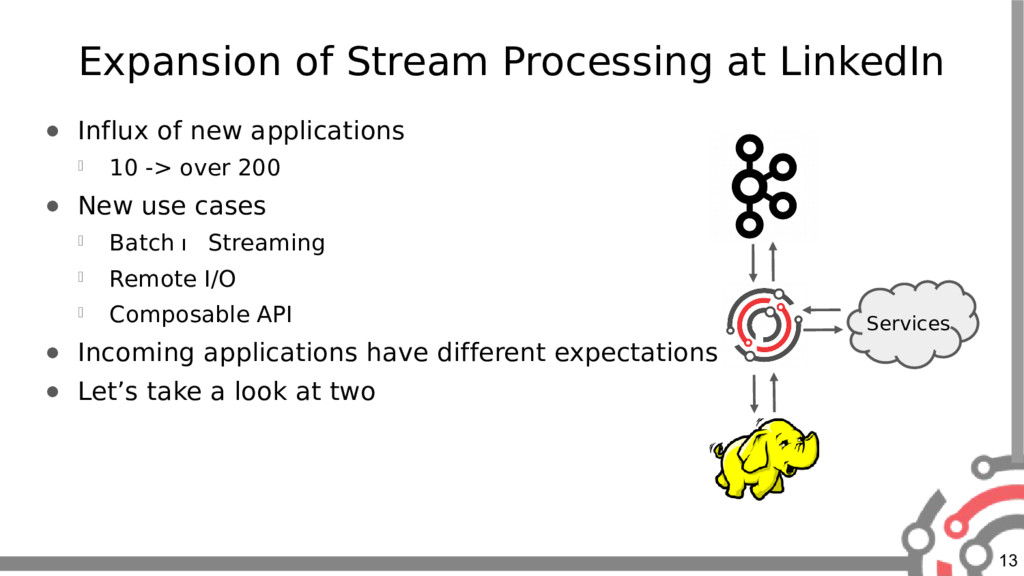
The shift to stream processing at LinkedIn has accelerated over the past few years. We now have over 200 Samza applications in production processing more than 260B events per day.
https://www.bigdataspain.org/2017/talk/apache-samza-jake-maes
Big Data Spain 2017
November 16th - 17th Kinépolis Madrid
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
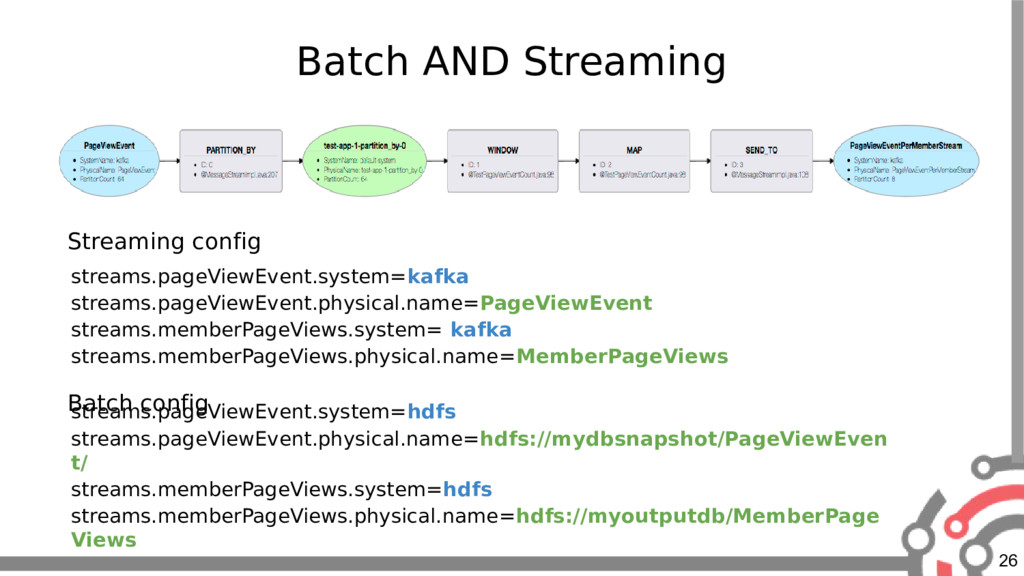{kind=link}
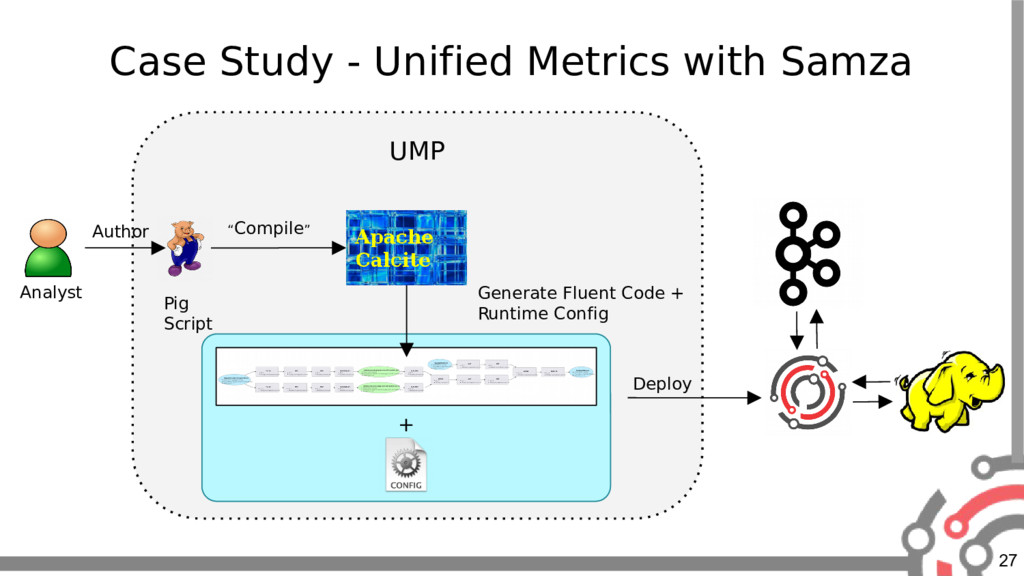{kind=link}
{kind=link}
{kind=link}
{kind=link}
![31 Questions Contact: • Email: [email protected] • Social: http://twitter.com/jakemaes Links:](https://files.speakerdeck.com/presentations/9a2654b2f652414aa119c258e4096533/slide_31.jpg){kind=link}