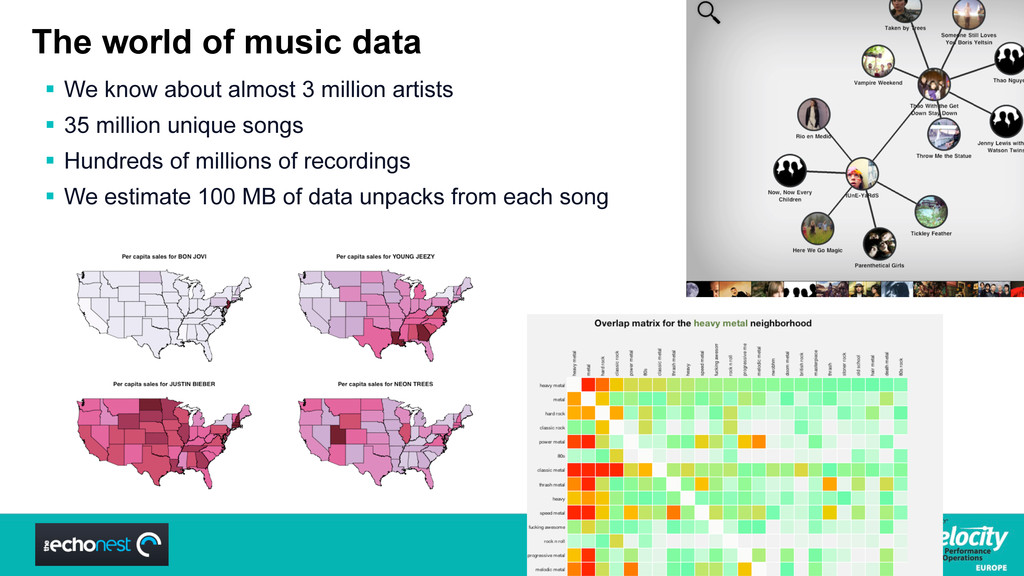
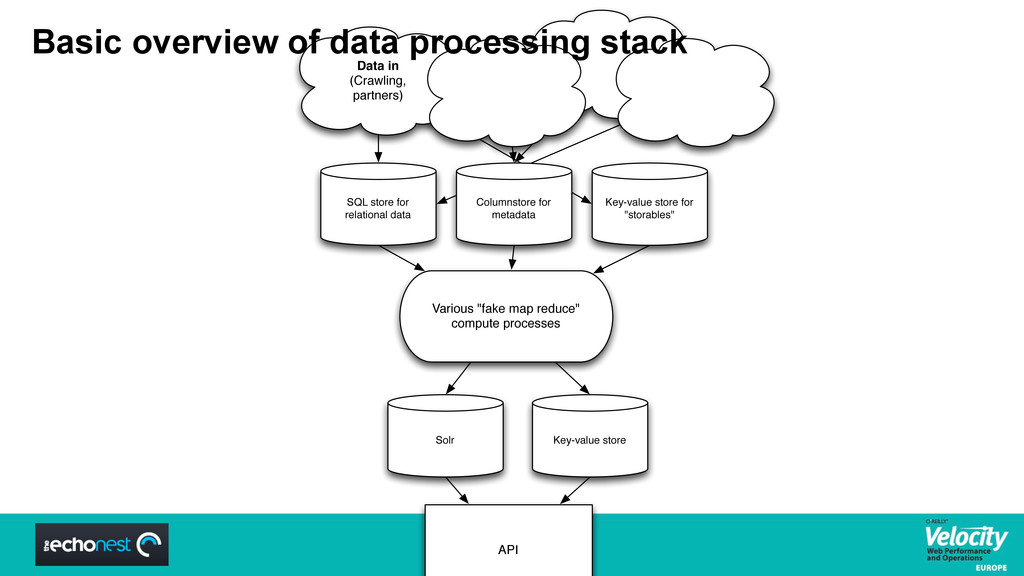
In the past few years, The Echo Nest has built the largest database of music anywhere – over 2 million artists and 30 million songs each with detailed information down to the pitch of each note in each guitar solo and every adjective ever said about your favorite new band. We’ve done it with a nimble and speedy custom infrastructure—web crawling, natural language processing, audio analysis and synthesis, audio fingerprinting and deduplication, and front ends to our massive key-value stores and text indexes. Our real time music data API handles hundreds of queries a second and powers most music discovery experiences you have on the internet today, from iHeartRadio and Spotify to eMusic, VEVO, MOG and MTV.
During this talk, the Echo Nest’s co-founder and CTO will run through the challenges and solutions needed to build music recommendation, search and identification at “severe scale,” with the constraint that most of our results are computed on the fly with little caching. It’s hard to store results when data about music changes on the internet so quickly as do the tastes and preferences of your customers’ listeners.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ email: [email protected] Thanks: Tyler Williams, Hui Cao, Aaron](https://files.speakerdeck.com/presentations/507d8d11e7912c000205aa27/slide_46.jpg){kind=link}