Sai Srirampur, a solution architect for PostgreSQL and Citus databases, will present "Optimizing distinct counts on PostgreSQL with HLL".
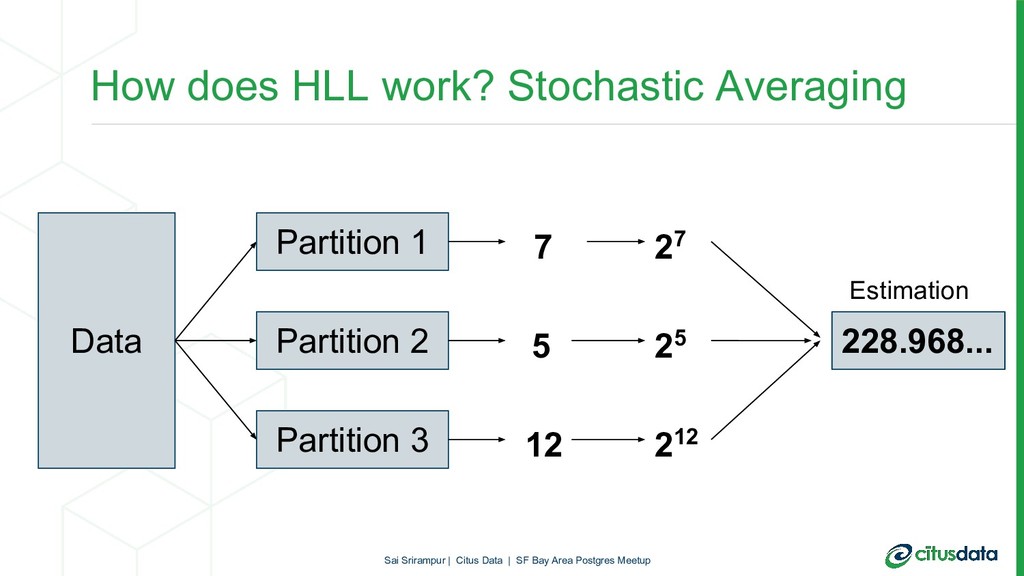
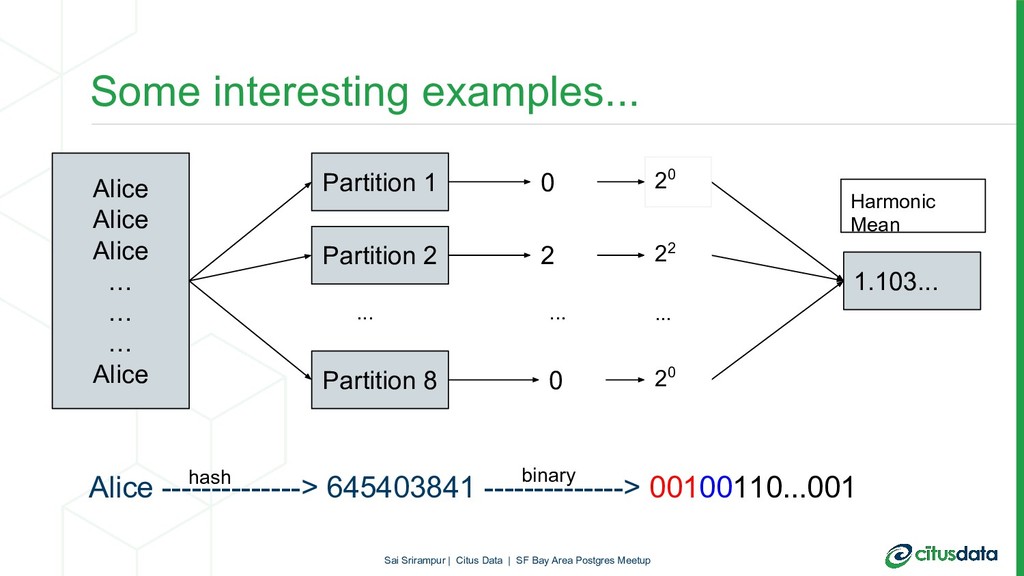
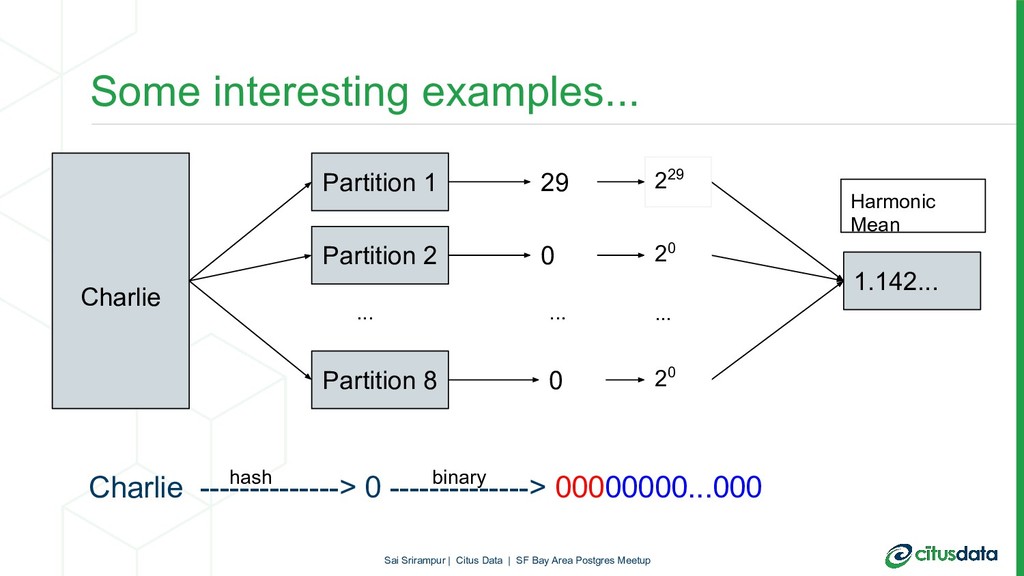
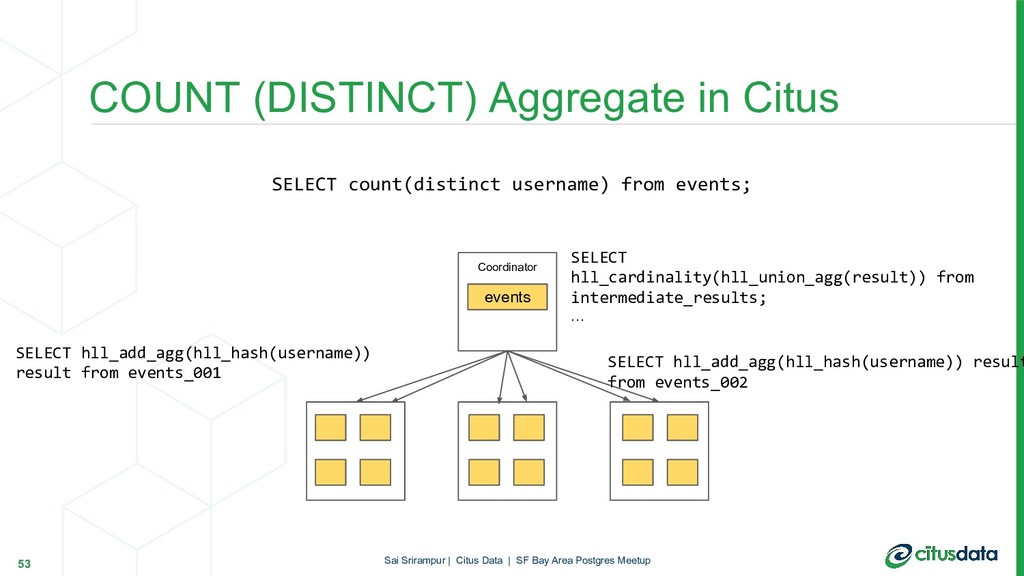
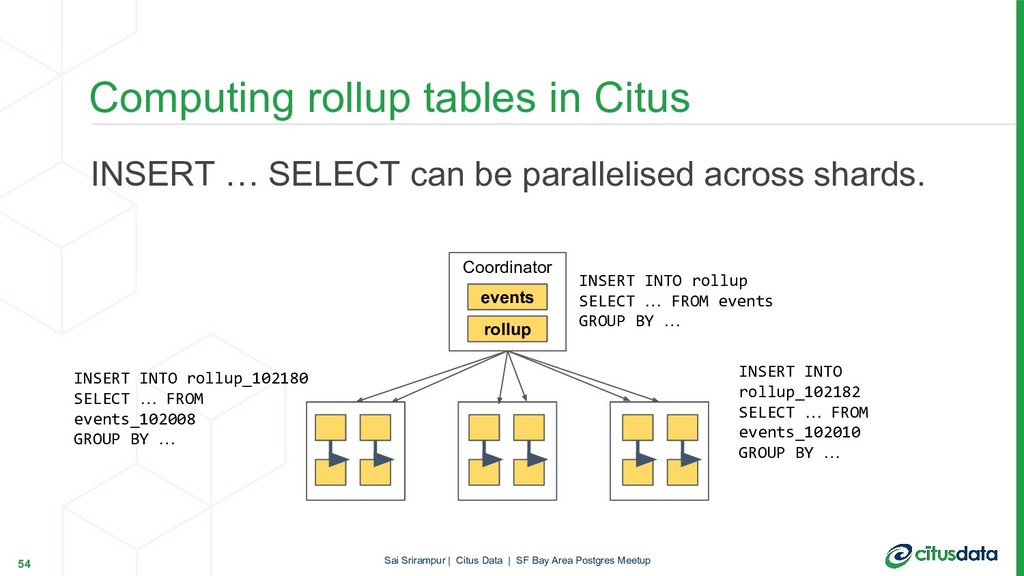
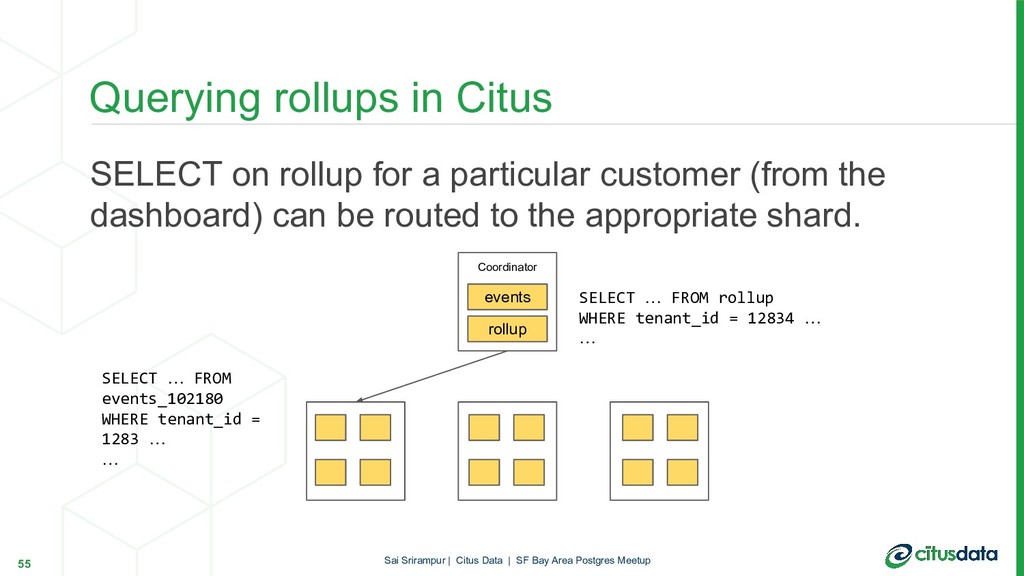
In this talk, we will focus on HyperLogLog (HLL) algorithm and its PostgreSQL extension postgresql-hll. HLL can provide approximate answers to COUNT(DISTINCT) queries in mathematically provable error bounds. HLL is not only fast and memory-efficient but also has very interesting properties which especially shine in a distributed environment. During the talk, first, we’ll look at the internals of the HLL. Then, we will look to understand why HLL algorithm is useful to get efficient pre-aggregations and distinct counts in scalable way. Finally, we will look at how HLL can be used in a distributed Postgres database cluster with Citus.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
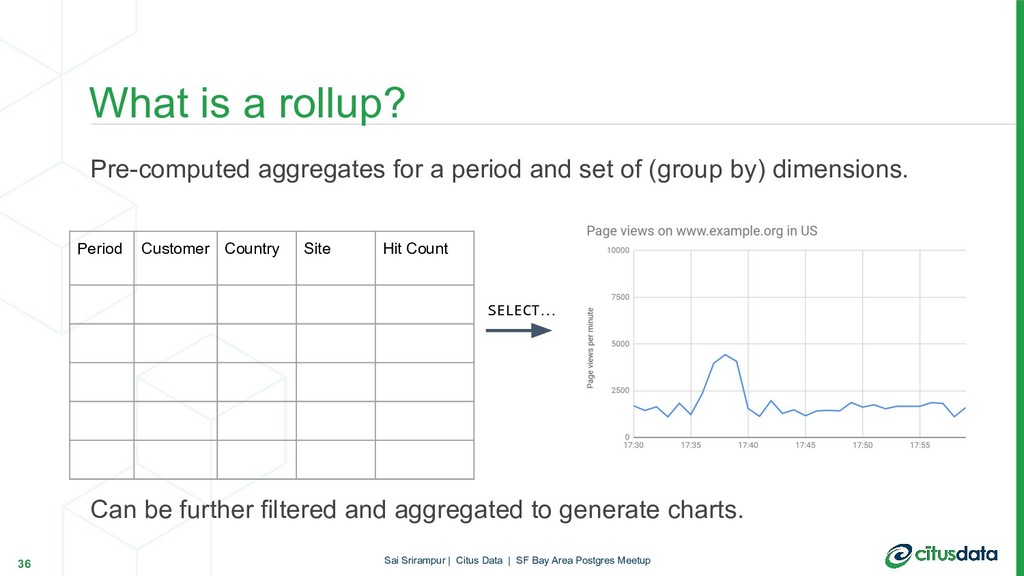{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
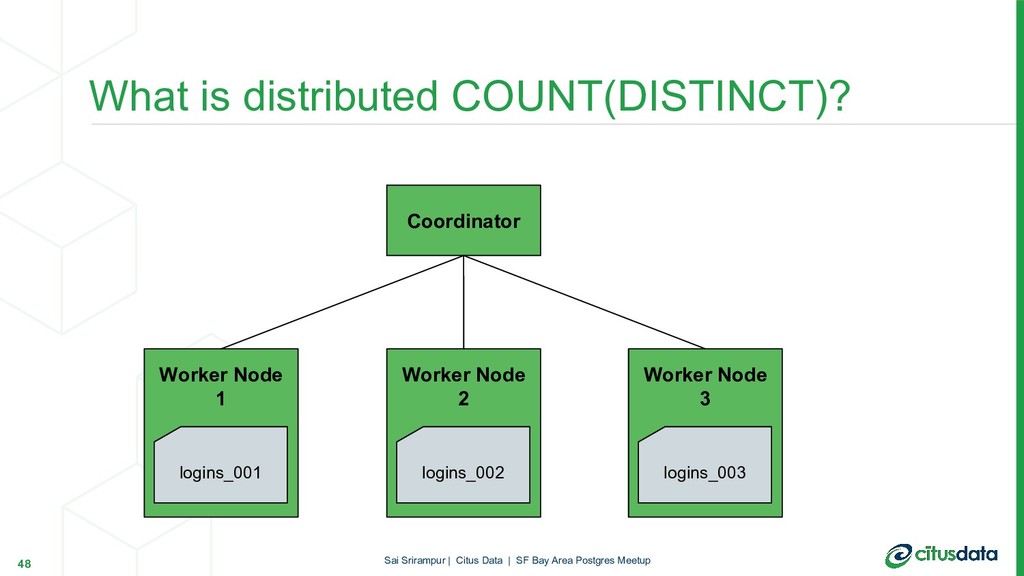{kind=link}
{kind=link}
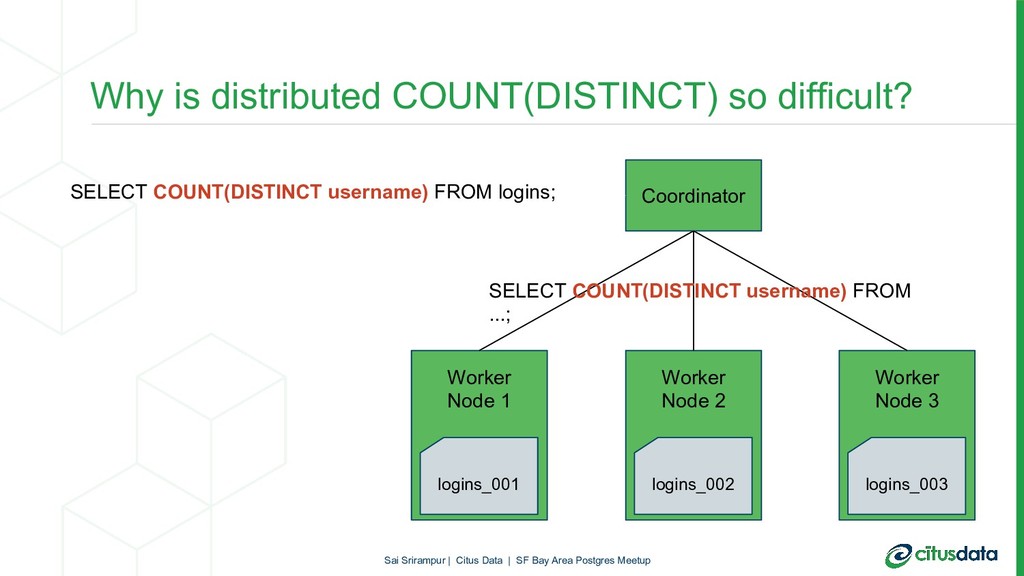{kind=link}
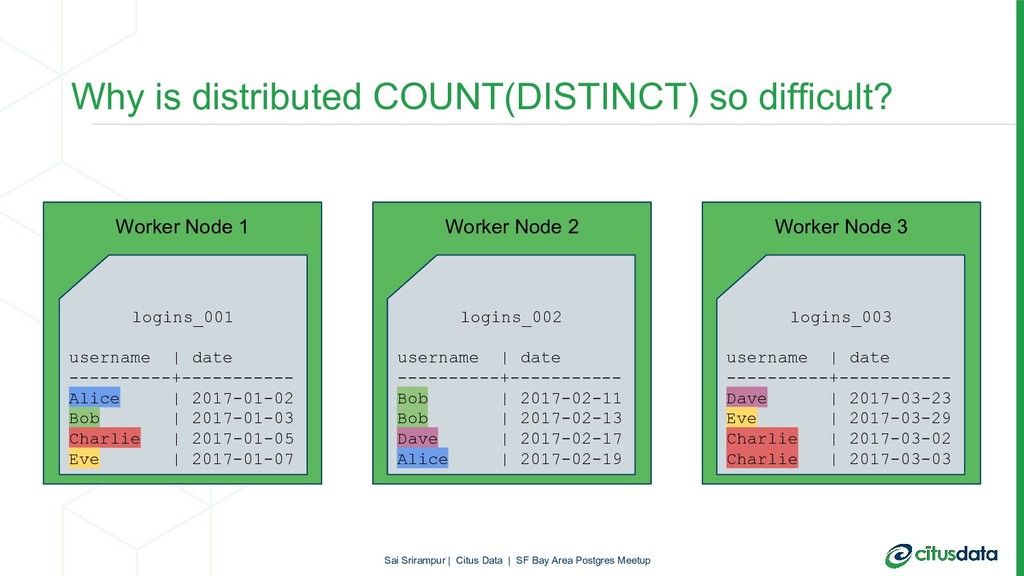{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}