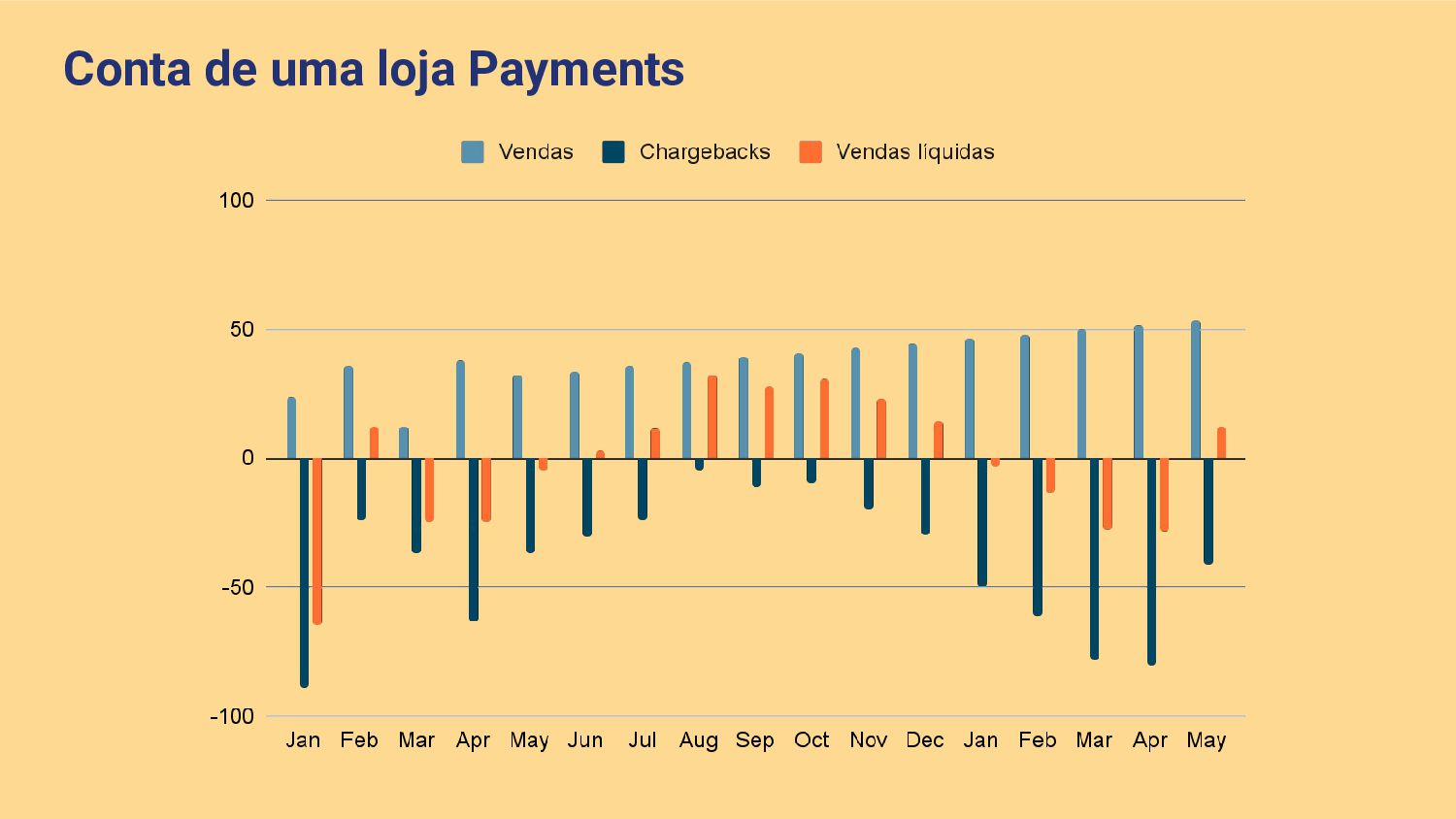
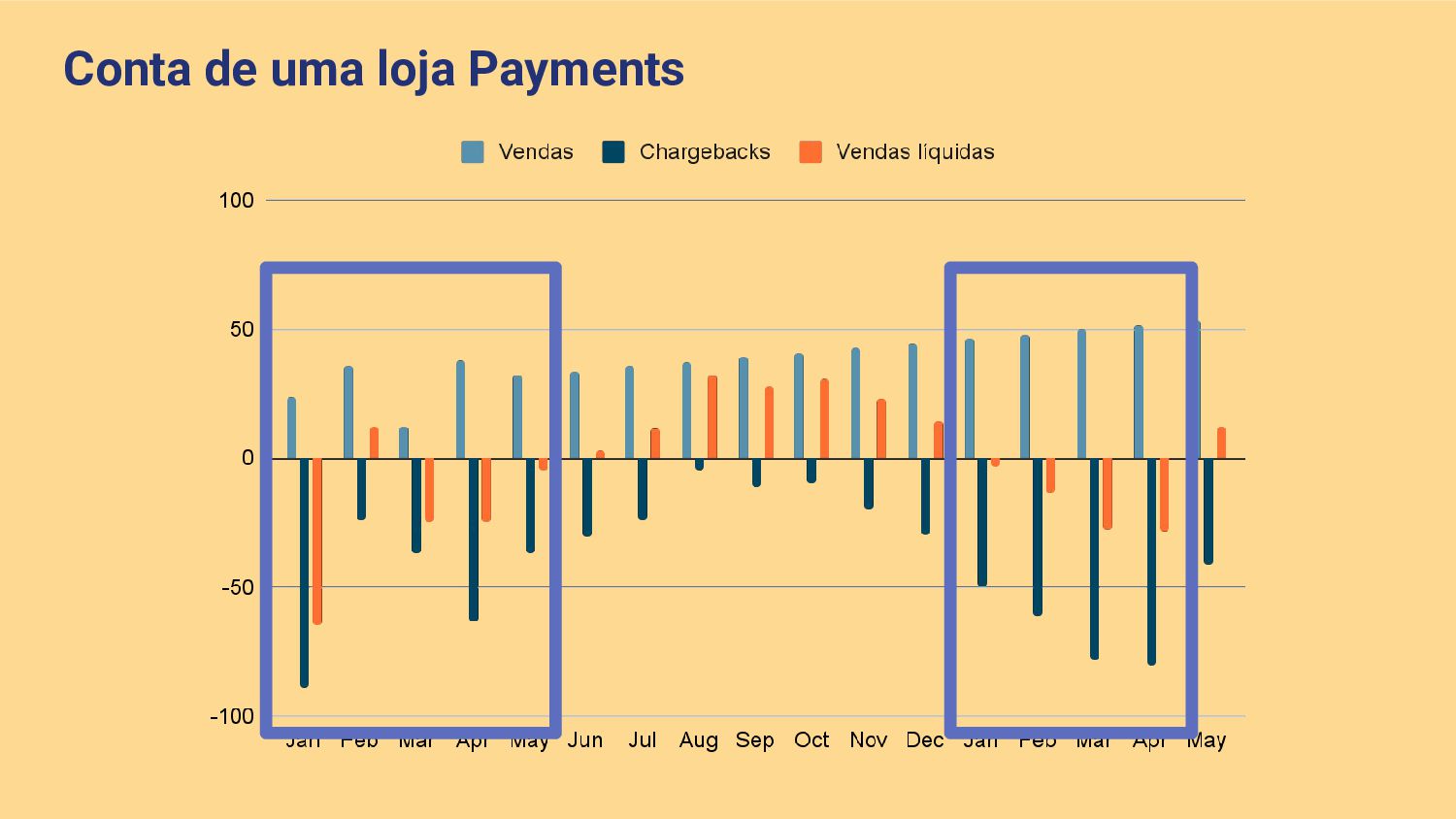
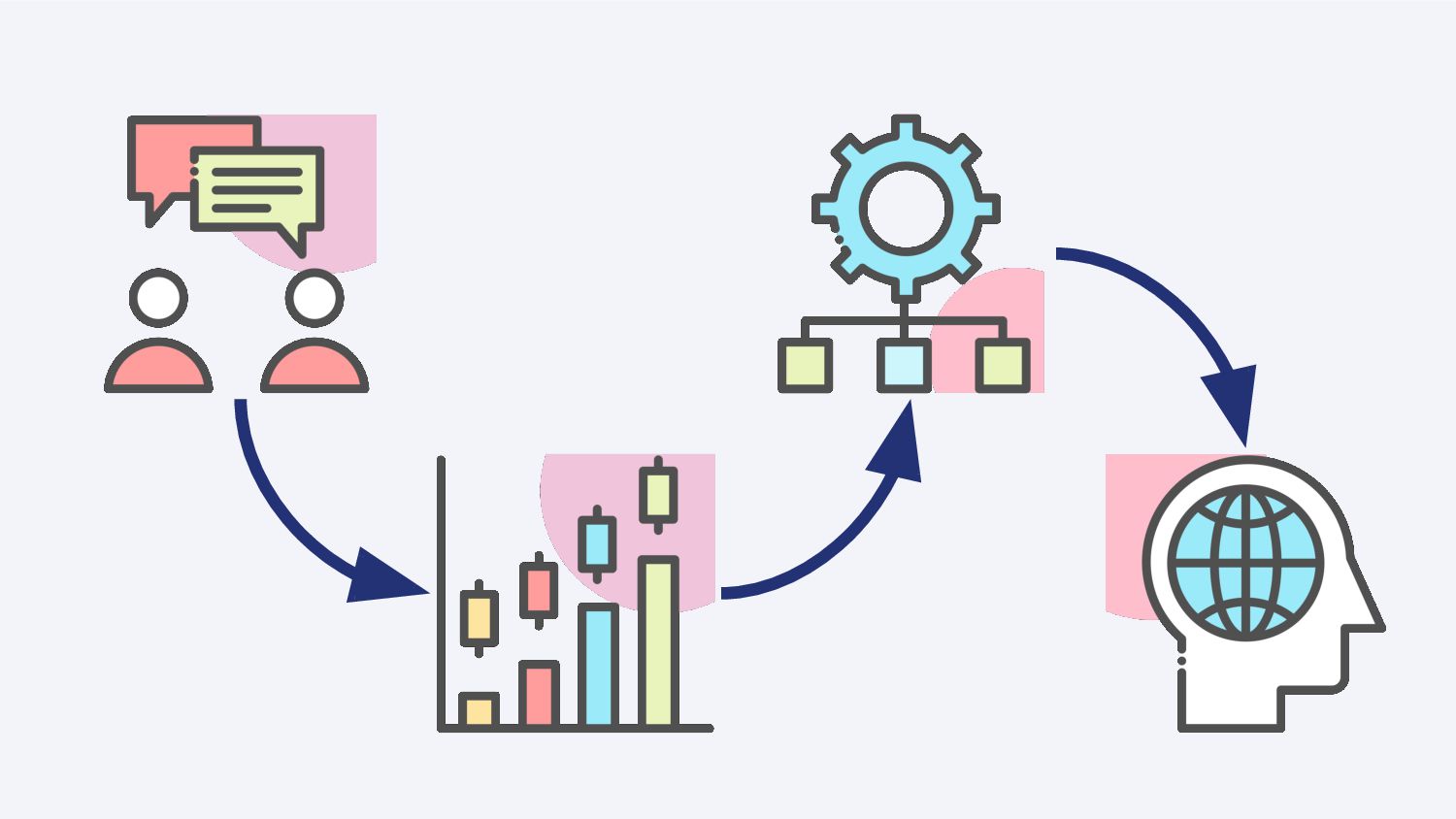
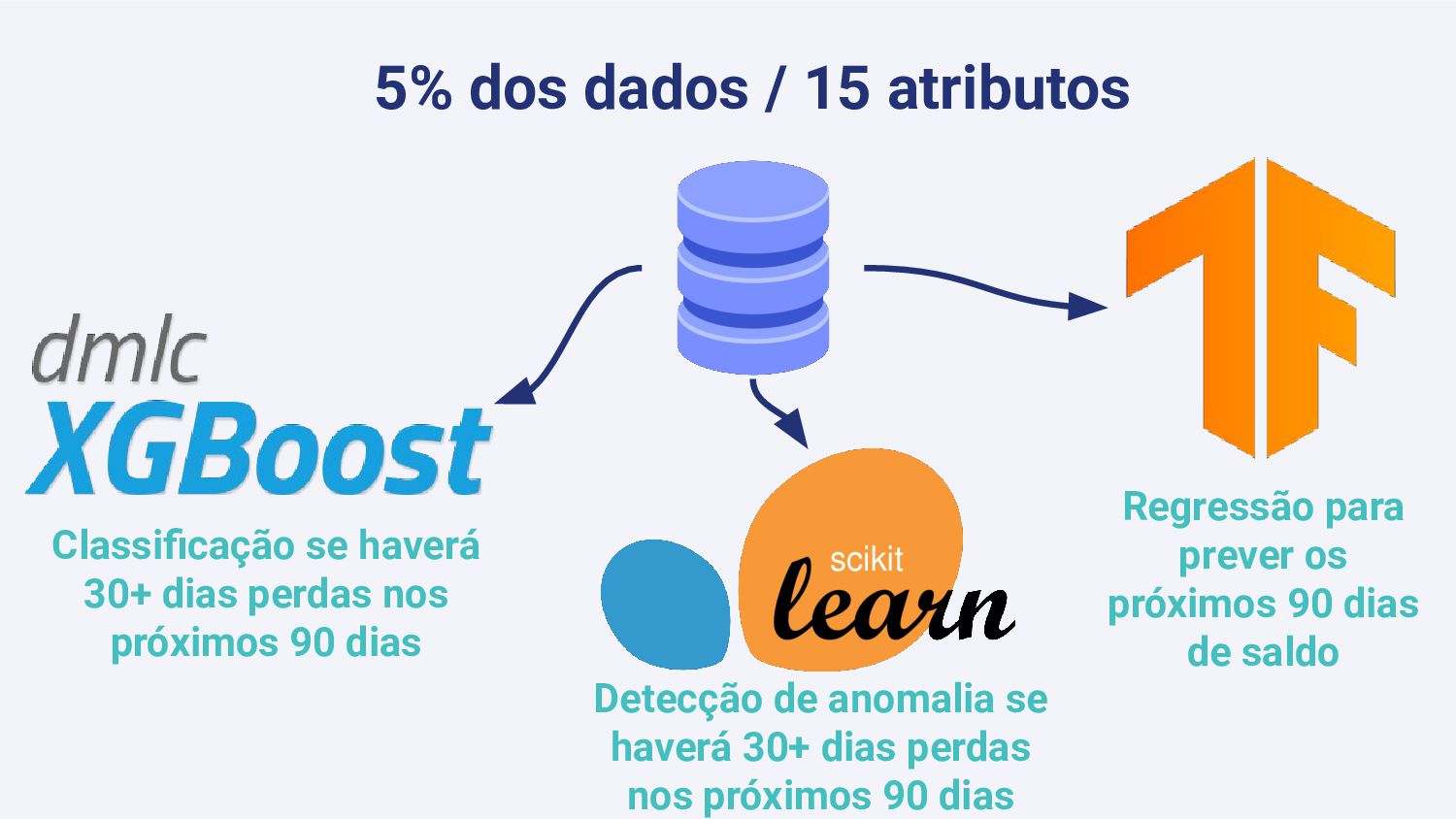
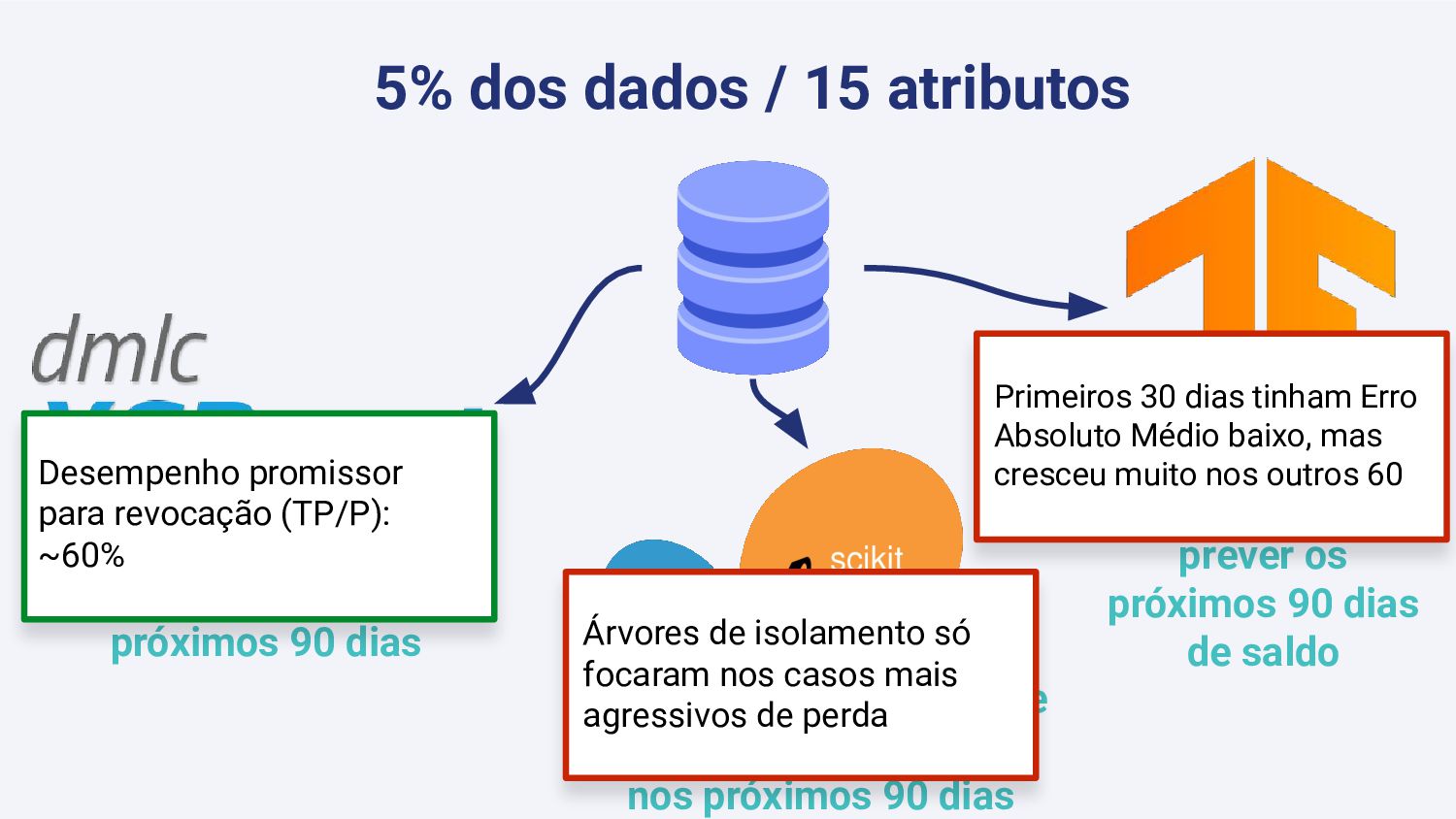
O Shopify Payments é um provedor de pagamentos que permite que lojas possam ser pagas em diversas formas. A maneira como o Payments é estruturado faz com que se lojas recebam chargebacks e retornos em larga escala, a perda monetária fique a cargo do Shopify. Para mitigar este problema, desenvolvemos um modelo de Aprendizado de Máquina para prever perdas em janelas de 3 meses. Nessa palestra abordaremos com base nesse exemplo prático, como Aprendizado de Máquina com enfoque em modelos e com enfoque na qualidade e volume de dados foi utilizado para previnir milhões de dólares em perdas.
Apresentação realizada para a 14ª edição da Semana da Computação e Tecnologia (SeCoT XIV).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
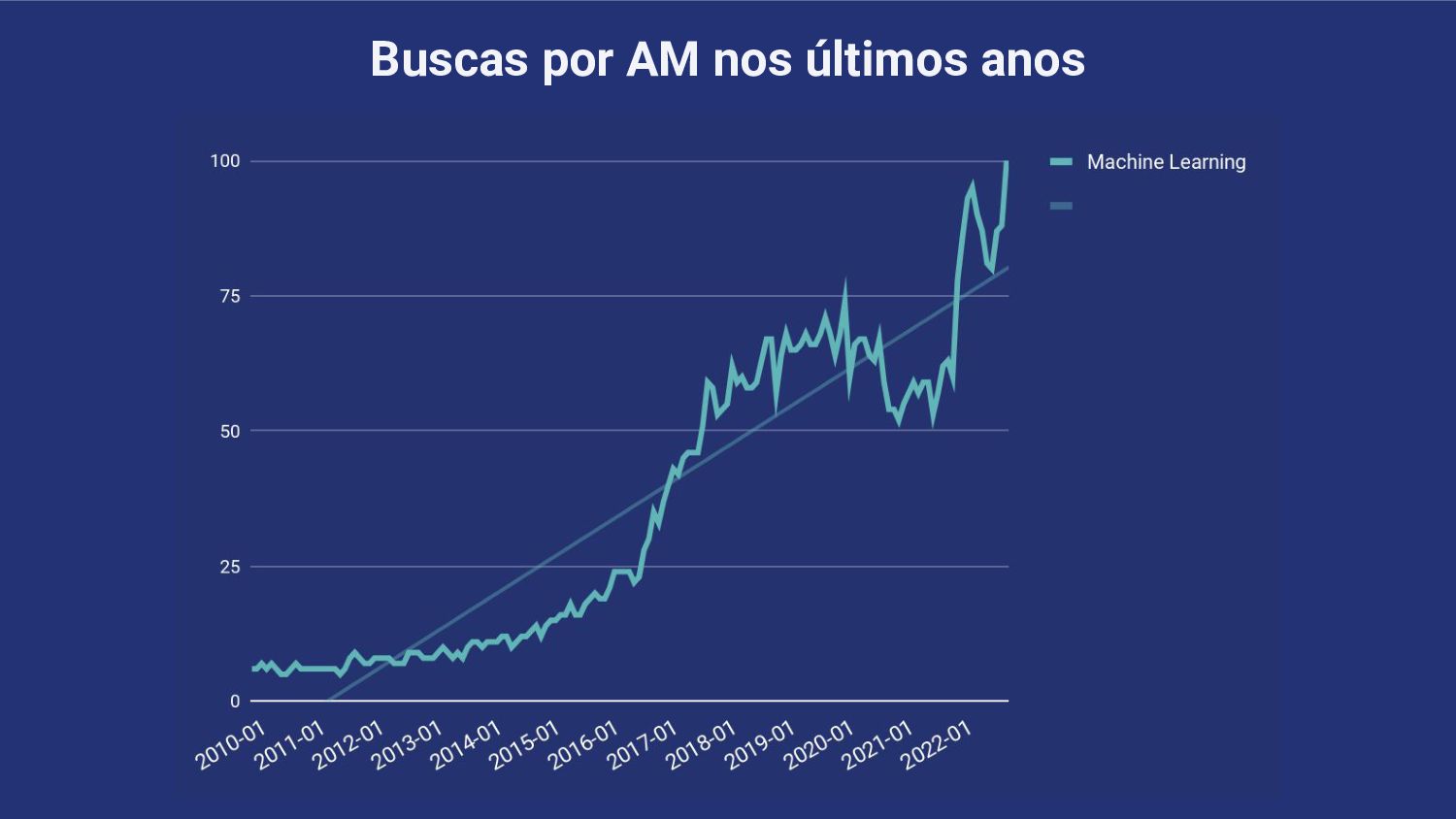{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
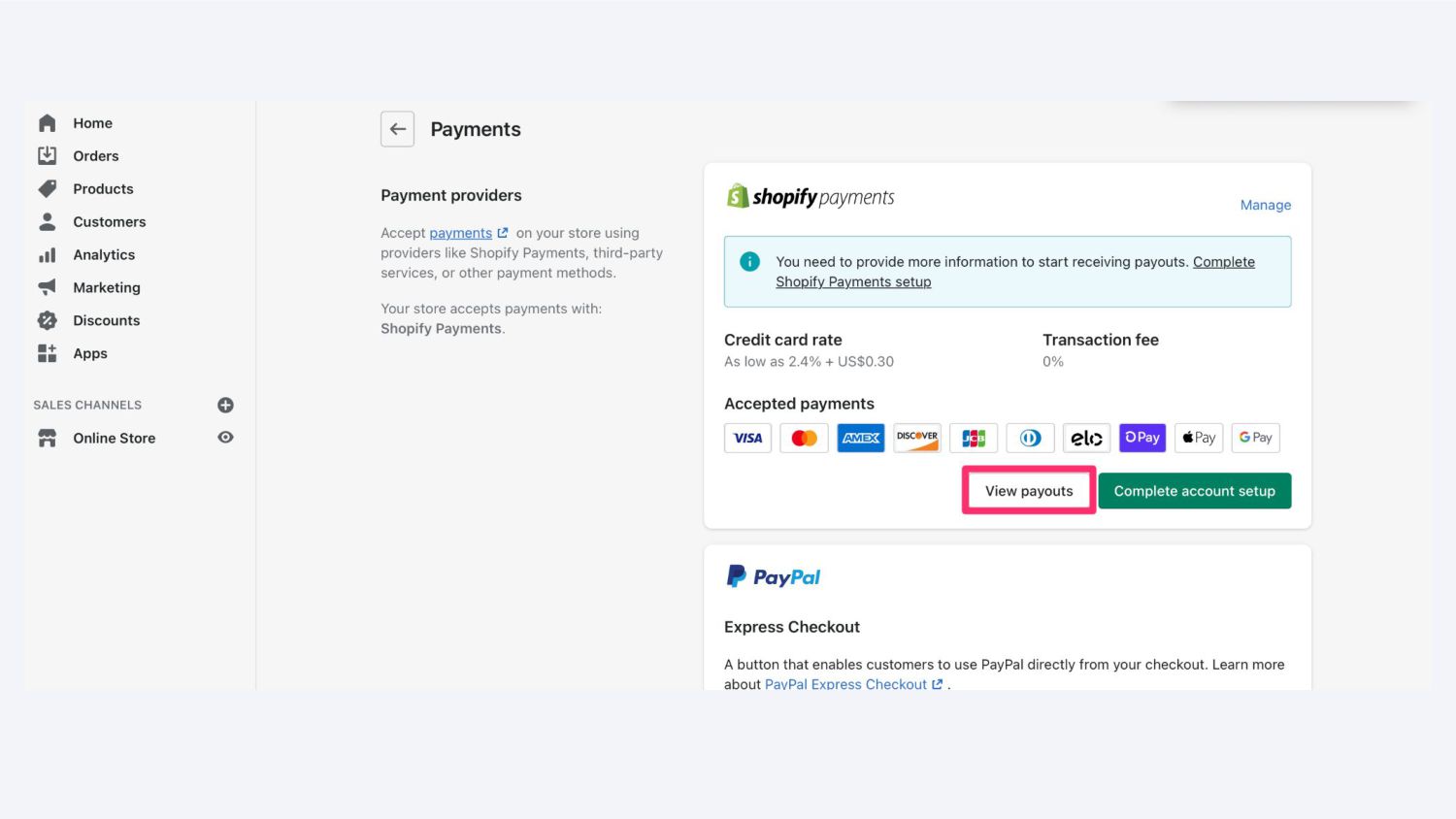{kind=link}
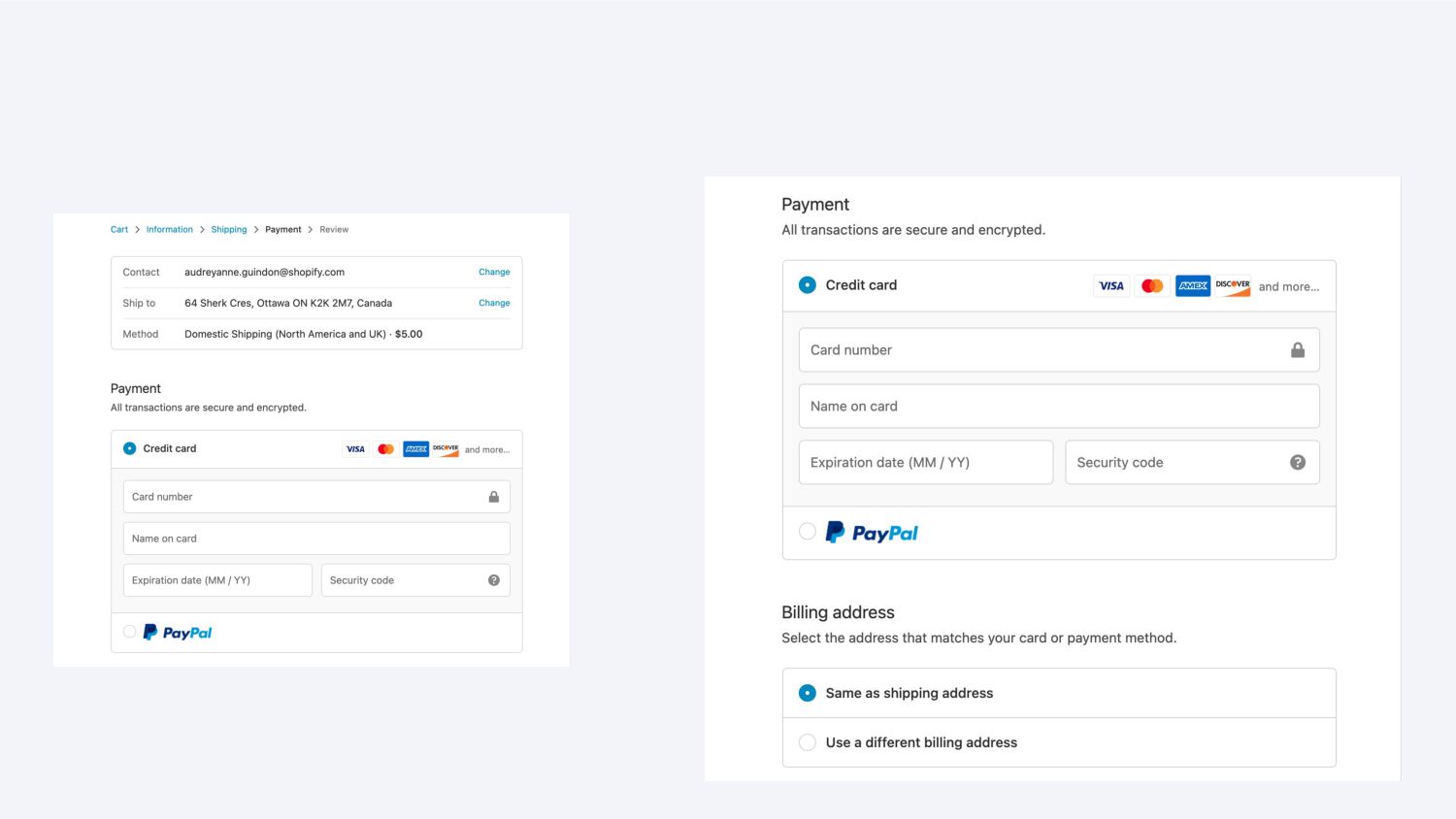{kind=link}
{kind=link}
{kind=link}
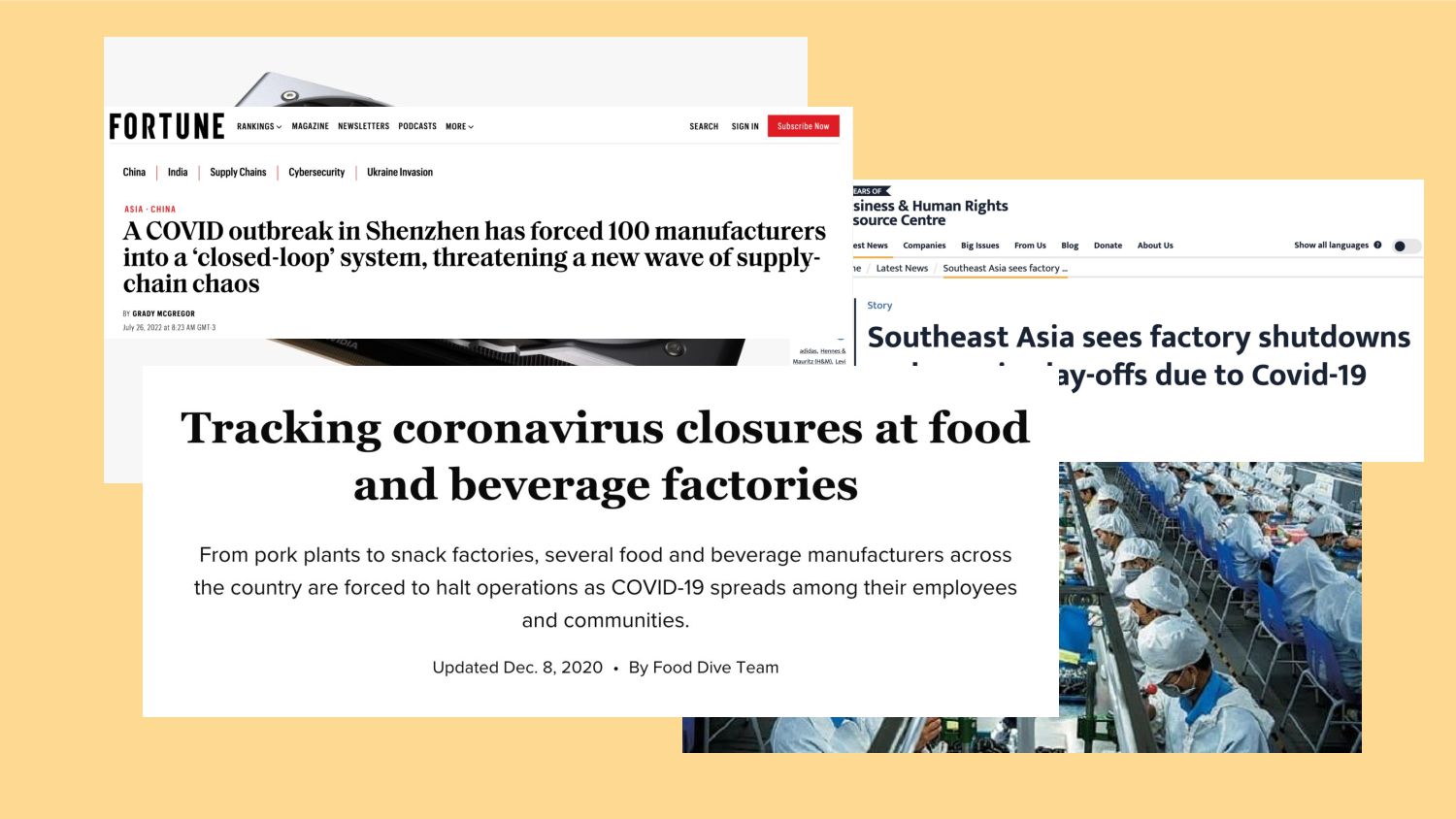{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
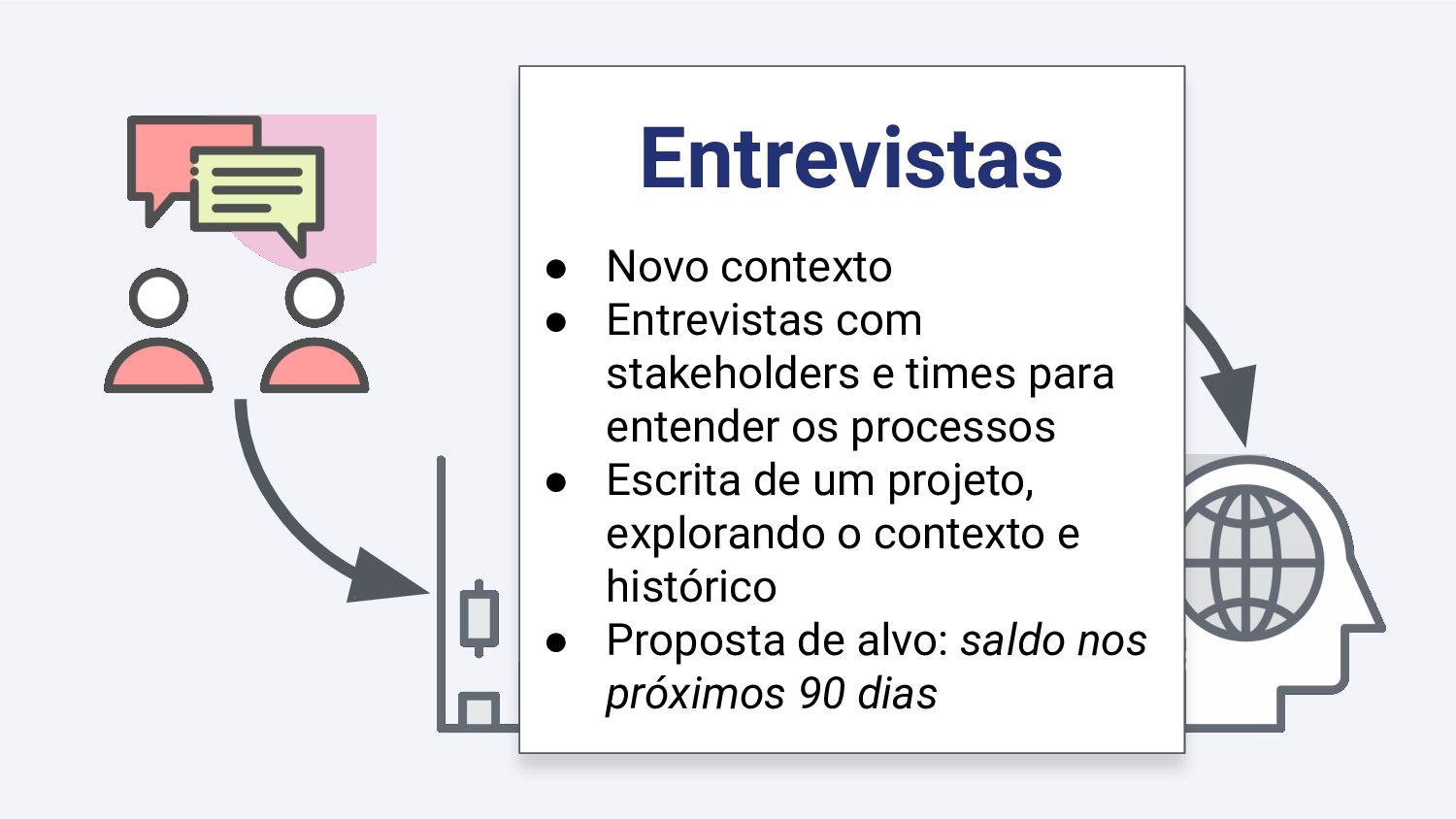{kind=link}
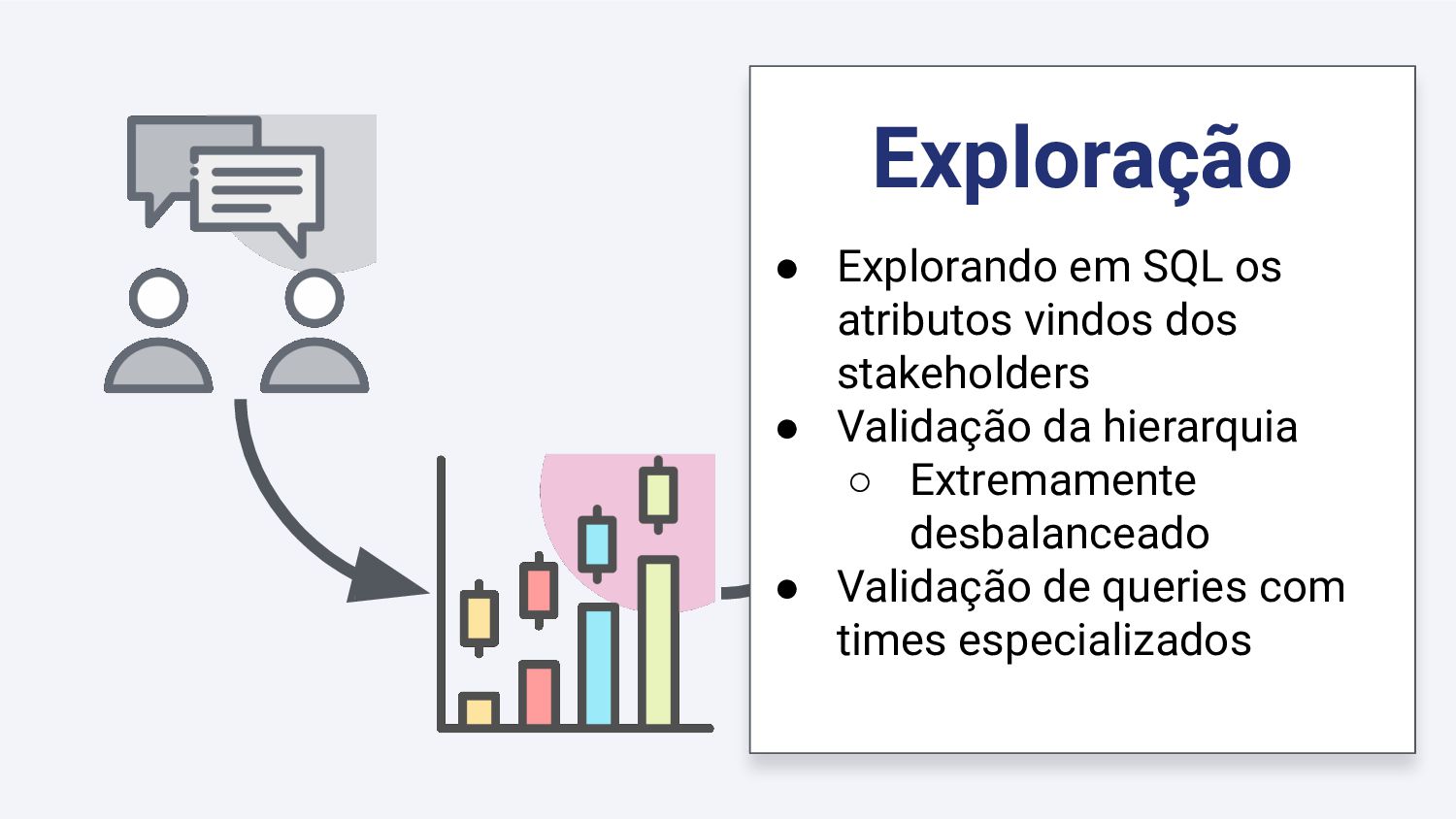{kind=link}
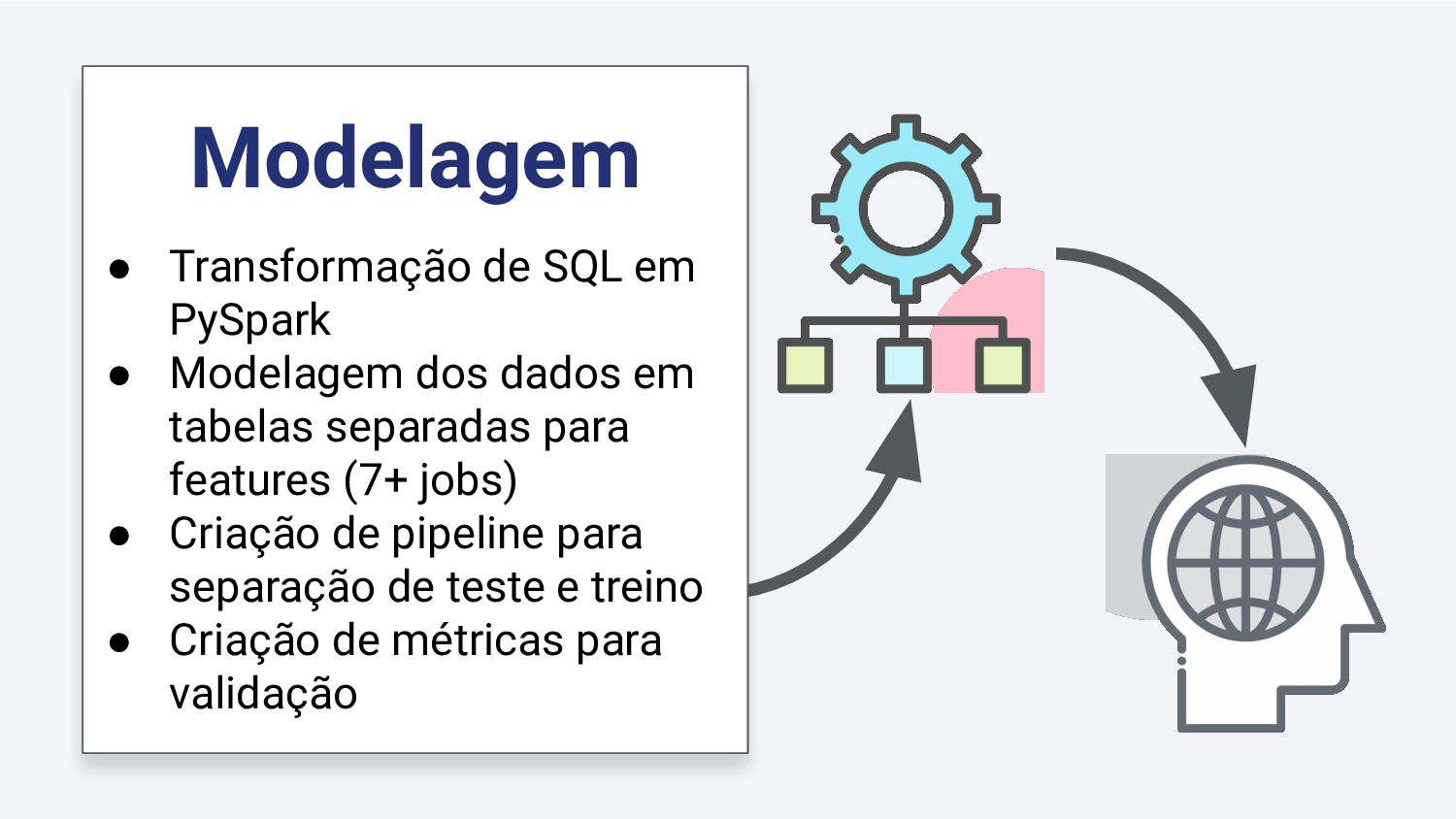{kind=link}
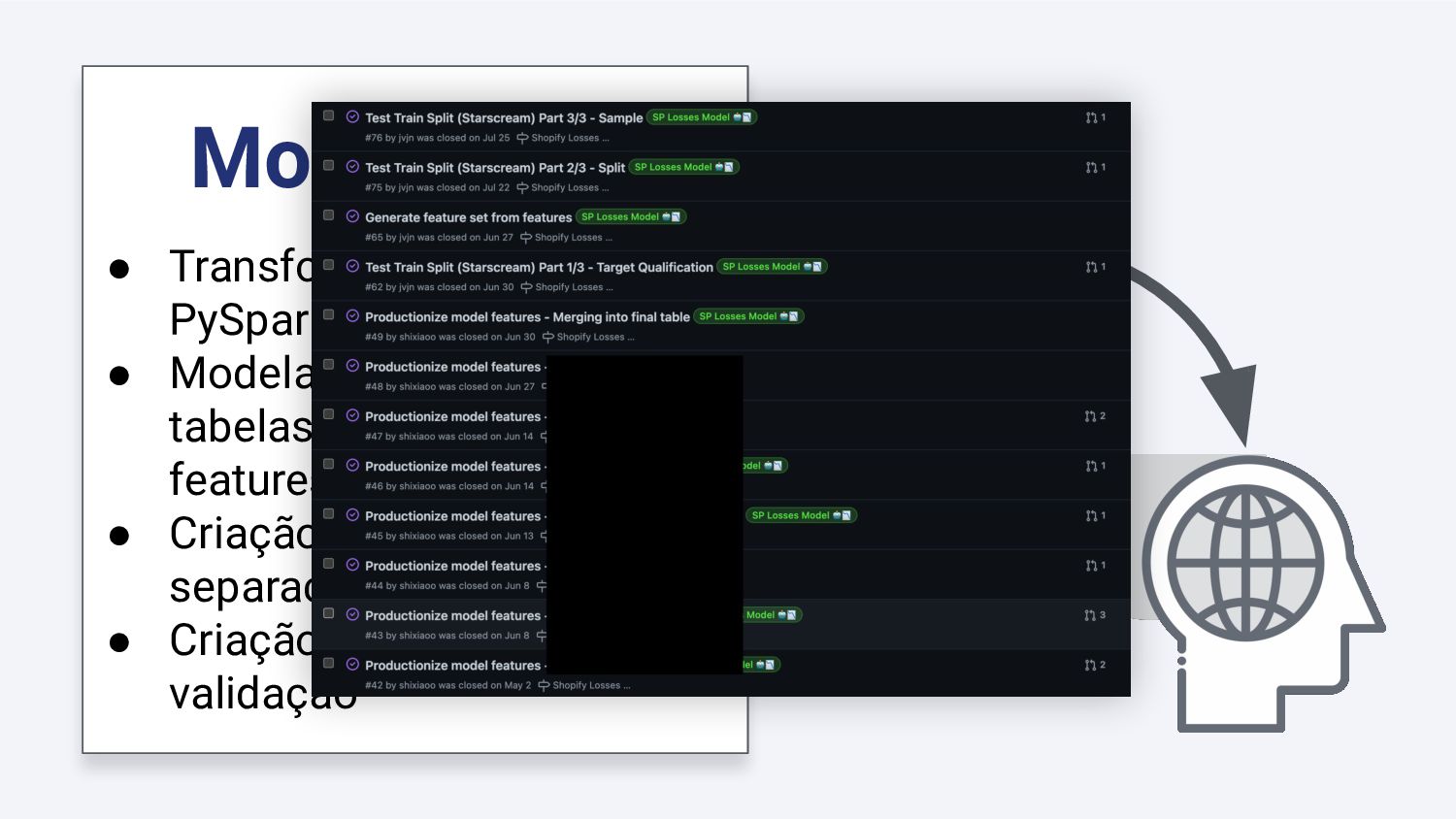{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
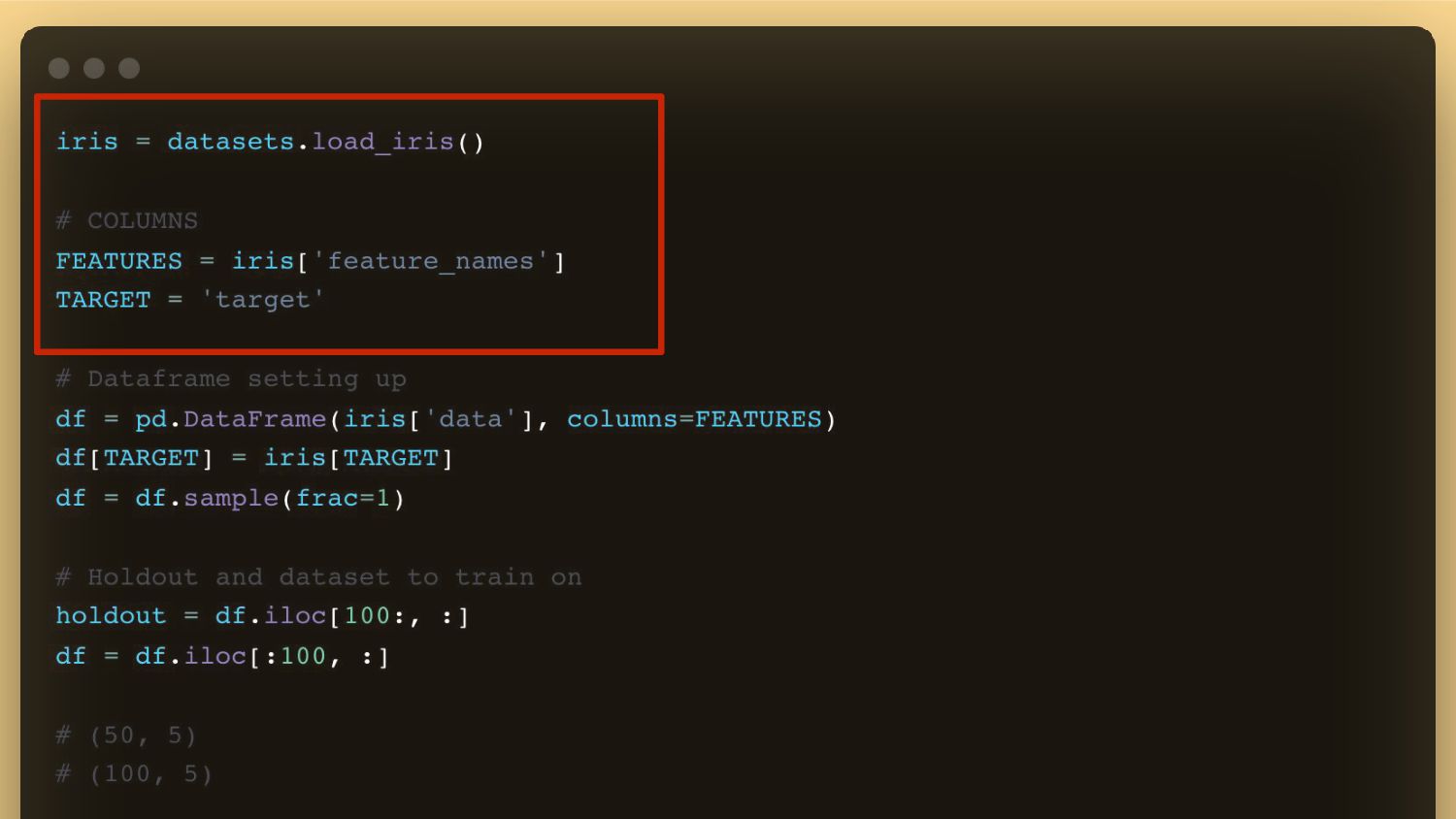{kind=link}
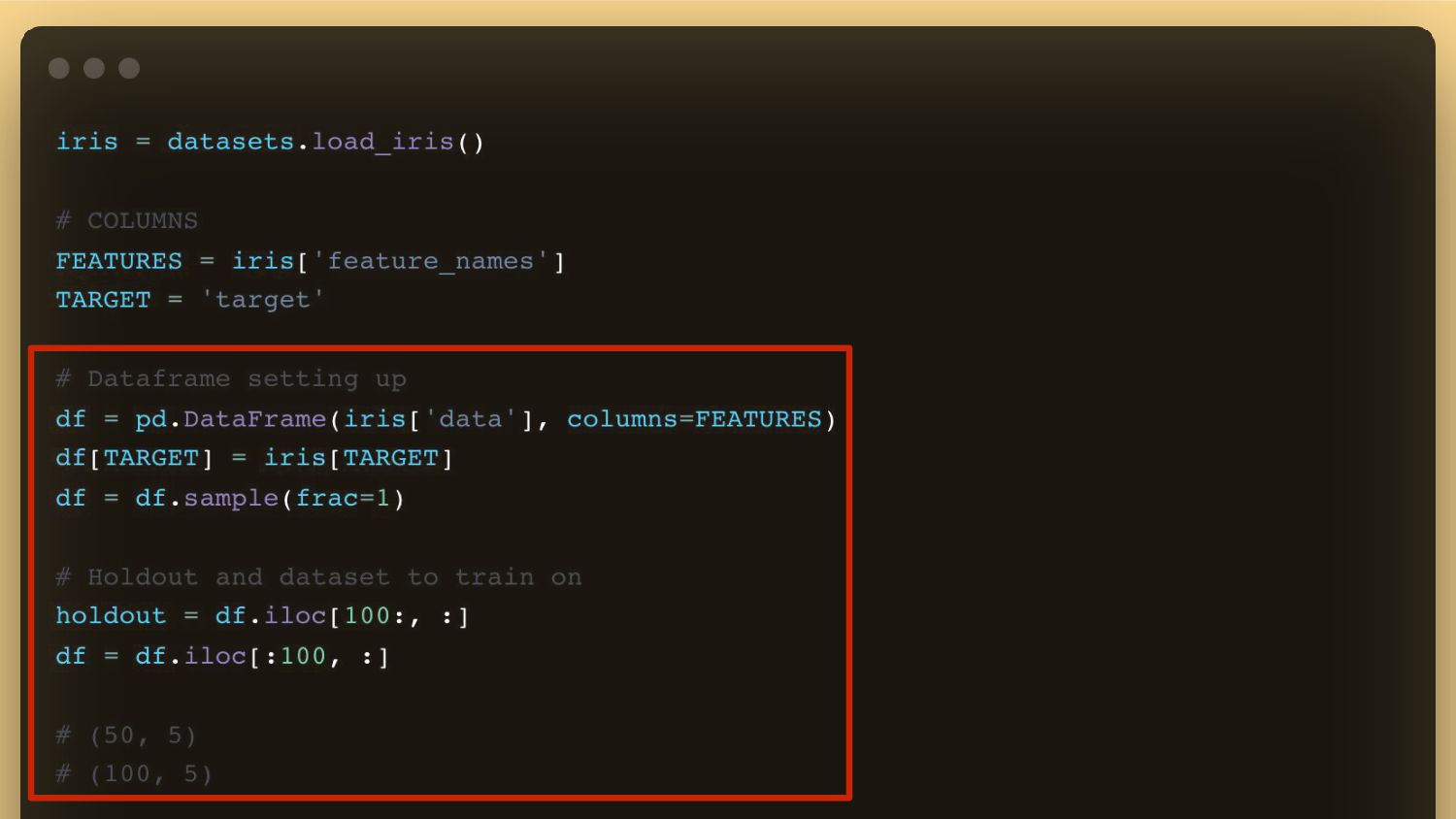{kind=link}
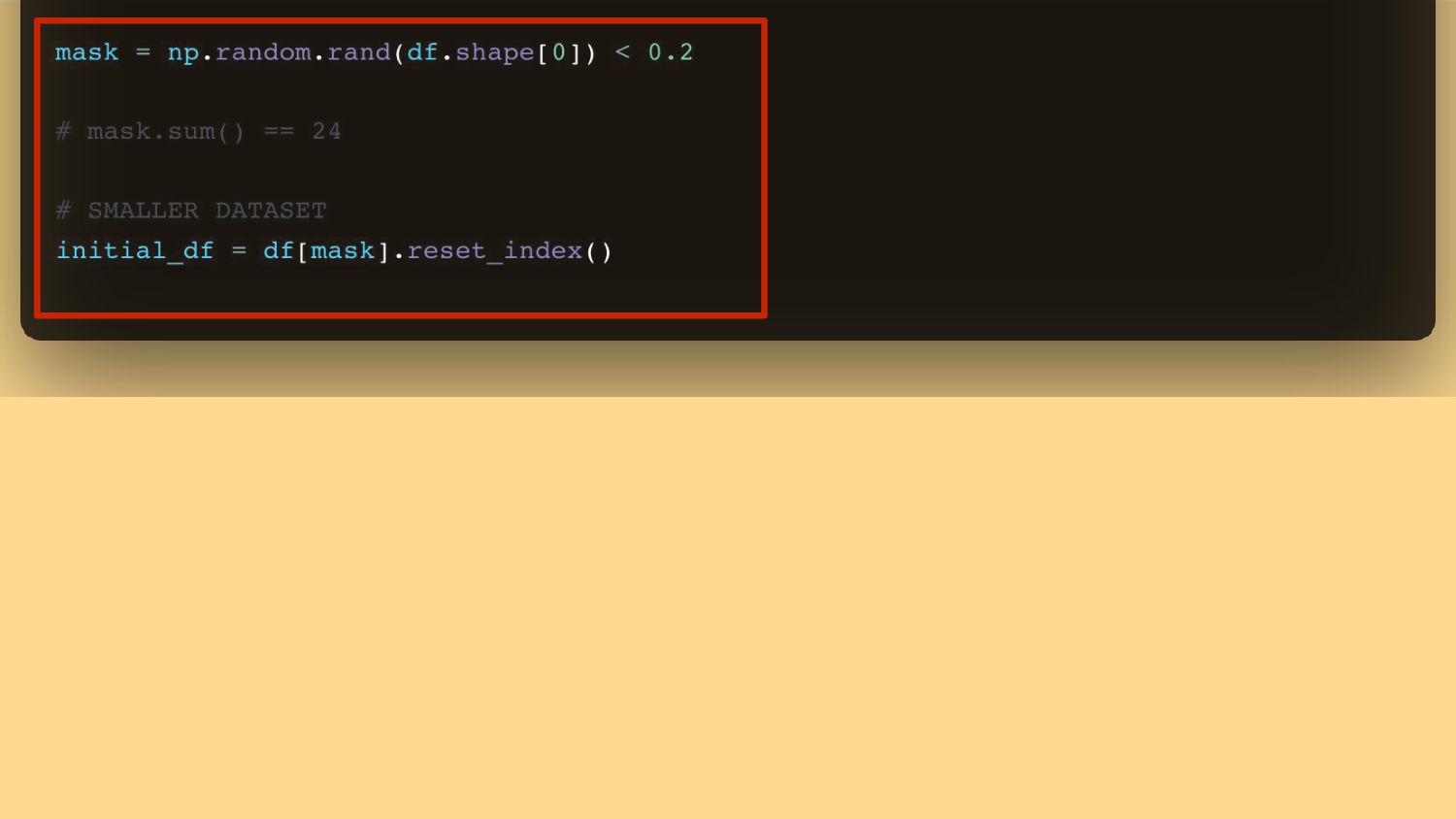{kind=link}
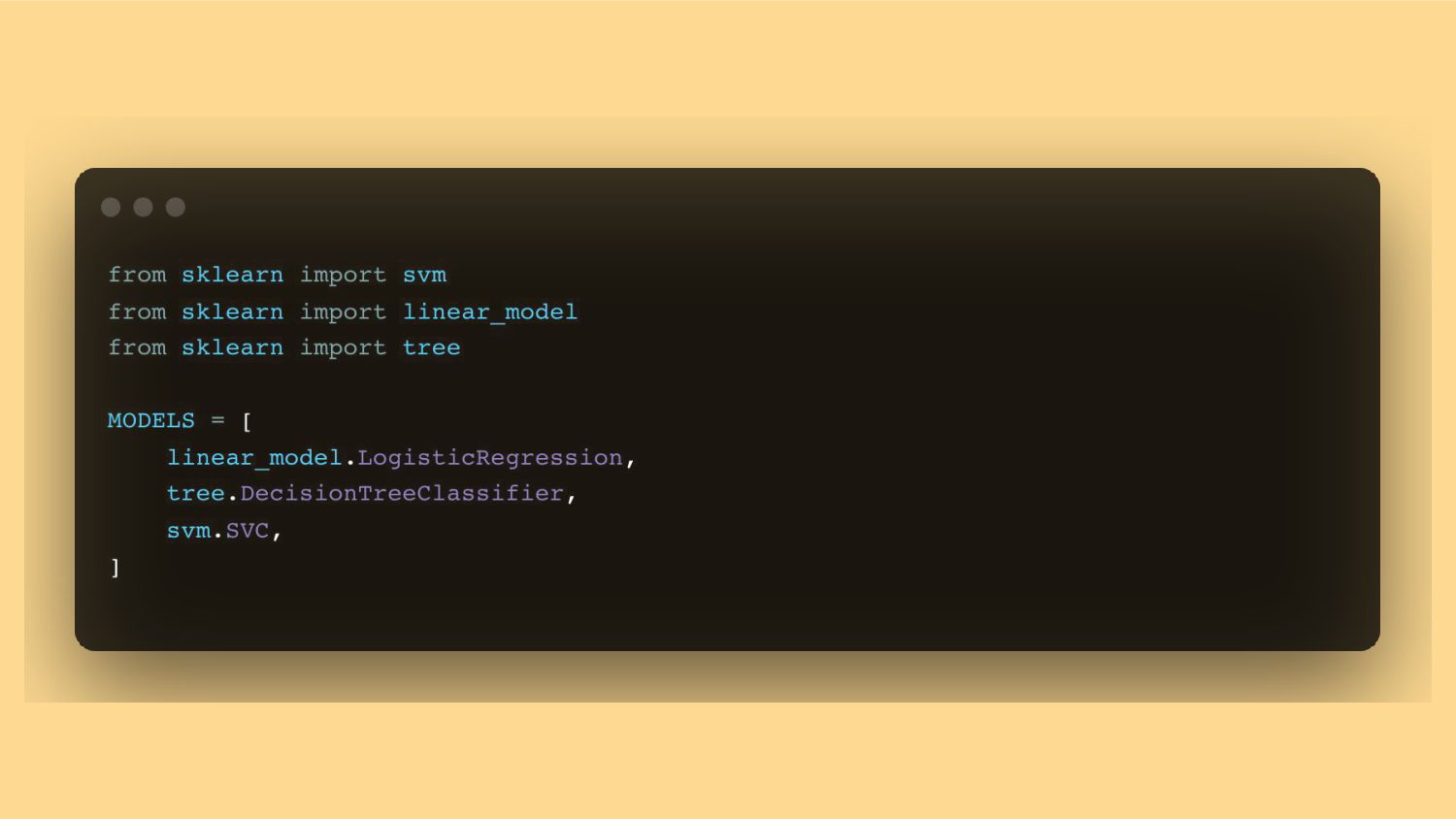{kind=link}
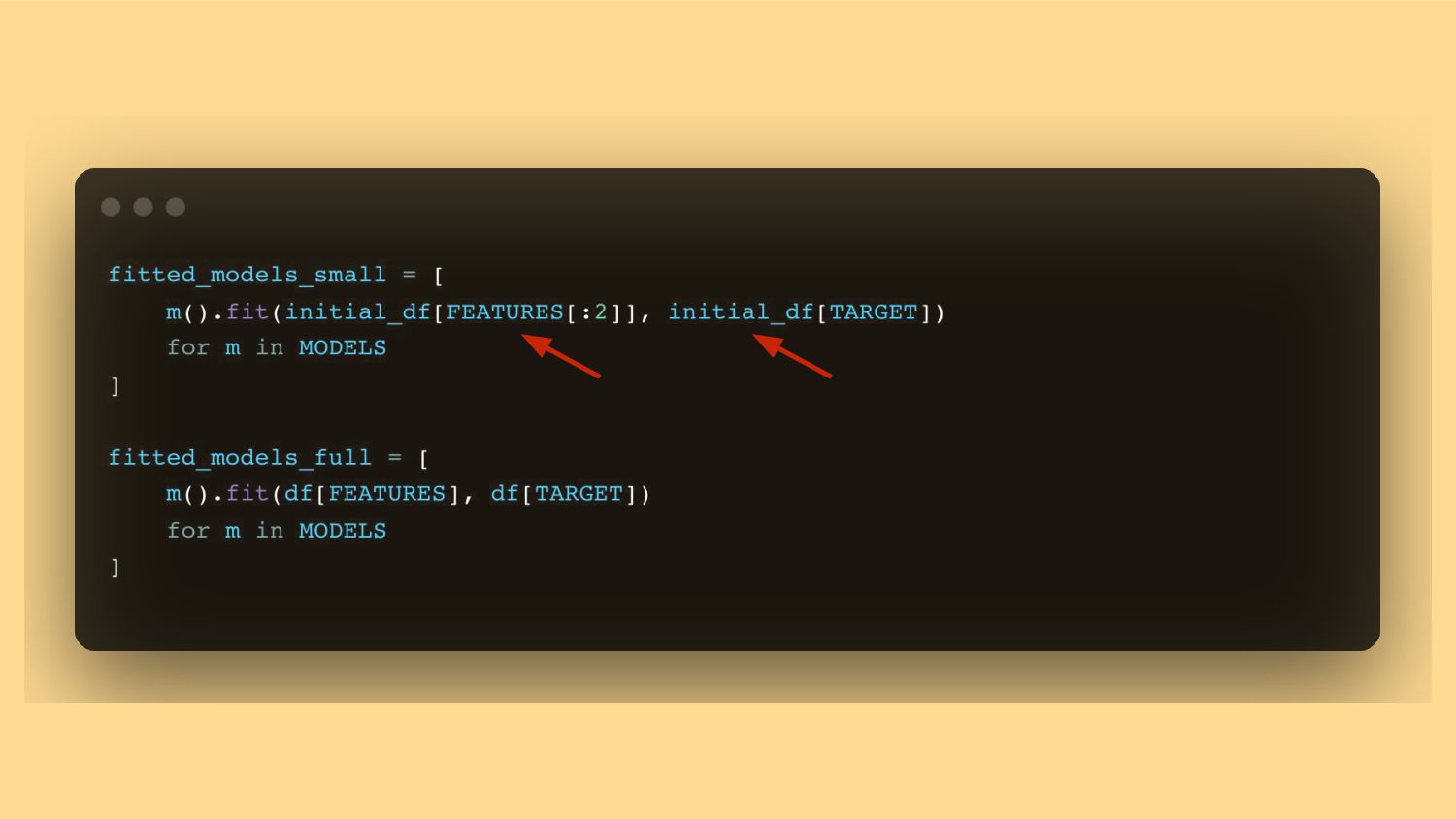{kind=link}
{kind=link}
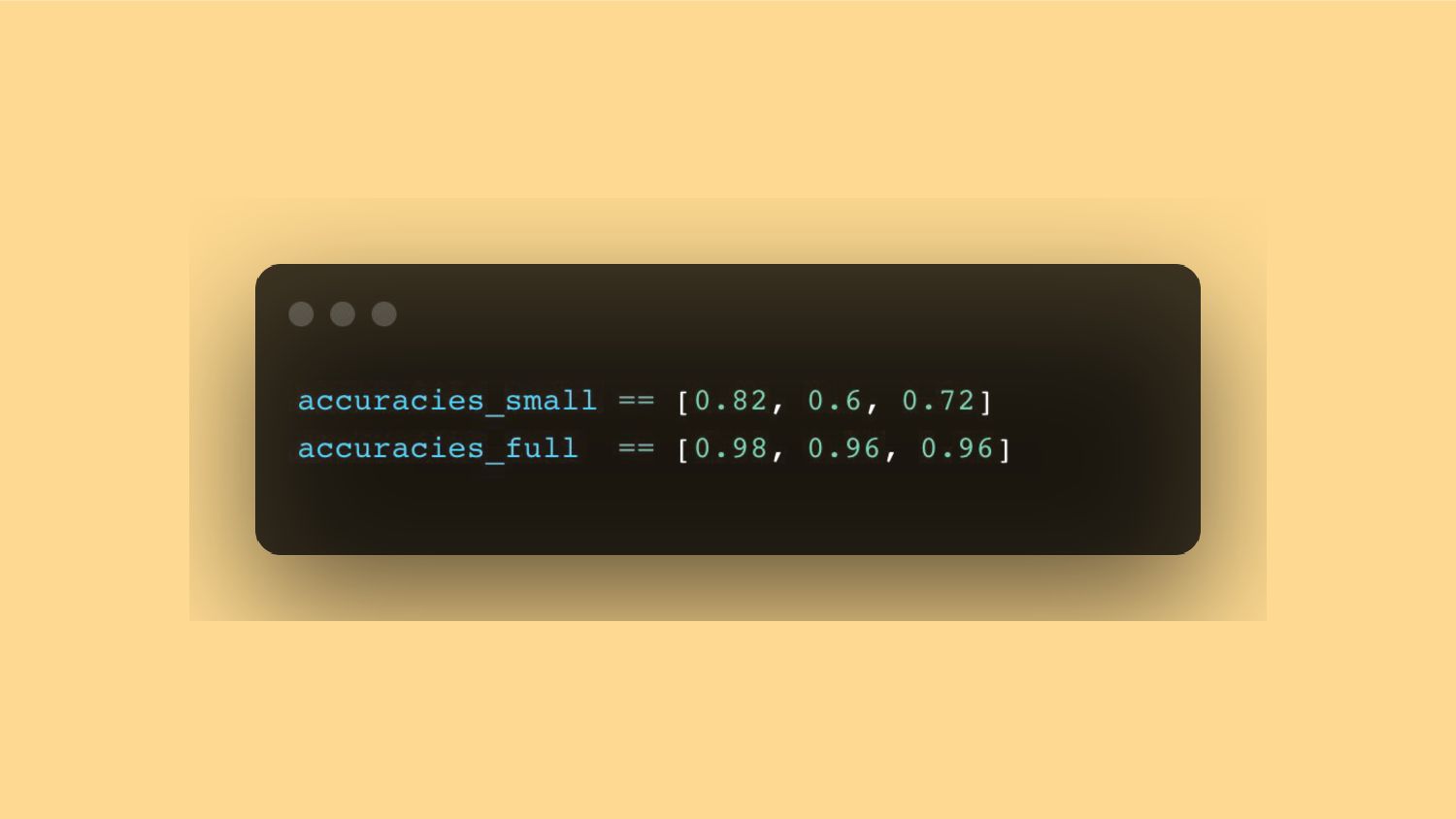{kind=link}
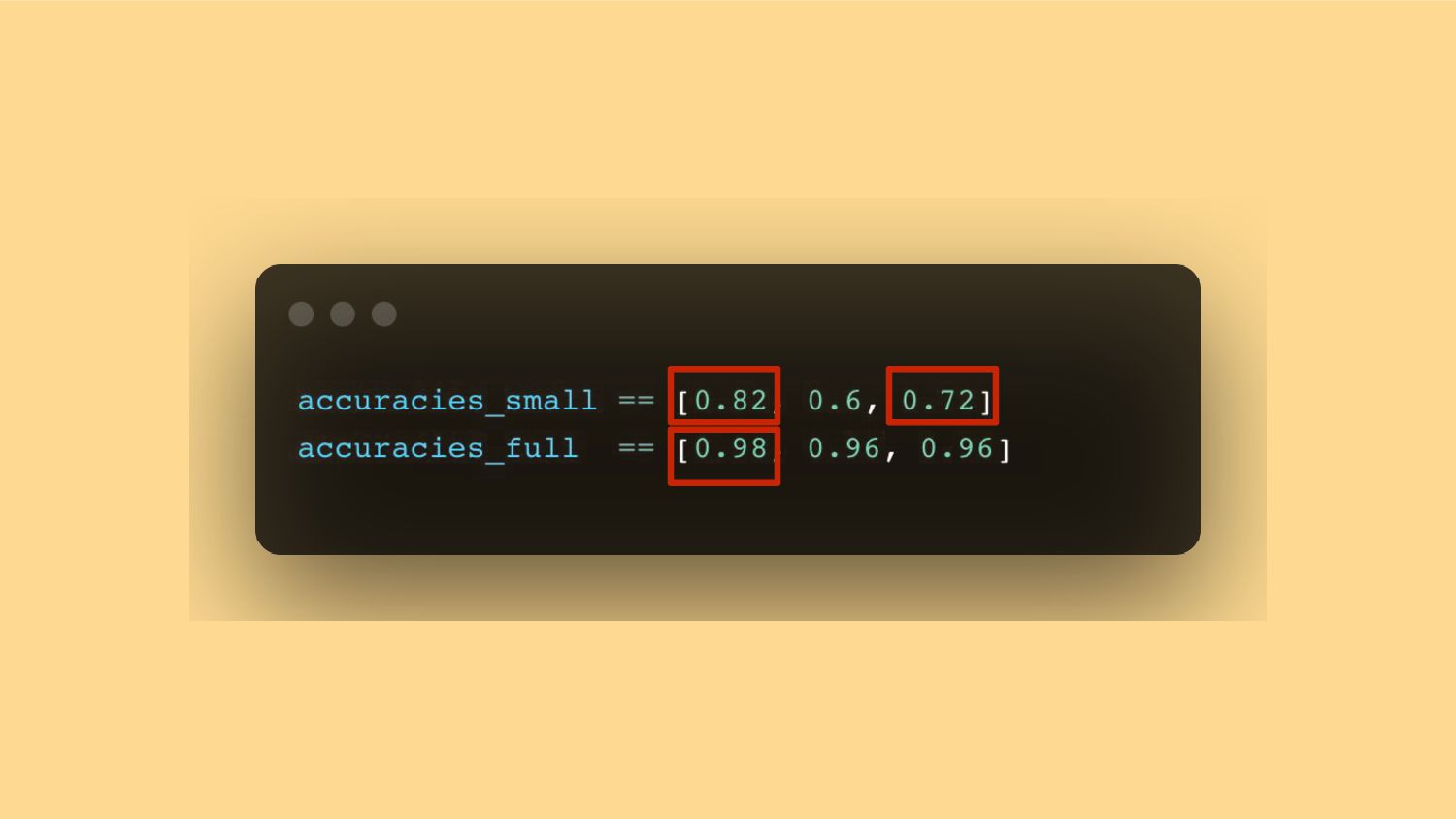{kind=link}
{kind=link}
{kind=link}