data products applying data science to large amounts of data Page 3 Amazon: 35% of product sales come from product recommendations Netflix: 75% of streaming video results from recommendations Prediction of click through rates
profiling: – How likely is this customer to pay back his mortgage? – How likely is this customer to get sick? • Fraud detection: – Detect illegal credit card activity and alert bank/consumer – Detect illegal insurance claims • Internal fraud detection (compliance): – Is this employee accessing financial information they are not allowed to access? Page 4
prediction – What is the LTV for customer X? • Marketing – Which new mobile phone should we offer to customer X so that they remain with us? – Location based advertising • Failure prediction – When will equipment X in cell tower Y fail? • Cell Tower Management – Predict load and bandwidth on cell towers to optimize network Page 5
Support: – What is the ideal treatment for this patient? • Cost management: – What is the expected overall cost of treatment for this patient over the life of the disease • Diagnostics: – Given these test results, what is the likelihood of cancer? • Epidemic management – Predict size and location of epidemic spread Page 6
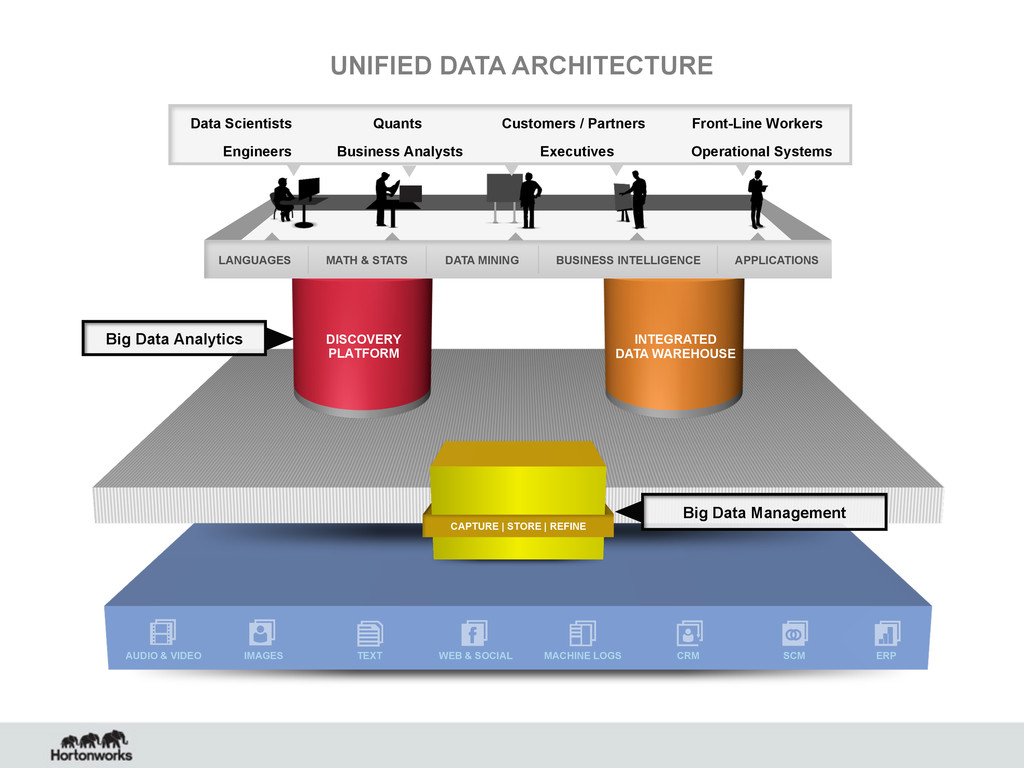
CRM SCM ERP DISCOVERY PLATFORM CAPTURE | STORE | REFINE INTEGRATED DATA WAREHOUSE UNIFIED DATA ARCHITECTURE Big Data Analytics Big Data Management LANGUAGES MATH & STATS DATA MINING BUSINESS INTELLIGENCE APPLICATIONS Engineers Data Scientists Business Analysts Front-Line Workers Customers / Partners Quants Operational Systems Executives
CRM SCM ERP DISCOVERY PLATFORM CAPTURE | STORE | REFINE INTEGRATED DATA WAREHOUSE LANGUAGES MATH & STATS DATA MINING BUSINESS INTELLIGENCE APPLICATIONS VIEWPOINT SUPPORT Engineers Data Scientists Business Analysts Front-Line Workers Customers / Partners Quants Operational Systems Executives TERADATA UNIFIED DATA ARCHITECTURE Aster Connector for Hadoop Teradata Connector for Hadoop Aster Teradata Connector SQL-H Aster Loader Teradata Loader SQL-H
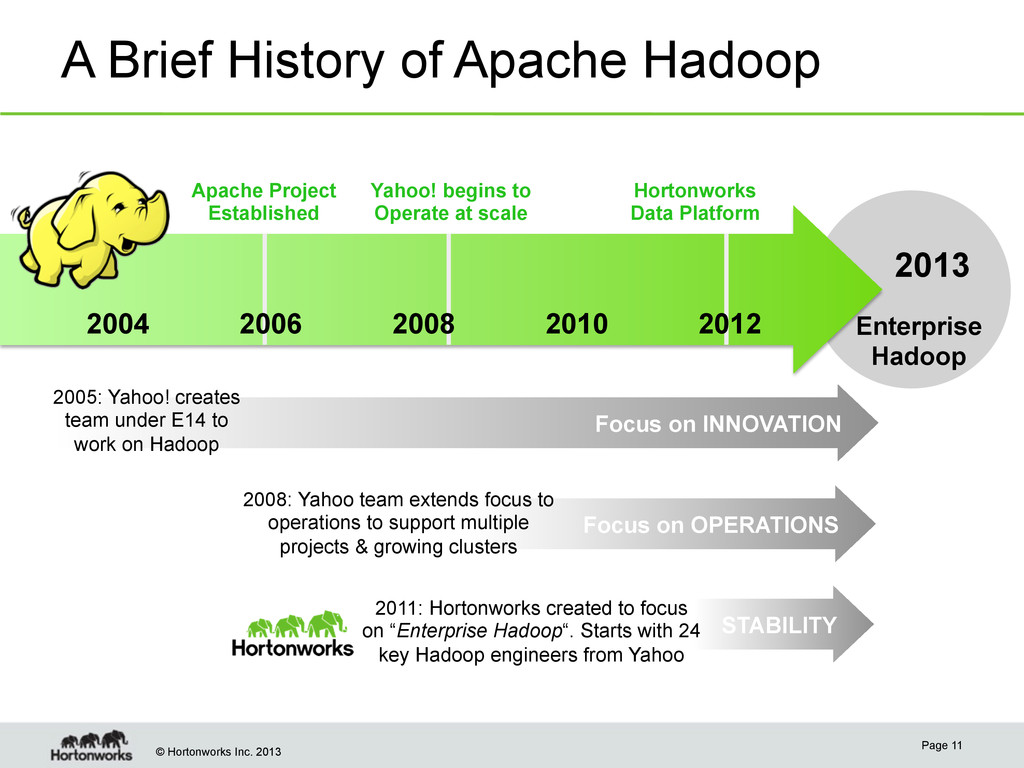
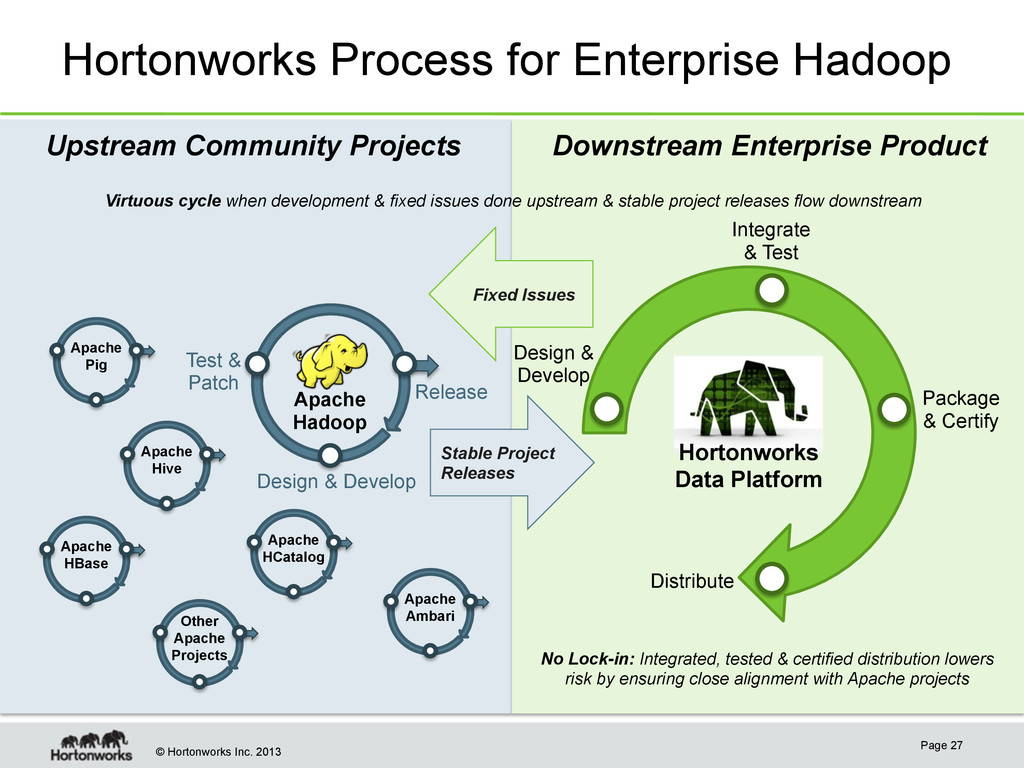
Page 11 2013 Focus on INNOVATION 2005: Yahoo! creates team under E14 to work on Hadoop Focus on OPERATIONS 2008: Yahoo team extends focus to operations to support multiple projects & growing clusters Yahoo! begins to Operate at scale Enterprise Hadoop Apache Project Established Hortonworks Data Platform 2004 2008 2010 2012 2006 STABILITY 2011: Hortonworks created to focus on “Enterprise Hadoop“. Starts with 24 key Hadoop engineers from Yahoo
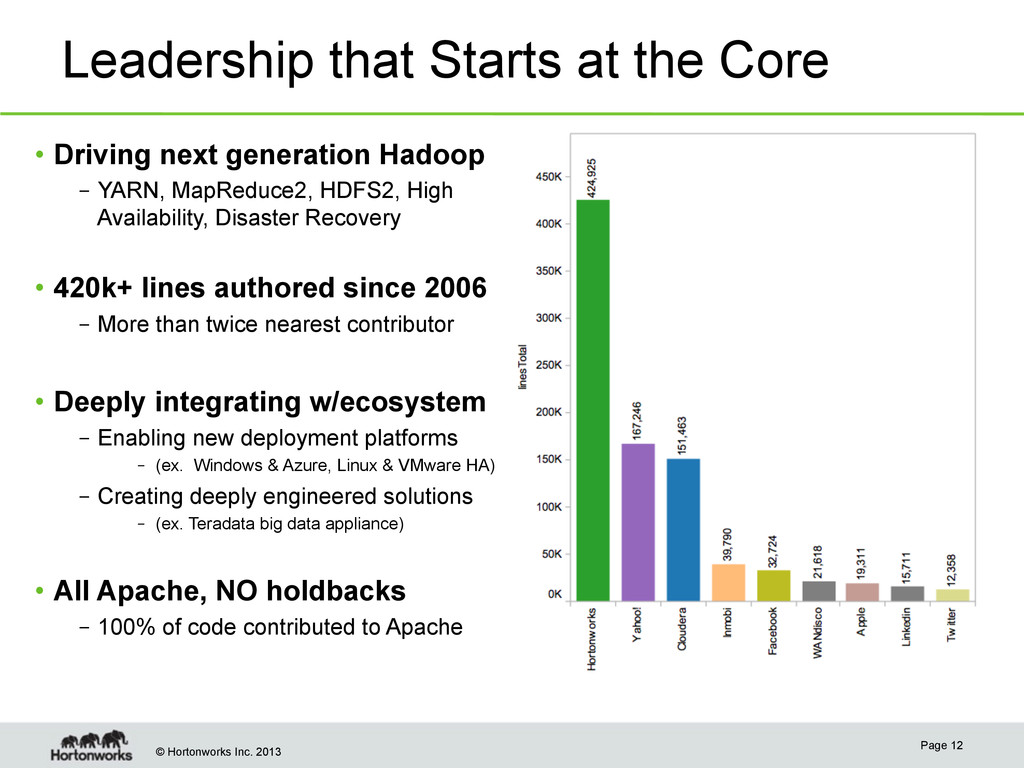
Page 12 • Driving next generation Hadoop – YARN, MapReduce2, HDFS2, High Availability, Disaster Recovery • 420k+ lines authored since 2006 – More than twice nearest contributor • Deeply integrating w/ecosystem – Enabling new deployment platforms – (ex. Windows & Azure, Linux & VMware HA) – Creating deeply engineered solutions – (ex. Teradata big data appliance) • All Apache, NO holdbacks – 100% of code contributed to Apache
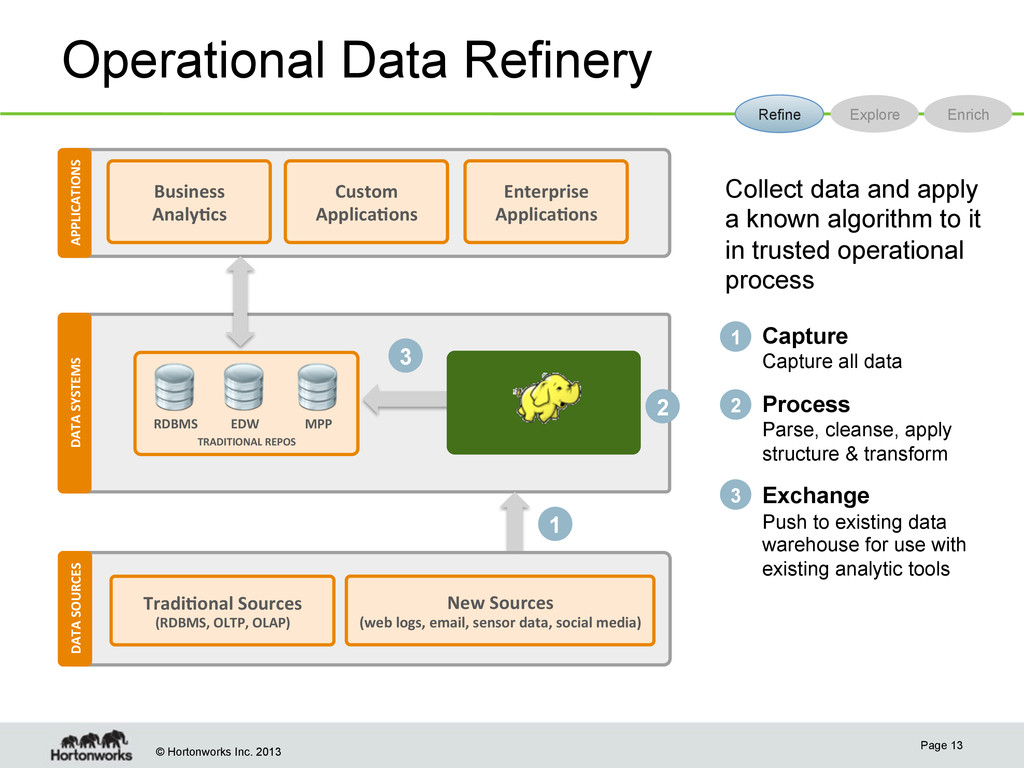
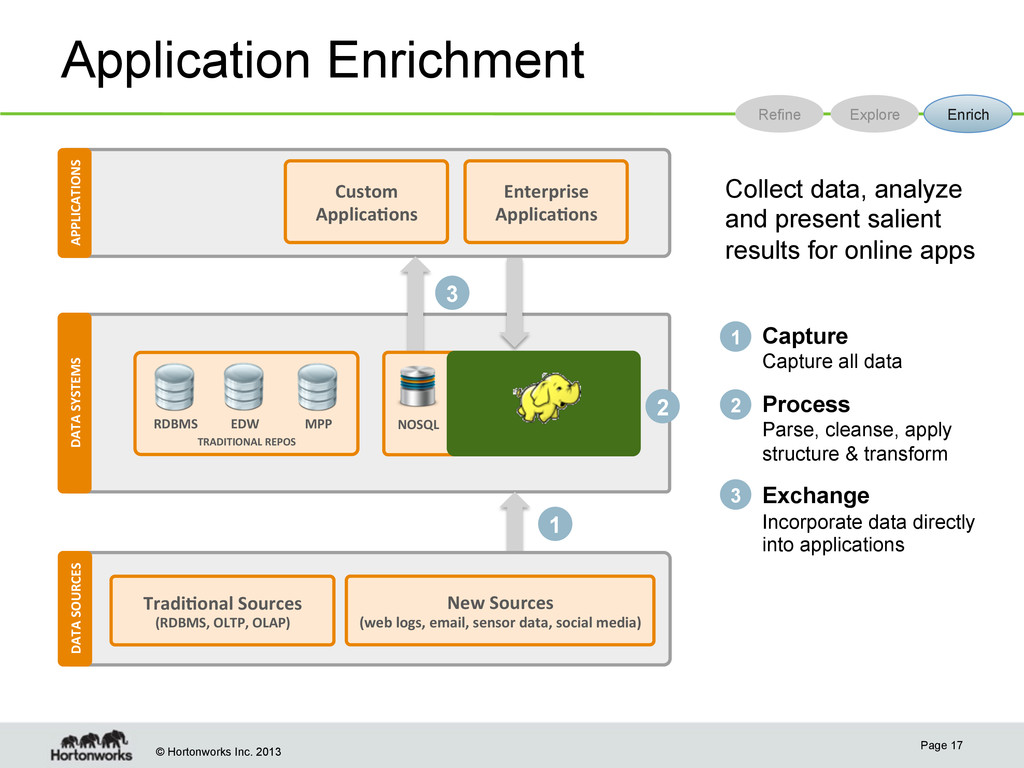
SYSTEMS DATA SOURCES 1 3 1 Capture Capture all data Process Parse, cleanse, apply structure & transform Exchange Push to existing data warehouse for use with existing analytic tools 2 3 Refine Explore Enrich 2 APPLICATIONS Collect data and apply a known algorithm to it in trusted operational process TRADITIONAL REPOS RDBMS EDW MPP Business Analy;cs Custom Applica;ons Enterprise Applica;ons Tradi;onal Sources (RDBMS, OLTP, OLAP) New Sources (web logs, email, sensor data, social media)
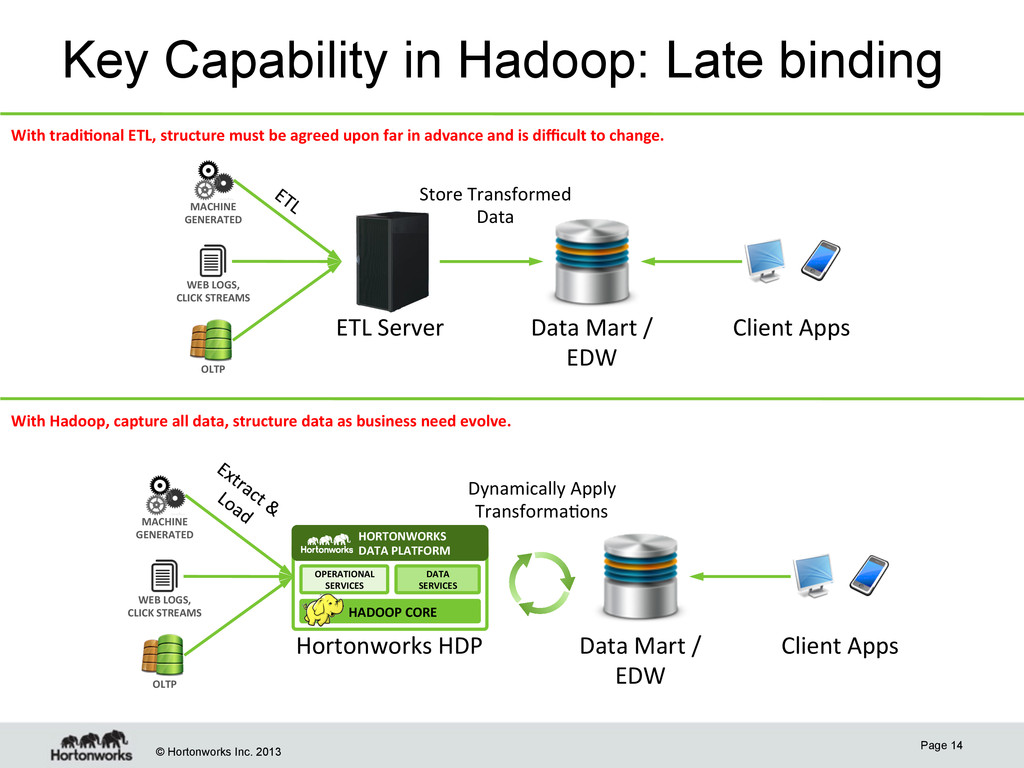
Page 14 DATA SERVICES OPERATIONAL SERVICES HORTONWORKS DATA PLATFORM HADOOP CORE WEB LOGS, CLICK STREAMS MACHINE GENERATED OLTP Data Mart / EDW Client Apps Dynamically Apply Transforma8ons Hortonworks HDP With tradi;onal ETL, structure must be agreed upon far in advance and is difficult to change. With Hadoop, capture all data, structure data as business need evolve. WEB LOGS, CLICK STREAMS MACHINE GENERATED OLTP ETL Server Data Mart / EDW Client Apps Store Transformed Data
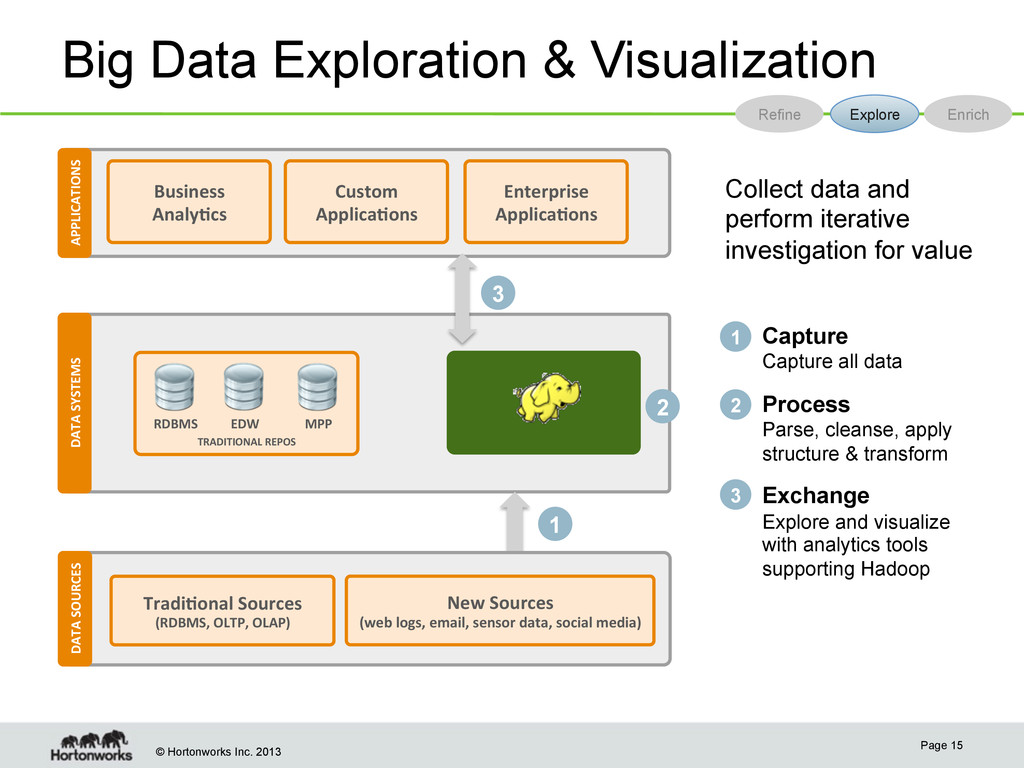
15 DATA SYSTEMS DATA SOURCES Refine Explore Enrich APPLICATIONS 1 Capture Capture all data Process Parse, cleanse, apply structure & transform Exchange Explore and visualize with analytics tools supporting Hadoop 2 3 Collect data and perform iterative investigation for value 3 2 TRADITIONAL REPOS RDBMS EDW MPP 1 Business Analy;cs Tradi;onal Sources (RDBMS, OLTP, OLAP) New Sources (web logs, email, sensor data, social media) Custom Applica;ons Enterprise Applica;ons
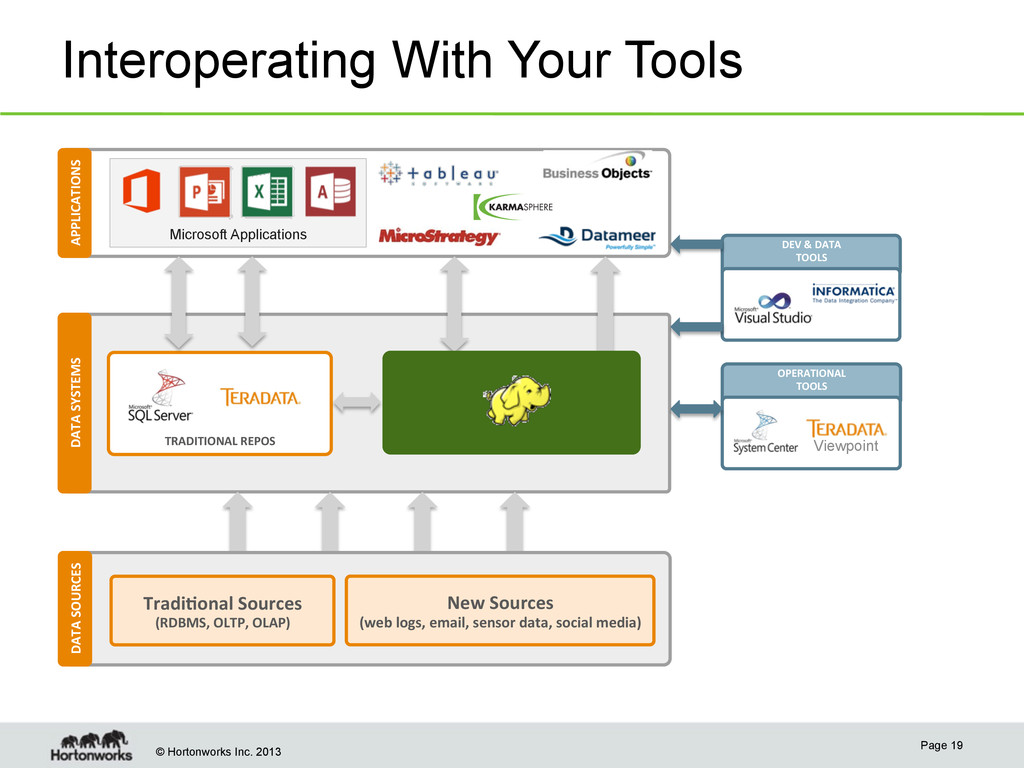
APPLICATIONS DATA SYSTEMS TRADITIONAL REPOS DEV & DATA TOOLS OPERATIONAL TOOLS Viewpoint Microsoft Applications DATA SOURCES MOBILE DATA OLTP, POS SYSTEMS Tradi;onal Sources (RDBMS, OLTP, OLAP) New Sources (web logs, email, sensor data, social media)
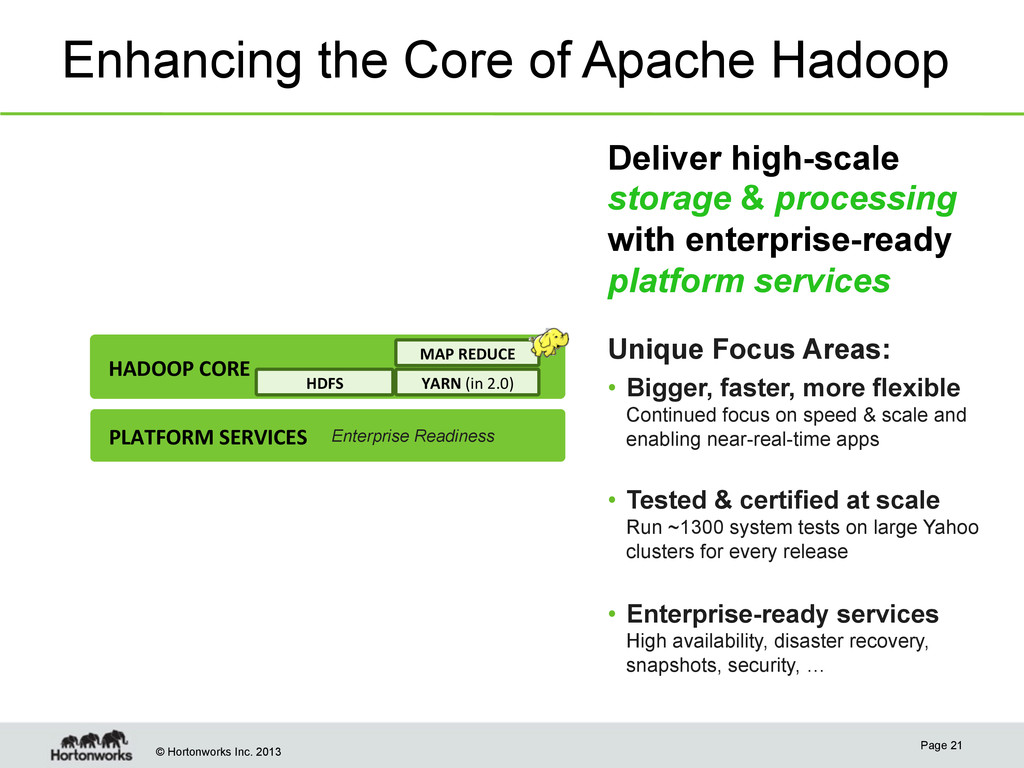
Page 21 HADOOP CORE PLATFORM SERVICES Enterprise Readiness HDFS YARN (in 2.0) MAP REDUCE Deliver high-scale storage & processing with enterprise-ready platform services Unique Focus Areas: • Bigger, faster, more flexible Continued focus on speed & scale and enabling near-real-time apps • Tested & certified at scale Run ~1300 system tests on large Yahoo clusters for every release • Enterprise-ready services High availability, disaster recovery, snapshots, security, …
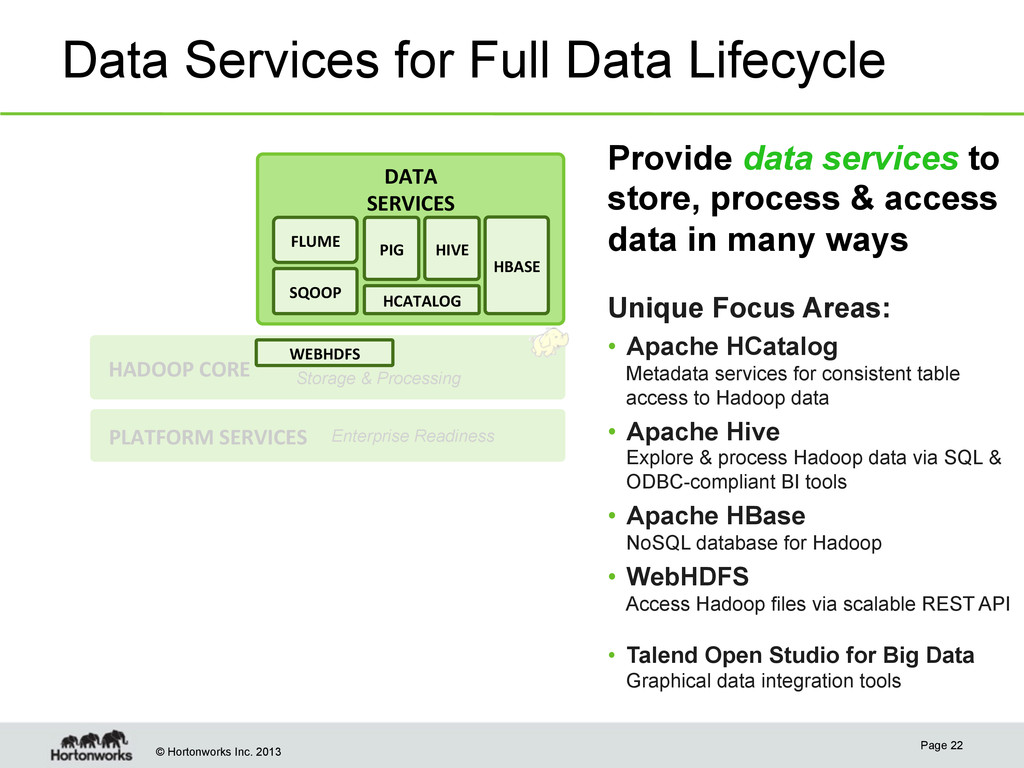
SERVICES Distributed Storage & Processing PLATFORM SERVICES Enterprise Readiness Data Services for Full Data Lifecycle WEBHDFS HCATALOG HIVE PIG HBASE SQOOP FLUME Provide data services to store, process & access data in many ways Unique Focus Areas: • Apache HCatalog Metadata services for consistent table access to Hadoop data • Apache Hive Explore & process Hadoop data via SQL & ODBC-compliant BI tools • Apache HBase NoSQL database for Hadoop • WebHDFS Access Hadoop files via scalable REST API • Talend Open Studio for Big Data Graphical data integration tools
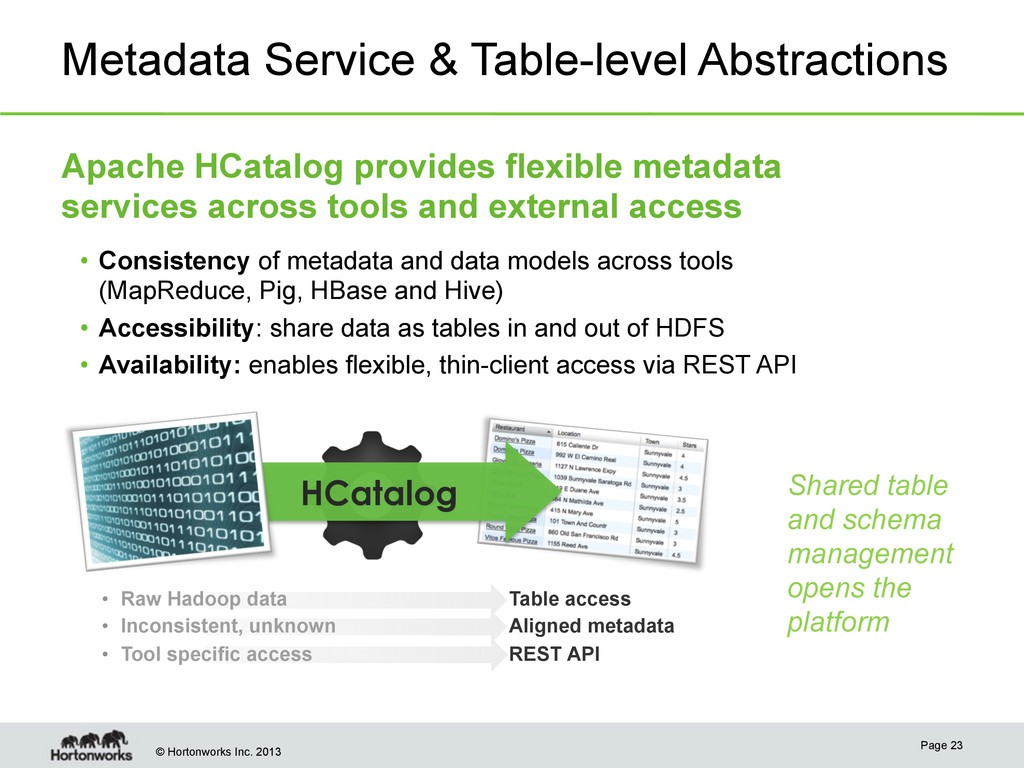
API • Raw Hadoop data • Inconsistent, unknown • Tool specific access Apache HCatalog provides flexible metadata services across tools and external access Metadata Service & Table-level Abstractions • Consistency of metadata and data models across tools (MapReduce, Pig, HBase and Hive) • Accessibility: share data as tables in and out of HDFS • Availability: enables flexible, thin-client access via REST API Shared table and schema management opens the platform Page 23
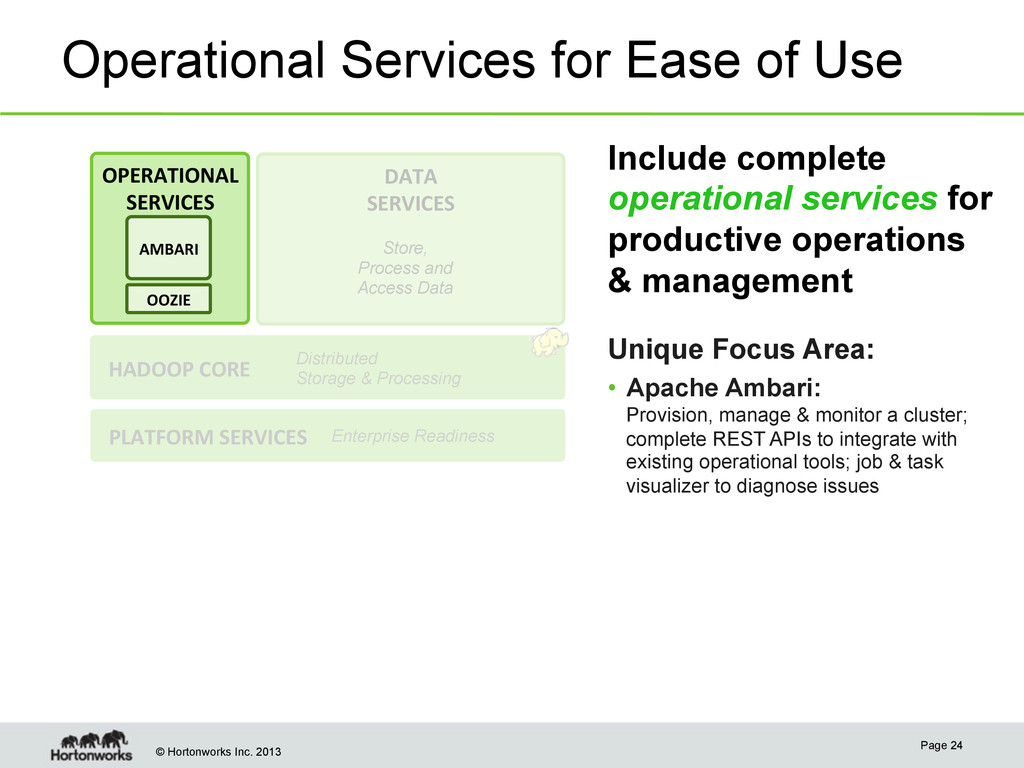
New Ambari Features • Job Diagnostics Visualize and troubleshoot Hadoop job execution and performance • Cluster History View historical job execution & performance • Instant Insight View health of Core Hadoop (HDFS, MapReduce) and related projects • Cluster Navigation “Quick link” buttons jump into namenode web UI for a server • REST interface provides external access to Ambari for existing tools. Facilitates integration with Microsoft System Center and Teradata Viewpoint Page 25
Appliance Page 28 PLATFORM SERVICES HADOOP CORE DATA SERVICES OPERATIONAL SERVICES Manage & Operate at Scale Store, Process and Access Data Enterprise Readiness Only Hortonworks allows you to deploy seamlessly across any deployment option • Linux & Windows • Azure, Rackspace & other clouds • Virtual platforms • Big data appliances HORTONWORKS DATA PLATFORM (HDP) Distributed Storage & Processing Deployable Across a Range of Options
• DEFINITION Better use of available data in the decision making process • RULE Key metrics derived from data should be tied to goals • PROVEN RESULTS Firms that adopt Data-Driven Decision Making have output and productivity that is 5-6% higher than what would be expected given their investments and usage of information technology* * “Strength in Numbers: How Does Data-Driven Decisionmaking Affect Firm Performance?” Brynjolfsson, Hitt and Kim (April 22, 2011) 1110010100001010011101010100010010100100101001001000010010001001000001000100000100 0100100100010000101110000100100010001010010010111101010010001001001010010100100111 11001010010100011111010001001010000010010001010010111101010011001001010010001000111
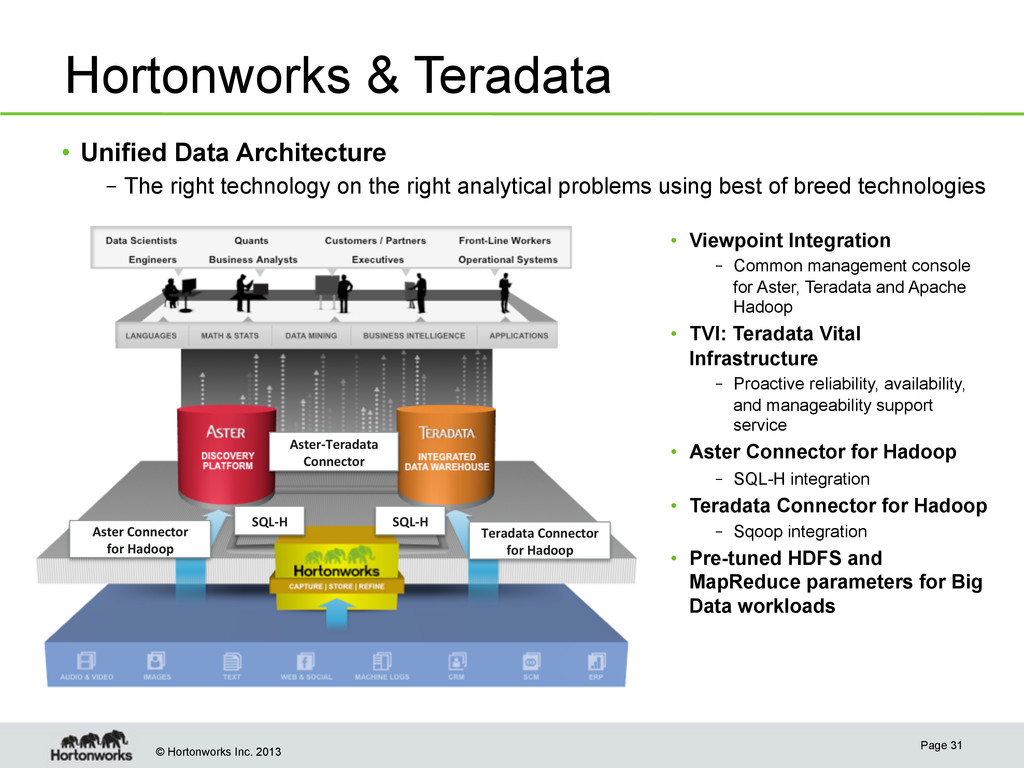
Viewpoint Integration – Common management console for Aster, Teradata and Apache Hadoop • TVI: Teradata Vital Infrastructure – Proactive reliability, availability, and manageability support service • Aster Connector for Hadoop – SQL-H integration • Teradata Connector for Hadoop – Sqoop integration • Pre-tuned HDFS and MapReduce parameters for Big Data workloads • Unified Data Architecture – The right technology on the right analytical problems using best of breed technologies SQL-‐H SQL-‐H Aster-‐Teradata Connector Aster Connector for Hadoop Teradata Connector for Hadoop
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}