Talk gave at the PyCon JP 2016 on 21th of September, 2016.
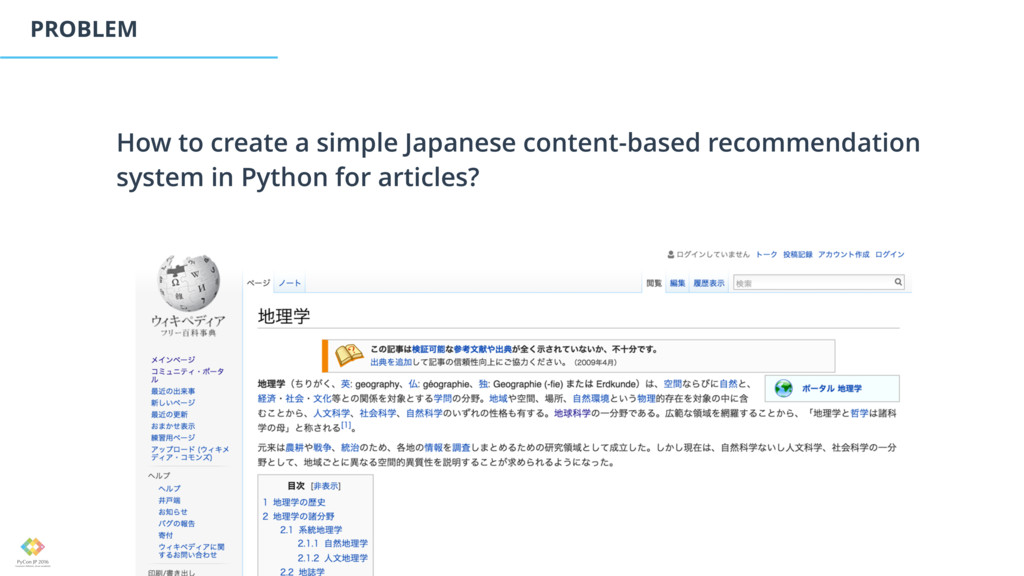
Online stores such as Amazon but also news/blogs websites suffer from information overload. Customers can easily get lost in their large variety (millions) of products or articles. Recommendation engines help users narrow down the large variety by presenting possible suggestions. In this talk, I will show how to create a simple Japanese content-based recommendation system in Python for blog posts.
Talk page: https://pycon.jp/2016/en/schedule/presentation/43/
Code: https://github.com/charles-vdulac/japanese-content-engine
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}