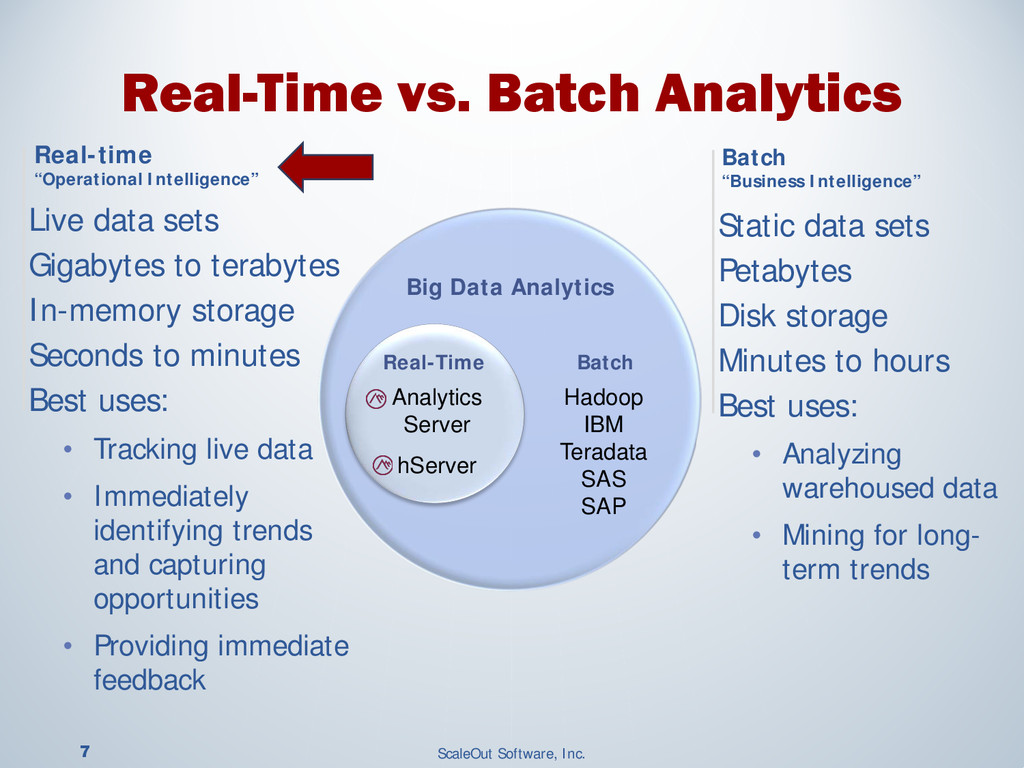
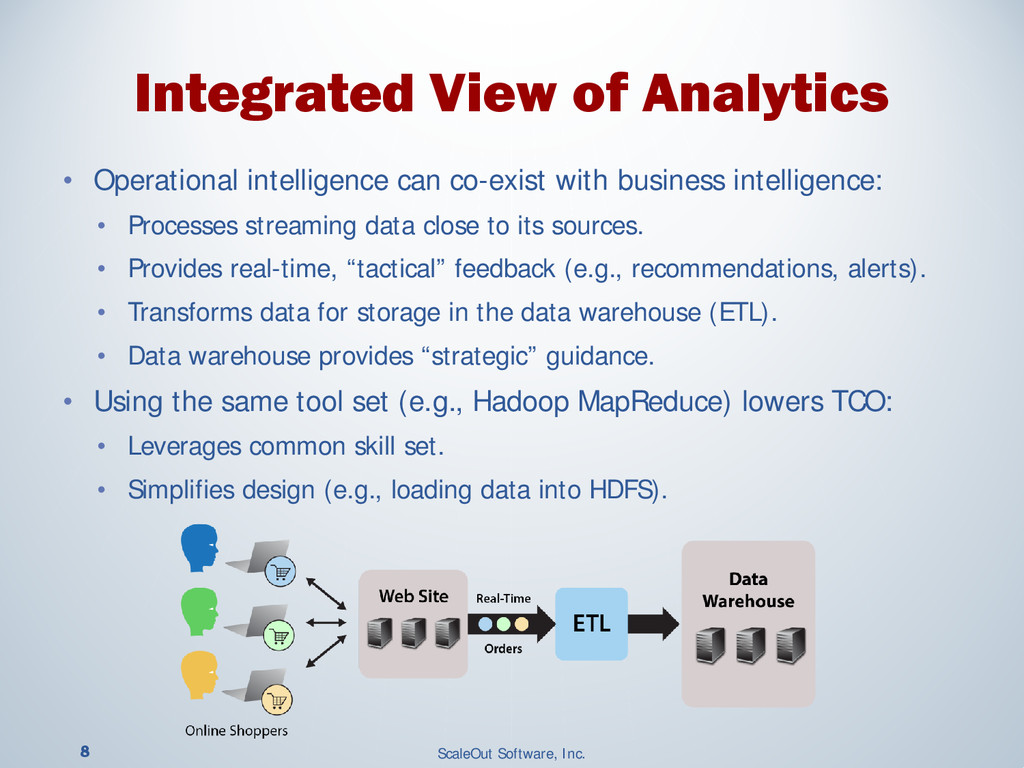
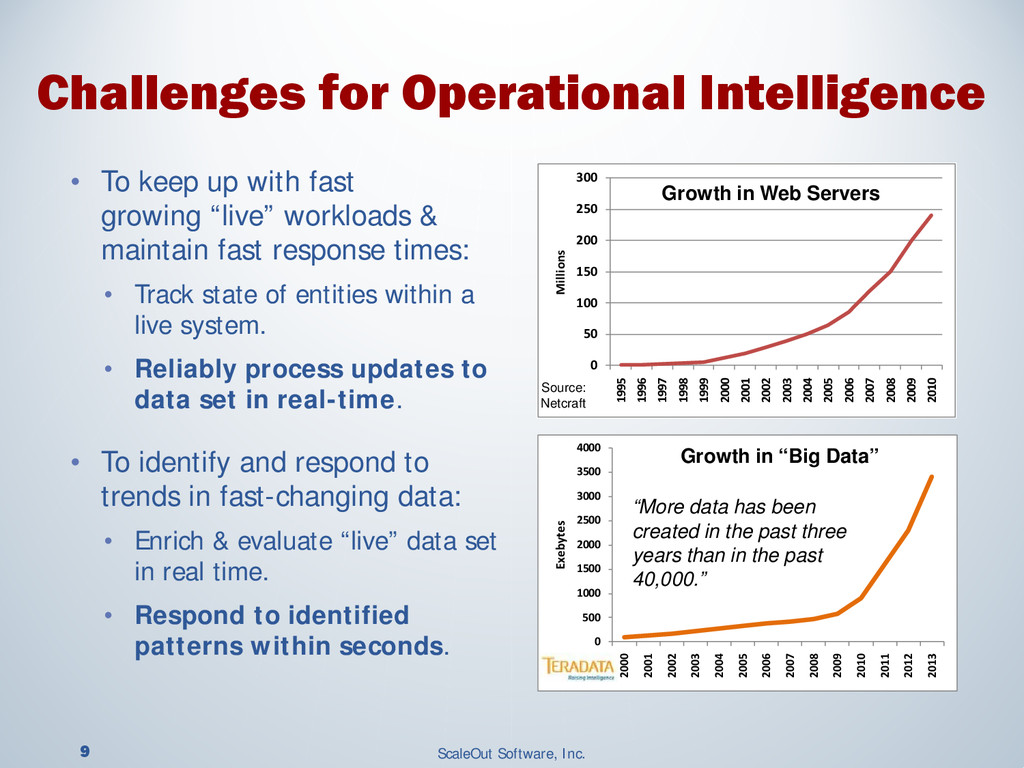
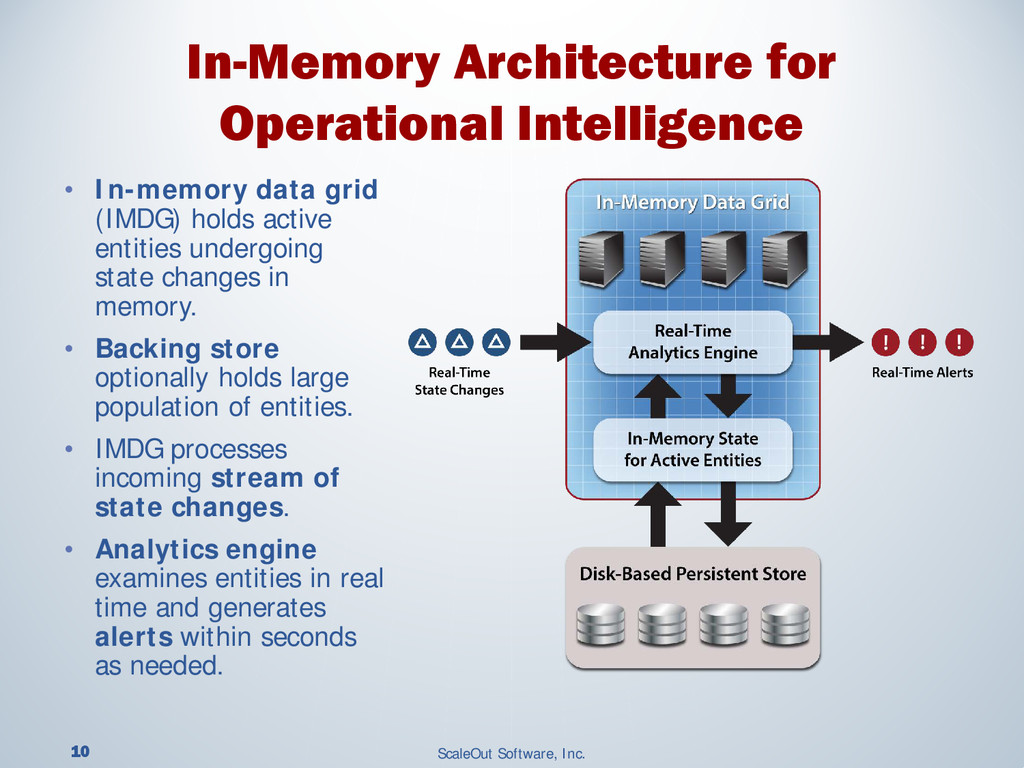
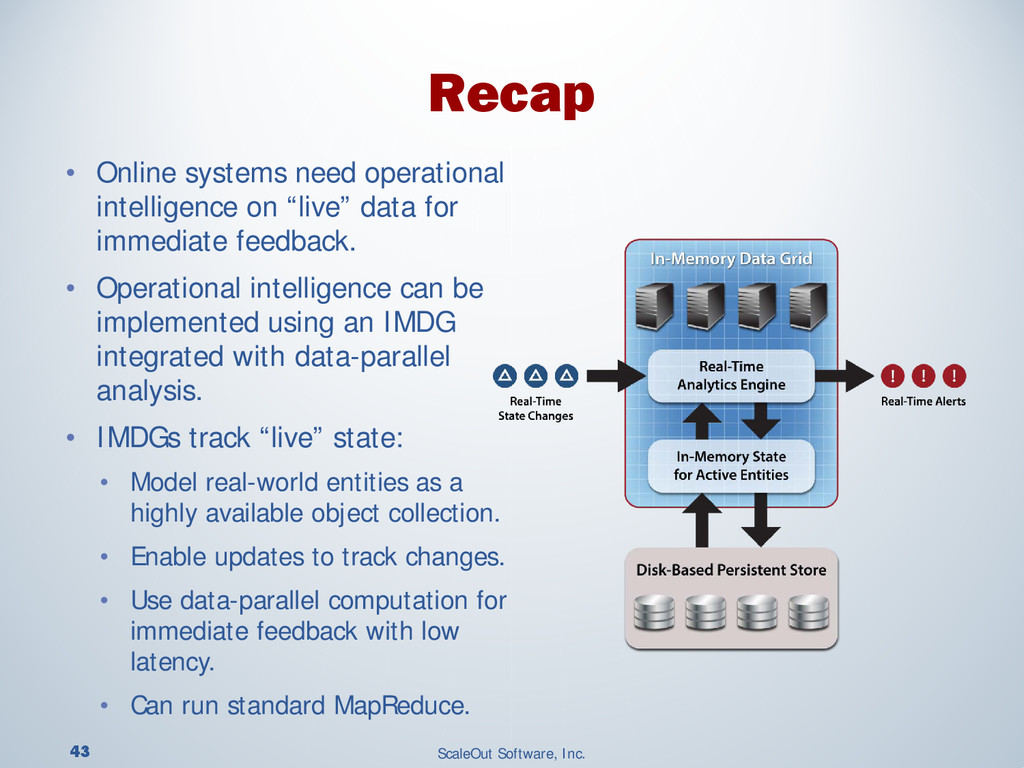
Operational systems manage our finances, shopping, devices and much more. Adding real-time analytics to these systems enables them to instantly respond to changing conditions and provide immediate, targeted feedback. This use of analytics is called “operational intelligence,” and the need for it is widespread. Financial trading applications must rapidly respond to fluctuating market conditions as market data flows through trading systems. E-commerce systems must reconcile orders with inventory changes on a second by second basis and need to quickly respond to shopping behavior to offer personalized recommendations. Smart grid monitoring systems need to continuously analyze telemetry from many sources to anticipate and respond to unexpected changes in power grids.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
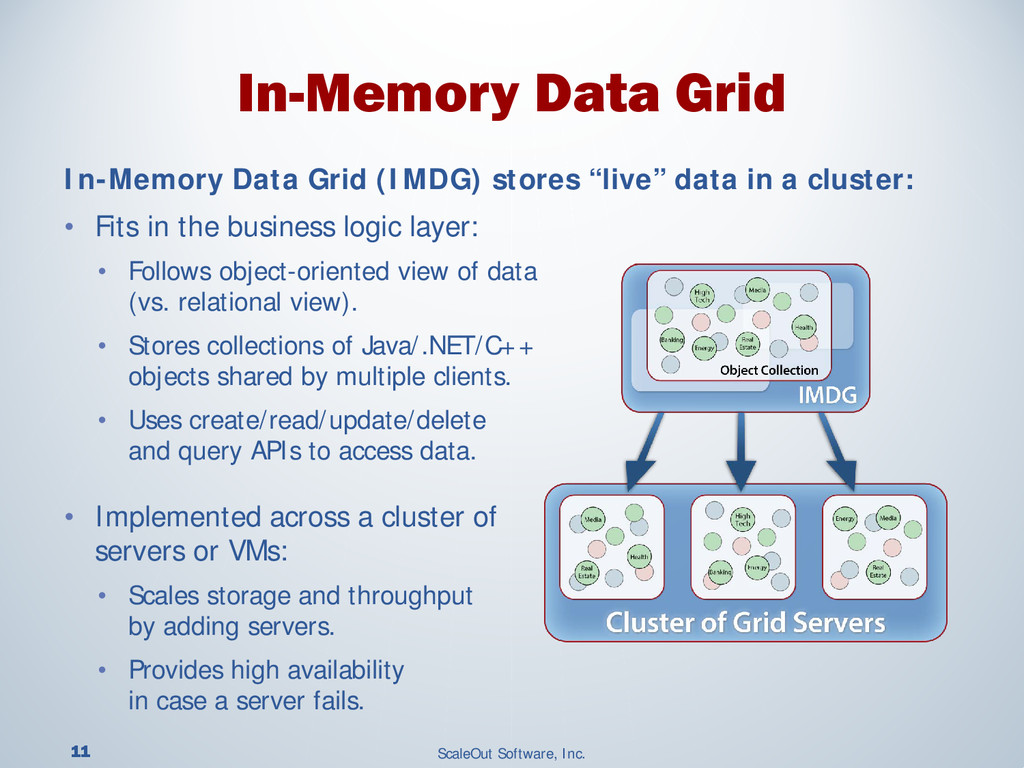{kind=link}
{kind=link}
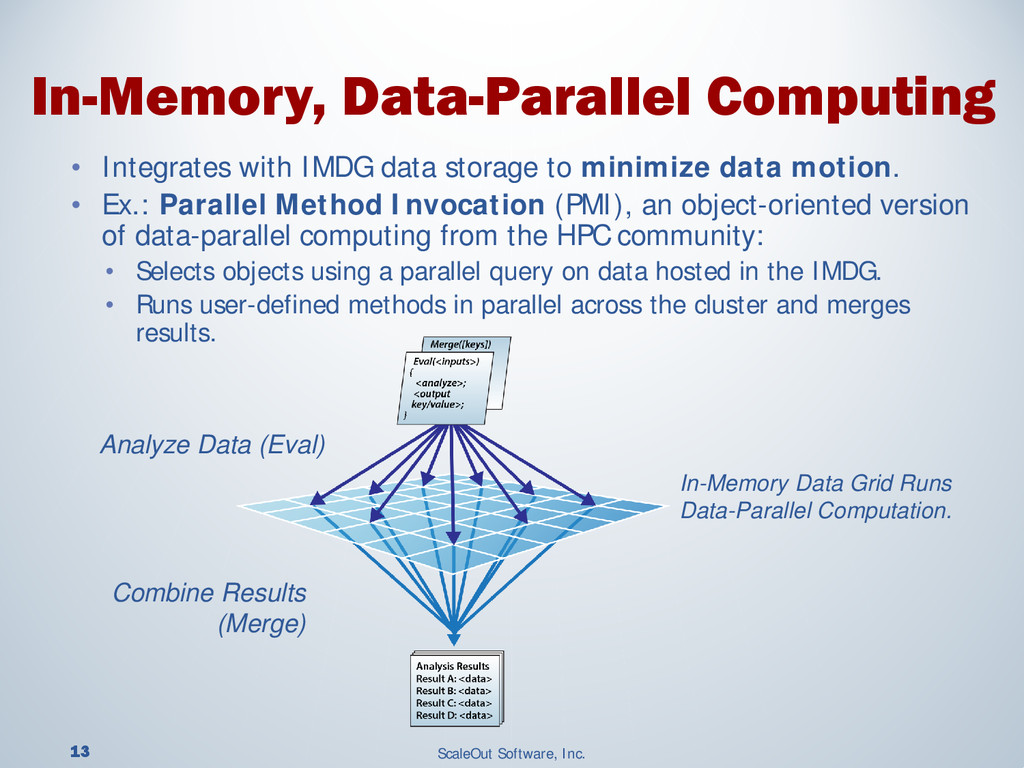{kind=link}
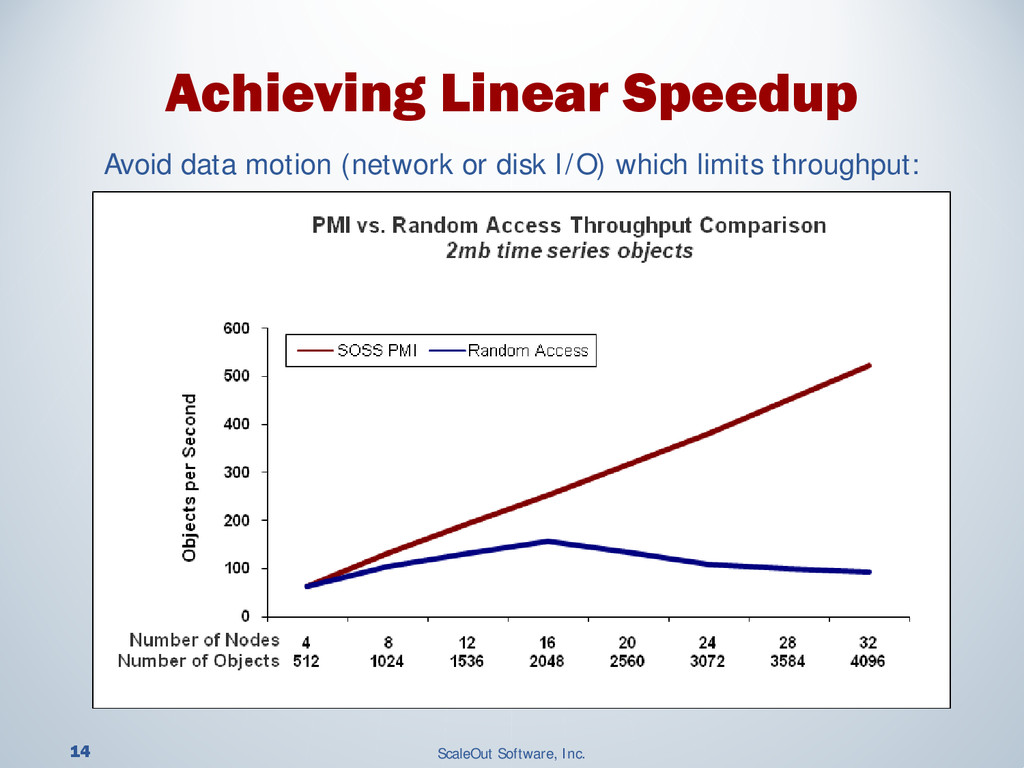{kind=link}
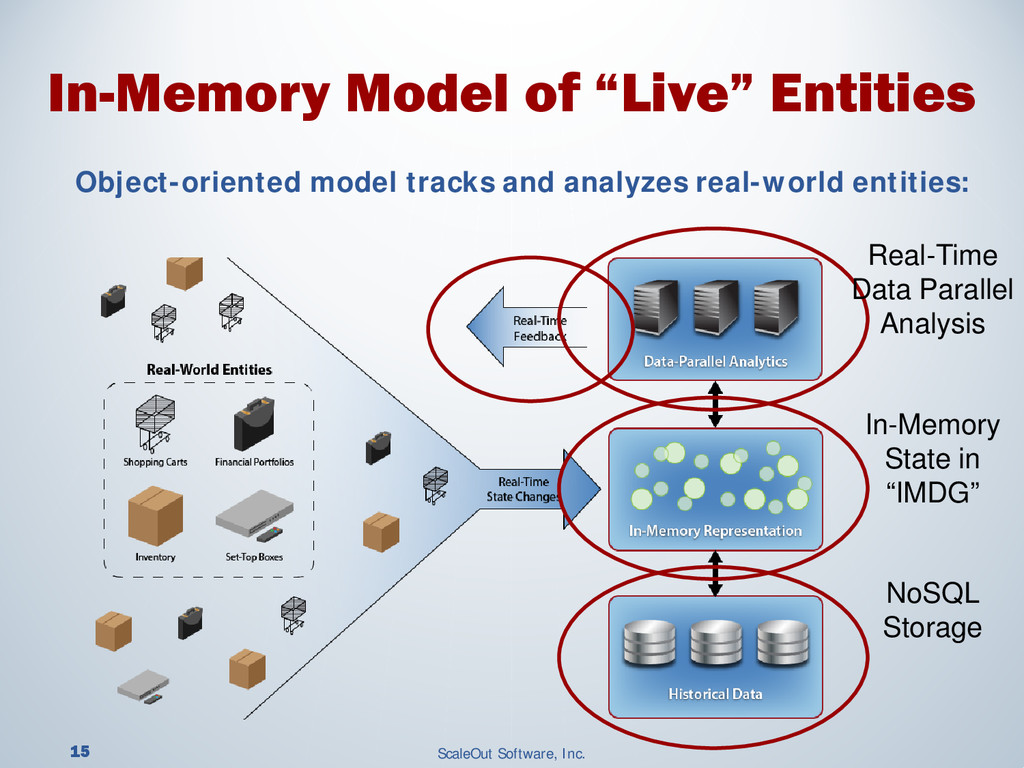{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
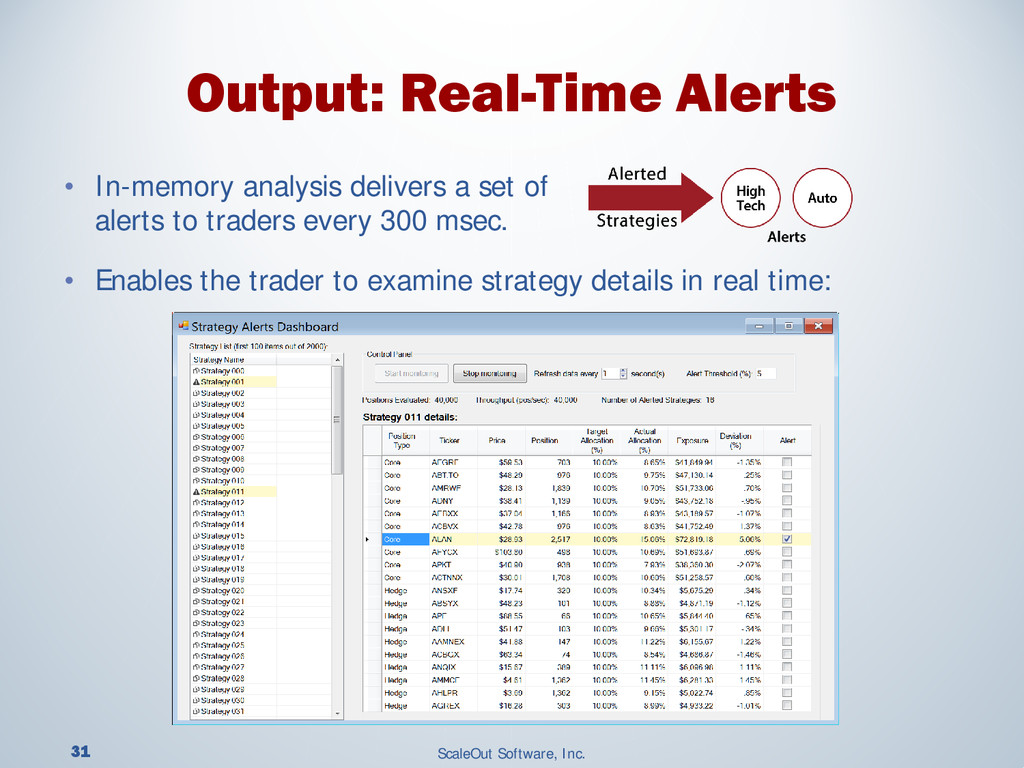{kind=link}
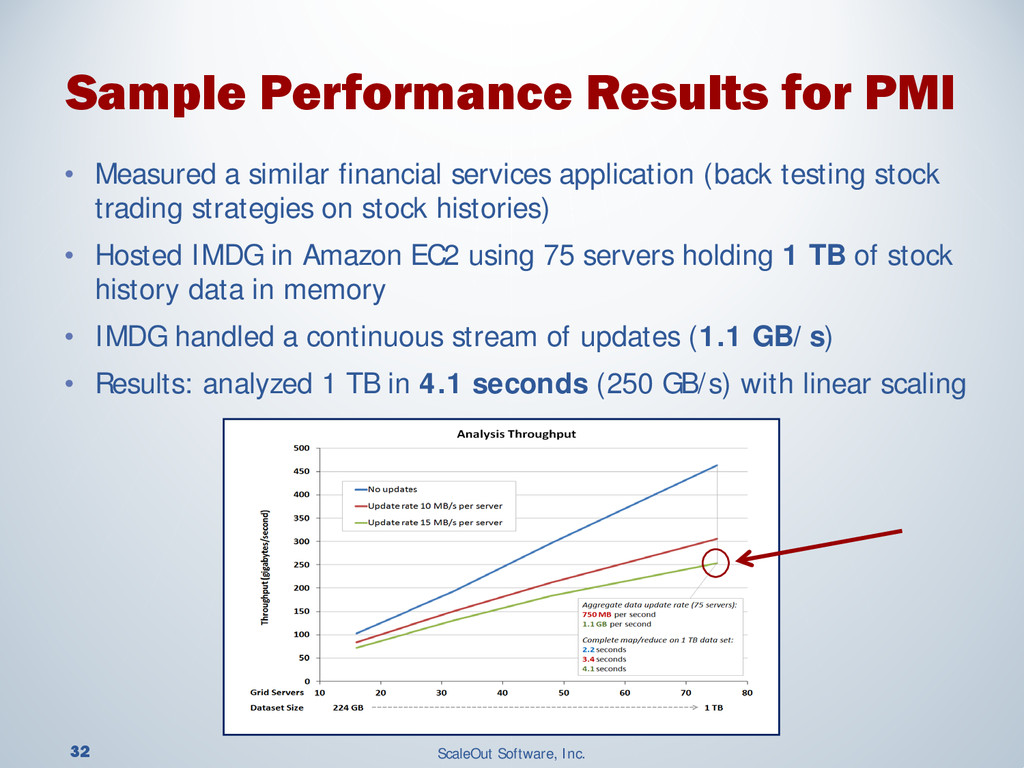{kind=link}
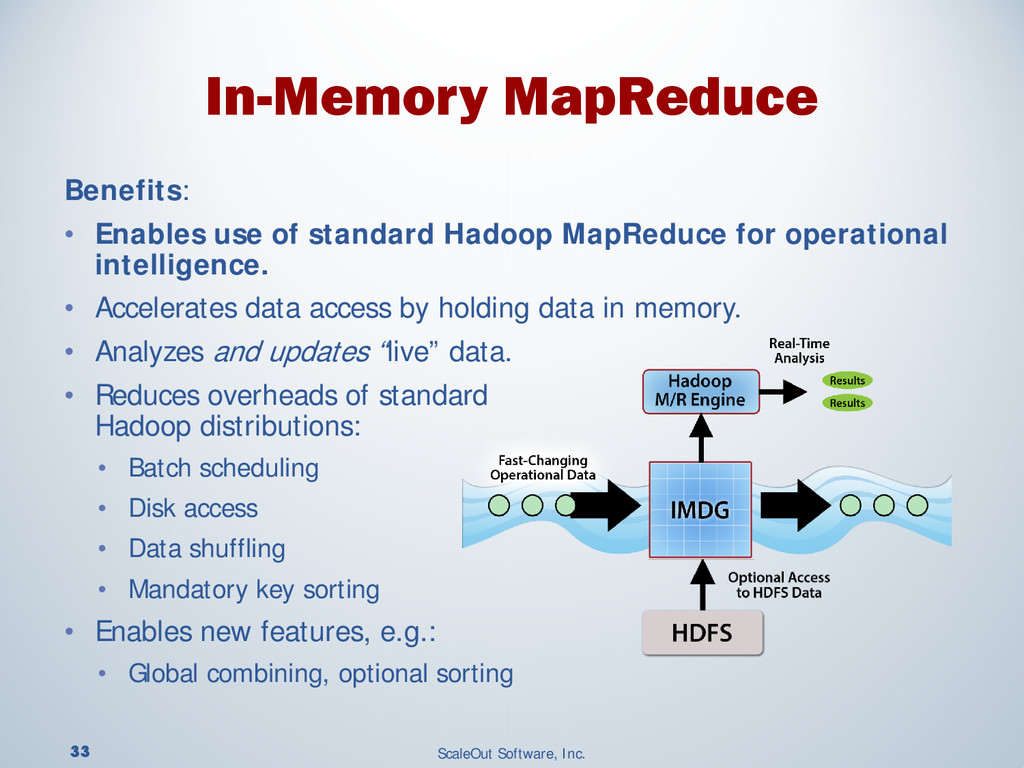{kind=link}
{kind=link}
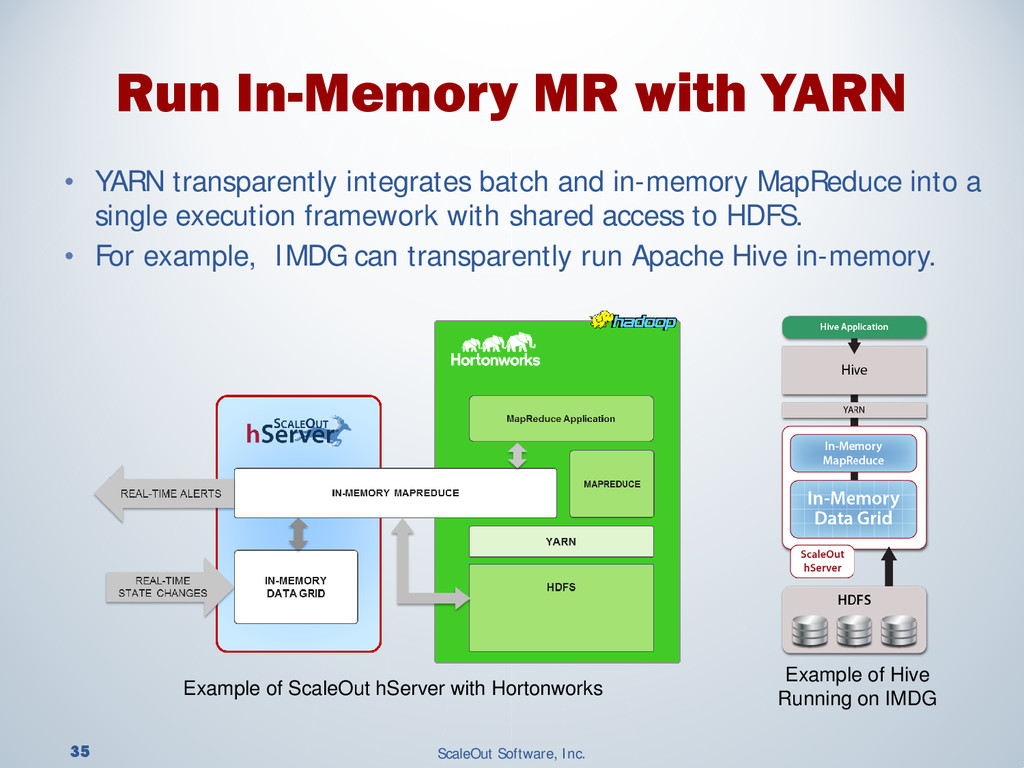{kind=link}
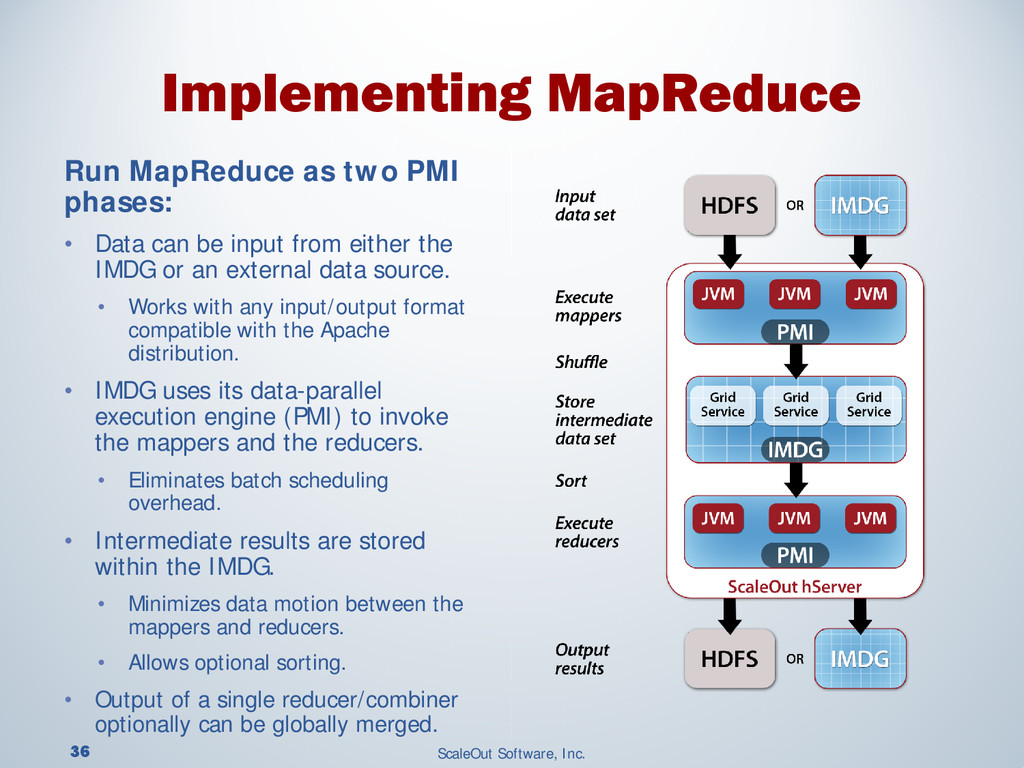{kind=link}
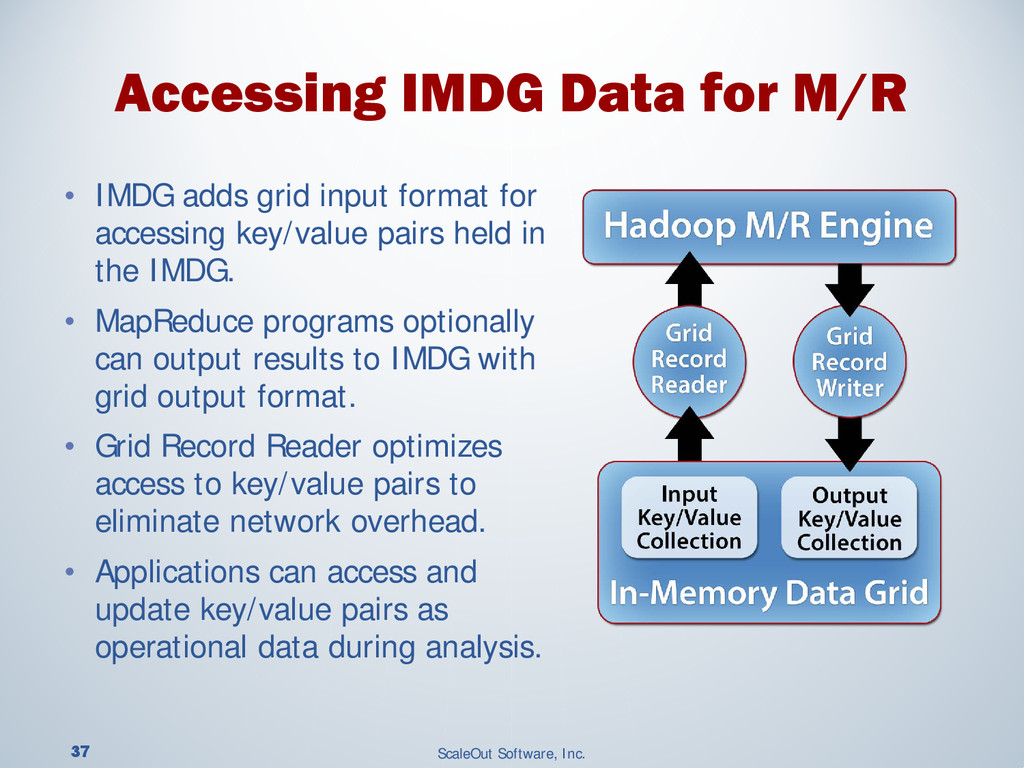{kind=link}
{kind=link}
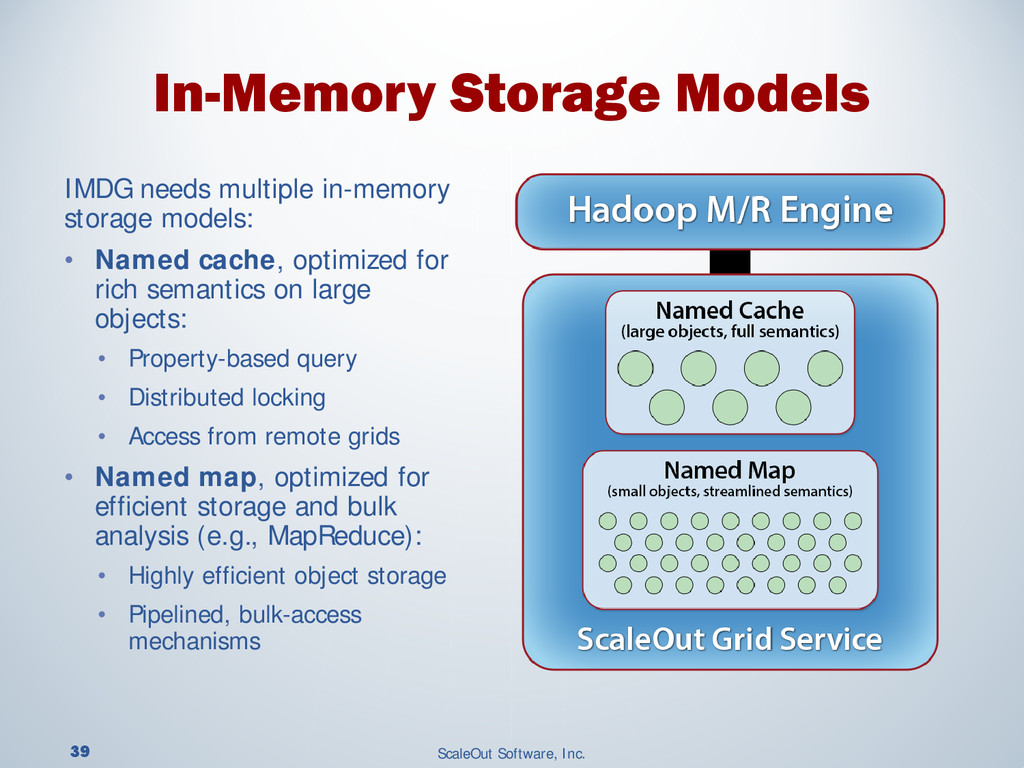{kind=link}
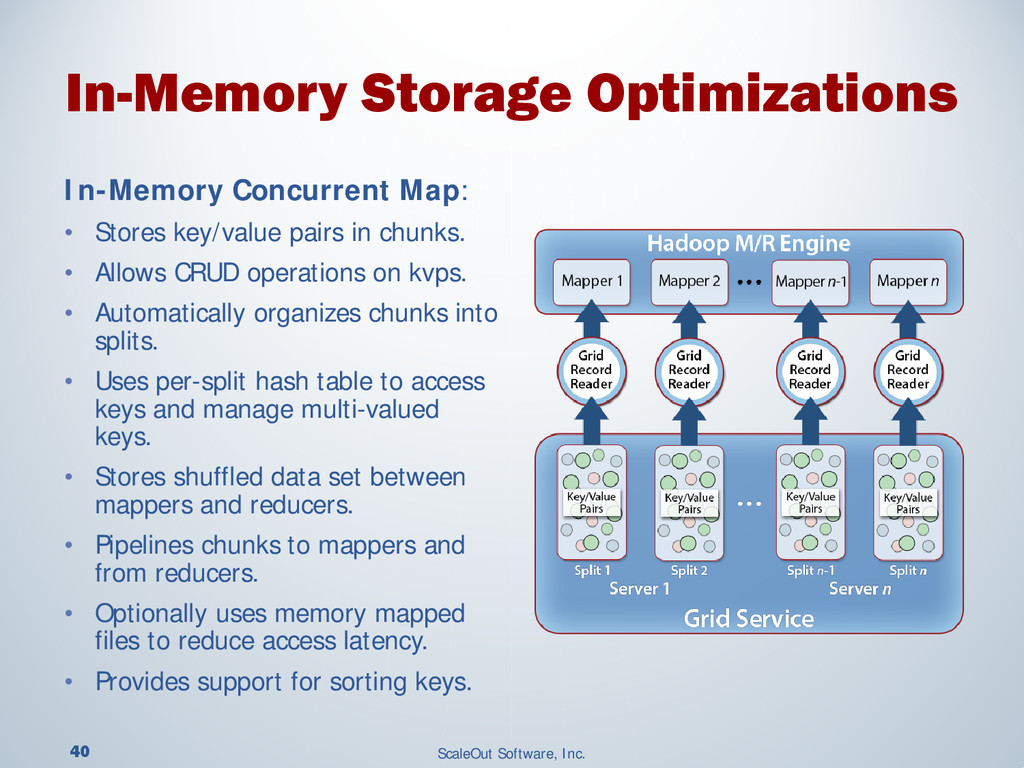{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}