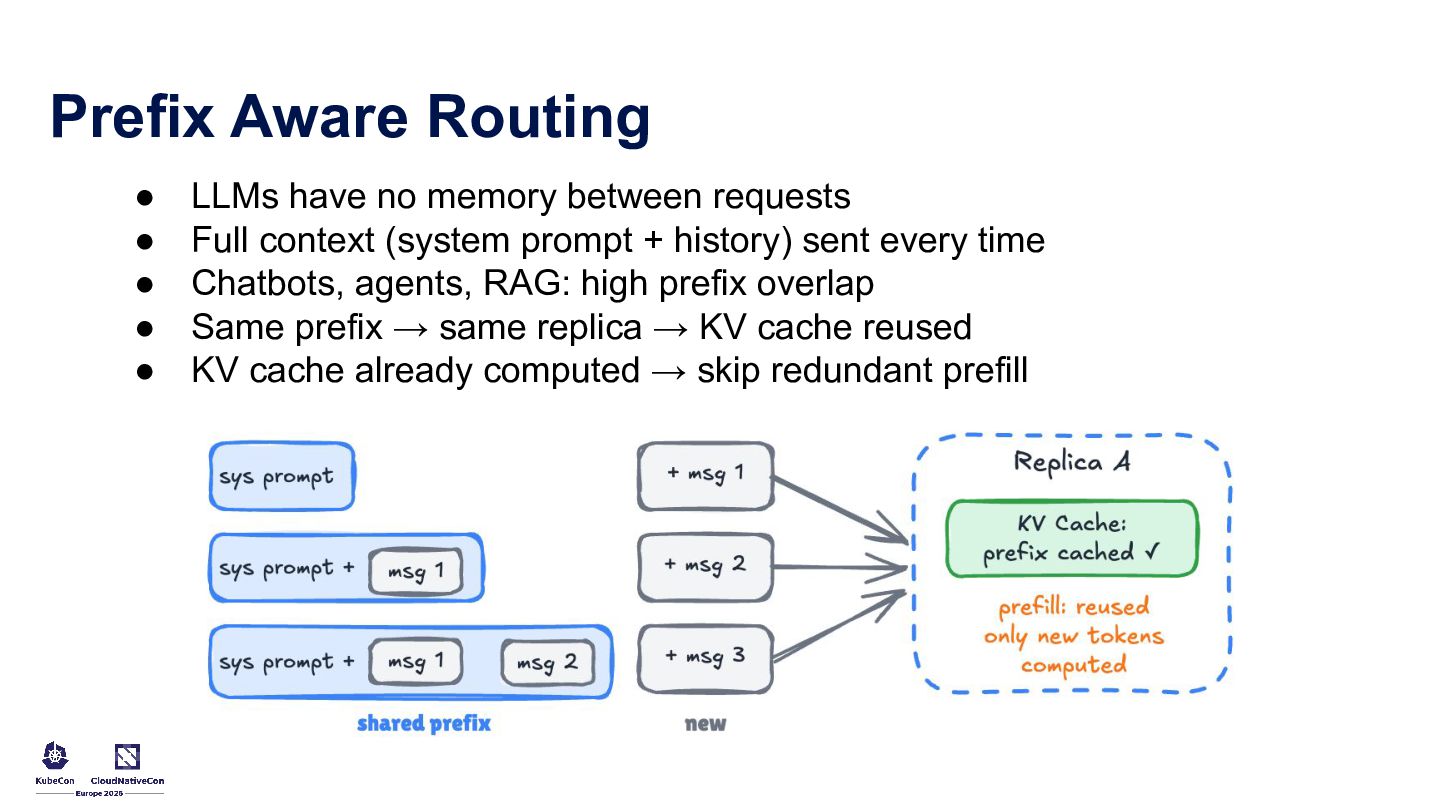
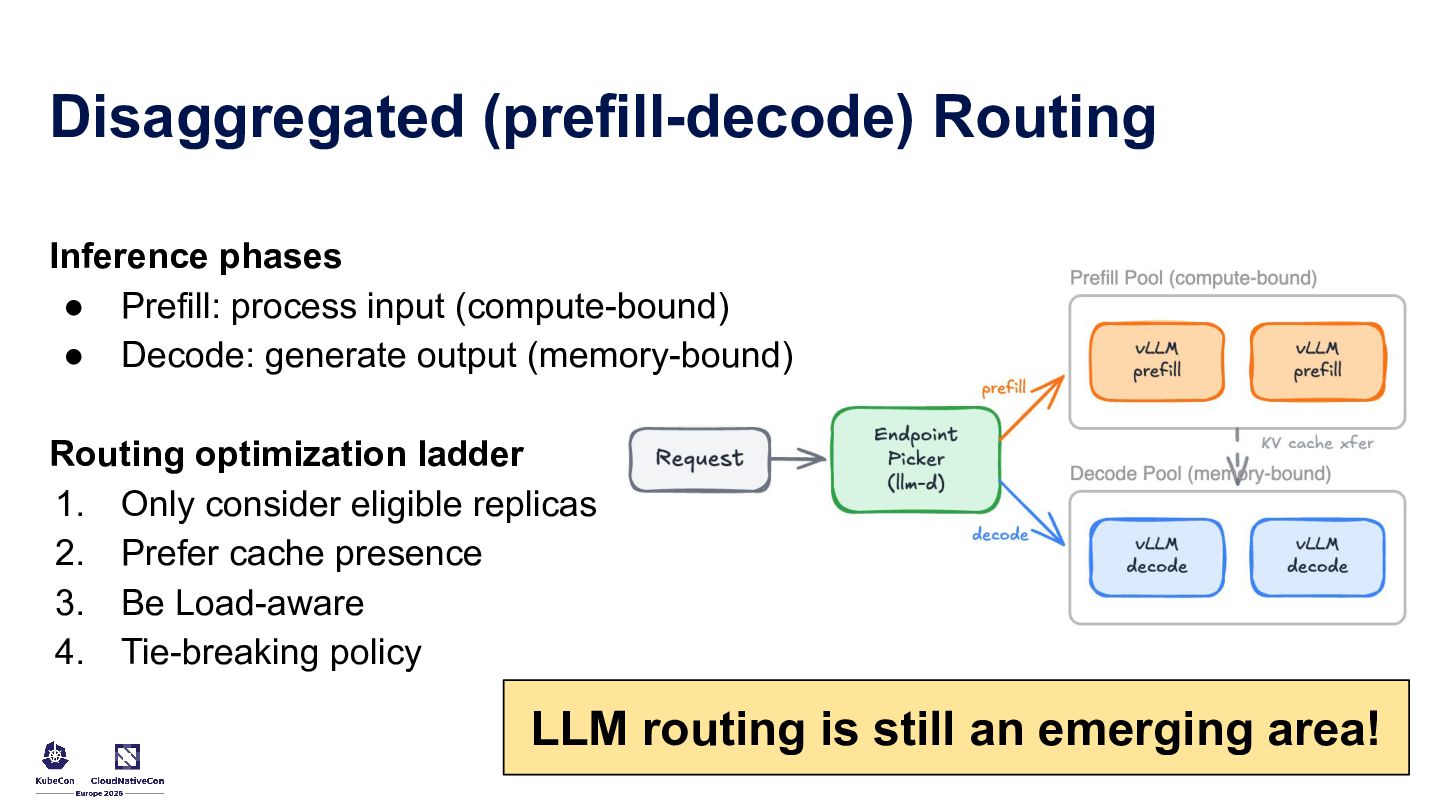
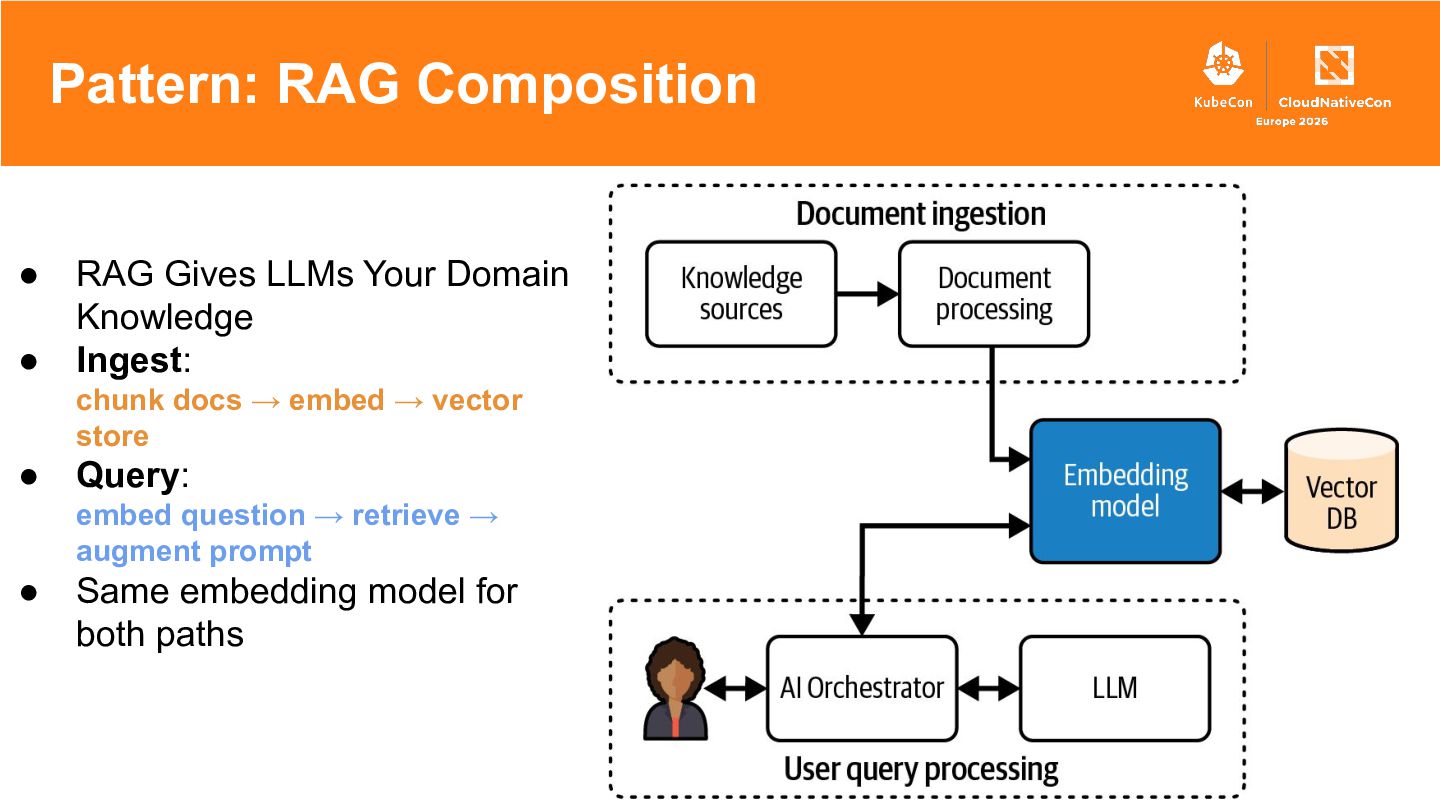
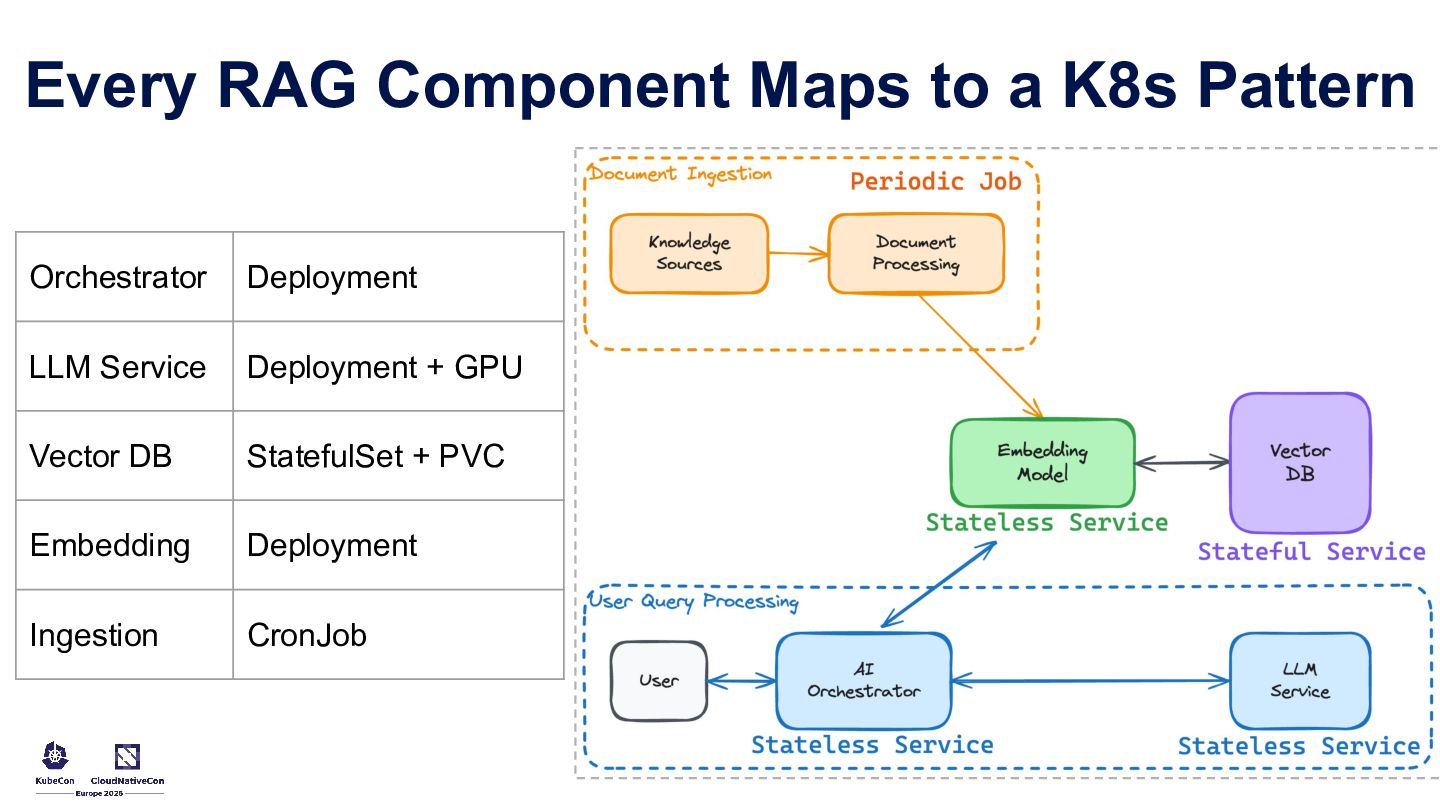
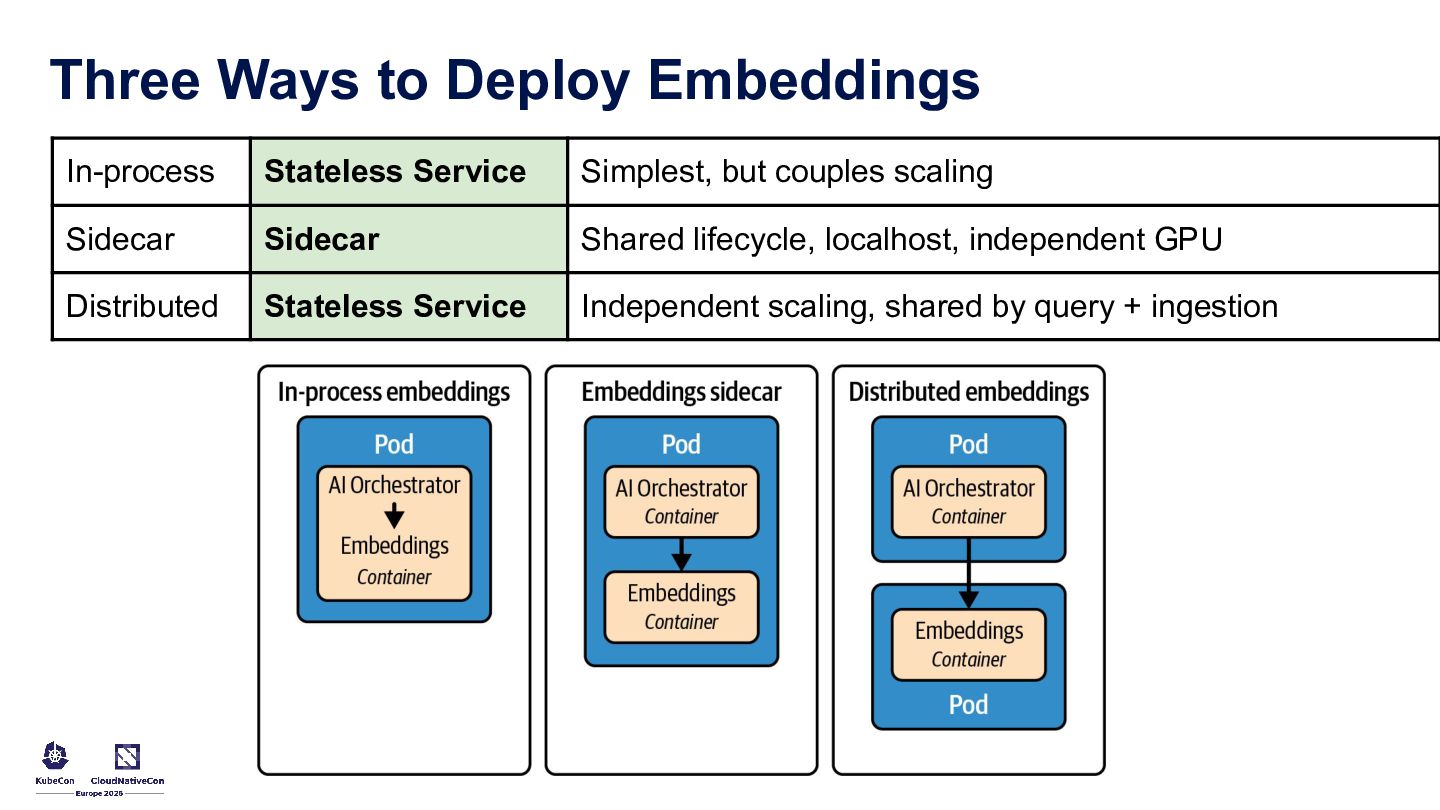
Running LLM and AI workloads on Kubernetes should not feel like a leap into the unknown. This talk uses familiar Kubernetes patterns to make GenAI systems easier to build and operate in production. It covers controllers and custom resources for stable model endpoints, startup patterns for predictable rollouts, GPU-aware scheduling, token-aware traffic management, gateway policies for latency control, and a practical RAG architecture with stateless orchestration, vector storage, and background ingestion.
{kind=link}
{kind=link}
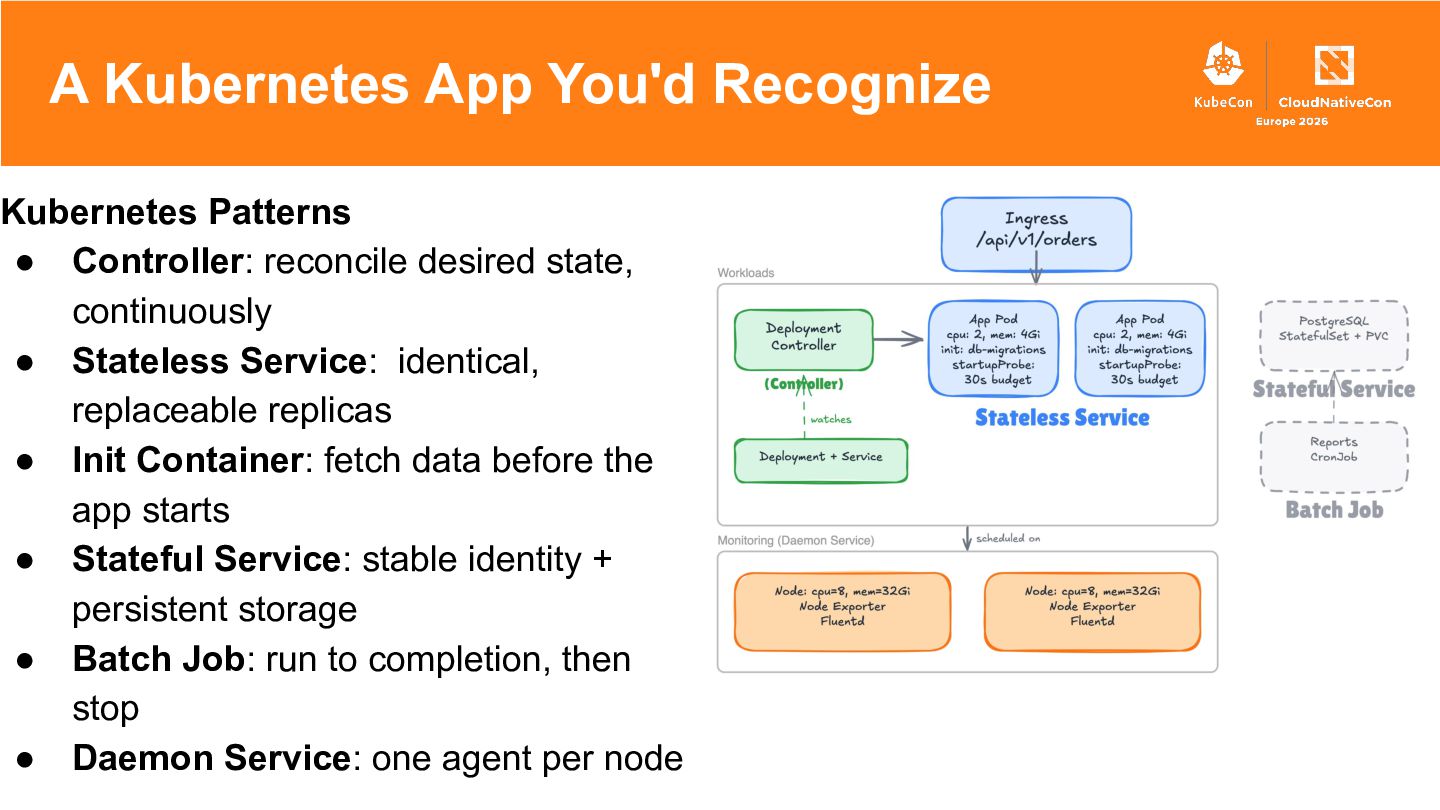{kind=link}
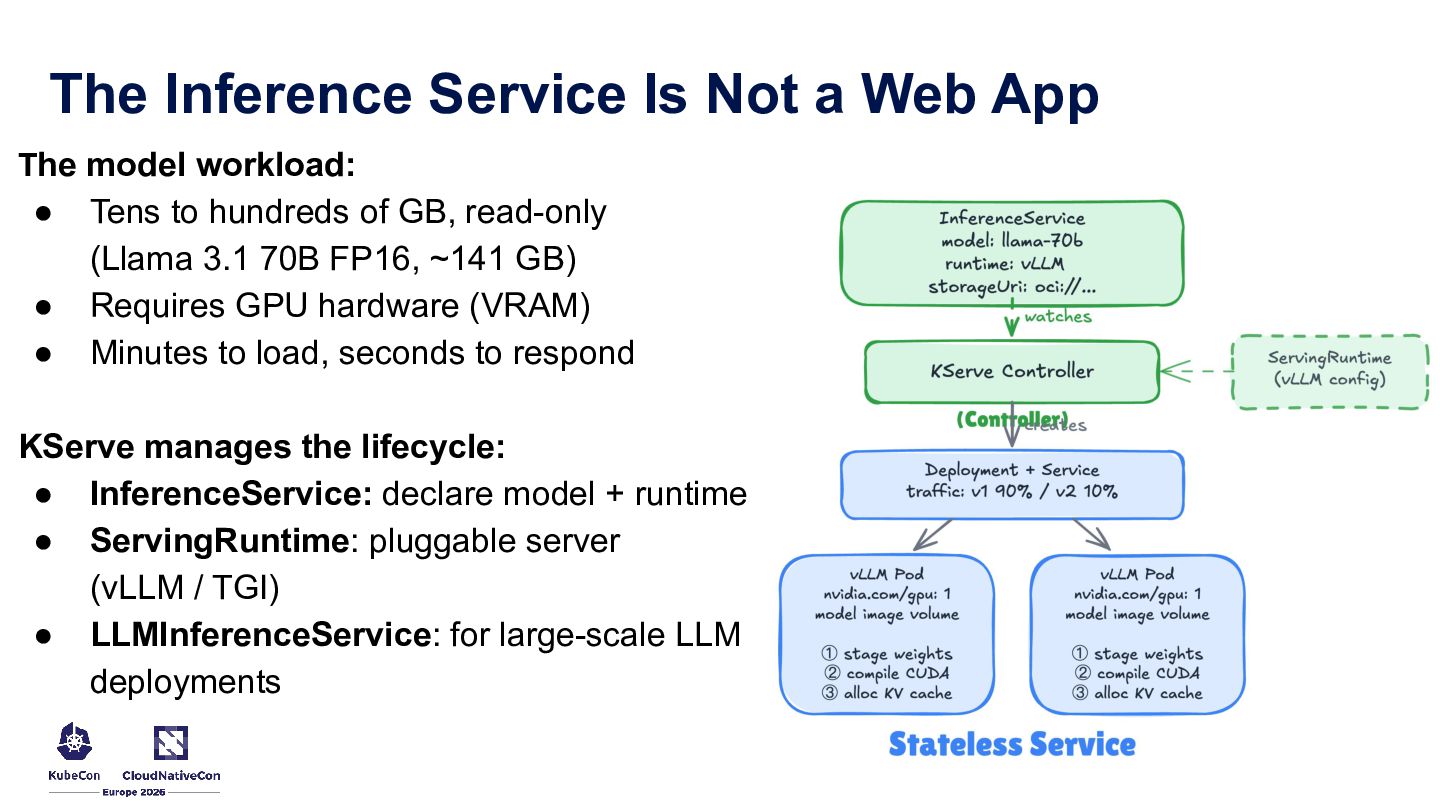{kind=link}
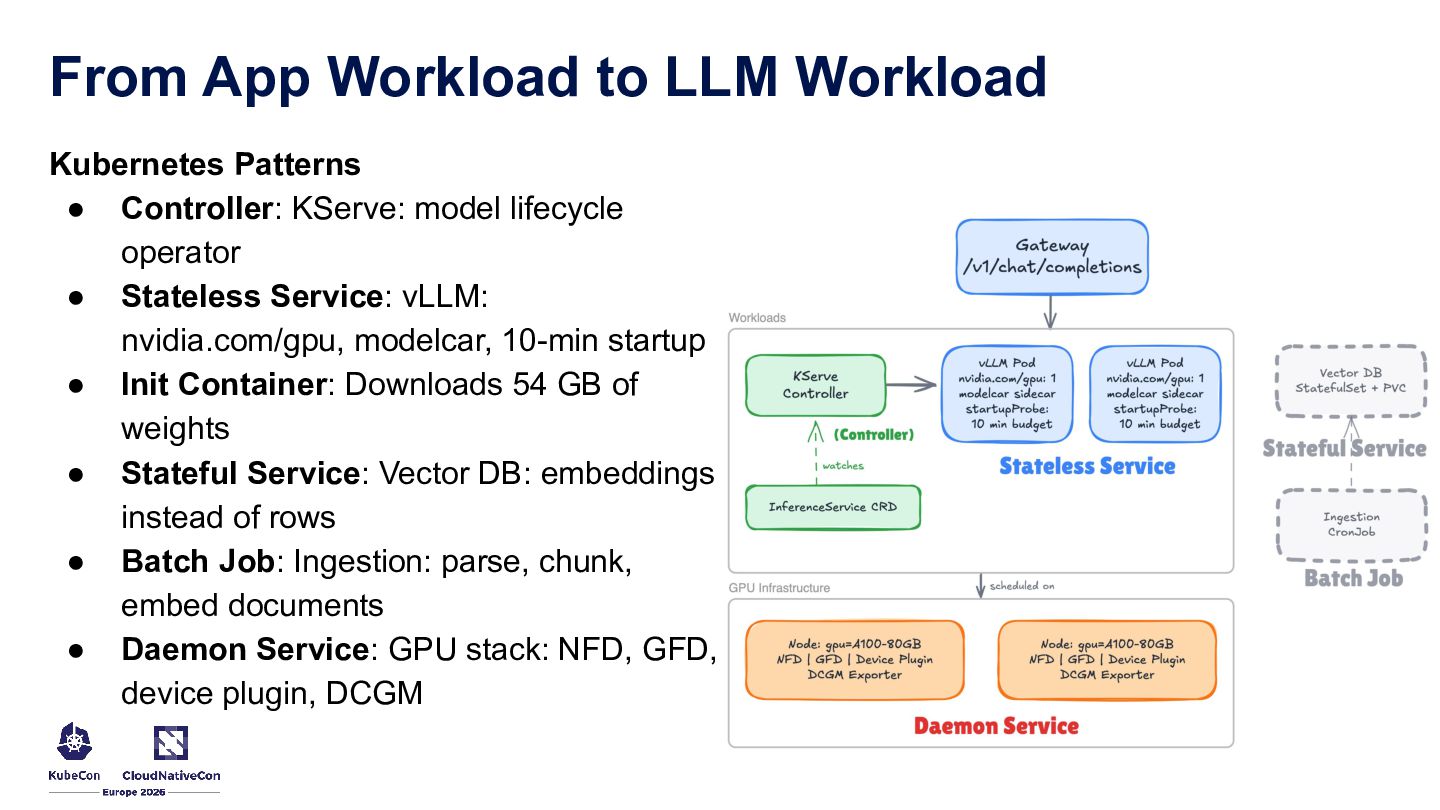{kind=link}
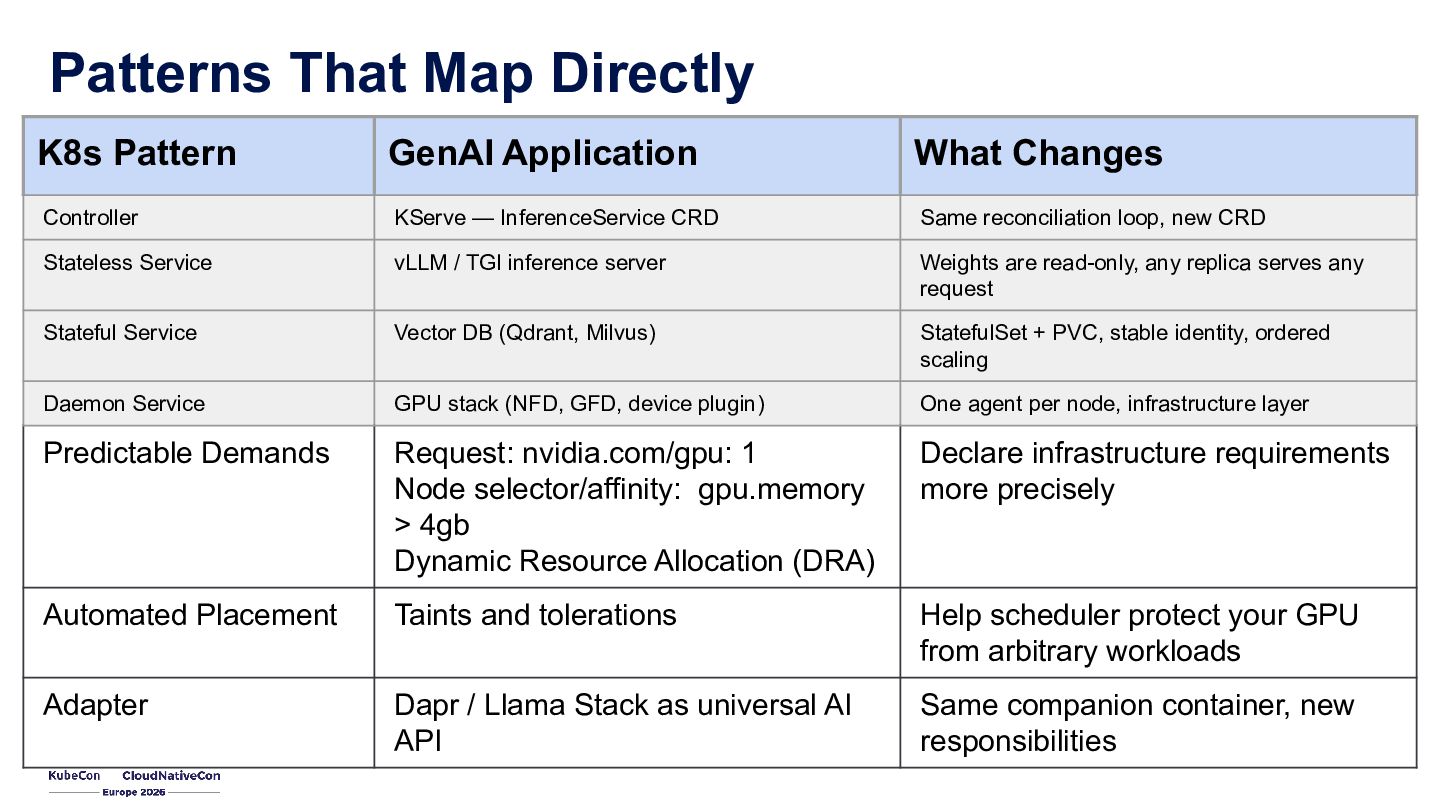{kind=link}
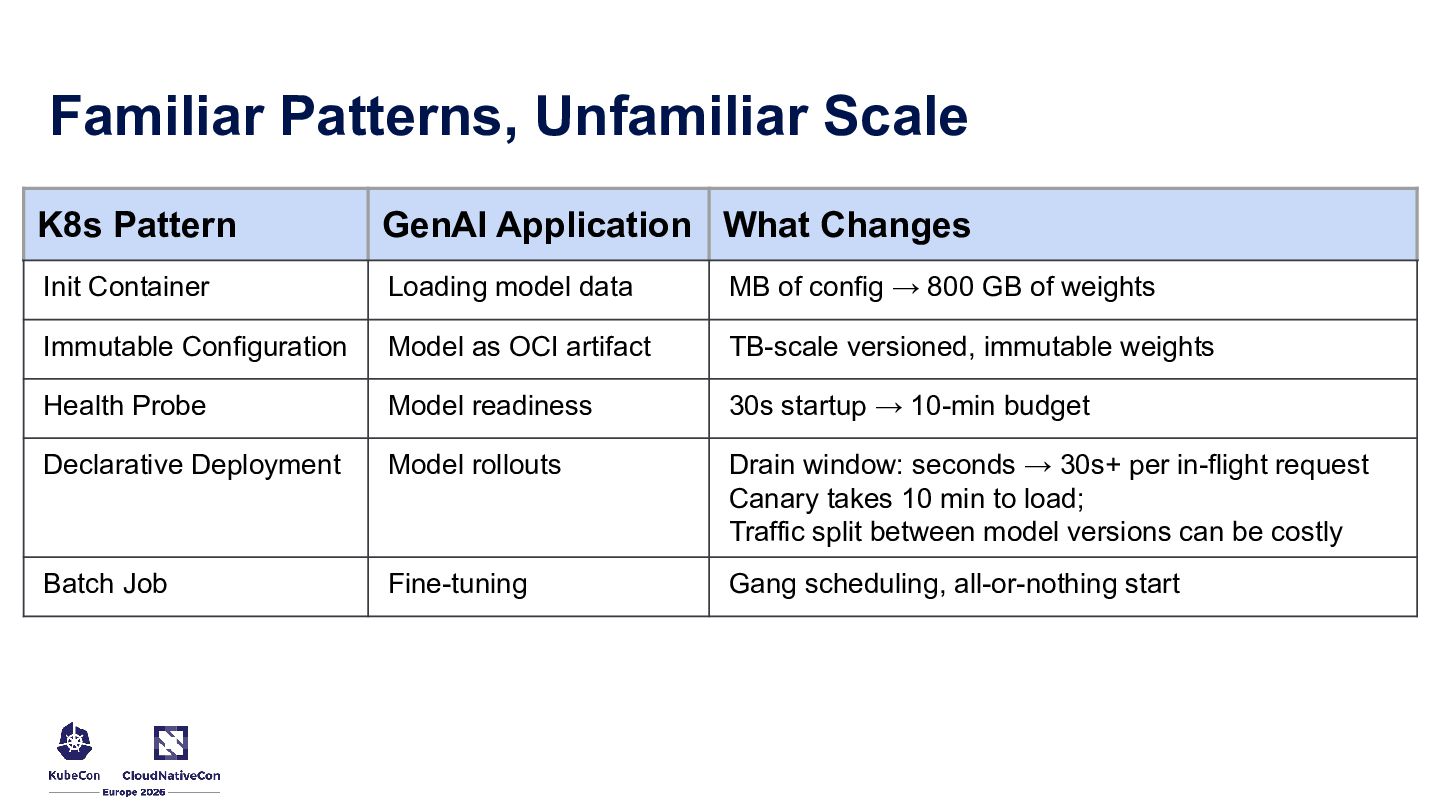{kind=link}
{kind=link}
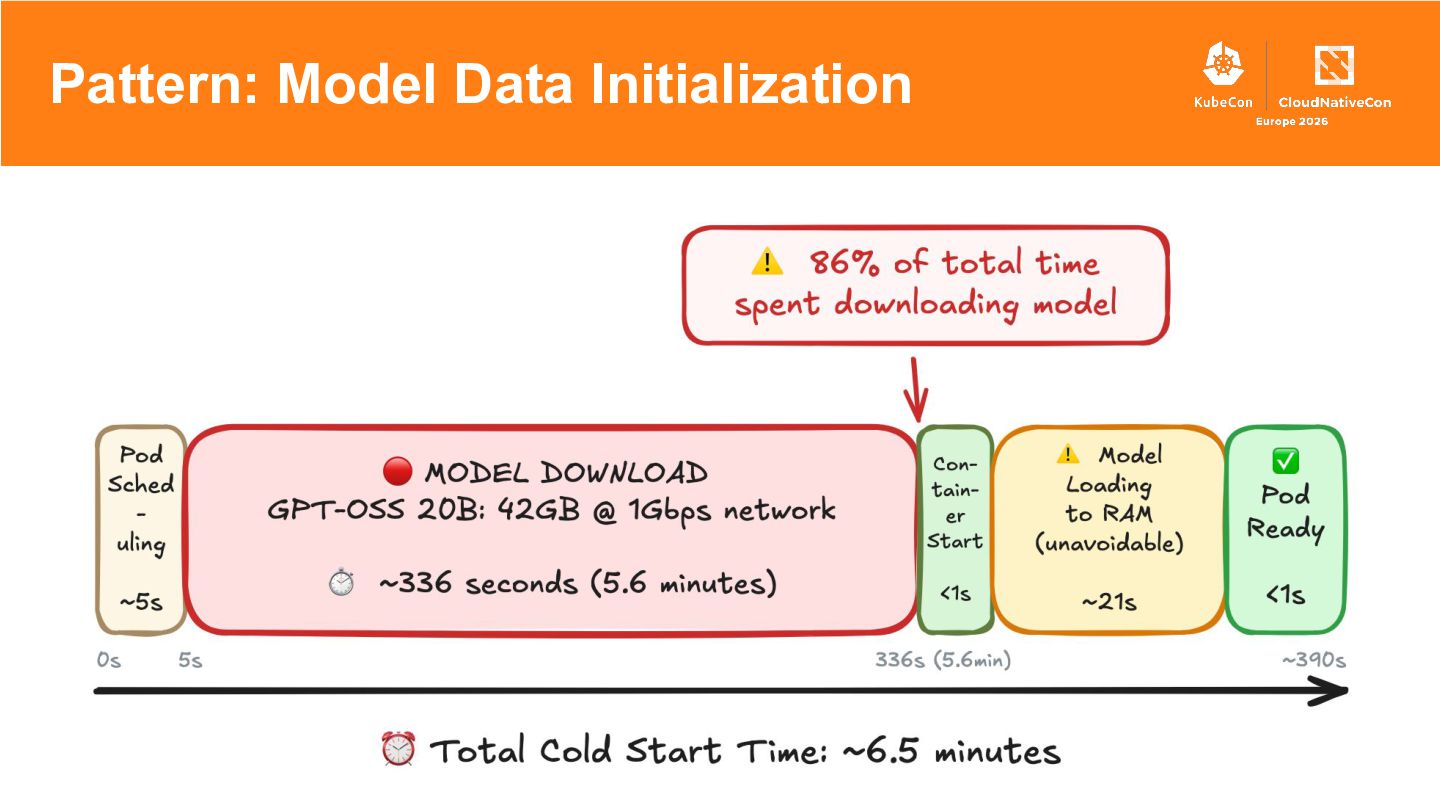{kind=link}
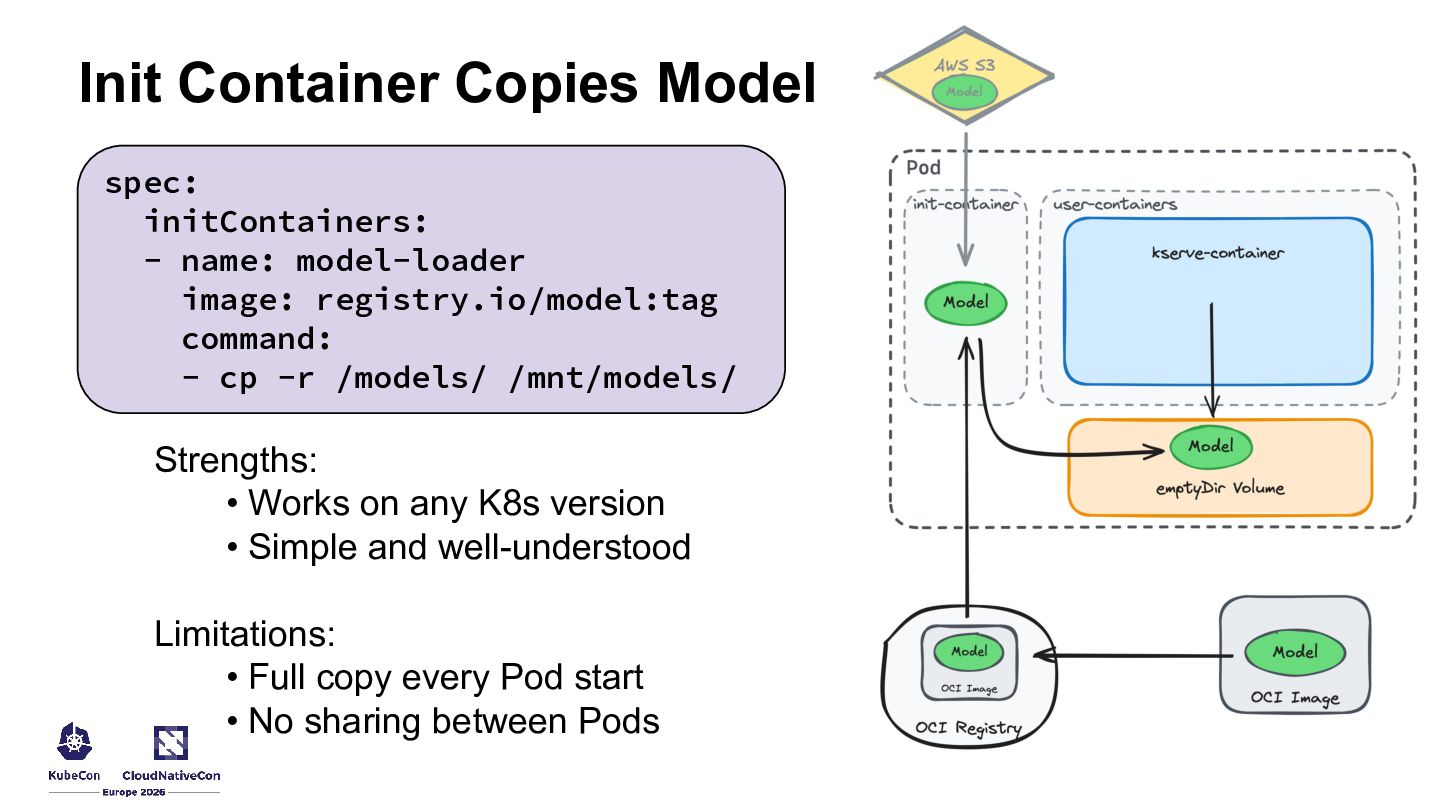{kind=link}
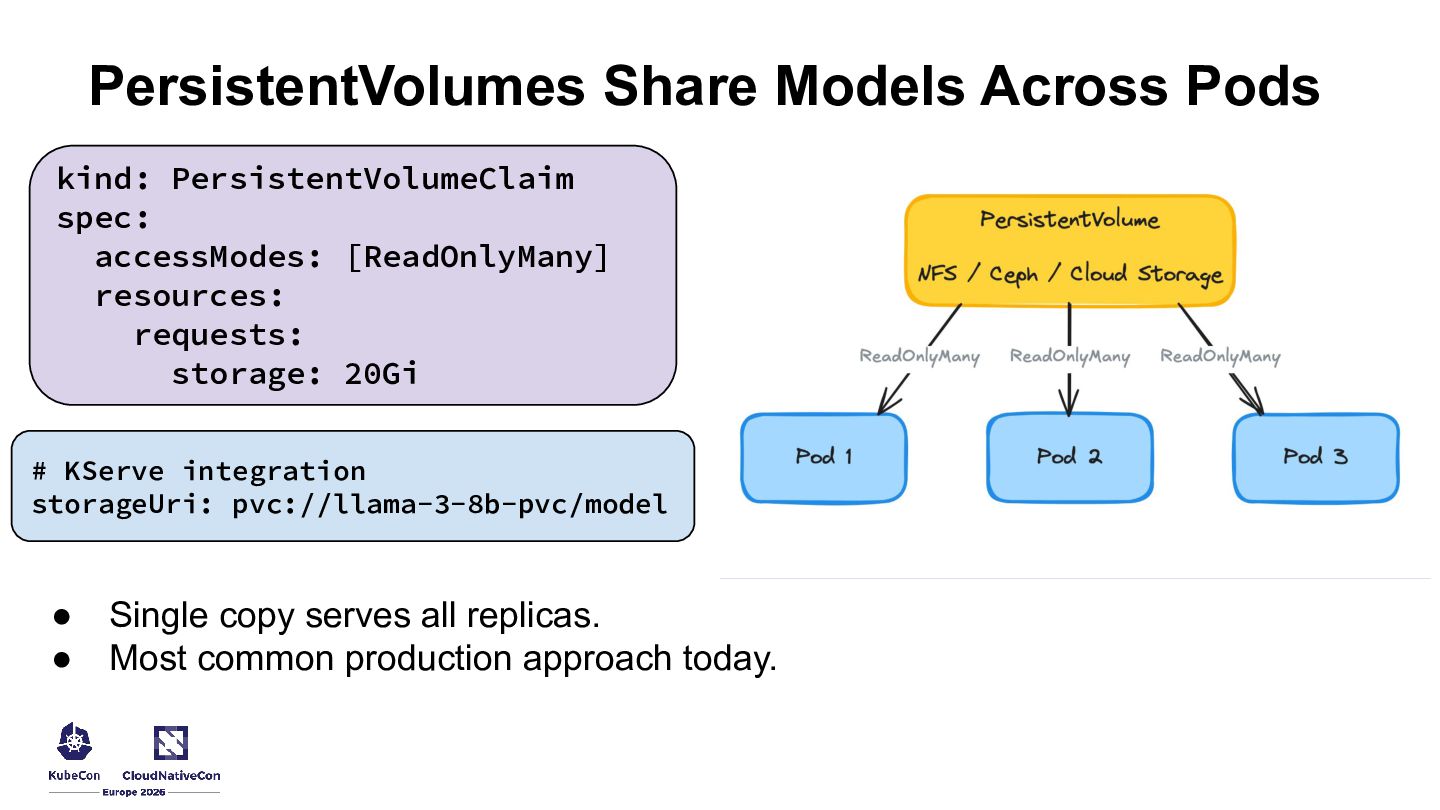{kind=link}
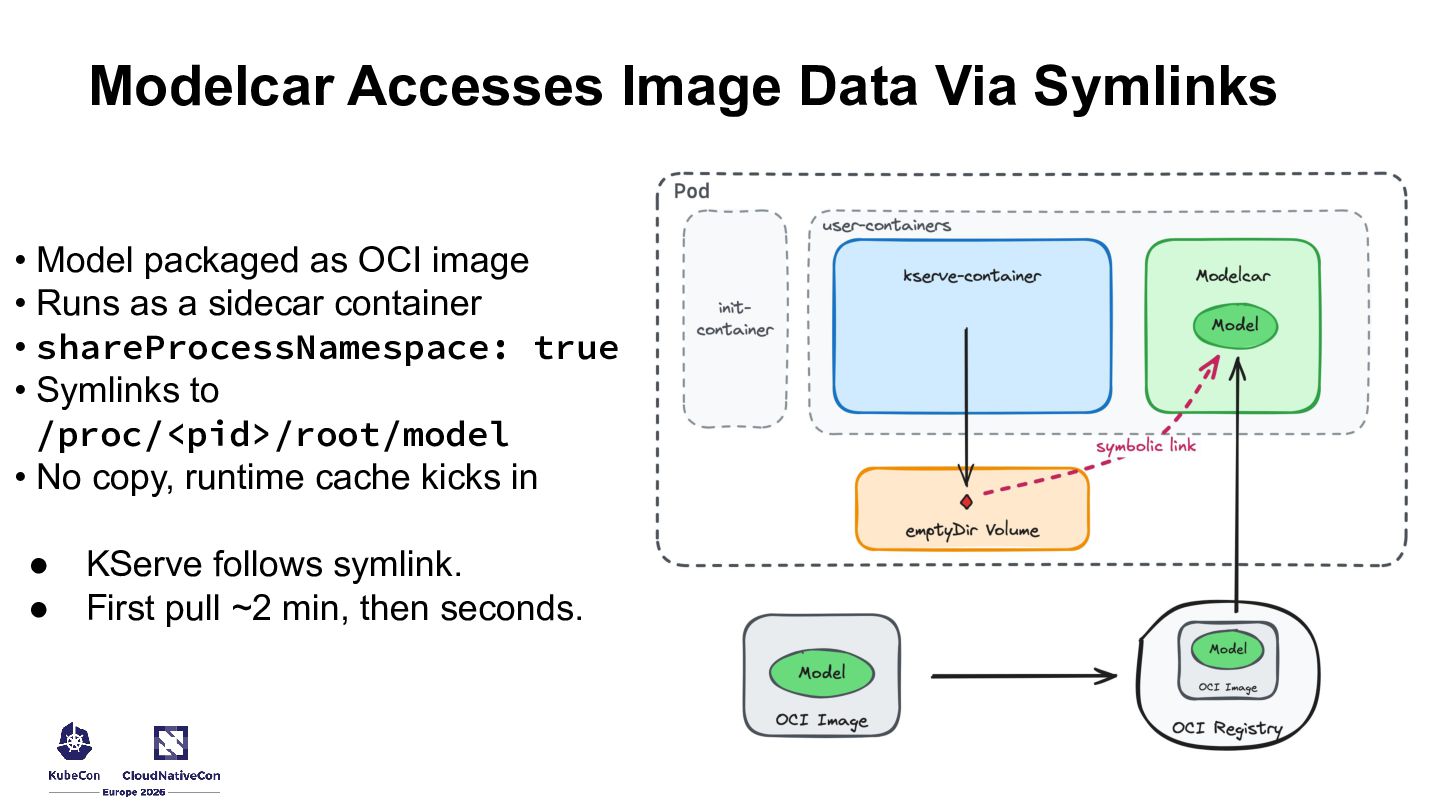{kind=link}
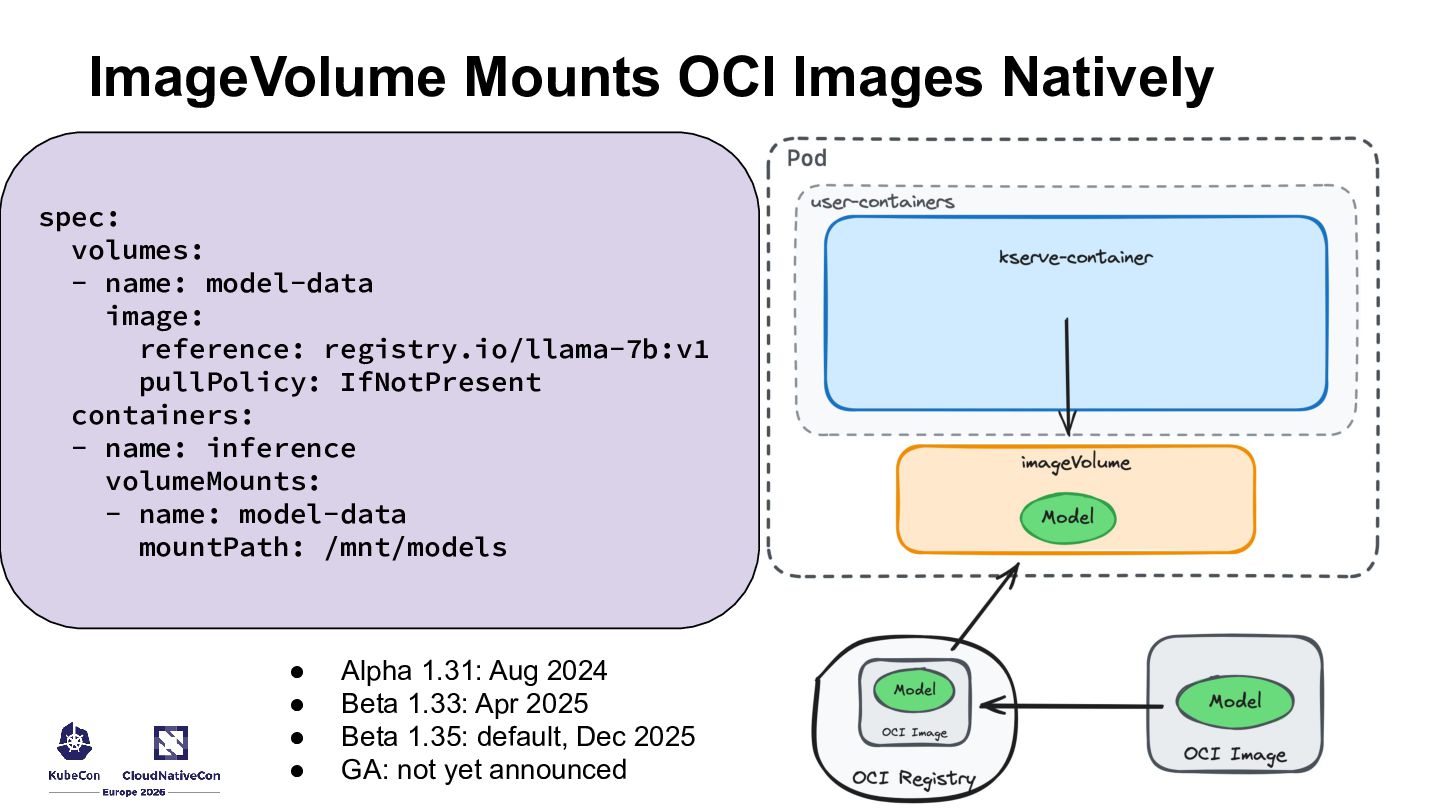{kind=link}
{kind=link}
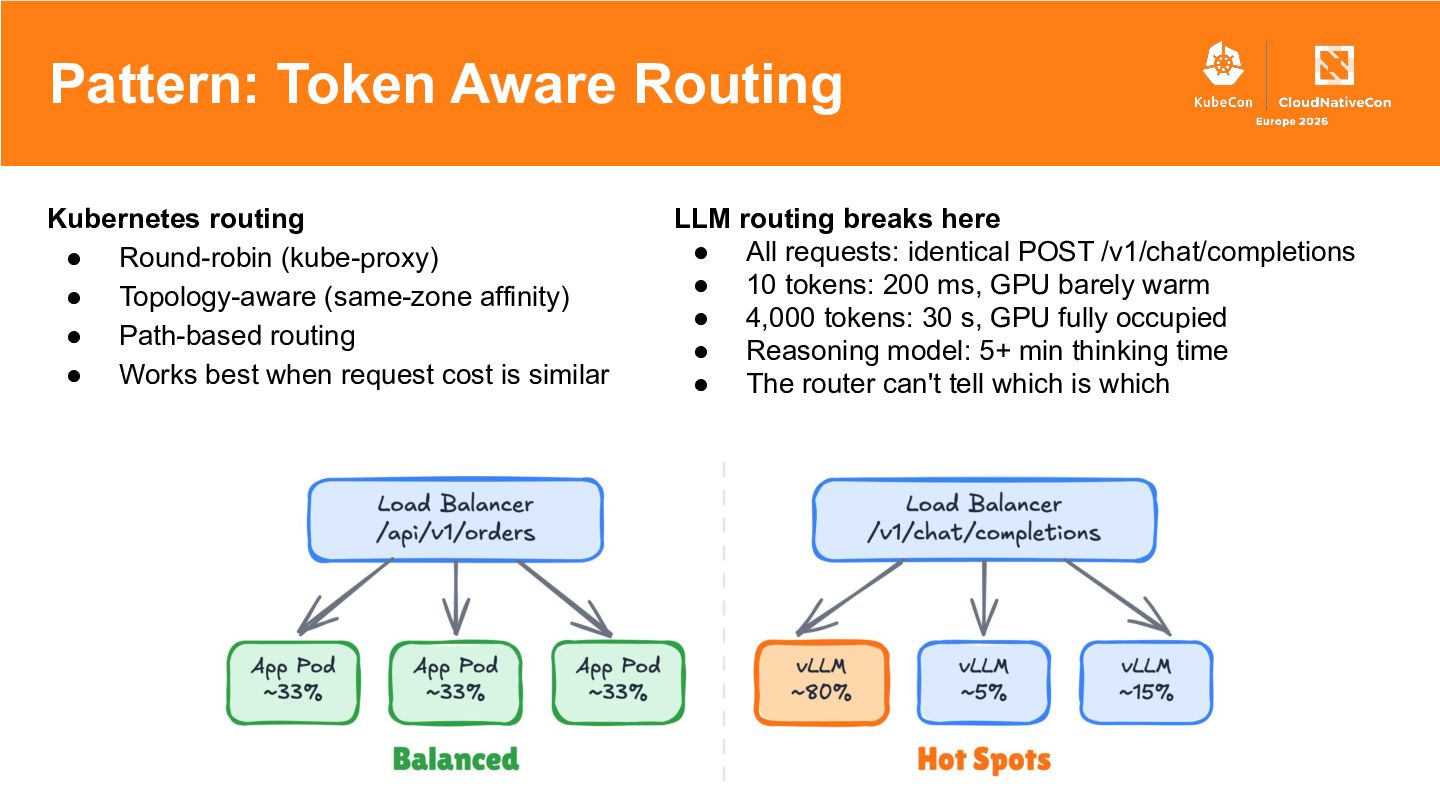{kind=link}
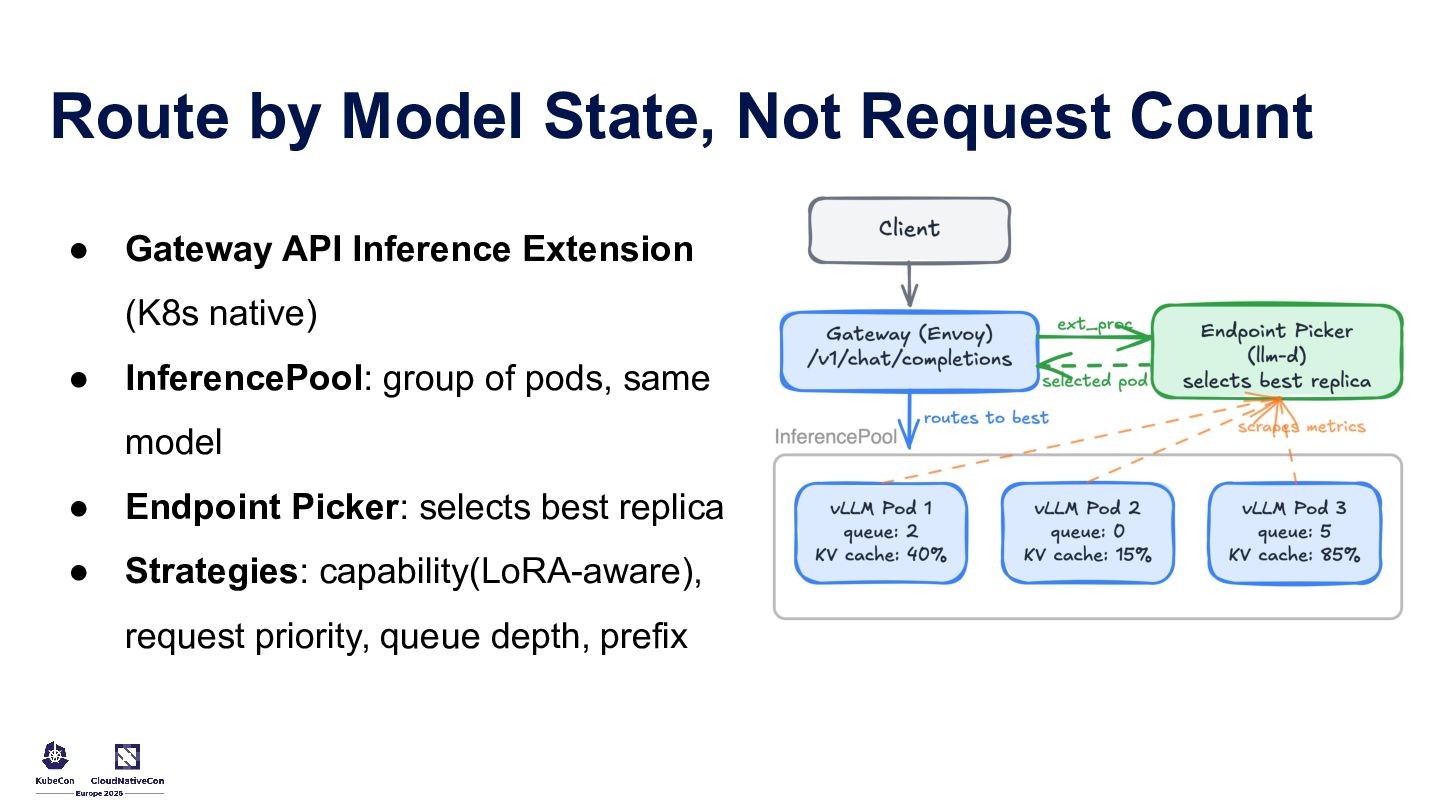{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}