now also including foundational cognitive capabilities – ½ of Platform team today is responsible for cognitive foundations like SOLR/Retrieve- &-Rank and Document Conversion/Ingestion services • Provides foundational capabilities for Watson cognitive services & solutions – Leverage other IBM services – Leverage open source – Build our own “if multiple cognitive service teams need it, the Watson Platform team builds/gets it” • Micro-services architecture skills & resources – Platform team provide “guides” to cognitive service teams to adopt micro-services architecture • Supports: – An ecosystem of 40+ microservices – Running on a mixture of containers (Marathon/Mesos+Netflix OSS), VMs, and baremetals – Network connectivity is required among all microservices 2
developers Nov 2013: Watson Developer Cloud launched Dec 2014: 8 services beta services available Mar 2015: Look at Mesos for faster deployment times Aug 2015: Mesoscon Seattle Sep 2015: Mesos/Marathon architecture in production with R&R service as GA (50 nodes) Jan-Feb 2016: Multiple small service releases (e.g. Personality Insights, Emotion Analysis) Mar 2016: Rollout of E2E Service Offerings (e.g. Dialog, Conversation) Nov 2016: Running 25 micro-services on M+M on 1000 nodes
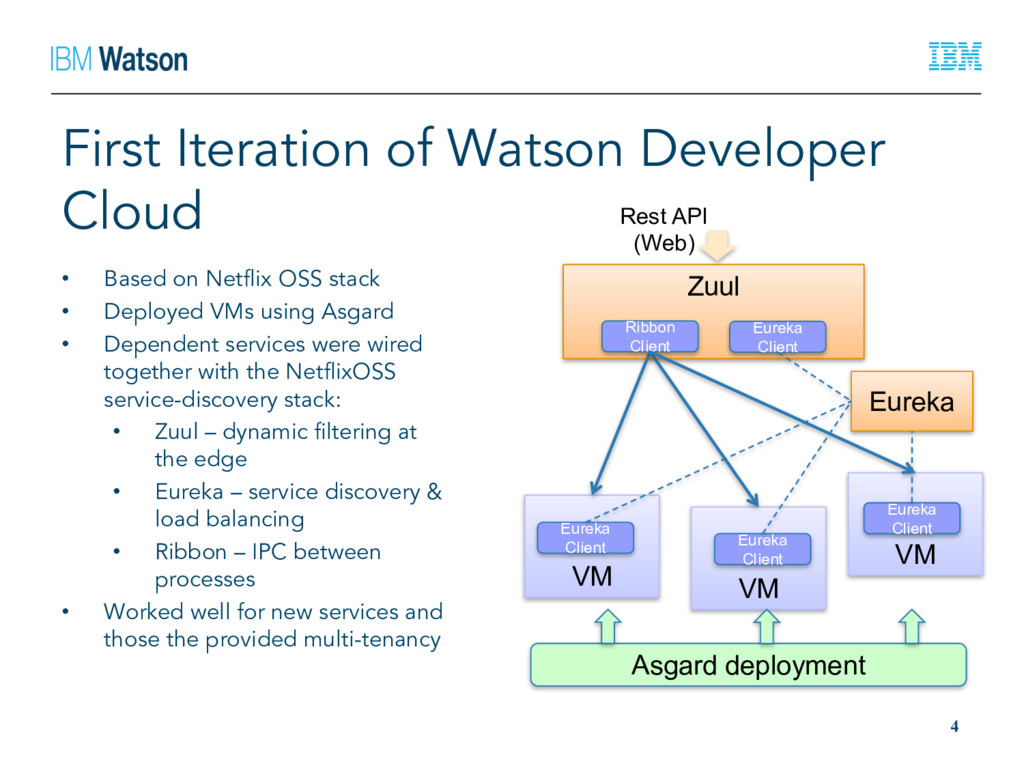
OSS stack • Deployed VMs using Asgard • Dependent services were wired together with the NetflixOSS service-discovery stack: • Zuul – dynamic filtering at the edge • Eureka – service discovery & load balancing • Ribbon – IPC between processes • Worked well for new services and those the provided multi-tenancy 4 VM VM VM Eureka Zuul Eureka Client Eureka Client Eureka Client Ribbon Client Eureka Client Asgard deployment Rest API (Web)
Rank is a wrapper around Solr • One Solr instance per tenant (can’t separate users in a single Solr instance) • Need to rapidly provision new instances • Tried wrapping Asgard APIs but still found VM provisioning too slow and updates across a large number of VMs would take too long • Solution never deployed | 5
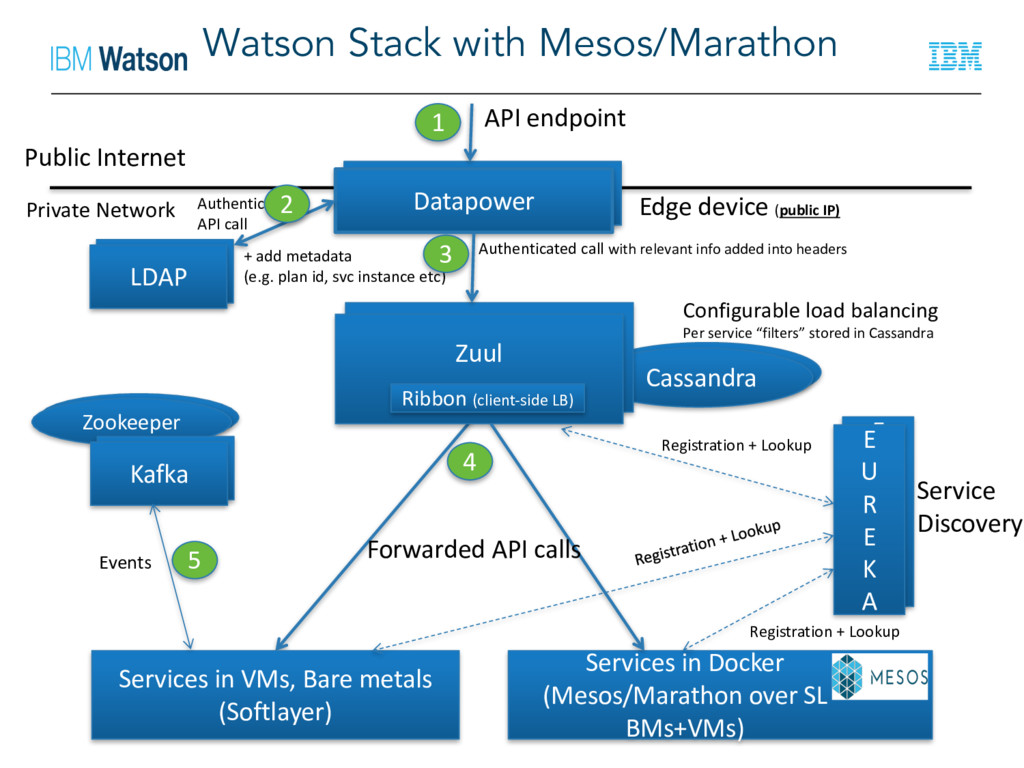
LDAP LDAP Zuul Zuul E U R E K A E U R E K A Services in VMs, Bare metals (Softlayer) Services in Docker (Mesos/Marathon over SL BMs+VMs) LDAP Kafka Public Internet Edge device (public IP) Authenticate API call Authenticated call with relevant info added into headers Configurable load balancing Per service “filters” stored in Cassandra Ribbon (client-side LB) API endpoint Service Discovery Registration + Lookup Registration + Lookup Forwarded API calls Events + add metadata (e.g. plan id, svc instance etc) 1 2 3 4 5 Private Network
APIs were just released as beta in Mesos • Cannot use remote storage since Solr doesn’t perform as efficiently • Implemented strategy using Solr Cloud and mirrored containers with the hopes that both would not go down at the same time • Hope is not a strategyL | 8 Node 1 Node 2 Solr Cloud using Zookeeper
R&R is new Marathon app, so 1000s of apps • Observed: • Marathon processes consistently could not designate a leader and lost connections to Zookeeper • Cause: • Zookeeper chroot too big. Limit of 1 MB on GET requests. • Too many env variable + applications cause additional large writes to the group:node chroot • Caused Zookeeper connects to consistently timeout on the 1 MB limit of GET requests from Marathon • Remediation: • Emergency upgrade from 0.9.0 to 0.11.1 solved the issue by compressing data. • Further enhanced in Marathon-4178 | 9
service meant treating each user as a Marathon application • Explosion of application instances • Marathon GUI couldn’t support • Had to limit to 1000 per Marathon instance and run multiple on top of Mesos
Solr containers could tolerate one container loss. • Observed: • Marathon lost connection with all containers. No checkpointing or control. • Cause: • Marathon instances lost connection for some time and re-registered under a different framework ID • All instances remained associated with old framework ID which no longer existed • Tried to hack zookeeper registry with new framework ID. Worked for a short time. Then Marathon rescheduled all instances to new hosts. • Remediation: • Had to run scripts to find old data volumes and migrate to new host • Developed custom pinning functionality for R&R service • Apps get started and updated on the same machines • Very brittle process since bare-metal machine failures include hardware problems | 11 Marathon lost connection for some time Connection resumes Marathon re- registered as new framework Try to fix in ZK registry All containers rescheduled
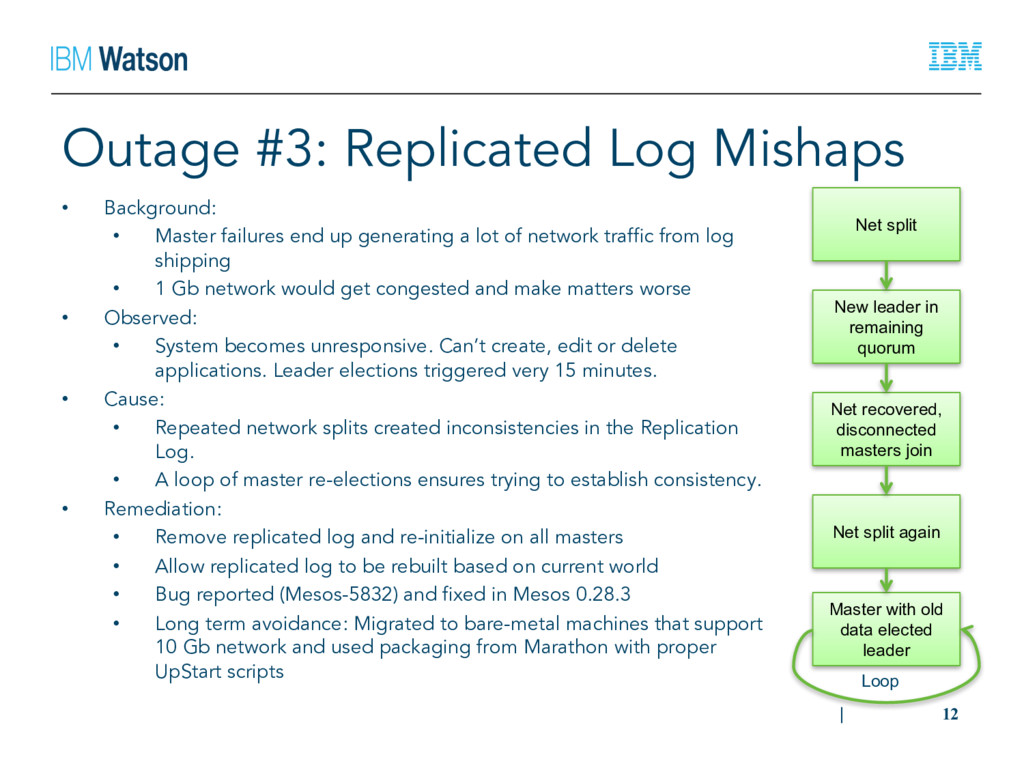
end up generating a lot of network traffic from log shipping • 1 Gb network would get congested and make matters worse • Observed: • System becomes unresponsive. Can’t create, edit or delete applications. Leader elections triggered very 15 minutes. • Cause: • Repeated network splits created inconsistencies in the Replication Log. • A loop of master re-elections ensures trying to establish consistency. • Remediation: • Remove replicated log and re-initialize on all masters • Allow replicated log to be rebuilt based on current world • Bug reported (Mesos-5832) and fixed in Mesos 0.28.3 • Long term avoidance: Migrated to bare-metal machines that support 10 Gb network and used packaging from Marathon with proper UpStart scripts | 12 Net split New leader in remaining quorum Net recovered, disconnected masters join Net split again Master with old data elected leader Loop
important for your service when it comes to availability + performance tradeoffs • Many remote storage options with multiple shards + SSDs can come pretty close to what you will get with a local drive, especially if disk encryption is involved • Pinning machines is a hack and makes things a linear problem • Hardware + general issues increase in frequency when you add more machines • Stateless services turn a few machines into a low priority alert that can be handled in the morning | 13
(make sure you have good network speeds) • Investing in large bandwidth components are super important especially if you are sending a bunch of traffic for your logs • Use fatal logging and leverage glog to increase verbosity during times of distress • Increase ZK timeouts to defend against network splits | 14
VM deployment assumed that they could port the same requirements to Docker container • Dangerous strategy since lack of bin packing may not allow for large containers to find a node if a bunch of tiny containers fill them up • Wasted money if the service never uses all memory assigned to it • Need to educate development teams on micro-service architecture: • Point out common services like logging • Break services into separate containers • Ensure memory limits are not set too high | 15
can be very difficult • We have many services that prefer more CPU and can deal with less MEM • This unfortunately means that you can have a ton of wasted resources on the MEM side • Short term: • Consider using roles and attributes to schedule certain workloads on machines with many CPUs but not a ton of RAM (heterogeneous machines can quickly become an important tradeoff) • Longer term: • Advanced workload scheduling capabilities | 16
we wanted to automatically create more instances • Had a constant problem with over provisioning of services to handle peak loads • Solutions such as marathon-lb would not work: • Not compatible with our Zuul design (marathon-lb uses haproxy) • Client-side monitoring vs container utilization • Looked at Aurora, but big blocker was lack of REST API. Most of our services didn’t want to work with Thrift wrapper. • Still working on solution to this. | 17
and de- duplication (Prometheus) • Depending on how many components you install on one machine, you can get considerable alert fatigue when updating masters or when there are multiple machine failures 2. Need detailed container usage metrics: • Find overprovisioning of containers (too big or too many) • Monitor utilization to make scaling decisions • Monitor container placement and manually orchestrate bin packing strategy 3. Capacity planning • Necessary to have good metrics on actual density and placement of existing services since Mesos will only show sums of the total cluster | 18
systems getting increasingly more difficult to update at scale • Ansible is great for fire and forget, but push-based models have a huge turnover time with a large number of nodes | 19 • Maintenance primitives in Mesos can be leveraged even without scheduler framework buy-in • You can still use operator end-points to reserve instances and hack in your own maintenance primitives • We used labels to define 5 zones for maintenance.
• Important to run against new services • Lowers risks prior to production deployment • Currently test two scenarios: • Percent instances down (e.g 25%) • Killing a very busy node • Measurements: • SLA • Recovery time | 20
to 1000 nodes on Mesos+Marathon • Achieved “four nines” availability for all months this year in multi-tenant cluster (except 1 – period of few hours when ran out of cluster capacity) • Now running smoothly in production and expanding rapidly • Need good architecture/development skills to handle production support • Advice for new users: • Stateful services not well supported • Get fastest network you can • Design micro-services properly (when moving from VMs) • More work to do on scheduling, autoscaling, metrics, maintenance/deployment • Chaos testing | 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}