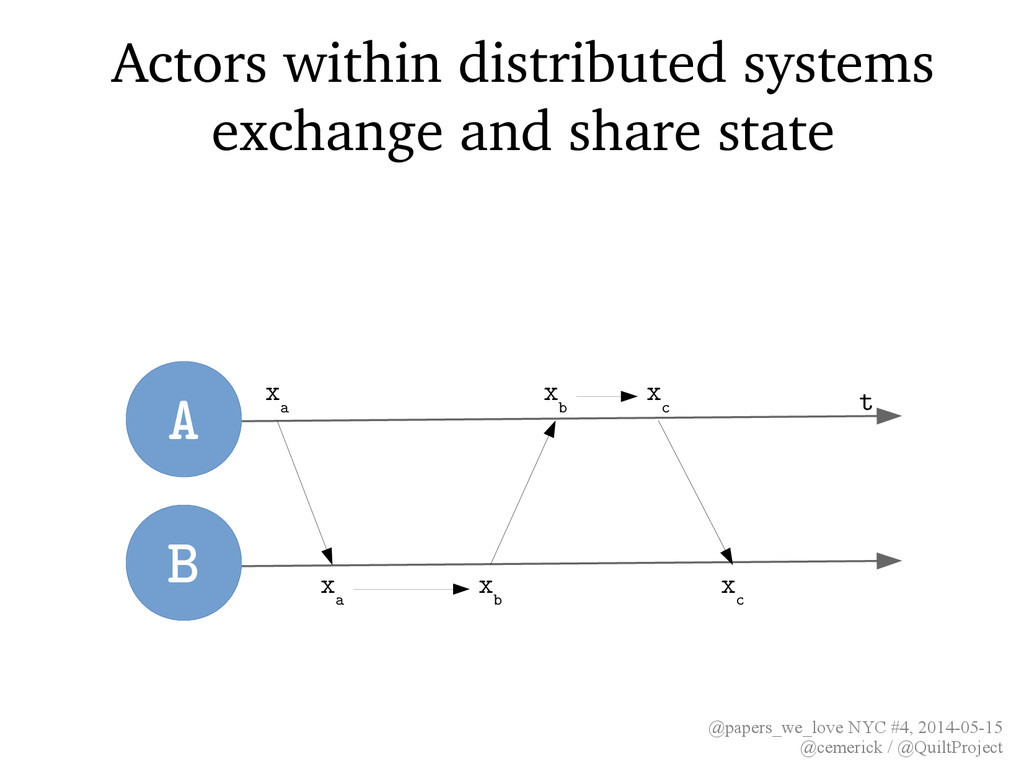
15, 2014 for your edification and entertainment, an audiovisual précis of: A comprehensive study of Convergent and Commutative Replicated Data Types by Shapiro, Preguiça, Baquero, and Zawirski (2011)
is this guy?” • Not going to follow the order of topics from the paper exactly • Key topics will be introduced along with section numbers from the paper (e.g. §4.3) • I'll be drawing upon materials used in the authors' presentations related to this paper (see references for links)
paper – Motivating problem – Theoretically- and algebraically-sound solution – Specification of practical data type designs – Challenges – Related work, further reading • Impact outside of academia • Questions & discussion
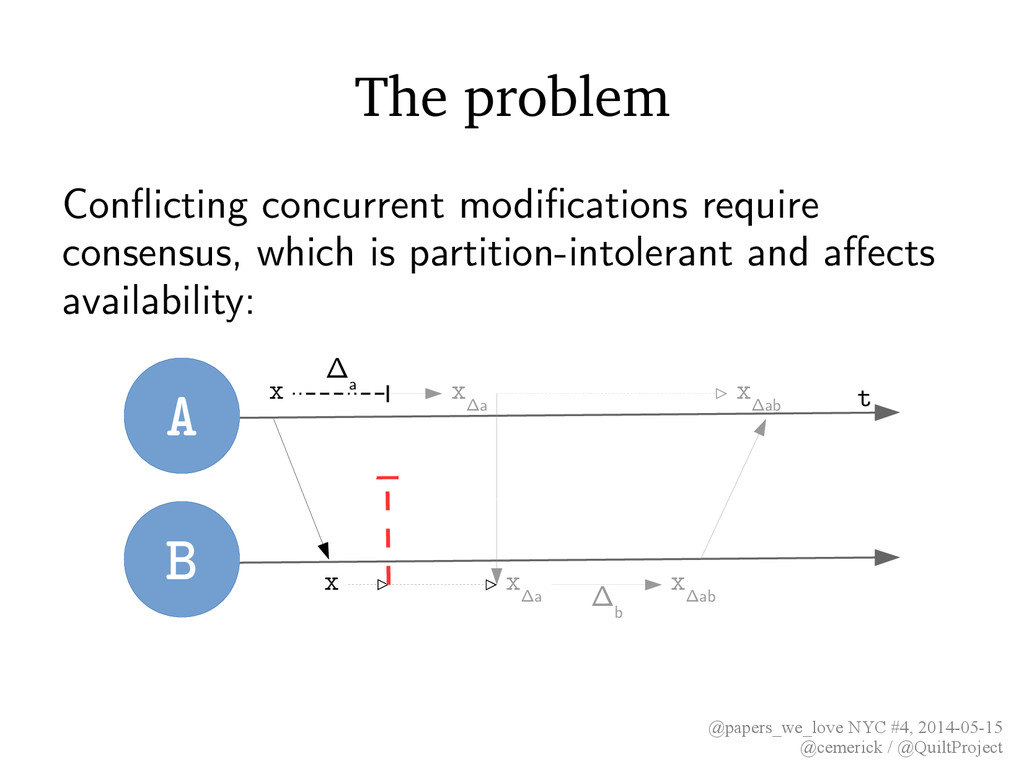
databases, Redis, consensus services (Paxos/Raft) • Global consensus → consistency • Total order of all events • Very expensive & constrains availability A t B x x x Δab x Δa x Δab Δ b Δ a x Δa ✝As well as strict serializability, which has even stronger guarantees.
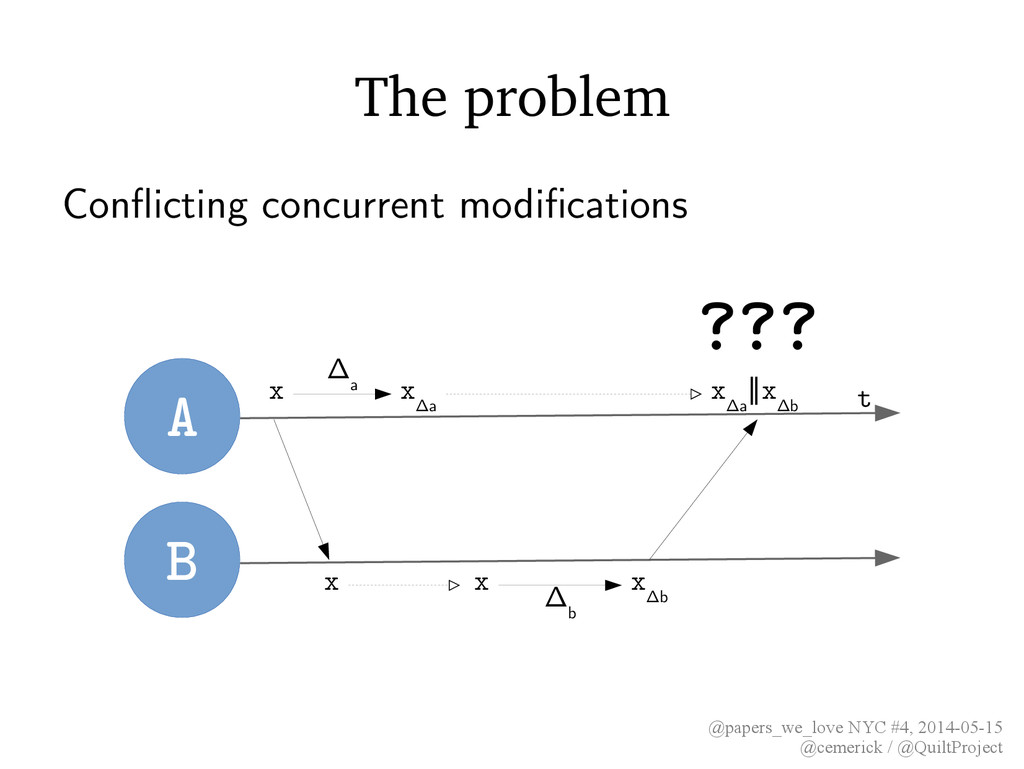
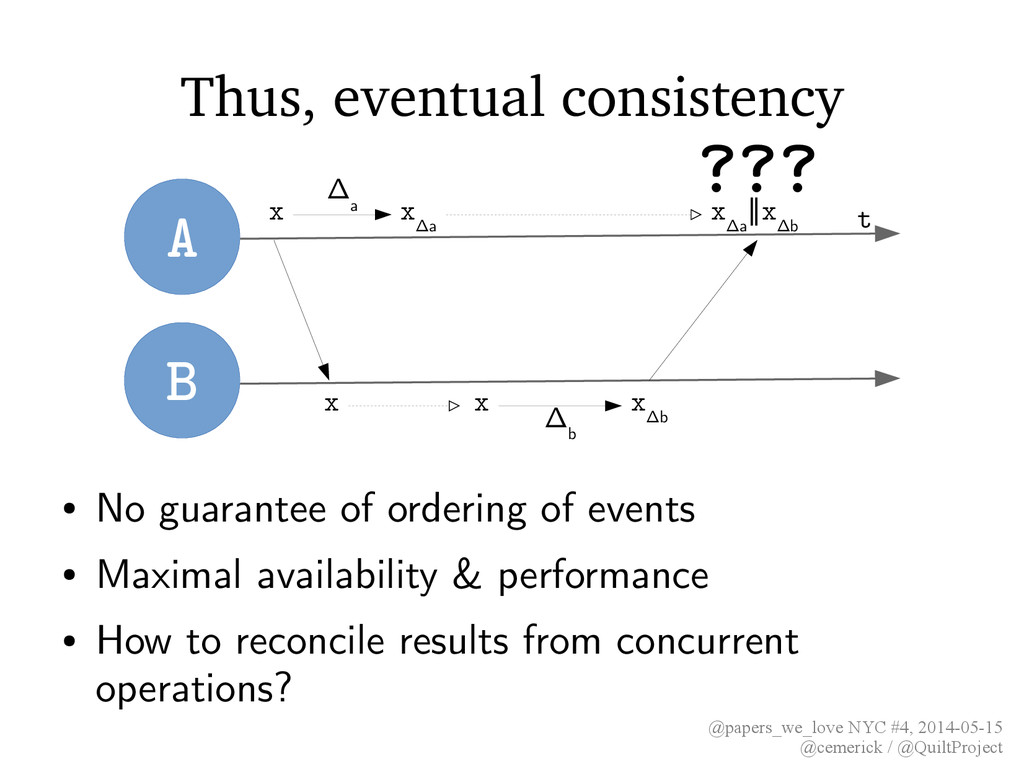
• No guarantee of ordering of events • Maximal availability & performance • How to reconcile results from concurrent operations? A t B x x x Δb x Δa x Δa ∥x Δb Δ b Δ a x ???
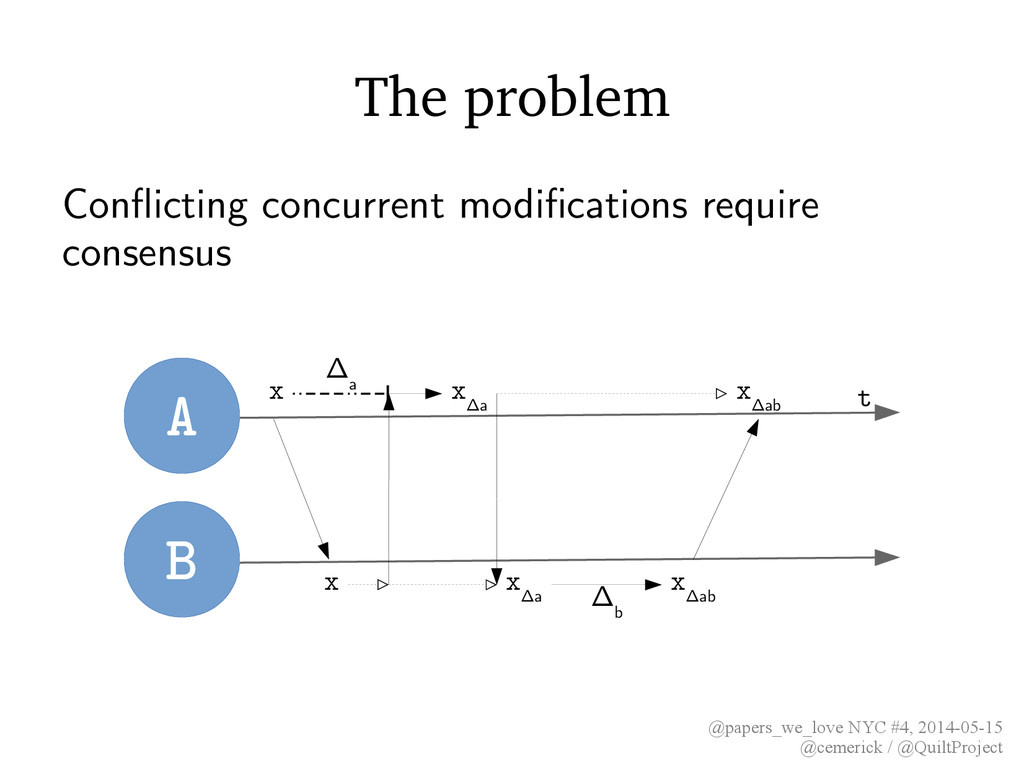
results of concurrent operations? • “Background” (deferred) consensus – Post-hoc resolution or rollback of conflicting updates • This is what we do today, all the time! – Resolving CouchDB conflicts and Riak siblings within applications – Merging (semi-)textual content via diffs • Very difficult to implement correctly, and no guiding formalisms to indicate correctness or warn against problems
Replicated Data Types (CRDTs) deterministically reconcile concurrent updates such that no conflicts arise – Performance, availability, scale of eventual consistency + reliable reconciliation as if you were using a consensus mechanism – Provably sound – Limitations: • No consensus → limitations on what can be stored, replicated, and reconciled (i.e. no global invariants) • Unbounded growth → “garbage collection”
CRDTs • What is replicated? – Entire state of the datatype? State-based, a.k.a. convergent replicated data type, a.k.a. CvRDT – Individual operations (+ arguments)? Operation-based, a.k.a. commutative replicated data type a.k.a. CmRDT – Options correspond to the two strategies for implementing optimistic replication✝ • These are formally equivalent §2.4 – Strategy: understand state-based constructions, move on to operation-based as optimization ✝http://research.microsoft.com/apps/pubs/default.aspx?id=66979
§2.3.1 All possible states within a CvRDT form a semilattice – Partially-ordered set established by a least upper bound (join, ) or greatest ≤ lower bound (meet, ) ≥ – Both relations are definitionally commutative, associative, and idempotent – Each application of join or meet yields a monotonically increasing or decreasing value {b} ø {a} {a} {a,b} t
join and meet are formally equivalent, join presumed throughout the literature • Update locally, propagate results to other replicas, where it must converge (the 'v' in “CvRDT”) • Requires weakest eventual consistency guarantees to yield convergence among all replicas, since join is associative and commutative – “infinitely often” transmission of state – Insensitive to reordered/dropped/repeated messages – Very expensive worst case, but easier to reason about
asynchronous replication • More than boxes, arrows • Better than (most) pseudocode: explicit about preconditions, where things happen, (a)synchrony, etc
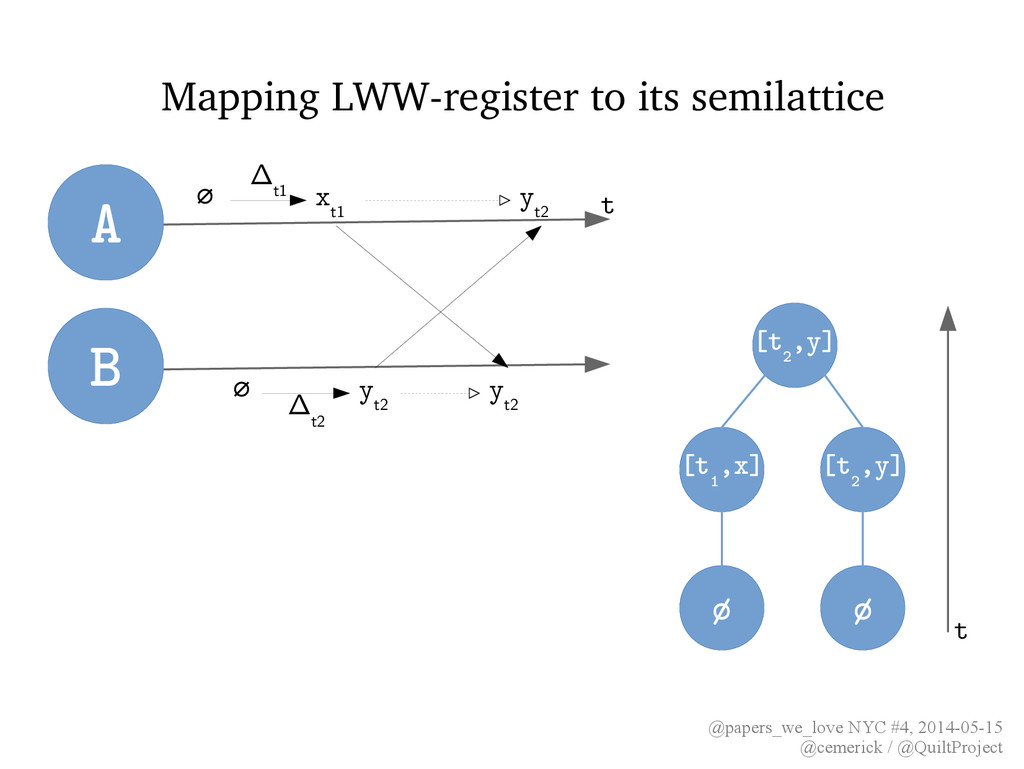
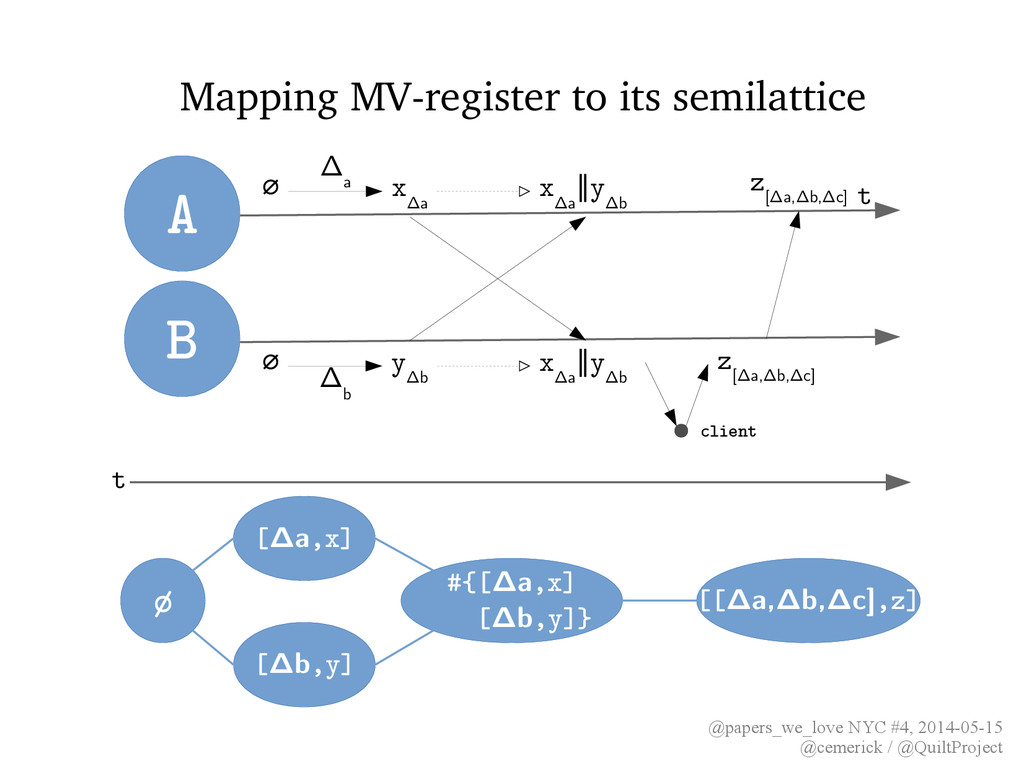
§3.2.2 • Assignments carry causal history (e.g. version vector) which defines semilattice's partial order • join retains all values assigned concurrently; some client can later assign a single value A t B ∅ y Δb x Δa x Δa ∥y Δb Δ b Δ a ∅ x Δa ∥y Δb client z [Δa,Δb,Δc] z [Δa,Δb,Δc]
Counterintuitive convergent characterizations – G-Set (“grow-only”): can add, cannot remove – 2P-Set (“two phase”): once removed, cannot add an element back • Composition of two G-sets – LWW-Set – PN-Set (positive & negative counters track membership): addition may not yield membership
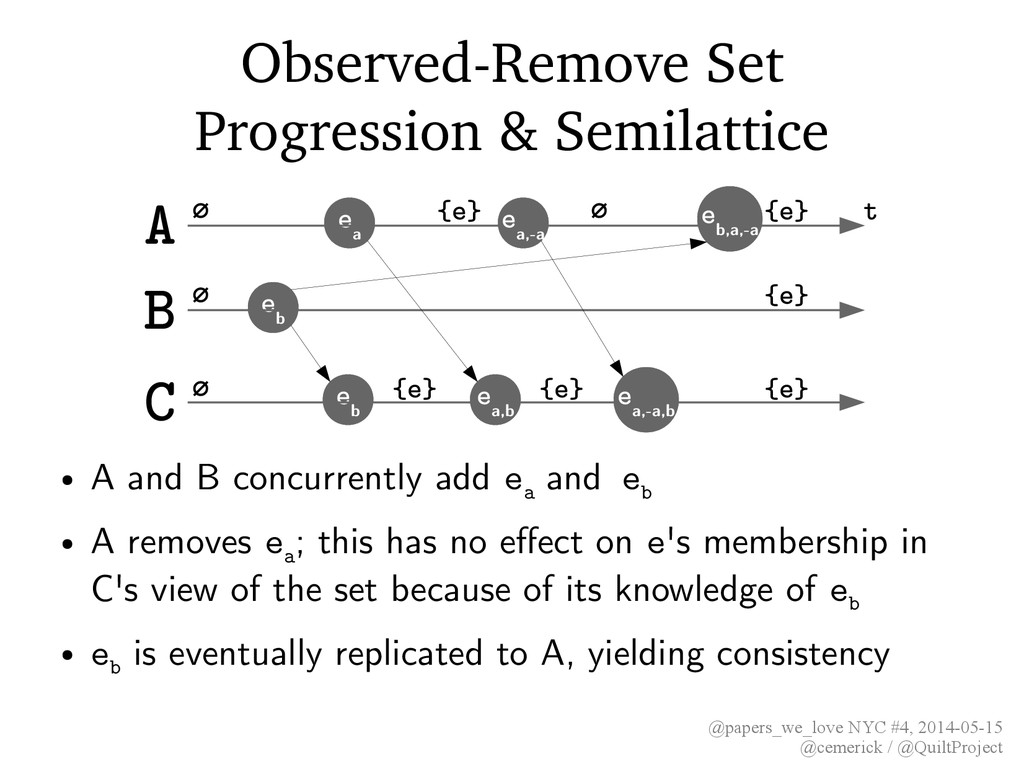
• Set CRDT with intuitive semantics ≈ – Given S.add(e) || S.remove(e), add wins • Strategy – tag each element uniquely (per actor or per operation), e τ – operation removing e must include set of all previously-unremoved τ for e – Set.contains(e) == true iff an e τ exists where τ has not been implicated in a removal of e • Tags are not exposed in userland API
& Semilattice e a A e b B e b C e a,b e a,-a e a,-a,b {e} ∅ e b,a,-a {e} {e} {e} ∅ ∅ ∅ {e} {e} t • A and B concurrently add e a and e b • A removes e a ; this has no effect on e's membership in C's view of the set because of its knowledge of e b • e b is eventually replicated to A, yielding consistency
Two sets, vertices + edges • Many different possible constructions given the local invariants one might want to preserve between edges and vertices • Global invariants cannot be guaranteed because of concurrent operations – e.g. cannot prevent cycles
§2.3.2 • Requires “reliable broadcast channel” – Operations delivered to each replica in causal order < d – All concurrent operations that are unordered with respect to < d must commute (the 'm' in CmRDT) • Far more efficient than worst-case state-based specification
• More complex, more difficult to reason about • More challenging to implement – Causal relationships between operations must be identified + maintained – Generally requires tracking “group membership”
• “Garbage”: additional overhead that accumulates in order to satisfy CRDT semantics – “tombstones” (e.g. remove tags in an OR-Set) – Unbalanced trees of identifiers in sequences • Optimistically collecting garbage and rolling back as necessary is an option in some cases • Others appear to require various levels of consensus to achieve • “Garbage” is not always waste – The right kind of tombstones are what makes consistent snapshot possible
work Lots of prior work had portions of CRDTs' semantics, before “CRDT” was identified as a concept: – Wuu and Bernstein, 'Efficient solutions to the replicated log and dictionary problems' (1984!) – Operational transforms – Any Dynamo-style system uses registers for values • LWW-registers: S3 • MV-registers: CouchDB conflicts, Riak siblings
work “Consistency as Logical Monotonicity” (CALM theorem) – s/semilattices/monotonic logic • Stricter semantics than semilattices; no way to characterize non-monotonic operations (remove, etc) without consensus – Implemented at the language level by Bloom • Nearly all data structures are monotonic or lattices • Allows for static analysis that identifies parts of your program that aren't monotonic (require synchronization/consensus mechanism to ensure safety)
page for this talk: http://bit.ly/pwl-nyc-4 • Shapiro et al. paper: http://bit.ly/shapiro-crdt-pdf • Shapiro talk @ MSR: http://bit.ly/shapiro-msr-talk • Chris Meiklejohn's 'Readings in Distributed Systems': http://bit.ly/cmeik-dist-sys-readings • CRDTs offered in v2.0 of Riak: http://bit.ly/riak-crdts • Bloom, a Ruby DSL for “disorderly programming”, an implementation of CALM: http://www.bloom-lang.net • The Quilt Project: http://quilt.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}