For the last decades, many Machine Learning methods have been proposed aiming categorizing data. Given many tentative models, those methods try to find the one that fits the dataset by building a hypothesis that predicts unseen samples reasonably well. One of the main concerns in that regard is selecting a model that performs well in unseen samples not overfitting on the known data. In this work, we introduce a classification method based on the minimum description length principle, which naturally offers a tradeoff between model complexity and data fit. The proposed method is multiclass, online and is generic in the regard of data representation. The experiments conducted in real datasets with many different characteristics, have shown that the proposed method is statiscally equivalent to the other classical baseline methods in the literature in the offline scenario and it performed better than some when tested in an online scenario. Moreover, the method has proven to be robust to overfitting and data normalization which poses great features a classifier must have in order to deal with large, complex and real-world classification problems.
{kind=link}
{kind=link}
{kind=link}
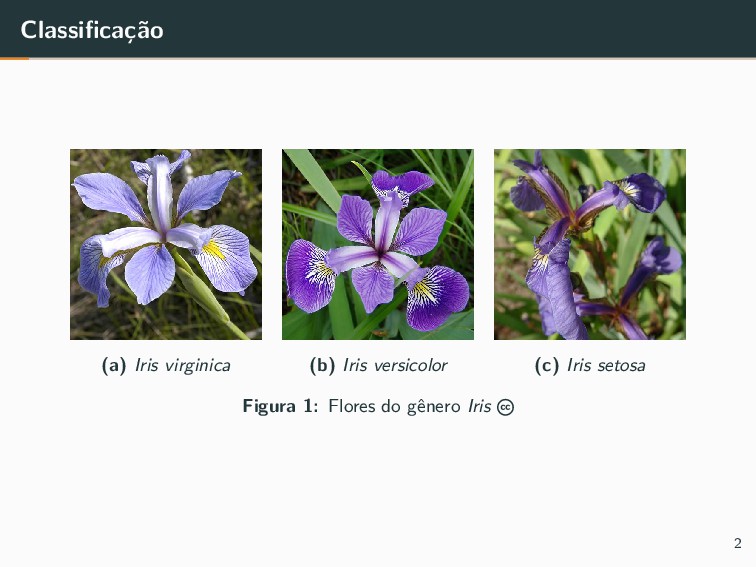{kind=link}
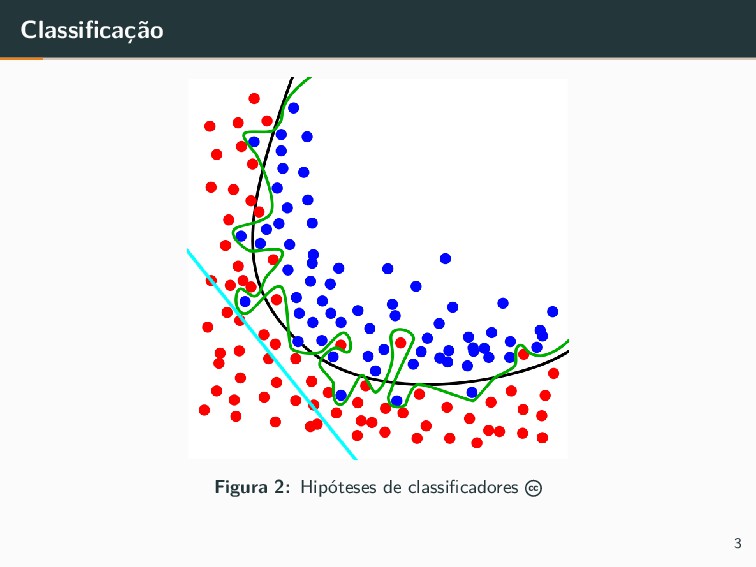{kind=link}
{kind=link}
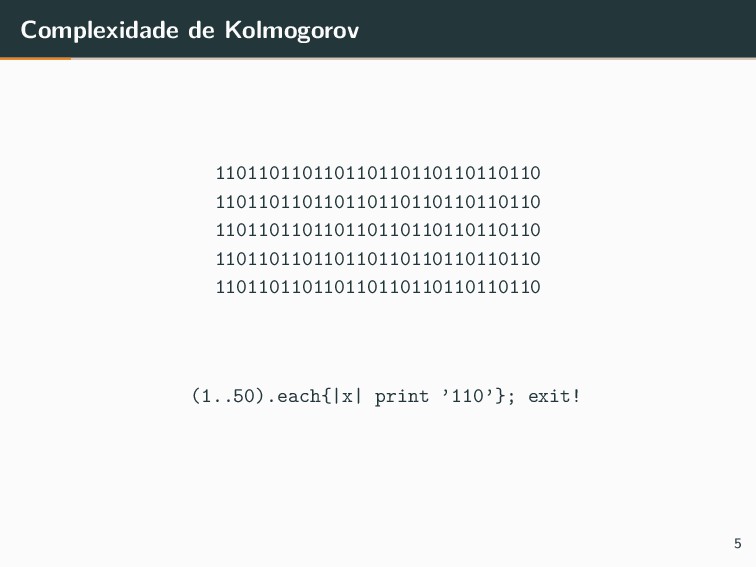{kind=link}
{kind=link}
{kind=link}
![Origem • Rissanen [19] em 1978 definiu o Princípio da](https://files.speakerdeck.com/presentations/ba679853f6d44b7aa864cbd6490d44ee/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
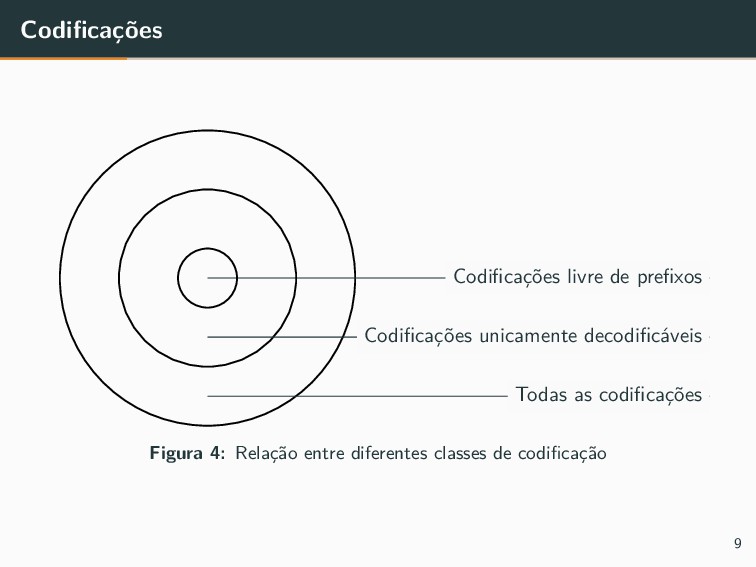{kind=link}
{kind=link}
{kind=link}
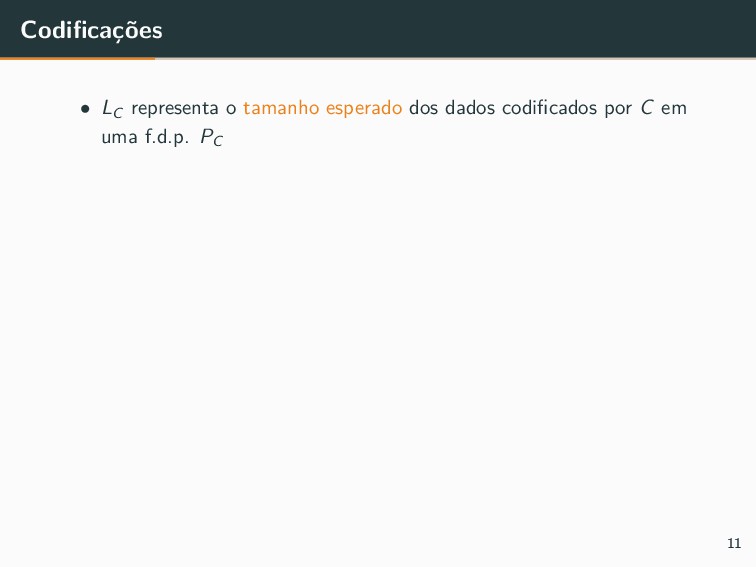{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
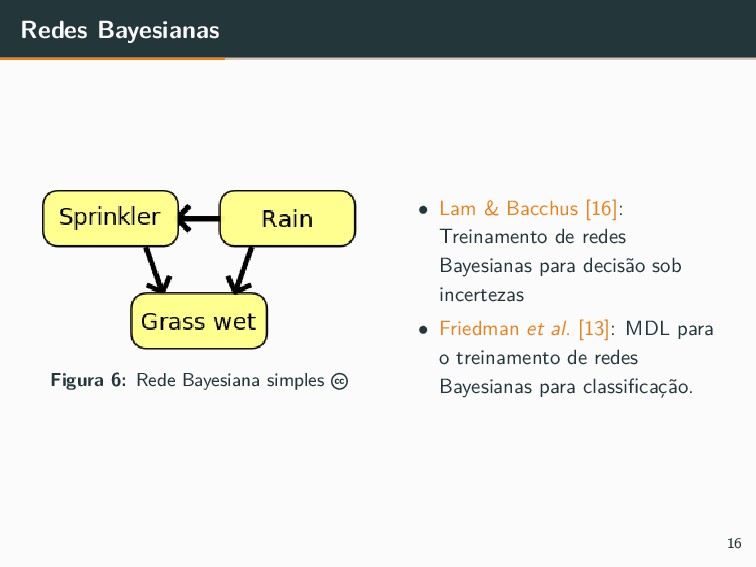{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
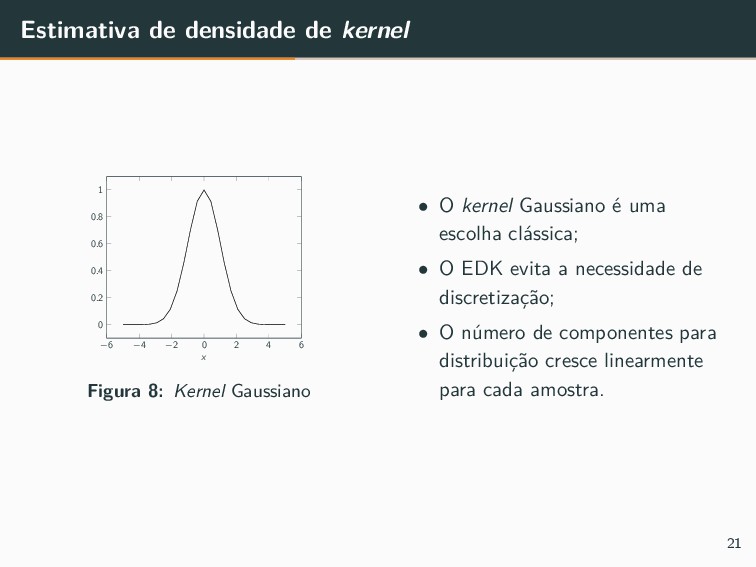{kind=link}
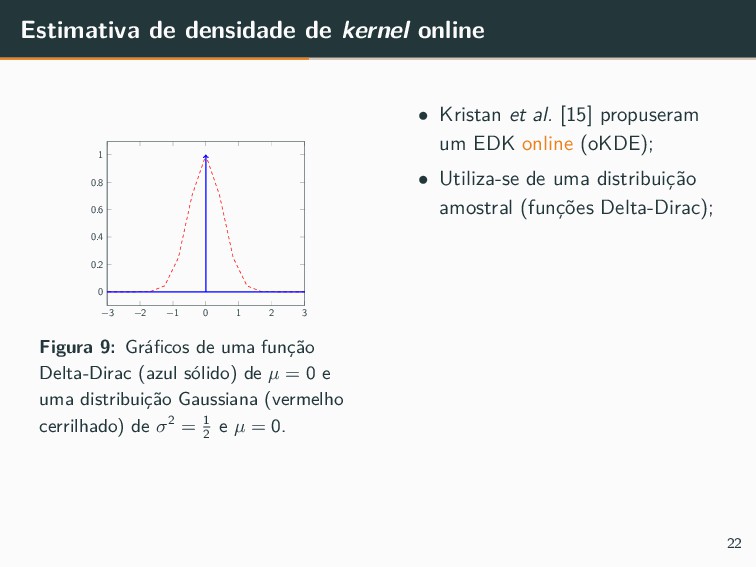{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
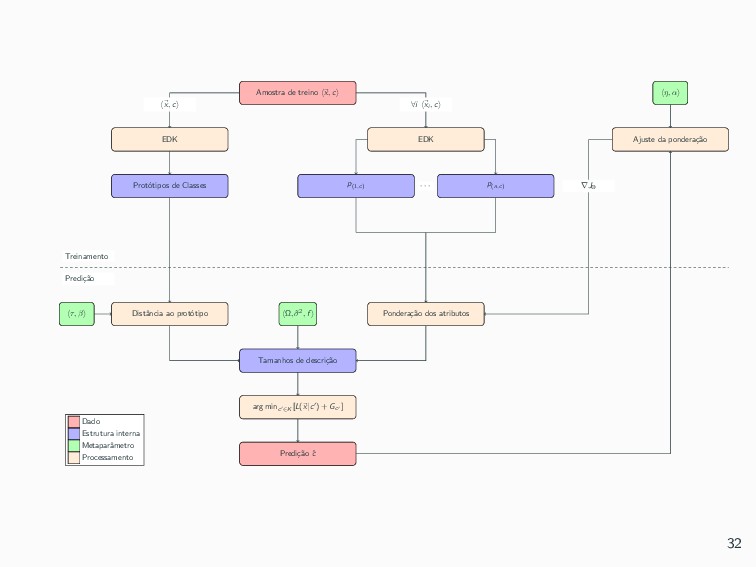{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Referências [1] Almeida, T. A. & Yamakami, A. (2012a). Advances](https://files.speakerdeck.com/presentations/ba679853f6d44b7aa864cbd6490d44ee/slide_85.jpg){kind=link}
![[6] Braga, I. A. & Ladeira, M. (2008). Filtragem adaptativa](https://files.speakerdeck.com/presentations/ba679853f6d44b7aa864cbd6490d44ee/slide_86.jpg){kind=link}
![[12] Ferreira, J., Matos, D. M., & Ribeiro, R. (2016).](https://files.speakerdeck.com/presentations/ba679853f6d44b7aa864cbd6490d44ee/slide_87.jpg){kind=link}
![[17] McLachlan, G. & Peel, D. (2004). Finite mixture models,](https://files.speakerdeck.com/presentations/ba679853f6d44b7aa864cbd6490d44ee/slide_88.jpg){kind=link}
![[23] Silva, R. M., Almeida, T. A., & Yamakami, A.](https://files.speakerdeck.com/presentations/ba679853f6d44b7aa864cbd6490d44ee/slide_89.jpg){kind=link}