失敗したリクエストの割合(HTTP 5xxやアプリケーションエラーなど)。信⽤できなさ ‧飽和度(Saturation) →ステムが限界にどれだけ近づいているか(CPU使⽤率、キュー⻑など)。リソース逼迫の近さ “If you can only measure four metrics of your user-facing system, focus on these four.” (Google SRE Book, Chapter 6: Monitoring Distributed Systems) → 「もしあなたが4つしか監視できないとしたら、この4つを選べ」というくらい、優先度が⾼い。
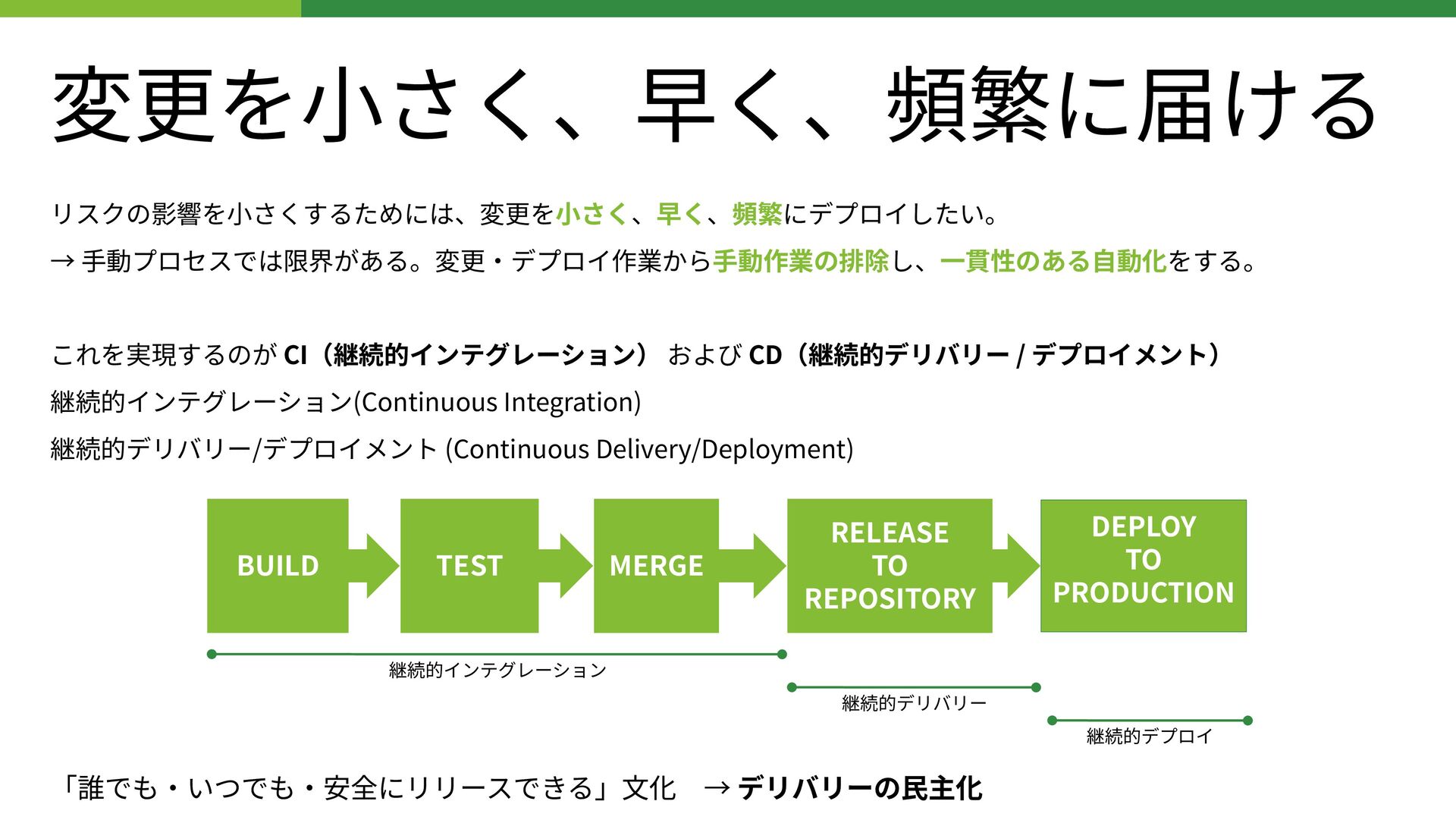
継続的インテグレーション(Continuous Integration) 継続的デリバリー/デプロイメント (Continuous Delivery/Deployment) BUILD TEST MERGE RELEASE TO REPOSITORY DEPLOY TO PRODUCTION 継続的インテグレーション 継続的デリバリー 継続的デプロイ 「誰でも‧いつでも‧安全にリリースできる」⽂化 → デリバリーの⺠主化
Flags) are a powerful technique, allowing teams to modify system behavior without changing code.” - Pete Hodgson フィーチャーフラグとは、コードを変更することなく システムの振る舞いを変えることができる強⼒なテクニックである 出典:Pete Hodgson「Feature Toggles (aka Feature Flags)」より引用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}