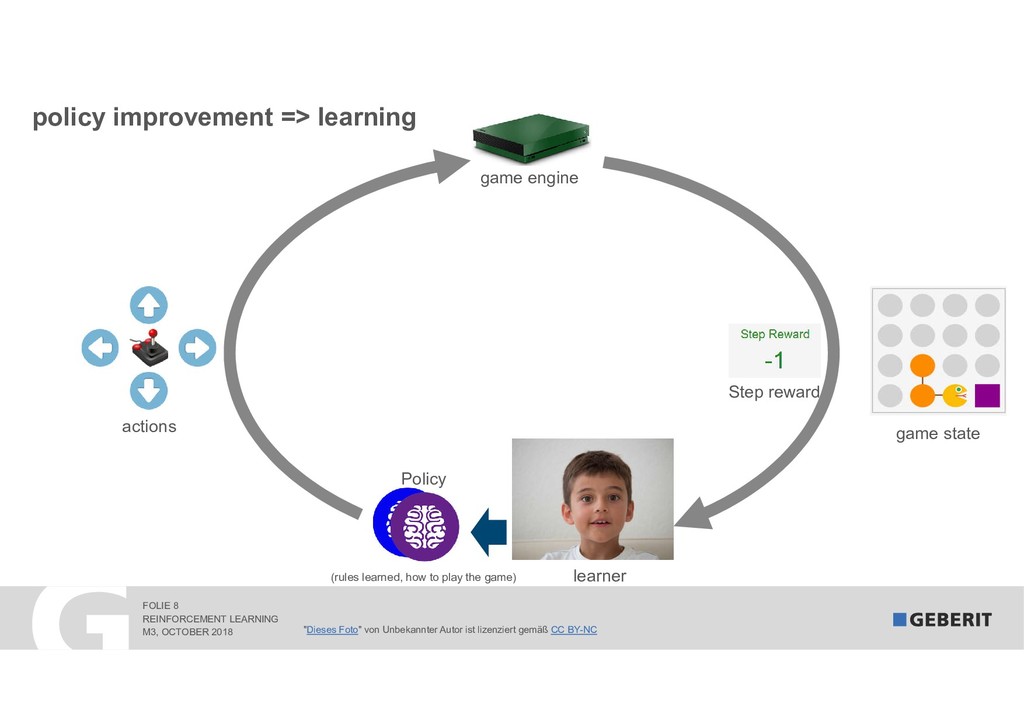
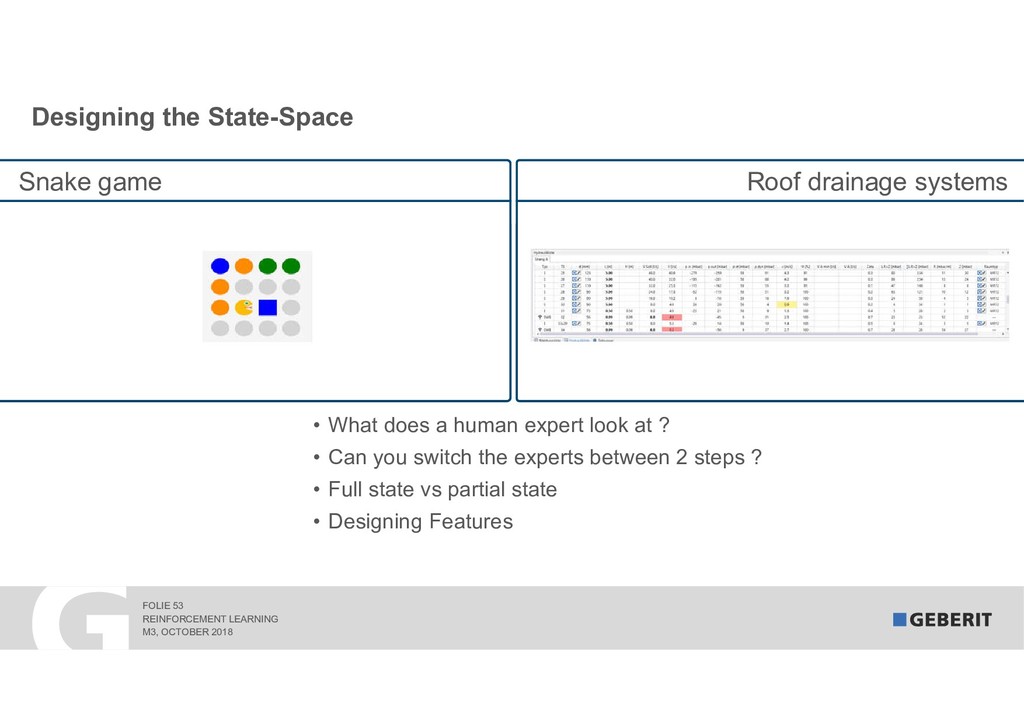
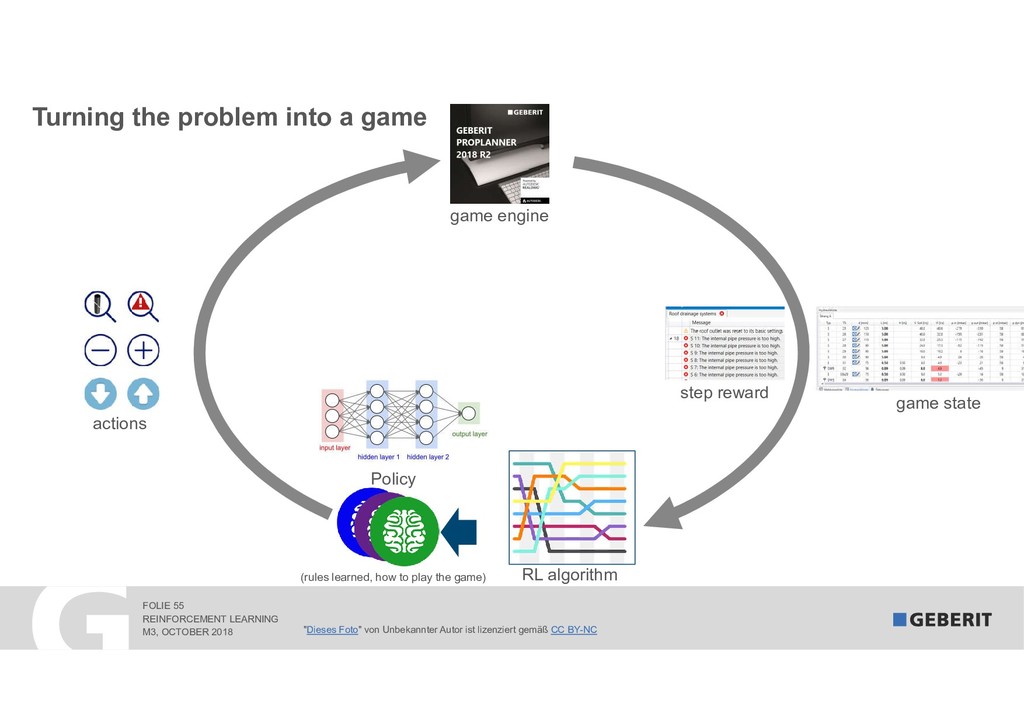
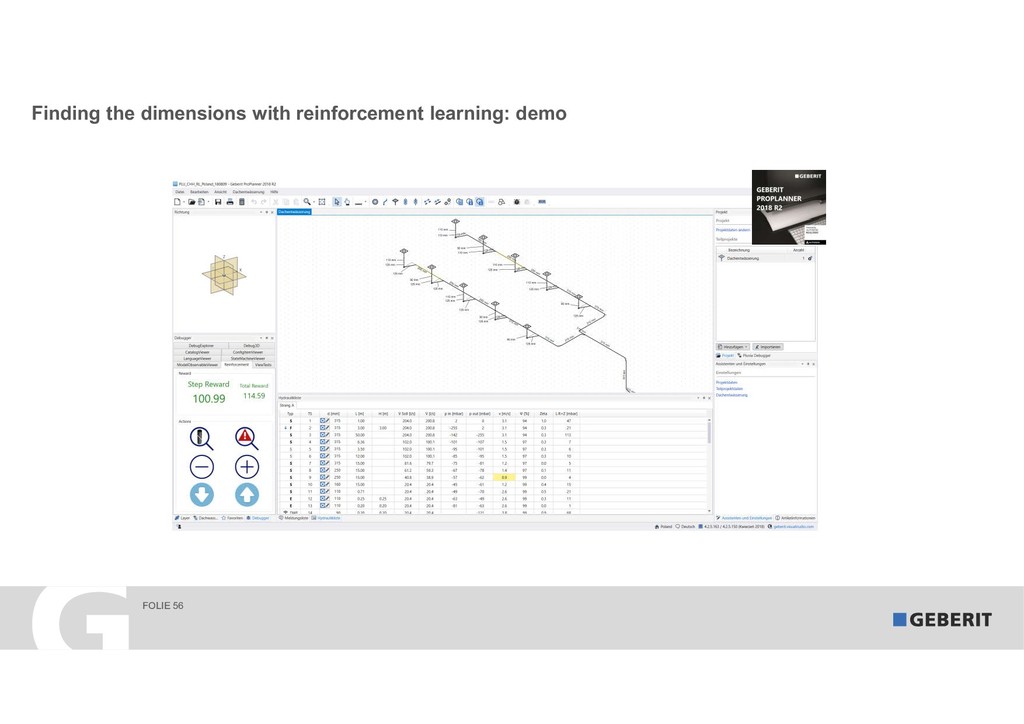
Reinforcement Learning (RL) learns complex processes autonomously. No big data sets with the "right" answers are needed: the algorithms learn by experimenting. In 2017, RL algorithms beat the reigning Go World Champion. In this session, I demonstrate "how" and "why" RL works. As a practical example, we apply RL to a syphonic roof drainage system where the choice of the "right" dimensions of trillions of possibilities is extremely difficult.
By the way, syphonic roof drainage systems prevent large buildings, such as airports or stadiums, from collapsing in heavy rain.
The talk shows how RL complements our existing machine learning solution and allowed us to reduce the fail rate by an astonishing 70 percent.
Speaker: Christian Hidber
Christian is a consultant at bSquare with a focus on .NET Development, Machine Learning and Azure and an international conference speaker. He has a PhD in computer algebra from ETH Zurich and did a postdoc at UC Berkeley where he researched online data mining algorithms. Currently he applies machine learning to industrial hydraulics simulations in the context of a product with 7,000 installations in 42 countries all around the world.
You can find him at:
https://www.linkedin.com/in/christian-hidber/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![FOLIE 59 Thank you! M3, OCTOBER 2018 REINFORCEMENT LEARNING [email protected]](https://files.speakerdeck.com/presentations/0637a0fae0cb41c2ae98ca7db7a6f7ac/slide_58.jpg){kind=link}
{kind=link}
{kind=link}