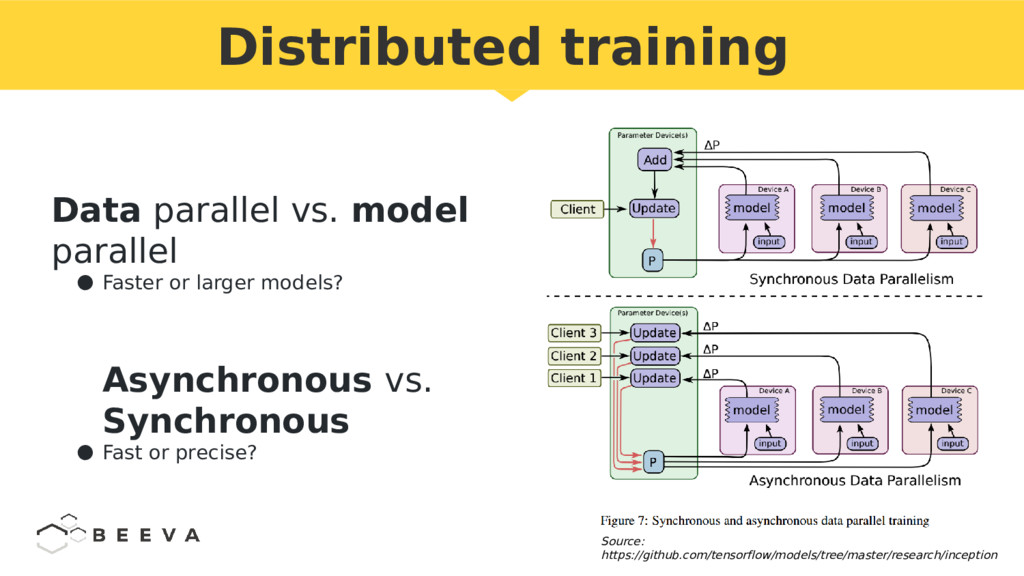
GPUs on the cloud as Infrastructure as a Service (IaaS) seem a commodity. However to efficiently distribute deep learning tasks on several GPUs is challenging.
https://www.bigdataspain.org/2017/talk/training-deep-learning-models-on-multiple-gpus-in-the-cloud
Big Data Spain 2017
November 16th - 17th Kinépolis Madrid
{kind=link}
{kind=link}
![ENRIQUE OTERO [email protected] @beevalabs_eom Data Scientist in BEEVA [email protected] |](https://files.speakerdeck.com/presentations/aa4b26562de64b13ae5a2d5c5a03a895/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
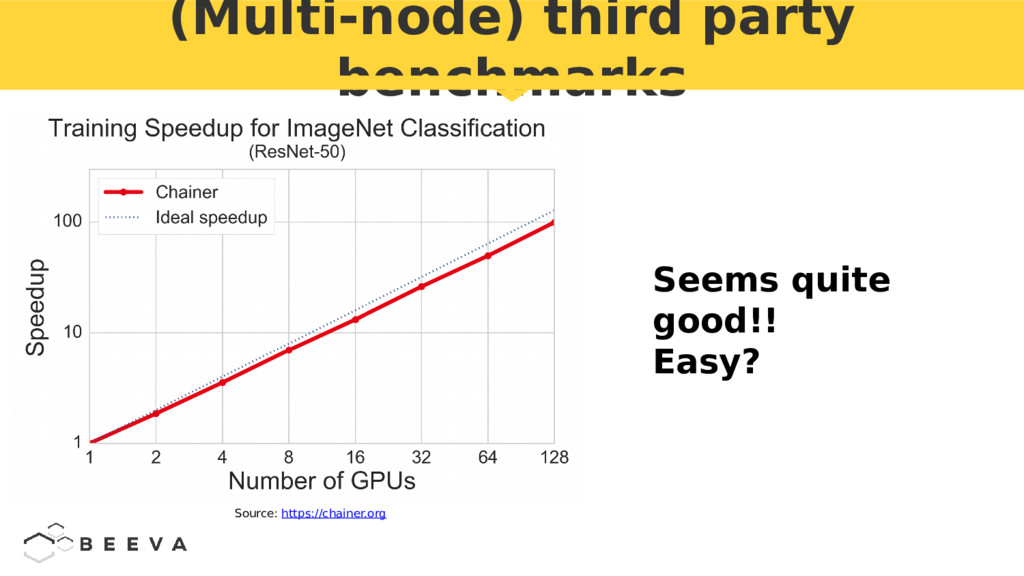{kind=link}
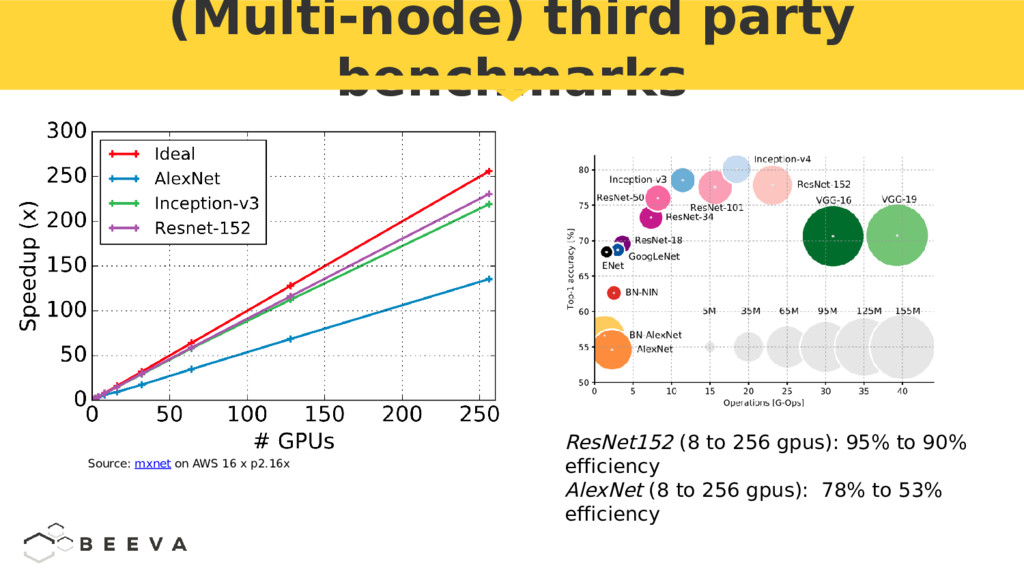{kind=link}
{kind=link}
{kind=link}
{kind=link}
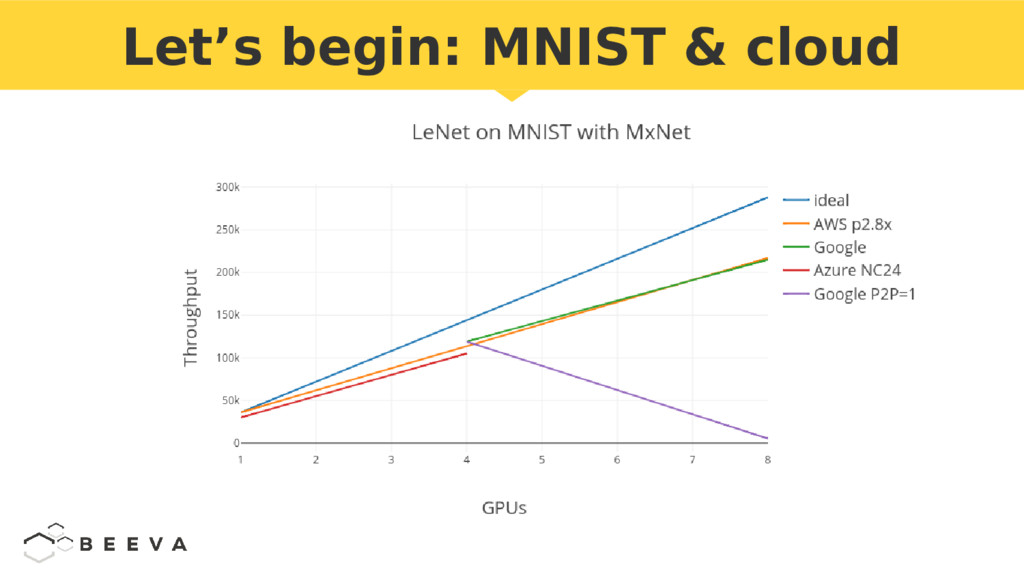{kind=link}
{kind=link}
{kind=link}
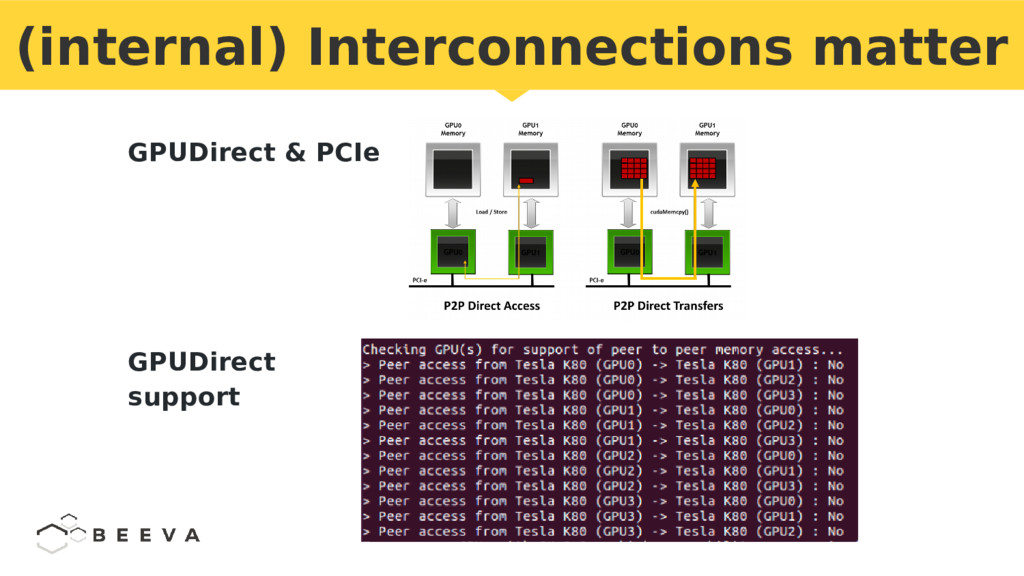{kind=link}
{kind=link}
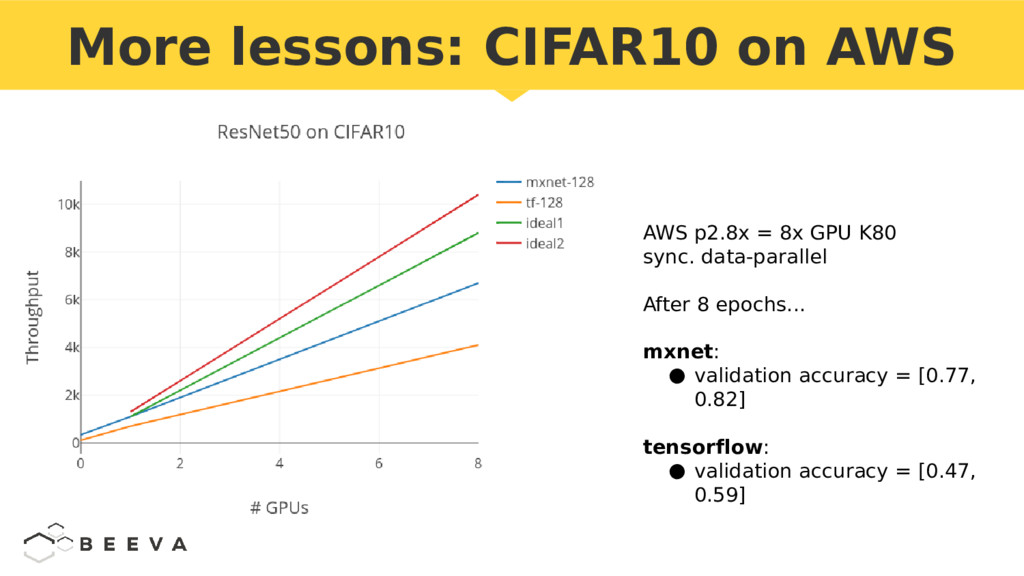
{kind=link}
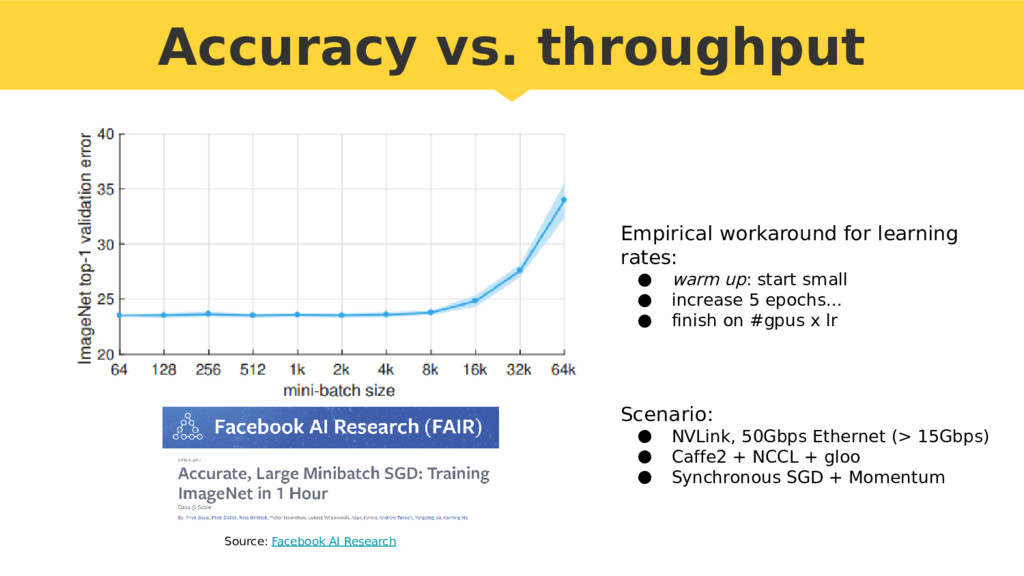
{kind=link}
{kind=link}
{kind=link}
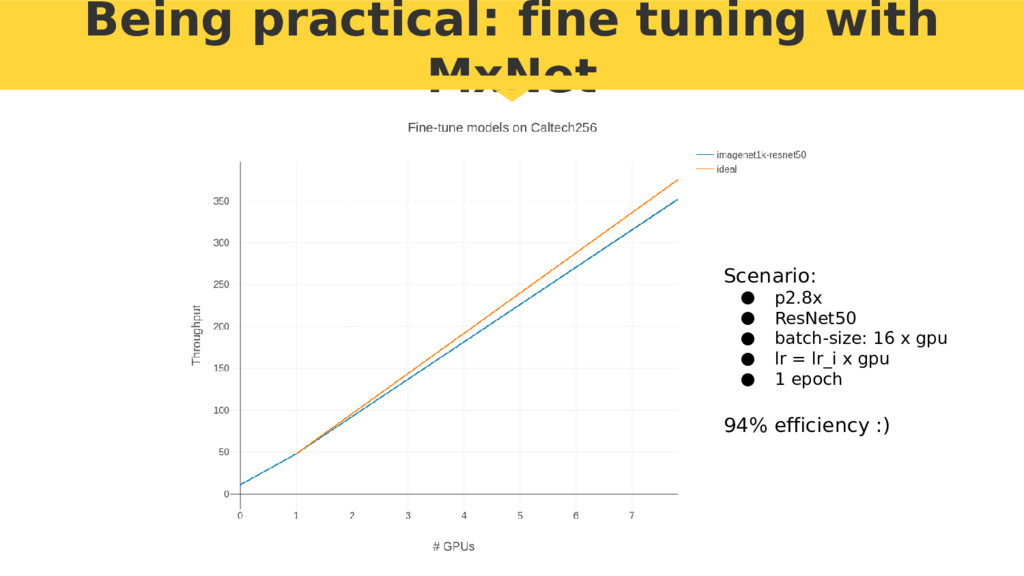
{kind=link}
{kind=link}
{kind=link}
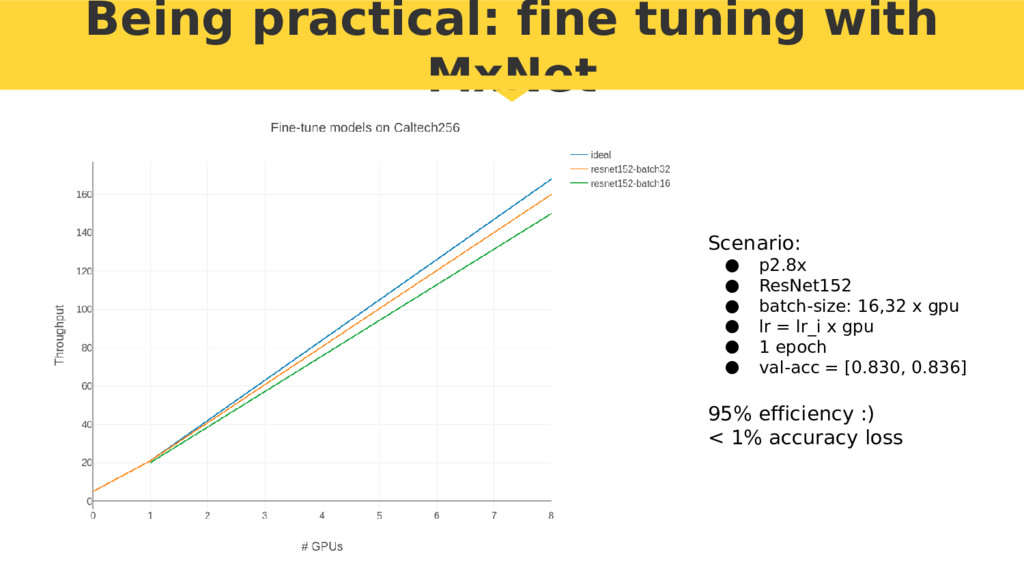{kind=link}
{kind=link}
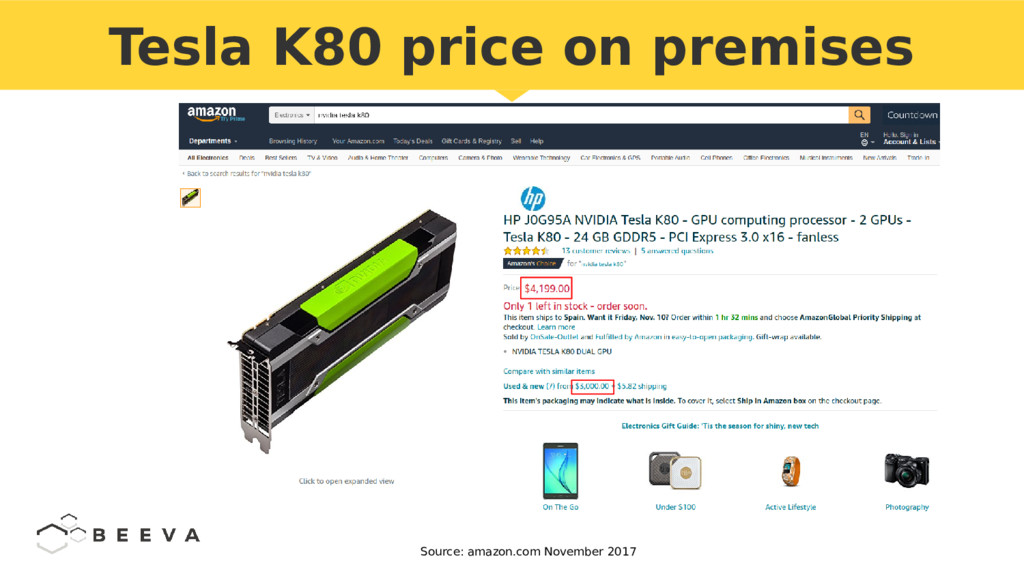{kind=link}
{kind=link}
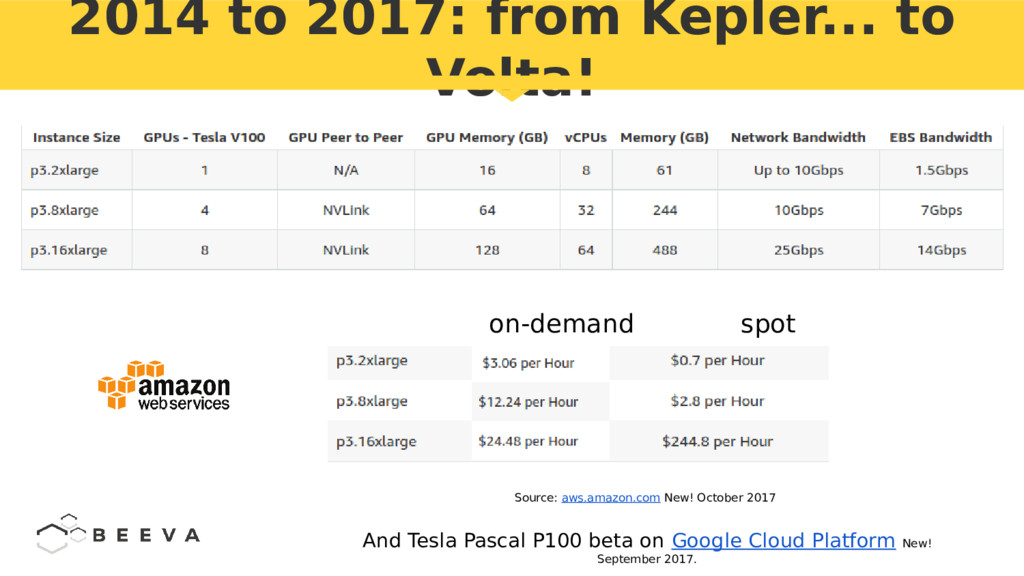{kind=link}
{kind=link}
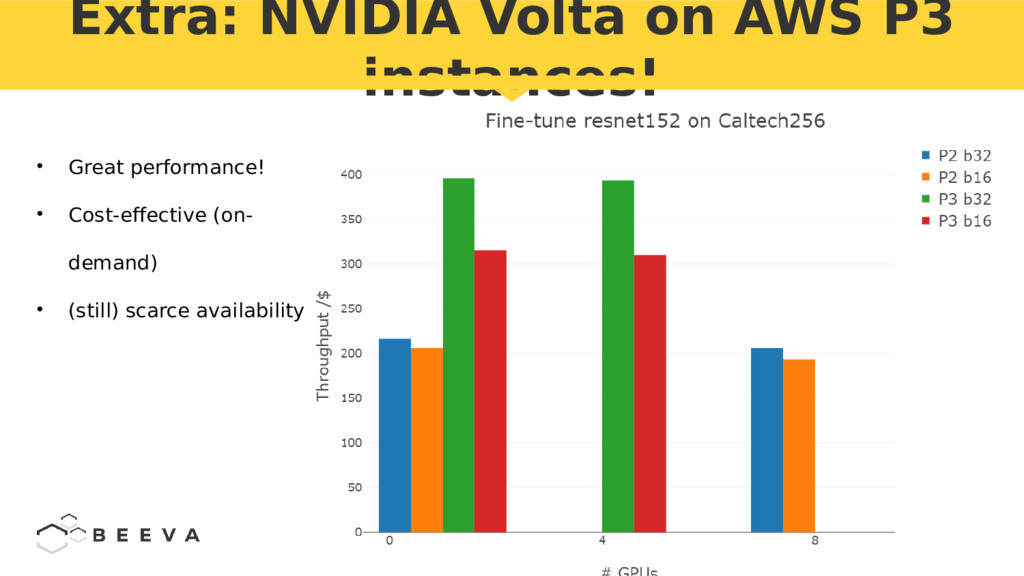{kind=link}
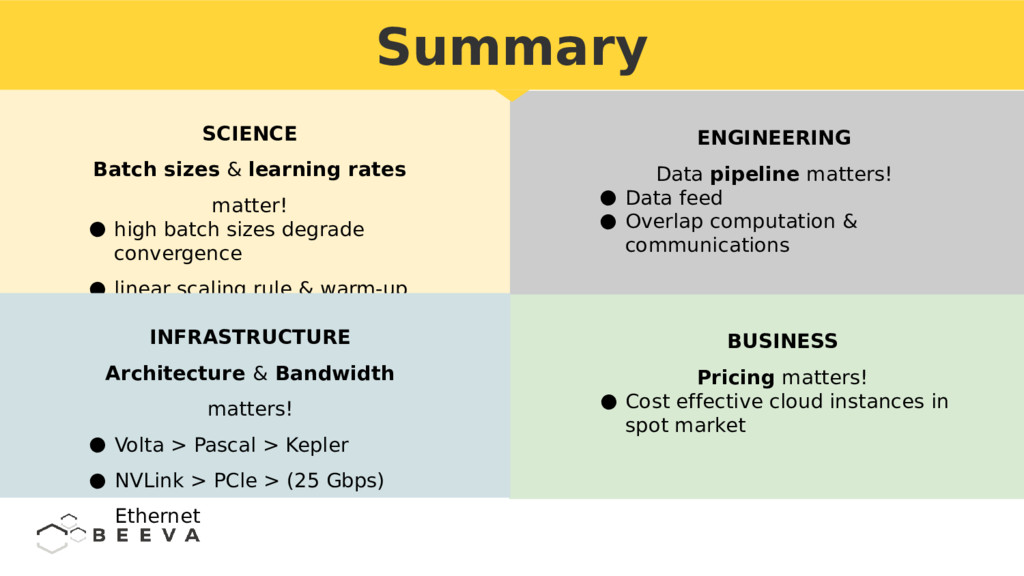{kind=link}
![THANKS FOR YOUR TIME [email protected] | www.beeva.com And we’re hiring!](https://files.speakerdeck.com/presentations/aa4b26562de64b13ae5a2d5c5a03a895/slide_37.jpg){kind=link}