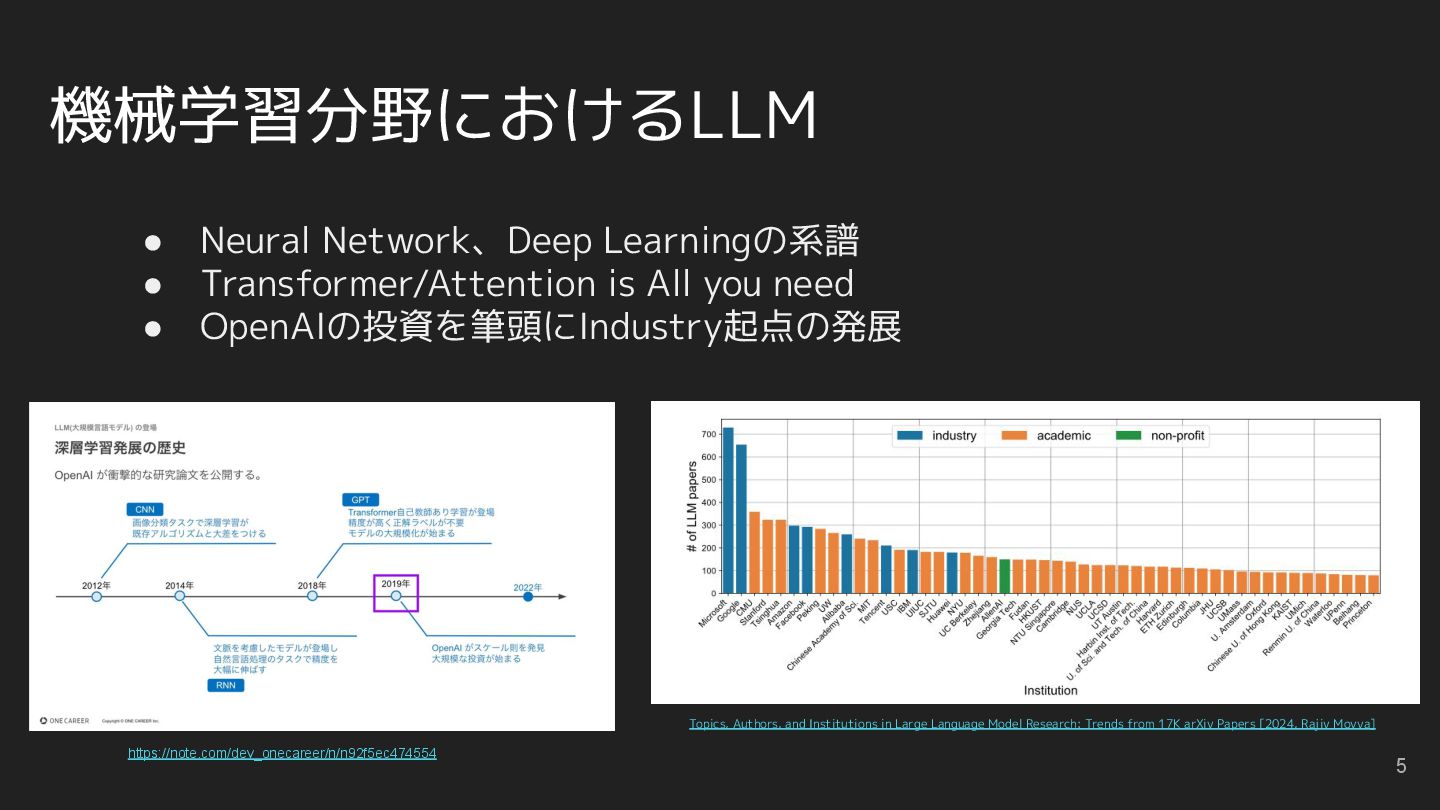
you need • OpenAIの投資を筆頭にIndustry起点の発展 Topics, Authors, and Institutions in Large Language Model Research: Trends from 17K arXiv Papers [2024, Rajiv Movva] https://note.com/dev_onecareer/n/n92f5ec474554
Sonia and Musolff, Leon and Peng, Sida and Salz, Tobias, The Effects of Generative AI on High-Skilled Work: Evidence from Three Field Experiments with Software Developers (Posted: 5 Sep 2024, Last revised: 22 Jun 2025, June 22, 2025). Available at SSRN: http://dx.doi.org/10.2139/ssrn.4945566 • 大規模な比較化実験 ◦ Microsoft/Accenture/匿名Fortune100企業 ◦ 4867人のSoftware Engineer • 生成AIを利用した開発者のタスク完了率が増加 ◦ 平均26.08%増(標準誤差10.3%) ◦ 勤続年数、職位の低いジュニア層に強い効果 ▪ AcceptRate、生産性(PR数)向上の双方で3.5ptの差 ◦ 導入率は全体の60~75% ▪ MS 75.6%、Accenture 69.4% ▪ 若手、ジュニアほど初期の導入率が高く継続利用も多い ▪ 一方、最終的に元々PRを多く出していた生産性が高い層の 導入率が少し上回るという逆転現象が起きた
◦ I²CやLoRaなどの通信から電力最適化など、10秒以内に±10%で動作するコード生成を検証 • コードと設計の両面で支援 ◦ I²Cドライバを単プロンプトで66%の確率で正しいコードを生成 ◦ LoRa通信やnRF52の電力消費を740倍削減 ◦ デバッグ、設計の支援 ▪ 人間との協調で初心者・熟練者共に LoRaセンサ構築の成功率が25%→100%に Tonnie, H., & Luitel, P. (2023). Exploring and Characterizing Large Language Models for Embedded System Development and Debugging. arXiv. https://arxiv.org/abs/2307.03817
Models for Code. https://arxiv.org/abs/2311.10372 • 2023 ◦ A Survey of using Large Language Models for Generating Infrastructure as Code https://aclanthology.org/2023.icon-1.48.pdf ◦ Large Language Models for Software Engineering: Survey and Open Problems https://ieeexplore.ieee.org/document/10449667 ◦ Large Language Models Meet NL2Code: A Survey https://www.microsoft.com/en-us/research/publication/large-language-models-meet-nl2code-a-survey/ • 2024 ◦ A Survey on Evaluating Large Language Models in Code Generation Tasks https://arxiv.org/abs/2408.16498 ◦ A Survey on Large Language Models for Code Generation https://arxiv.org/pdf/2406.00515 ◦ A Survey on LLMs for Code Generation https://github.com/juyongjiang/CodeLLMSurvey ◦ A Survey on LLM-based Code Generation for Low-Resource and Domain-Specific Programming Languages https://arxiv.org/abs/2410.03981 ◦ A Survey of Large Language Models for Code: Evolution, Benchmarking, and Future Trends https://arxiv.org/abs/2311.10372 ◦ Large Language Models for Software Engineering: A Systematic Literature Review https://arxiv.org/abs/2308.10620 • 2025 ◦ Large Language Models for Code Generation: A Comprehensive Survey of Challenges, Techniques, Evaluation, and Applications https://arxiv.org/abs/2503.01245 ◦ Large Language Models for Game Development: A Survey on Automated Code Generation https://pure.roehampton.ac.uk/portal/en/publications/large-language-models-for-game-development-a-survey-on-automated- ◦ Automated Code Generation with Large Language Models https://medium.com/@sunnypatel124555/automated-code-generation-with-large-language-models-llms-0ad32f4b37c8 ◦ How Does LLM Reasoning Work for Code? A Survey and a Call to Action https://arxiv.org/abs/2506.13932 太字は特に参考になったもの
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ebayによるLocal LLMによる生産性の向上 [2024/02] Cutting Through the Noise: Three Things We've](https://files.speakerdeck.com/presentations/001b6adcdd1f4202a701809c88ac44d6/slide_13.jpg){kind=link}
![GitHub Copilotによるタスク完了率の向上 [2024/09] Cui, Zheyuan and Demirer, Mert and Jaffe,](https://files.speakerdeck.com/presentations/001b6adcdd1f4202a701809c88ac44d6/slide_14.jpg){kind=link}
![組込み開発への利用 [2024/02] • マイクロコントローラ+センサ、アクチュエータを動かし物理的に評価 ◦ LLM(GPT‑3.5, GPT‑4, PaLM 2) ◦ 450件のハードウェア・イン・ザ・ループ(HIL)実験環境](https://files.speakerdeck.com/presentations/001b6adcdd1f4202a701809c88ac44d6/slide_15.jpg){kind=link}
![実業務コーディングの割合公表値 17 [2024, Q3 earnings call: CEO’s remarks, Sundar Pichai]](https://files.speakerdeck.com/presentations/001b6adcdd1f4202a701809c88ac44d6/slide_16.jpg){kind=link}
{kind=link}
![どこまで生産性は上がるのか [2025/03] • 加速度的に伸びる生産性の予測 ◦ ほぼ全ての分野で3~6ヶ月単位でAIの性能が倍増している ◦ 自動運転など遅い分野があるがほぼ全てが指数関数的 ◦ 2030年には現在1ヶ月かかっている](https://files.speakerdeck.com/presentations/001b6adcdd1f4202a701809c88ac44d6/slide_18.jpg){kind=link}
![AI開発で本当に全ての生産性が向上するのか [2025/07] • シニアなOSS開発者による実験 ◦ 5年以上PJに関わった16名の開発者と246件のissue ◦ 110万行以上のプロジェクトに導入 ◦ Cursor](https://files.speakerdeck.com/presentations/001b6adcdd1f4202a701809c88ac44d6/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[参考] AIコーディングサーベイ • 2022 ◦ A Survey of Large Language](https://files.speakerdeck.com/presentations/001b6adcdd1f4202a701809c88ac44d6/slide_31.jpg){kind=link}
{kind=link}