• この能力は非常に応用範囲が広く、ビジネスの現場でもよく活用されている • The cat is on the table. -> 猫がテーブルの上にいます。 • The weather is nice today. -> 今日は天気がいいです。 • I love to read books. -> 本を読むのが大好きです。 • She is a good friend. -> 彼女はいい友達です。 • The children are playing outside. -> ビジネス エンジニア DS・MLE LLM The children are playing outside. 従来の機械学習(ディープラーニングを含む) LLMのIn-Context Learning 子供たちが外で遊んでいます。 学習データ 機械学習モデル • The cat is on the table. • The weather is nice today. • I love reading books. • She is a good friend. • 猫がテーブルの上にいます。 • 今日は天気がいいです。 • 本を読むのが大好きです。 • 彼女はいい友達です。 インプットデータ アウトプットデータ 機械学習モデル 推論 学習 推論 子供たちが外で遊んでいます。 LLMはプロンプト内でどのような出力を行えばいいか学習を行い、未知の タスクについても出力を行うことができる能力を獲得している。 これを学術的にはメタ学習(meta learning)と呼ぶ 大規模言語モデルとは
• 入力が長くなると、文脈を保持する能力が低下し、矛盾した応答や意味の通らない回答をすることがある。 • Lost in the Middle ◦ 論文:Lost in the Middle: How Language Models Use Long Contexts 論理的な推論・因果関係 • モデルの構造上、数学などに必要な論理的な推論や因果関係を踏まえた出力が難しい 学習データのバイアス • モデルの学習に使われたデータに含まれる偏見(性別・人種・文化など)をそのまま再現してしまうことがある ビジネス エンジニア DS・MLE 大規模言語モデルとは
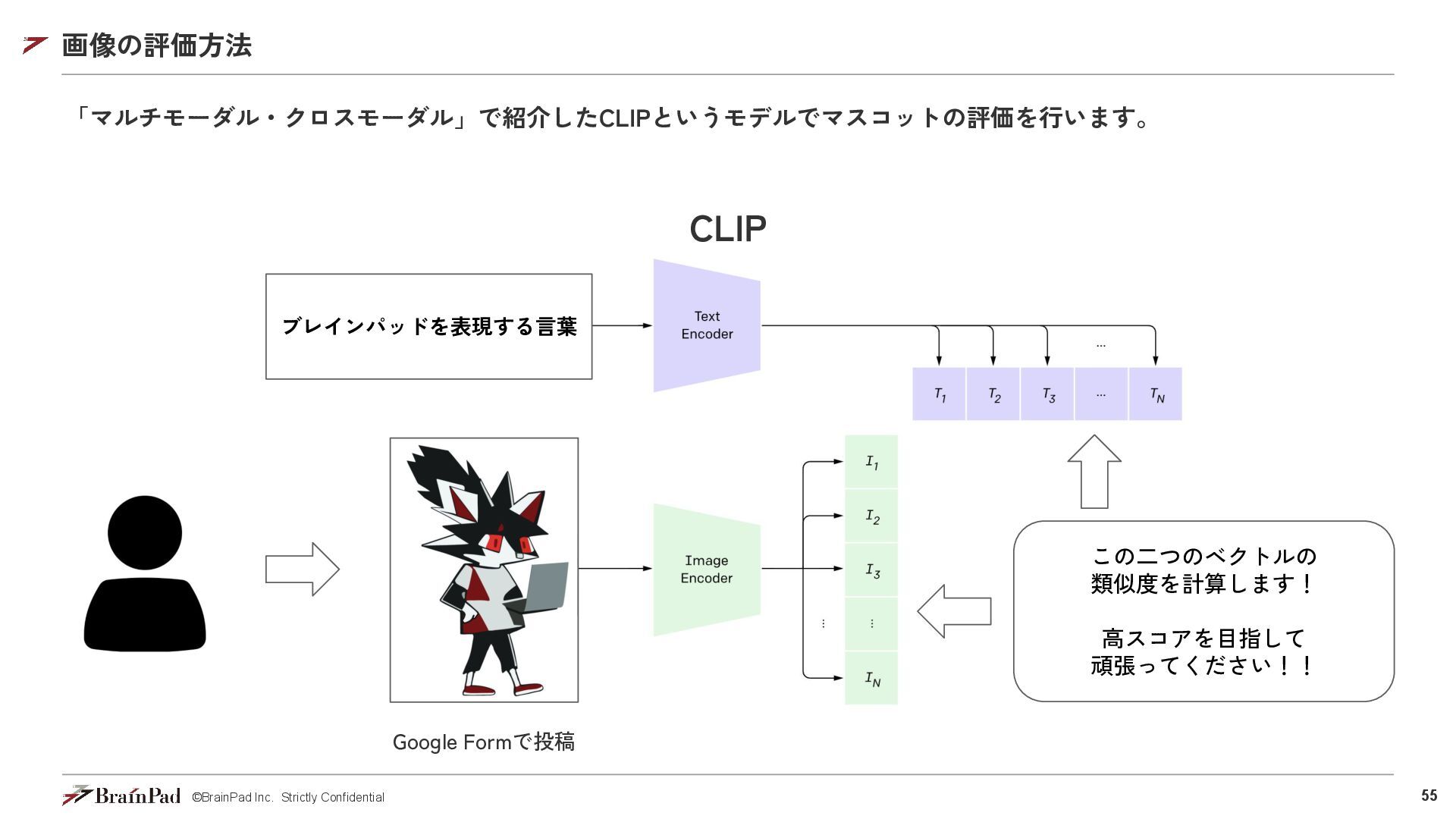
モダリティの組み合わせだけタスクが存在 • Text 2(to) Image • Image 2 Text...OCR • Text 2 Speech • Speech 2 Text • Text 2 Music • Image 2 Music • Text 2 Movie • Movie 2 Text • Image 2 Movie • … クロスモーダルモデルとは モダリティ間の変換に焦点を当てているモデルの総称 白い子猫 Text 2 Image Speech 2 Text 引用元:https://focus-tantei.com/directional-speaker-harassment/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![株式会社ブレインパッド 106-0032 東京都港区六本木三丁目 1番1号 六本木ティーキューブ TEL:03-6721-7002 FAX:03-6721-7010 www.brainpad.co.jp [email protected] 本資料は、未刊行文書として日本及び各国の著作権法に基づき保護されております。本資料には、株式会社ブレインパッド所有の特定情報が含まれており、これら情報に基づく本資料の内容は、貴社以外の第三者に開示されること、また、本資料を評価する以外の目的で、その一部または全文を複製、使用、 公開することは、禁止されています。また、株式会社ブレインパッドによる書面での許可なく、それら情報の一部または全文を使用または公開することは、いかなる場合も禁じられております。 ©BrainPad Inc.](https://files.speakerdeck.com/presentations/2d0a95a785734c00ab0f850dfd1e412d/slide_57.jpg){kind=link}