Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文読み会 / Deep Interest Network for Click-Through...
Search
chck
March 15, 2019
Research
30
0
Share
論文読み会 / Deep Interest Network for Click-Through Rate Prediction
社内論文読み会、PaperFridayでの発表資料です
chck
March 15, 2019
More Decks by chck
See All by chck
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
160
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.5k
CyberAgent AI Lab研修 / Container for Research
chck
1
2.3k
CyberAgent AI Lab研修 / Code Review in a Team
chck
3
2.3k
論文読み会 / Socio-Technical Anti-Patterns in Building ML-Enabled Software: Insights from Leaders on the Forefront
chck
0
120
CyberAgent AI事業本部MLOps研修Container編 / Container for MLOps
chck
3
6k
論文読み会 / GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models
chck
0
81
論文読み会 / On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
chck
0
60
論文読み会 / GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
chck
0
62
Other Decks in Research
See All in Research
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
110
量子コンピュータの紹介
oqtopus
0
310
定数整数除算・剰余算最適化再考
herumi
1
120
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
270
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
2
130
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
750
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
3.6k
[チュートリアル] 電波マップ構築入門 :研究動向と課題設定の勘所
k_sato
0
450
Using our influence and power for patient safety
helenbevan
0
350
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
1.1k
2026.01ウェビナー資料
elith
0
380
【NICOGRAPH2025】Photographic Conviviality: ボディペイント・ワークショップによる 同時的かつ共生的な写真体験
toremolo72
0
240
Featured
See All Featured
Joys of Absence: A Defence of Solitary Play
codingconduct
1
380
Believing is Seeing
oripsolob
1
130
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
710
Code Review Best Practice
trishagee
74
20k
Bash Introduction
62gerente
615
210k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
300
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Odyssey Design
rkendrick25
PRO
2
650
Java REST API Framework Comparison - PWX 2021
mraible
34
9.3k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.7k
Amusing Abliteration
ianozsvald
1
190
Transcript
Deep Interest Network for Click-Through Rate Prediction 3/15 PaperFriday, Yuki
Iwazaki@AI Lab
Authors: Guorui Zhou, Chengru Song, Xiaoqiang Zhu, Ying Fan, Han
Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, Kun Gai Alibaba, Inc. 2
先週に引き続き ... CTR予測 by DNN ◂ 2016年以降急速に発展 ◂ 前回はDeepFM(2017) ◂
今日の論文はDIN(2018) 3
1. Motivaton 4
None
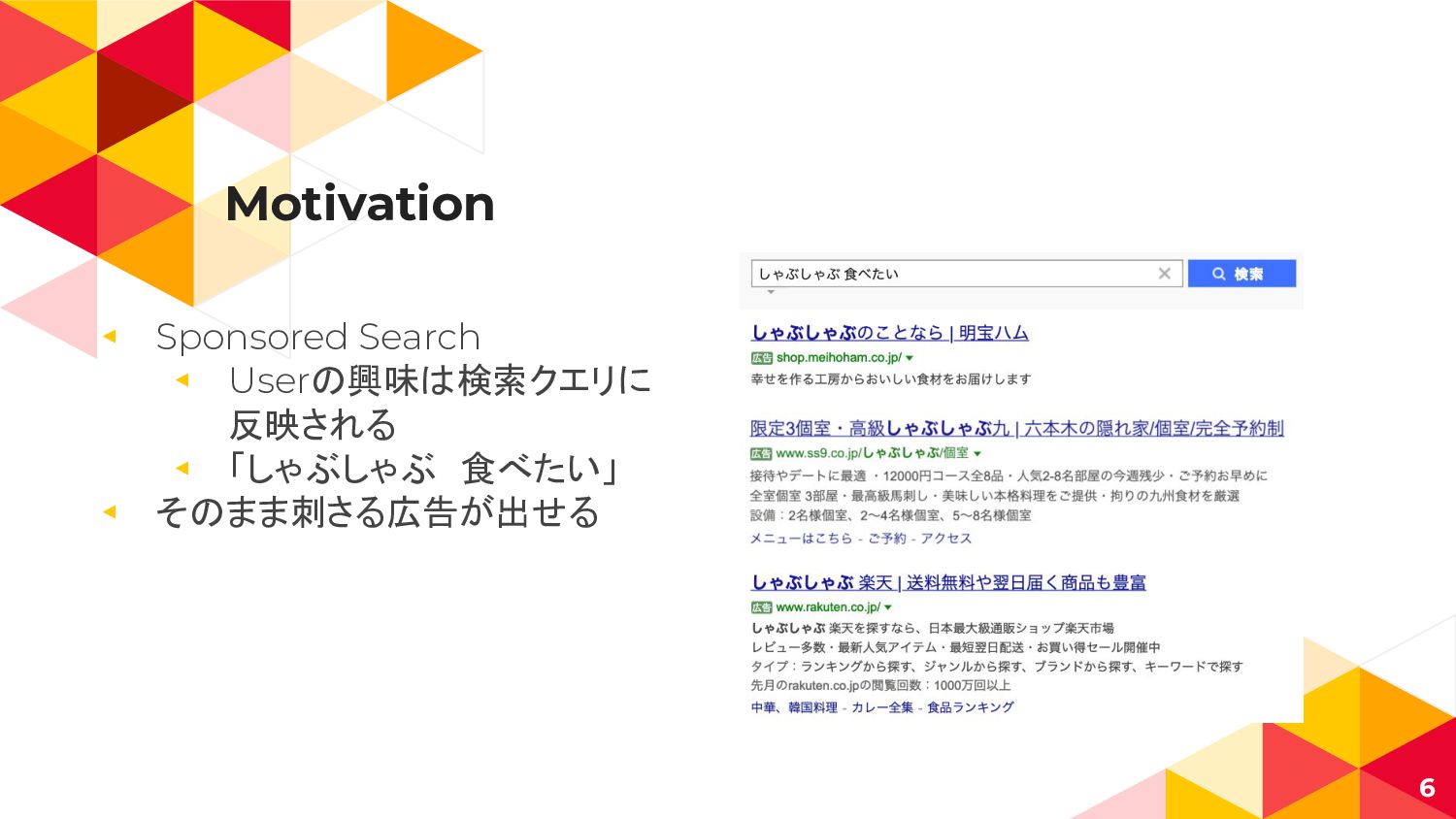
Motivation 6 ◂ Sponsored Search ◂ Userの興味は検索クエリに 反映される ◂ 「しゃぶしゃぶ 食べたい」
◂ そのまま刺さる広告が出せる
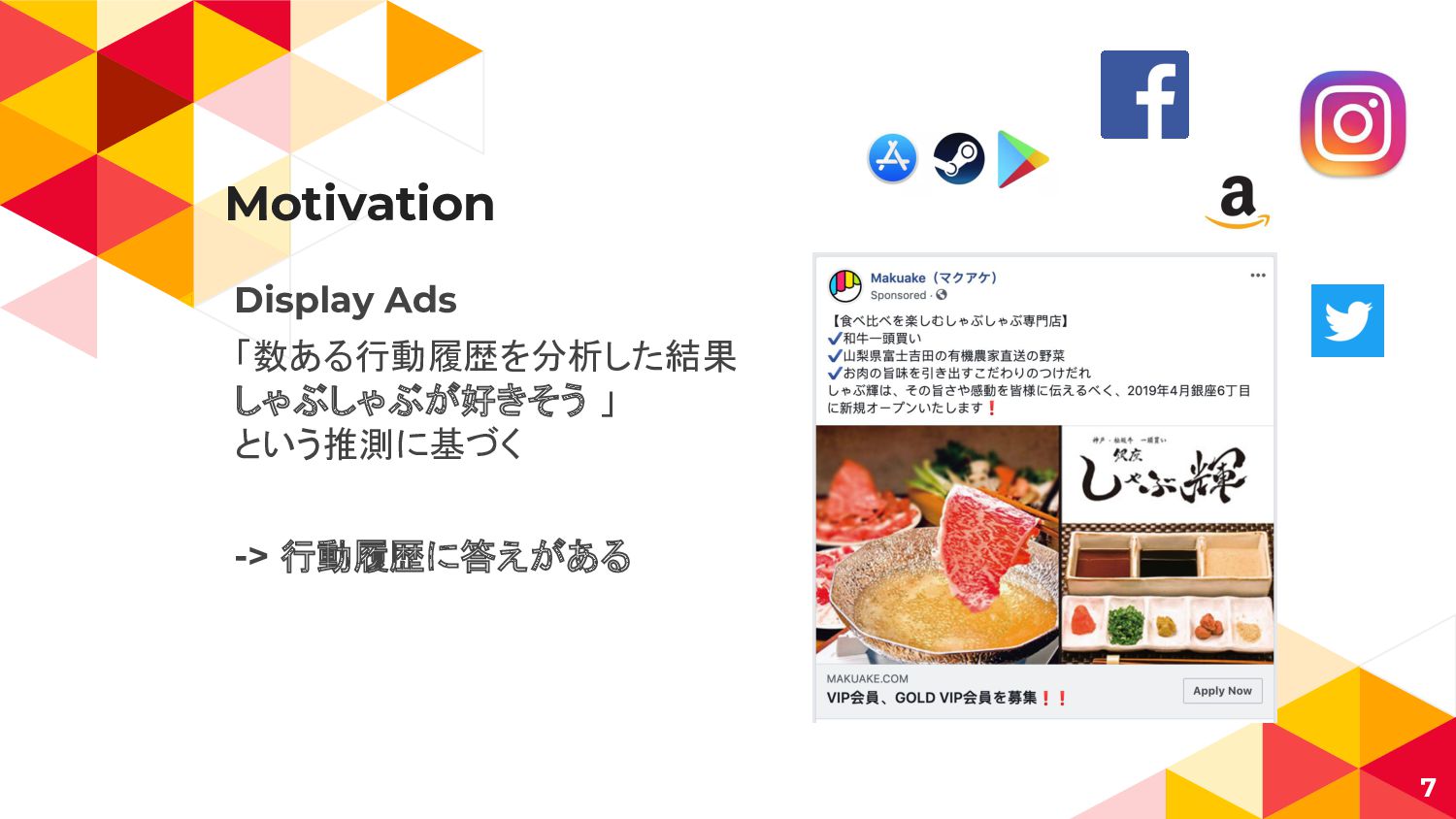
Motivation ◂ Display Ads 「数ある行動履歴を分析した結果 しゃぶしゃぶが好きそう 」 という推測に基づく -> 行動履歴に答えがある
7
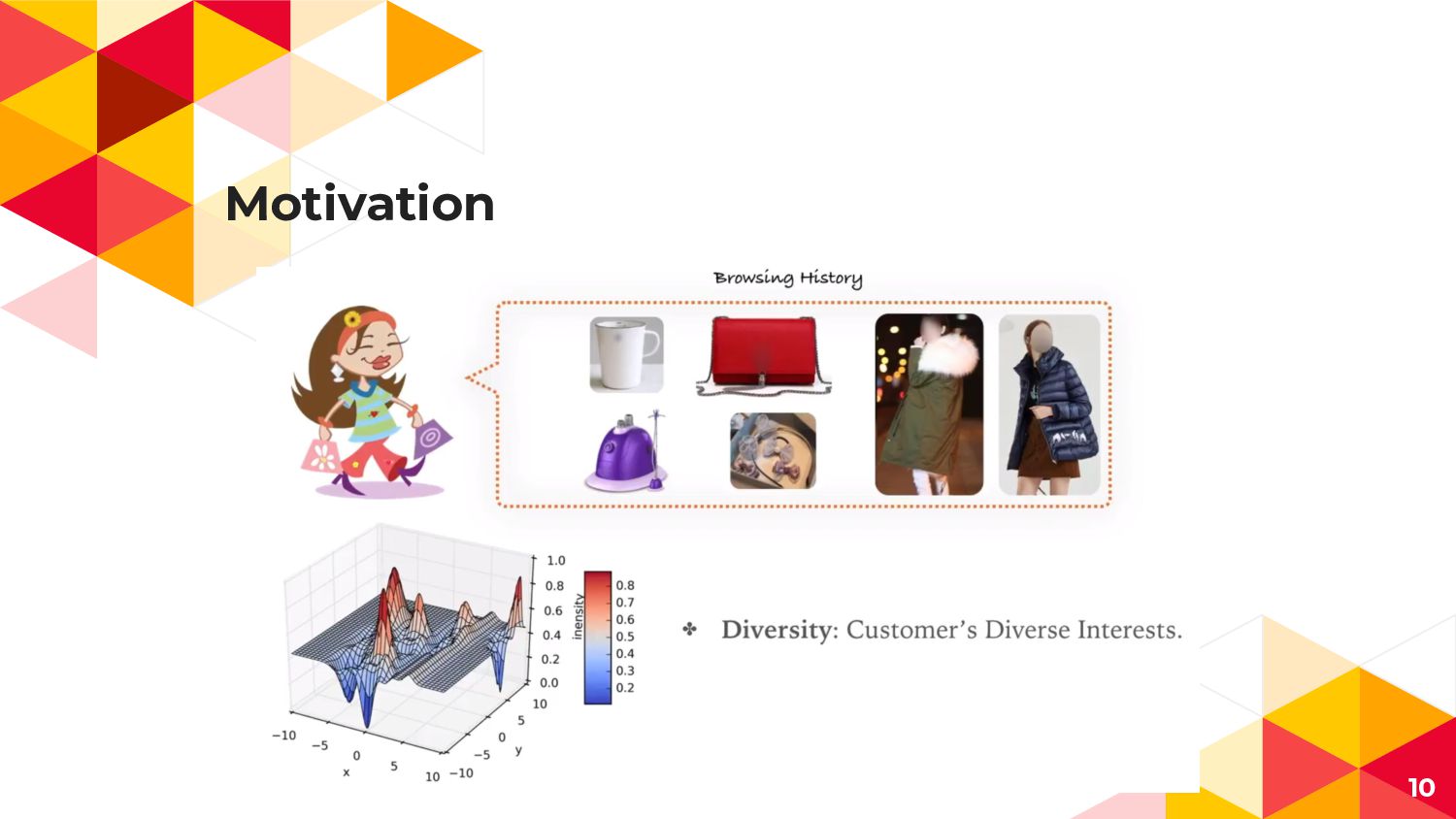
“ User interests are diverse. 8
Motivation 9
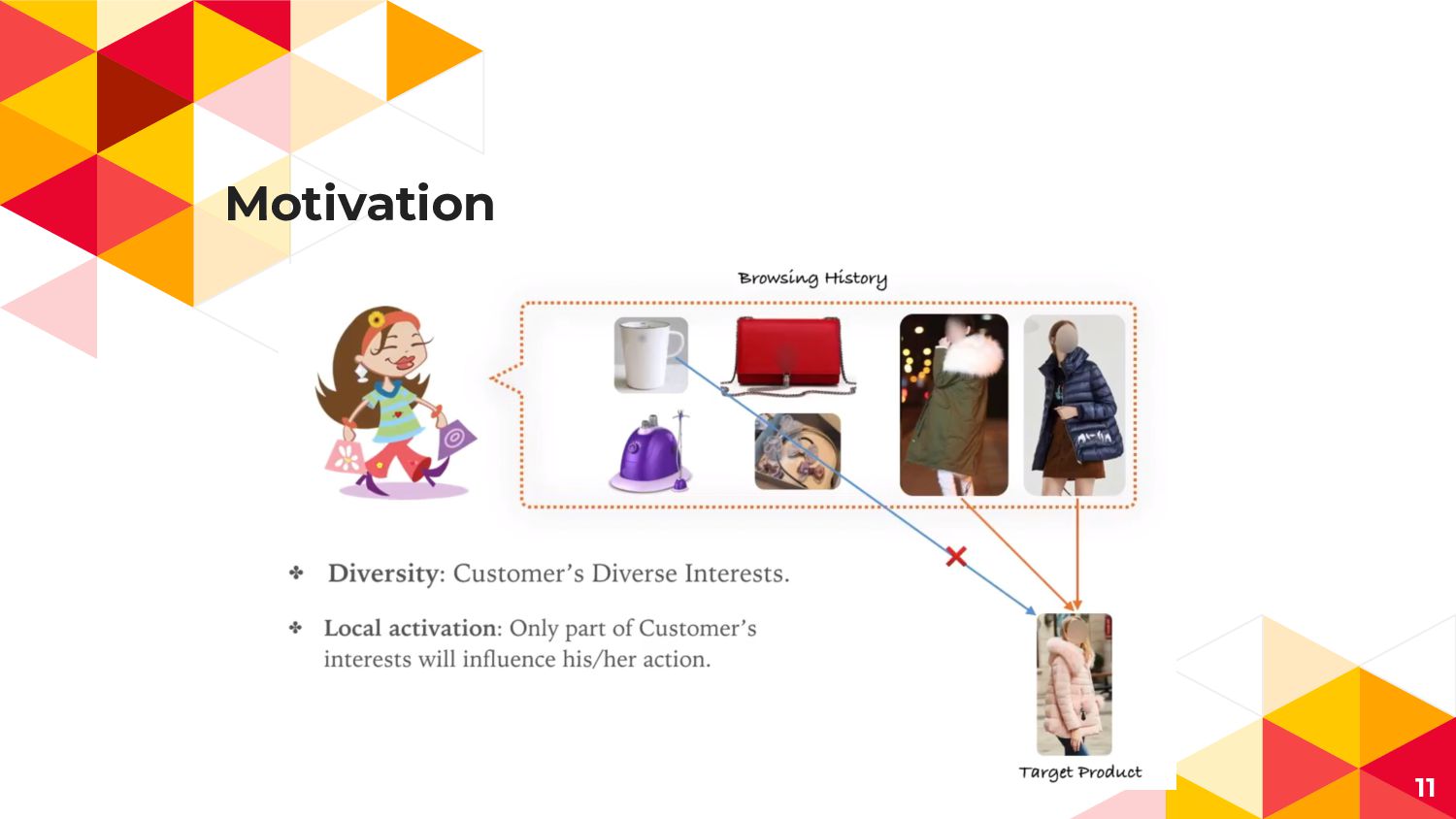
Motivation 10
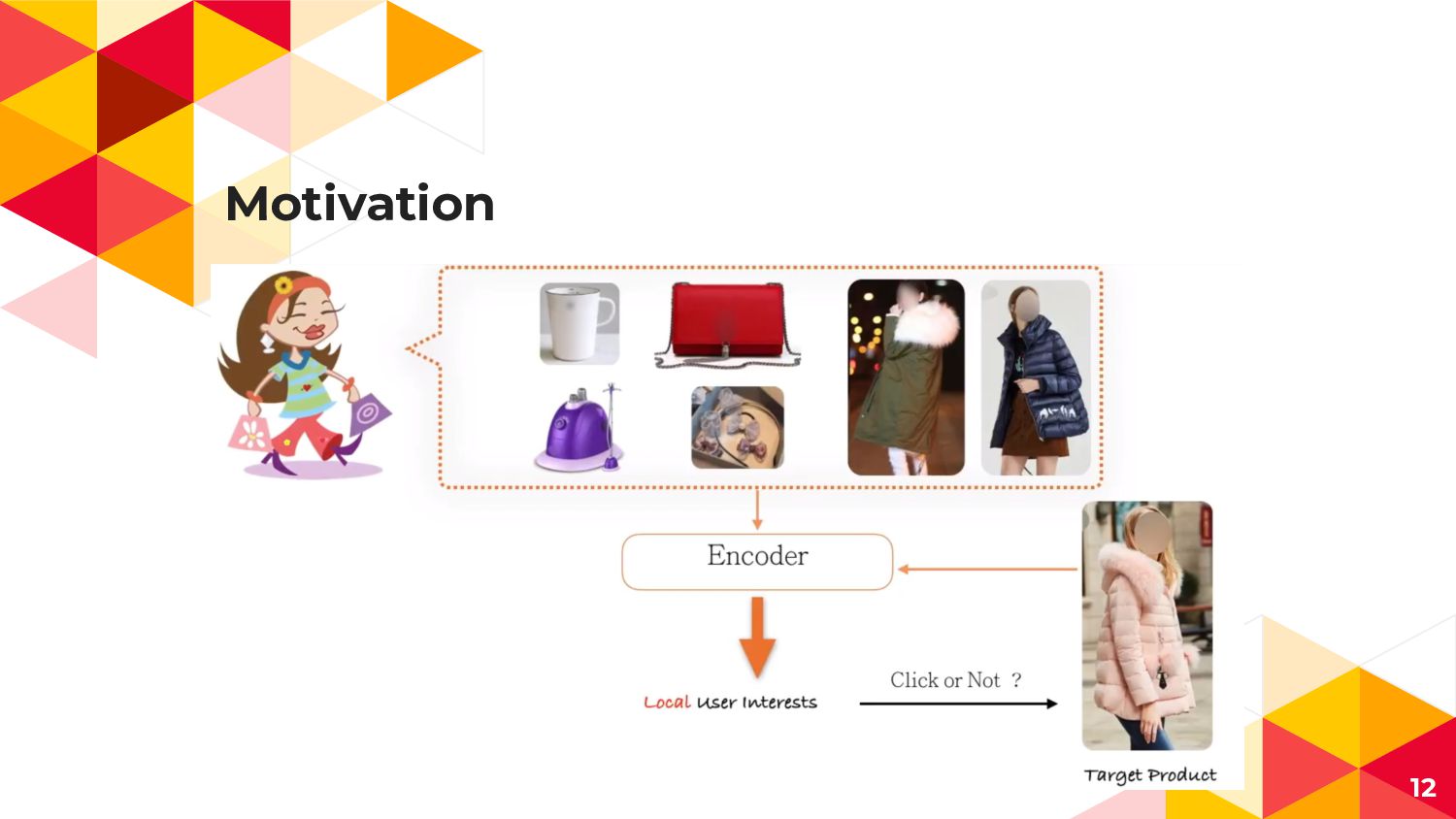
Motivation 11
Motivation 12
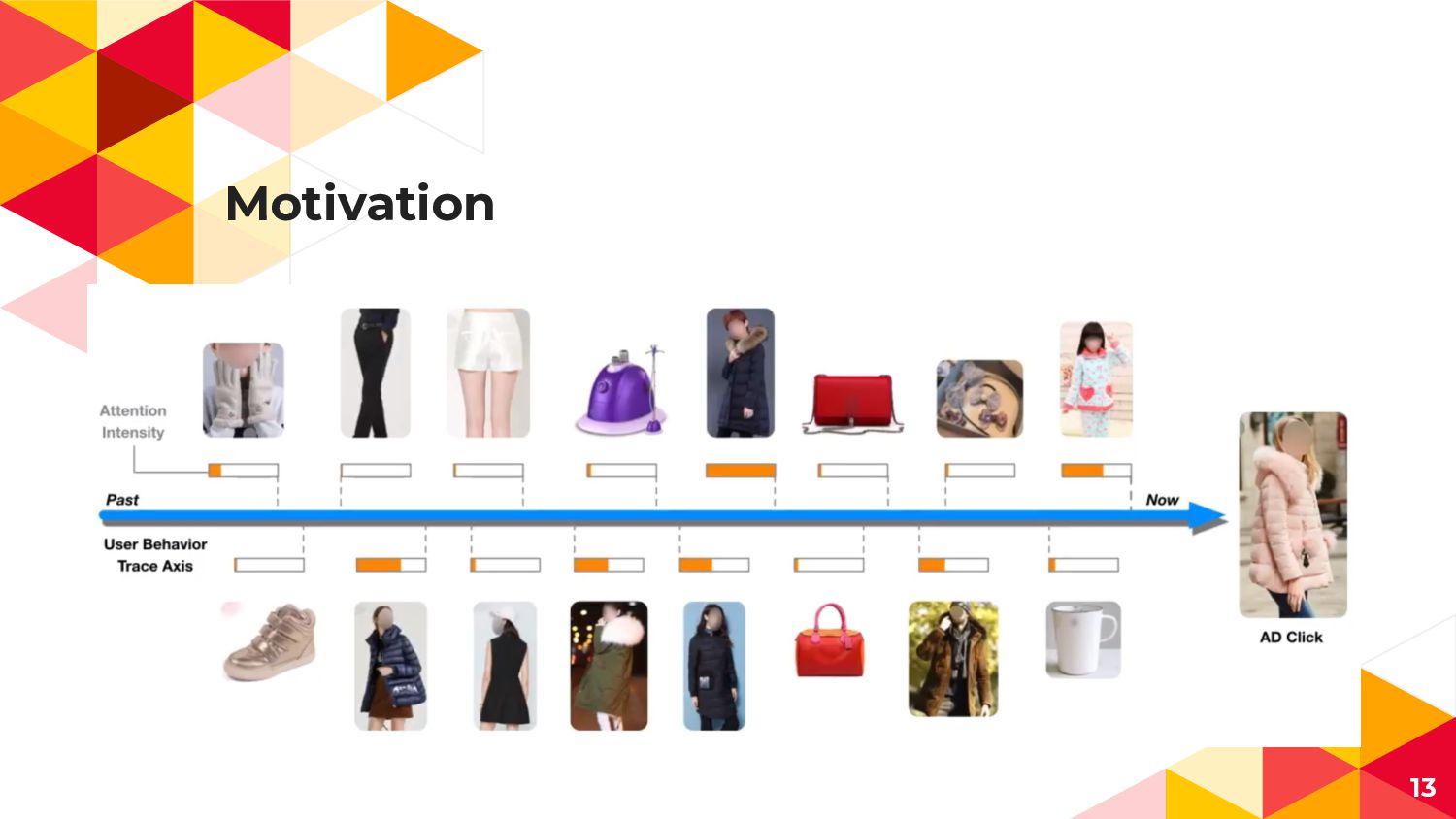
Motivation 13
Motivation ◂ User interests are diverse ◂ Historical user behaviorの中でも
広告に寄与するbehaviorの組み合わせが CTR予測において特に重要 14
1. Deep Interest Network DIN 15
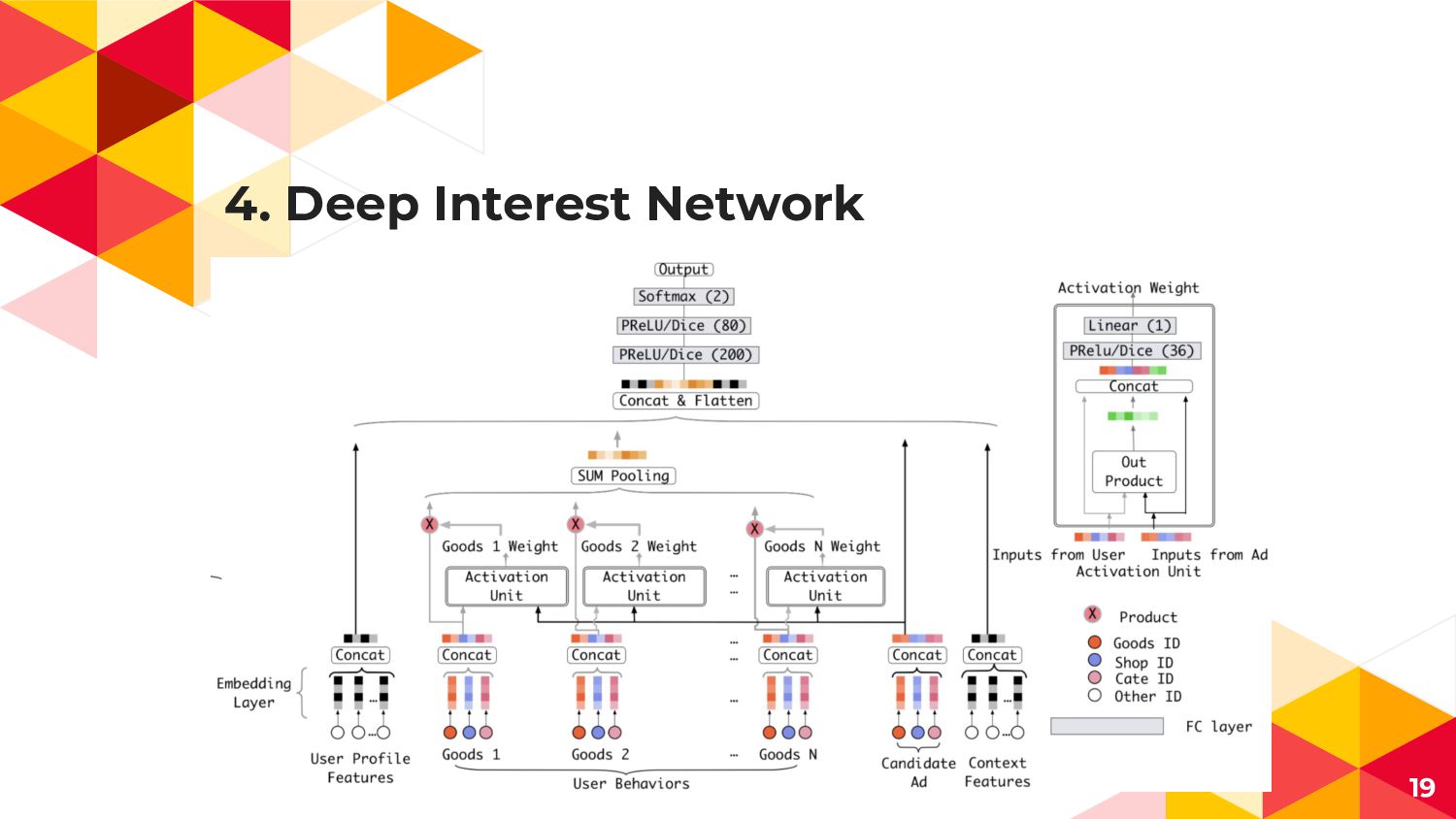
1. INTRODUCTION ◂ KDD 2018の論文 ◂ E-CommerceのDisplay Adsが対象 16
tl;dr 1. User Historical behaviorとAdの関連性を 上手く表現するDNNの提案 2. 過学習を抑制する効率的な正則化項と 分布の違いに強い活性化関数の提案 3.
Public・Private(Alibaba)のデータでsuperior 17
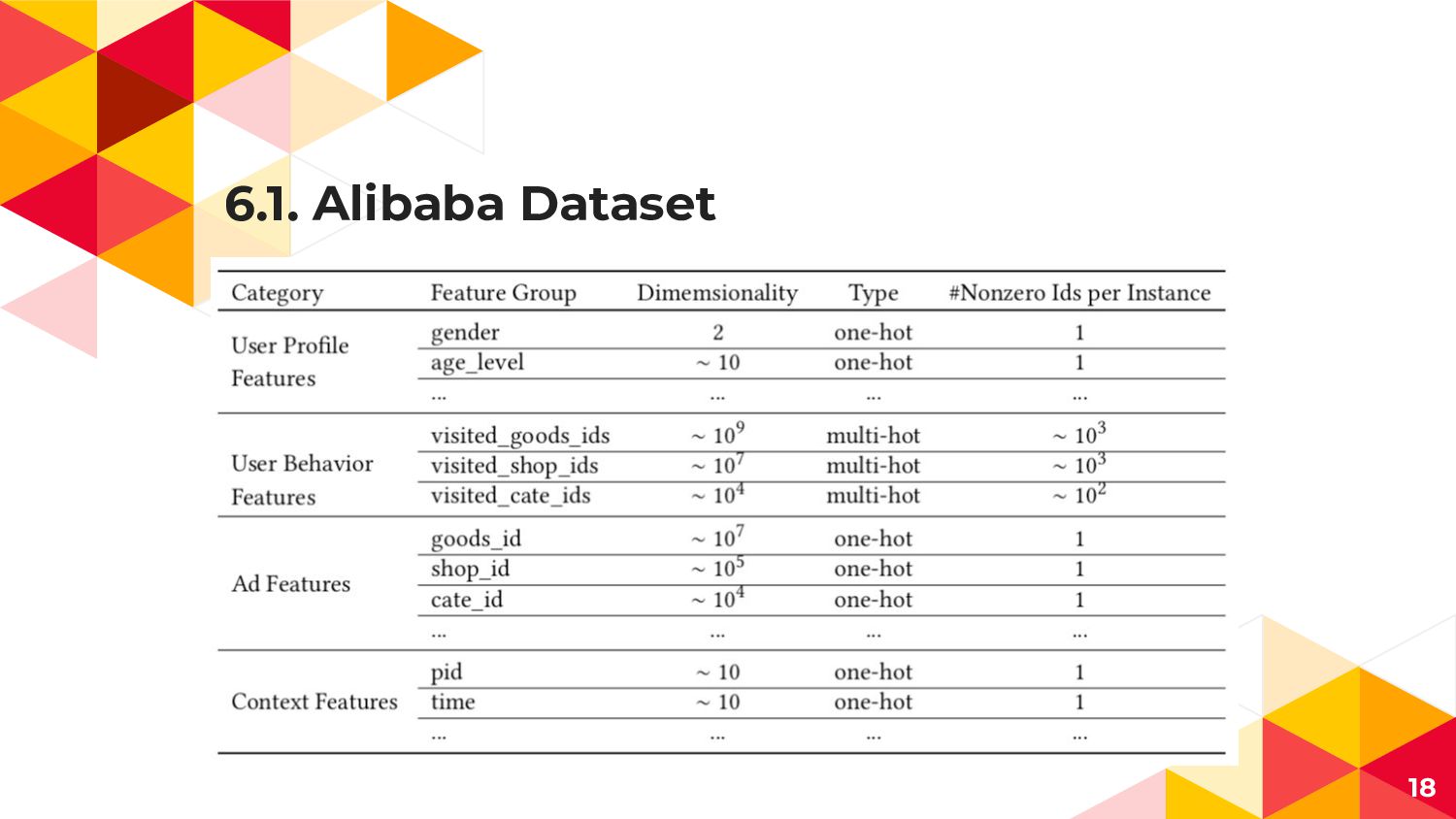
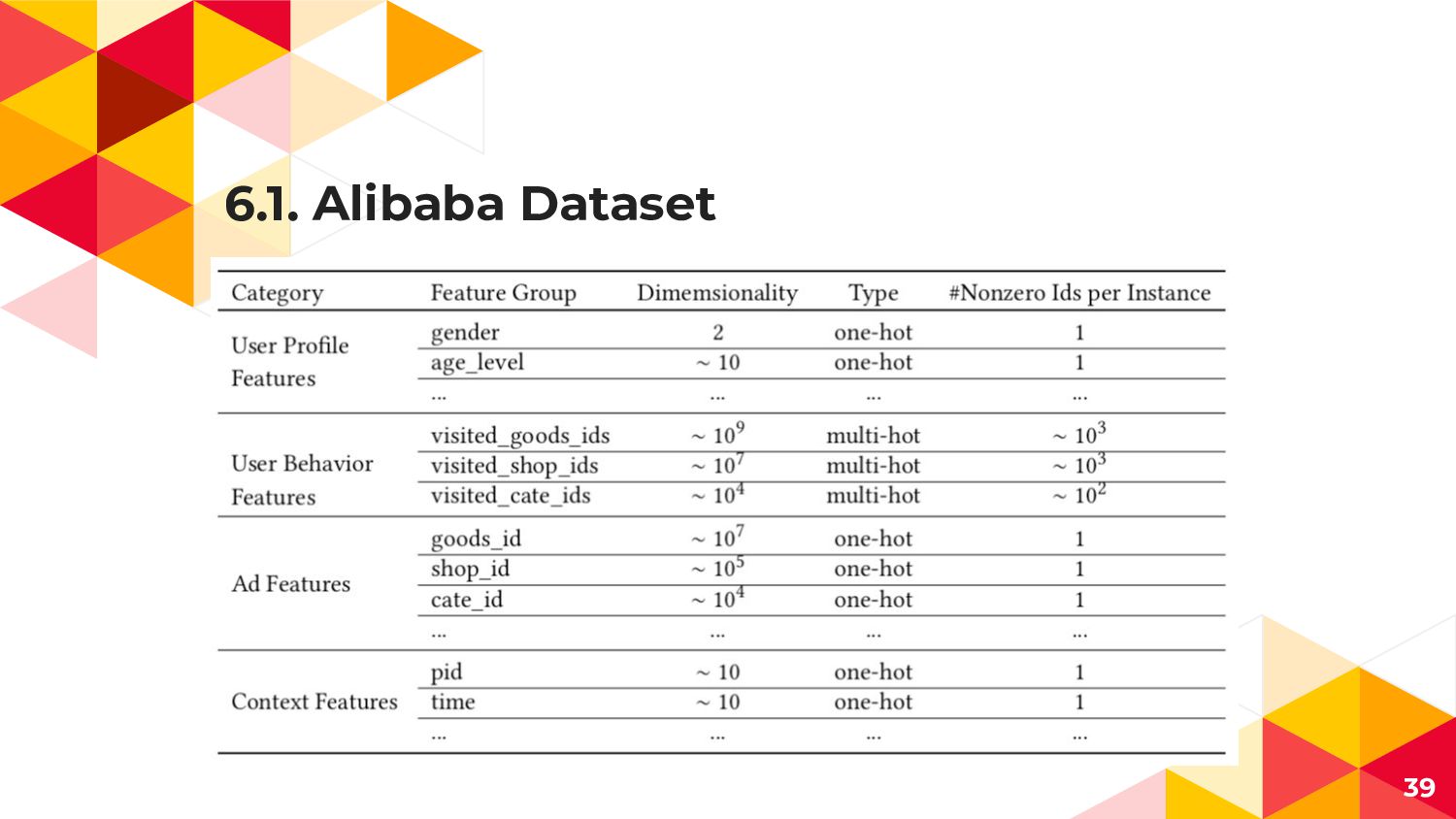
6.1. Alibaba Dataset 18
4. Deep Interest Network 19
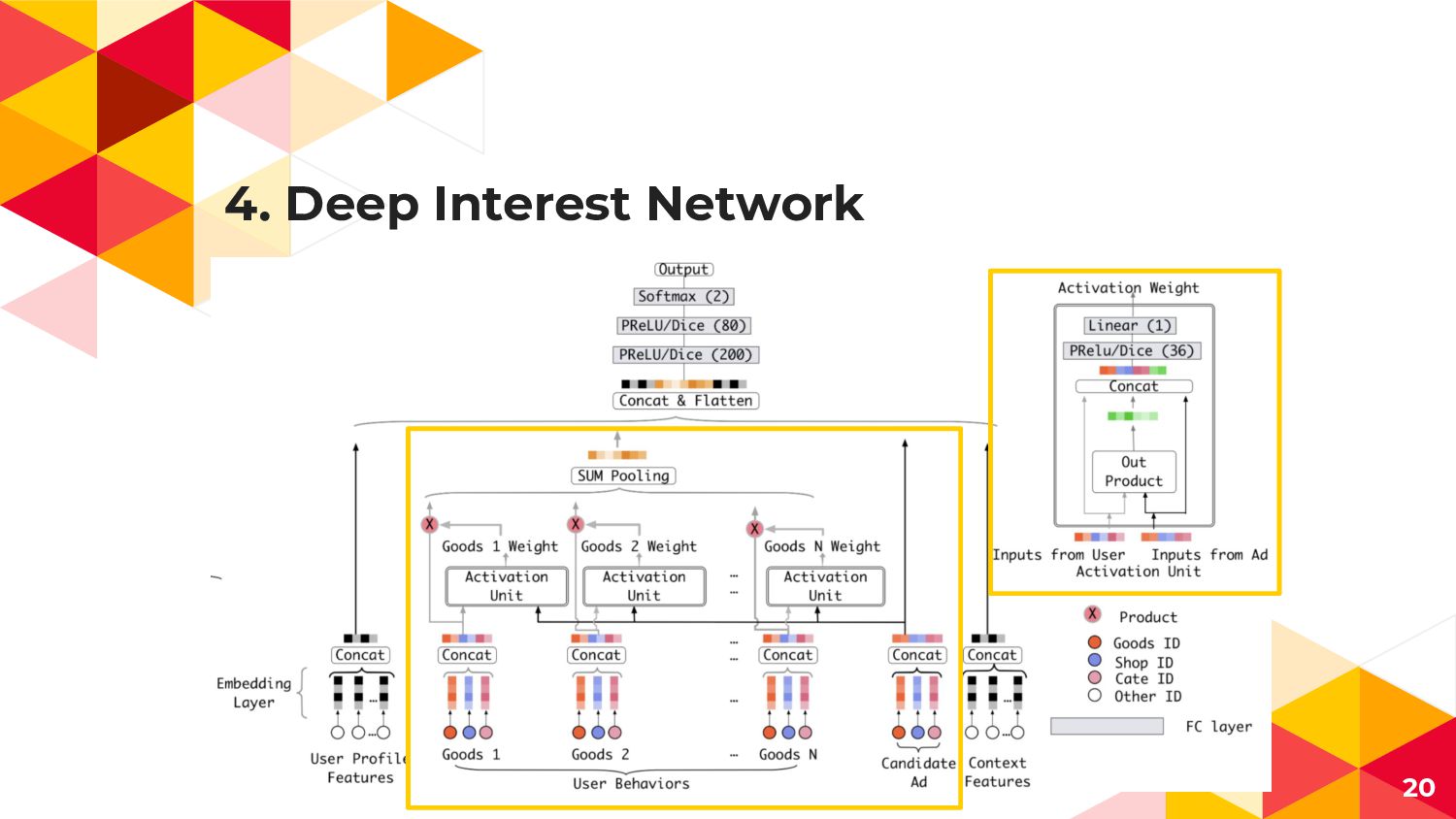
4. Deep Interest Network 20
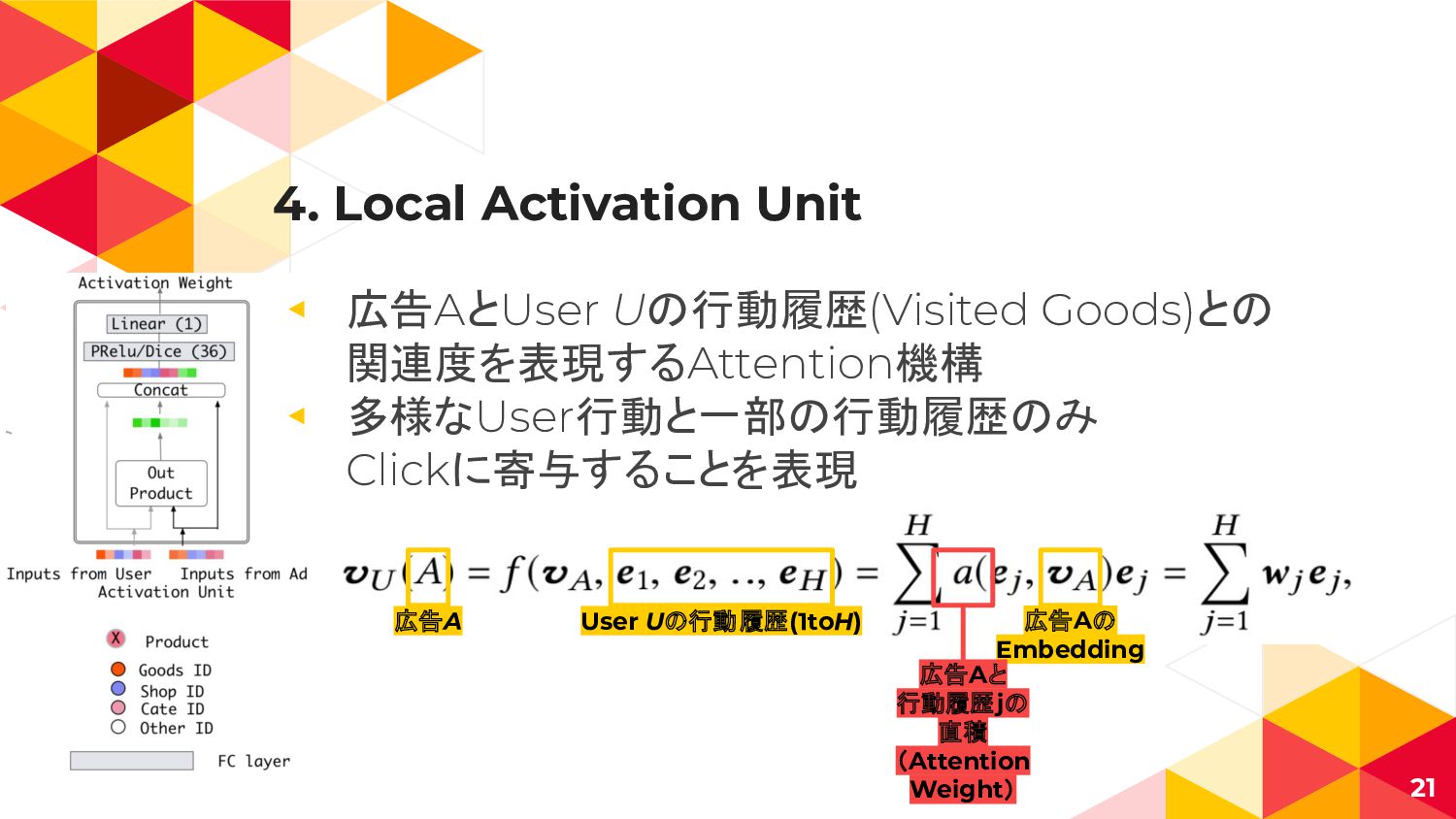
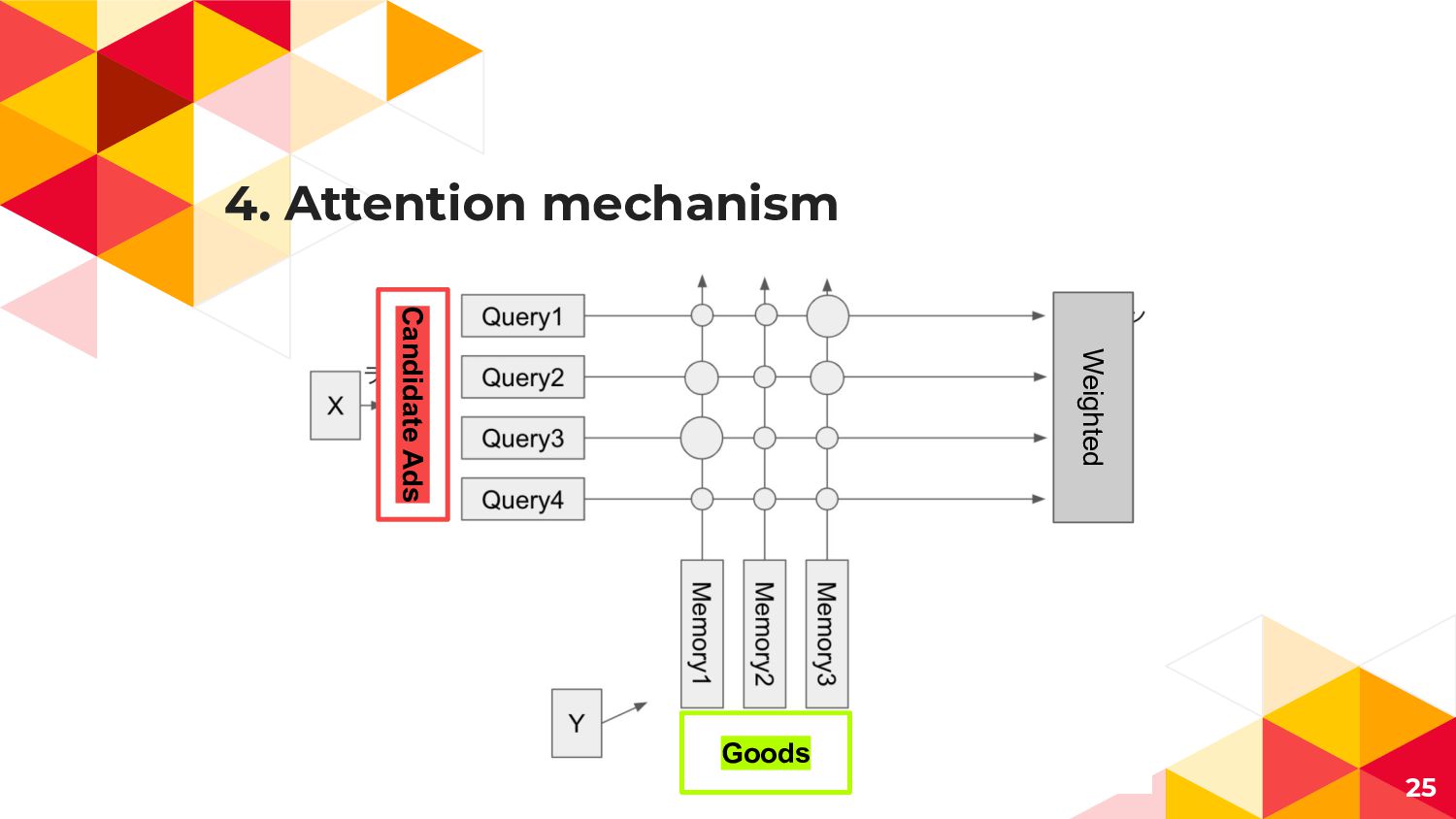
4. Local Activation Unit ◂ 広告AとUser Uの行動履歴(Visited Goods)との 関連度を表現するAttention機構 ◂
多様なUser行動と一部の行動履歴のみ Clickに寄与することを表現 User Uの行動履歴(1toH) 広告A 広告Aの Embedding 広告Aと 行動履歴jの 直積 (Attention Weight) 21
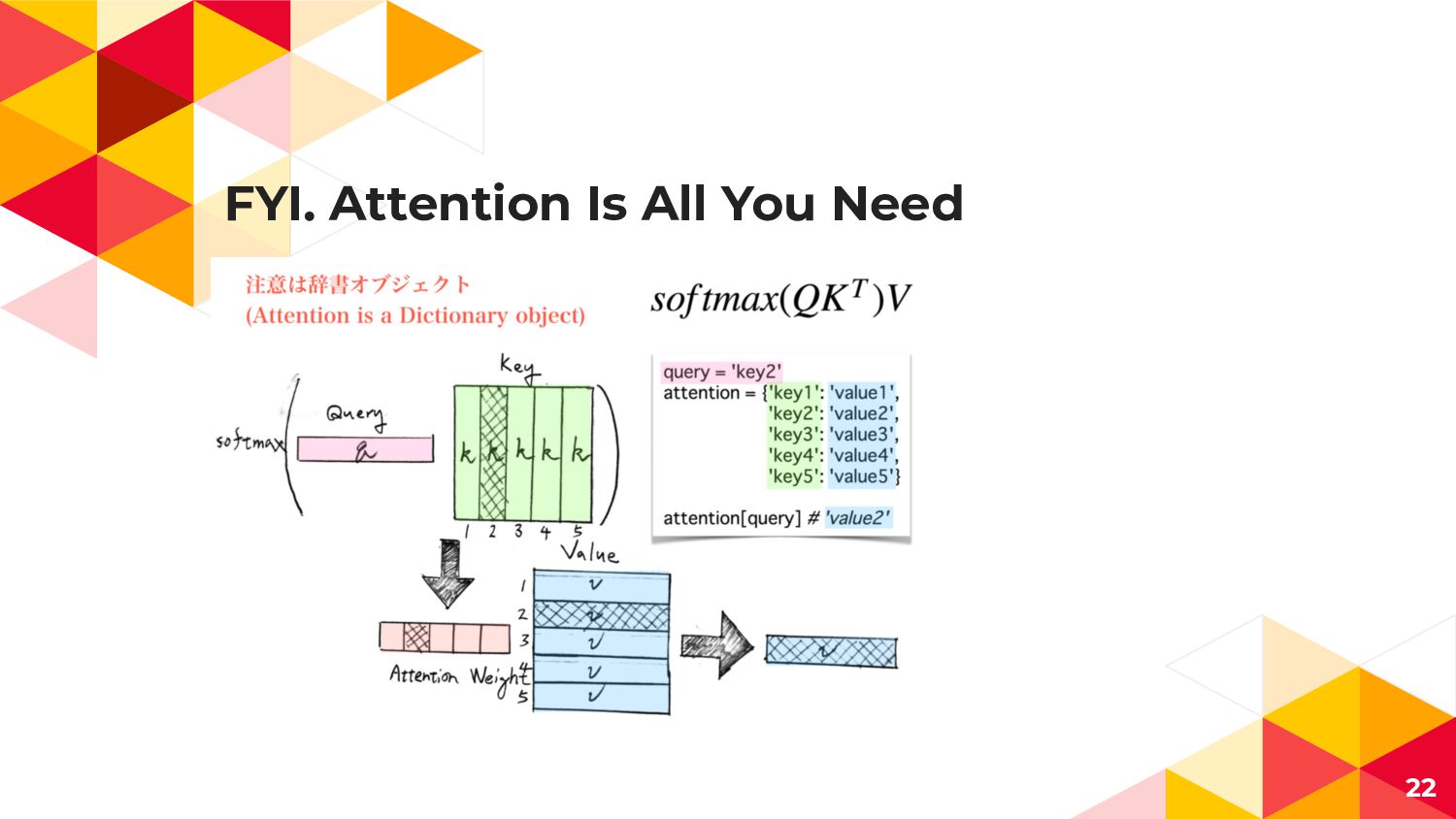
FYI. Attention Is All You Need 22
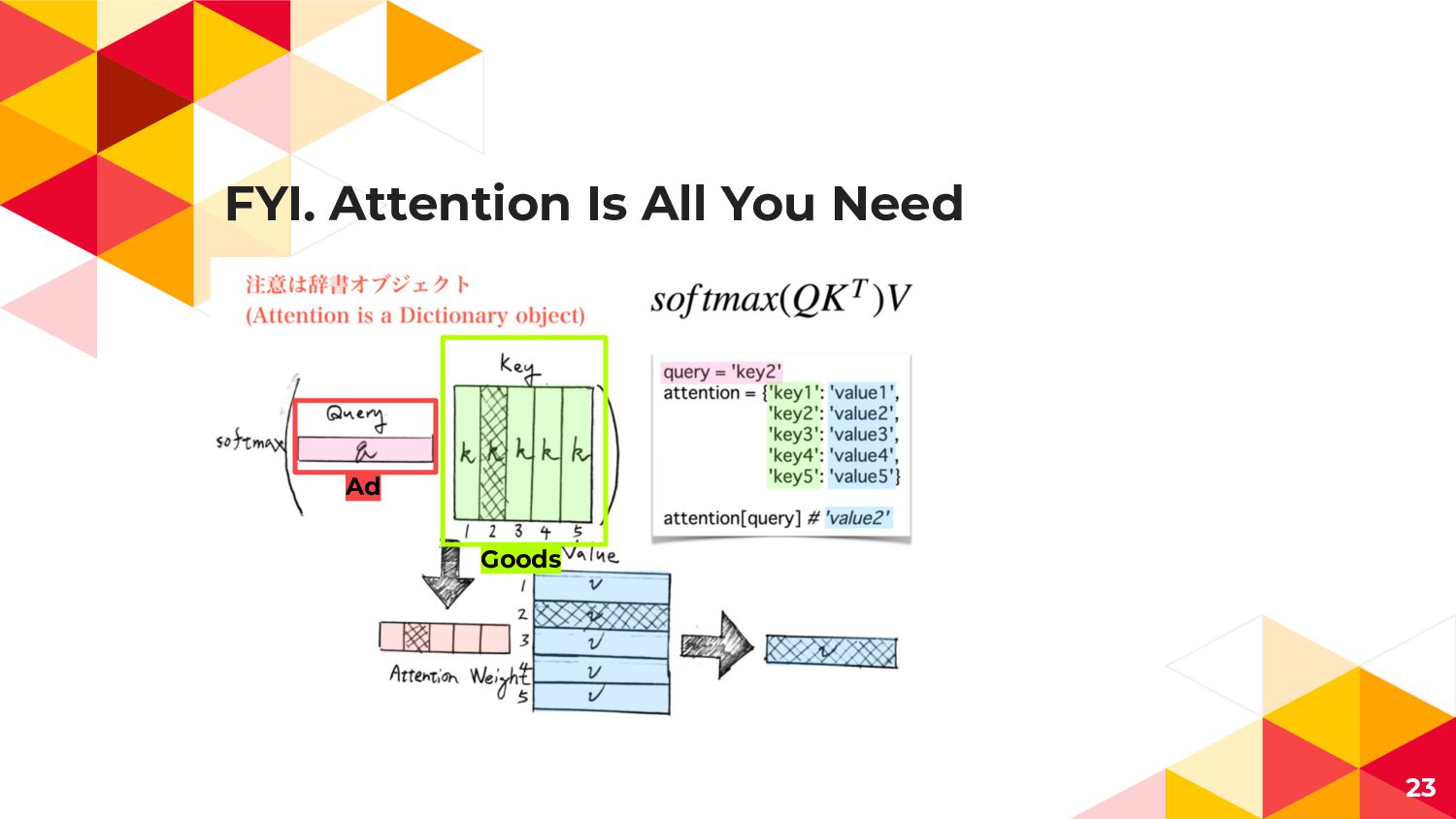
FYI. Attention Is All You Need 23 Goods Ad
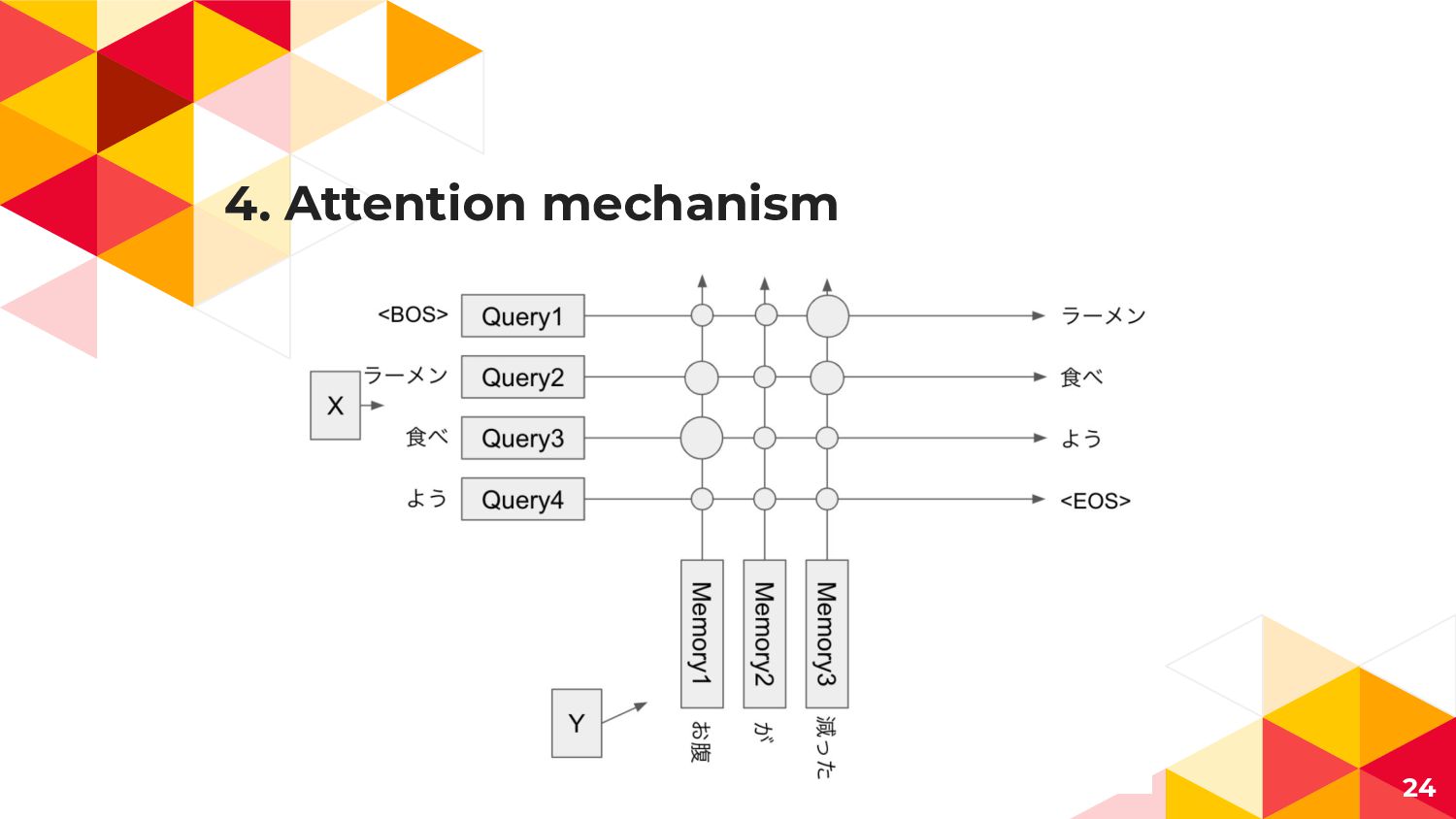
4. Attention mechanism 24
4. Attention mechanism 25 Goods Candidate Ads Weighted
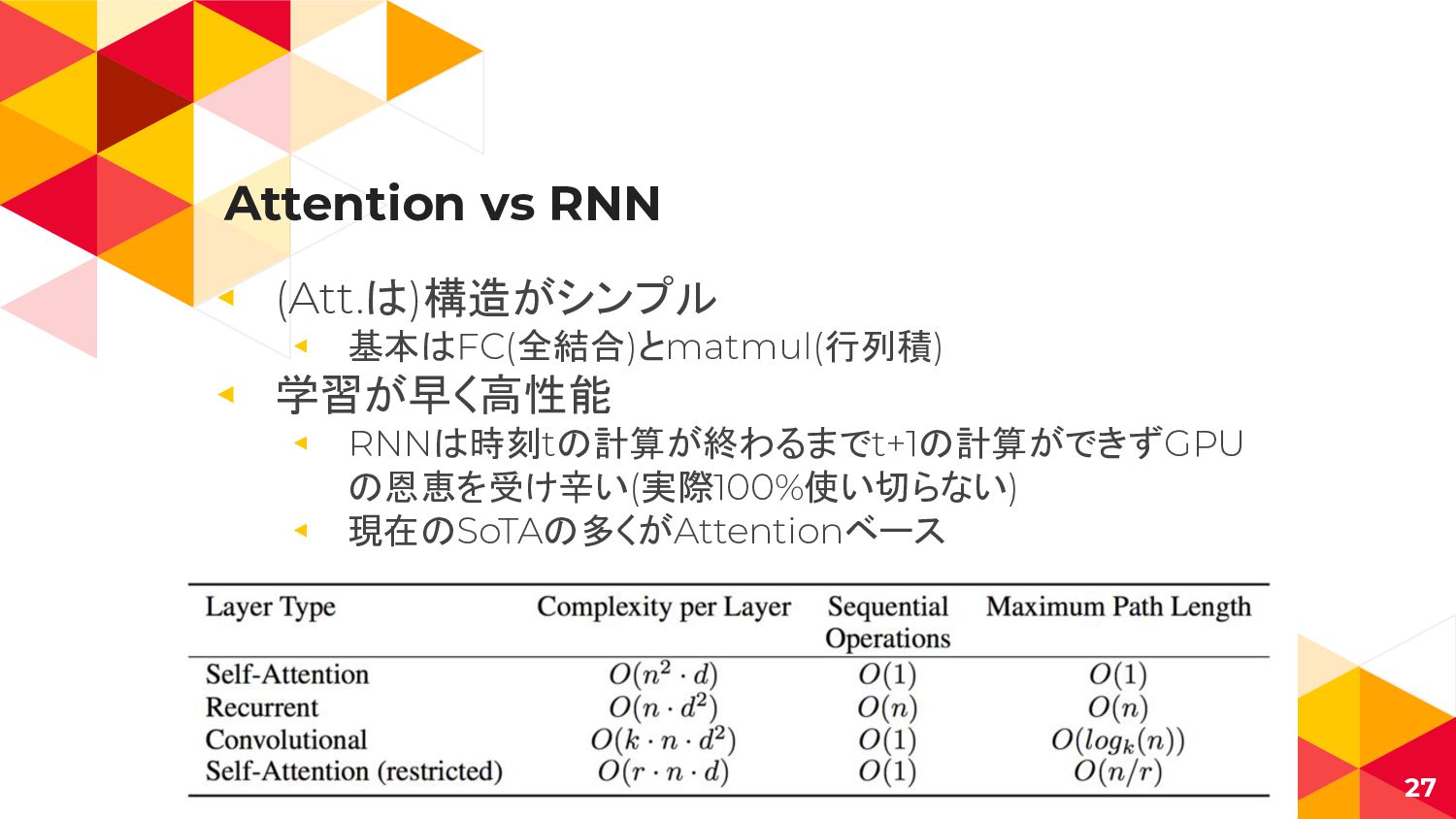
RNN(LSTM) shows no improvement ◂ SequentialといえばRNN、試したが改善せず ◂ NLPのように文法的制約もなく、 未来成分が収束していかない ◂
興味が定まらず、同時に複数の興味も持つため適さない ◂ 文章ほど意味のある連続性が行動履歴にはない ◂ ここの設計は今後の課題 26
Attention vs RNN ◂ (Att.は)構造がシンプル ◂ 基本はFC(全結合)とmatmul(行列積) ◂ 学習が早く高性能 ◂
RNNは時刻tの計算が終わるまでt+1の計算ができずGPU の恩恵を受け辛い(実際100%使い切らない) ◂ 現在のSoTAの多くがAttentionベース 27
5. TRAINING TECHNIQUES ◂ Regularization ◂ Activation Function 28
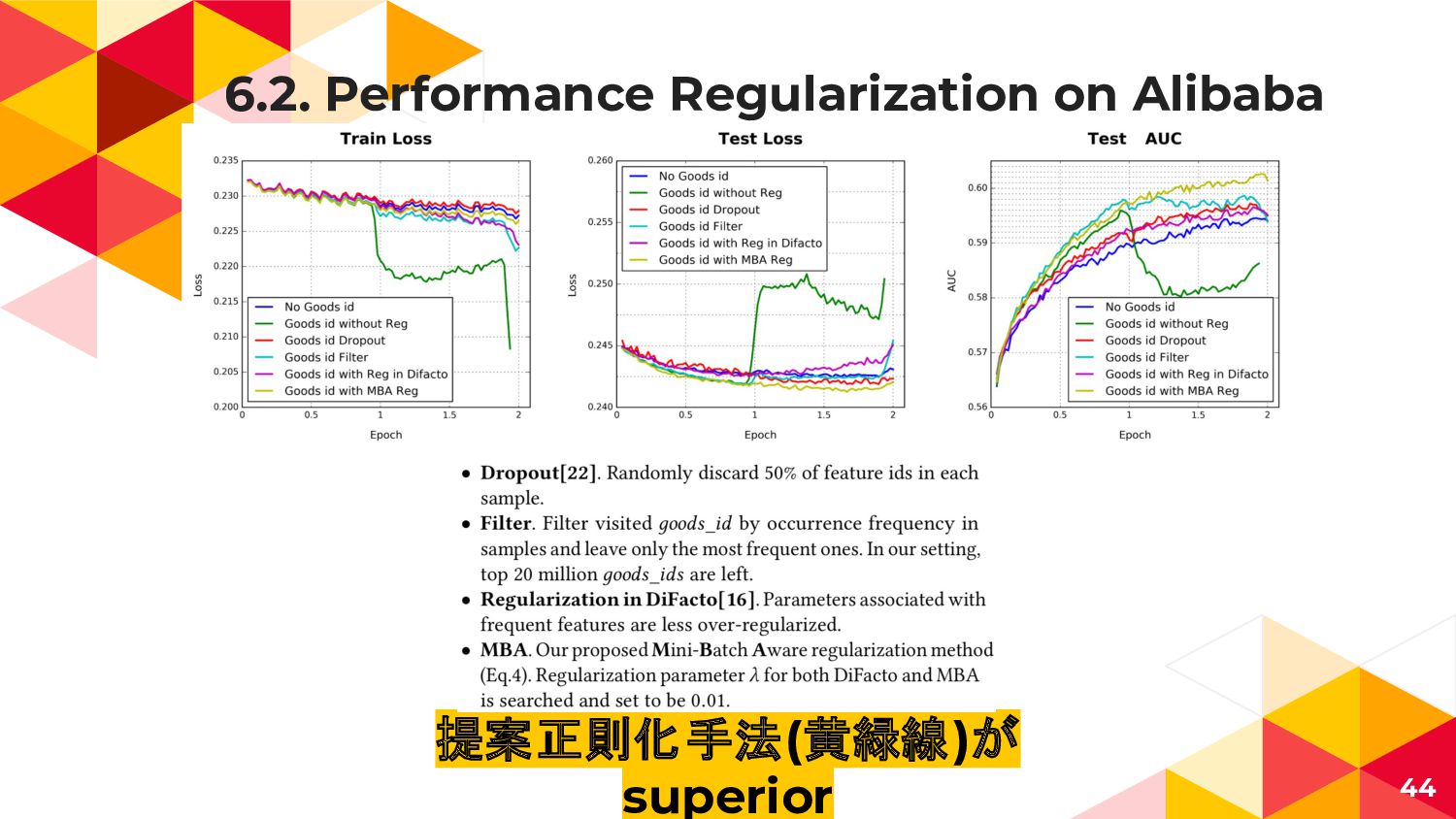
5.1. Regularization ◂ 学習ついでに最小化させるペナルティ項, 次元爆発防止 ◂ ||W|| 1 とか||W|| 2
2とか||W|| ∞ とか ◂ over fitを防ぐけどunder fitにもなる ◂ 正則化のないRichな特徴はモデルの性能を著しく低下 (緑線) ◂ Traditional L1 L2-norm arise heavy computation ◂ 本来non zeroなsparse成分だけ注目したいが 全成分からnorm計算しないといけない 29
5.1. Mini-batch Aware Regularization (proposed) ◂ non zeroなsparse成分だけ計算可能なL2正則化項 ◂ 低頻度な特徴ほど強い正則化をかけて影響を和らげる
30 低頻度な素性程 ここが大きくなる : batch x内に特徴 jがあるか : 特徴jの全出現回数 : 1epoch中に取りうるサンプル数(ミニバッチサイズ) : 特徴空間の次元数 L2正則化項
5.2. Activation Function ◂ 入力を非線形変換するNNの肝 ◂ 傾きが学習で使われるため 微分可能なことが大事 ◂ 種類がたくさん
◂ ReLU: Rectified Linear Unit ◂ LReLU: Leaky ReLU ◂ PReLU: Parametric ReLU ◂ Regularized PReLU ◂ Dice (proposed) ... 31
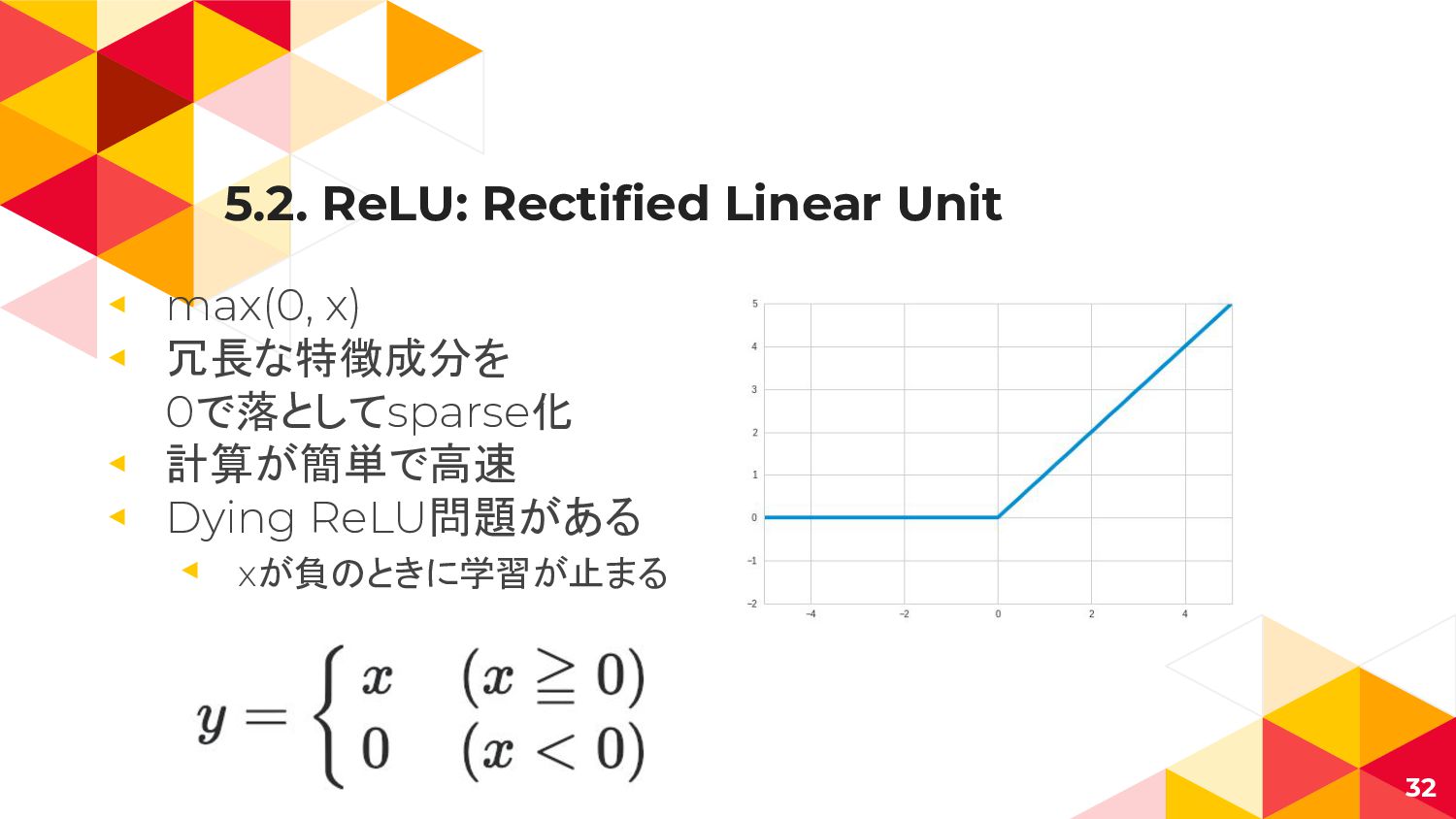
5.2. ReLU: Rectified Linear Unit ◂ max(0, x) ◂ 冗長な特徴成分を
0で落としてsparse化 ◂ 計算が簡単で高速 ◂ Dying ReLU問題がある ◂ xが負のときに学習が止まる 32
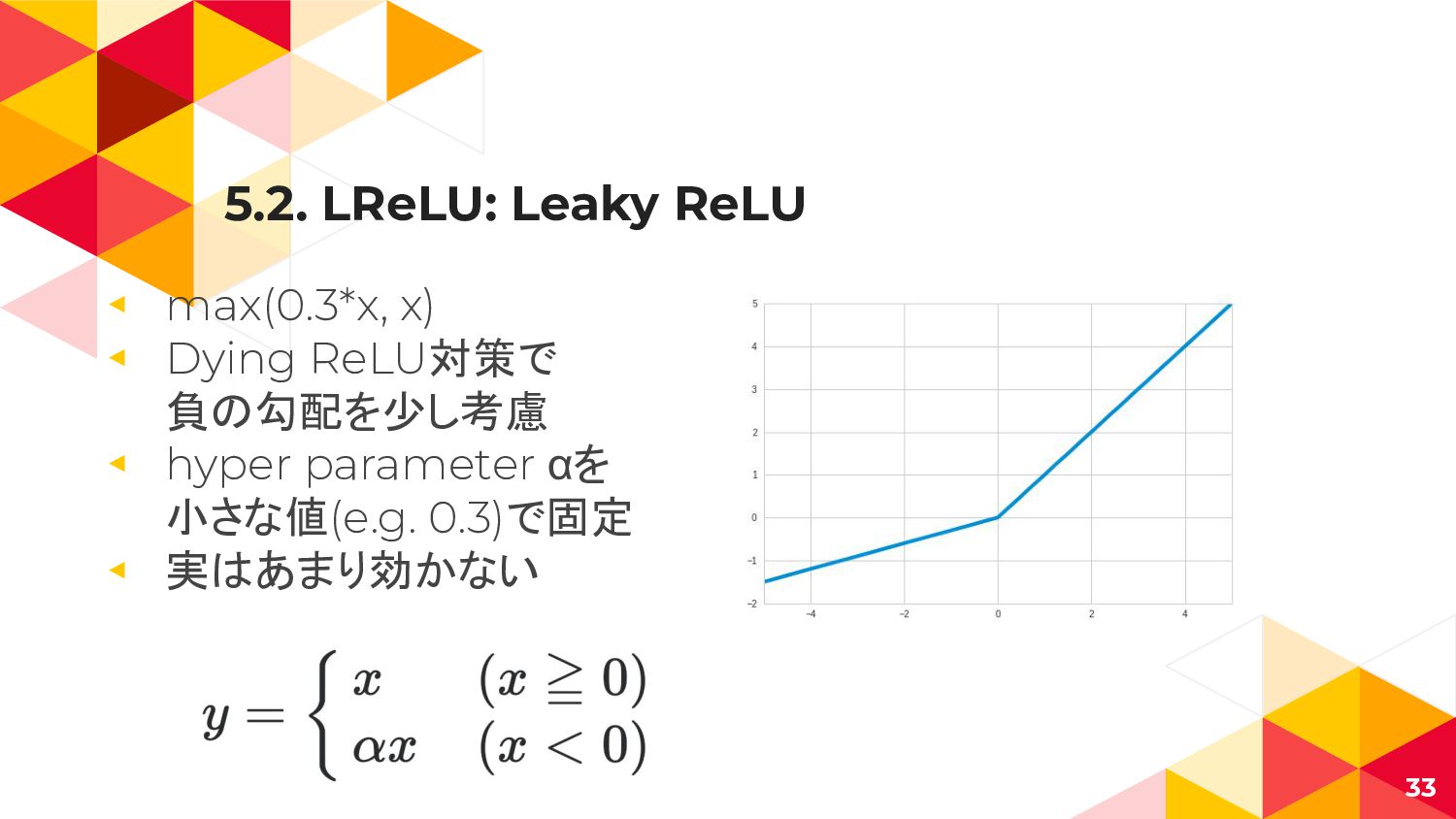
5.2. LReLU: Leaky ReLU ◂ max(0.3*x, x) ◂ Dying ReLU対策で
負の勾配を少し考慮 ◂ hyper parameter αを 小さな値(e.g. 0.3)で固定 ◂ 実はあまり効かない 33
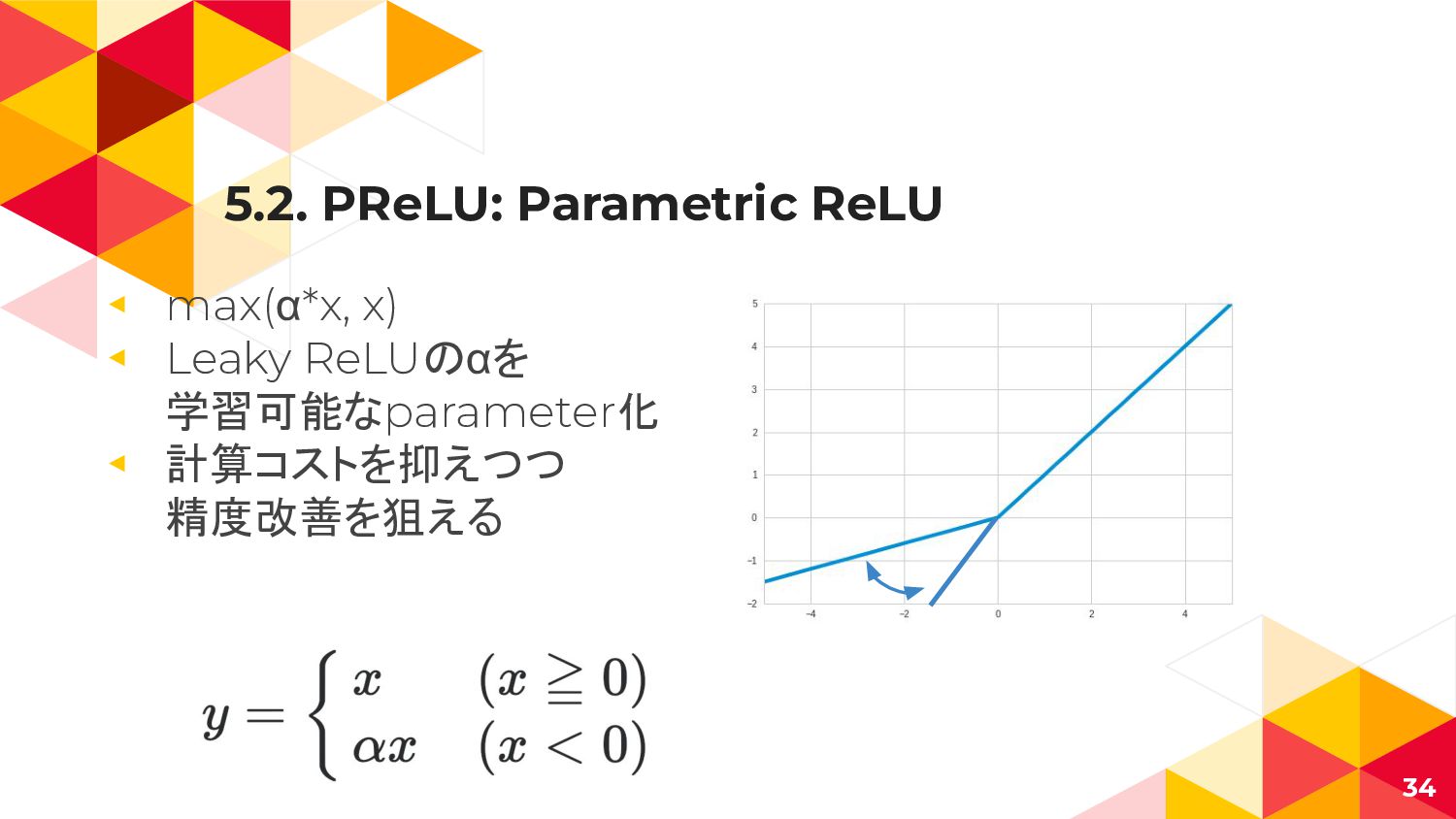
5.2. PReLU: Parametric ReLU ◂ max(α*x, x) ◂ Leaky ReLUのαを
学習可能なparameter化 ◂ 計算コストを抑えつつ 精度改善を狙える 34
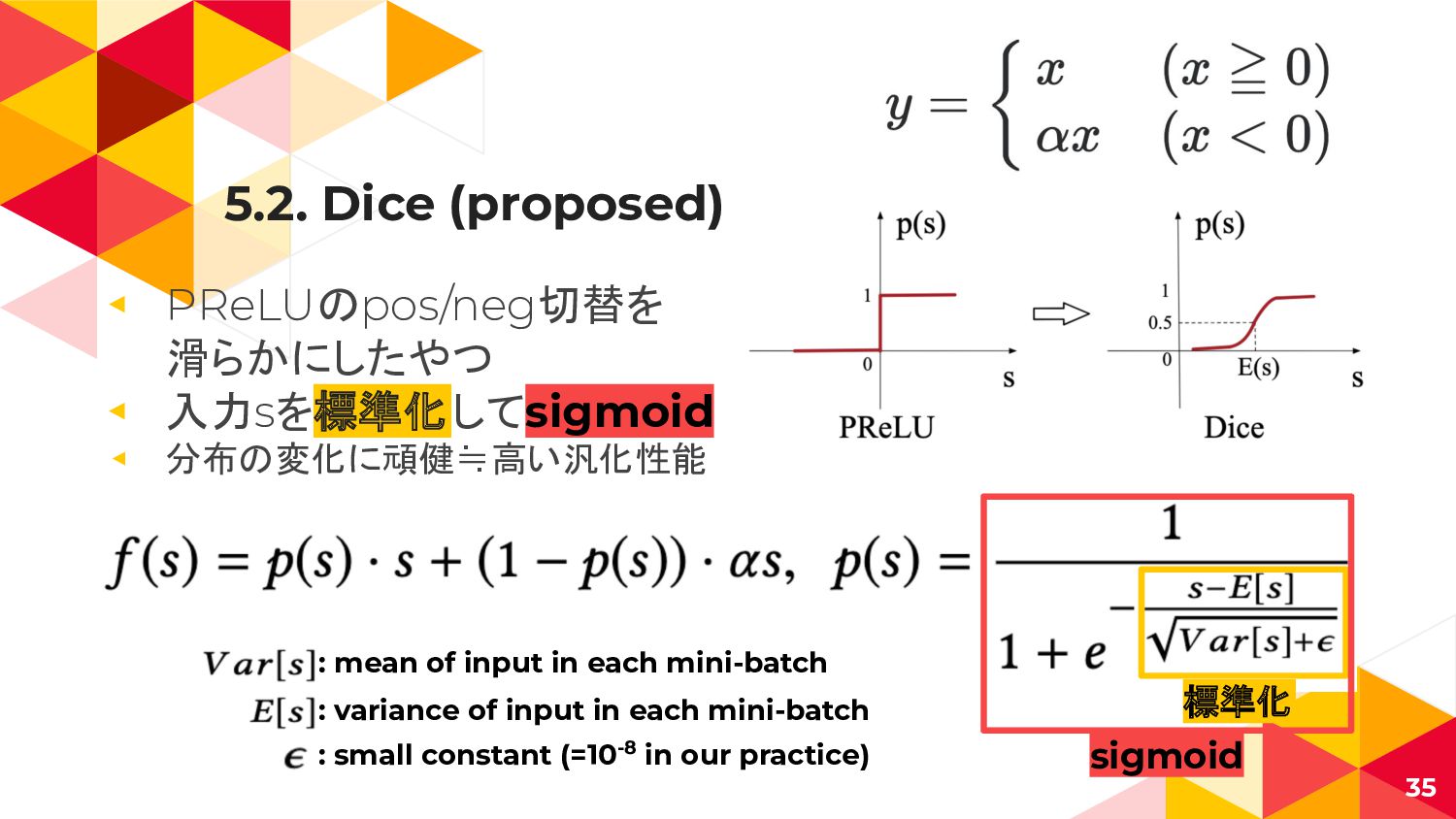
5.2. Dice (proposed) ◂ PReLUのpos/neg切替を 滑らかにしたやつ ◂ 入力sを標準化してsigmoid ◂ 分布の変化に頑健≒高い汎化性能
35 : mean of input in each mini-batch : variance of input in each mini-batch : small constant (=10-8 in our practice) 標準化 sigmoid
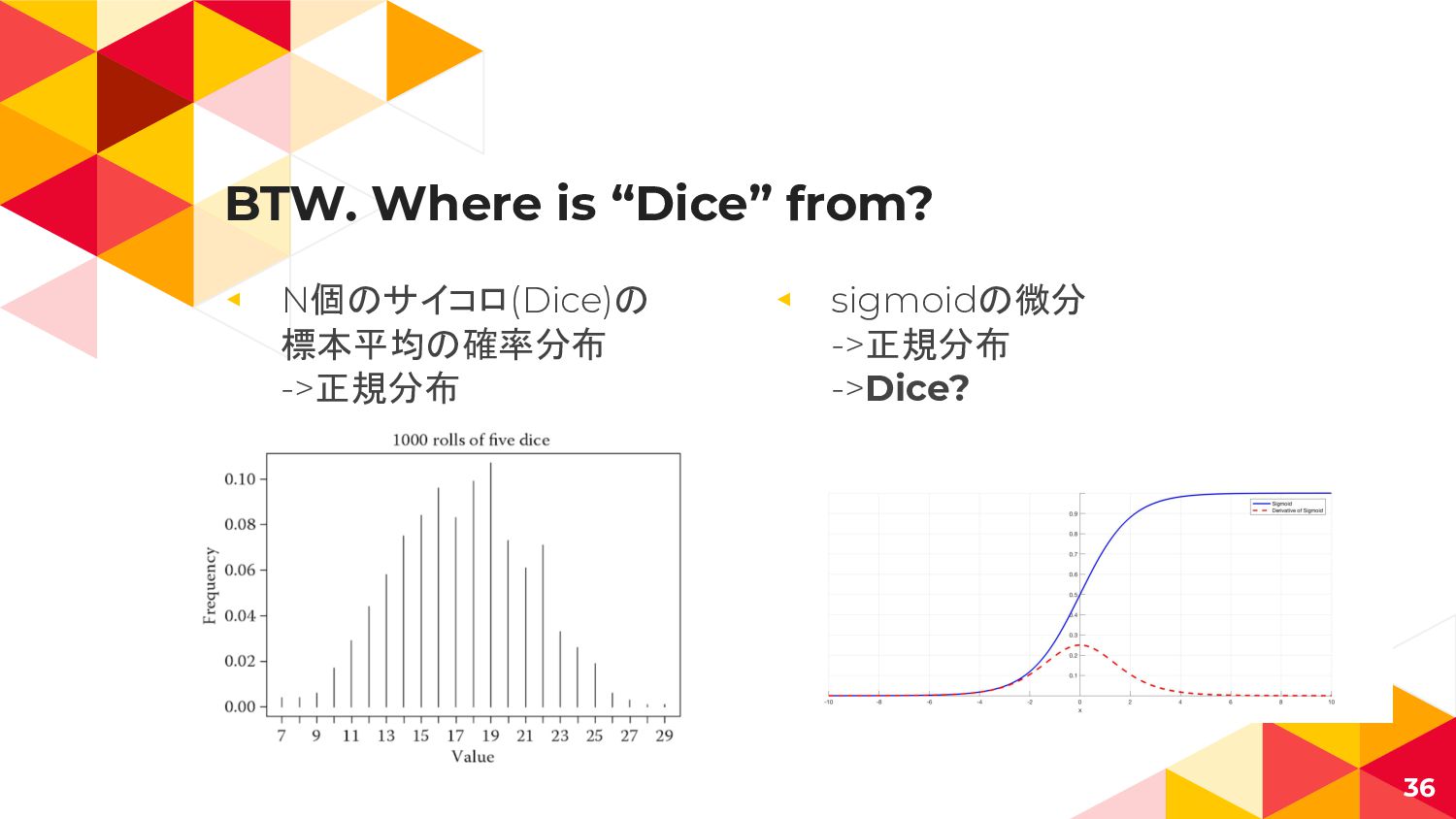
BTW. Where is “Dice” from? ◂ N個のサイコロ(Dice)の 標本平均の確率分布 ->正規分布 ◂
sigmoidの微分 ->正規分布 ->Dice? 36
6. EXPERIMENTS 1. Model comparison on public datasets 2. Performance
of regularization 3. Model comparison on alibaba dataset 4. A/B testing 5. Visualization 37
6.1. Datasets ◂ Amazon ◂ 商品のレビュー x Userのデータ ◂ レビュー数が5以上の家電商品,
Userに絞って 各Userのreview履歴を元に最後にreviewした商品を予測 ◂ MovieLens ◂ 映画のレビュー x Userのデータ ◂ 0-5 Rating -> 0-3=not Click, 4-5=Click ◂ Randomに選んだ100000Usersで学習, 残り38493UsersでTest ◂ 各Userのrating履歴を元に与えられた映画に 3以上つけるかを予測 ◂ Alibaba ◂ 2週間分20億の広告配信trafficで学習, 翌日の1.4億でTest 38
6.1. Alibaba Dataset 39
6.1. Metrics 40 Random予測を0.5としてbaselineから何%改善したか
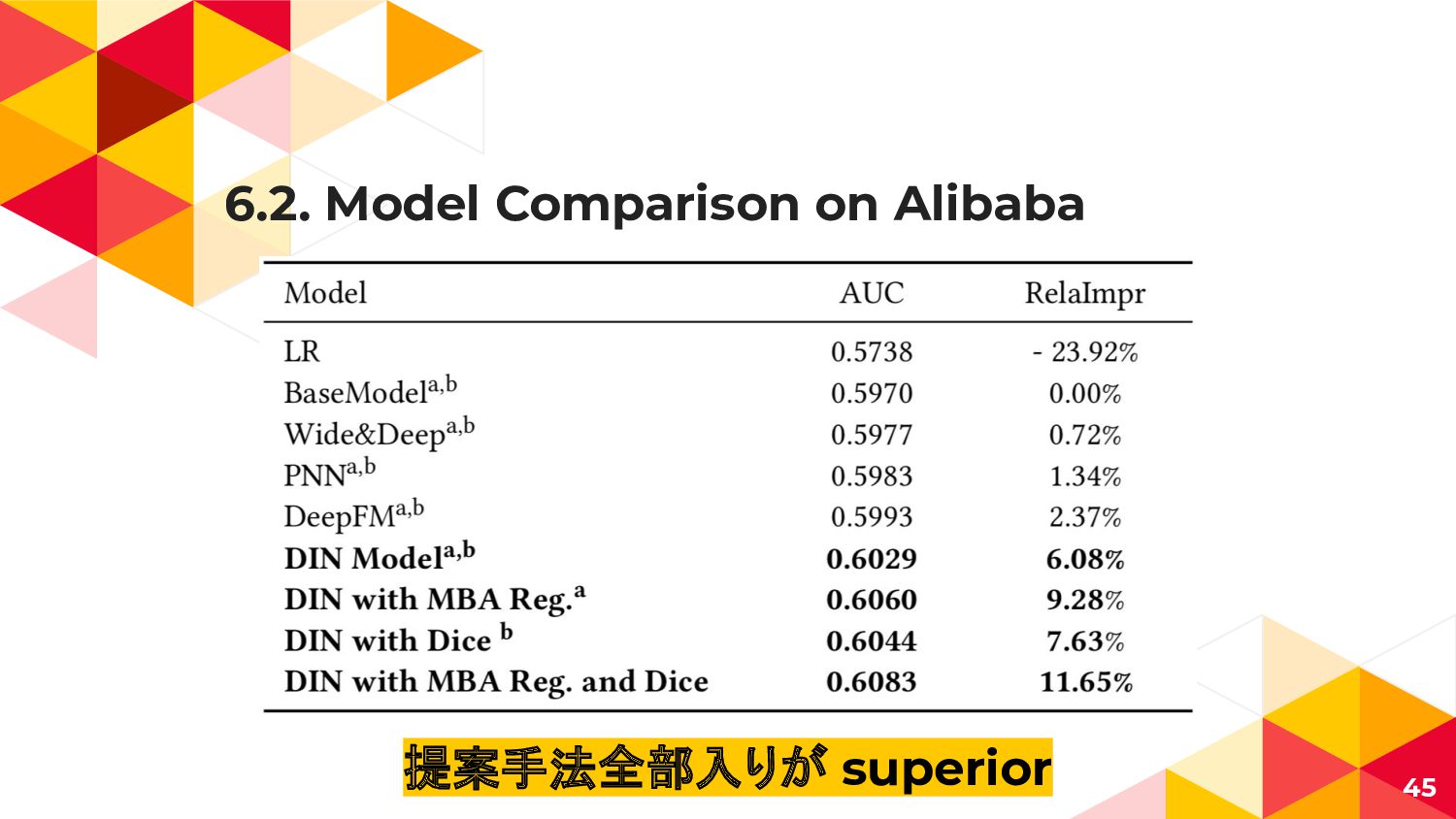
6.2. 戦わせるモデル ◂ LR ◂ ロジスティック回帰, 1層のsigmoid ◂ BaseModel ◂
特徴をシンプルに横に繫げて MLP ◂ Wide&Deep ◂ 特徴を横に繋げてMLPかつ 効きそうなEmbeddingの組を明示的に交差項として混ぜる ◂ Wide部分が線形モデルなので Feature Engineering依存 ◂ PNN ◂ 交互作用として特徴同士の内積や外積を取って横に繋げて MLP ◂ 低次元の交差項を捉えるのが苦手 ◂ DeepFM ◂ GoodsやAd, UserFeatureの交互作用をFMで表現することでPNNの弱点を克服 41
6.2. 戦わせるモデル ◂ 先程の既存手法たち ◂ 基本的にhistoricalを考慮していない ◂ Proposed DNN ◂
Proposed DNN w/ Proposed reg. ◂ Proposed DNN w/ Proposed act. ◂ Proposed w/ Proposed reg. & act. 42
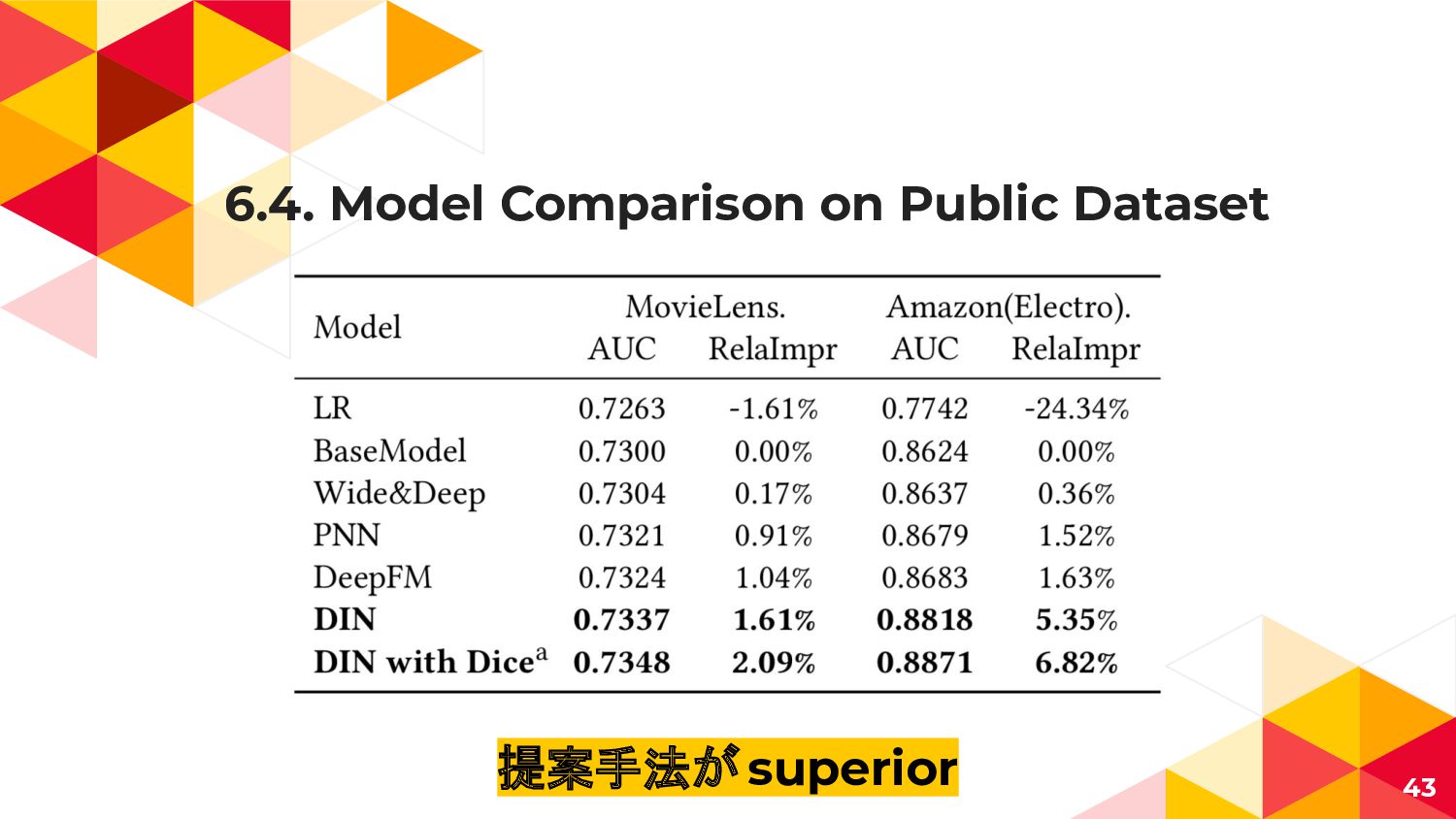
6.4. Model Comparison on Public Dataset 43 提案手法が superior
6.2. Performance Regularization on Alibaba 44 提案正則化手法(黄緑線)が superior
6.2. Model Comparison on Alibaba 45 提案手法全部入りが superior
6.7. Online A/B Test ◂ 2017/05 - /06の1ヶ月間実施 ◂ CTR:
10%↑ ◂ CVR: 3.3%↑ ◂ GPM: 12.6%↑ 46
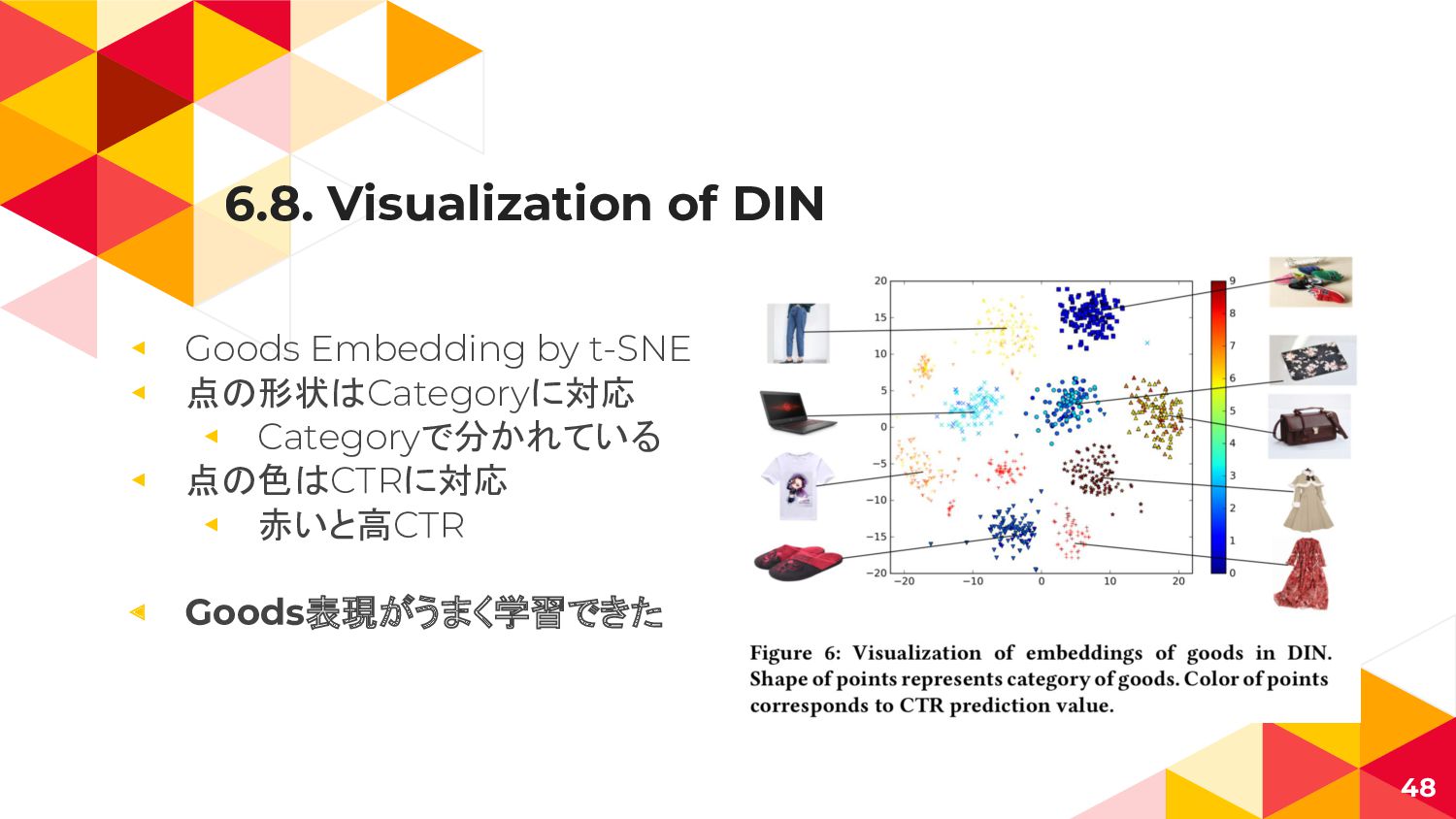
6.8. Visualization of DIN ◂ どのBehavior(接触した Goods)がモデルに 寄与したか ◂ 広告クリエイティブに
関連の高い Goodsを 可視化できた 47
6.8. Visualization of DIN ◂ Goods Embedding by t-SNE ◂
点の形状はCategoryに対応 ◂ Categoryで分かれている ◂ 点の色はCTRに対応 ◂ 赤いと高CTR ◂ Goods表現がうまく学習できた 48
SUMMARY ◂ Userの行動履歴を組み込んだDNNでCTR予測改善 ◂ Ad * Hitorical Behaviorの関連性をAttentionで表現 ◂ Datasetの設計が興味深い
◂ Movie Rating -> CTR予測 ◂ RNNで上手くいってるモデルと比較してほしかった ◂ GPU likeで学習コストも比較的軽めな構造 ◂ BehaviorとMeta dataがあればいいので適用しやすそう ◂ Userの行動履歴を持つプロダクトでいかがでしょうか 49
50 Thanks! Any questions? You can find me at ◂
@chck ◂
[email protected]
Appendix
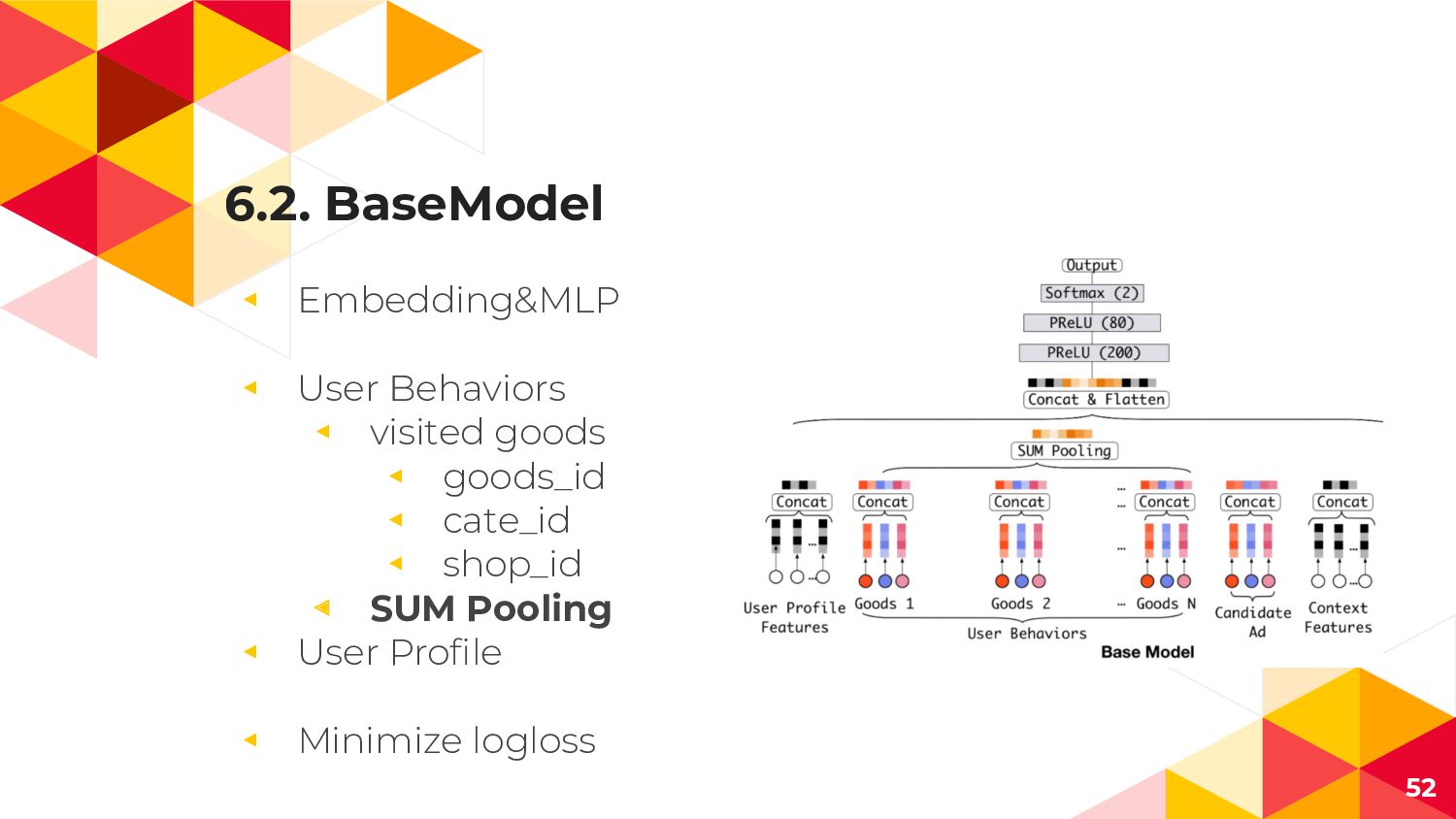
6.2. BaseModel ◂ Embedding&MLP ◂ User Behaviors ◂ visited goods
◂ goods_id ◂ cate_id ◂ shop_id ◂ SUM Pooling ◂ User Profile ◂ Minimize logloss 52
6.2. Pooling in CNN ◂ Convolution Layerで 畳み込んだ行列をどう Down Samplingするか
◂ Max ◂ Sum ◂ Average ◂ Is a pooling layer necessary in CNN? 53
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}