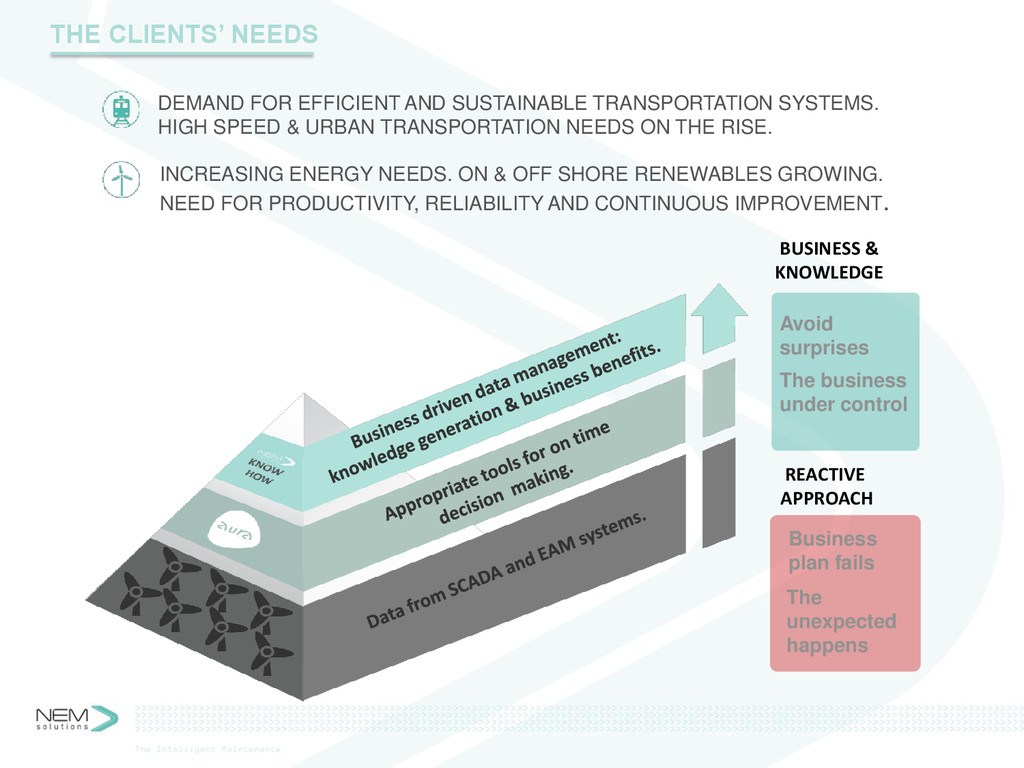
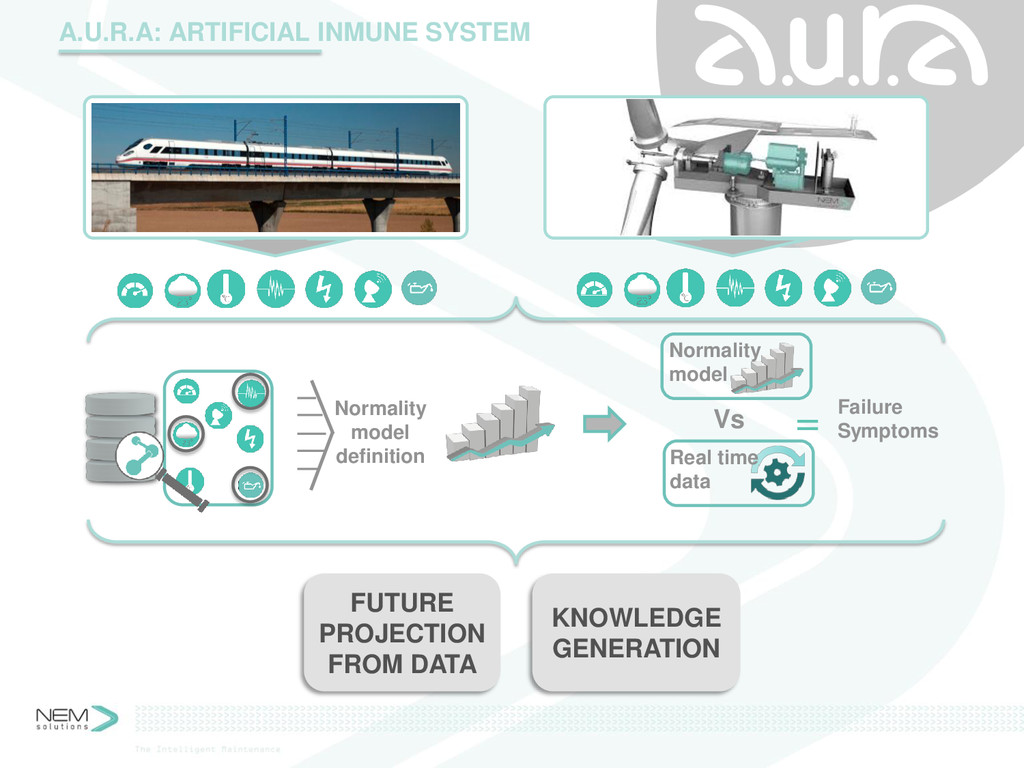
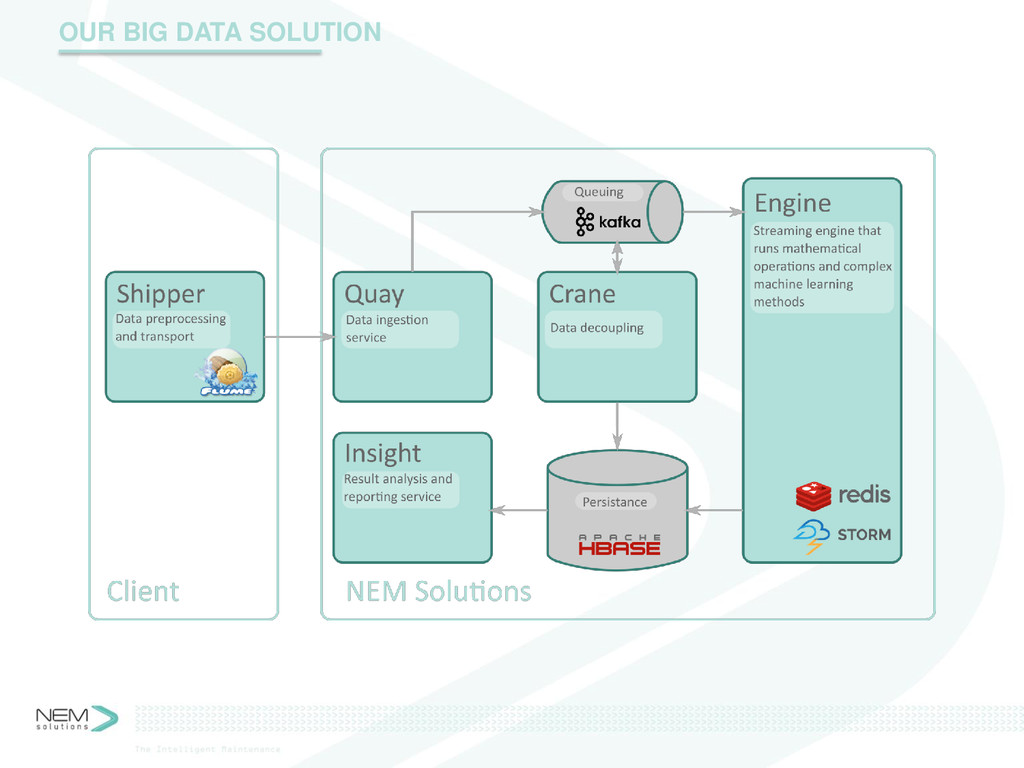
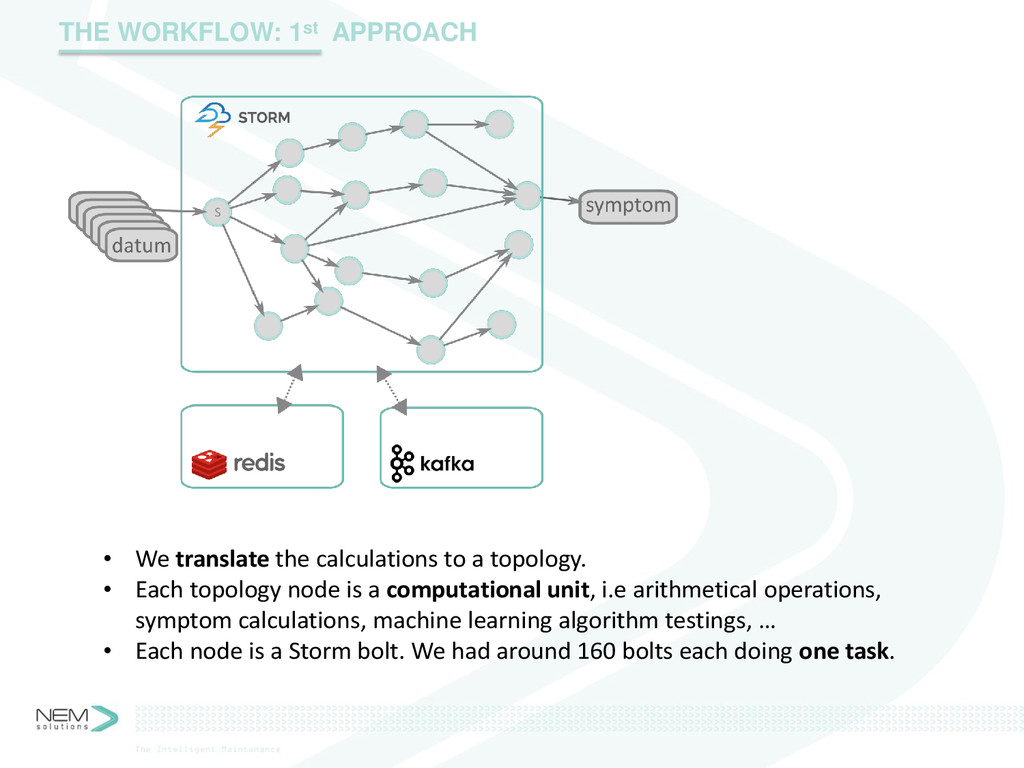
Complex machines, e.g. trains or wind turbines, require very solid maintenance procedures. Anticipating the wear of a piece or the failure of a system allows a sensitive maintenance scheduling and prevention of catastrophic failures. The race towards efficiency has enabled the spreading of sensors that collect huge data about the current state of the different components of said machines. Collecting and storing this data can be considered a solvable problem. However, all that data is of no use by itself. An optimal maintenance can derive from decisions that can derive from information that can derive from that big lake of data.
Session presented at Big Data Spain 2015 Conference
16th Oct 2015
Kinépolis Madrid
http://www.bigdataspain.org
Event promoted by: http://www.paradigmatecnologico.com
Abstract:http://www.bigdataspain.org/program/fri/slot-36.html#spch36.2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}