Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文読み会 / GLAZE: Protecting Artists from Style Mi...
Search
chck
April 14, 2023
Research
93
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文読み会 / GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models
社内論文読み会、PaperFridayでの発表資料です
chck
April 14, 2023
More Decks by chck
See All by chck
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.7k
CyberAgent AI Lab研修 / Container for Research
chck
1
2.4k
CyberAgent AI Lab研修 / Code Review in a Team
chck
3
2.4k
論文読み会 / Socio-Technical Anti-Patterns in Building ML-Enabled Software: Insights from Leaders on the Forefront
chck
0
140
CyberAgent AI事業本部MLOps研修Container編 / Container for MLOps
chck
3
6k
論文読み会 / On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
chck
0
71
論文読み会 / GUIGAN: Learning to Generate GUI Designs Using Generative Adversarial Networks
chck
0
66
機械学習開発のためのコンテナ入門 / Container for ML
chck
0
990
Other Decks in Research
See All in Research
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
140
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
660
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
390
AIで最適化を解けるか?
mickey_kubo
0
130
Ankylosing Spondylitis
ankh2054
0
180
正規分布と最適化について
koide3
1
290
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
500
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
430
Claude Code × autoresearch 実践
mathbullet
0
200
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
200
Using our influence and power for patient safety
helenbevan
0
370
Featured
See All Featured
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Git: the NoSQL Database
bkeepers
PRO
432
67k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Embracing the Ebb and Flow
colly
88
5.1k
So, you think you're a good person
axbom
PRO
2
2.1k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
340
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Navigating Team Friction
lara
192
16k
Ruling the World: When Life Gets Gamed
codingconduct
0
270
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Transcript
GLAZE: Protecting Artists from Style Mimicry by Text-to-Image Models 23/04/14
PaperFriday, Yuki Iwazaki@AI Lab
2 Point: 画像生成モデルのスタイル模倣をミスリードさせる ノイズ合成ツールを絵描き向けに公開 arXiv preprint, 2023 Feb Authors: Shawn
Shan, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, Ben Y. Zhao Reason: - Diffusion modelが流行っているのでそのキャッチアップ - 生成モデルの芸術界への影響
Introduction 3
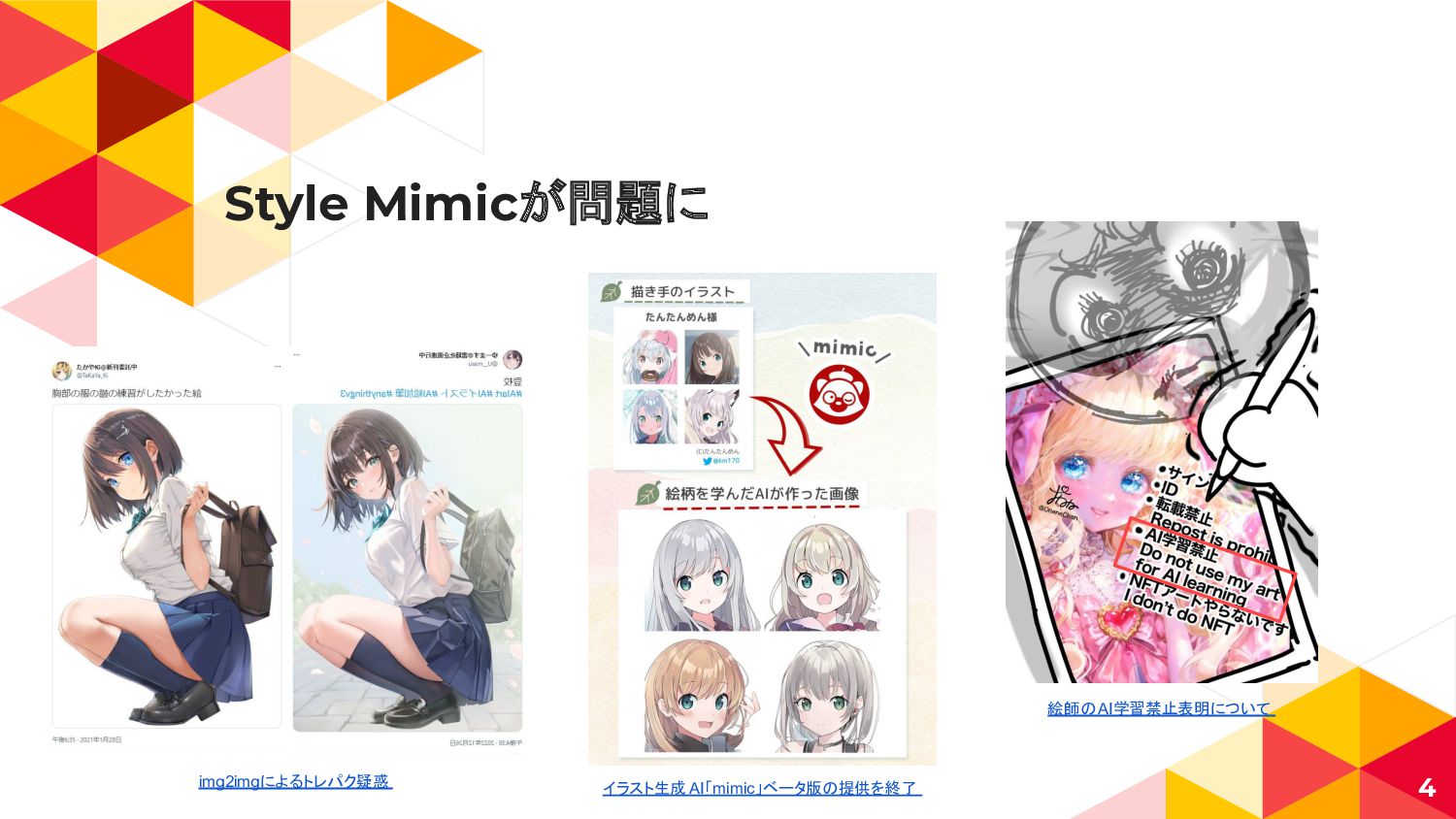
Style Mimicが問題に 4 イラスト生成 AI「mimic」ベータ版の提供を終了 img2imgによるトレパク疑惑 絵師のAI学習禁止表明について
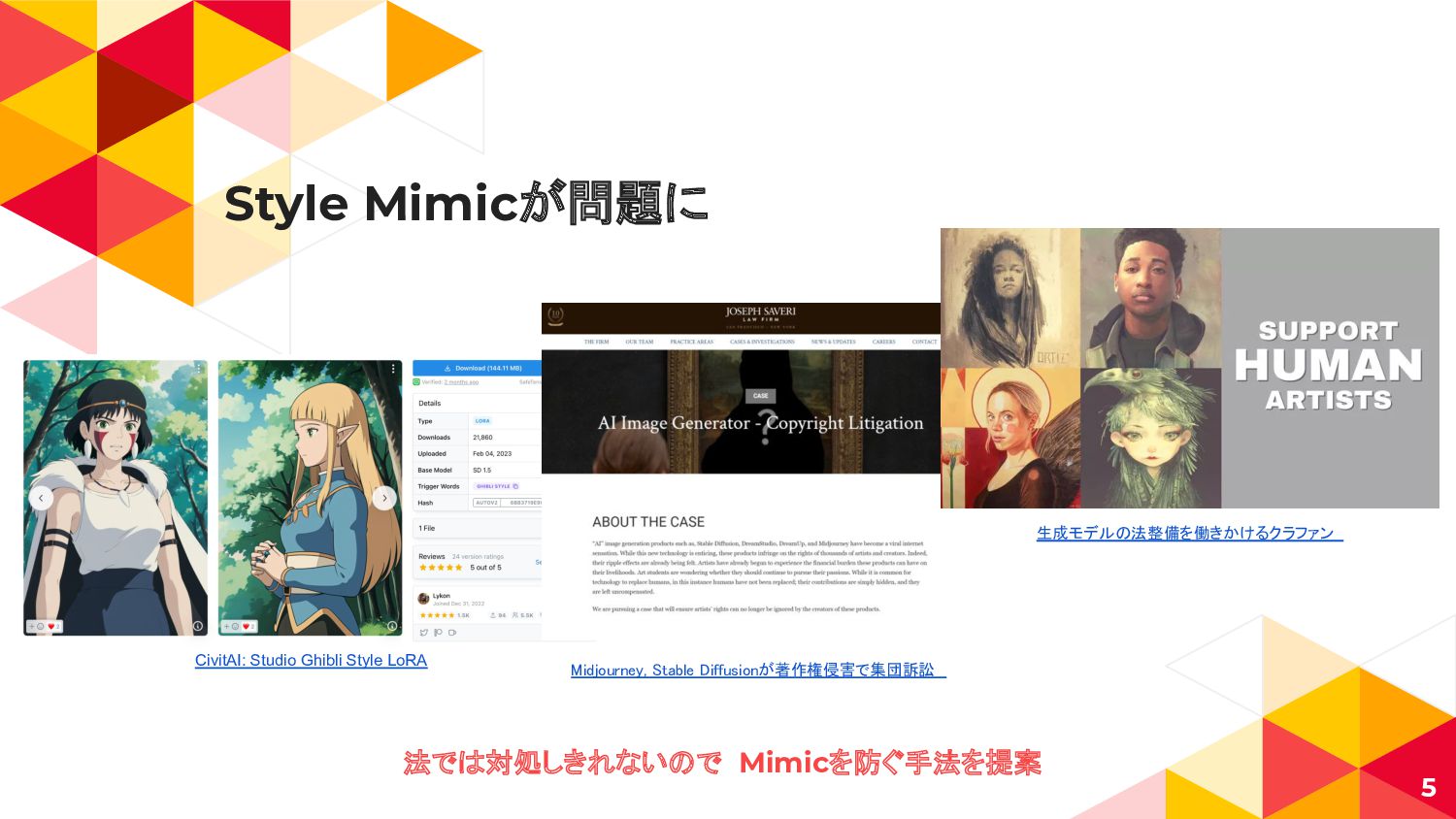
Style Mimicが問題に 5 CivitAI: Studio Ghibli Style LoRA Midjourney, Stable
Diffusionが著作権侵害で集団訴訟 生成モデルの法整備を働きかけるクラファン 法では対処しきれないので Mimicを防ぐ手法を提案
Recent Work 6
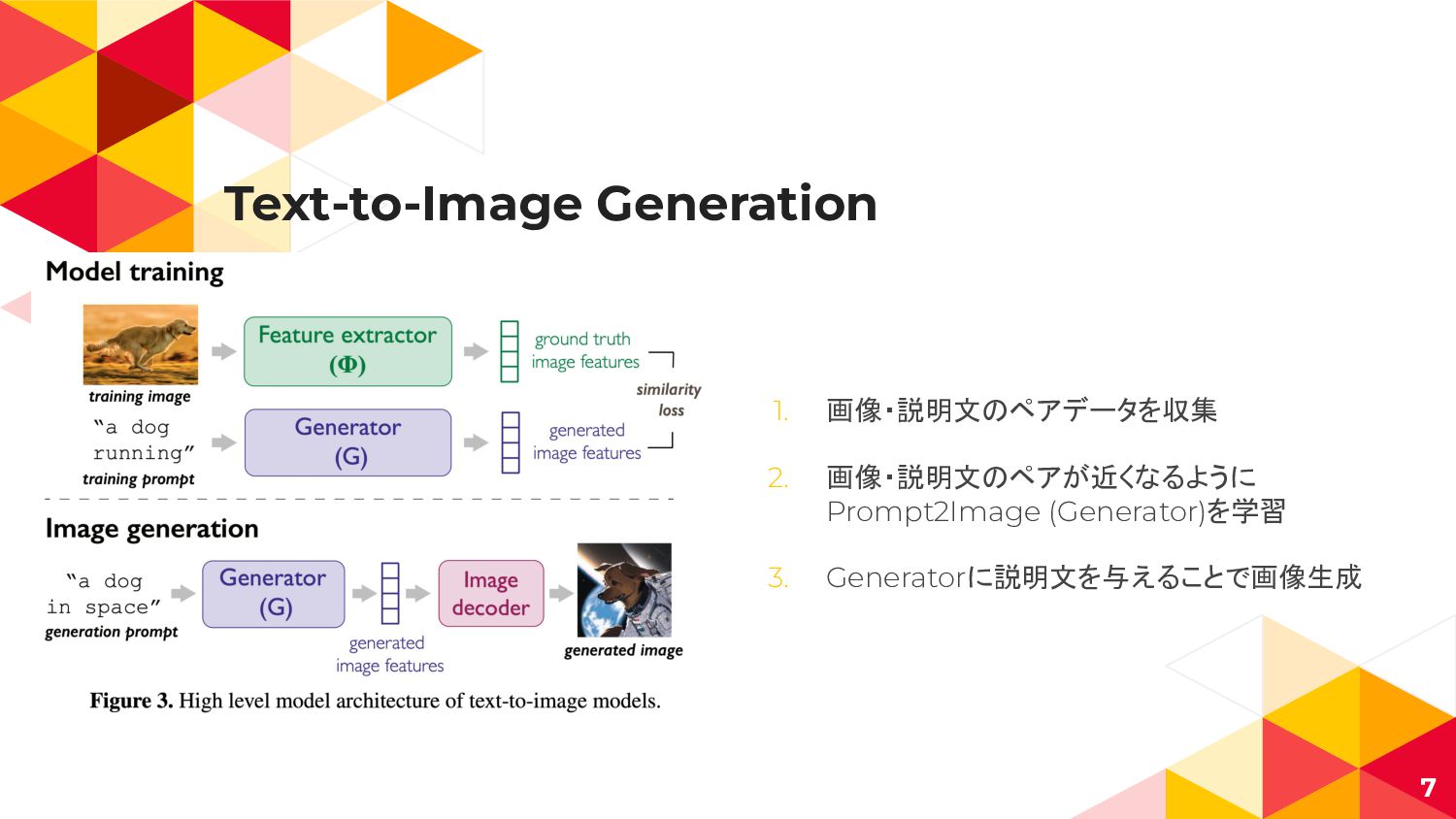
Text-to-Image Generation 7 1. 画像・説明文のペアデータを収集 2. 画像・説明文のペアが近くなるように Prompt2Image (Generator)を学習 3.
Generatorに説明文を与えることで画像生成
Style mimicry techniques a. 著名なArtistの場合: 学習データに名前を含んでいるので生 成時のTextにArtist名を含めるだけ b. 著名でない場合: 学習済生成モデルを
Target ArtistでFine-tune 学習コストは画像追加 20枚, GPU1枚20分程度 10 OpenAI DALL·E 2 https://zenn.dev/kwashizzz/articles/ml-stable-diffusion-colab-fn
Proposed Method 11
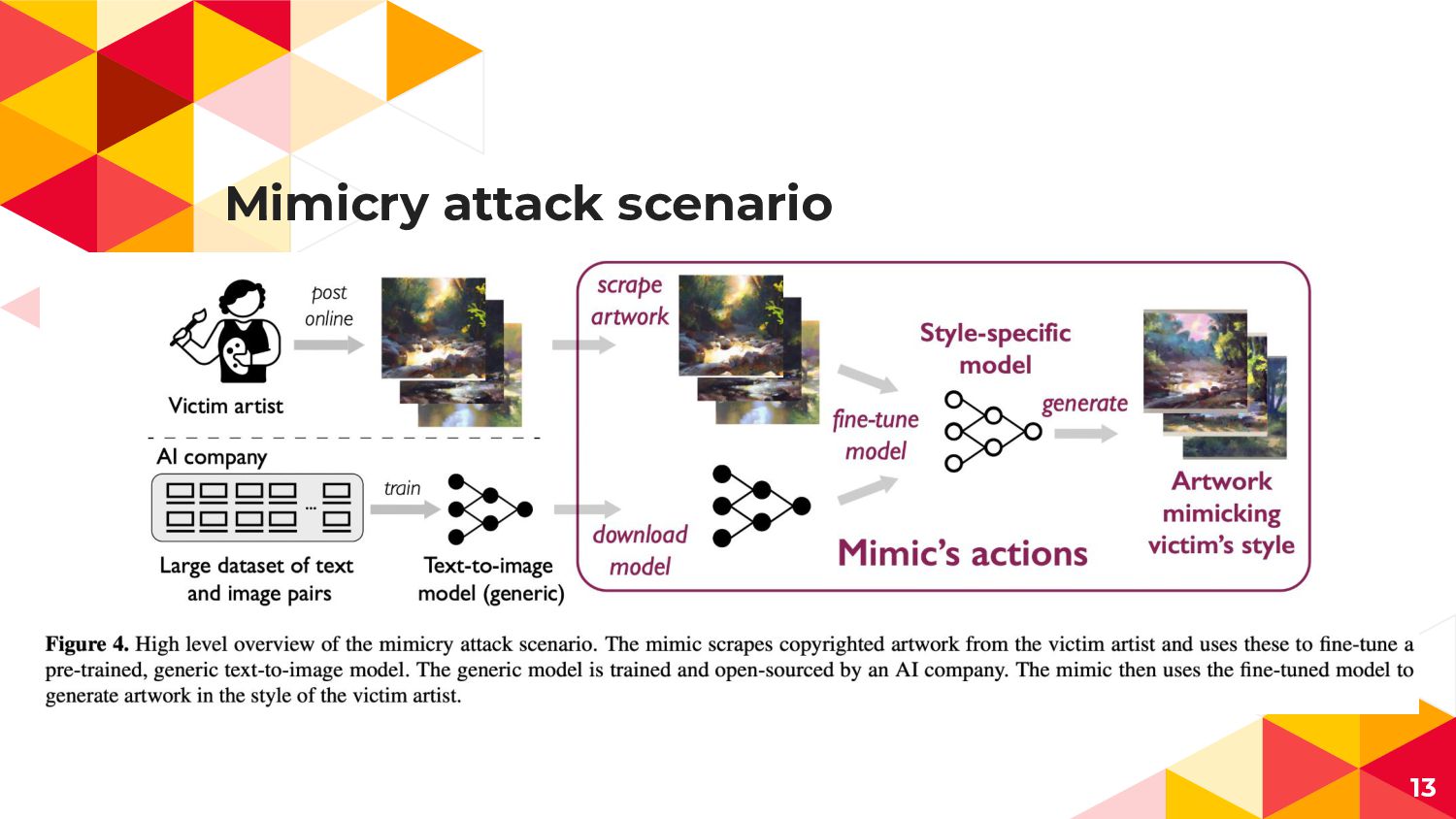
Mimicry attack scenario 13
GLAZE to protect style mimicry 絵をオンラインに投稿する前に スタイル模倣を阻害するノイズを乗せる └指定アーティストとは別のスタイルで学習されてしまう ようなノイズ 14
Design Intuition 15 画風の定義は難しいので Style transferに着目 模倣されてもいい特徴( Objectや位置関係)を分離
Computing Style Cloaks 任意のスタイル Tに変換した入力画像 xと 視覚的な特徴が同じになるようなノイズδ x を計算 16
2.入力画像 xをスタイル Tに変換した画像 汎用な画像特徴抽出器 1. 入力画像 xにノイズを加えた画像
Detailed System Design 0. 入力画像x, 画像特徴抽出器Φ, スタイル転送モデル Ω, ノイズ強度pが与えられる 1.
スタイルTの選択...ゴッホのような公開アーティスト画像を収集、スタイル候補群とする 入力画像xの特徴量との距離が遠いスタイル候補を選択 2.スタイル変換...事前学習済スタイル転送モデル Ωを使って スタイル変換画像Ω(x,T)を生成 3.ノイズの計算... 4.画像のアップロード...全作品を差し替えなくても効果的 17 ノイズの強さを調整 ダミースタイルの特徴に近く、ノイズを加えても見た目の近 さ(LPIPS)も担保されるような δ_xを計算
Evaluation 18
Experiment Setup ◂ Dataset ◂ 現代アーティスト: 協力者4名×30枚前後 ◂ pHashで既存の公開学習データに当画像が含まれていないことを確認 ◂
歴史的アーティスト: WikiArtの195名×30枚 ◂ これらは逆に公開学習データに含まれているので画風阻害が難しいシナリオ ◂ 模倣シナリオ ◂ 1. キャプション生成モデル を使ってオリジナル画像から説明文を生成 ◂ 説明文にアーティスト名も追記 ◂ 2. 説明文と画像のペアから該当アーティストの生成モデルを学習 ◂ 3. 生成した説明文から模倣画像を生成、オリジナル画像と比較 ◂ 生成モデル ◂ Stable Diffusion…拡散ベースの画像生成モデル ◂ DALL-E-mega…VAEベースの画像生成モデル 19
Evaluation Metrics ◂ CLIP-based genre shift↑: ◂ CLIPで生成画像の芸術ジャンルを推定、 上位3ジャンルが正解ジャンルを含まない生成画像率 ->
高い程ジャンルをシフトできている ◂ Human evaluation↑: ◂ 本手法を適用したオリジナル画像と模倣画像を見せ、 対策成功率を5段階評価 -> 高い程成功 20
Protection Performance 21
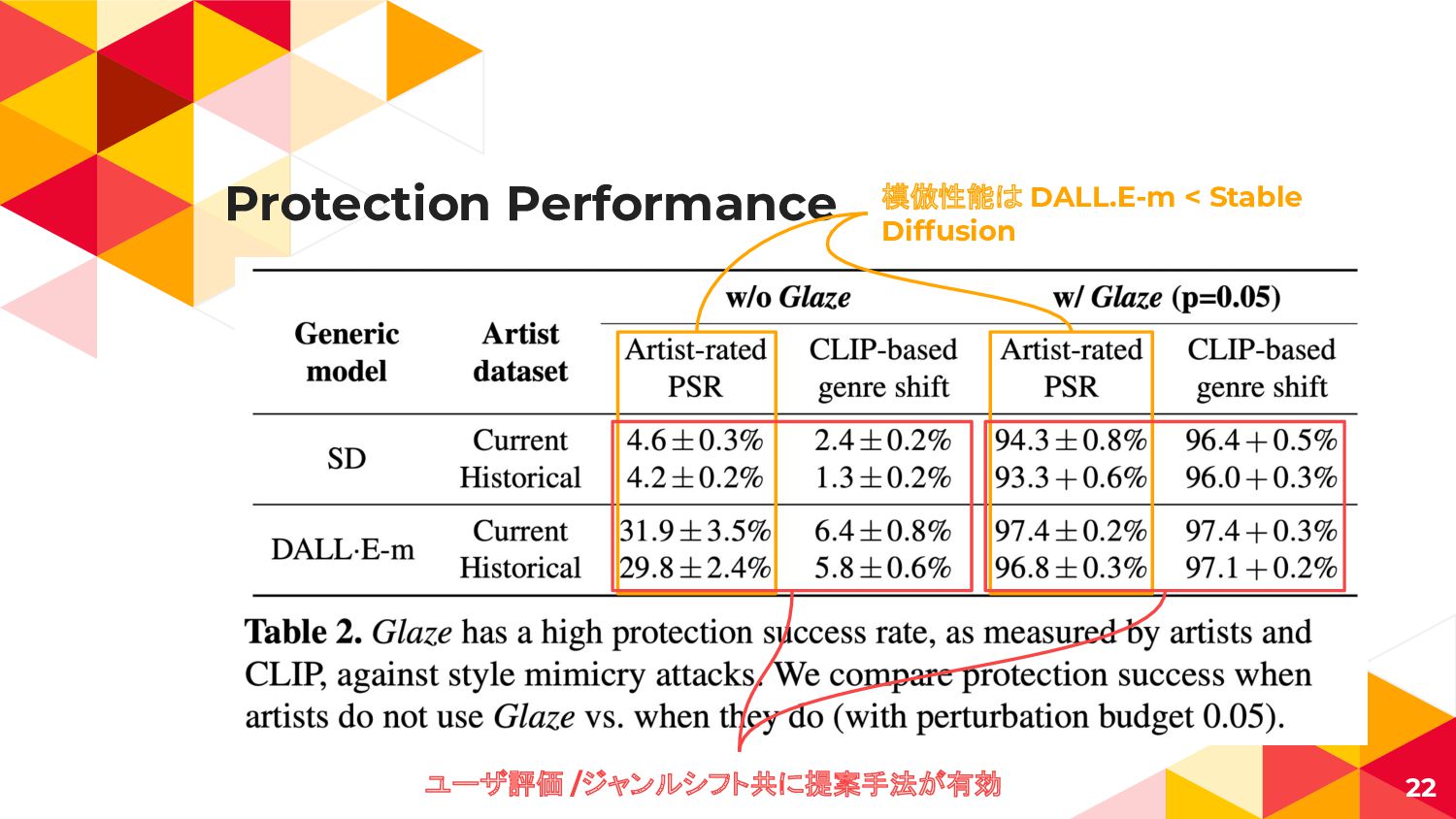
Protection Performance 22 模倣性能は DALL.E-m < Stable Diffusion ユーザ評価 /ジャンルシフト共に提案手法が有効
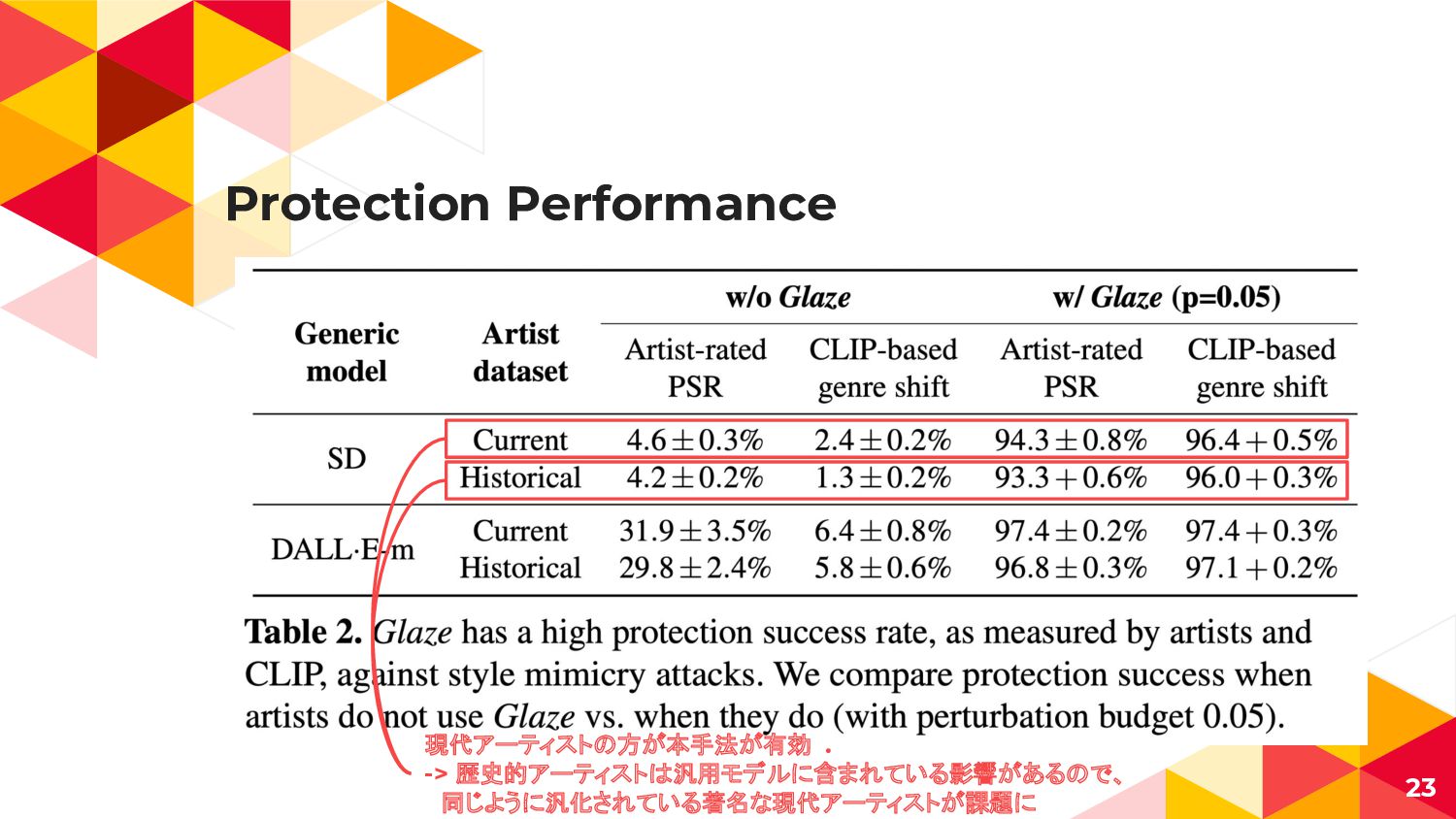
Protection Performance 23 現代アーティストの方が本手法が有効 . -> 歴史的アーティストは汎用モデルに含まれている影響があるので、 同じように汎化されている著名な現代アーティストが課題に
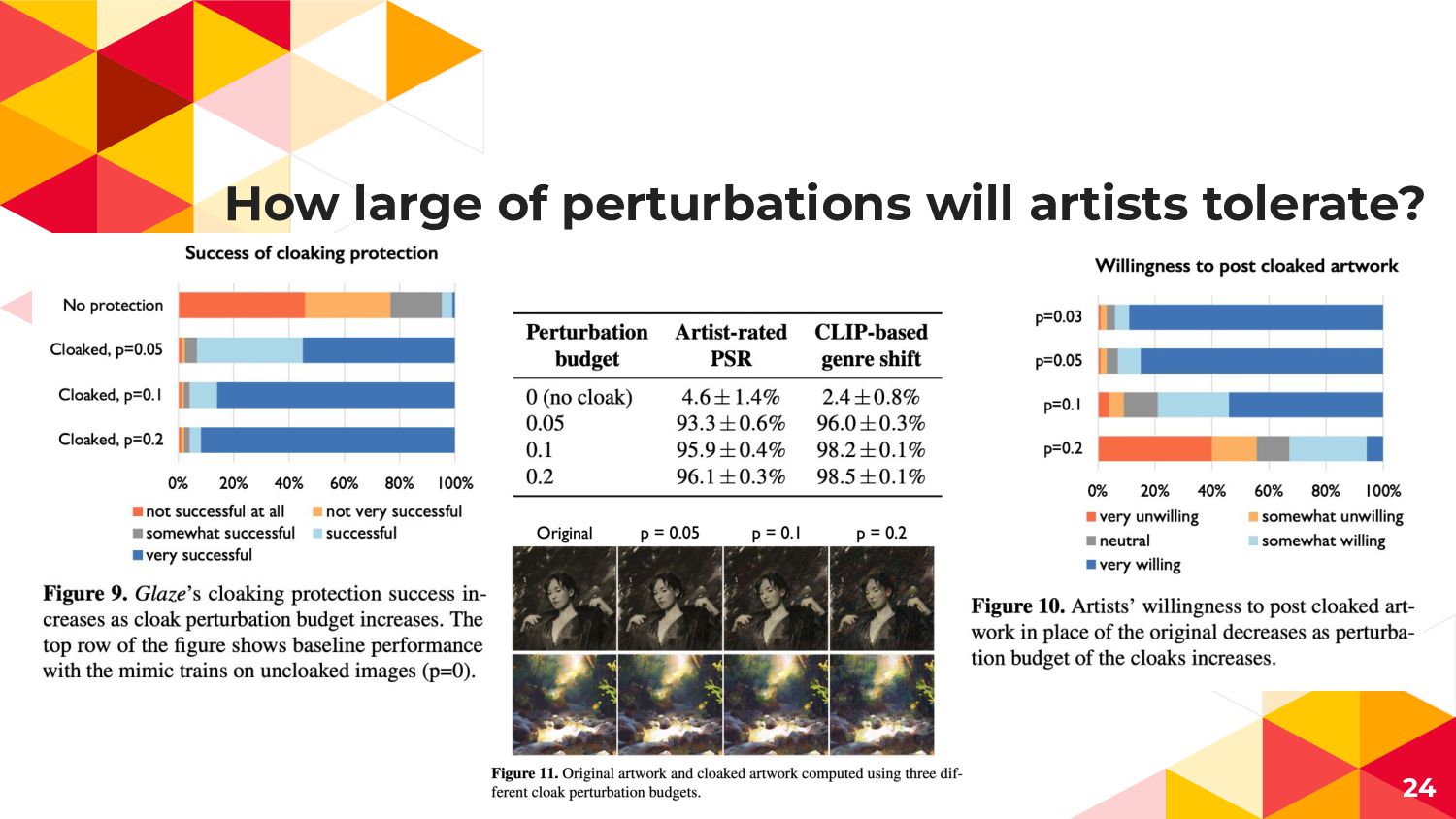
How large of perturbations will artists tolerate? 24
Protection Robustness 25 特徴抽出器 Φのベースモデルによる比較( ΦA:ΦA: > ΦA:ΦB) 対策/生成モデルで特徴抽出器の ベースモデル
や学習データ が異なっていても本手法は有効 特徴抽出器 Φの学習データセットによる比較 (ΦB:ΦA: > ΦC:ΦA)
Protection Robustness 26 全作品の 25%のノイズ対応でも 9割近い効果がある 75%対応すると見た目でもダミースタイルが効いていることがわかる
Real-World Performance scenario.comという画像一式をアップロードしたら そのスタイルの画像が生成できるWeb Service上での評価 27 実サービスでも本手法が有効
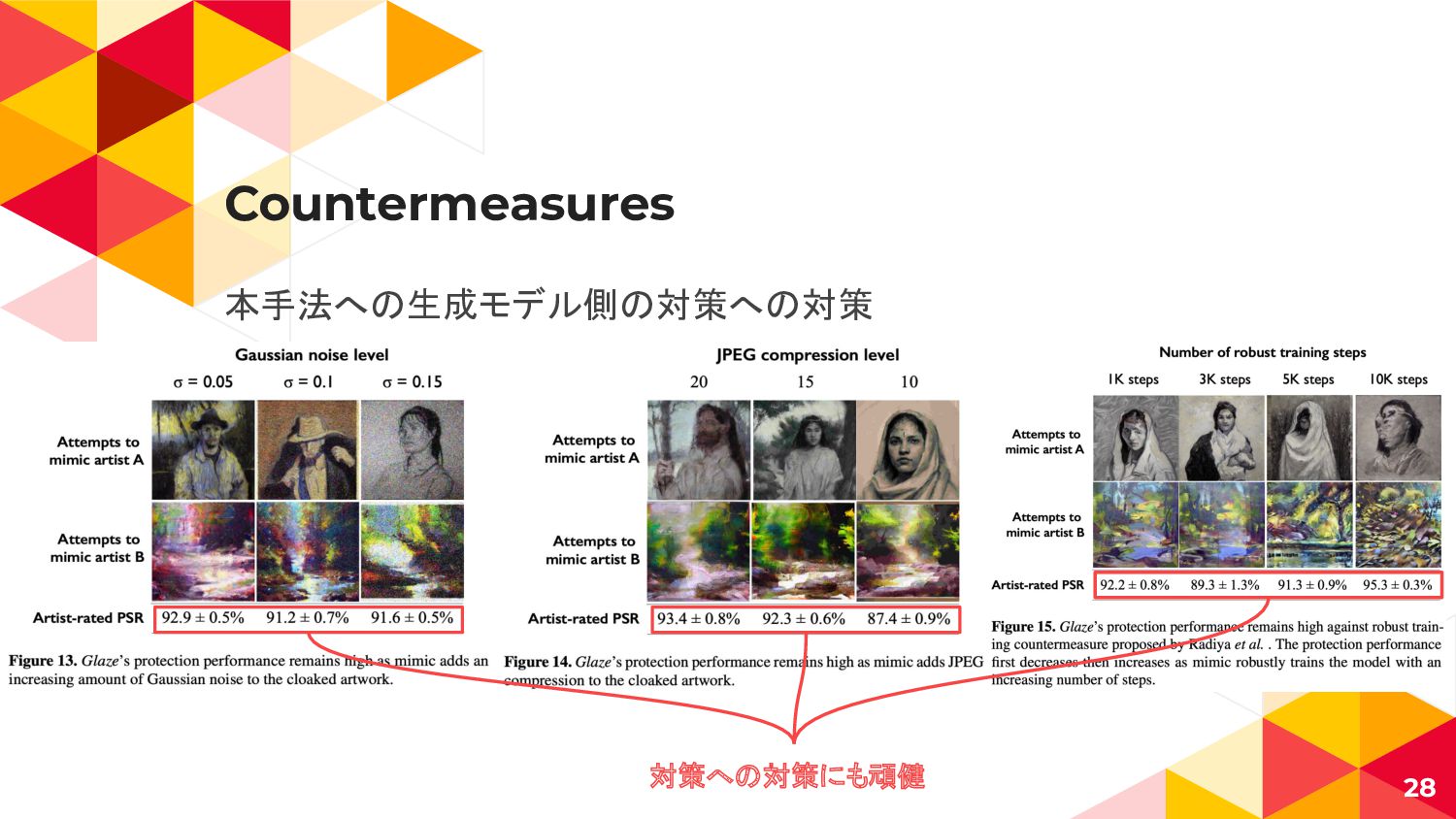
Countermeasures 本手法への生成モデル側の対策への対策 28 対策への対策にも頑健
Limitations ◂ この手法をかけていない割合の高いアーティストには効果が薄い ◂ 絵が出回るほど既に有名だったり歴の長いアーティスト ◂ 対策の対策の対策の... ◂ 運用を続けていくことや ツールとして公開しているのでまずは広く使ってもらうことが大切
◂ ユーザの計算リソースに依存 ◂ エッジ(ユーザーPC)側で処理を完結する都合上 ◂ 4GBのモデルのダウンロードの後 , GTX 1080 GPUで画像1枚あたり20分 29
Comment • いたちごっこ ◦ これが流行ることでのデータ汚染もありえそう ▪ このノイズにも強いモデルが出るだけ説 ◦ 生成/対策モデルの性能向上によるリアル GAN
• エッジ推論の良い実例 ◦ デスクトップアプリも使いやすい • 一般ユーザ的にはノイズが気になるのでは ◦ ノイズ強度(弱→強)を変えて回してみた結果 ↓ 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}