CoRL 2025 Overview — p. 4-8 What is CoRL / Participation scale & acceptance / Industry exhibitions 3. Awards Summary — p. 9-10 Best Paper / Best Student Paper 4. Research Trends — p. 11-13 VLA / Real2Sim2Real / Tactile sensing & Manipulation 5. Conclusion & Acknowledgements — p. 14-15 6. Paper Survey (Highlights) — p. 16-107 VLA / Real2Sim2Real / Dexterous Manipulation / Locomotion / Evaluation, Reward, and Reasoning
and research trends from CoRL 2025. ◦ Provide an overview of selected papers — highlighting and summarizing notable works in robot learning. • Author ◦ Haruki Abe – M2, Harada-Kurose-Mukuta Lab. ◦ Research Focus: Reinforcement Learning • Notes ◦ Unless otherwise noted, figures and images were used based on materials from the papers, posters, or publicly available videos discussed in this slide deck.
Learning) is one of the top-tier international conferences in the field of robot learning. • The 9th edition was held in Seoul, South Korea. • Like many other machine learning conferences, CoRL also includes a rebuttal phase.
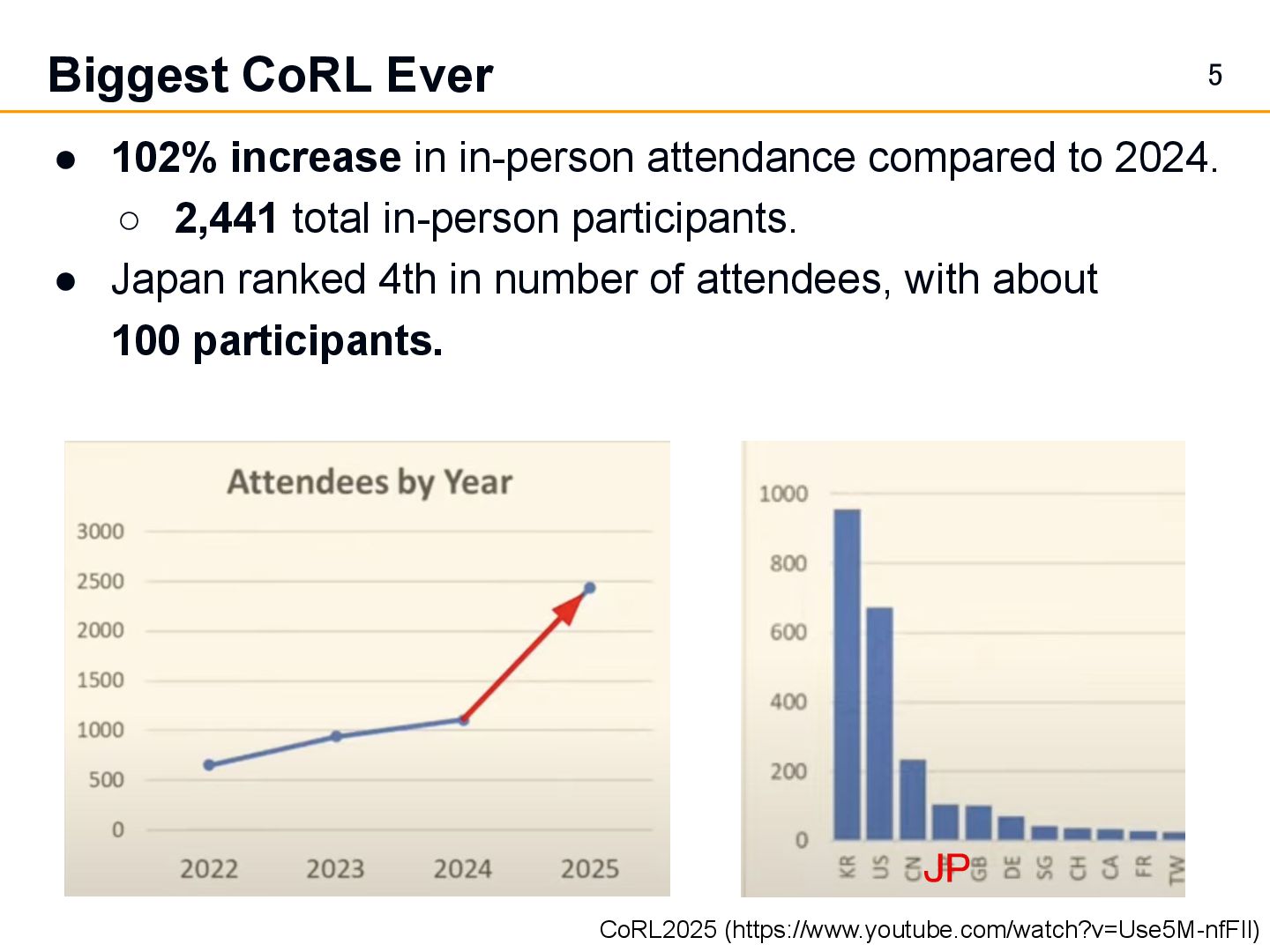
compared to 2024. ◦ 2,441 total in-person participants. • Japan ranked 4th in number of attendees, with about 100 participants. JP CoRL2025 (https://www.youtube.com/watch?v=Use5M-nfFlI)
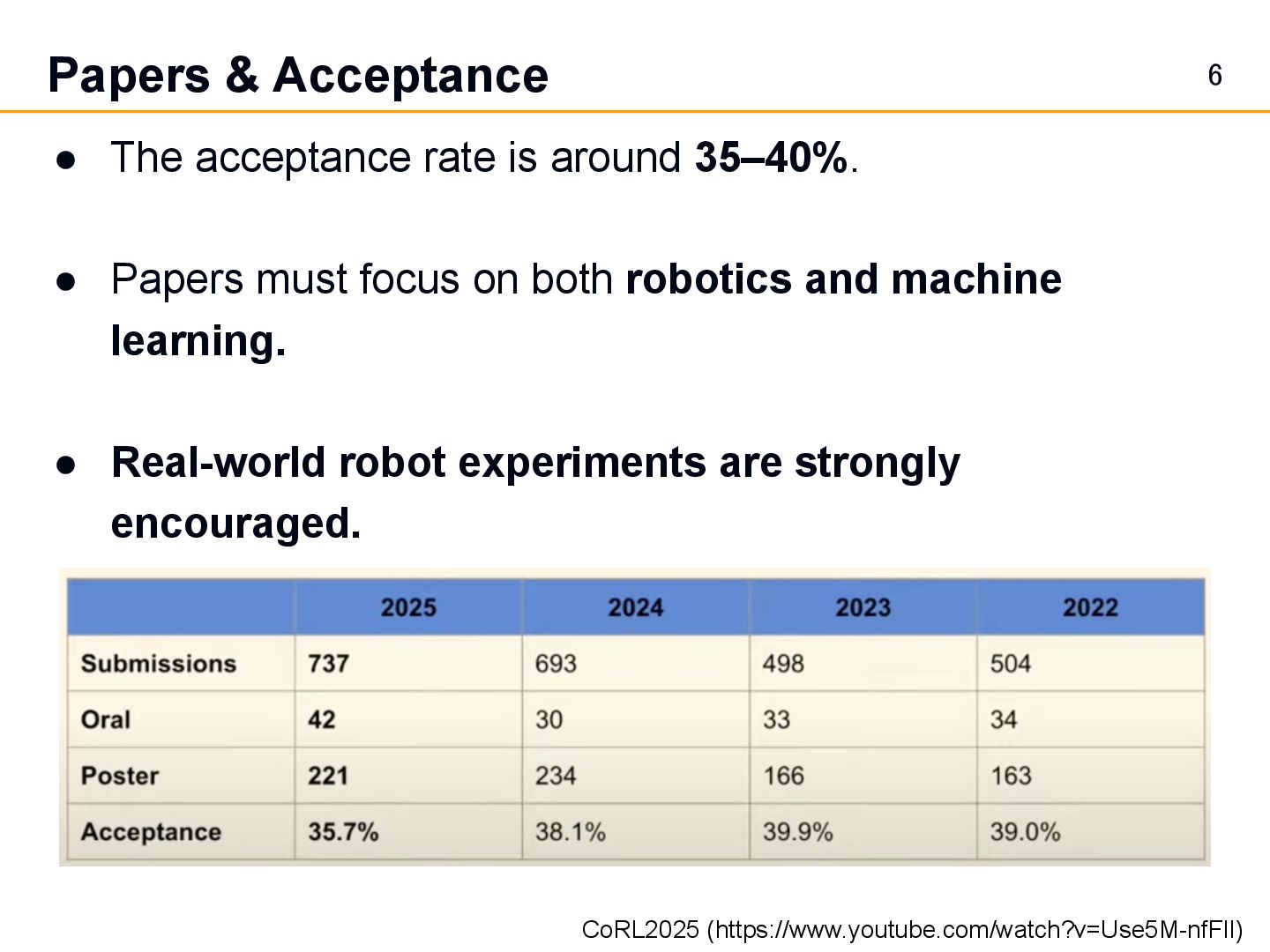
35–40%. • Papers must focus on both robotics and machine learning. • Real-world robot experiments are strongly encouraged. CoRL2025 (https://www.youtube.com/watch?v=Use5M-nfFlI)
their work at CoRL. • Companies often announce new models for CoRL. ◦ Last year: Physical Intelligence — π0 ◦ This year: Google DeepMind — Gemini Robotics 1.5 This Gemini Robotics 1.5 is controlled by the operator through natural language instructions. Gemini Robotics π0: A Vision-Language-Action Flow Model for General Robot Control (Kevin et al. 2025) Gemini Robotics 1.5 (https://deepmind.google/models/gemini-robotics/gemini-robotics/)
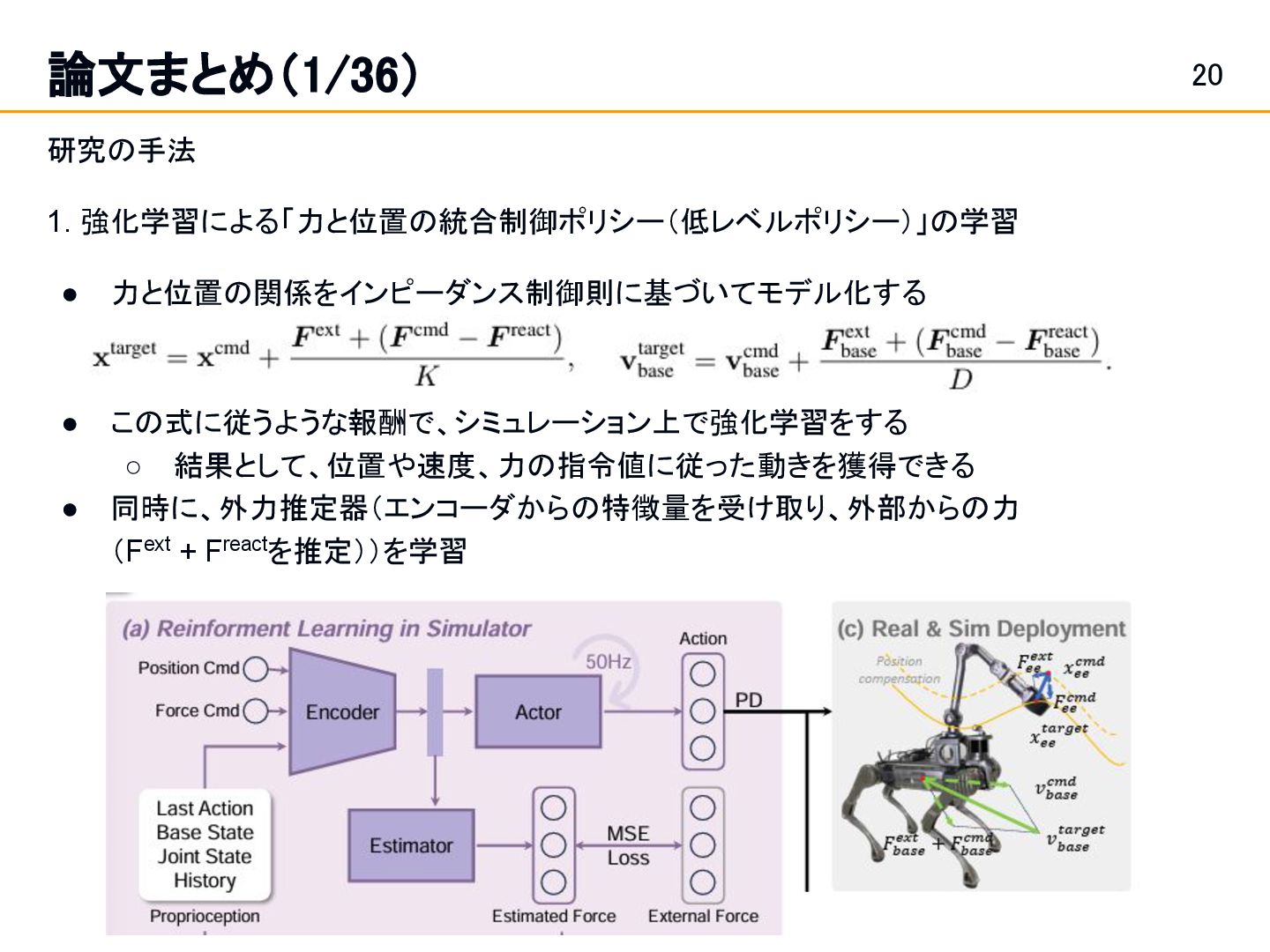
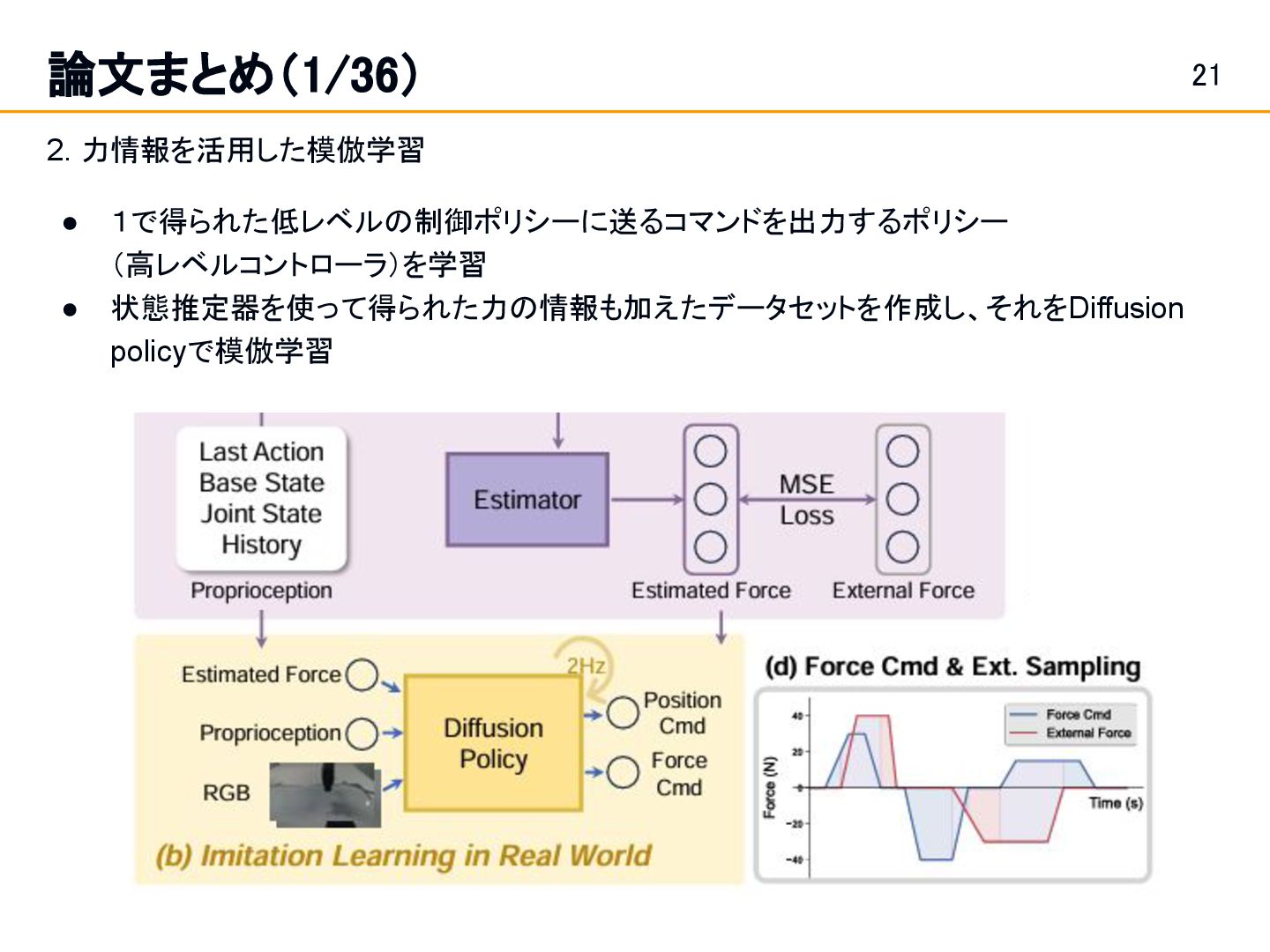
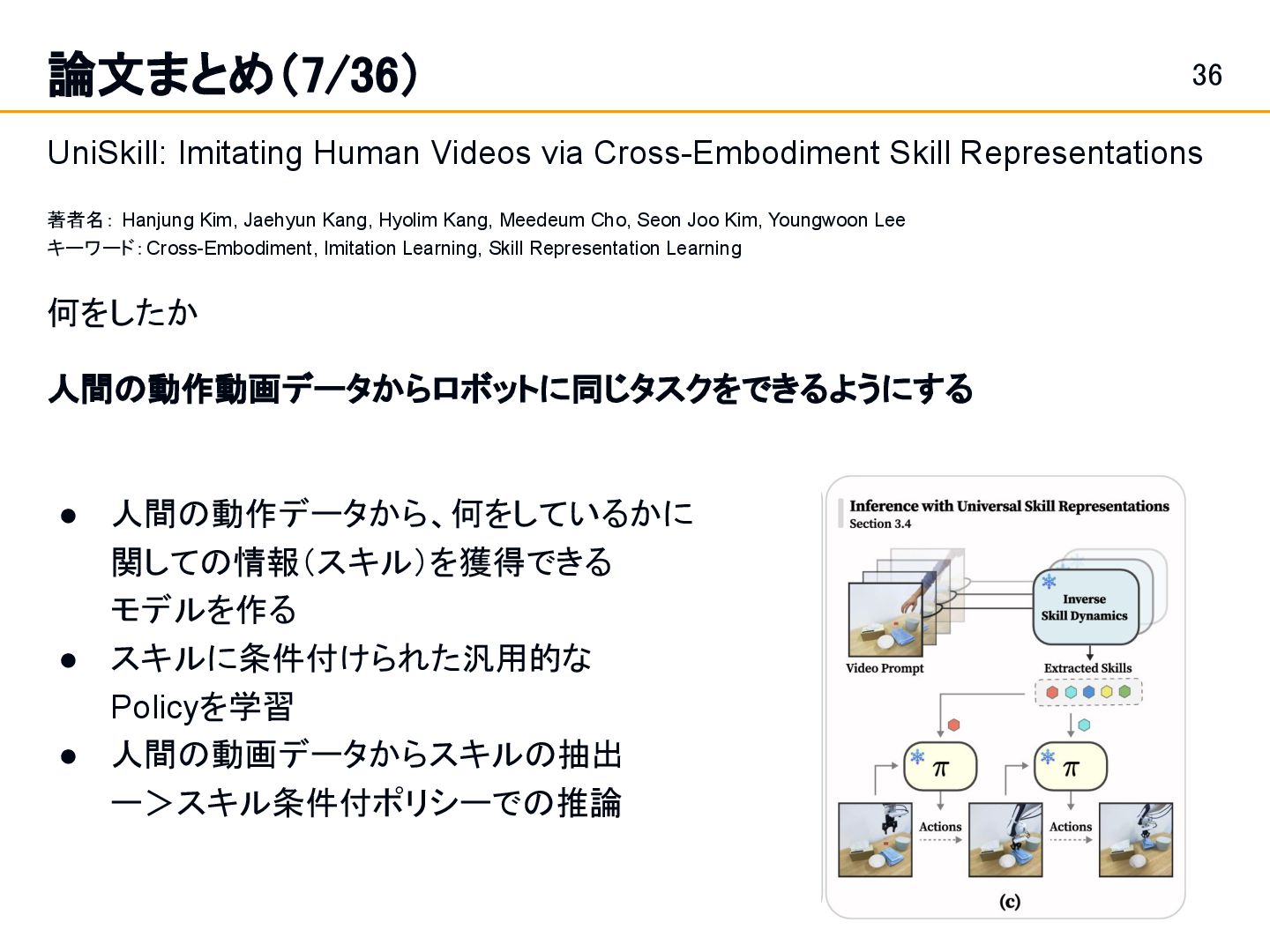
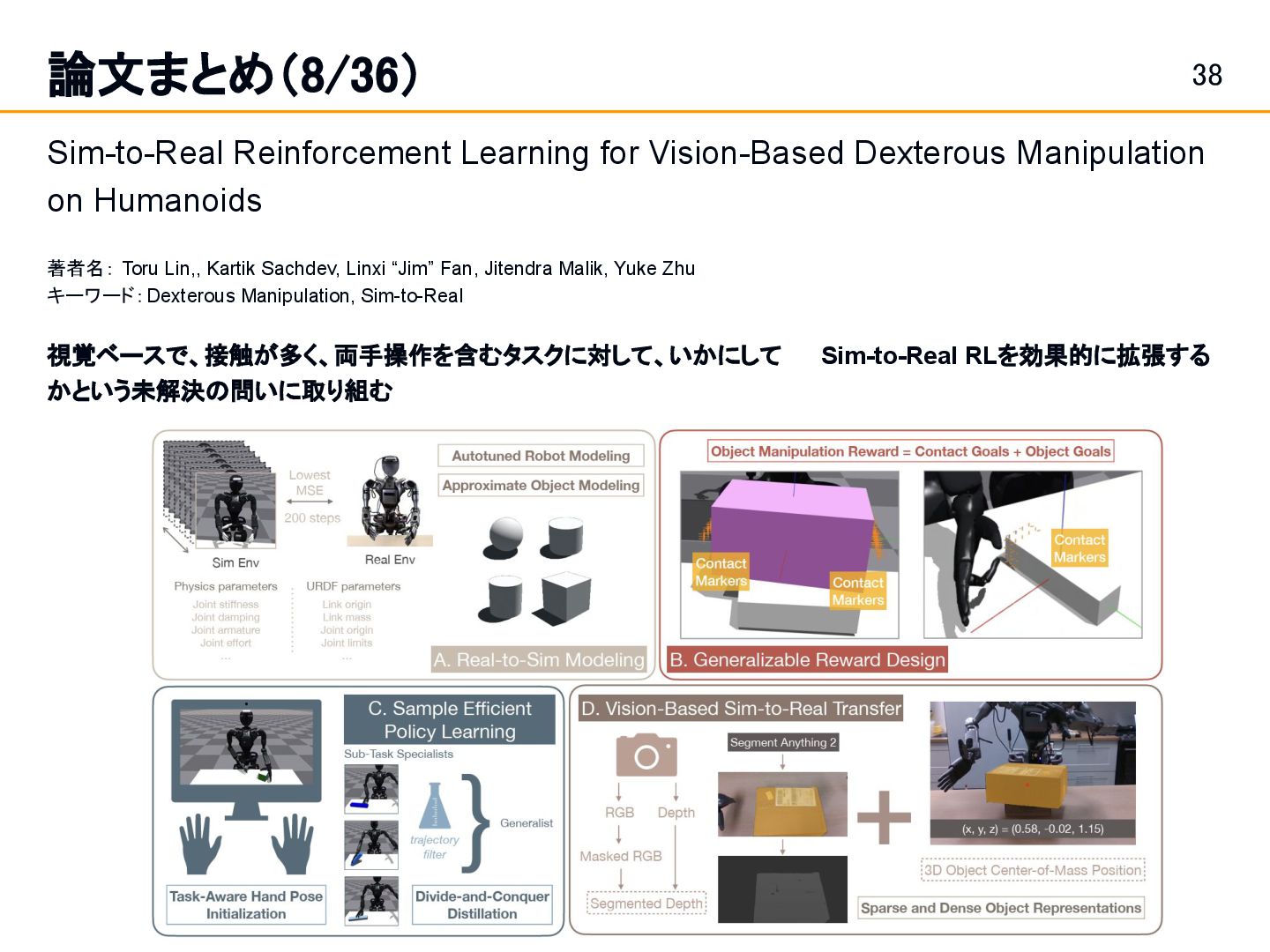
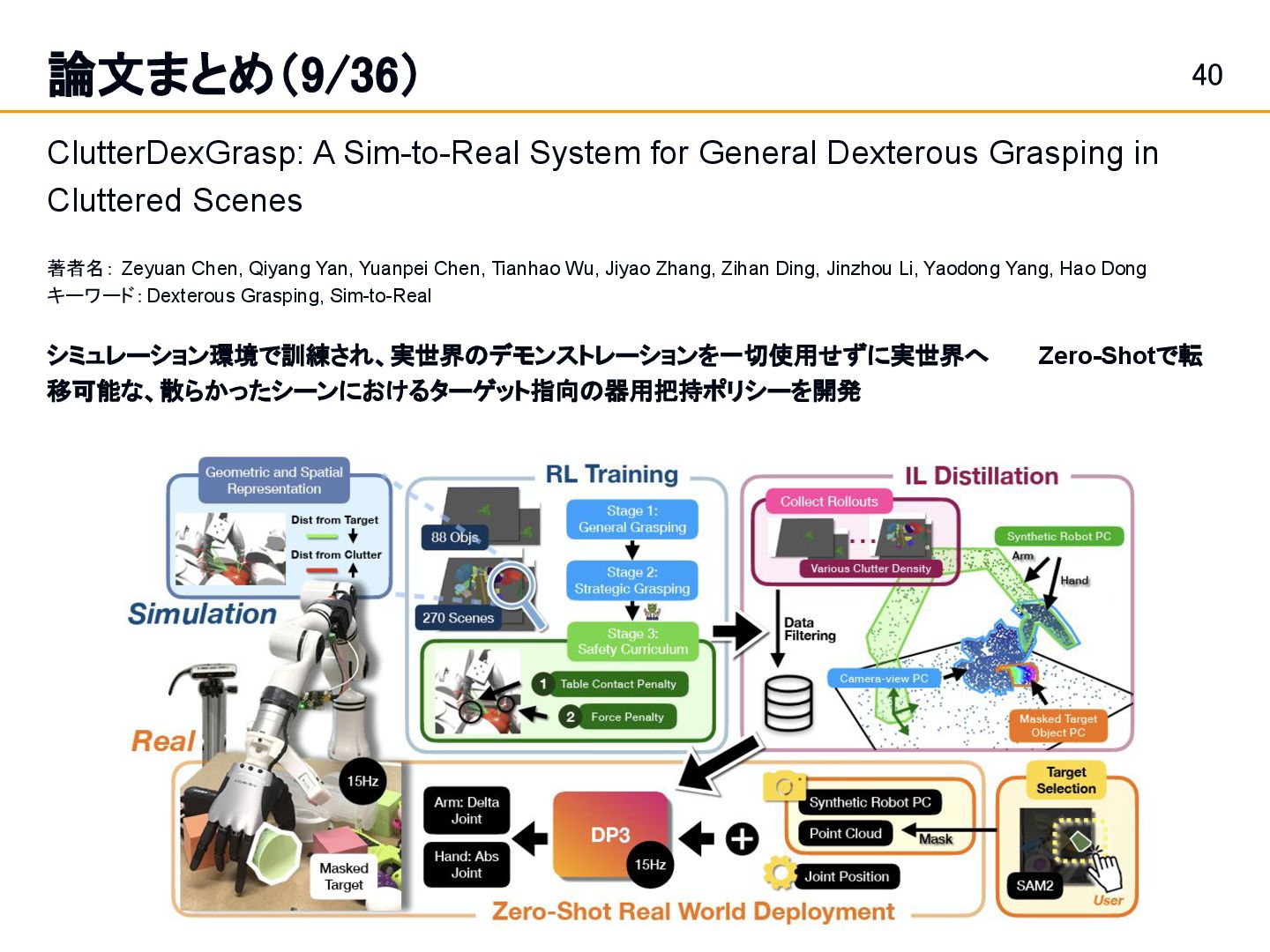
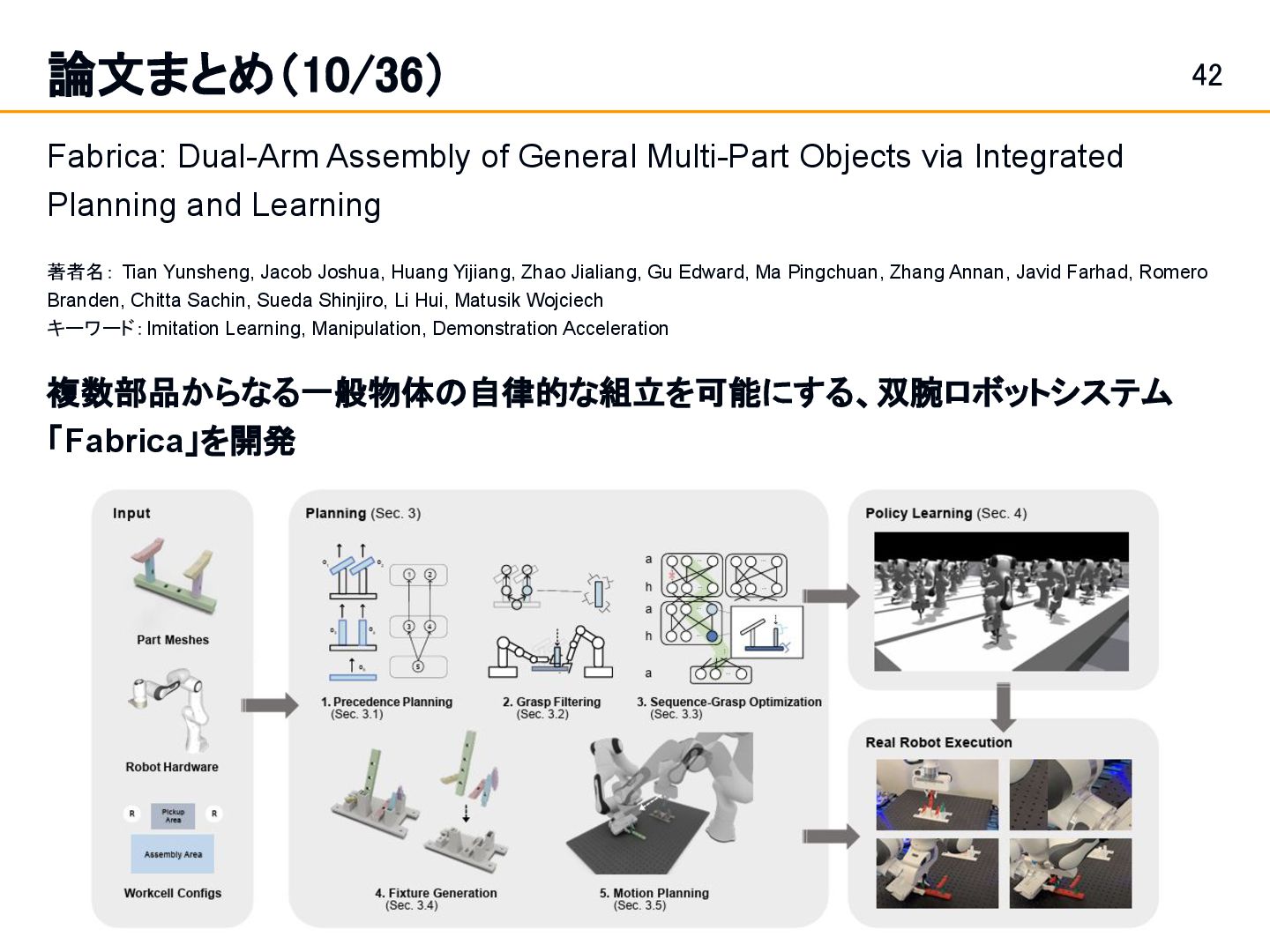
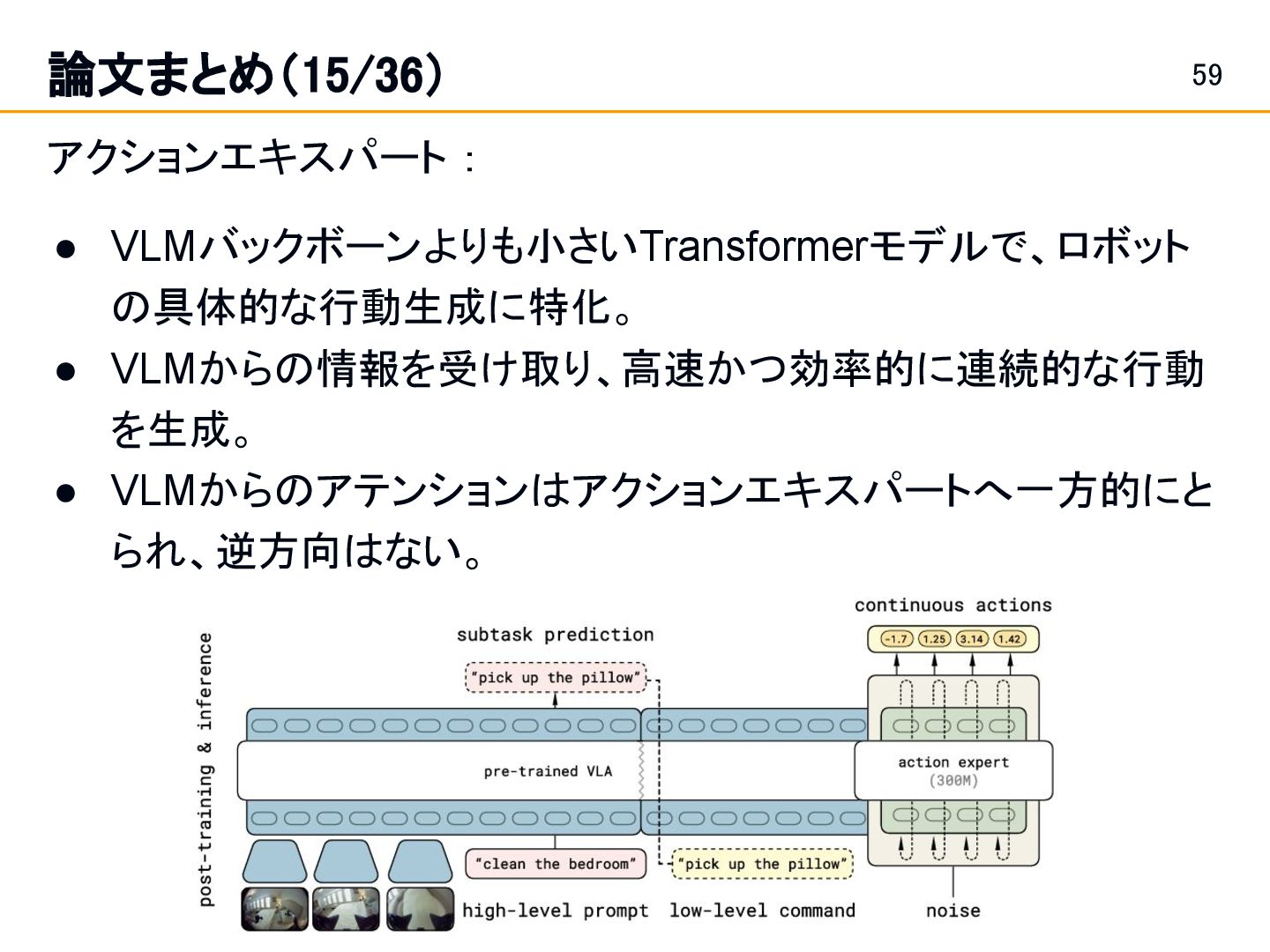
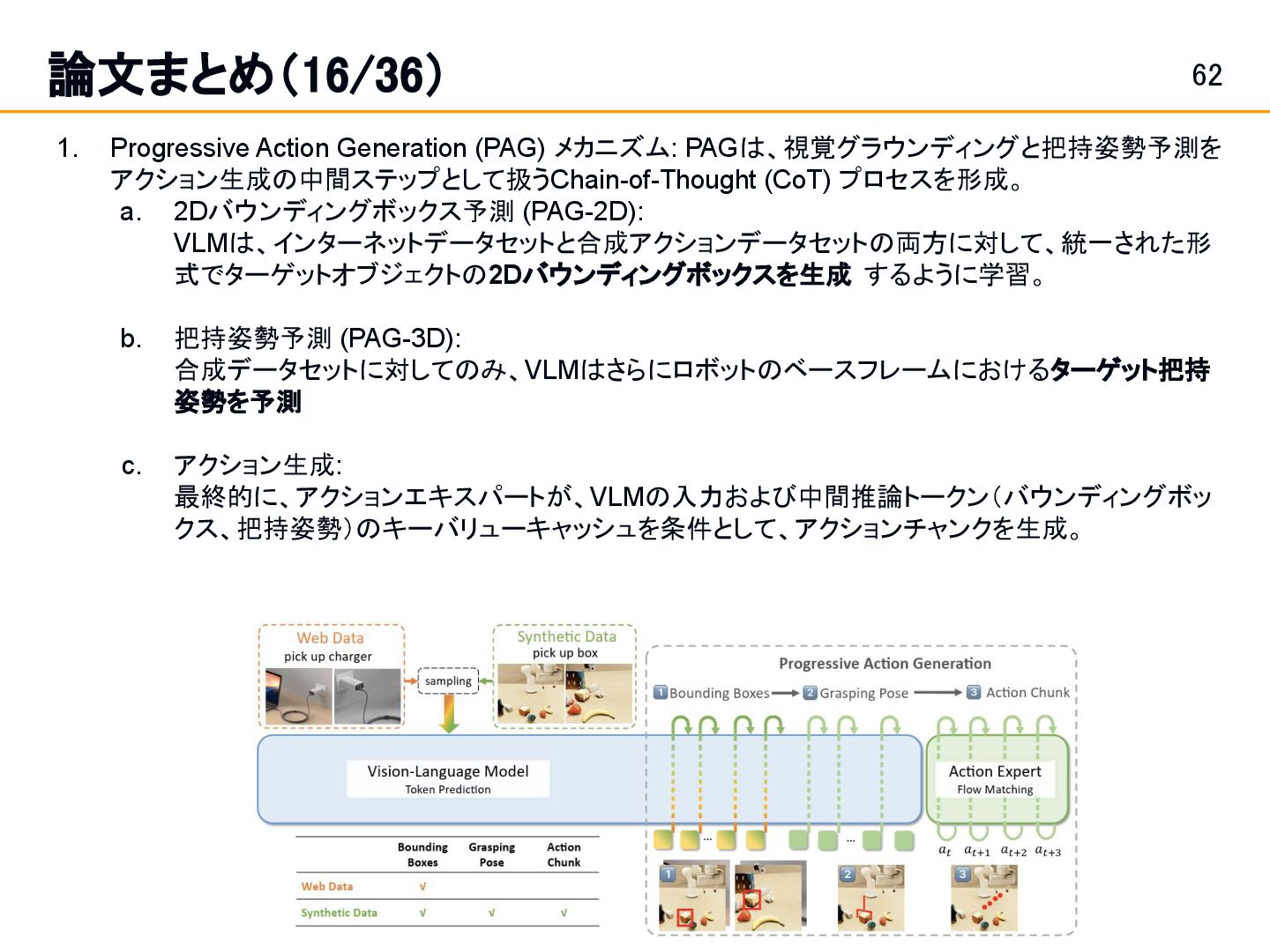
Position and Force Control in Legged Loco-Manipulation [Zhi et al.]スライド 19: 論文まとめ(1/36) Fabrica: Dual-Arm Assembly of General Multi-Part Objects via Integrated Planning and Learning [Tian et al.] スライド 42: 論文まとめ(10/36) • Learning a single integrated policy for both force and position control — without using force sensors. • Developed Fabrica, a dual-arm robotic system that enables autonomous assembly of general objects composed of multiple parts.
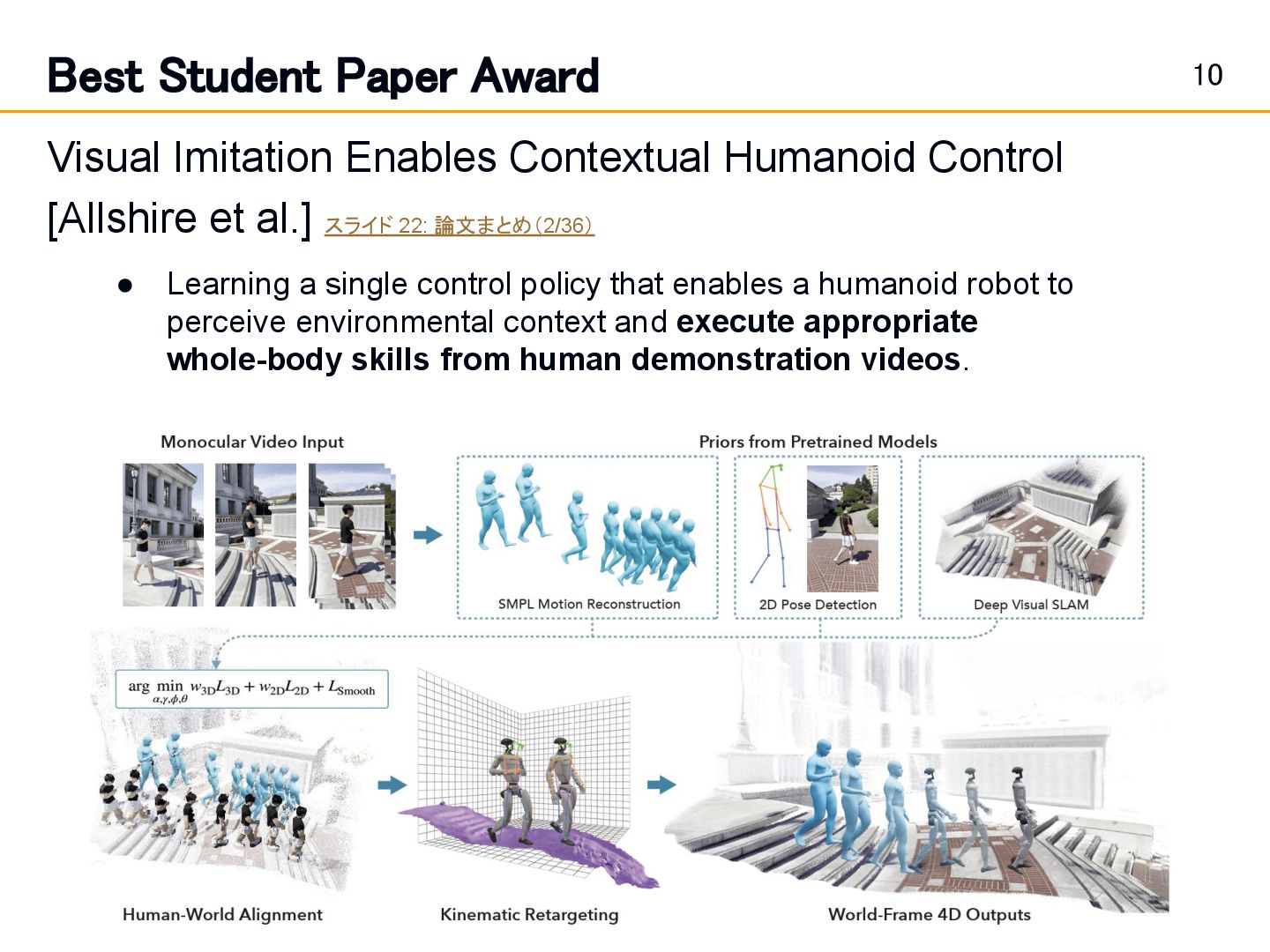
Humanoid Control [Allshire et al.] スライド 22: 論文まとめ(2/36) • Learning a single control policy that enables a humanoid robot to perceive environmental context and execute appropriate whole-body skills from human demonstration videos.
Robot foundation model — learning diverse skills with a single policy. • example: π0.5 [Black et al.], GraspVLA [Deng et al.], DexVLA [Wen et al.], ControlVLA [Li et al.], Long-VLA [Fan et al.], TrackVLA [Wang et al.], 3DS-VLA [Li et al.], Endo-VLA [Ng et al.], RICL [Sridhar et al.], RoboMonkey [Kwok et al.], RoboArena [Atreya et al.] etc. pi0.5 RoboArena GraspVLA
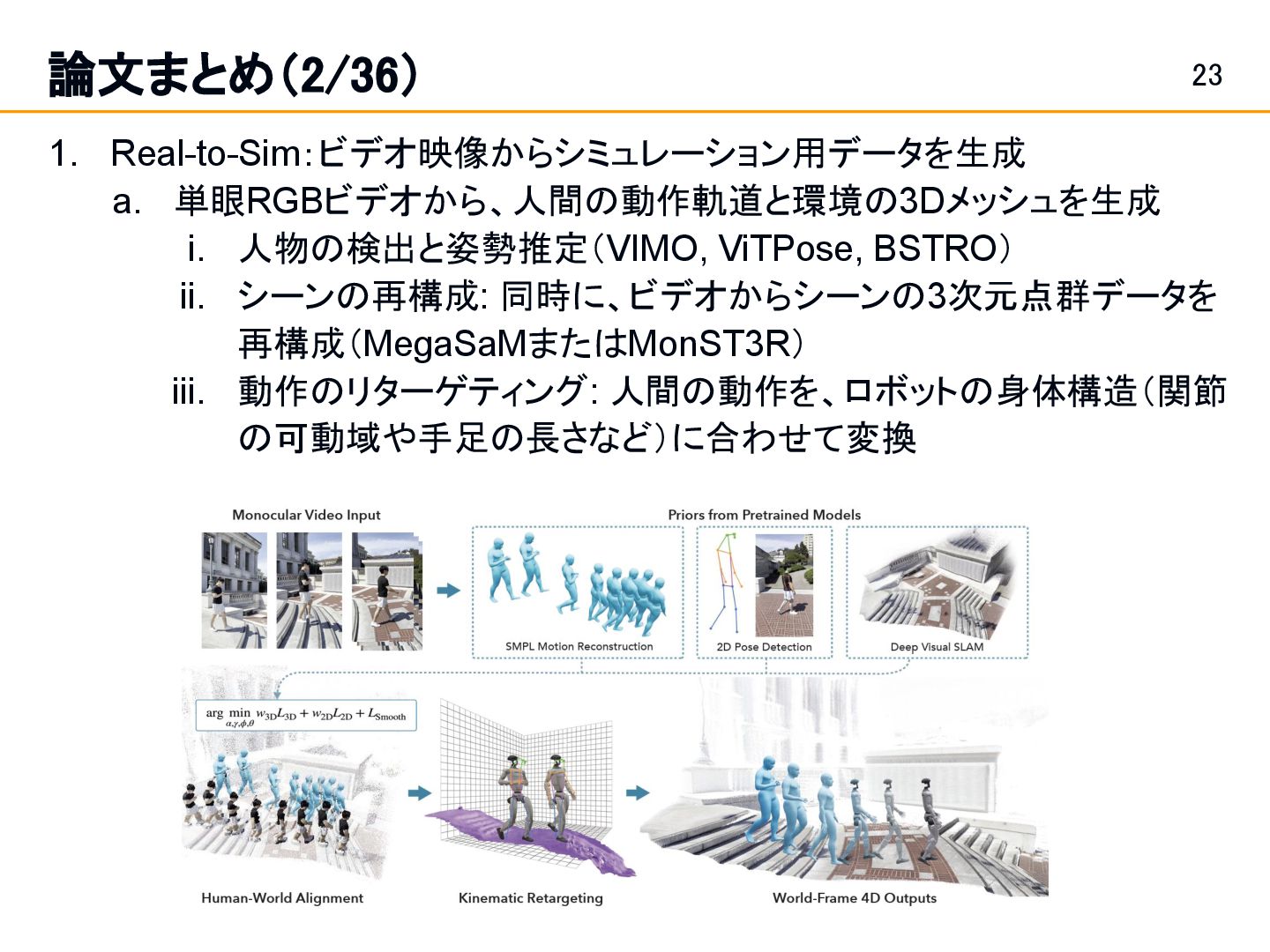
environments from video and other data, training models in these environments, and then deploying them back to the real world. • example: X-Sim [Dan et al.], Real2Render2Real [Yu et al.], VIDEOMIMIC [Allshire et al.], ImMimic [Liu et al.] etc. X-Sim Real2Render2Real
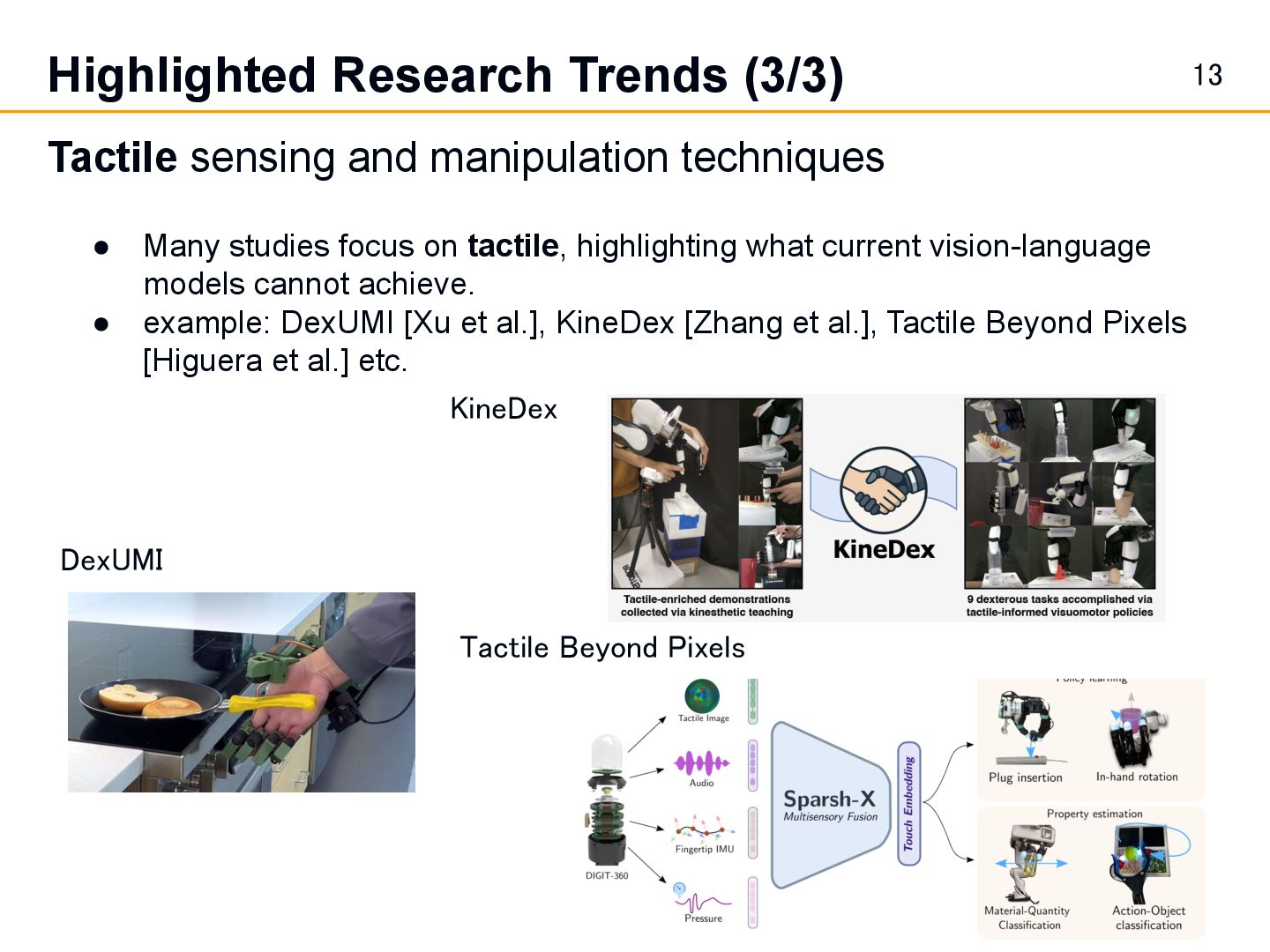
• Many studies focus on tactile, highlighting what current vision-language models cannot achieve. • example: DexUMI [Xu et al.], KineDex [Zhang et al.], Tactile Beyond Pixels [Higuera et al.] etc. Tactile Beyond Pixels DexUMI KineDex
Moonshot R&D (Grant No. JPMJPS2011), JST CREST (Grant No. JPMJCR2015), and the Basic Research Grant (“Super AI”) of the Institute for AI and Beyond, The University of Tokyo. • I am especially grateful to Specially Appointed Assistant Professor Yasuhiro Kato and Project Researcher Yusuke Mori for their advice on slide. • I also thank Prof. Tatsuya Harada and all members of our laboratory.
of some of the research that attracted attention at CoRL. • This deck provides a broad summary — if a paper interests you, I encourage you to read the original work yourself for details. • (Currently, the slides are written in Japanese🙇)
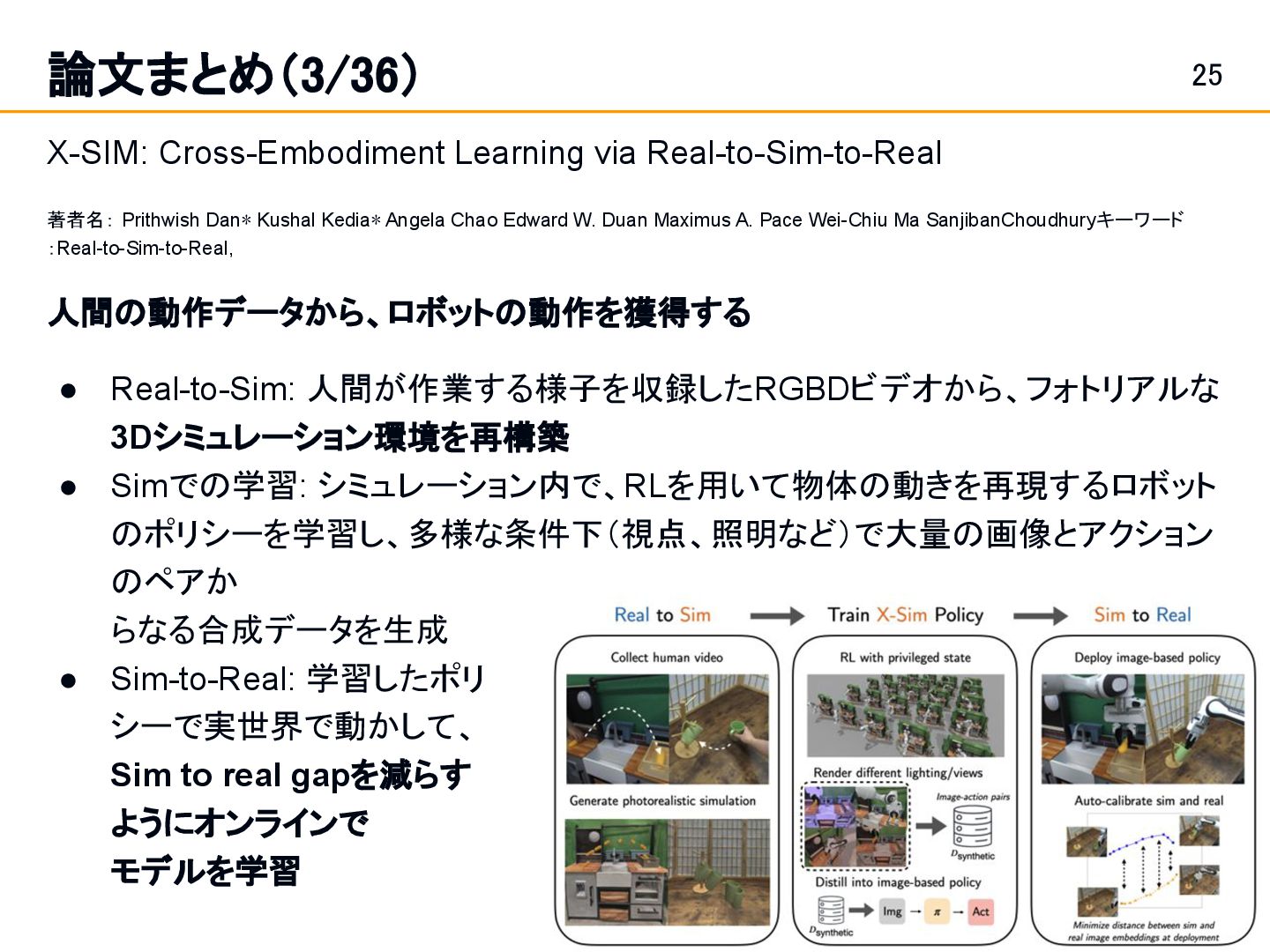
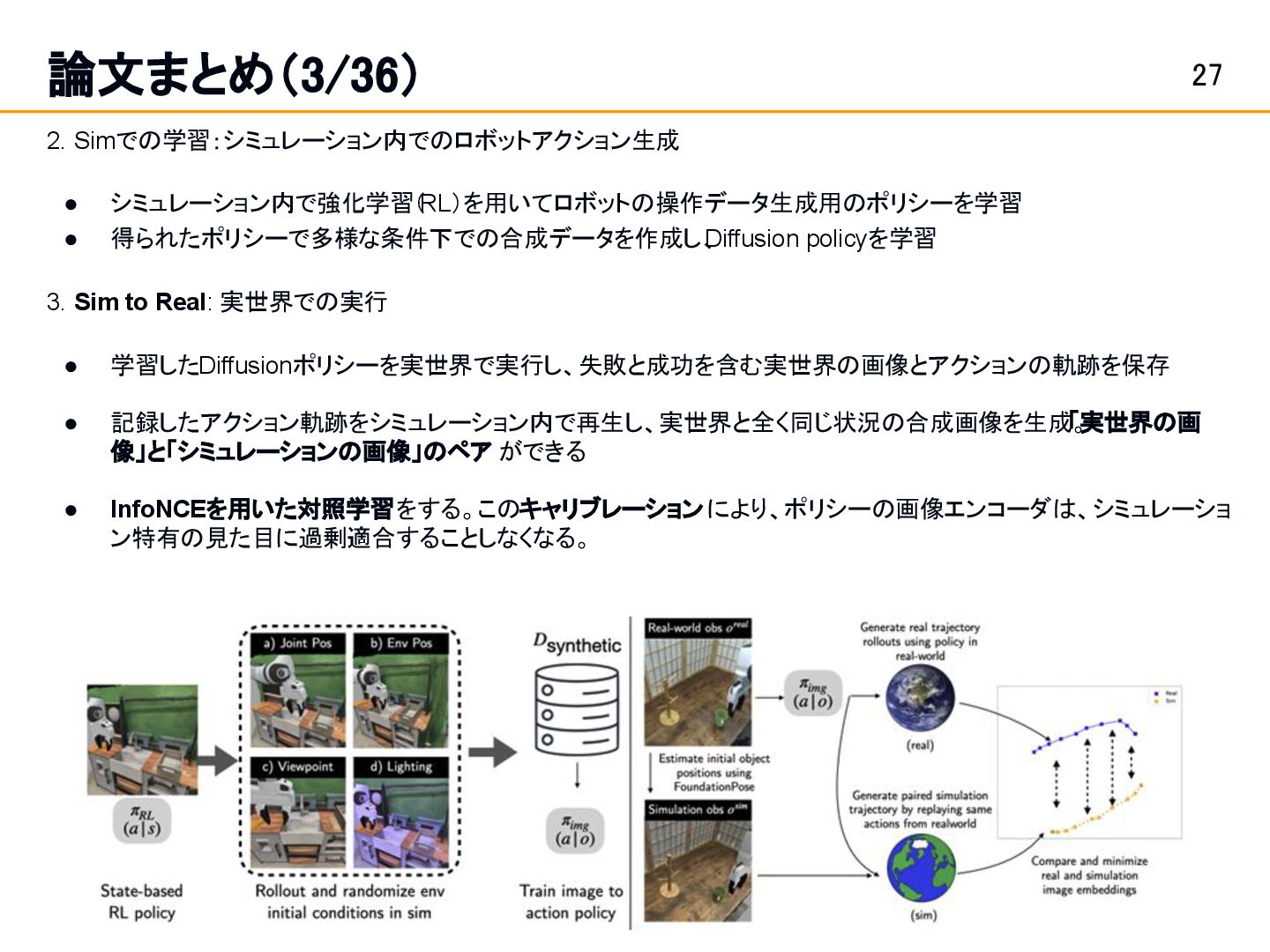
Dan∗ Kushal Kedia∗ Angela Chao Edward W. Duan Maximus A. Pace Wei-Chiu Ma SanjibanChoudhuryキーワード :Real-to-Sim-to-Real, 人間の動作データから、ロボットの動作を獲得する • Real-to-Sim: 人間が作業する様子を収録したRGBDビデオから、フォトリアルな 3Dシミュレーション環境を再構築 • Simでの学習: シミュレーション内で、RLを用いて物体の動きを再現するロボット のポリシーを学習し、多様な条件下(視点、照明など)で大量の画像とアクション のペアか らなる合成データを生成 • Sim-to-Real: 学習したポリ シーで実世界で動かして、 Sim to real gapを減らす ようにオンラインで モデルを学習
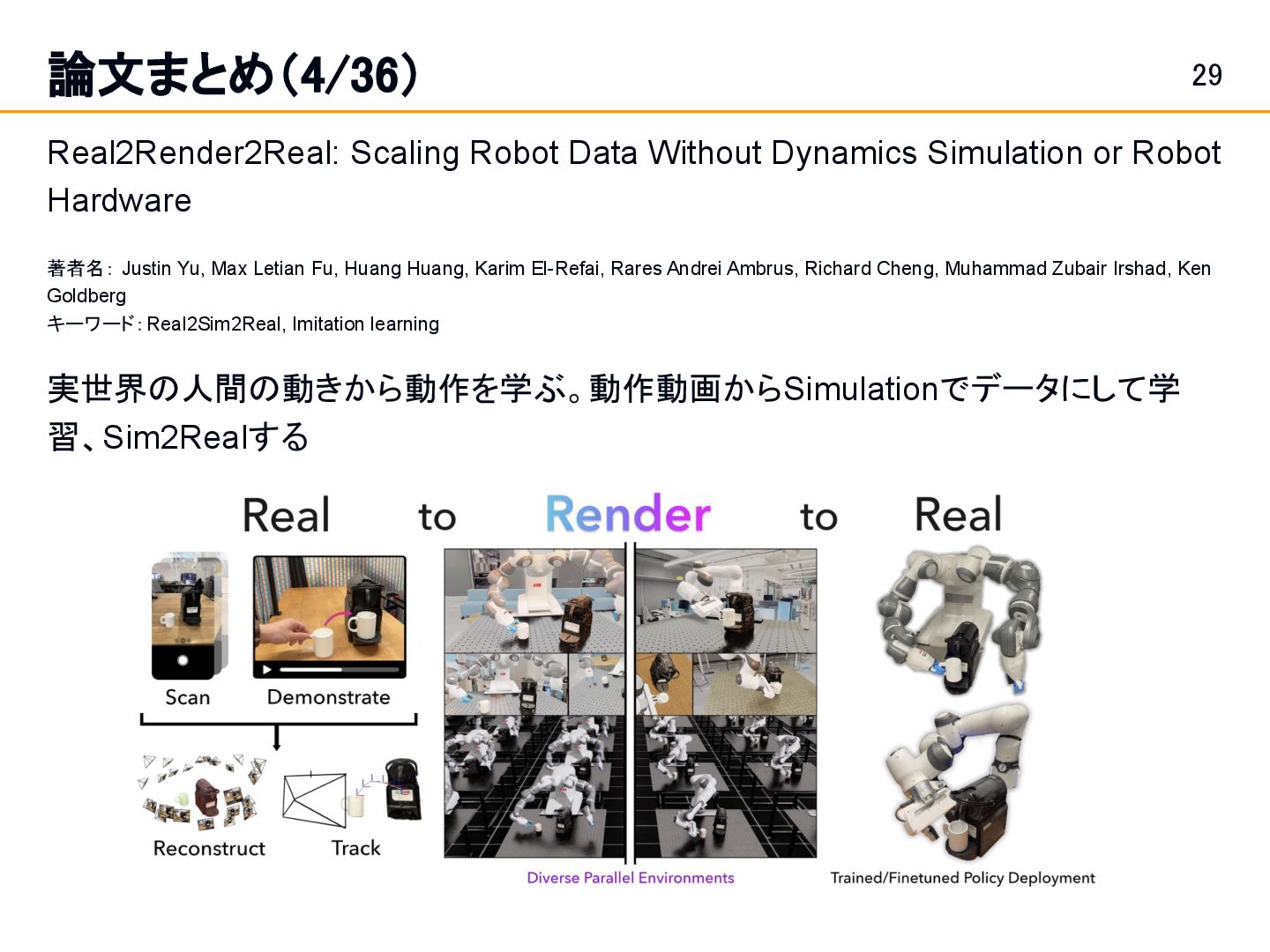
or Robot Hardware 著者名: Justin Yu, Max Letian Fu, Huang Huang, Karim El-Refai, Rares Andrei Ambrus, Richard Cheng, Muhammad Zubair Irshad, Ken Goldberg キーワード:Real2Sim2Real, Imitation learning 実世界の人間の動きから動作を学ぶ。動作動画からSimulationでデータにして学 習、Sim2Realする
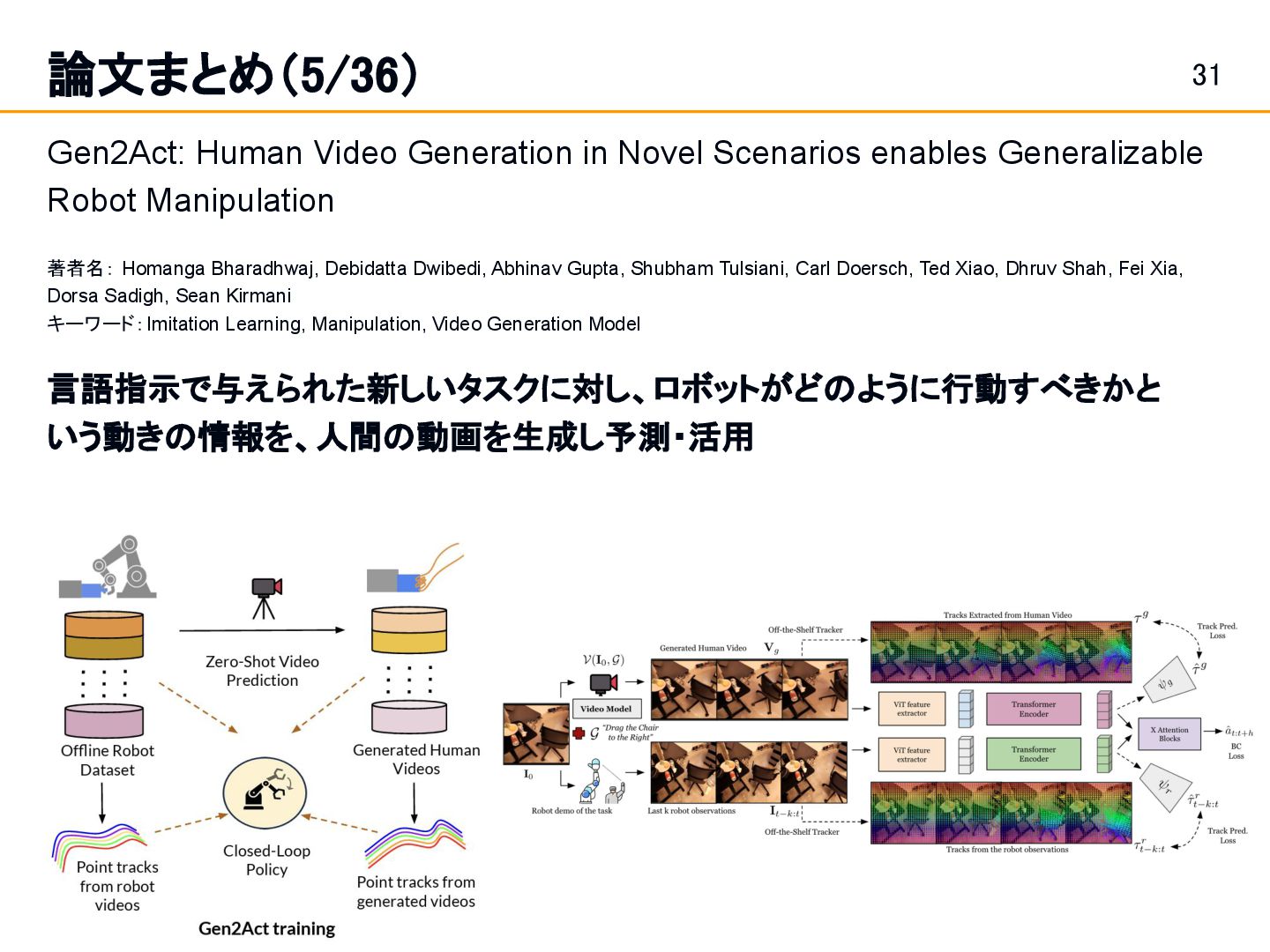
生成動画に基づくロボット制御: a. 生成された人間動画(Vg)と、ロボットの観測履歴 (I_t-k:k)の各フレームから、ViTエンコーダを用いて視覚特 徴を抽出 b. 動画からポイントトラックも抽出 c. 学習時には、Behavior cloningに加えて、生成動画からポ イントトラックを予測する補助タスク を学習。
動で設計。 2. 動作計画 (Motion Planning) a. 最後に、部品を掴んでから所定の位置へ運ぶまでの一連 のロボットアームの具体的な動作経路を計算。 b. ローカルな制御:強化学習による精密なはめ込み i. 計画に誘導された残差行動 ii. 強化学習ポリシーがゼロから動きを学習するのではな く、プランニングで計算された理想的な動作からの「補 正量(ずれ)」のみを学習
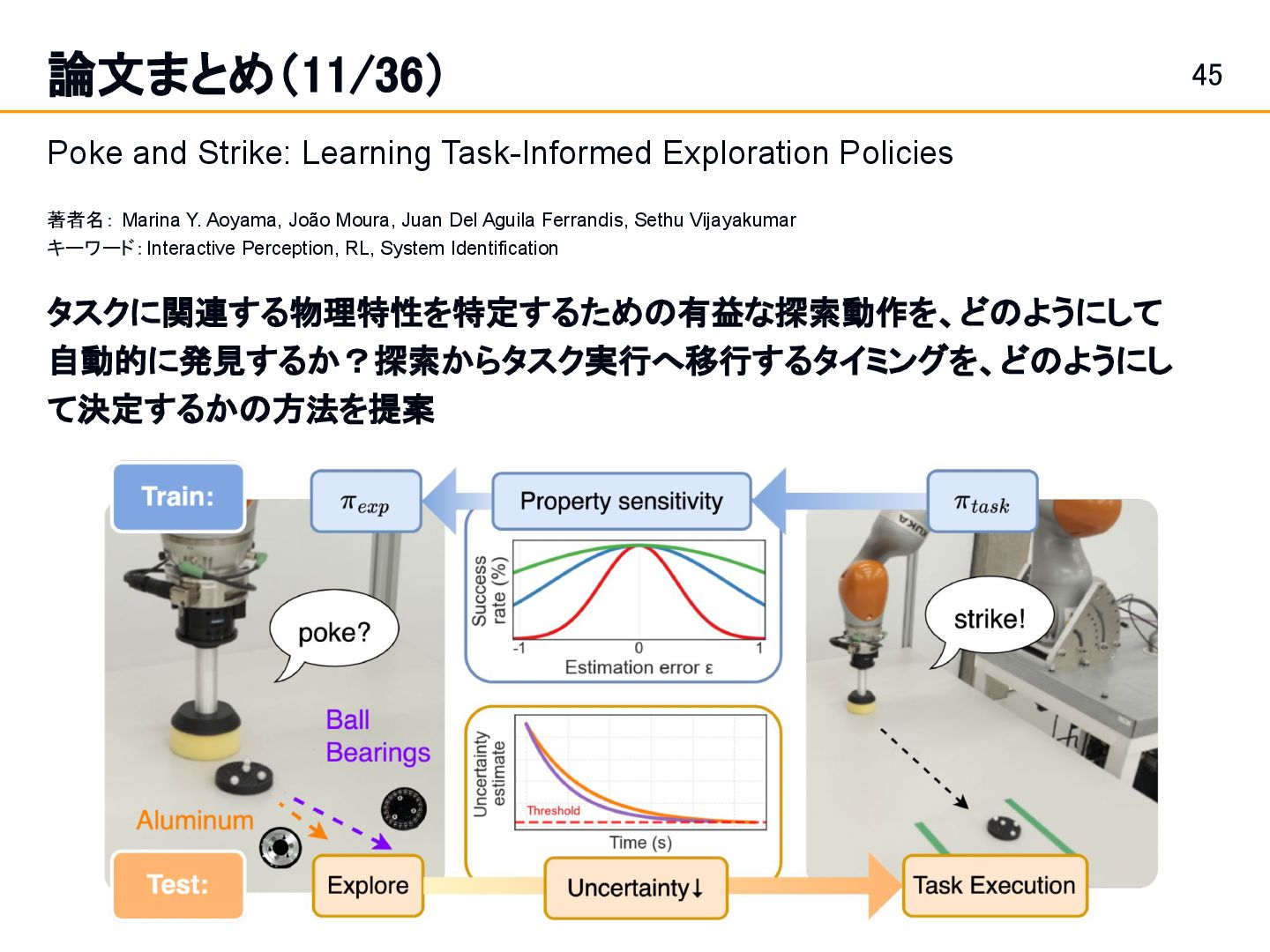
著者名: Marina Y. Aoyama, João Moura, Juan Del Aguila Ferrandis, Sethu Vijayakumar キーワード:Interactive Perception, RL, System Identification タスクに関連する物理特性を特定するための有益な探索動作を、どのようにして 自動的に発見するか?探索からタスク実行へ移行するタイミングを、どのようにし て決定するかの方法を提案
c. この感度に基づいて、タスクの成否に大きく寄与する特性に対し て、より高い精度を達成するよう誘導する探索方策の報酬。 2. 探索方策とオンライン推定器の同時学習(シミュレーション) a. 上記の報酬を使い、強化学習によって探索方策を訓練。 b. 同時に、探索中の観測データから物理特性をリアルタイムで推 定するオンライン推定器 も学習。 論文まとめ(11/36)
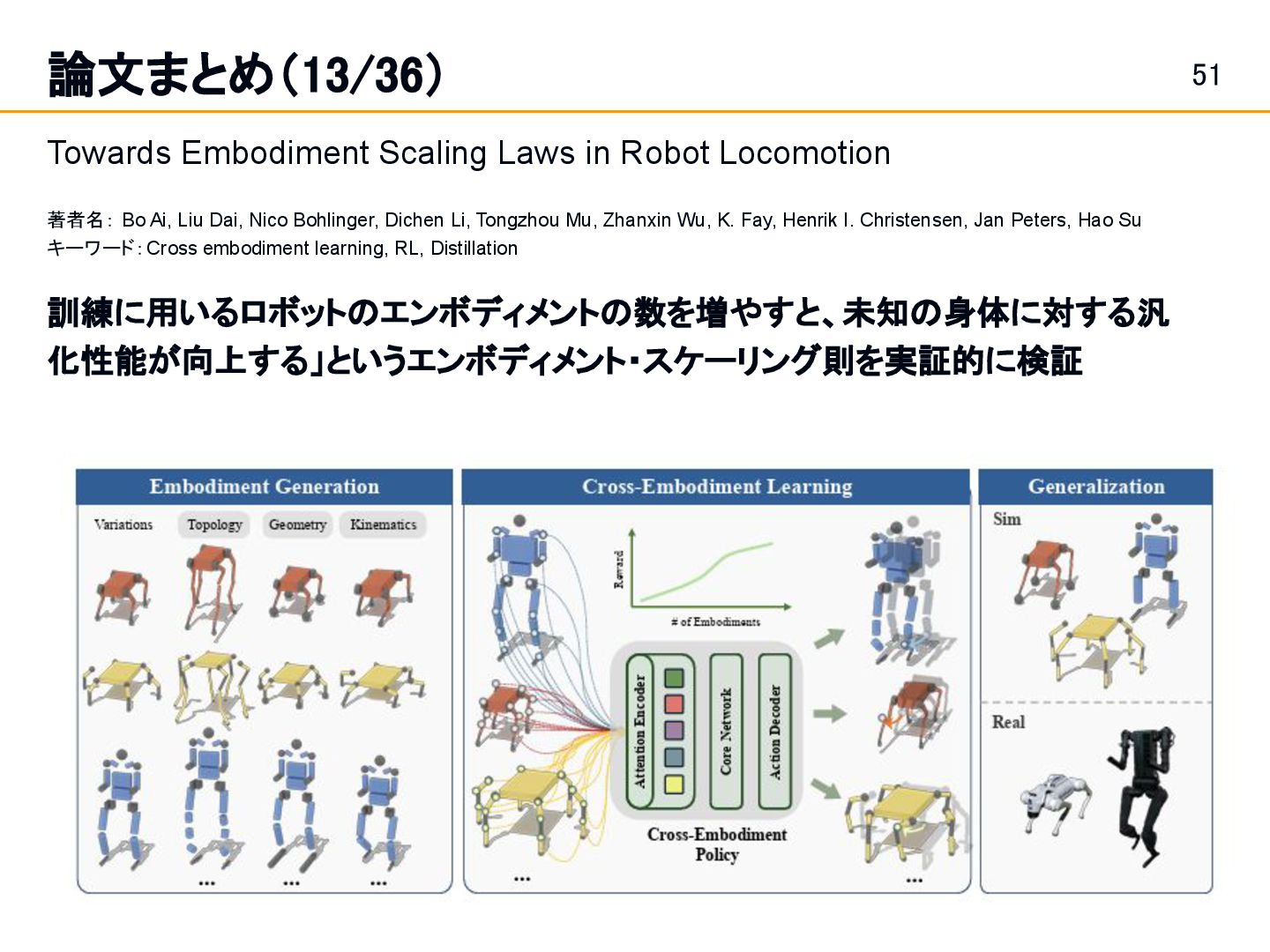
著者名: Bo Ai, Liu Dai, Nico Bohlinger, Dichen Li, Tongzhou Mu, Zhanxin Wu, K. Fay, Henrik I. Christensen, Jan Peters, Hao Su キーワード:Cross embodiment learning, RL, Distillation 訓練に用いるロボットのエンボディメントの数を増やすと、未知の身体に対する汎 化性能が向上する」というエンボディメント・スケーリング則を実証的に検証
ンスタンスのユニークなオブジェクトを使用しこれらをランダムにスケールし、さまざまな ポーズでテーブル上に落下させることで、多様で物理的に妥当なシーンを生成。 b. 安定した対蹠把持の姿勢を計算し生成するために 把持合成アルゴリズム を使用。 c. 生成されたオープンループの把持姿勢に到達し、オブジェクトを持ち上げるための衝突 のない軌道を計画するために、 モーションプランニングアルゴリズム CuRobo を使 用。 d. 高性能なフォトリアリスティックレイトレースレンダリングを提供する Isaac Sim を使用し て、RGB画像をレンダリング 。
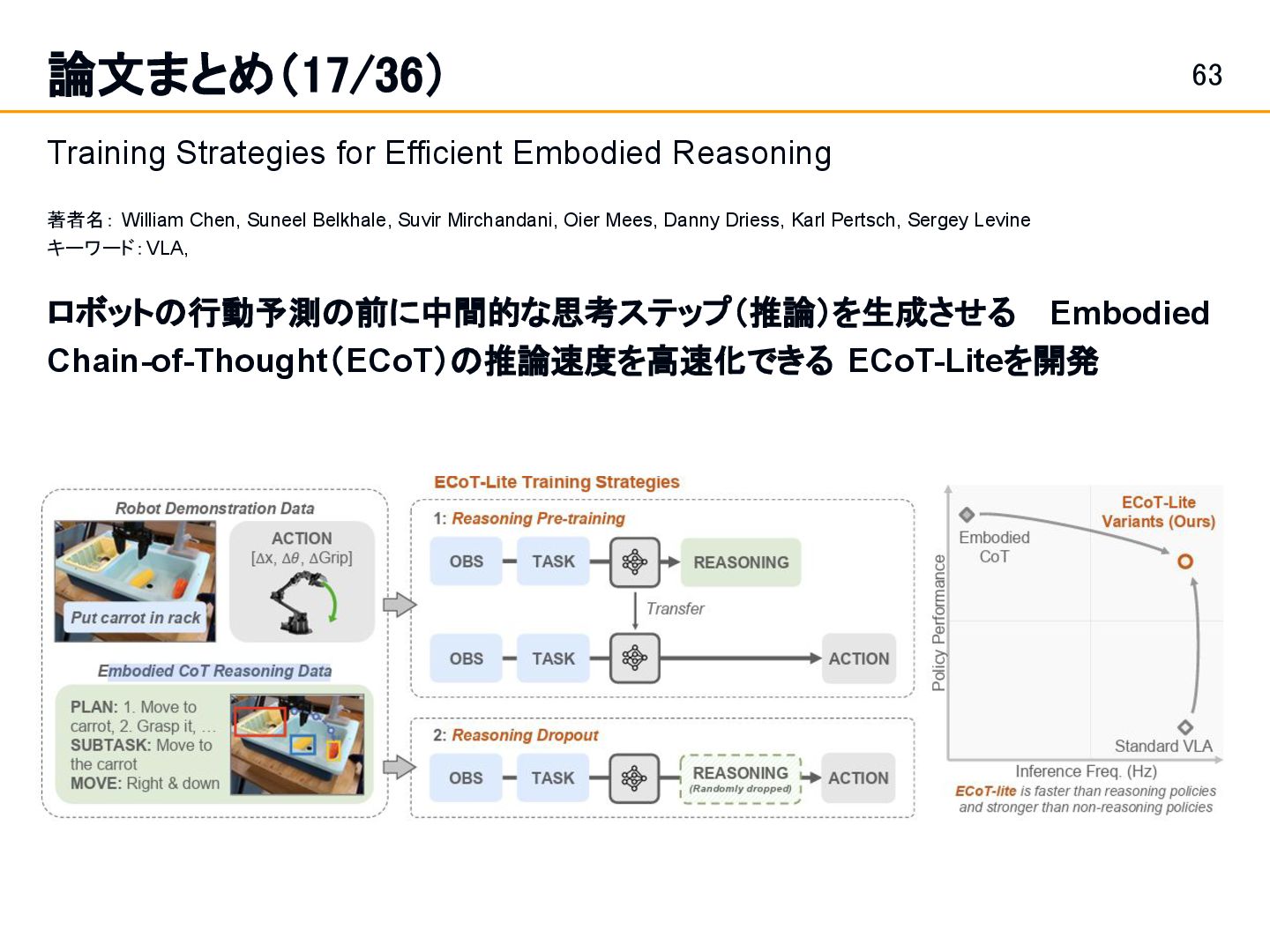
William Chen, Suneel Belkhale, Suvir Mirchandani, Oier Mees, Danny Driess, Karl Pertsch, Sergey Levine キーワード:VLA, ロボットの行動予測の前に中間的な思考ステップ(推論)を生成させる Embodied Chain-of-Thought(ECoT)の推論速度を高速化できる ECoT-Liteを開発
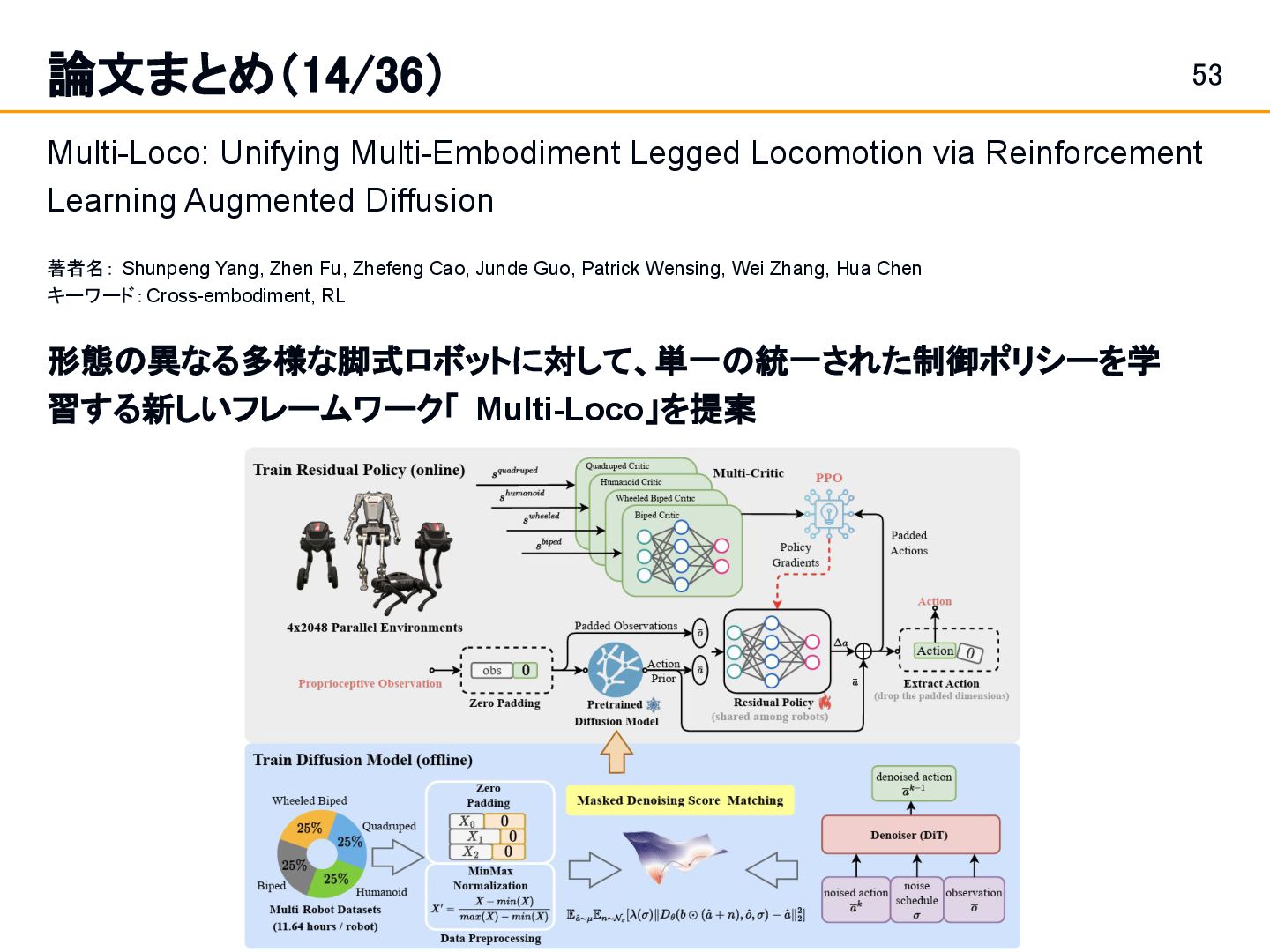
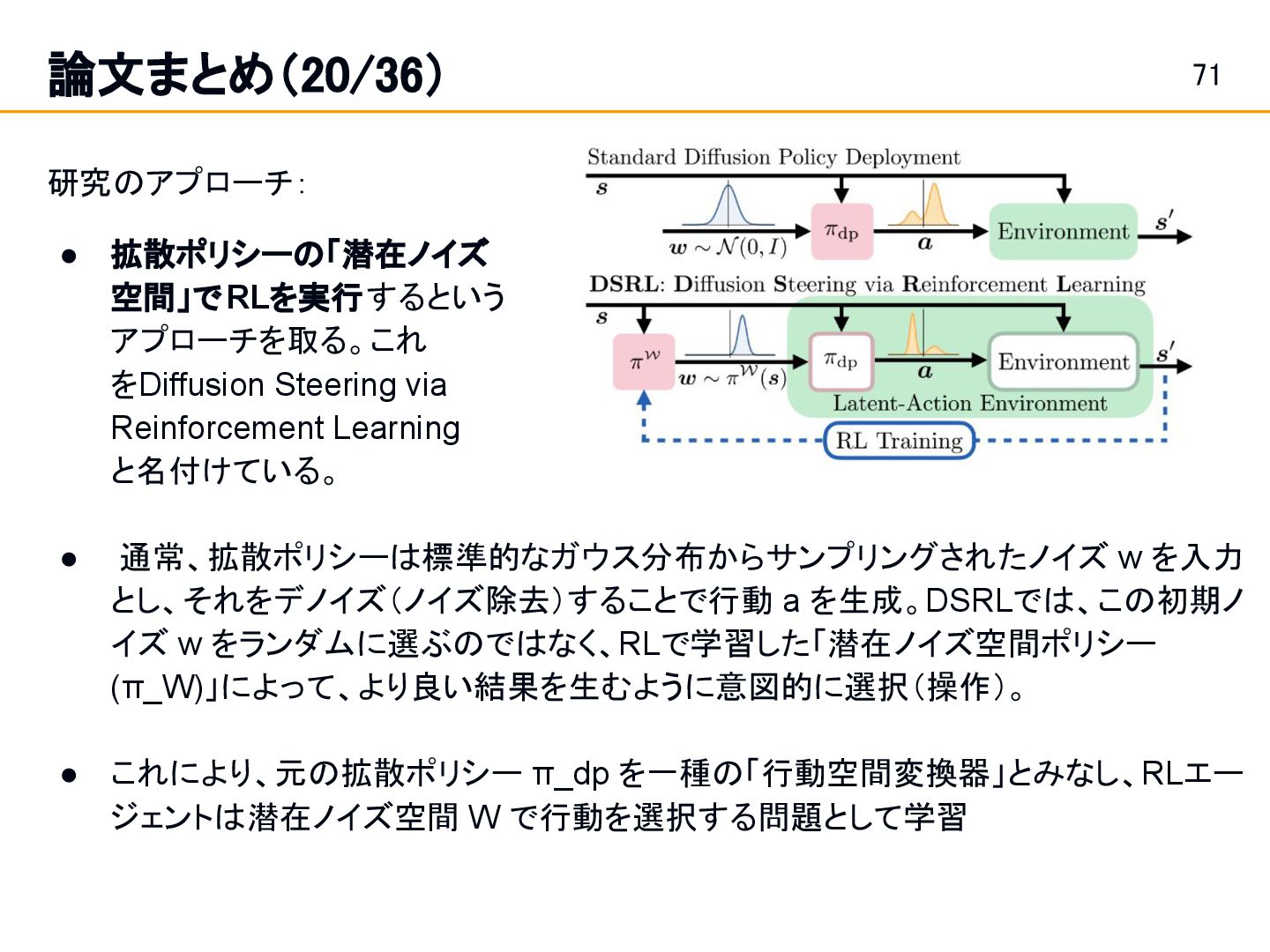
via Reinforcement Learning と名付けている。 • 通常、拡散ポリシーは標準的なガウス分布からサンプリングされたノイズ w を入力 とし、それをデノイズ(ノイズ除去)することで行動 a を生成。DSRLでは、この初期ノ イズ w をランダムに選ぶのではなく、RLで学習した「潜在ノイズ空間ポリシー (π_W)」によって、より良い結果を生むように意図的に選択(操作)。 • これにより、元の拡散ポリシー π_dp を一種の「行動空間変換器」とみなし、RLエー ジェントは潜在ノイズ空間 W で行動を選択する問題として学習
Transport Couplings 著者名: Andreas Sochopoulos, Nikolay Malkin, Nikolaos Tsagkas, João Moura, Michael Gienger, Sethu Vijayakumar キーワード:Flow matching policy, Imitation learning 追加の学習フェーズを必要とせずに、高品質かつ多様な動作を少ないステップで 高速に生成できる、新しいフローマッチング手法を開発する
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}