APIs are a fantastic way to extend the functionality of a solution across the data center and public clouds. However, as a solution expands the features and available use cases, the complexity of an API surface area scales in parallel. In terms of cloud data management, it can be difficult to create a consistent and deterministic experience when dealing with a huge quantity of integration points (virtual machines, cloud native workloads, file servers, physical servers, hypervisors, etc). At the same time, the user experience is directly impacted by the quality of documentation and frequency of communication, which are often overlooked by project teams. In this session, you’ll hear about the construction of REST and GraphQL APIs that are used by infrastructure engineers and cloud architects around the globe for data management and the various challenges tackled to deliver an exceptional user experience.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
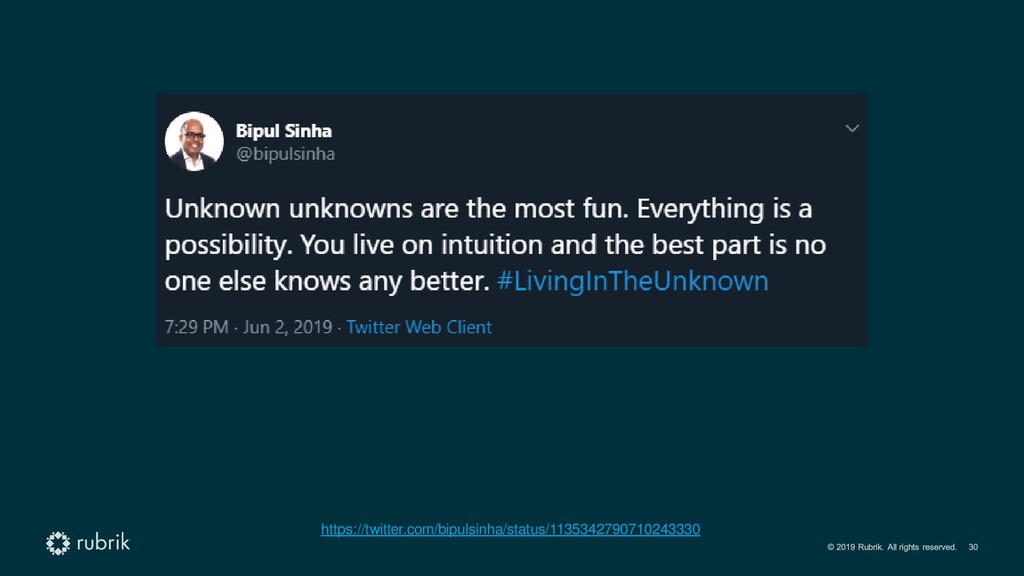{kind=link}
{kind=link}
{kind=link}
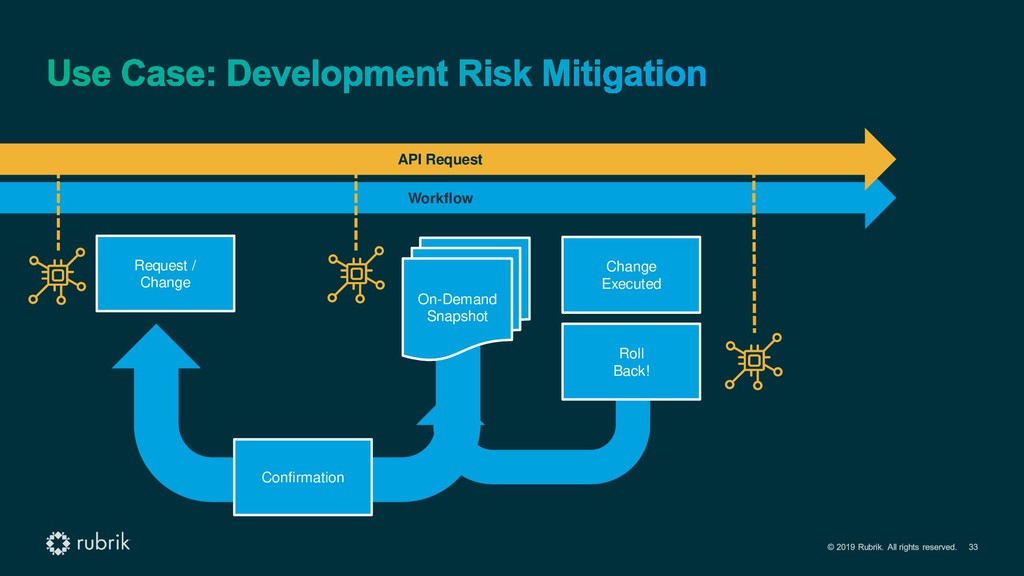{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}