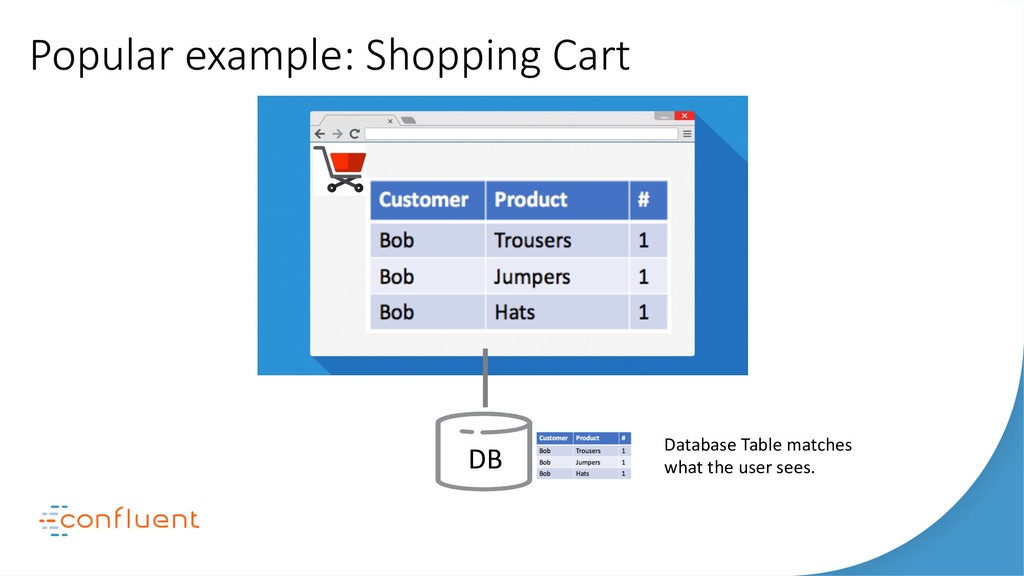
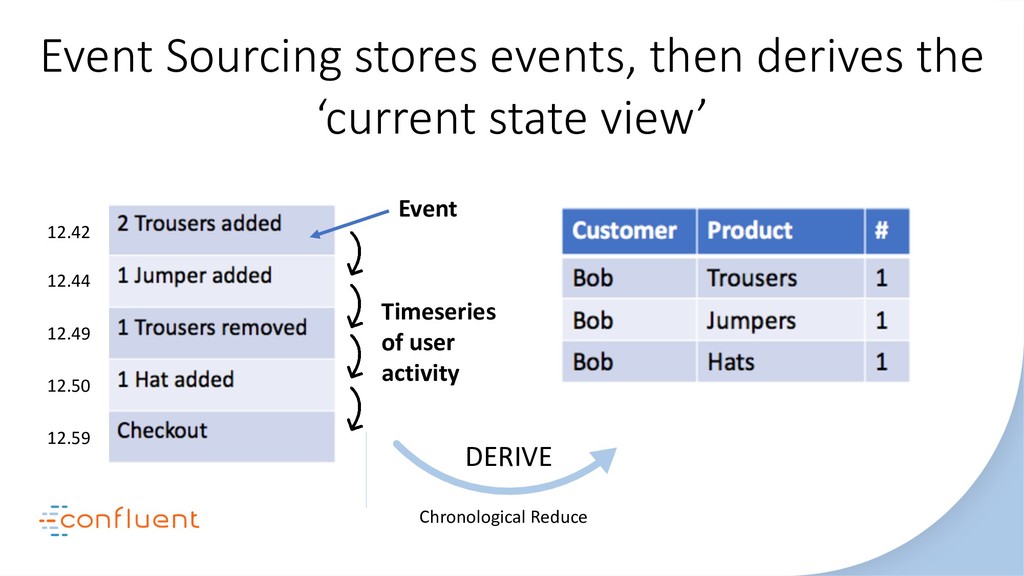
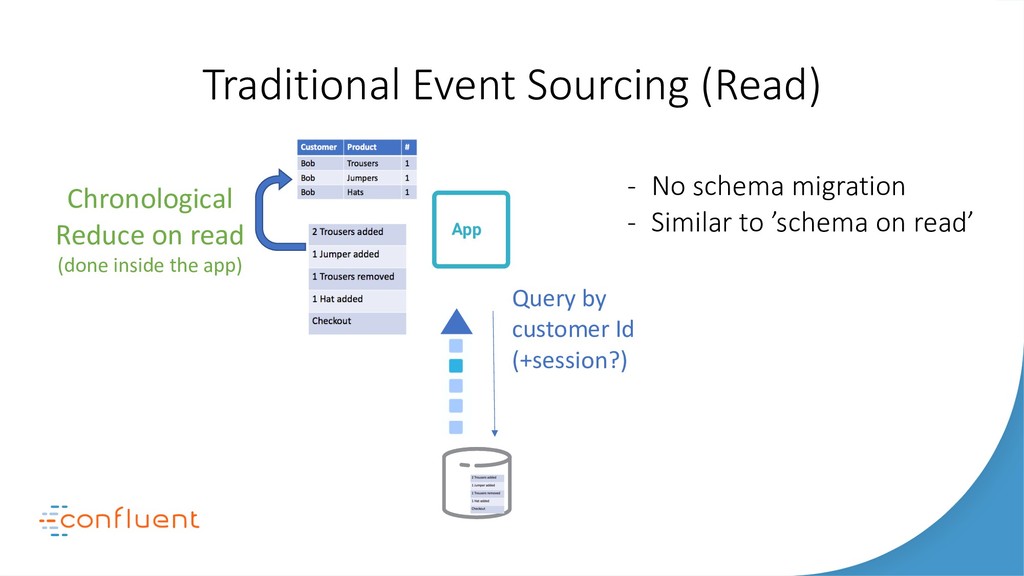
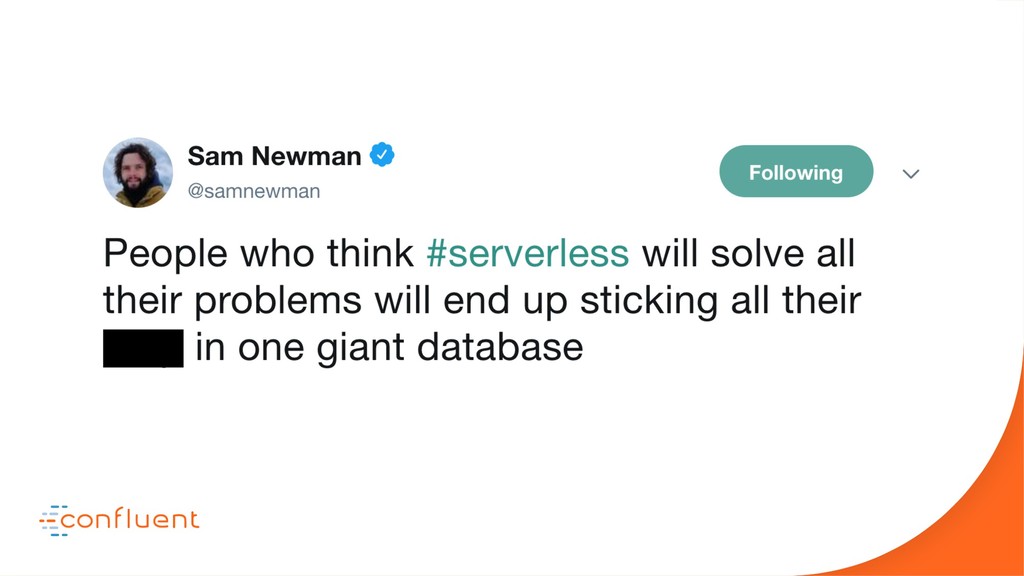
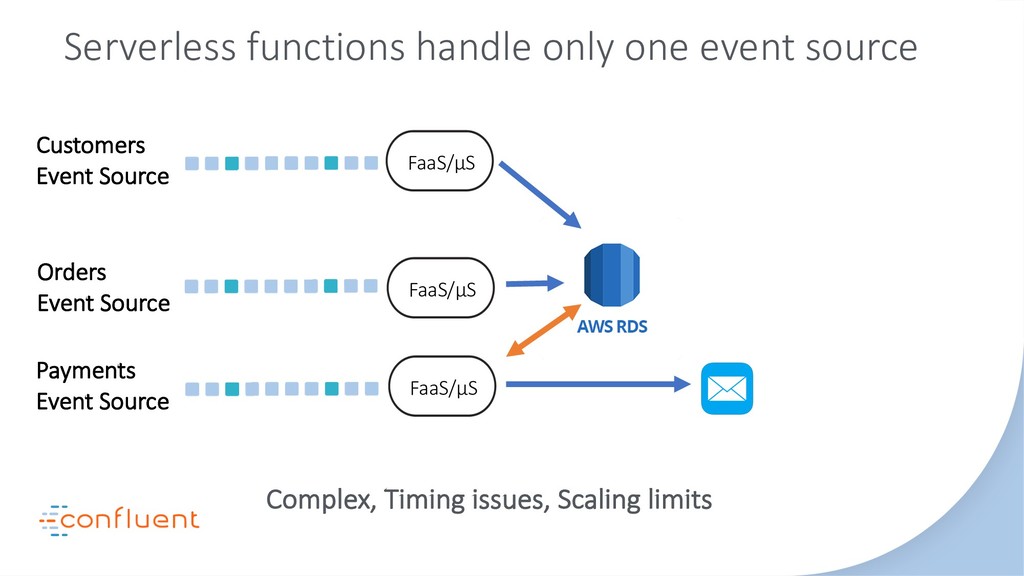
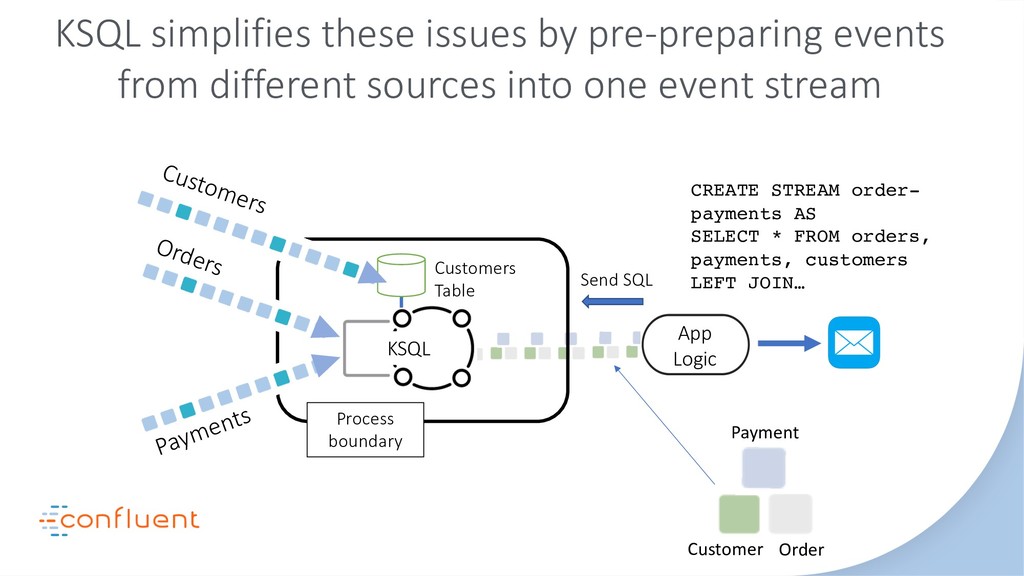
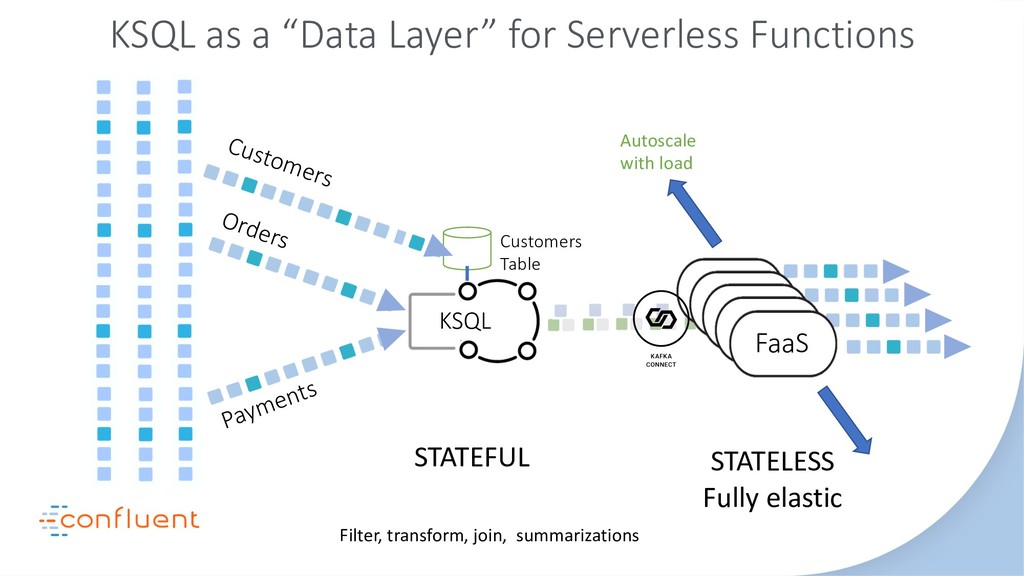
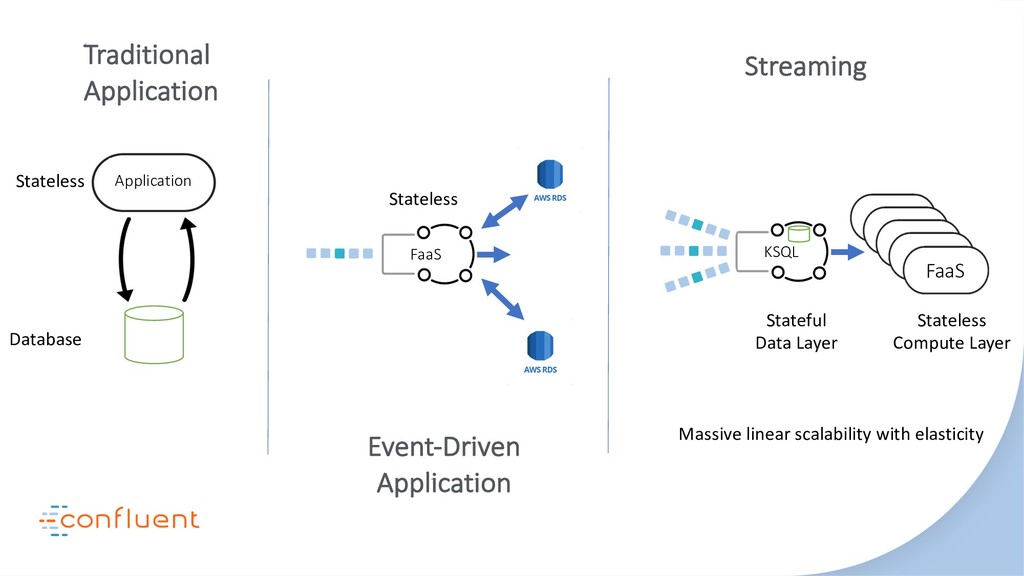
In this talk we’ll look at the relationship between three of the most disruptive software engineering paradigms: event sourcing, stream processing and serverless. We’ll debunk some of the myths around event sourcing. We’ll look at the inevitability of event-driven programming in the serverless space and we’ll see how stream processing links these two concepts together with a single ‘database for events’. As the story unfolds we’ll dive into some use cases, examine the practicalities of each approach-particularly the stateful elements-and finally extrapolate how their future relationship is likely to unfold. Key takeaways include: The different flavors of event sourcing and where their value lies. The difference between stream processing at application- and infrastructure-levels. The relationship between stream processors and serverless functions. The practical limits of storing data in Kafka and stream processors like KSQL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
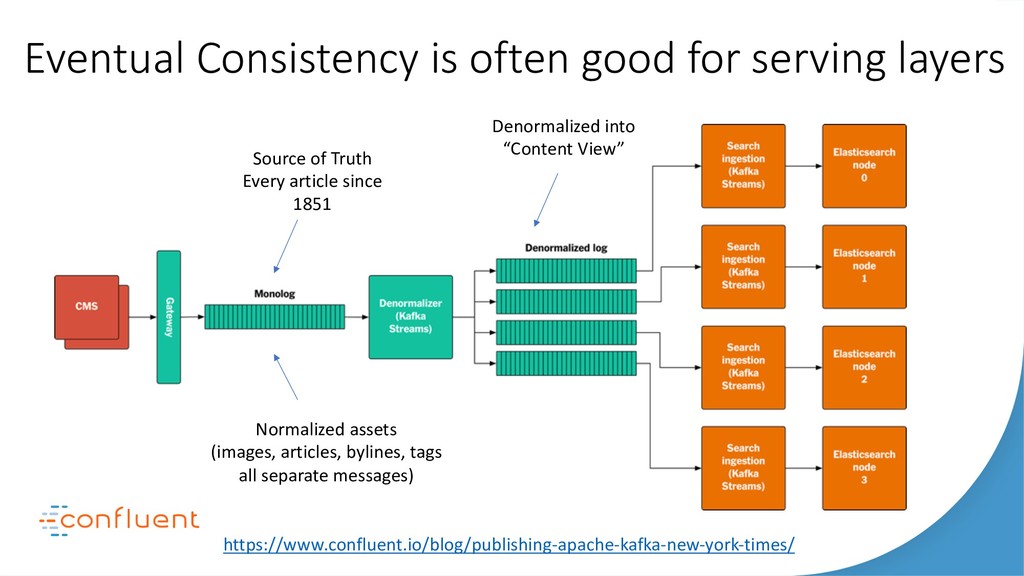{kind=link}
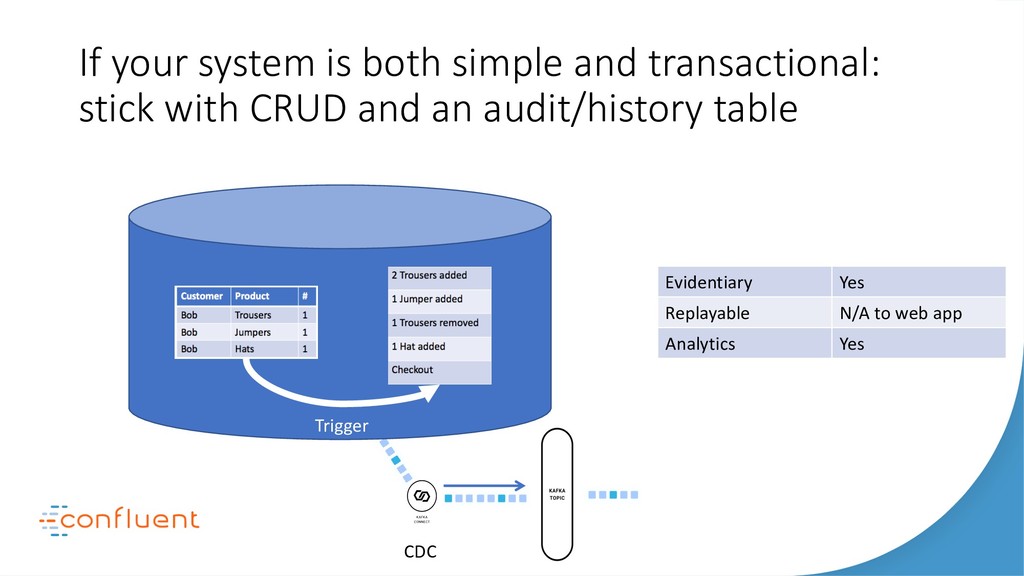{kind=link}
{kind=link}
{kind=link}
{kind=link}
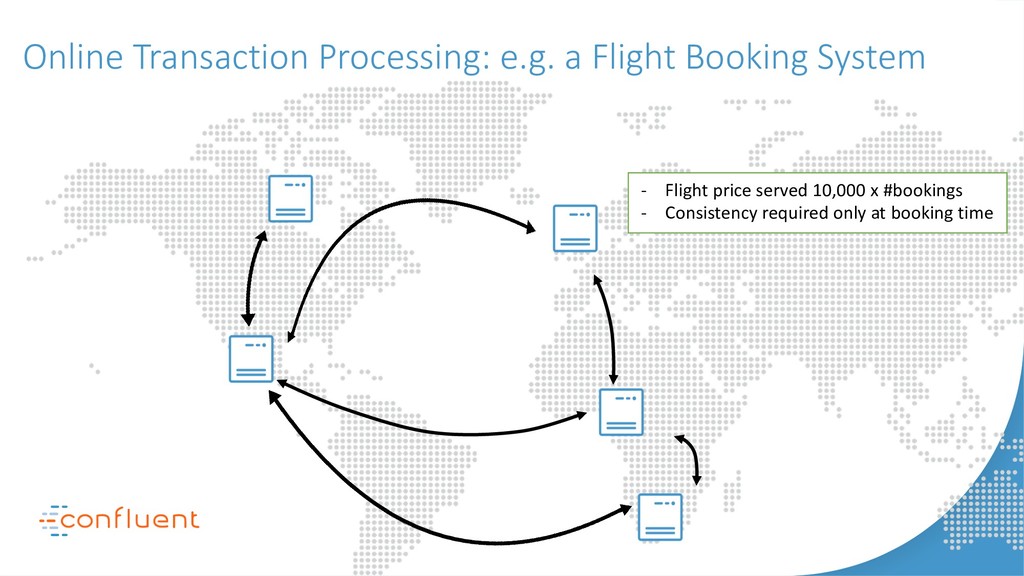{kind=link}
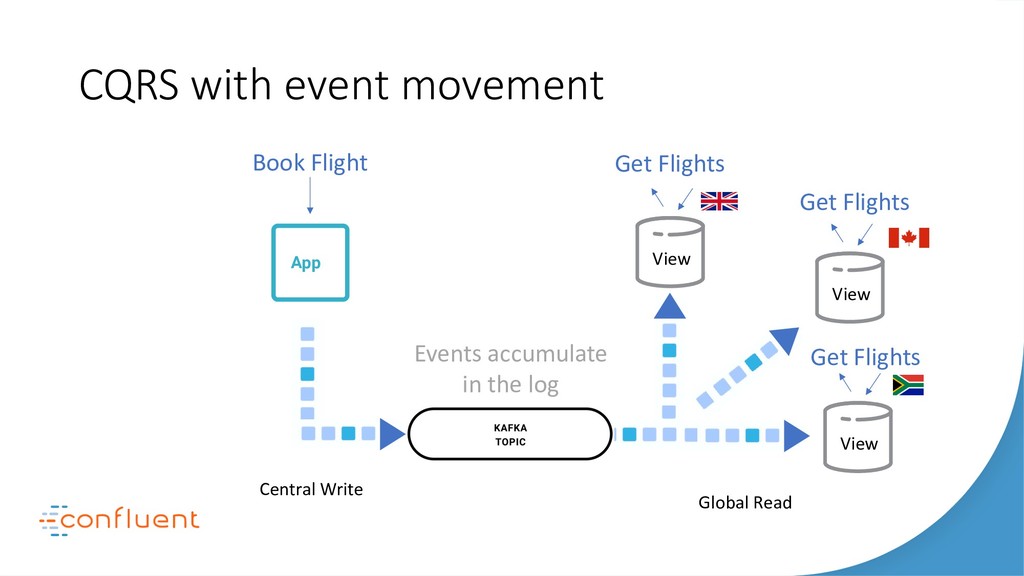{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}