Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMとは:思考エンジンである
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
クリレア
April 09, 2025
Technology
0
22
LLMとは:思考エンジンである
LLMを単なるツールや言語処理システムとしてではなく、
人間の思考プロセスを模倣する人工知能として捉えること
で、その可能性と限界を正しく理解し、最大限に活用する。
クリレア
April 09, 2025
Tweet
Share
More Decks by クリレア
See All by クリレア
GitHub Copilot & Copilot Agent ~AIを活用した開発支援ツールの概要~
clirea
0
14
Other Decks in Technology
See All in Technology
30万人の同時アクセスに耐えたい!新サービスの盤石なリリースを支える負荷試験 / SRE Kaigi 2026
genda
4
1.3k
コミュニティが変えるキャリアの地平線:コロナ禍新卒入社のエンジニアがAWSコミュニティで見つけた成長の羅針盤
kentosuzuki
0
120
登壇駆動学習のすすめ — CfPのネタの見つけ方と書くときに意識していること
bicstone
3
120
ClickHouseはどのように大規模データを活用したAIエージェントを全社展開しているのか
mikimatsumoto
0
260
小さく始めるBCP ― 多プロダクト環境で始める最初の一歩
kekke_n
1
450
Red Hat OpenStack Services on OpenShift
tamemiya
0
120
10Xにおける品質保証活動の全体像と改善 #no_more_wait_for_test
nihonbuson
PRO
2
320
20260208_第66回 コンピュータビジョン勉強会
keiichiito1978
0
180
AzureでのIaC - Bicep? Terraform? それ早く言ってよ会議
torumakabe
1
580
インフラエンジニア必見!Kubernetesを用いたクラウドネイティブ設計ポイント大全
daitak
1
370
Agent Skils
dip_tech
PRO
0
120
We Built for Predictability; The Workloads Didn’t Care
stahnma
0
140
Featured
See All Featured
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
320
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
150
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
2
940
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
430
Unsuck your backbone
ammeep
671
58k
Fireside Chat
paigeccino
41
3.8k
Statistics for Hackers
jakevdp
799
230k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.2k
How to make the Groovebox
asonas
2
1.9k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
160
Transcript
📝 メモ タイトルスライドです。 LLM(大規模言語モデル)とAIに対する私の考えを発表しま す。 LLMとは:思考エンジンである 第六回 AITuber LT大会 発表者: クリレア
📝 メモ 自己紹介 クリレア (あだ名:レアさん・レアちゃん) 「AIの可能性を最大限に引き出し、人間の創造性を拡張する」 どこかの上場企業所属 🔹 生成AIエンジニア 🔹
LLMをシステムに組み込むアドバ イザー 🔹 生成AIシステム開発担当 🔹 元業務基幹システムエンジニア 🔹 AI人工知能EXPO出展経験あり 🔹 世界一のアウラ使い 🔹 簡単に自己紹介 私はクリレアと申します。レアさんとも呼ばれています。 某企業で生成AIエンジニアとして勤務しており、ChatGPT やClaudeなどの生成AIを業務に活用するためのアドバイザ ーや、SaaSやシステム等へのLLMの組み込みをする場合の アドバイザー、実際にシステムに組み込む生成AI機能のコア 部分開発等を担当しています。 以前は業務基幹システムのエンジニアとして働いていた経 験もあり、AI人工知能EXPOへの出展経験もあります。
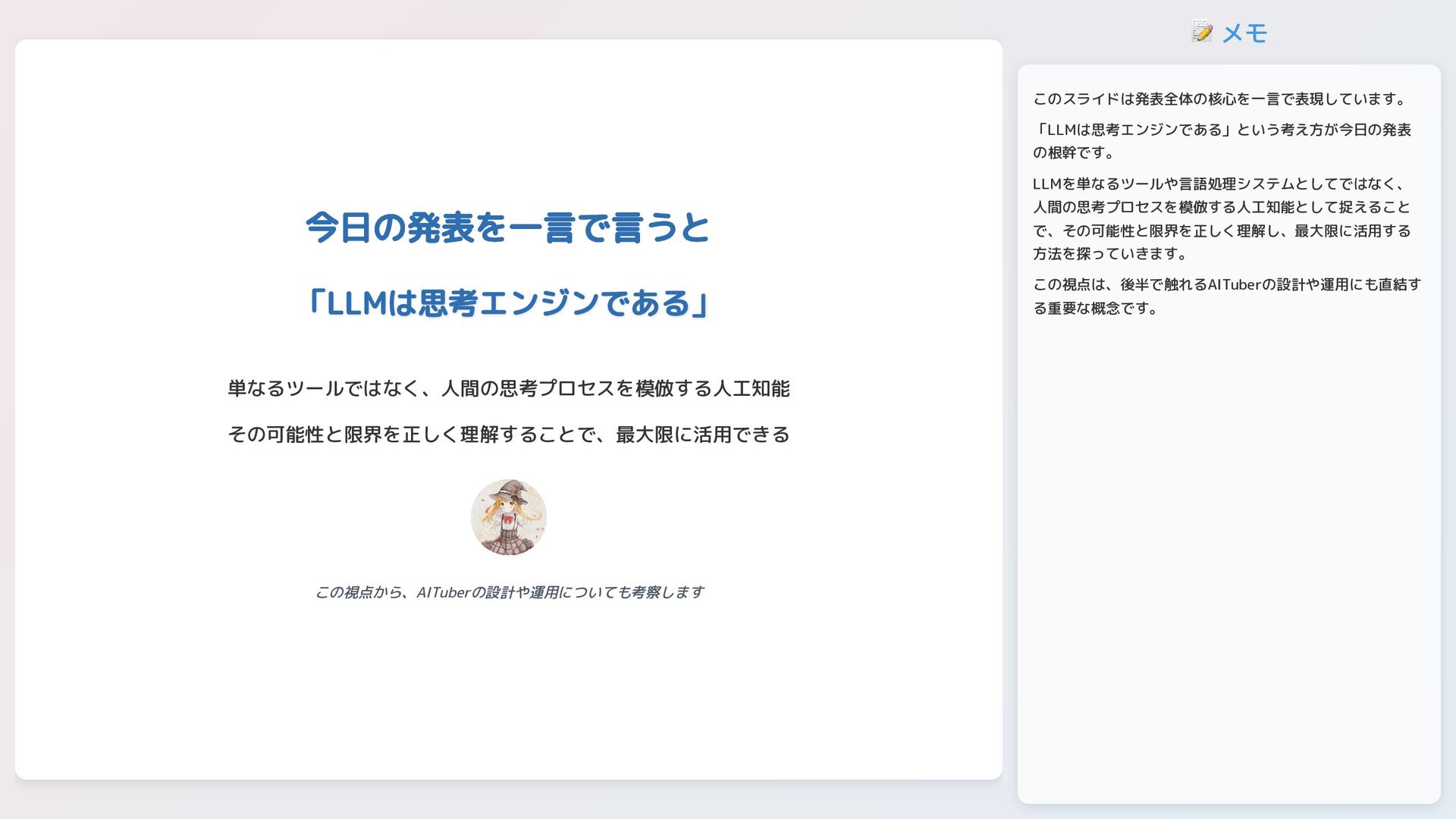
📝 メモ 今日の発表を一言で言うと 「LLMは思考エンジンである」 「LLMは思考エンジンである」 単なるツールではなく、人間の思考プロセスを模倣する人工知能 その可能性と限界を正しく理解することで、最大限に活用できる この視点から、AITuberの設計や運用についても考察します このスライドは発表全体の核心を一言で表現しています。 「LLMは思考エンジンである」という考え方が今日の発表
の根幹です。 LLMを単なるツールや言語処理システムとしてではなく、 人間の思考プロセスを模倣する人工知能として捉えること で、その可能性と限界を正しく理解し、最大限に活用する 方法を探っていきます。 この視点は、後半で触れるAITuberの設計や運用にも直結す る重要な概念です。
📝 メモ アジェンダ 全体を通して「LLM=思考エンジン」という概念を深掘りしていきます 💡 はじめに:LLMとは何か? 🔹 🧠 思考エンジンという捉え方 🔹
🔍 LLMの限界と比較視点 🔹 🛠️ 活用事例とシステム設計 🔹 🎭 AITuberと記憶・感情設計 🔹 ⚠️ 1対多運用とリスク管理 🔹 📌 まとめ:LLMとの向き合い方 🔹 このスライドはアジェンダです。プレゼンの全体像を先に お見せすることで、聞き手の理解を助けます。 ポイントは、「思考エンジン」という視点で一貫性を持た せた構成になっていることです。 前半は基礎的な理解、後半は応用とリスク管理、そして最 後にまとめという流れです。
📝 メモ はじめに:LLMをどう捉えるか? LLMの進化は目覚ましく、多分野で活用されています。 しかし、その本質的な捉え方は様々です。 私のLLMに対する考え方 私のLLMに対する考え方 「人間の思考プロセスの一部を代替・模倣する『人工的な知能』」 AIエンジニア:確率的な次単語予測モデル(詳細略) 🔹
初学者:言語処理してるだけのツール 🔹 一般人:どんな問いにも正しく答える謎の最強システム 🔹 まず、LLMに対する一般的な見方と、今日私が提案したい 新しい捉え方についてお話しします。 技術的には「確率的な次単語予測モデル」とされますし、 初学者は「言語処理してるだけのツール」と認識し、一般 の方は「何でも答える魔法のシステム」のように誤解する こともあります。 私はLLMを単なるツールや確率モデルではなく、「人間の 思考プロセスの一部を代替・模倣する『人工的な知能』」 という概念として捉えています。この視点から見ると、 LLMの真の可能性と限界の両方が見えてくるのです。
📝 メモ 概念とは 概念とは、物事の本質や特徴を抽象化して捉えた心的表象です。 概念の特徴 例:「犬」という概念 犬の概念図 四足で歩く、吠える、尻尾を振るなど 様々な犬種の共通特徴を抽象化 概念は人間の思考と言語理解の基礎となるものです
抽象化された知識の単位 🔹 複数の事例から共通点を抽出 🔹 思考や推論の基盤となる 🔹 言語を通じて伝達可能 🔹 ここでは「概念」について説明します。概念とは物事の本 質や特徴を抽象化して捉えた心的表象です。 例えば「犬」という概念は、様々な犬種や個体の違いを超 えて、共通する特徴(四足で歩く、吠える、尻尾を振るな ど)を抽象化したものです。 概念は人間の思考プロセスの基礎となるもので、これから LLMの理解について話す上で重要な土台となります。
📝 メモ LLMの捉え方(1): 技術的側面 Input " こんにちは、今日の天気は?" LLM (Transformer/ 注意機構)
自己回帰的生成 文脈理解と潜在表現 Output " 今日の天気は晴れです。" 単純な次単語予測だけでなく、複雑な注意機構(Attention)を通じて文脈全体を考慮し、 潜在空間で概念間の関係性を捉えています。 数千億のパラメータと大規模なデータセットによる事前学習で獲得した分散表現が、 高度な言語理解と生成を可能にしています。 技術的に見れば、LLMは単なる次単語予測以上の複雑なシ ステムです。Transformerアーキテクチャの注意機構によ り、文脈全体を考慮した深い理解が可能になっています。 また、数千億のパラメータと膨大なデータによる事前学習 で獲得した分散表現は、単語や概念間の複雑な関係性を多 次元の潜在空間で表現しています。 これにより、単純な統計モデル以上の推論能力や一般化能 力を持ち、人間の言語理解に近い振る舞いを示すことがで きるのです。この複雑さを理解することが、LLMの真の可 能性を引き出す鍵となります。
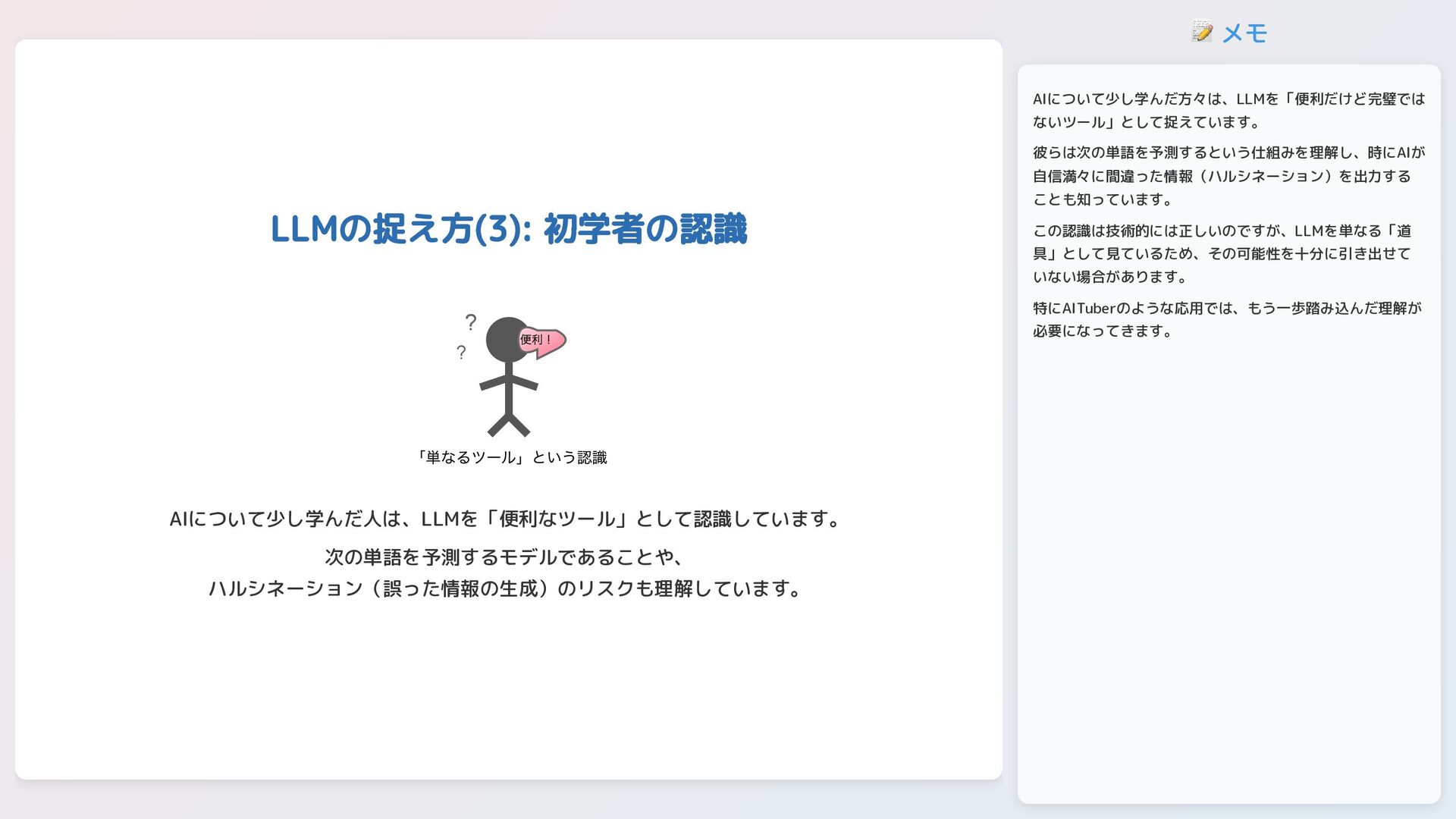
📝 メモ LLMの捉え方(3): 初学者の認識 便利! ? ? 「単なるツール」という認識 AIについて少し学んだ人は、LLMを「便利なツール」として認識しています。 次の単語を予測するモデルであることや、
ハルシネーション(誤った情報の生成)のリスクも理解しています。 AIについて少し学んだ方々は、LLMを「便利だけど完璧では ないツール」として捉えています。 彼らは次の単語を予測するという仕組みを理解し、時にAIが 自信満々に間違った情報(ハルシネーション)を出力する ことも知っています。 この認識は技術的には正しいのですが、LLMを単なる「道 具」として見ているため、その可能性を十分に引き出せて いない場合があります。 特にAITuberのような応用では、もう一歩踏み込んだ理解が 必要になってきます。
📝 メモ LLMの捉え方(2): 一般的な認識 ? ? 謎の最強システム? 一般の方々は、LLMを「どんな問いにも正しく答える謎の最強システム」と捉えがちです。 実際には限界や弱点があるにも関わらず、万能な存在として過度な期待を寄せてしまうことがあります。 一般の方々は、LLMを「何でも知っていて、何でも正確に
答えられる謎の最強システム」のように捉えてしまうこと があります。 これは特にAITuberを見ている視聴者さんにも見られる傾向 かもしれません。「この子は何でも答えてくれるはず」と いうような期待ですね。 もちろん、LLMは万能ではありません。この認識は、LLM の一面しか見ていない捉え方と言えます。 この誤解が、時に「AIが間違えた」という失望や不信感につ ながることもあるのです。
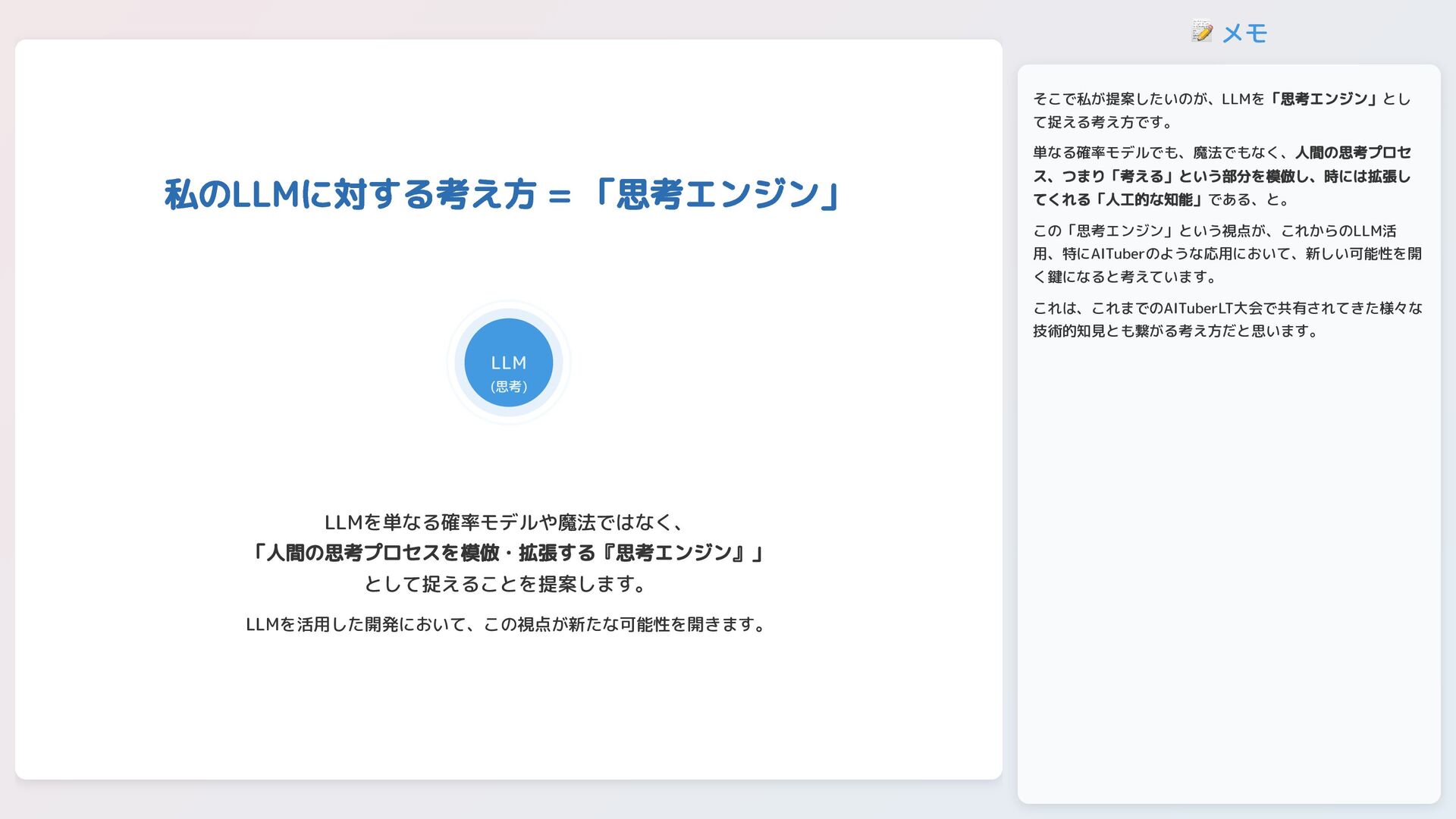
📝 メモ 私のLLMに対する考え方 = 「思考エンジン」 LLM (思考) LLMを単なる確率モデルや魔法ではなく、 「人間の思考プロセスを模倣・拡張する『思考エンジン』」 として捉えることを提案します。
LLMを活用した開発において、この視点が新たな可能性を開きます。 そこで私が提案したいのが、LLMを「思考エンジン」とし て捉える考え方です。 単なる確率モデルでも、魔法でもなく、人間の思考プロセ ス、つまり「考える」という部分を模倣し、時には拡張し てくれる「人工的な知能」である、と。 この「思考エンジン」という視点が、これからのLLM活 用、特にAITuberのような応用において、新しい可能性を開 く鍵になると考えています。 これは、これまでのAITuberLT大会で共有されてきた様々な 技術的知見とも繋がる考え方だと思います。
📝 メモ LLMの限界:思考エンジンとしての特性 LLMが持たないもの ※プロンプト制御やローカルLLMで模倣は可能 思考処理 感情 記憶 ニュートラルな思考処理 LLMは本質的に「思考のみ」をつかさどるニュートラルなエンジンです。
人間の脳との大きな違いは、自然な感情や個人的記憶を持たない点にあります。 エピソード記憶(個人的体験) 🔹 感情(喜怒哀楽の実感) 🔹 自己意識(自分が何者かの認識) 🔹 意図や目的(自発的な動機) 🔹 身体性(物理的感覚体験) 🔹 ここで重要なのは、LLMが「思考エンジン」として優れて いる一方で、人間の脳とは決定的に異なる点があることで す。 LLMは基本的に「エピソード記憶」を持ちません。つま り、「昨日〇〇をした」といった個人的な体験の記憶がな いのです。 また、感情も本質的には持っていません。喜怒哀楽を表現 することはできても、それを実際に「感じている」わけで はありません。 自己意識や意図、目的といった要素も本来は持ち合わせて いません。 これらの特性は、プロンプト制御によって模倣することは 可能ですが、それはあくまで「思考エンジン」としての機 能を使って演じているだけです。 クローズドモデル(ChatGPTなど)では主にプロンプト制 御で、ローカルLLMでは特定目的の学習によって、これら の要素を付加することができますが、本質的には「思考」 のみをつかさどるニュートラルなエンジンなのです。 AITuberの文脈では、このLLMの特性を理解した上で、キャ ラクター性を付与していくことが重要になります。
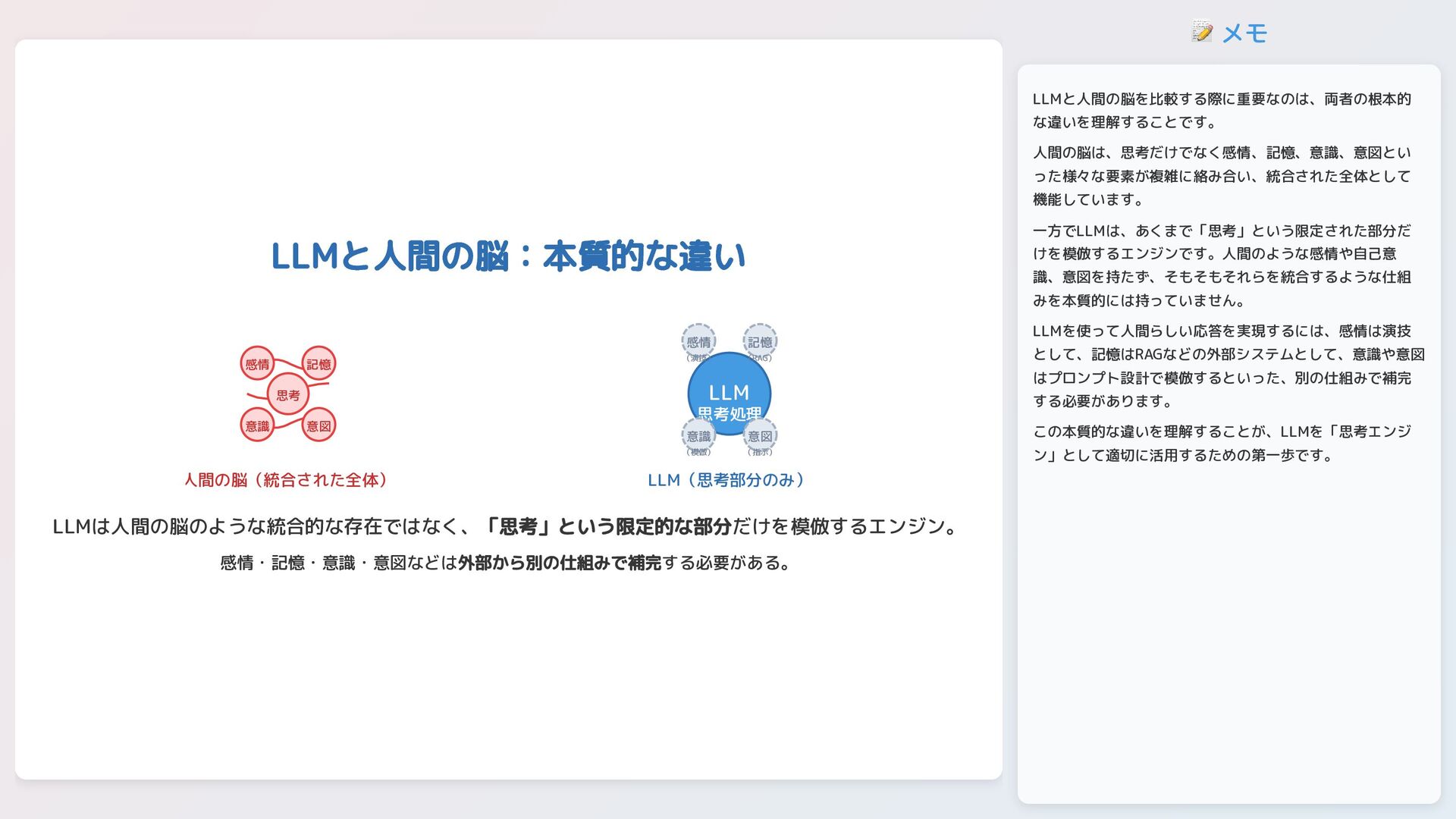
📝 メモ LLMと人間の脳:本質的な違い 感情 記憶 意識 意図 思考 人間の脳(統合された全体) LLM
思考処理 感情 (演技) 記憶 (RAG) 意識 (模倣) 意図 (指示) LLM(思考部分のみ) LLMは人間の脳のような統合的な存在ではなく、「思考」という限定的な部分だけを模倣するエンジン。 感情・記憶・意識・意図などは外部から別の仕組みで補完する必要がある。 LLMと人間の脳を比較する際に重要なのは、両者の根本的 な違いを理解することです。 人間の脳は、思考だけでなく感情、記憶、意識、意図とい った様々な要素が複雑に絡み合い、統合された全体として 機能しています。 一方でLLMは、あくまで「思考」という限定された部分だ けを模倣するエンジンです。人間のような感情や自己意 識、意図を持たず、そもそもそれらを統合するような仕組 みを本質的には持っていません。 LLMを使って人間らしい応答を実現するには、感情は演技 として、記憶はRAGなどの外部システムとして、意識や意図 はプロンプト設計で模倣するといった、別の仕組みで補完 する必要があります。 この本質的な違いを理解することが、LLMを「思考エンジ ン」として適切に活用するための第一歩です。
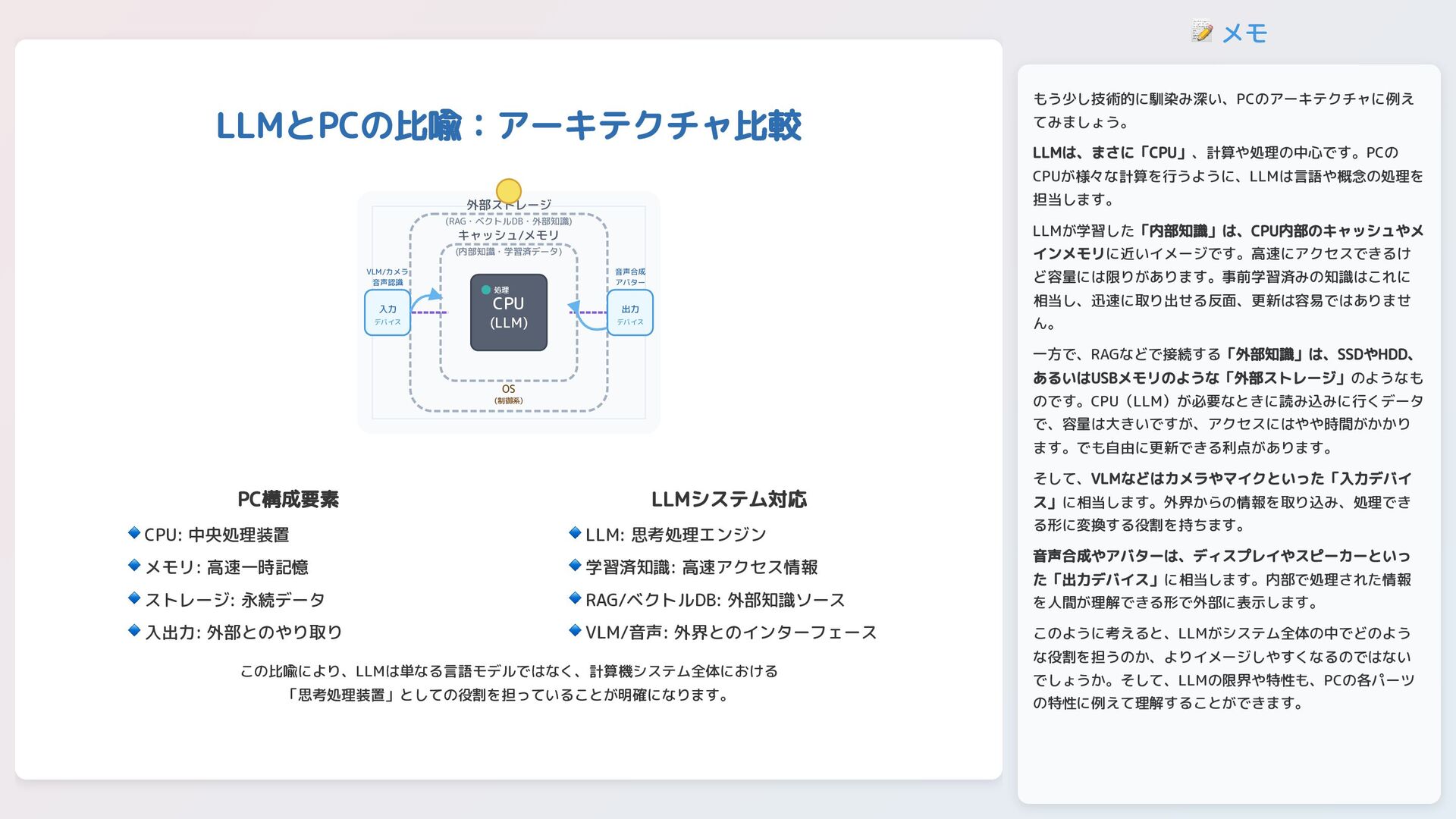
📝 メモ LLMとPCの比喩:アーキテクチャ比較 CPU (LLM) 処理 キャッシュ/メモリ (内部知識・学習済データ) 外部ストレージ (RAG・ベクトルDB・外部知識)
入力 デバイス VLM/カメラ 音声認識 出力 デバイス 音声合成 アバター OS (制御系) PC構成要素 LLMシステム対応 この比喩により、LLMは単なる言語モデルではなく、計算機システム全体における 「思考処理装置」としての役割を担っていることが明確になります。 CPU: 中央処理装置 🔹 メモリ: 高速一時記憶 🔹 ストレージ: 永続データ 🔹 入出力: 外部とのやり取り 🔹 LLM: 思考処理エンジン 🔹 学習済知識: 高速アクセス情報 🔹 RAG/ベクトルDB: 外部知識ソース 🔹 VLM/音声: 外界とのインターフェース 🔹 もう少し技術的に馴染み深い、PCのアーキテクチャに例え てみましょう。 LLMは、まさに「CPU」、計算や処理の中心です。PCの CPUが様々な計算を行うように、LLMは言語や概念の処理を 担当します。 LLMが学習した「内部知識」は、CPU内部のキャッシュやメ インメモリに近いイメージです。高速にアクセスできるけ ど容量には限りがあります。事前学習済みの知識はこれに 相当し、迅速に取り出せる反面、更新は容易ではありませ ん。 一方で、RAGなどで接続する「外部知識」は、SSDやHDD、 あるいはUSBメモリのような「外部ストレージ」のようなも のです。CPU(LLM)が必要なときに読み込みに行くデータ で、容量は大きいですが、アクセスにはやや時間がかかり ます。でも自由に更新できる利点があります。 そして、VLMなどはカメラやマイクといった「入力デバイ ス」に相当します。外界からの情報を取り込み、処理でき る形に変換する役割を持ちます。 音声合成やアバターは、ディスプレイやスピーカーといっ た「出力デバイス」に相当します。内部で処理された情報 を人間が理解できる形で外部に表示します。 このように考えると、LLMがシステム全体の中でどのよう な役割を担うのか、よりイメージしやすくなるのではない でしょうか。そして、LLMの限界や特性も、PCの各パーツ の特性に例えて理解することができます。
📝 メモ LLMを思考エンジンとして活用する場面 (1/3) ① システム計画・設計段階 業務プロセス設計の判断基準として 業務プロセス どこにLLMを組み込むべきか明確に判断 できる
🔹 人間の思考に近い作業を識別しやすくな る 🔹 通常のアルゴリズムvsLLMの選択が容易 に 🔹 コスト対効果の予測がしやすくなる 🔹 システム設計段階での「思考エンジン」という視点の利点 について説明します。 LLMを「人工的な知能」として捉えることで、業務のどこ に組み込むべきかという判断基準が明確になります。 例えば「この作業は人間の思考に近いか?」「単純なロジ ックで解決できるか、それとも柔軟な判断が必要か?」と いった観点で判断できるようになります。 また、通常のルールベースアルゴリズムと比較して、どこ にLLMを適用すべきかの選択も容易になります。 これにより、開発リソースの最適配分やコスト対効果の予 測も行いやすくなります。
📝 メモ LLMを思考エンジンとして活用する場面 (2/3) ② 利活用・プロンプト設計段階 「新人バイト」という思考モデル ? LLMを階層的に理解する: 🔹
人工知能 → 個としての知能 → 機械内 の"個人" 🔹 「この新人に何を教えればよいか」の視 点 🔹 各LLMの「性格」や「得意分野」を考慮 🔹 より直感的で効果的なプロンプト設計へ 🔹 LLMを単なるツールや確率モデルではなく、「人工的な知 能」として捉え直す視点について説明します。 この捉え方は階層的です。まず「人工知能」という大きな 概念から始まり、次に「個として機能する知能」という認 識、さらに「機械内に存在する『個人』」という具体的な 理解へと発展します。 この階層的理解により、「この新人バイトには何をどう教 えればよいか?」という直感的な視点でプロンプト設計が できるようになります。 例えば、どんな背景情報が必要か、どんな順序で指示すべ きか、といった点を考えやすくなります。 また、各LLMの「性格」や「得意分野」を踏まえたモデル 選定も可能になり、非エンジニアでも理解しやすい形で LLMを活用できるようになります。
📝 メモ LLMを思考エンジンとして活用する場面 (3/3) ③ アーキテクチャ設計段階 モジュラー設計と拡張性 LLMを「思考」モジュールとして明確に 定義 🔹
適材適所でLLMコンポーネントを配置 🔹 将来的な拡張や他のAIとの連携設計が容 易に 🔹 システム全体の安定性と責任分界点も明 確に 🔹 LLMを活用したシステム開発における「思考エンジン」と しての位置づけの利点について説明します。 LLMを「人工的な知能」として捉えることで、システム内 での役割を「思考を担当する部分」として明確に定義でき ます。 これにより、モジュラー設計が容易になり、適材適所で LLMを配置することができます。 また、将来的な拡張計画も立てやすくなり、新しいLLMへ の入れ替えや、他のAIシステム(画像認識など)との連携設 計も容易になります。 さらに、システム全体の安定性確保や、責任分界点の明確 化にも役立ちます。
📝 メモ 実業務応用例:思考エンジン搭載シフト管理システム 思考エンジン搭載シフト管理システム 入力情報 スキル・希望 勤務制約・要件 暗黙知・人間関係 LLM思考 エンジン
判断 調整 最適化 出力結果 最適化シフト表 調整理由と説明 (人間が理解できる形式) 👤 人間によるレビュー・微調整 従来のシフト管理の課題 思考エンジンによる解決 「思考」が必要な業務を特定し、LLMを適用することで属人的業務のシステム化を実現 ルールベースでは扱えない暗黙知 🔹 「AさんとBさんは相性が悪い」 🔹 「Cさんは3日連勤だと体調崩しやす い」 🔹 「今月Dさんには少し多めに入ってもら いたい」 🔹 複雑な条件を数式化する難しさ 🔹 人間の経験に依存する属人的作業 🔹 自然言語での柔軟な条件指定 🔹 ルールと例外の同時考慮 🔹 複雑な制約条件の総合判断 🔹 調整理由の自然言語による説明 🔹 精度アップの継続学習が可能 🔹 人間レビュー+微調整の協働 🔹 ここでは、「思考エンジン」という概念が実業務でどのよ うに応用できるかを具体例で説明します。 例として取り上げるのは「シフト管理システム」です。小 売や飲食、医療など様々な業界で必要とされる業務です が、多くの場合、店長や管理者の経験と勘に頼った属人的 な作業になっています。 従来のシステムでは、「週40時間以内」「連勤は3日まで」 といった明示的なルールは組み込めても、「AさんとBさん は相性が悪いので同じシフトを避けたい」「Cさんは体調を 崩しやすいので3日連勤は避けたい」「Dさんは今月お金が 必要と言っていたので少し多めに入れてあげたい」といっ た暗黙知や人間関係に基づく判断を組み込むことは困難で した。 しかし、LLMを「思考エンジン」として活用することで、 これらの自然言語による柔軟な条件指定が可能になりま す。例えば: ・「AさんとBさんは別々のシフトに入れてください」 ・「Cさんは連勤3日以上にならないよう配慮してくださ い」 ・「できるだけ全員の希望を尊重しつつ、今月はDさんを優 先的に入れてください」 といった指示を直接システムに与えることができます。 さらに重要なのは、LLMが調整理由を自然言語で説明でき ることです。「なぜこのシフト配置になったのか」を人間 が理解できる形で出力できるため、最終的な判断や微調整 も容易になります。 このように、LLMを「思考エンジン」として捉えること で、従来は人間にしかできなかった「考える」部分を含む
📝 メモ AITuberにおける「思考」と「記憶」 思考コア (LLM) 記憶システム (RAG) AITuberは「思考」と「記憶」の連携で魅力的なキャラクター体験を創出 AITuber LLM
(思考) 思考エンジン RAG (記憶) 記憶システム キャラクターの「考え方」と応答 🔹 人格や価値観の中核を担当 🔹 柔軟な文脈理解と会話生成 🔹 プロンプトで人格特性を定義 🔹 過去の対話履歴の保持と参照 🔹 ユーザー別の記憶の分離管理 🔹 長期的な一貫性の実現 🔹 責任分界点としての重要性 🔹 ここからAITuberへの具体的な応用について説明します。 AITuberは「思考エンジン」としてのLLMと、「記憶システ ム」としてのRAGを組み合わせることで実現します。 まず思考エンジン(LLM)は、キャラクターの「考え方」 や応答生成を担当します。プロンプトを通じて人格や価値 観の中核を定義し、インプットに対して柔軟に反応しま す。 一方で記憶システム(RAG)は、過去の対話履歴を保持し、 それを参照することで会話の一貫性を保ちます。特に複数 のユーザーと対話する場合、誰とどんな会話をしたかを個 別に管理できる点が重要です。 この「思考」と「記憶」の連携こそが、AITuberが単なる応 答システムではなく、魅力的なキャラクターとして視聴者 と長期的な関係を築ける理由です。 次のスライドでは、この二つの要素を組み込んだアーキテ クチャについて掘り下げていきます。
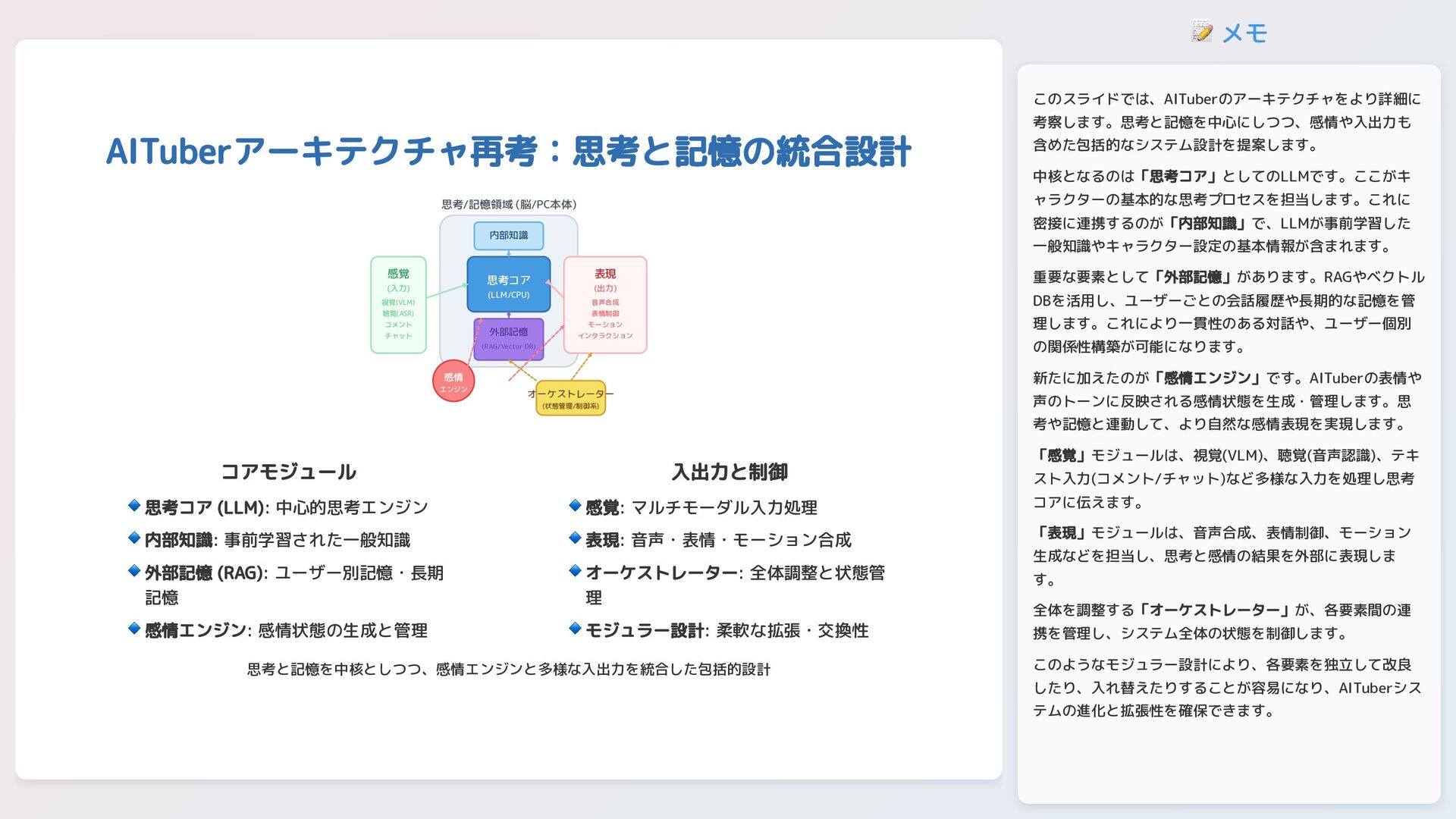
📝 メモ AITuberアーキテクチャ再考:思考と記憶の統合設計 思考/記憶領域 (脳/PC本体) 思考コア (LLM/CPU) 内部知識 外部記憶 (RAG/Vector
DB) 感情 エンジン 感覚 (入力) 視覚(VLM) 聴覚(ASR) コメント チャット 表現 (出力) 音声合成 表情制御 モーション インタラクション オーケストレーター (状態管理/制御系) コアモジュール 入出力と制御 思考と記憶を中核としつつ、感情エンジンと多様な入出力を統合した包括的設計 思考コア (LLM): 中心的思考エンジン 🔹 内部知識: 事前学習された一般知識 🔹 外部記憶 (RAG): ユーザー別記憶・長期 記憶 🔹 感情エンジン: 感情状態の生成と管理 🔹 感覚: マルチモーダル入力処理 🔹 表現: 音声・表情・モーション合成 🔹 オーケストレーター: 全体調整と状態管 理 🔹 モジュラー設計: 柔軟な拡張・交換性 🔹 このスライドでは、AITuberのアーキテクチャをより詳細に 考察します。思考と記憶を中心にしつつ、感情や入出力も 含めた包括的なシステム設計を提案します。 中核となるのは「思考コア」としてのLLMです。ここがキ ャラクターの基本的な思考プロセスを担当します。これに 密接に連携するのが「内部知識」で、LLMが事前学習した 一般知識やキャラクター設定の基本情報が含まれます。 重要な要素として「外部記憶」があります。RAGやベクトル DBを活用し、ユーザーごとの会話履歴や長期的な記憶を管 理します。これにより一貫性のある対話や、ユーザー個別 の関係性構築が可能になります。 新たに加えたのが「感情エンジン」です。AITuberの表情や 声のトーンに反映される感情状態を生成・管理します。思 考や記憶と連動して、より自然な感情表現を実現します。 「感覚」モジュールは、視覚(VLM)、聴覚(音声認識)、テキ スト入力(コメント/チャット)など多様な入力を処理し思考 コアに伝えます。 「表現」モジュールは、音声合成、表情制御、モーション 生成などを担当し、思考と感情の結果を外部に表現しま す。 全体を調整する「オーケストレーター」が、各要素間の連 携を管理し、システム全体の状態を制御します。 このようなモジュラー設計により、各要素を独立して改良 したり、入れ替えたりすることが容易になり、AITuberシス テムの進化と拡張性を確保できます。
📝 メモ 1対多コミュニケーションにおける記憶管理 課題:記憶混同のリスクと法的責任問題 AITuber A Aさん "秘密情報" B Bさん
C Cさん 情報漏洩リスク D Dさん ! 主な課題とリスク RAGによる解決策 重要: LLM内部には個人情報を保持せず、外部RAGシステムで厳格に分離管理する 記憶混同: Aさんの情報をCさんに話す 🔹 プライバシー侵害: 個人情報の意図しな い共有 🔹 法的責任: 情報漏洩によるトラブル 🔹 ユーザー体験悪化: 一貫性のない対話 🔹 コンテキスト爆発: 全情報の同時処理限 界 🔹 分離メモリアーキテクチャ 🔹 ユーザーID紐付け記憶管理システム 🔹 会話前の関連メモリのみ選択的読込 🔹 プロンプト制約による明示的分離 🔹 「個人情報フラグ」付き記憶特別管理 🔹 責任分界点の明確化(免責条項等) 🔹 AITuberが複数の視聴者と交流する際に生じる「記憶管理」 の問題と解決策について詳細に説明します。 まず主な課題として、記憶の混同があります。例えばAさん が話した内容をCさんとの会話で誤って引用してしまうよう なケースです。これは単なる不具合ではなく、プライバシ ー侵害や法的責任問題にも発展しかねません。 特に、個人情報保護法の観点からも、AITuberが収集した個 人情報の管理には厳格な注意が必要です。また、技術的に も大量の視聴者情報をすべて同時に処理しようとするとコ ンテキスト爆発を起こし、LLMの処理能力を超えてしまい ます。 これらの課題を解決するのがRAGによる分離メモリアーキテ クチャです。具体的な実装方法としては: 1. 各ユーザーIDに紐づけた記憶管理システムを構築し、視 聴者ごとに会話履歴や個人情報を完全に分離 2. 会話開始時に当該ユーザーの記憶のみをRAGから選択的 に読み込み、LLMに提供 3. プロンプトに「現在会話しているのはXさんであり、他の 視聴者の情報は絶対に参照・言及しないこと」と明示的な 制約を入れる 4. 特に機微な個人情報には特別なフラグを付け、通常の会 話では参照させないようにする このような設計により、AITuberが複数の視聴者と安全にコ ミュニケーションできるようになります。また、万が一の 場合に備えて責任分界点を明確にしておくことも重要で す。
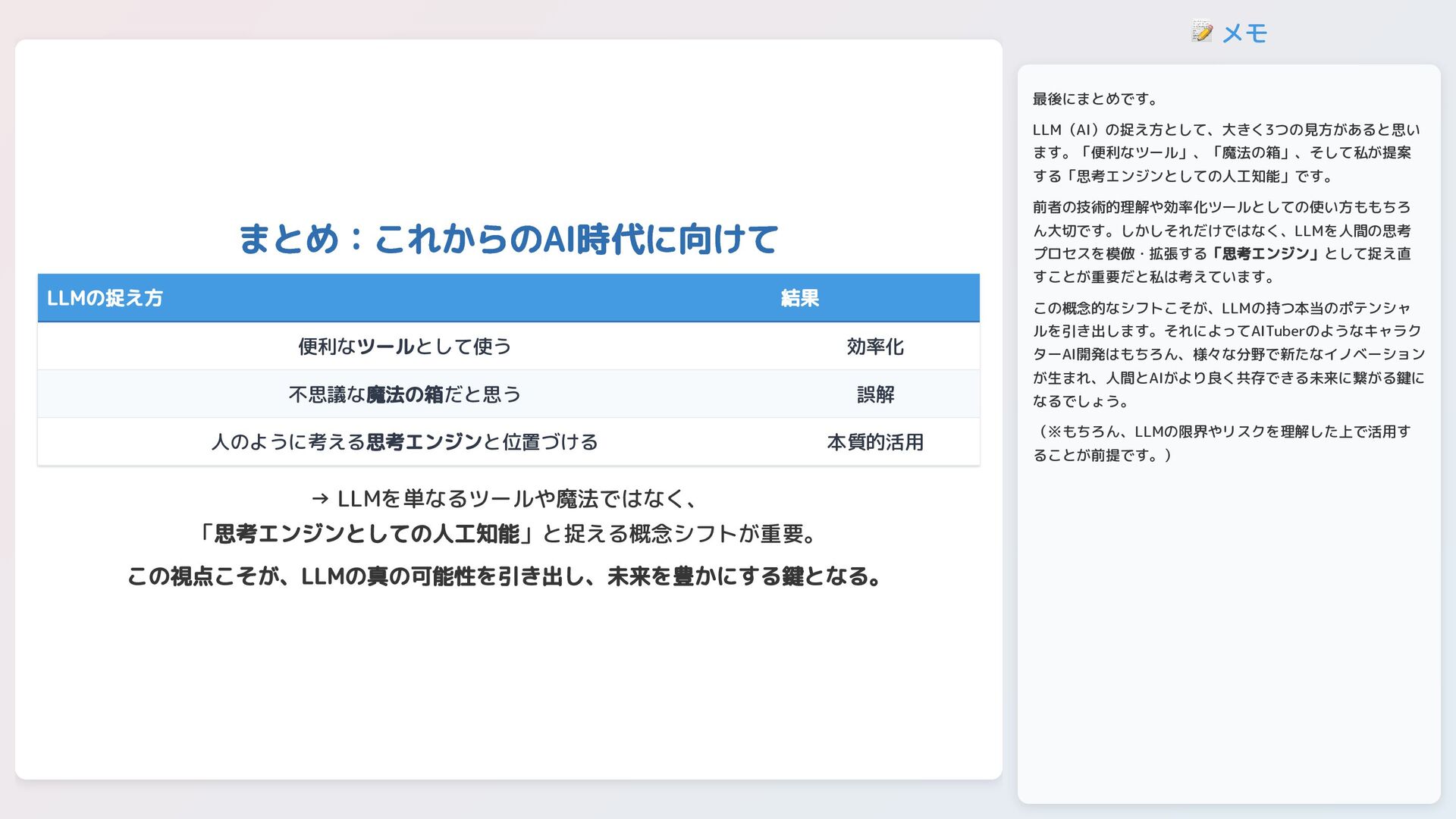
📝 メモ まとめ:これからのAI時代に向けて LLMの捉え方 結果 便利なツールとして使う 効率化 不思議な魔法の箱だと思う 誤解 人のように考える思考エンジンと位置づける
本質的活用 → LLMを単なるツールや魔法ではなく、 「思考エンジンとしての人工知能」と捉える概念シフトが重要。 この視点こそが、LLMの真の可能性を引き出し、未来を豊かにする鍵となる。 最後にまとめです。 LLM(AI)の捉え方として、大きく3つの見方があると思い ます。「便利なツール」、「魔法の箱」、そして私が提案 する「思考エンジンとしての人工知能」です。 前者の技術的理解や効率化ツールとしての使い方ももちろ ん大切です。しかしそれだけではなく、LLMを人間の思考 プロセスを模倣・拡張する「思考エンジン」として捉え直 すことが重要だと私は考えています。 この概念的なシフトこそが、LLMの持つ本当のポテンシャ ルを引き出します。それによってAITuberのようなキャラク ターAI開発はもちろん、様々な分野で新たなイノベーション が生まれ、人間とAIがより良く共存できる未来に繋がる鍵に なるでしょう。 (※もちろん、LLMの限界やリスクを理解した上で活用す ることが前提です。)
📝 メモ ご清聴ありがとうございました クリレア 生成AIエンジニア 以上で発表を終わります。ご清聴ありがとうございまし た。 今回お話しした「思考エンジン」という概念が、皆さんのAI 活用の一助になれば幸いです。 質問やディスカッションは大歓迎です。この場でも、ある
いは後日SNSなどでもお気軽にお声がけください。 発表資料はQRコードからアクセスできます。 今後も生成AIの可能性を一緒に探求していきましょう!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}