MPP Offload – More data under query. – Database unable to keep up with SLAs. • Analysis of semi-structured data. • ETL / Data Refinement • +++ Increasingly: Business Intelligence and interactive query Page 3
was originally developed at Facebook. " More data than existing RDBMS could handle. " 60,000+ Hive queries per day. " More than 1,000 users per day. " 100+ PB of data. " 15+ TB of data loaded daily. " Hive is a proven solution at extreme scale.
for Hadoop • Multiple persistence options: – Flat text for simple data imports. – Columnar format (RCFile) for high performance processing. • Secure and concurrent remote access • ODBC/JDBC connectivity • Highly extensible: – Supports User Defined Functions and User Defined Aggregation Functions. – Ships with more than 150 UDF/UDAF. – Extensible readers/writers can process any persisted data. • Support from 10+ BI vendors Page 12
BI Tools Page 13 • Seamless integration with BI tools such as Excel, PowerPivot, MicroStrategy, and Tableau • Efficiently maps advanced SQL functionality into HiveQL – With configurable pass-through of HiveQL for Hive-aware apps • ODBC 3.52 standard compliant • Supports Linux & Windows High quality ODBC driver developed in partnership with Simba. Free to download & use with Hortonworks Data Platform. Applications & Spreadsheets Visualization & Intelligence ODBC Hortonworks Data Platform
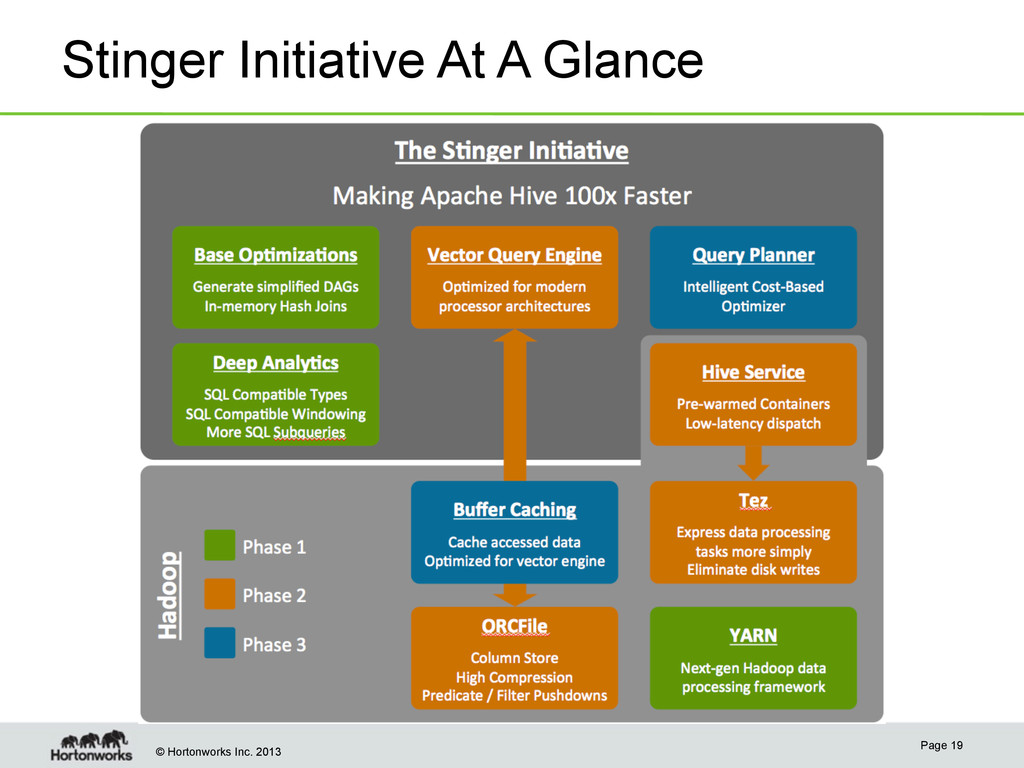
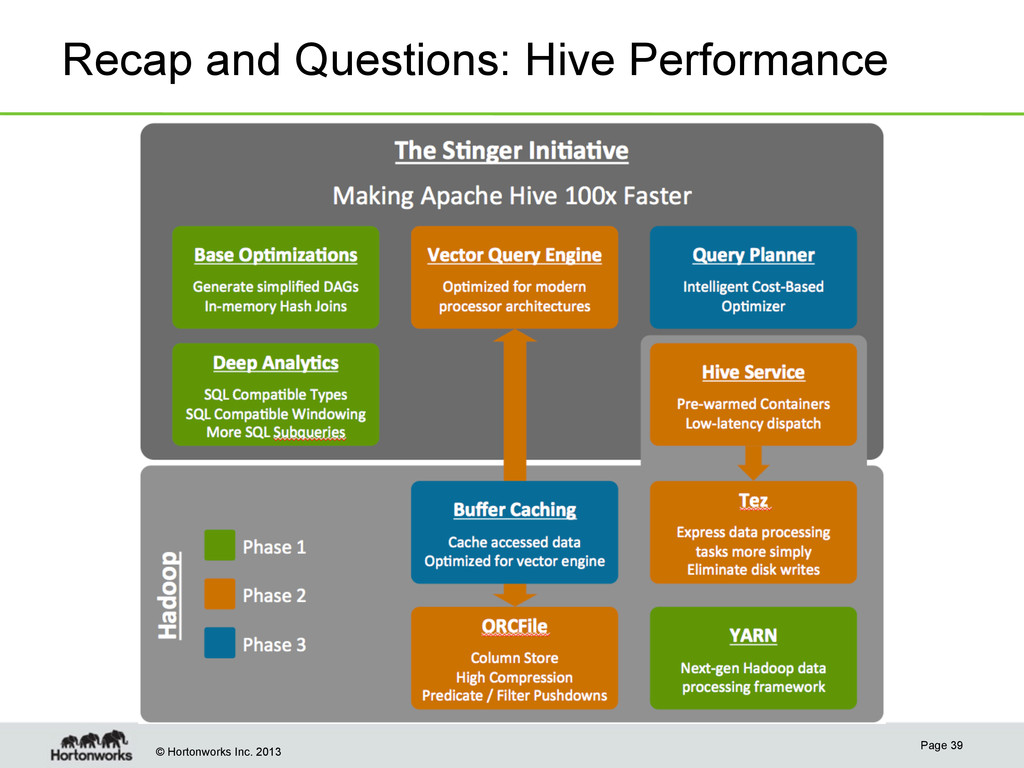
Tez • New primitives move beyond map-reduce and beyond batch • Avoid unnecessary persistence of temporary data • Hive, Pig and others generate Tez plans for high perf Query Engine Improvements • Cost-based optimizer • In-memory joins • Caching hot tables • Vector processing State-of-the-art Column Store • “Optimized RCFile” or ORCFile • Minimizes disk IO and deserialization Tez Service • Always-on service for query interactivity Improve Latency and Throughput Analytics Functions • SQL:2003 Compliant • OVER with PARTITION BY and ORDER BY • Wide variety of windowing functions: • RANK • LEAD/LAG • ROW_NUMBER • FIRST_VALUE • LAST_VALUE • Many more • Aligns well with BI ecosystem Improved SQL Coverage • Non-correlated Subqueries using IN in WHERE • Expanded SQL types including DATETIME, VARCHAR, etc. Extend Deep Analytical Ability Making Hive Best for Interactive Query
In-Memory Hash Join: – For joins where one side fits in memory: – New in-memory-hash-join algorithm. – Hive reads the small table into a hash table. – Scans through the big file to produce the output. • Introduction of Sort-Merge-Bucket Join: – Applies when tables are bucketed on the same key. – Dramatic speed improvements seen in benchmarks. • Other Improvements: – Lower the footprint of the fact tables in memory. – Enable the optimizer to automatically pick map joins. Page 20
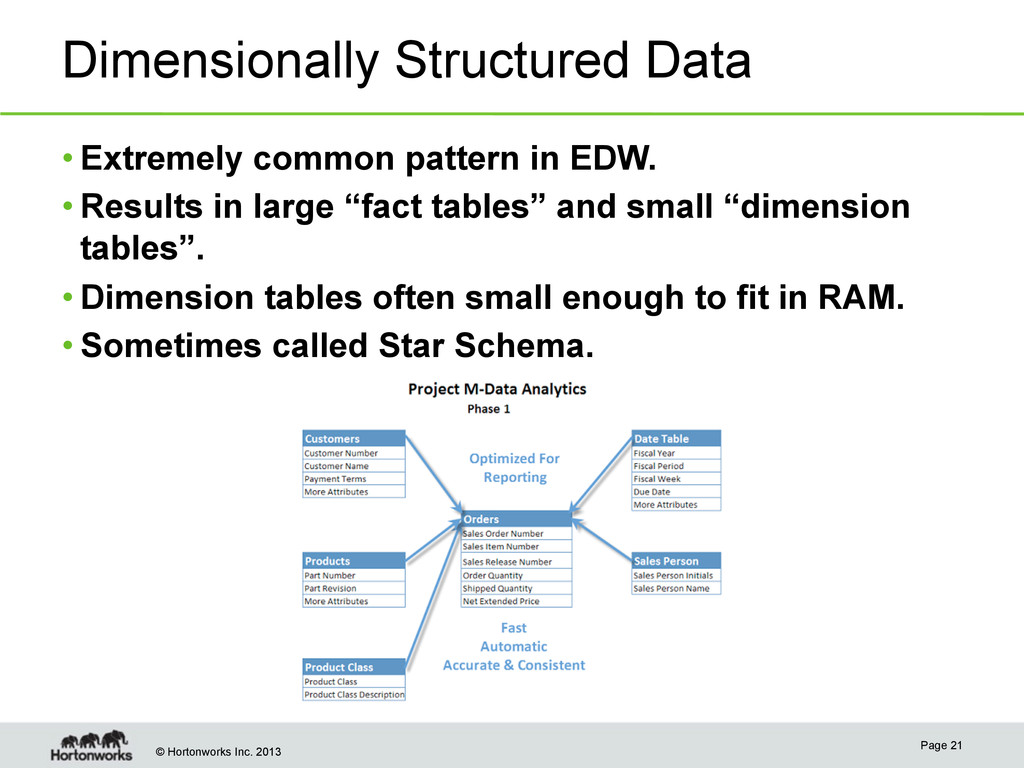
in EDW. • Results in large “fact tables” and small “dimension tables”. • Dimension tables often small enough to fit in RAM. • Sometimes called Star Schema. Page 21
from TPC-DS Query 27 • Dramatic speedup on Hive 0.11 Page 22 SELECT col5, avg(col6) FROM fact_table join dim1 on (fact_table.col1 = dim1.col1) join dim2 on (fact_table.col2 = dim2.col1) join dim3 on (fact_table.col3 = dim3.col1) join dim4 on (fact_table.col4 = dim4.col1) GROUP BY col5 ORDER BY col5 LIMIT 100;
physically co-locate rows within files. • Buckets can be sorted or unsorted. Page 24 CREATE EXTERNAL TABLE IF NOT EXISTS test_table ( Id INT, name String ) PARTITIONED BY (dt STRING, hour STRING) CLUSTERED BY(country,continent) SORTED BY(country,continent) INTO n BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LOCATION '/home/test_dir';
a better columnar storage file – Tightly aligned to Hive data model • Decompose complex row types into primitive fields – Better compression and projection • Only read bytes from HDFS for the required columns. • Store column level aggregates in the files – Only need to read the file meta information for common queries – Stored both for file and each section of a file – Aggregates: min, max, sum, average, count – Allows fast access by sorted columns • Ability to add bloom filters for columns – Enables quick checks for whether a value is present Page 25
blocks of 1K or more records, rather than one record at a time • Each block contains an array of Java scalars, one for each column • Avoids many function calls, virtual dispatch, CPU pipeline stalls • Size to fit in L1 cache, avoid cache misses • Generate code for operators on the fly to avoid branches in code, maximize deep pipelines of modern processers • Up to 30x faster processing of records • Beta possible in 2H 2013 Page 26
always have hotspots: – Metadata – Small dimension tables • Build into YARN or Tez Service ways of buffering frequently used data into memory so it is not always read from disk. • Part of the “last mile” of latency efforts. Page 28
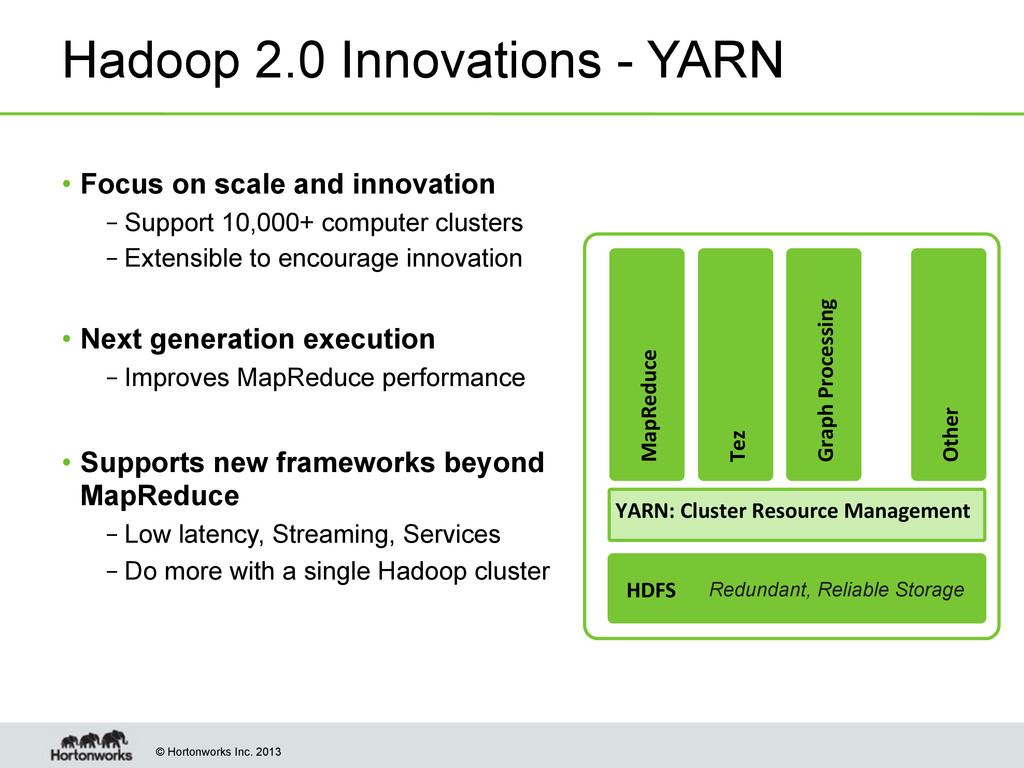
Focus on scale and innovation – Support 10,000+ computer clusters – Extensible to encourage innovation • Next generation execution – Improves MapReduce performance • Supports new frameworks beyond MapReduce – Low latency, Streaming, Services – Do more with a single Hadoop cluster HDFS MapReduce Redundant, Reliable Storage YARN: Cluster Resource Management Tez Graph Processing Other
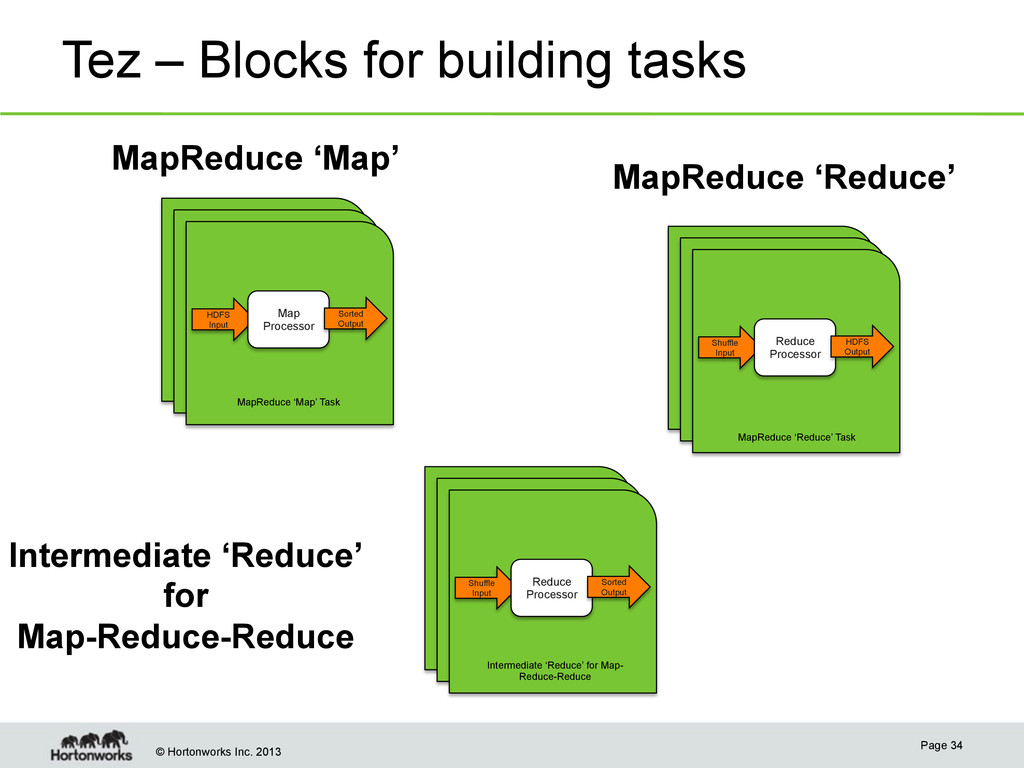
• Use it for the base of MapReduce, Hive, Pig, Cascading etc. • Enables pipelining of jobs • Removes task and job launch times • Hive and Pig jobs no longer need to move to the end of the queue between steps in the pipeline • Does not write intermediate output to HDFS – Much lighter disk and network usage • Built on YARN Page 32
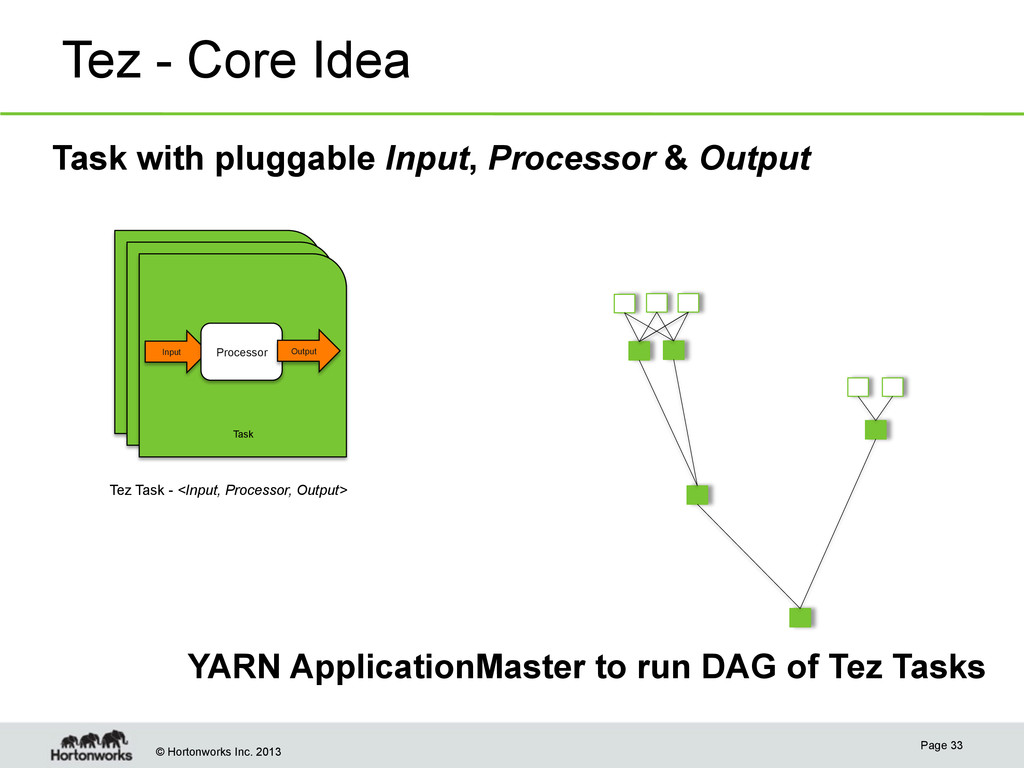
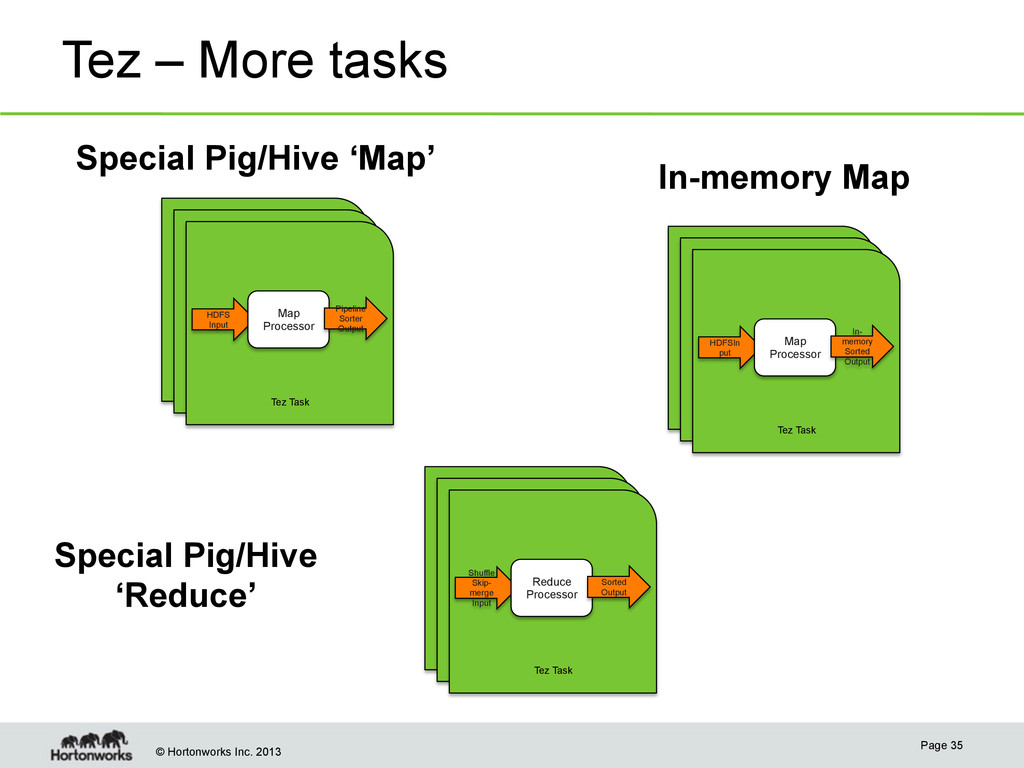
pluggable Input, Processor & Output Page 33 YARN ApplicationMaster to run DAG of Tez Tasks Input Processor Task Output Tez Task - <Input, Processor, Output>
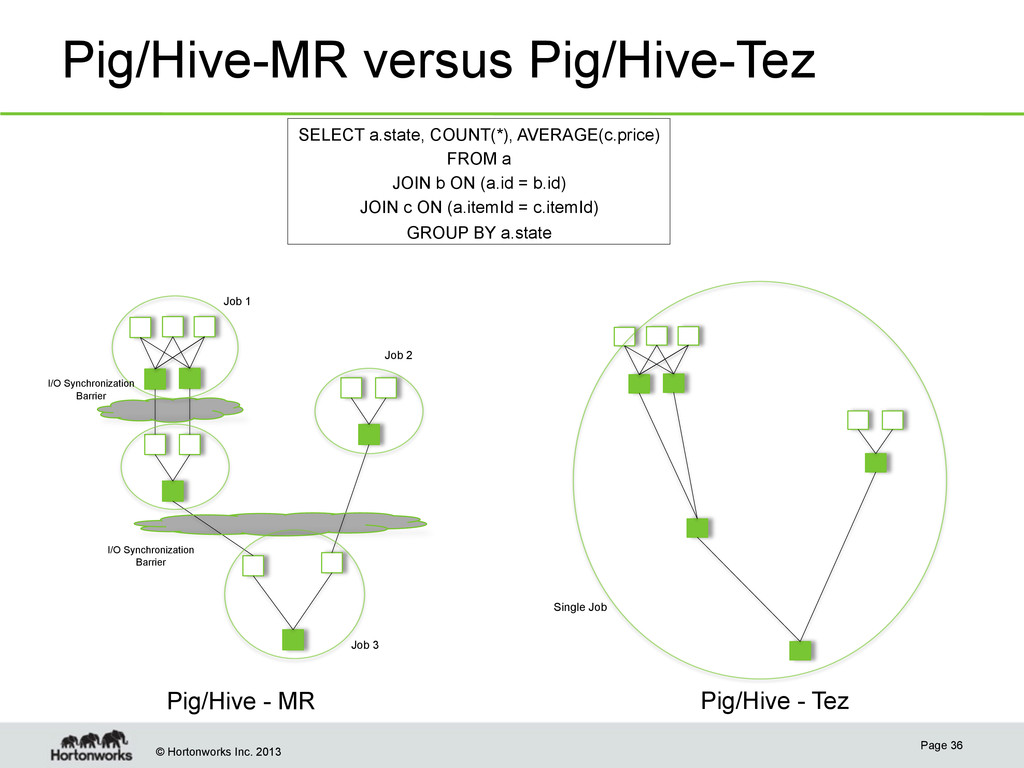
a.state, COUNT(*), AVERAGE(c.price) FROM a JOIN b ON (a.id = b.id) JOIN c ON (a.itemId = c.itemId) GROUP BY a.state Pig/Hive - MR Pig/Hive - Tez I/O Synchronization Barrier I/O Synchronization Barrier Job 1 Job 2 Job 3 Single Job
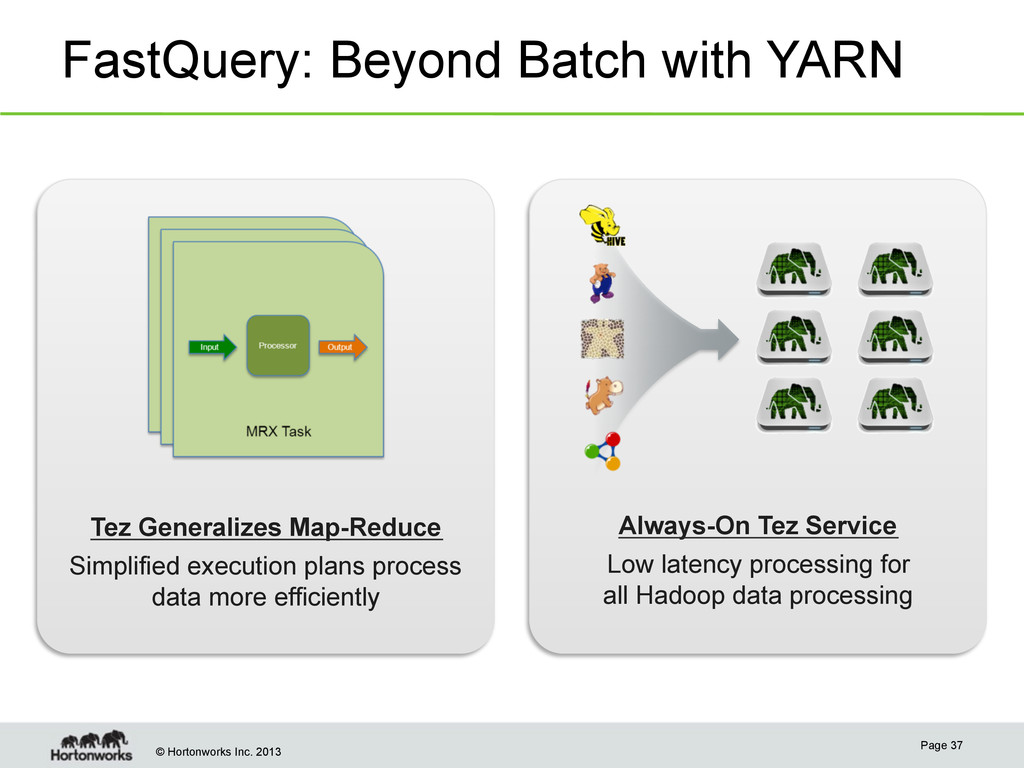
37 Tez Generalizes Map-Reduce Simplified execution plans process data more efficiently Always-On Tez Service Low latency processing for all Hadoop data processing
– Job launch & task-launch latencies are fatal for short queries (in order of 5s to 30s) • Solution – Tez Service – Removes task-launch overhead – Removes job-launch overhead – Hive/Pig – Submit query-plan to Tez Service – Native Hadoop service, not ad-hoc Page 38
Functions – OVER clauses – Multiple PARTITION BY and ORDER BY supported – Windowing supported (ROWS PRECEDING/FOLLOWING) – Large variety of aggregates – RANK – FIRST_VALUE – LAST_VALUE – LEAD / LAG – Distrubutions Page 41
– Add fixed point NUMERIC and DECIMAL type (in progress) – Add VARCHAR and CHAR types with limited field size – Add DATETIME – Add size ranges from 1 to 53 for FLOAT – Add synonyms for compatibility – BLOB for BINARY – TEXT for STRING – REAL for FLOAT • SQL Semantics: – Sub-queries in IN, NOT IN, HAVING. – EXISTS and NOT EXISTS Page 42
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}