Apresentação de Luciano Resende no Big Data Week São Paulo 2017 [http://sao-paulo.bigdataweek.com].
Entenda a nova tecnologia de código aberto que construímos para habilitar a IBM Data Science Experience à fornecer aos cientistas de dados uma experiência completa do notebook Jupyter em seu navegador, mantendo a computação e os dados em uma nuvem corporativa escalável e segura.
{kind=link}
![Luciano Resende [email protected] @ http://lresende.blogspot.com/ https://www.linkedin.com/in/lresende @lresende1975 https://github.com/lresende Data Science](https://files.speakerdeck.com/presentations/80df619783b54e188a12bee5cbcb82f7/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
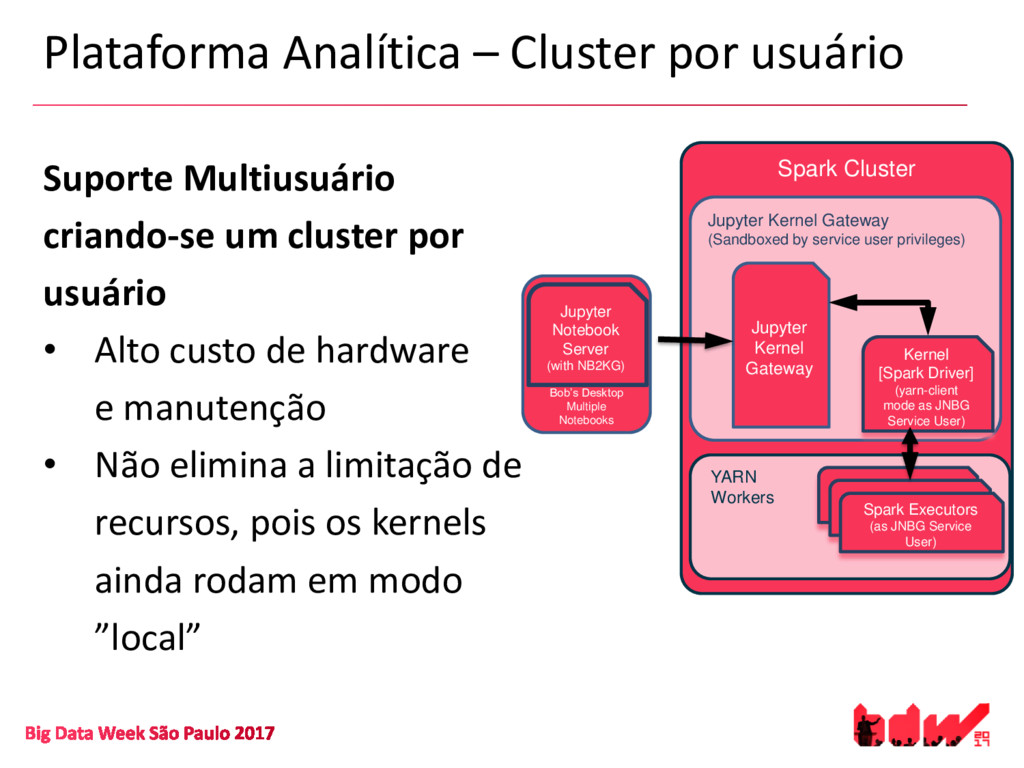{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
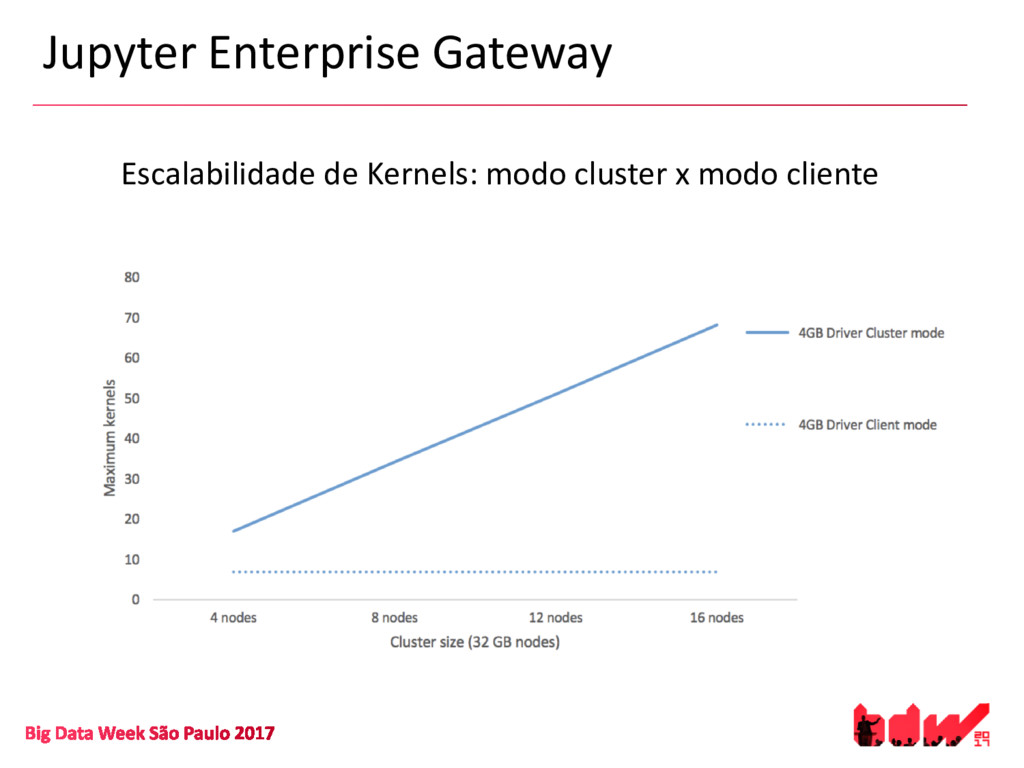{kind=link}
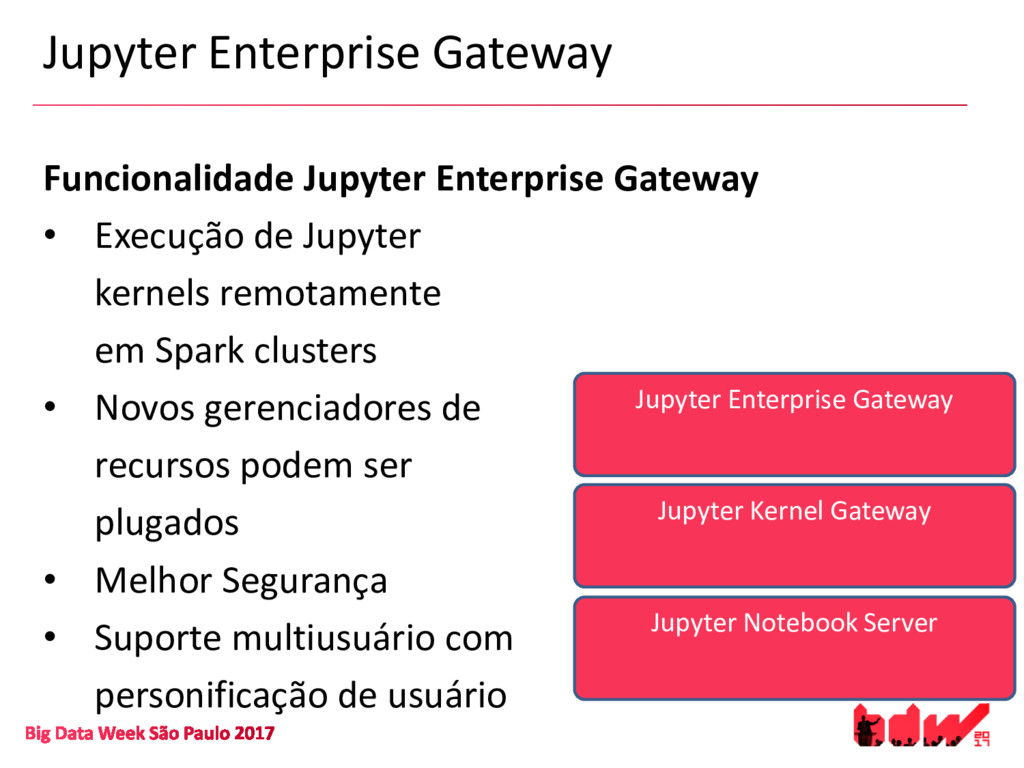{kind=link}
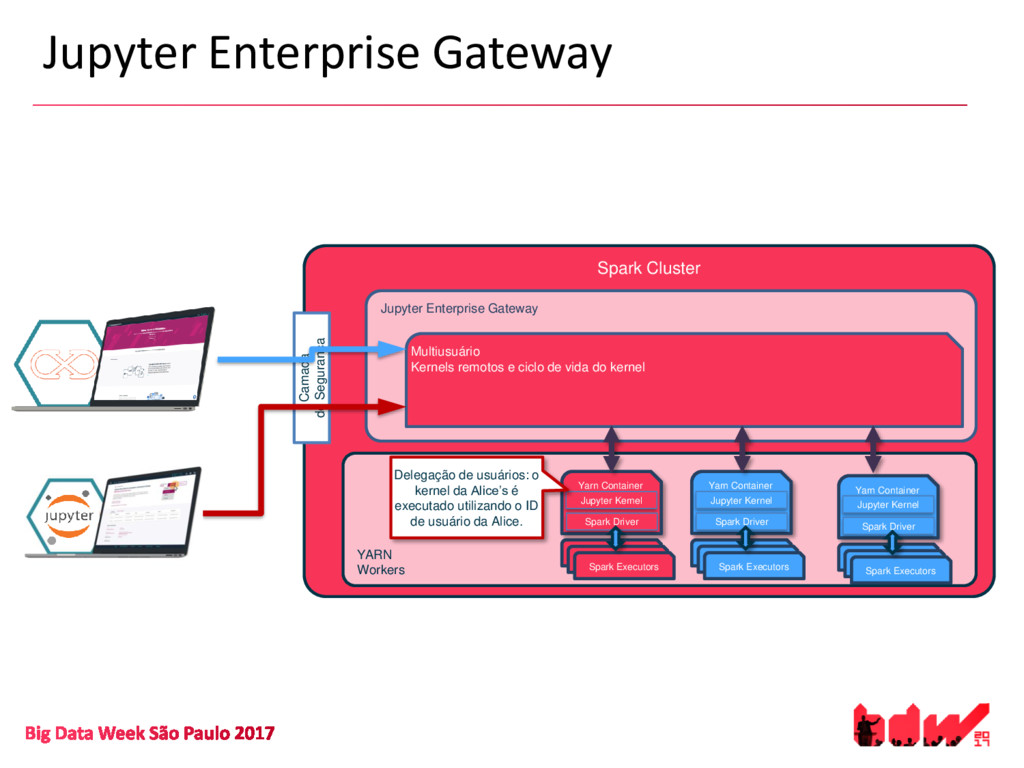{kind=link}
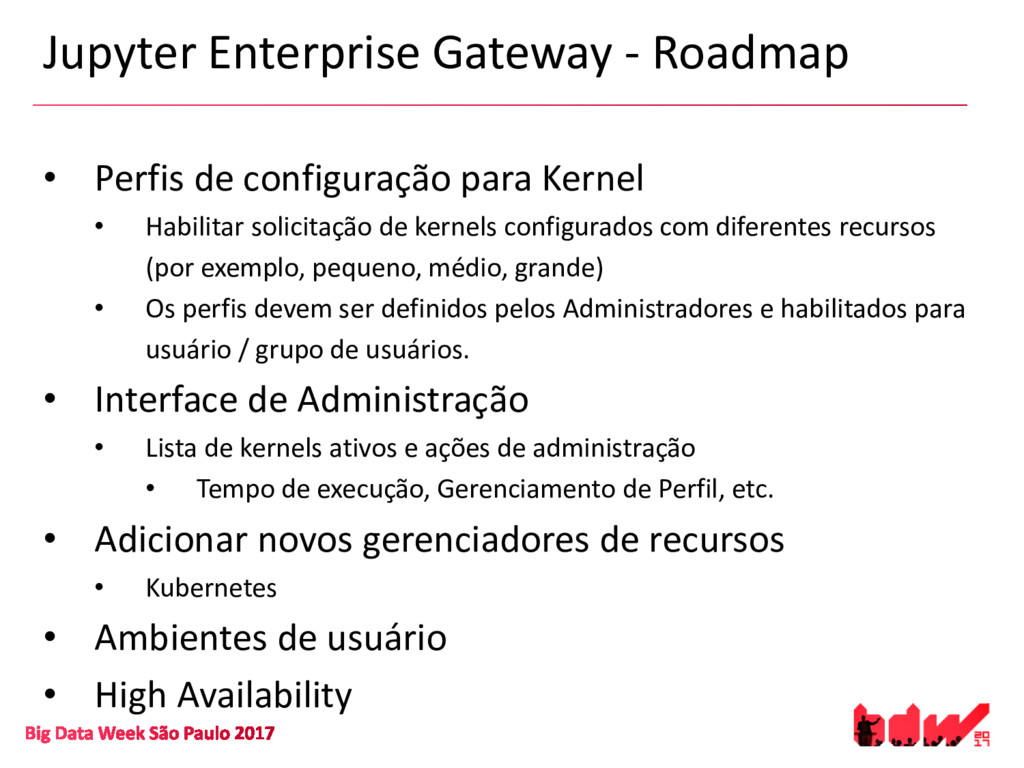{kind=link}
{kind=link}