Apache Spark is a great solution for building Big Data applications. It provides really fast SQL-like processing, machine learning library, and streaming module for near real time processing of data streams. Unfortunately, during application development and production deployments we often encounter many difficulties in mixing various data sources or bulk loading of computed data to SQL or NoSQL databases
https://www.bigdataspain.org/2017/talk/apache-spark-vs-rest-of-the-world-problems-and-solutions
Big Data Spain 2017
16th - 17th November Kinépolis Madrid
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
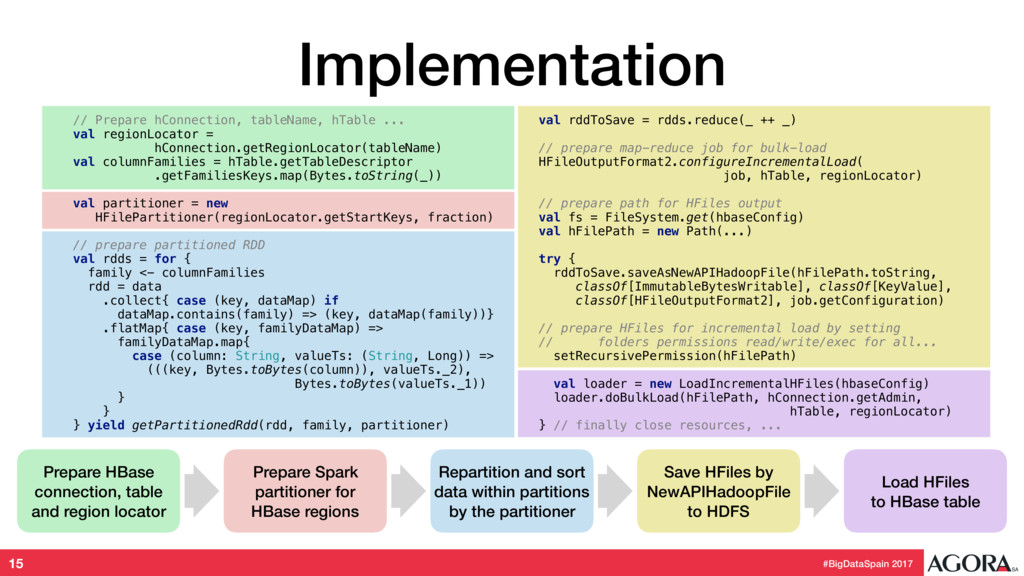{kind=link}
{kind=link}
{kind=link}
{kind=link}
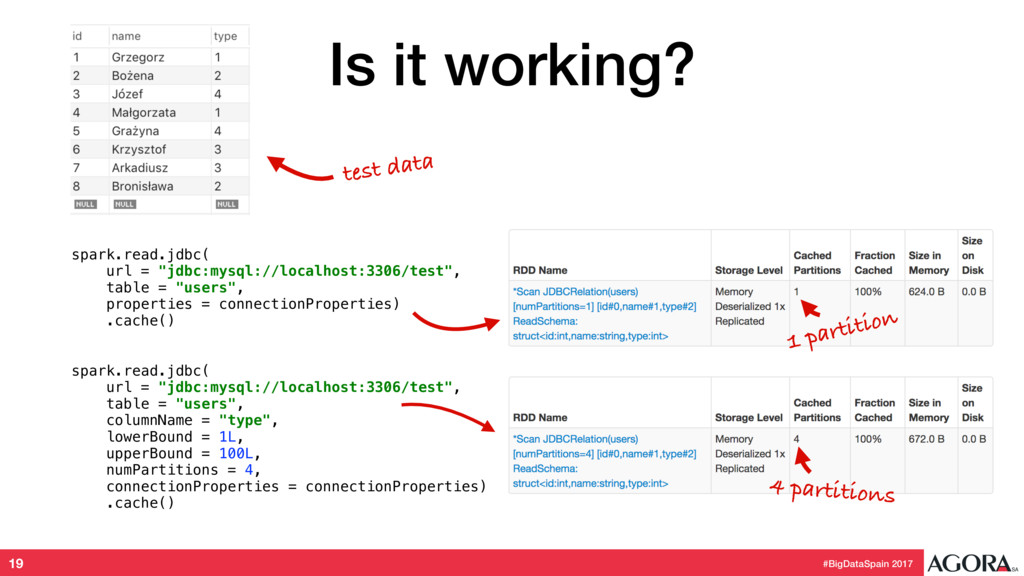{kind=link}
{kind=link}
{kind=link}
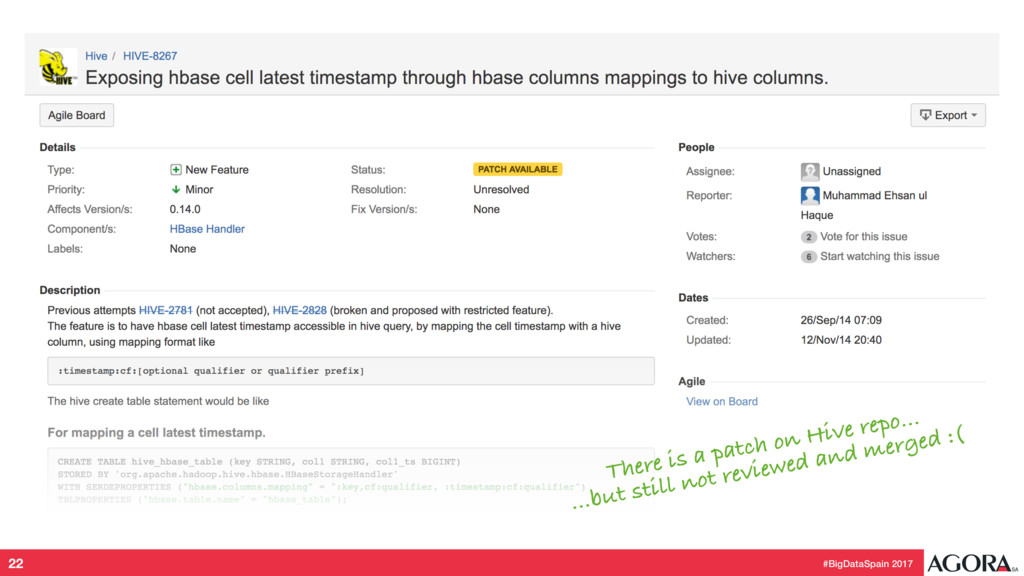{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Questions? [email protected] www.linkedin.com/in/arkadiusz-jachnik](https://files.speakerdeck.com/presentations/6d3ee7b894de44e0be57b0ece14cfee8/slide_28.jpg){kind=link}