fits into RAM • fragmentation? what’s that? • your lock % is super low • electing a new primary? no problem! • you’ve never had a queue size death spiral young mongo “problems” Tuesday, May 14, 13
how do you keep mongo running at scale? • how do you upsize or downsize cluster hardware? how do you optimize what you’ve got? • how can you track down bad queries and degraded performance? • what happens to your data as it ages and fragments? • how do you get mongo to tell you before its problems become critical? MongoDB grows up ... Tuesday, May 14, 13
snapshot • mongodump • 10gen backup service Provisioning options: • snapshot • secondary sync • mongorestore Snapshots are great and you should use them. Tuesday, May 14, 13
and databases • Hard on your primary, does a full table scan of all data • On > 2.2.0 you can sync from a secondary by button- mashing rs.syncFrom() on startup • Or use iptables to block secondary from viewing primary (all versions) • Not riskless, it resets the padding factor for all collections to 1 Tuesday, May 14, 13
RAID (this is hard to change later!) • Include mongodb::raid_data in your replica set recipe • Set a role attribute for mongodb[:vols] to indicate how many volumes to RAID • Set a role attribute for mongodb[:volsize] to indicate the size of the volumes • Set the mongodb[:use_piops] attribute if you want to use PIOPS volumes Tuesday, May 14, 13
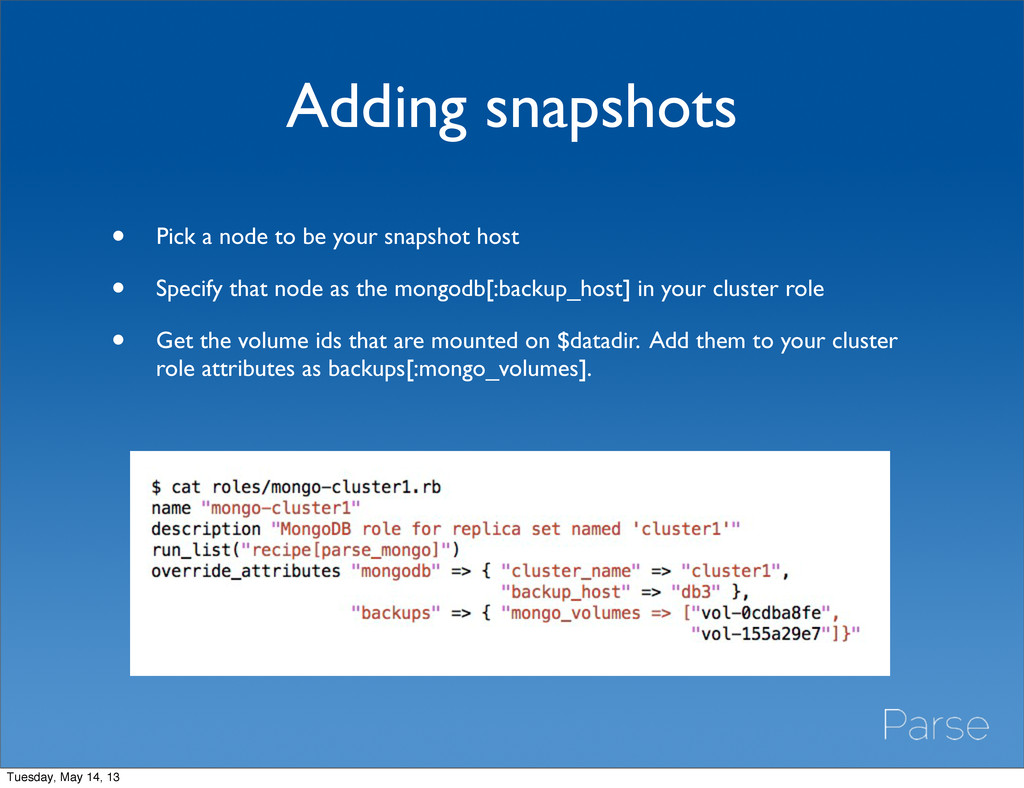
host • Specify that node as the mongodb[:backup_host] in your cluster role • Get the volume ids that are mounted on $datadir. Add them to your cluster role attributes as backups[:mongo_volumes]. Tuesday, May 14, 13
the backup host • Cron job does an ec2-consistent-snapshot of the volumes specified in backups[:mongo_volumes] • Locks mongo during snapshot • Tags a “daily” snapshot once a day, so you can easily prune hourly snapshot sets while keeping raid array sets coherent Tuesday, May 14, 13
see if mongo $dbpath is mounted • if not, grab the latest completed set of snapshots for the volumes in backup[:mongo_volumes] • provision and attach a new volume from each snapshot • assemble the RAID array, mount on $dbpath To reprovision, just delete the aws attributes from the node, detach the old volumes, and re-run chef-client. Tuesday, May 14, 13
but vote. • They are awesome. They give you more flexibility and reliability. • To provision an arbiter, use the LWRP. • If you have lots of clusters, you may want to run arbiters for multiple clusters on each arbiter host. • Arbiters tend to be more reliable than nodes because they have less to do. Tuesday, May 14, 13
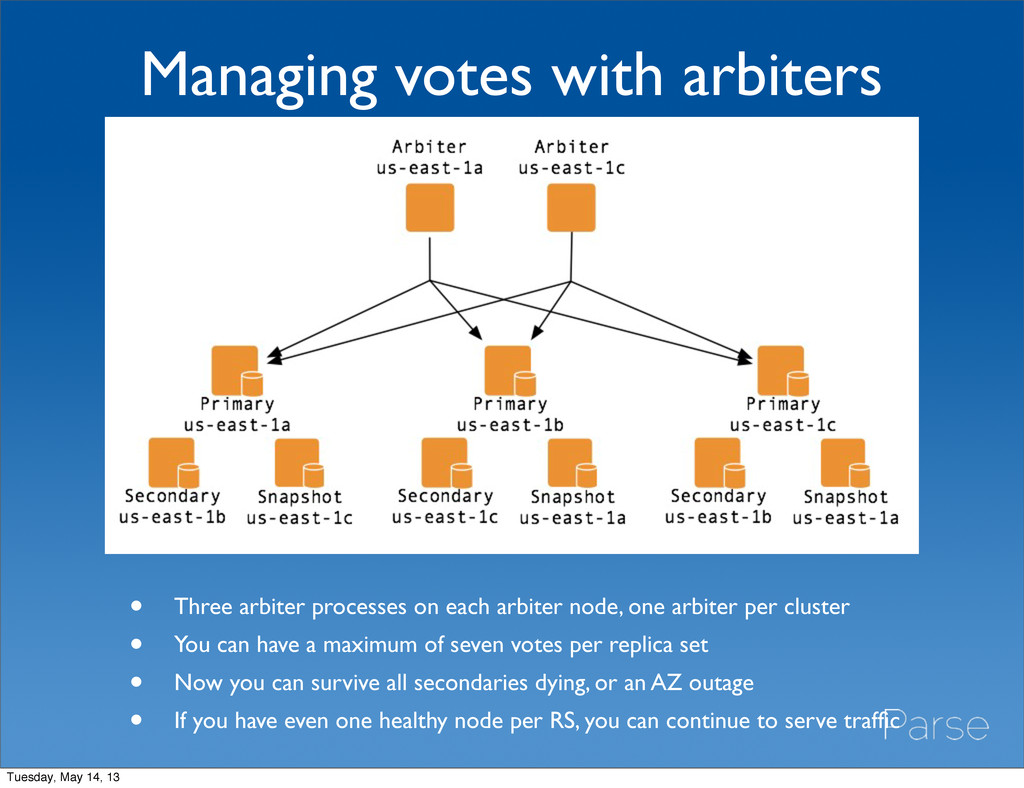
arbiter node, one arbiter per cluster • You can have a maximum of seven votes per replica set • Now you can survive all secondaries dying, or an AZ outage • If you have even one healthy node per RS, you can continue to serve traffic Tuesday, May 14, 13
your money there. • You should have enough RAM for your working set to fit • In 2.4 you can estimate the size of your working set with db.serverStatus() (yay!) • In other versions, check your paging statistics. High paging out to disk usually means you are short on RAM. Tuesday, May 14, 13
of <0.1% • Maximum provisioning size of 1024 GB • Raid together multiple volumes for higher performance, more storage • Supports EBS snapshots • Costs 2x regular EBS • Can only attach to certain instance types PIOPS Tuesday, May 14, 13
when you exceed your PIOPS limit, your disk stops for a few seconds Avoid this. Estimating PIOPS • estimate how many IOPS to provision with the “tps” column of sar -d 1 Tuesday, May 14, 13
is lost forever if you stop or resize the instance • Use EBS on only your snapshot node to take advantage of EBS backup • Or you can snapshot with LVM • ... or 10gen’s new mongodb backups as a service Ephemeral storage Tuesday, May 14, 13
• test they are actually being applied with “cat /proc/<pid>/limits” • Raise your connection limits • max_conn is 80% of soft ulimit, maximum hard-coded to 20k • Put the journal on a separate physical disk • Mount the filesystem with noatime and nodiratime Tuesday, May 14, 13
than a science. • If you are not using all your RAM, your blockdev may be set too high and you may be reading lots of empty space into RAM. • readahead of 32 is probably too small, 2048 is way too big. 64-256 is a good range depending on the size of your documents. • If you are using RAID, the md device and each constituent volume should have the same readahead Tuesday, May 14, 13
node to priority = 0 • Set your snapshot node to hidden = 1 • Consider making your snapshot node nonvoting • Lock mongo or stop mongod during snapshot • Run continuous compaction on your snapshot node, so that restores are always compacted. Tuesday, May 14, 13
S3 • run “dd” on each of the data files to pull blocks down • Always warm up a snapshot before promoting • in mongodb 2.4 you can use db.touch() • warm up both indexes and data • http://blog.parse.com/2013/03/07/techniques-for-warming-up-mongodb/ Tuesday, May 14, 13
underuse of memory • Deletes are not the only source of fragmentation • db.<collection>.stats to find the padding factor (between 1 - 2, the higher the more fragmentation) • Repair, compact, or reslave regularly (db.printReplicationInfo() to get the length of your oplog to see if repair is a viable option) Tuesday, May 14, 13
scratch • limited by the size of your data & oplog • very hard on your primary, use rs.syncFrom() or iptables to sync from secondary • Repair your node • also limited by the size of your oplog • can cause small discrepancies in your data • Run continuous compaction on your snapshot node • easiest, cleanest solution, but beware newExtents if you do a lot of big deletes Tuesday, May 14, 13
sort by db namespace • mongodb.log • search for queries that are holding the lock for a long time • profiling • enable with db.setProfilingLevel() • query the system.profile collection Tuesday, May 14, 13
db.currentOp().inprog.length for queue size • sort by namespace, numYields, locktype for useful query spelunking • sometimes does not print namespace or full query • add comments to each query in your driver to get more/better detail. • are you building any indexes? • run explain() on queries that are long-running Tuesday, May 14, 13
slow queries > 100 ms by default, change with --slowms • look for high nscanned numbers -- indicates you may need more / different indexes • check the logs for which queries are holding the global or db read/write locks the longest • you can match connection ids to IPs to tell which host a query came from Tuesday, May 14, 13
persist through db restarts. We have a script in chef to enable profiling on all dbs once a day. • writing to this collection costs you, but worth it • use db.system.profile.find() to get slow queries for a certain collection, time frame, runtime, etc • much of the same info as the mongo log, but queryable and javascripty • it’s a capped collection; you may want to enlarge it Tuesday, May 14, 13
your tipping point looks like • Don’t switch your primary or restart when overloaded • Do kill queries before the tipping point • Write your kill script before you need it • don’t kill internal mongo operations, only queries. Tagging queries with comments makes this easier. • Read your mongodb.log. Enable profiling! ... when queries pile up ... Tuesday, May 14, 13
votes to elect a primary • set your priority levels explicitly • max 7 votes; don’t run with an even # • if you have problems with secondaries, delegate voting to arbiters • voting while snapshotting can be a problem. Set snapshot nodes to be nonvoting if you can. • check your mongo log. Is something vetoing? Do they have an inconsistent view of the cluster state? Tuesday, May 14, 13
cause a secondary to crash unrecoverably • be careful which queries you kill; never kill oplog tailers or other internal database operations • arbiters are more stable than secondaries, consider using them to form a quorum with your primary Tuesday, May 14, 13
is to re-snapshot off the primary and rebuild your secondaries. • however, you can dangerously repair a secondary: 1. stop mongo 2. bring it back up in standalone mode 3. repair the offending collection 4. restart mongo again as part of the replica set Tuesday, May 14, 13
factor, try compaction • You rs.remove() a node and get weird driver errors? • always shut down mongod after removing from replica set • Huge background flush spike? • probably an EBS or disk problem • You run out of connection limits? • possibly a driver bug • hard-coded to 80% of soft ulimit until 20k is reached. Tuesday, May 14, 13
• check your mongodb.log for large newExtent warnings • also make sure you aren’t reaching PIOPS limits • You get weird driver errors after adding/removing/ re-electing? • several drivers have problems with this, you may have to restart Tuesday, May 14, 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}