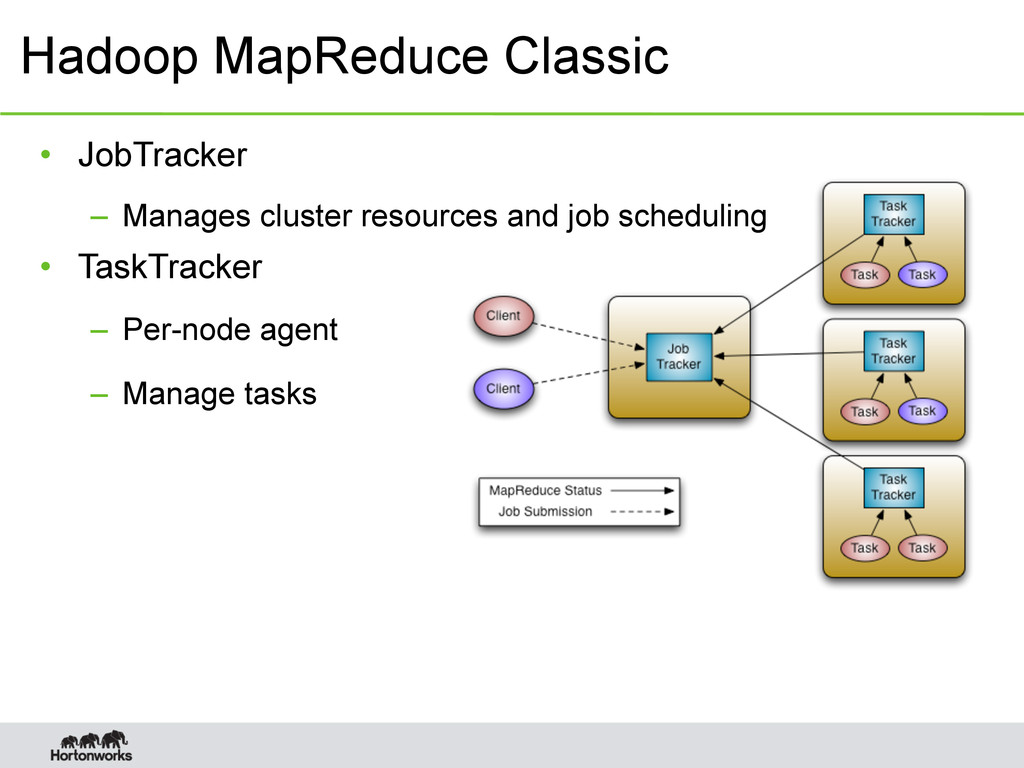
nodes – Maximum concurrent tasks – 40,000 – Coarse synchronization in JobTracker • Single point of failure – Failure kills all queued and running jobs – Jobs need to be re-submitted by users • Restart is very tricky due to complex state 4
reduce slots – Low resource utilization • Lacks support for alternate paradigms – Iterative applications implemented using MapReduce are 10x slower – Hacks for the likes of MPI/Graph Processing • Lack of wire-compatible protocols – Client and cluster must be of same version – Applications and workflows cannot migrate to different clusters 5
• Agility & Evolution – Ability for customers to control upgrades to the grid software stack. • Scalability - Clusters of 6,000-10,000 machines – Each machine with 16 cores, 48G/96G RAM, 24TB/36TB disks – 100,000+ concurrent tasks – 10,000 concurrent jobs 6
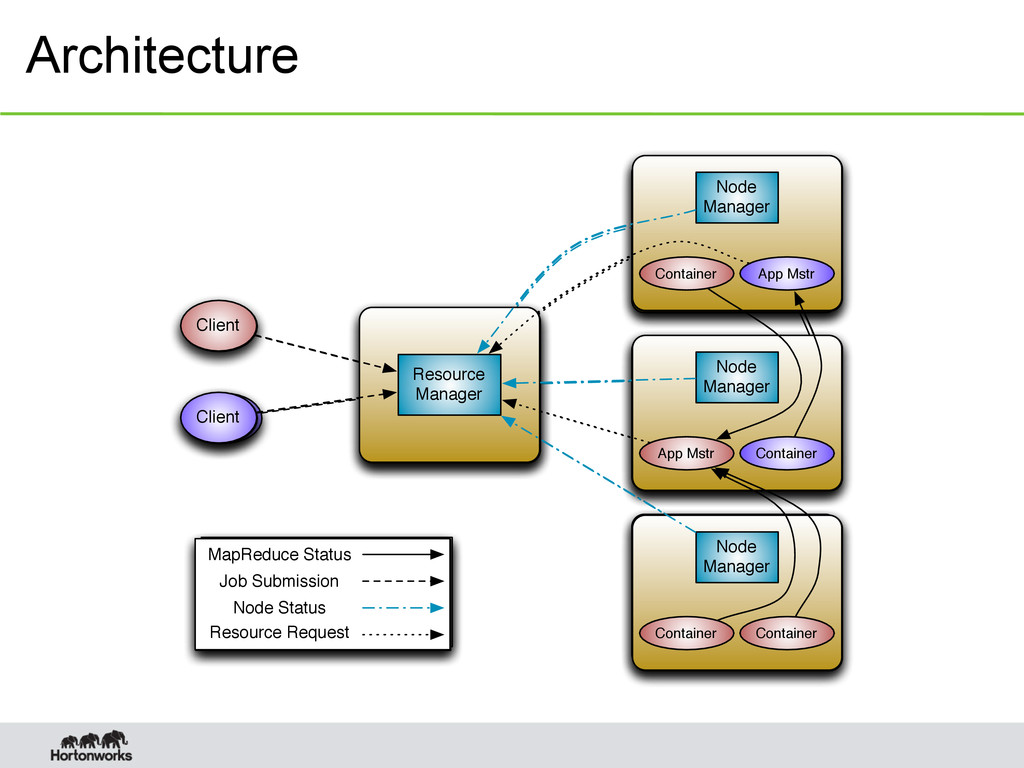
the framework – Example – Map Reduce Job • Container – Basic unit of allocation – Example – container A = 2GB, 1CPU – Fine-grained resource allocation – Replaces the fixed map/reduce slots 8
single point of failure – state saved in ZooKeeper (coming soon) • Application Masters are restarted automatically on RM restart – Application Master • Optional failover via application-specific checkpoint • MapReduce applications pick up where they left off via state saved in HDFS • Wire Compatibility – Protocols are wire-compatible – Old clients can talk to new servers – Rolling upgrades 12 Improvements vis-à-vis classic MapReduce
library – Multiple versions of MapReduce can run in the same cluster (a la Apache Pig) • Faster deployment cycles for improvements – Customers upgrade MapReduce versions on their schedule – Users can customize MapReduce 13 Improvements vis-à-vis classic MapReduce
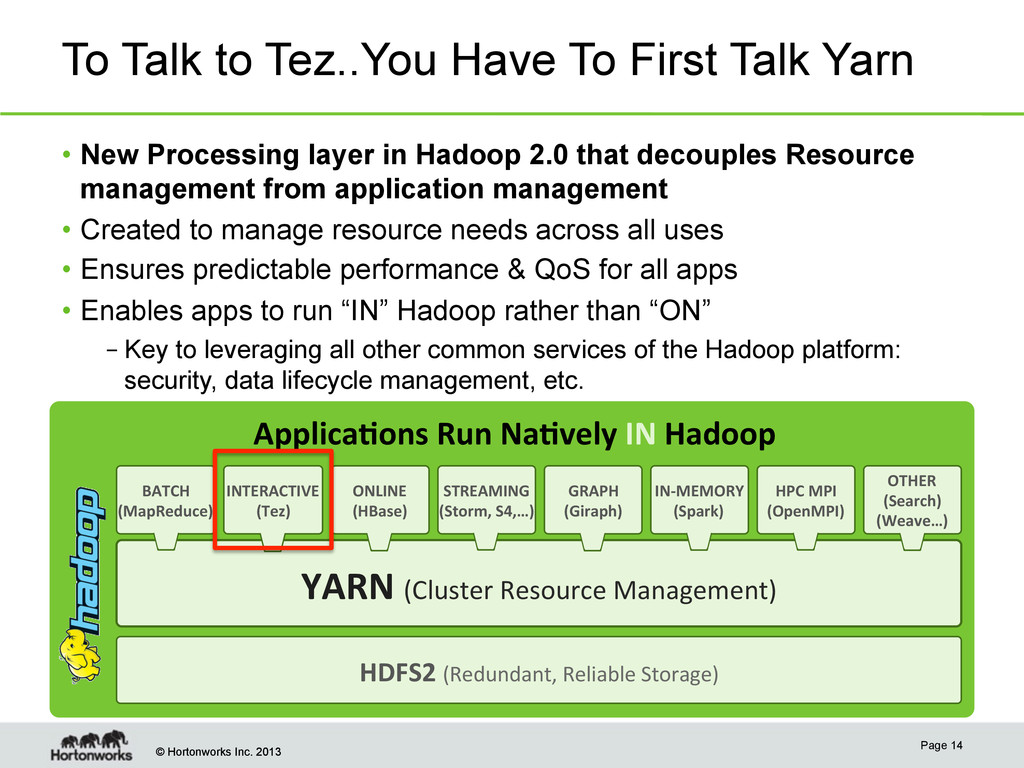
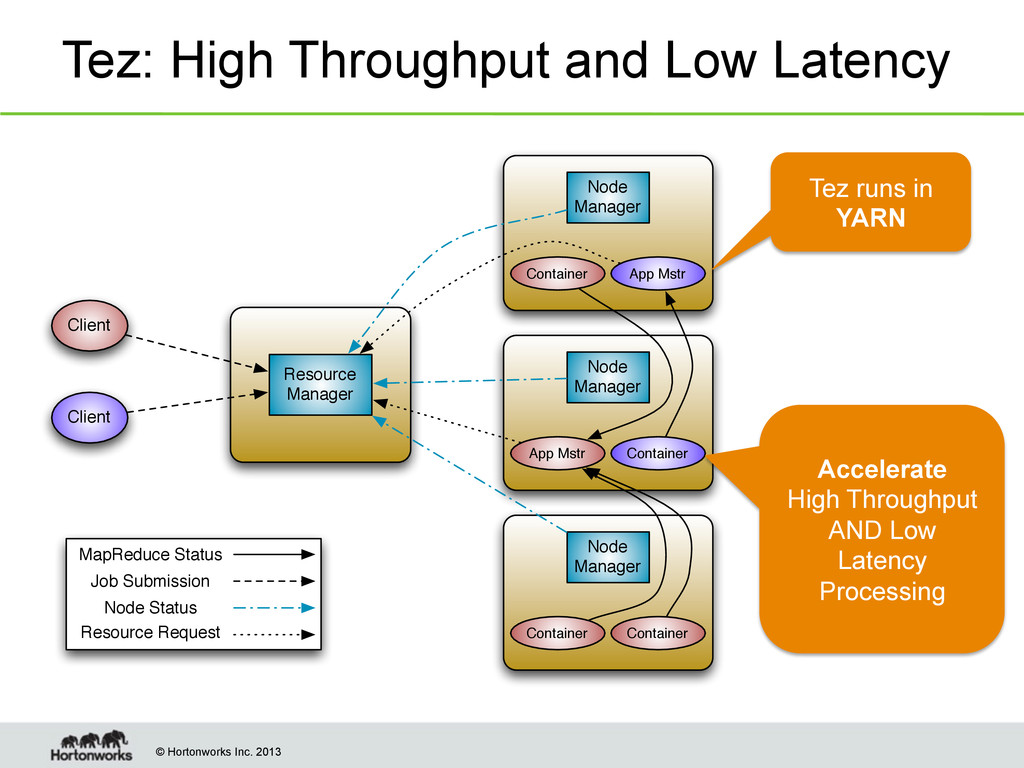
to Tez..You Have To First Talk Yarn • New Processing layer in Hadoop 2.0 that decouples Resource management from application management • Created to manage resource needs across all uses • Ensures predictable performance & QoS for all apps • Enables apps to run “IN” Hadoop rather than “ON” – Key to leveraging all other common services of the Hadoop platform: security, data lifecycle management, etc. Page 14 Applica'ons Run Na'vely IN Hadoop HDFS2 (Redundant, Reliable Storage) YARN (Cluster Resource Management) BATCH (MapReduce) INTERACTIVE (Tez) STREAMING (Storm, S4,…) GRAPH (Giraph) IN-‐MEMORY (Spark) HPC MPI (OpenMPI) ONLINE (HBase) OTHER (Search) (Weave…)
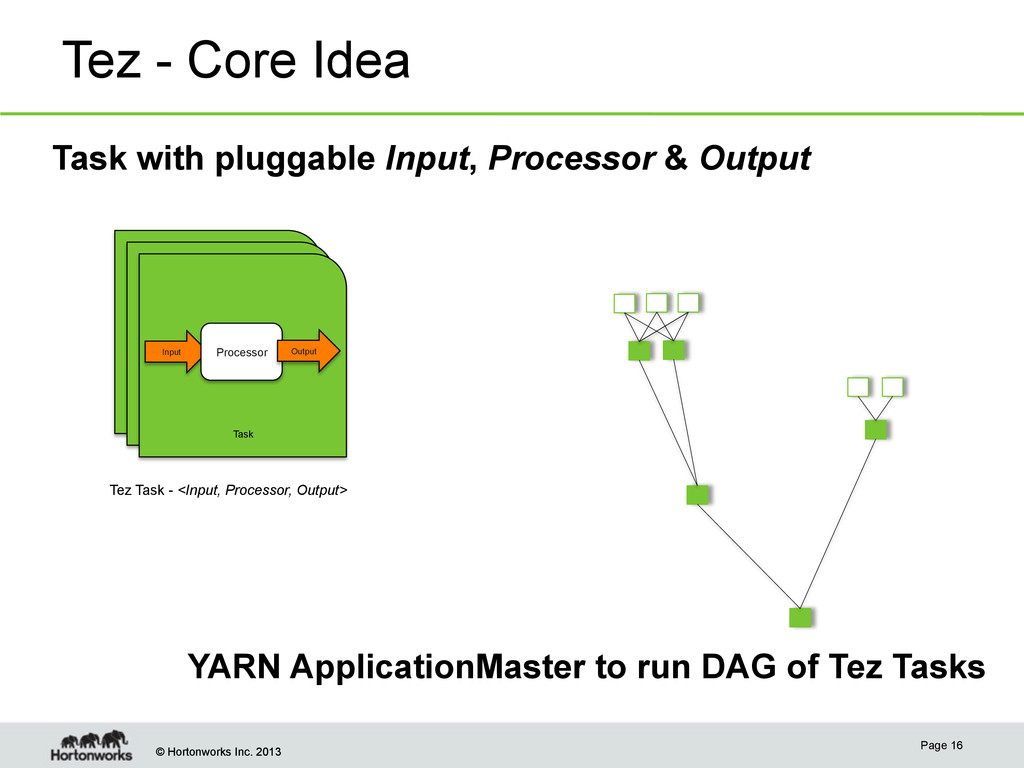
Core Idea Task with pluggable Input, Processor & Output Page 16 YARN ApplicationMaster to run DAG of Tez Tasks Input Processor Task Output Tez Task - <Input, Processor, Output>
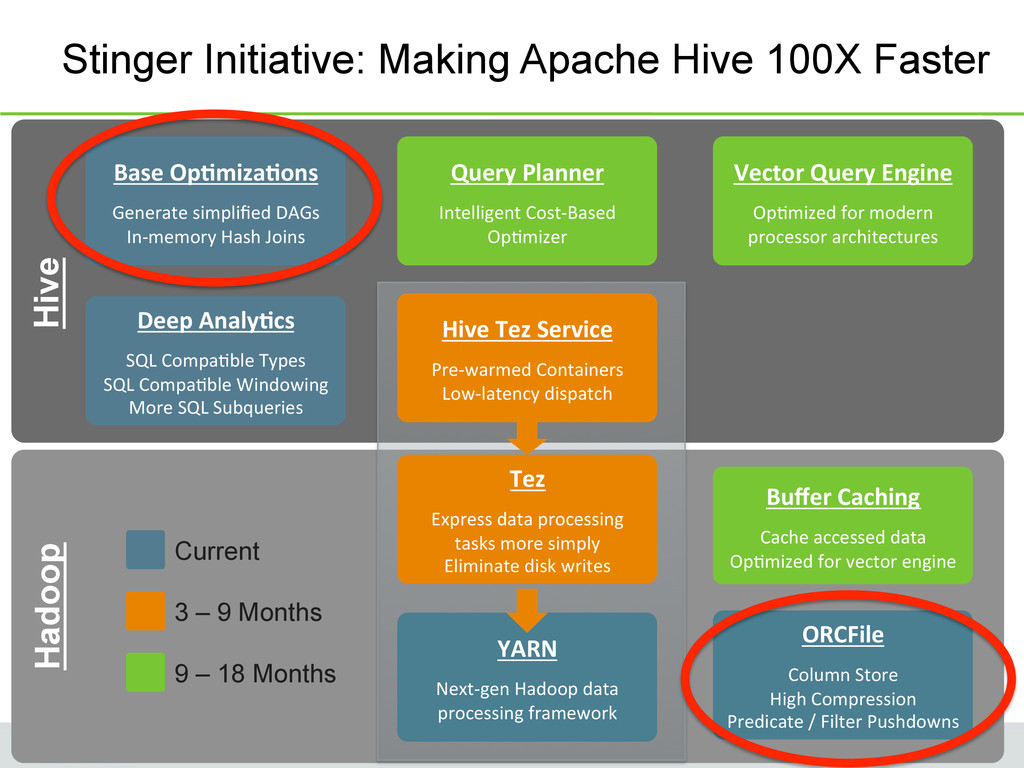
Performance • Low level data-processing, execution engine on YARN • Base for MapReduce, Hive, Pig, Cascading, etc. • Re-usable data processing primitives (ex: sort, merge, intermediate data management) • All Hive SQL, can be expressed as single job – Jobs are no longer interrupted (efficient pipeline) – Avoid writing intermediate output to HDFS when performance outweights job re-start (speed and network/disk usage savings) – Break MR contract to turn MRMRMR to MRRR (flexible DAG) • Removes task and job overhead (10s savings is huge for a 2s query!) Page 17
• MR Query Startup Expensive – Job launch & task-launch latencies are fatal for short queries (in order of 5s to 30s) • Tez Service – An always-on pool of Application Masters – Hive (and soon others like Pig) jobs are executed on an Application Masterin the pool instead of starting a new Application Master(saving precious seconds) – Container Preallocation/Ware Containers • In Summary… – Removes job-launch overhead (Application Master) – Removes task-launch overhead (Pre-warmed Containers) Page 18
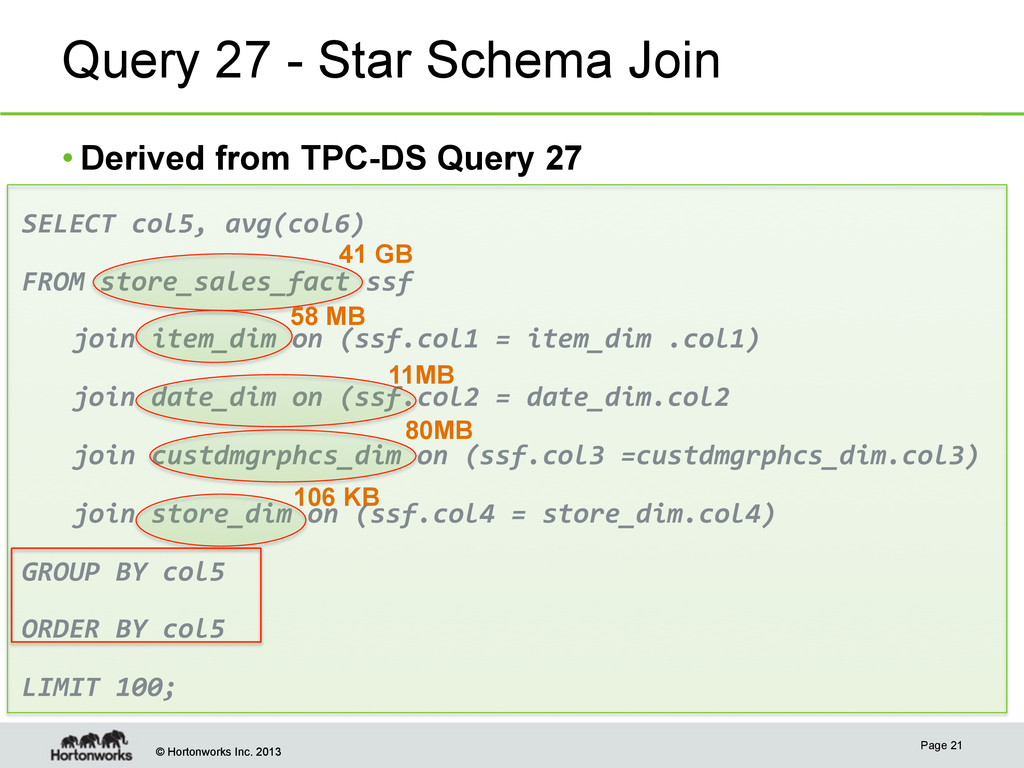
Spec • The TPC-DS benchmark data+query set • Query 27 – big table(store_sales) joins lots of small tables – A.K.A Star Schema Join • What does Query 27 do? For all items sold in stores located in specified states during a given year, find the average quantity, average list price, average list sales price, average coupon amount for a given gender, marital status, education and customer demographic..
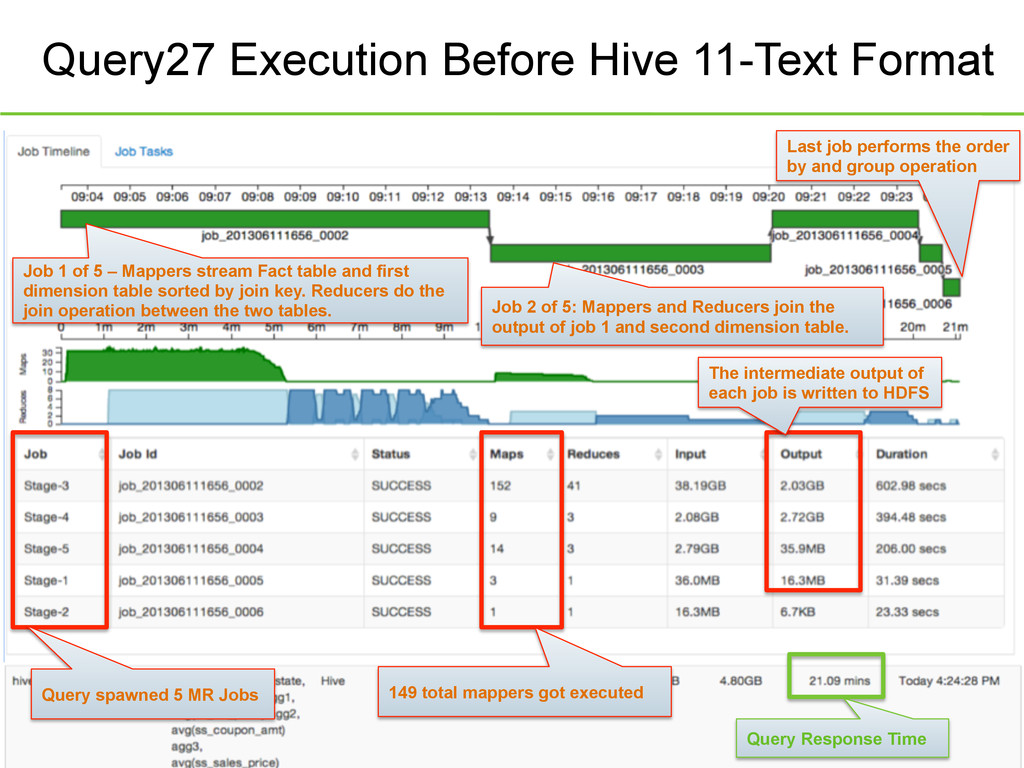
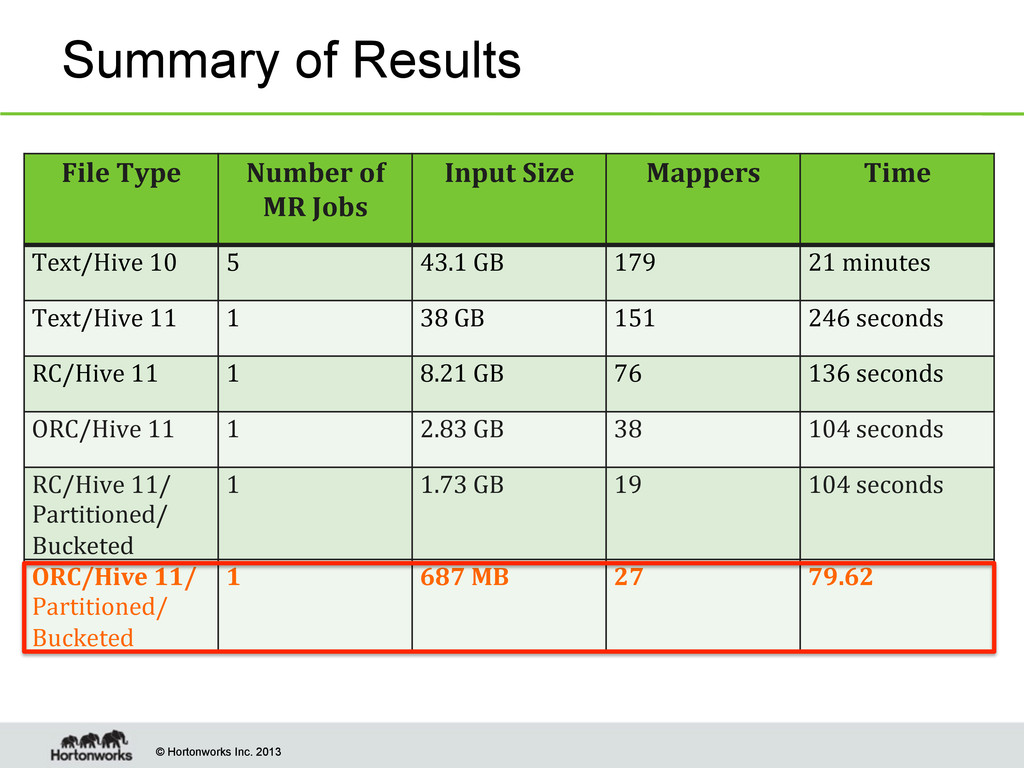
Before Hive 11-Text Format Query spawned 5 MR Jobs The intermediate output of each job is written to HDFS Job 1 of 5 – Mappers stream Fact table and first dimension table sorted by join key. Reducers do the join operation between the two tables. Job 2 of 5: Mappers and Reducers join the output of job 1 and second dimension table. Last job performs the order by and group operation Query Response Time 149 total mappers got executed
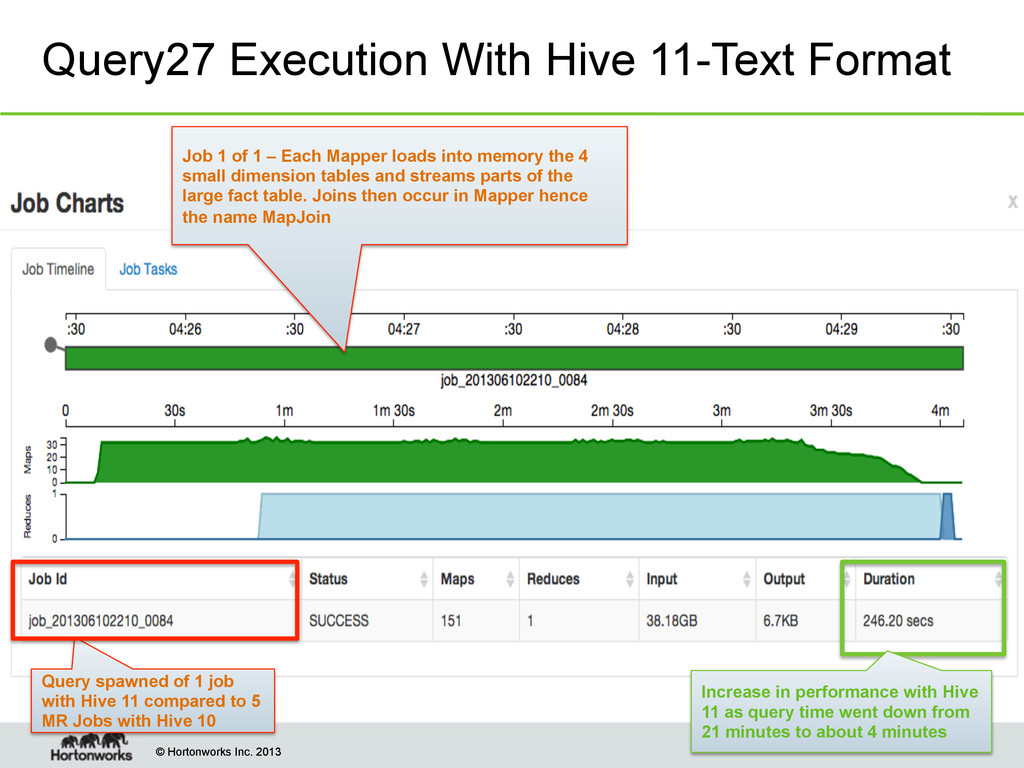
With Hive 11-Text Format Query spawned of 1 job with Hive 11 compared to 5 MR Jobs with Hive 10 Job 1 of 1 – Each Mapper loads into memory the 4 small dimension tables and streams parts of the large fact table. Joins then occur in Mapper hence the name MapJoin Increase in performance with Hive 11 as query time went down from 21 minutes to about 4 minutes
With Hive 11- RC Format Conversion from Text to RC file format decreased size of dimension data set from 38 GB to 8.21 GB Smaller file equates to less IO causing the query time to decrease from 246 seconds to 136 seconds
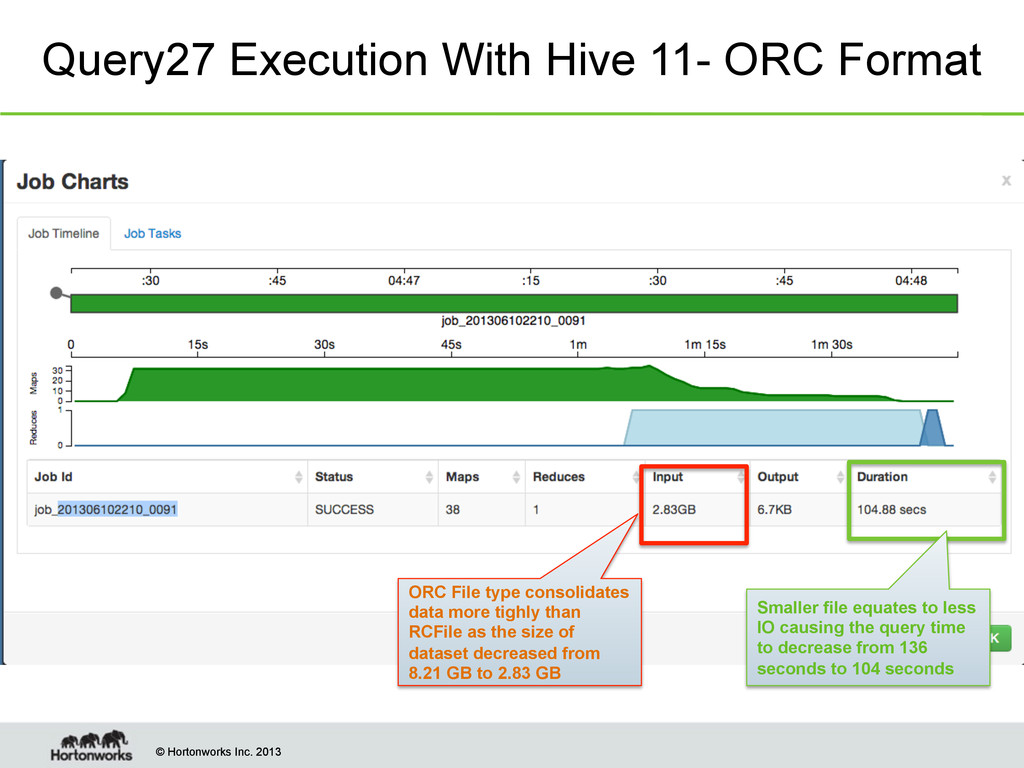
With Hive 11- ORC Format ORC File type consolidates data more tighly than RCFile as the size of dataset decreased from 8.21 GB to 2.83 GB Smaller file equates to less IO causing the query time to decrease from 136 seconds to 104 seconds
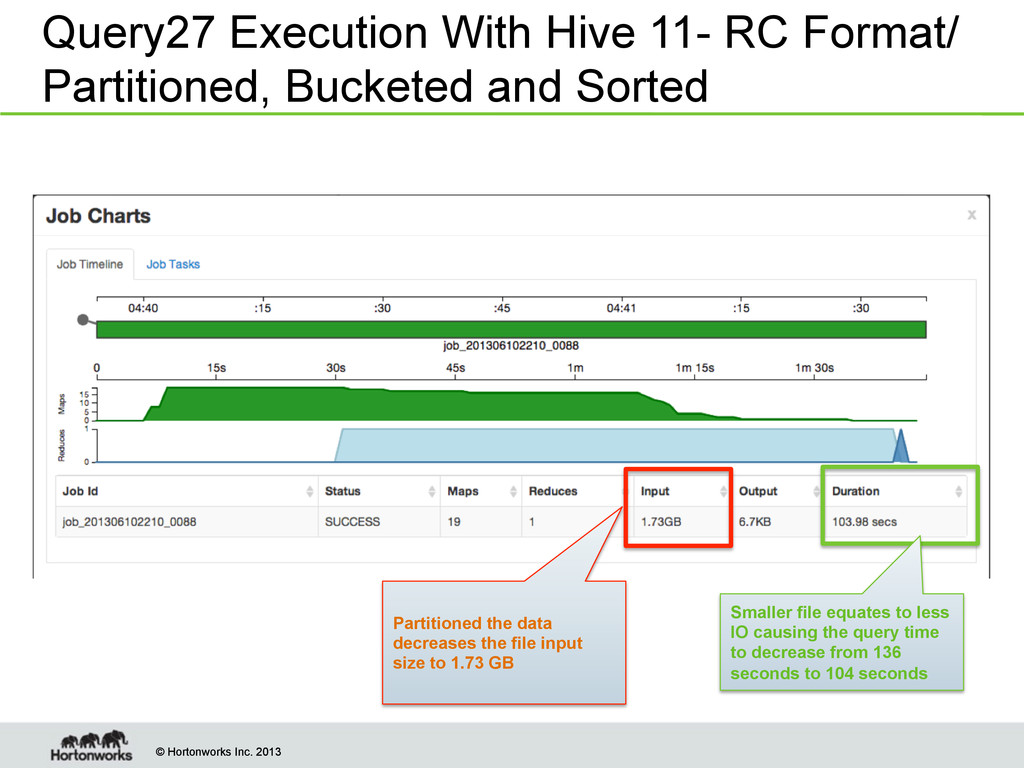
With Hive 11- RC Format/ Partitioned, Bucketed and Sorted Partitioned the data decreases the file input size to 1.73 GB Smaller file equates to less IO causing the query time to decrease from 136 seconds to 104 seconds
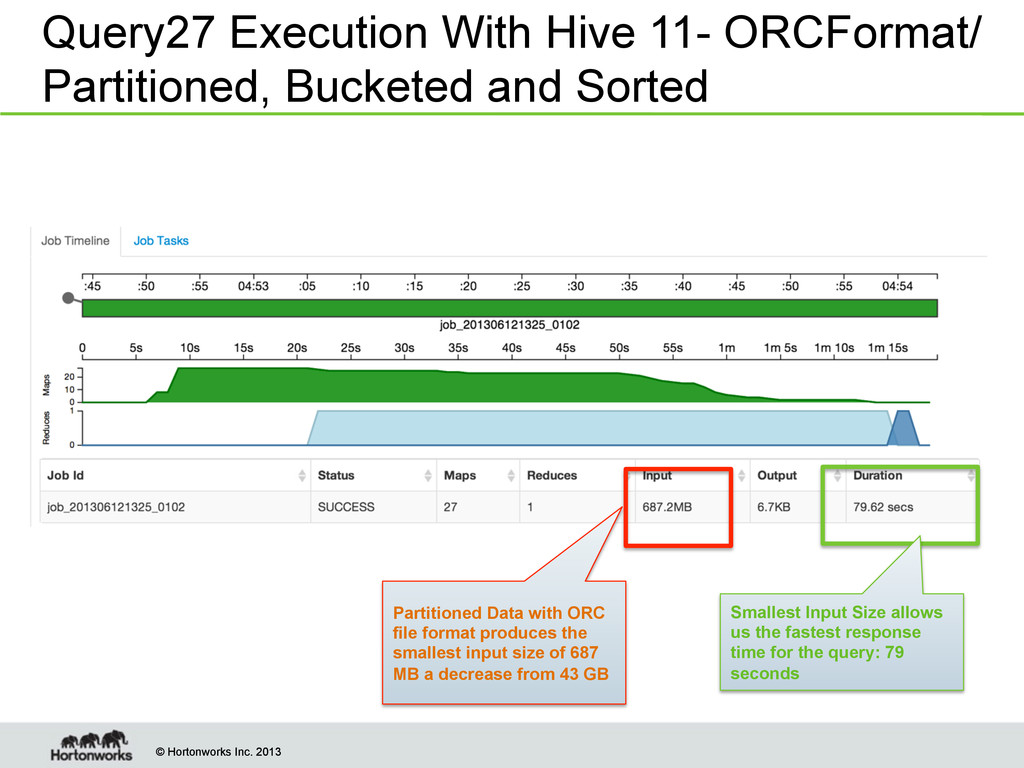
With Hive 11- ORCFormat/ Partitioned, Bucketed and Sorted Partitioned Data with ORC file format produces the smallest input size of 687 MB a decrease from 43 GB Smallest Input Size allows us the fastest response time for the query: 79 seconds
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}