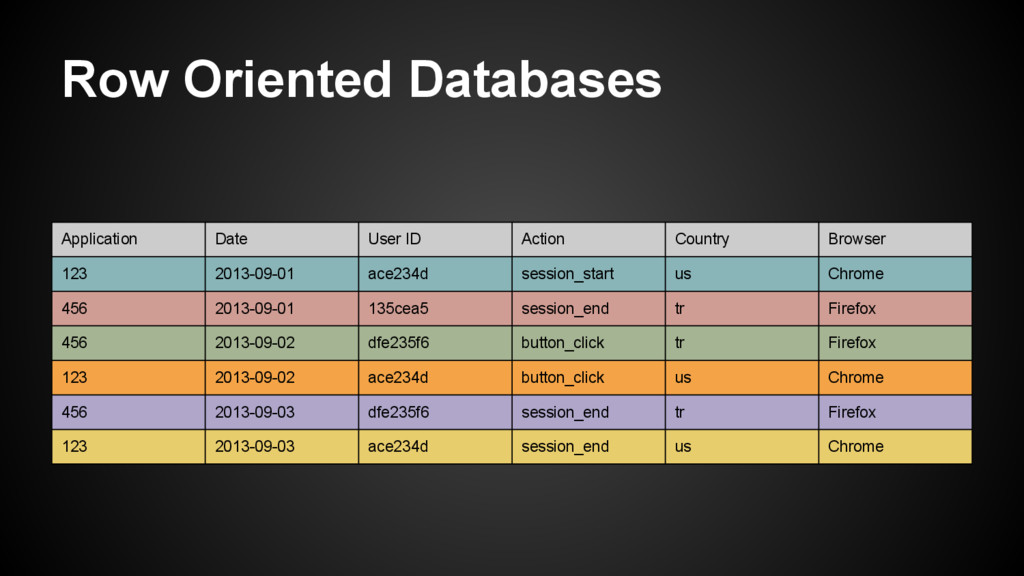
6 rows = 36 i/o points • How about an index? ◦ Reduces the # of rows we have to read ◦ Adds additional storage overhead ◦ Creates a lot of random i/o (disks are bad at this) • What if we have 6 trillion rows? ◦ Reading all of those unneeded columns adds up ◦ Additional index overhead is now significant ▪ Even 1% of 100 TB is 1 TB SELECT count(distinct(user_id)) WHERE appid = 123
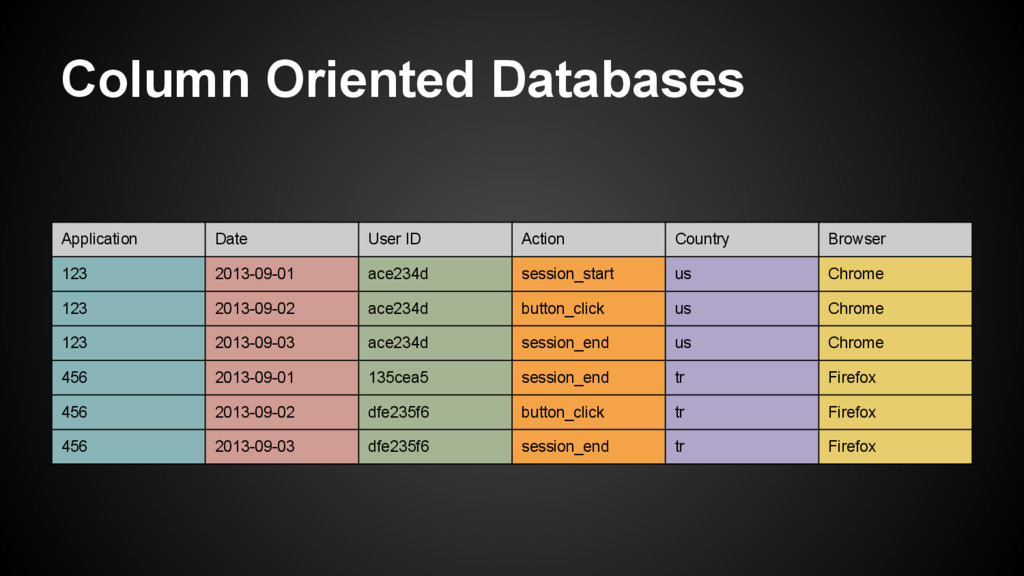
6 rows = 6 i/o points • Sorting instead of index ◦ Reduces the # of rows we have to read ◦ Adds overhead during insertion ◦ No need for additional index storage ◦ All sequential i/o (disks are great at this) • Compression ◦ Values in a given column tend to look very similar ◦ Compression works really well on similar data ◦ Greatly reduced i/o (even vs compressed rows) SELECT count(distinct(user_id)) WHERE appid = 123
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}