Share
Dataware House(DWH)とDataLakeでデータが分断されていませんか? そのサイロ化問題を解決するのが、DWHの「信頼性」とDataLakeの「柔軟性」を両立させる新標準「LakeHouse」です 。中核技術Apache Icebergがデータレイクの信頼性を高め 、BIからAIまで多様なワークロードを単一基盤で実現します 。特に生成AI(RAG)活用の鍵となる「信頼できる唯一の情報源」 として不可欠な、次世代データ基盤の全体像を解説します 。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
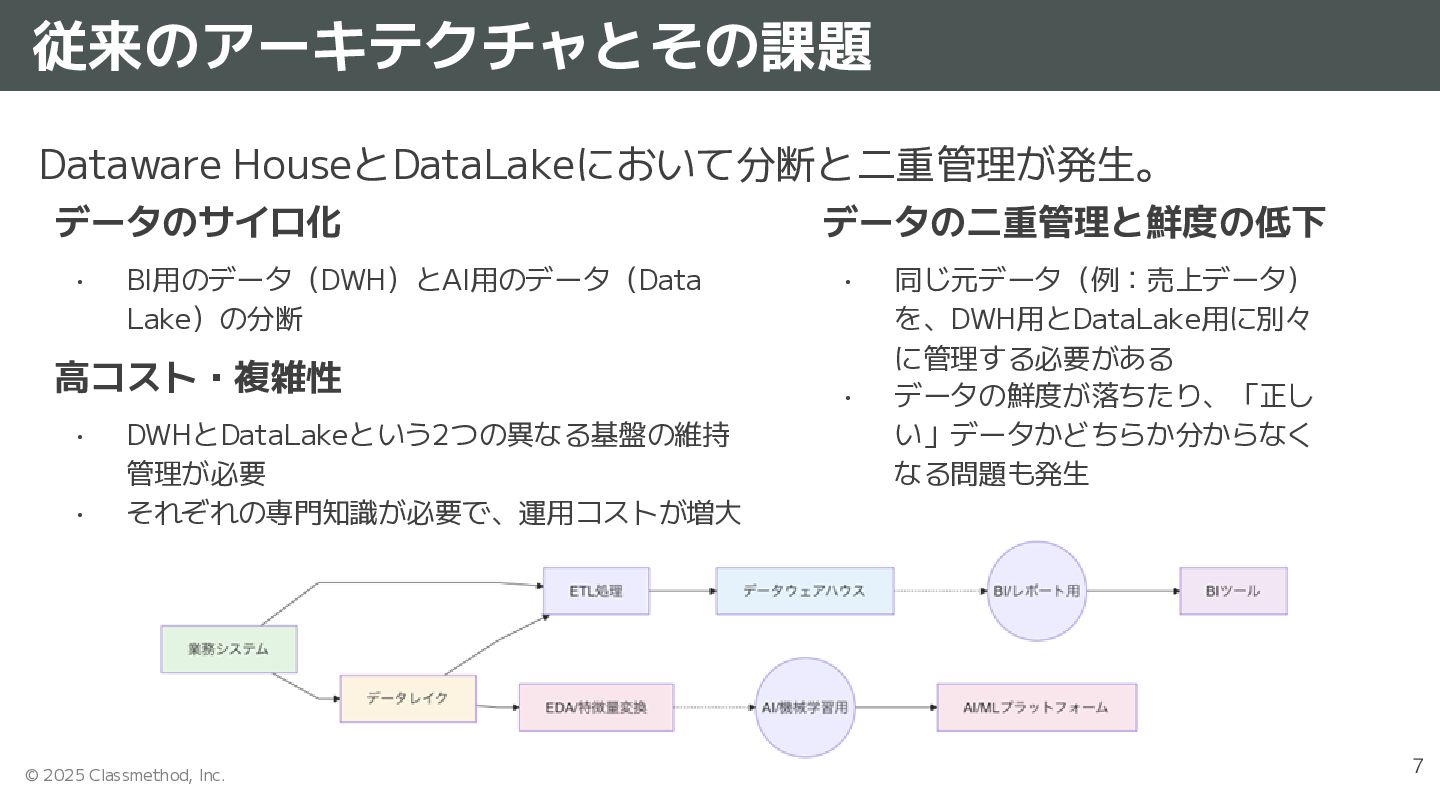
{kind=link}
{kind=link}
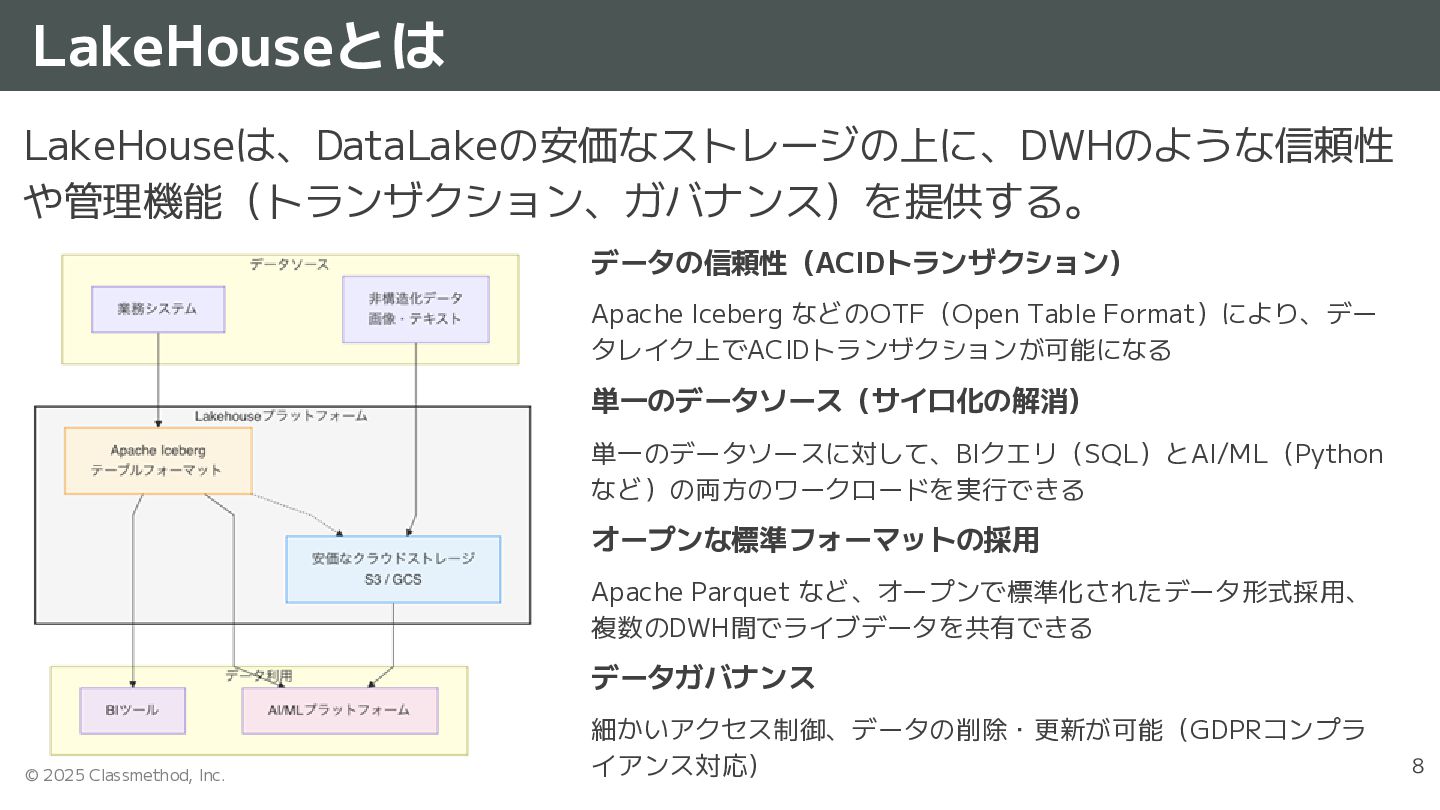
{kind=link}
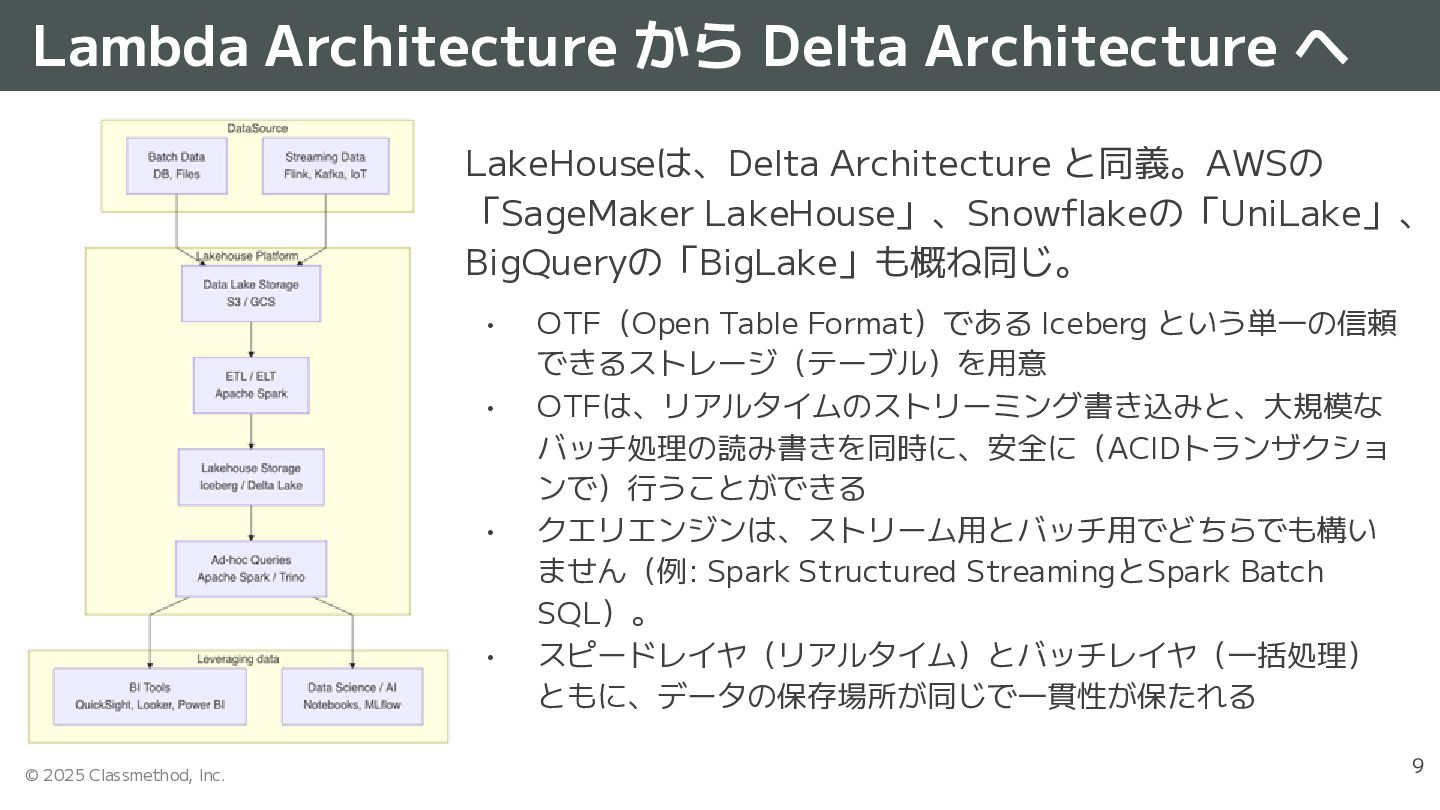
{kind=link}
{kind=link}
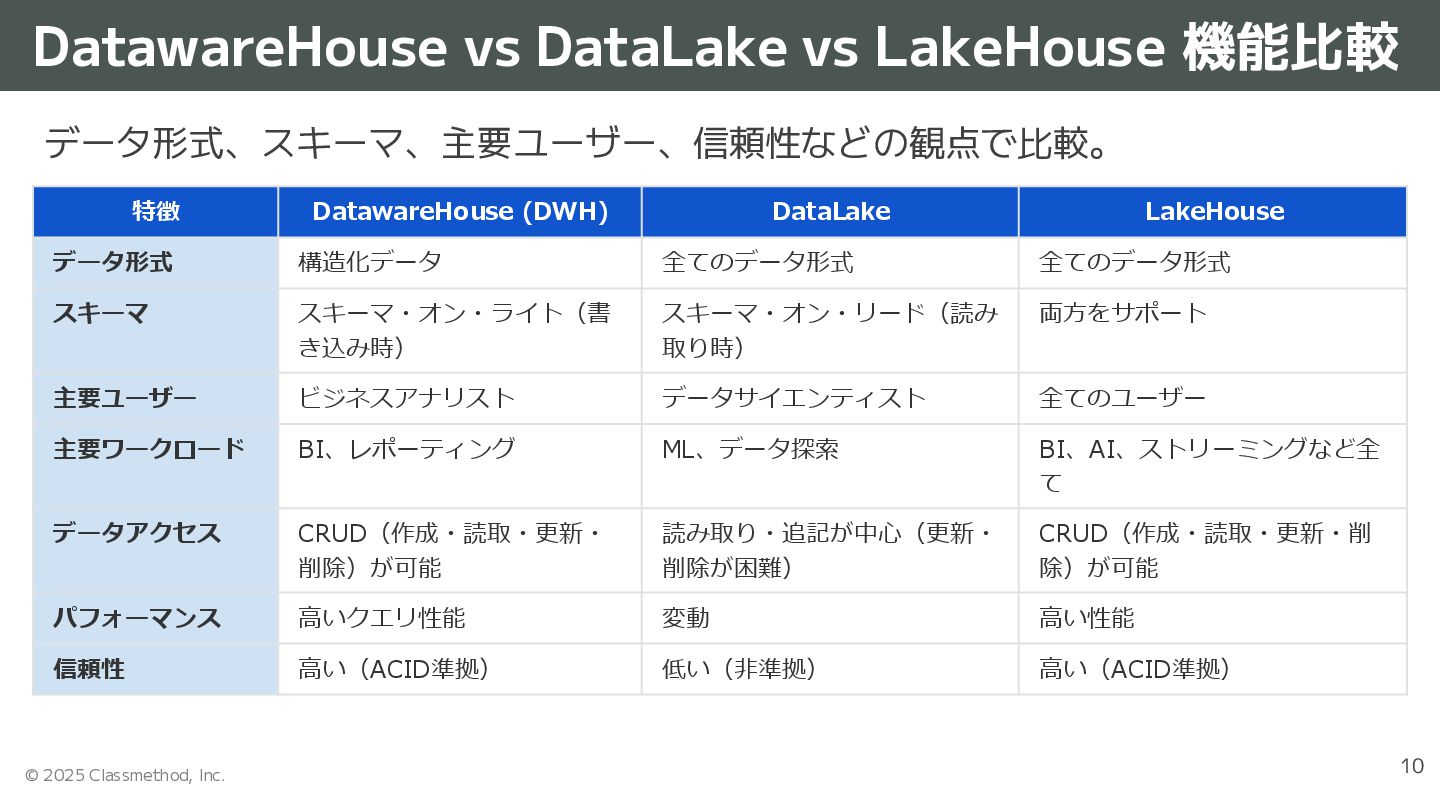{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
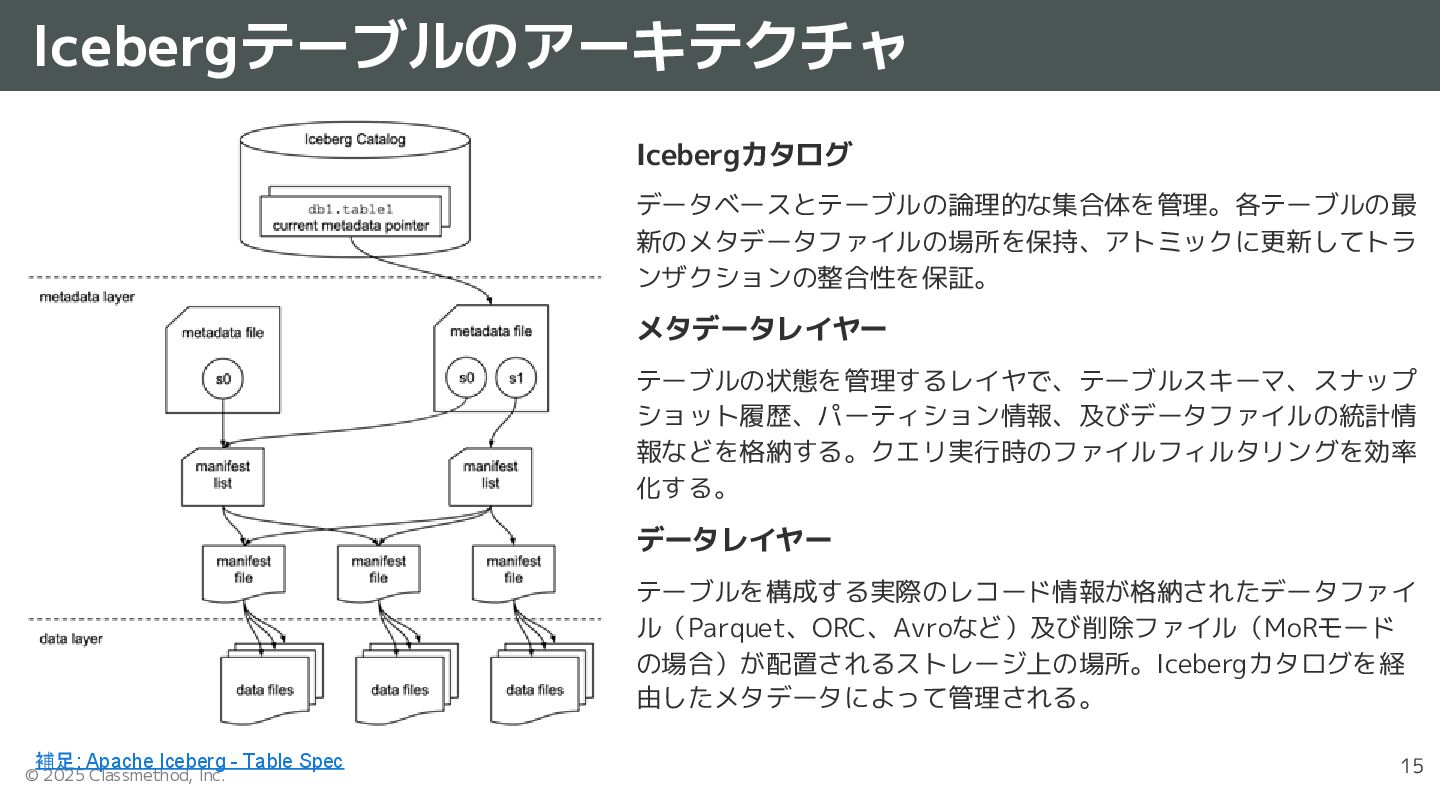{kind=link}
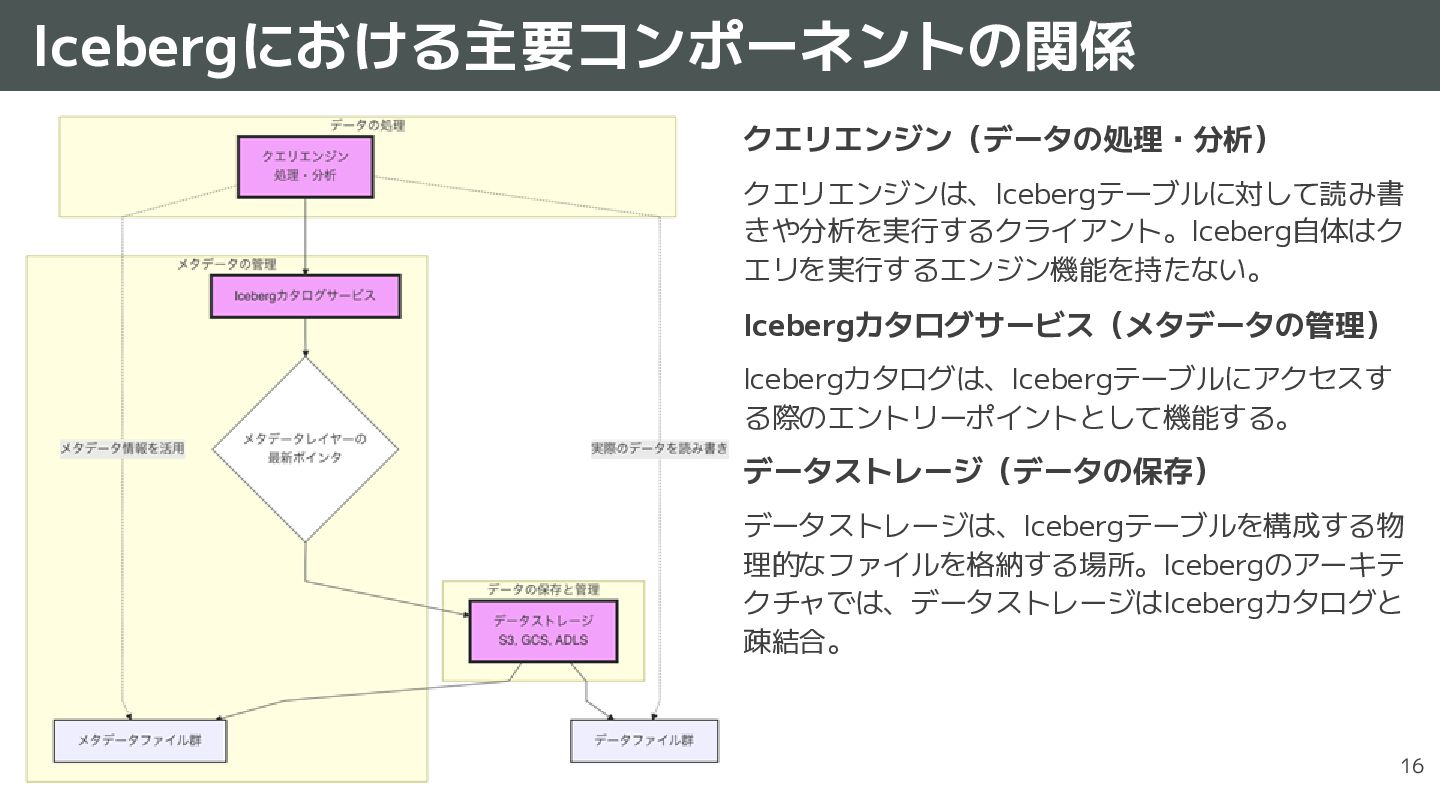{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
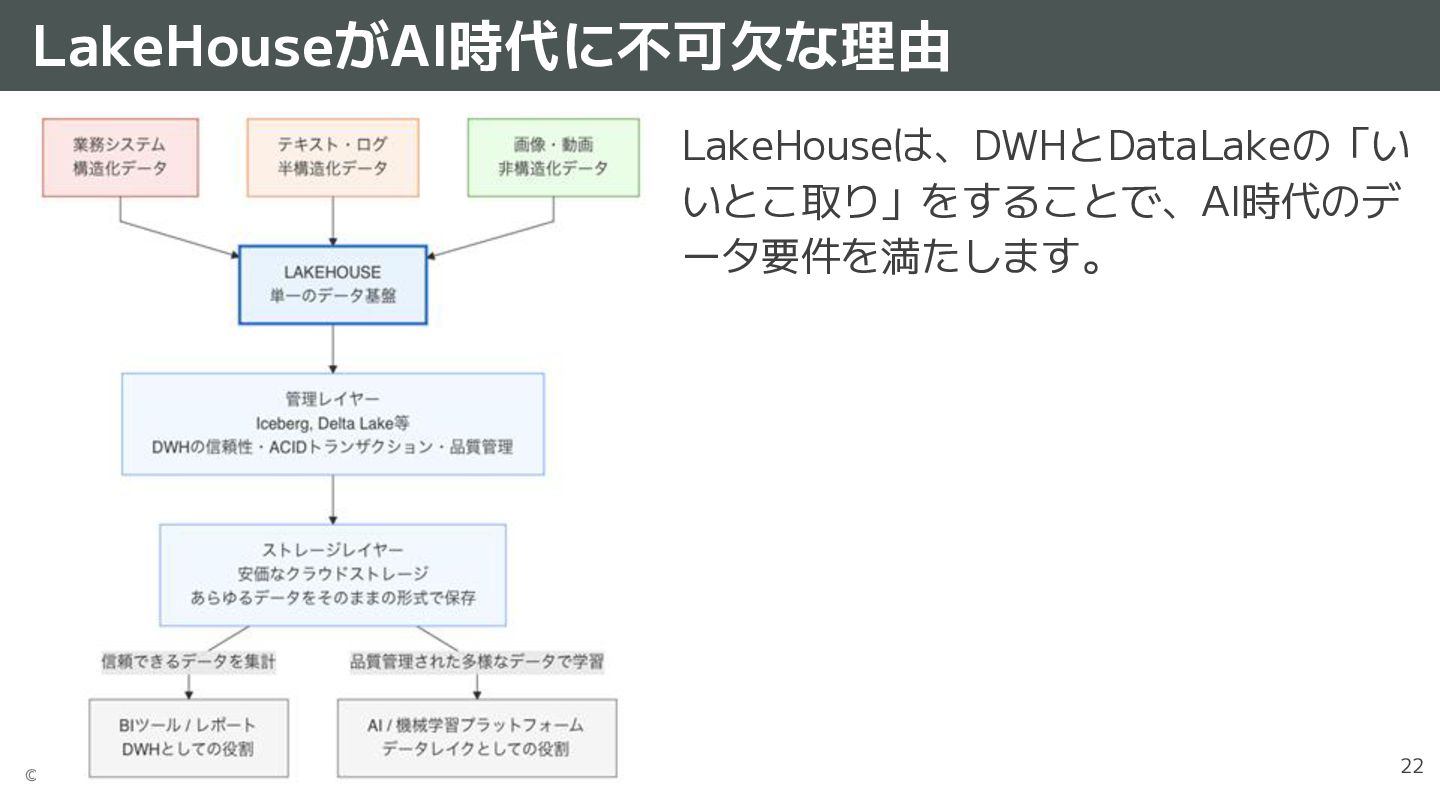{kind=link}
{kind=link}
{kind=link}
{kind=link}
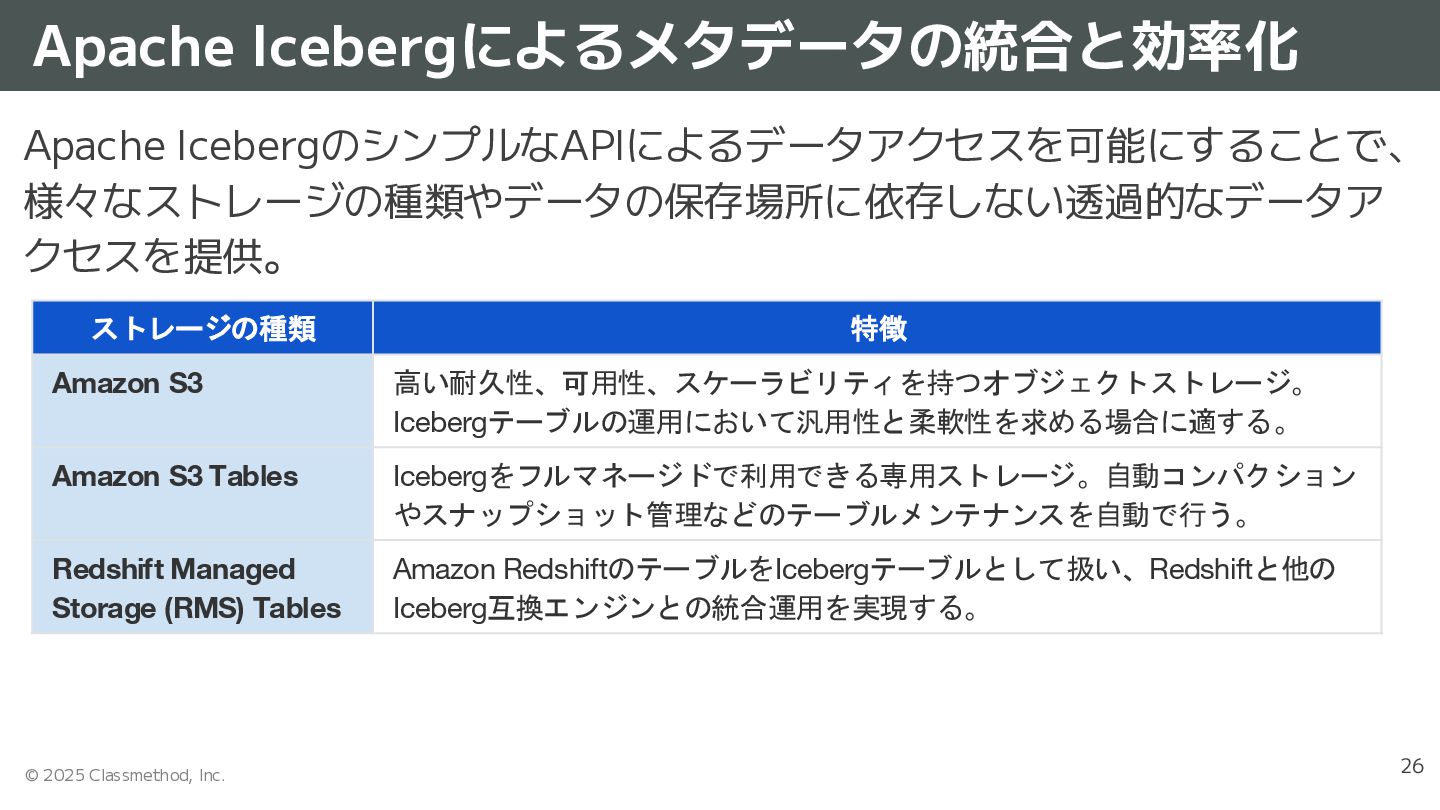{kind=link}
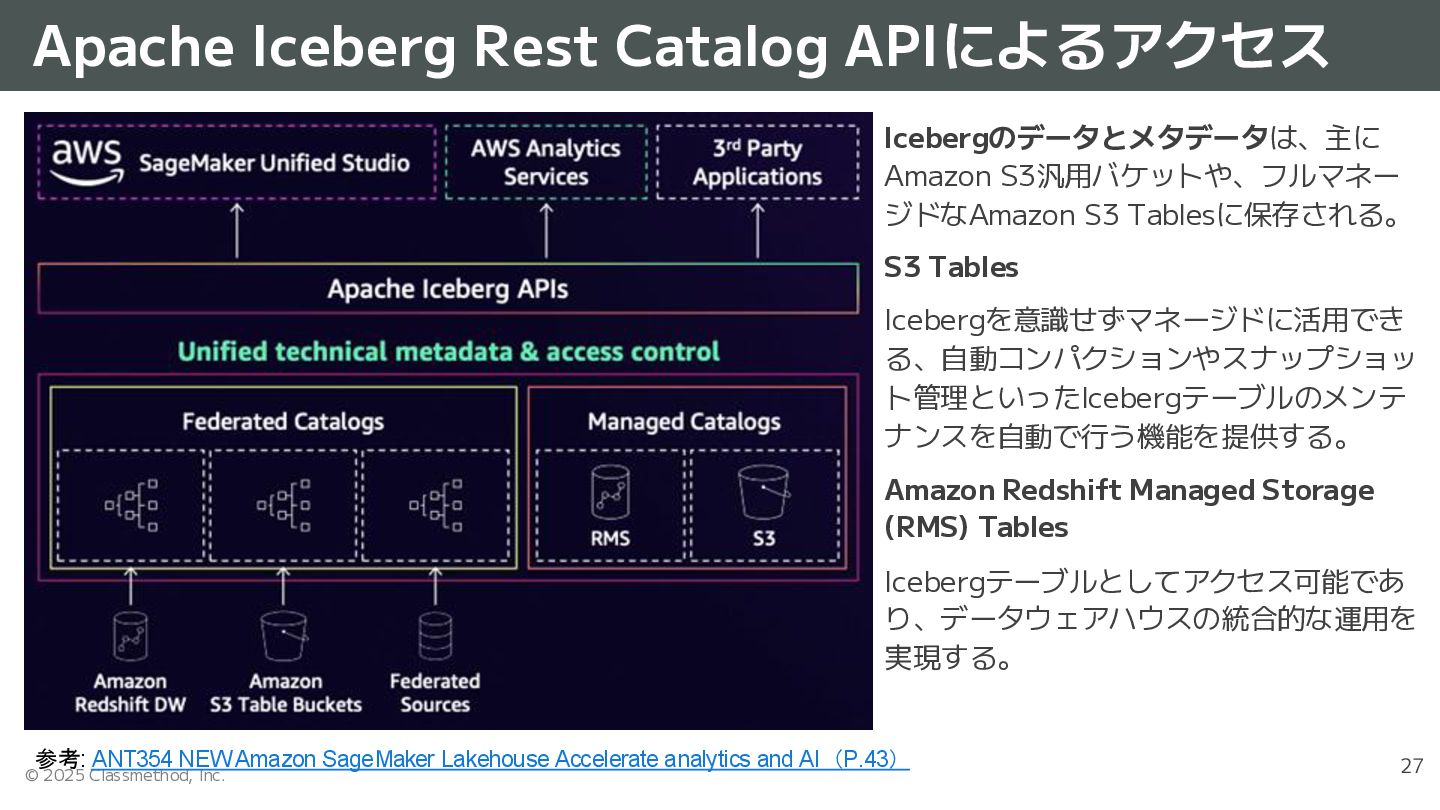{kind=link}
{kind=link}
{kind=link}
{kind=link}