https://2017.codefest.ru/lecture/1172
На сегодняшний день подход big data доказал свою полезность для бизнеса и сформировался как самостоятельное направление в IT-индустрии. Анализом больших объёмов статистики занимаются не только компании-гиганты, в этой области пробуют силы даже стартапы. Однако у небольших компаний нет готовой инфраструктуры и набора inhouse-решений для приёма, доставки и обработки данных.
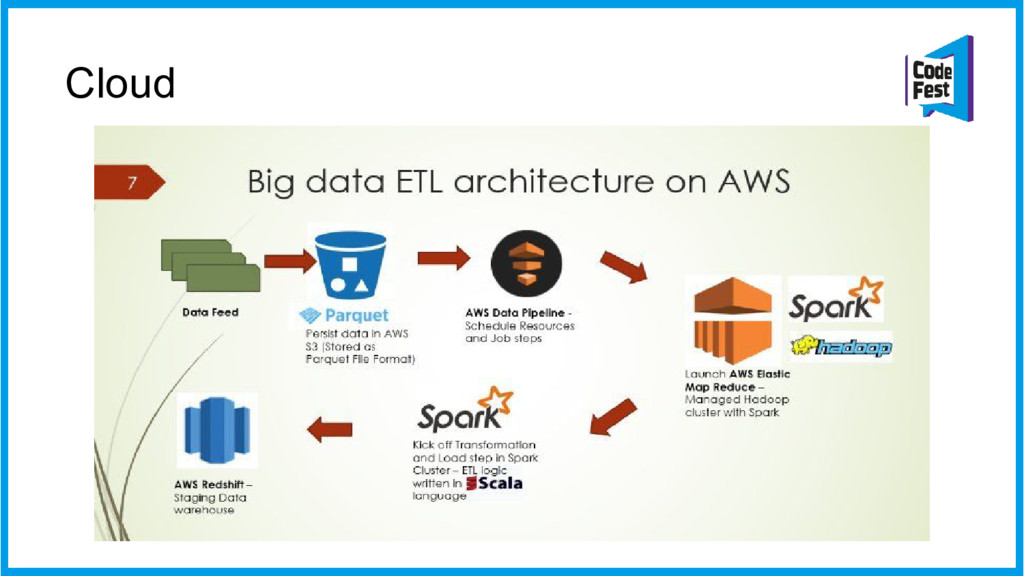
В этом докладе я расскажу о принципах, подходах и open-source компонентах на которых можно такое решение построить. Сфокусируемся на инженерной части BigData: бэкендах приёма, очередях доставки и хранилищах данных. Рассмотрим потоковую (data streaming) и массовую (map-reduce) обработку данных. Также поговорим про такую важную тему как форматы представления данных, немного затронем тему сбора данных в приложении / браузере. И конечно я расскажу как и с помощью каких инструментов мы решали эту задачу в 2GIS. В ходе рассказа будут упомянуты Golang, C++, Hadoop, Kafka, Spark и некоторые другие технологии. Если вы используете другой стек - не страшно, упор будет сделан на принципы и архитектуру.
Цель моего доклада: Если (на самом деле когда) к вам прийдёт CEO со словами "давай начнём собирать данные", вы будете знать, какими принципами руководствоваться и в какую сторону копать. Информации на тему “как освоить R, Python, Hadoop за 21 день и стать высокооплачиваемым data scientist ’ом, увы, не будет.
{kind=link}
![[Not So] Big Data • ~ 100 миллиардов записей в](https://files.speakerdeck.com/presentations/4ec6e5dc2e0c49cfa976c44b382e7d63/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
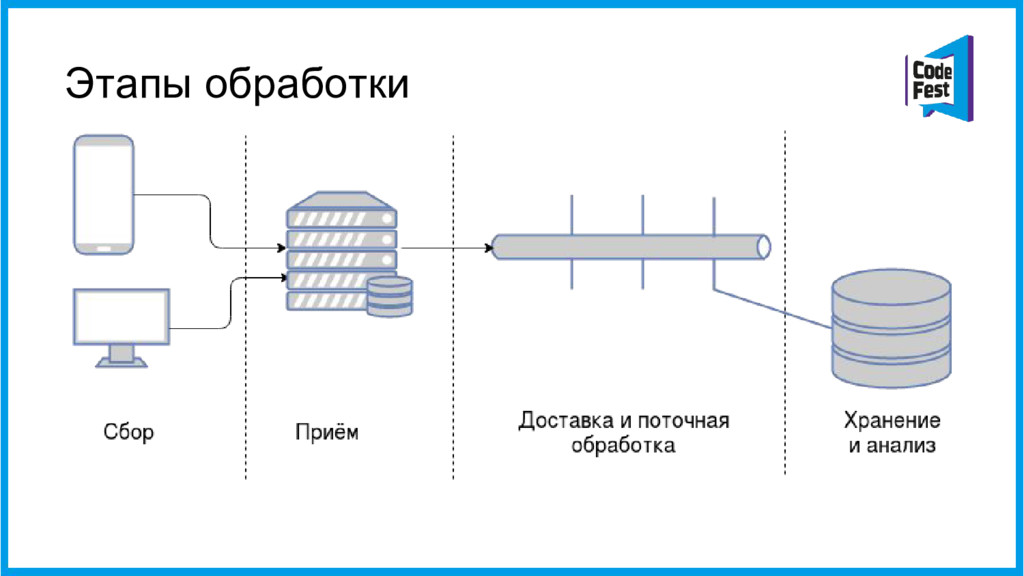{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
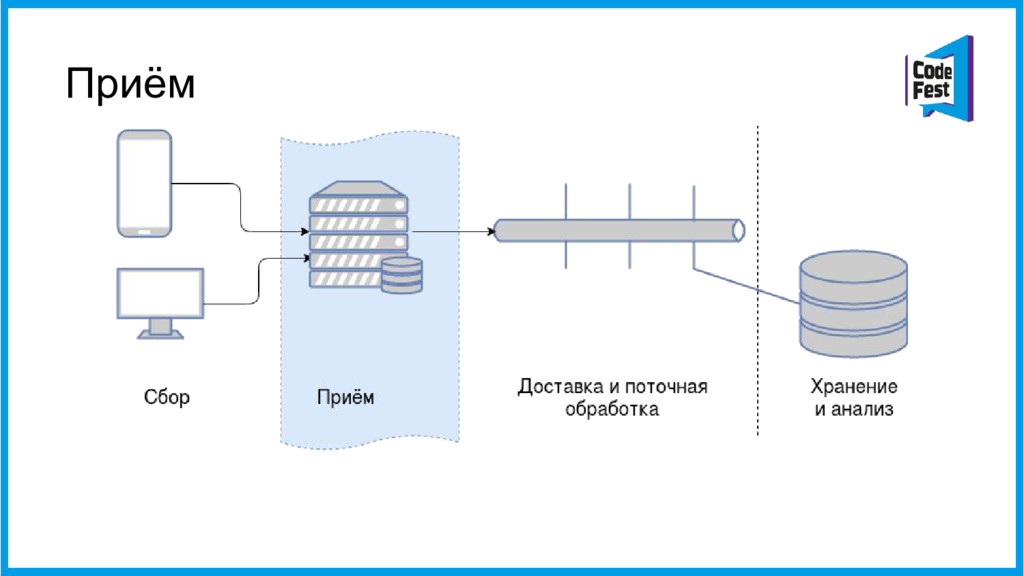{kind=link}
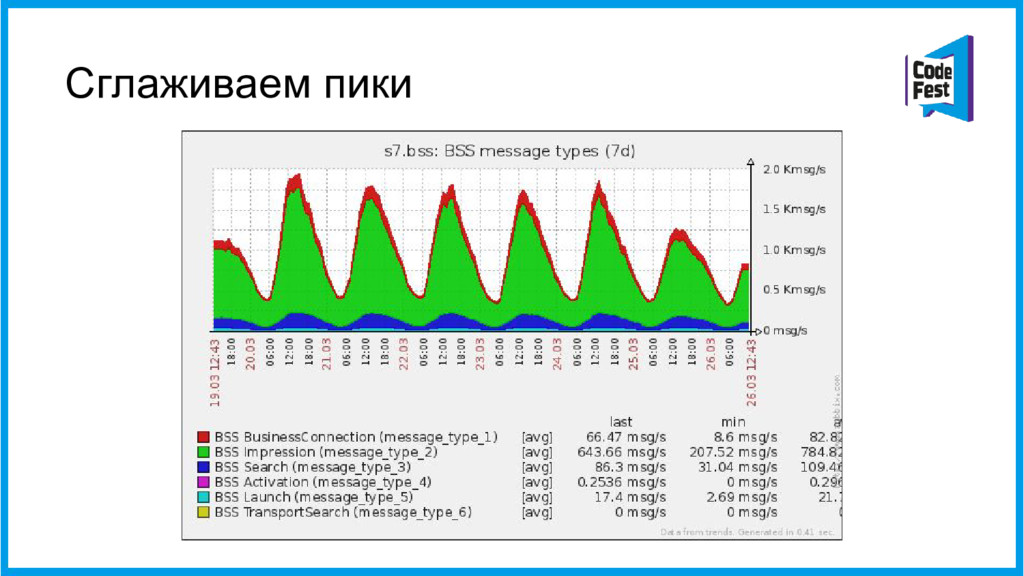{kind=link}
{kind=link}
{kind=link}
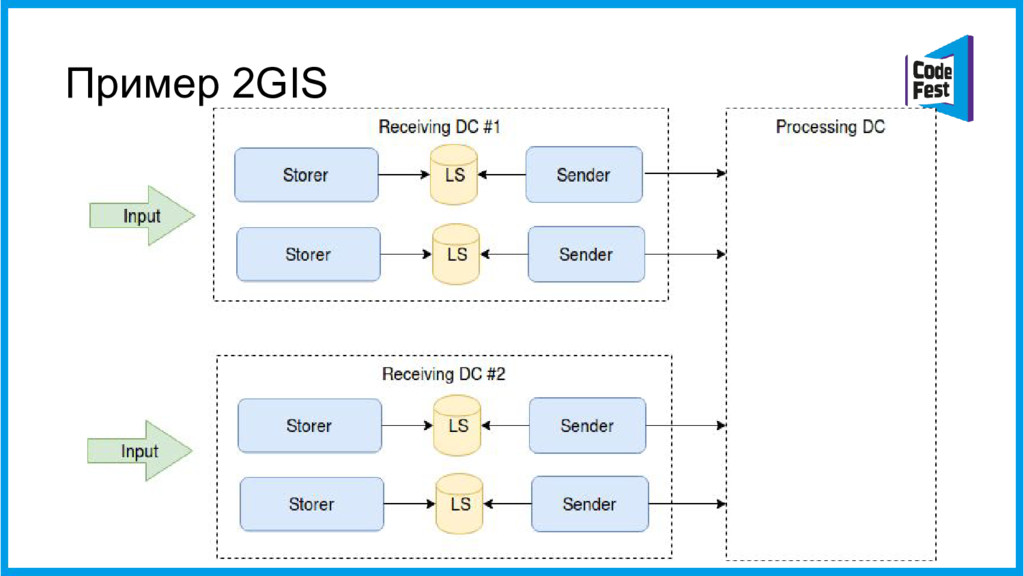{kind=link}
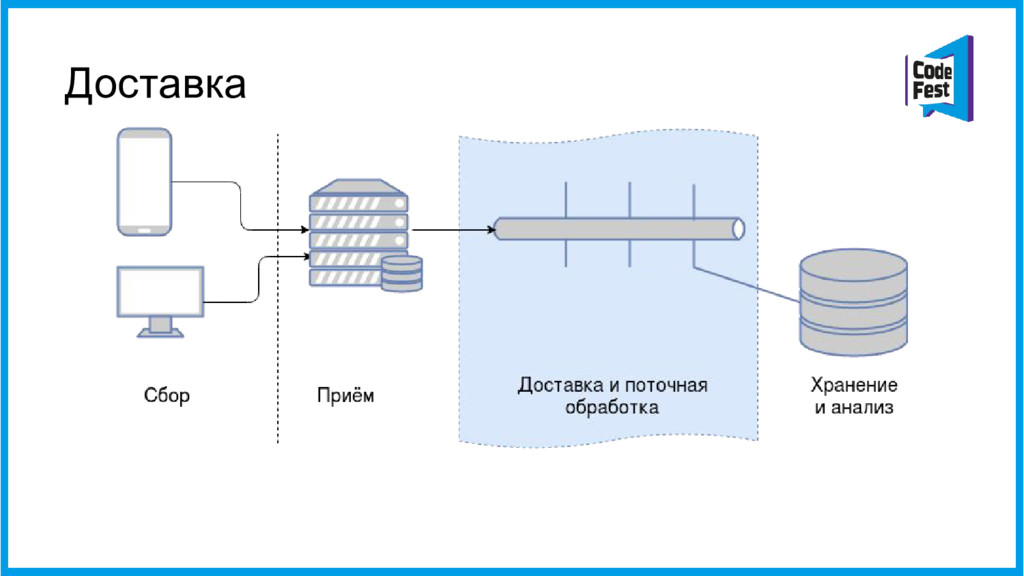{kind=link}
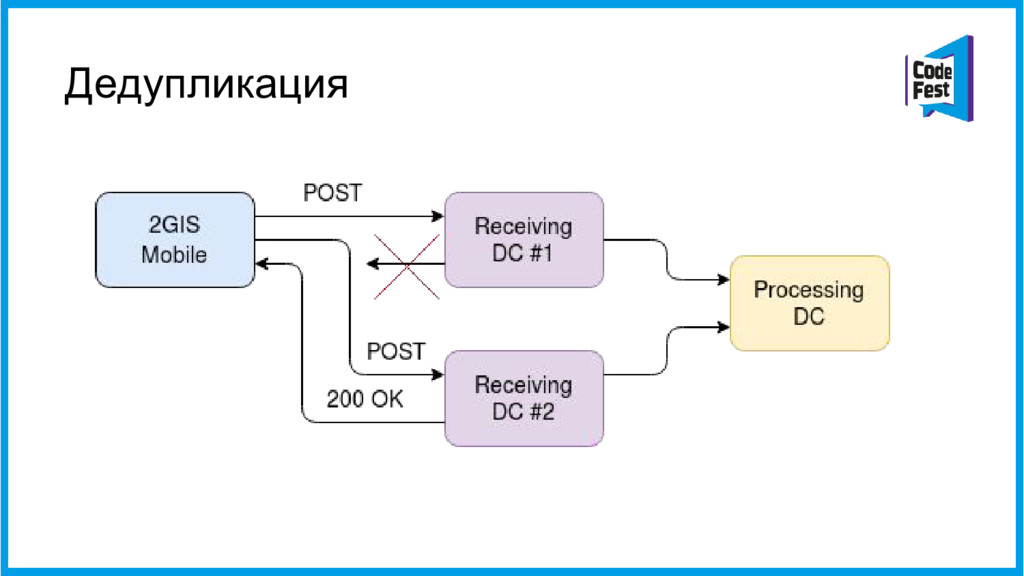{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
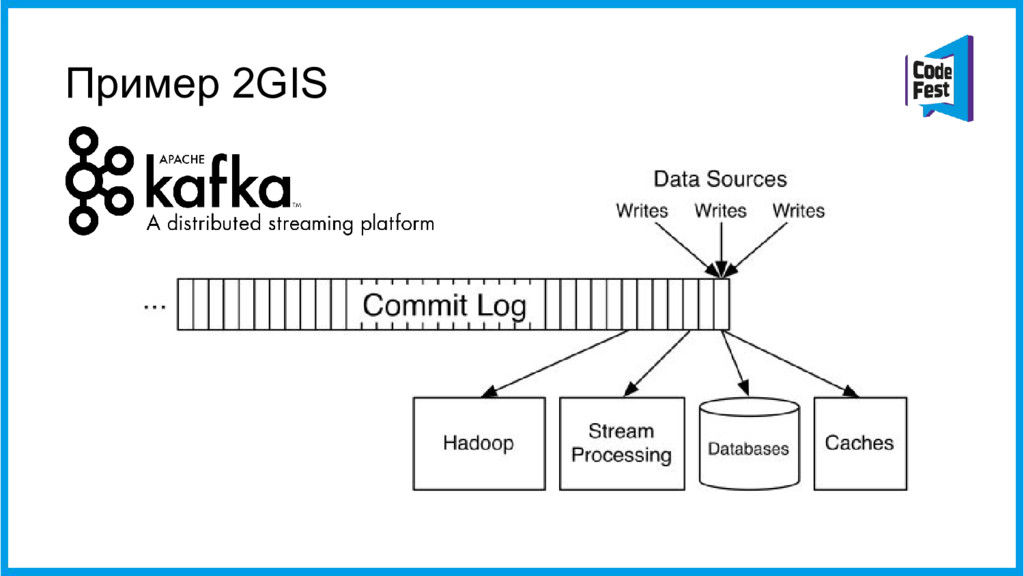{kind=link}
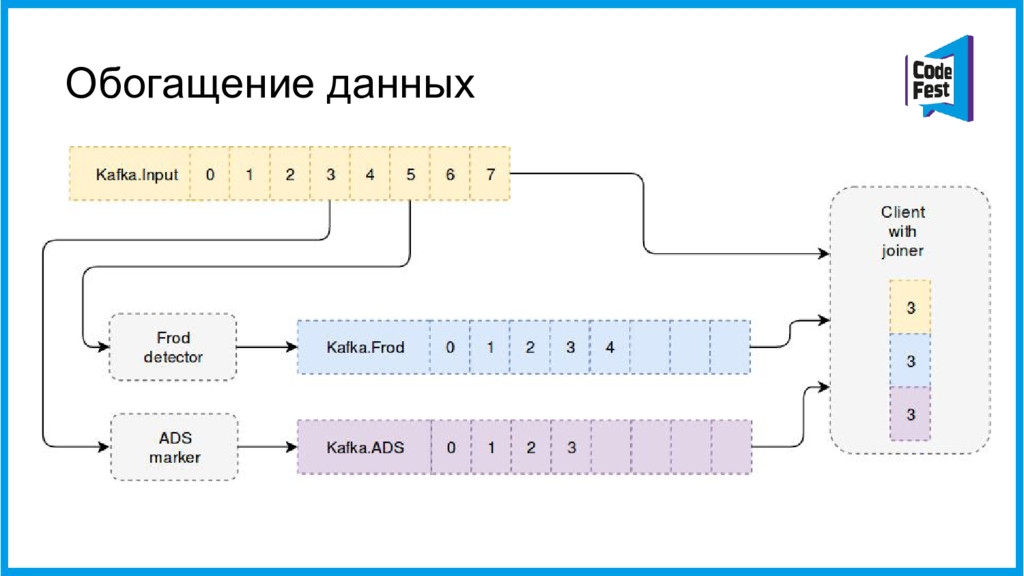{kind=link}
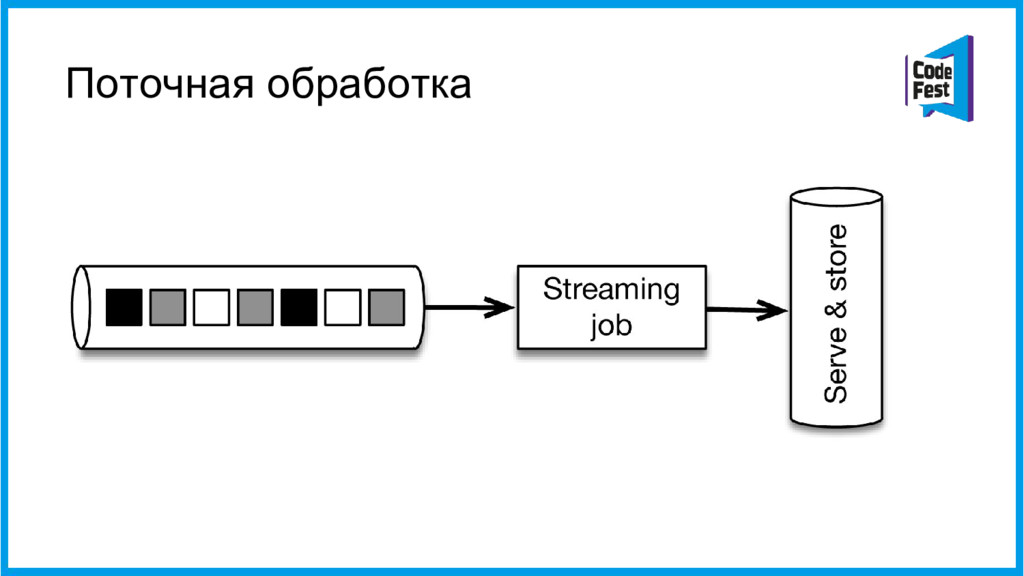{kind=link}
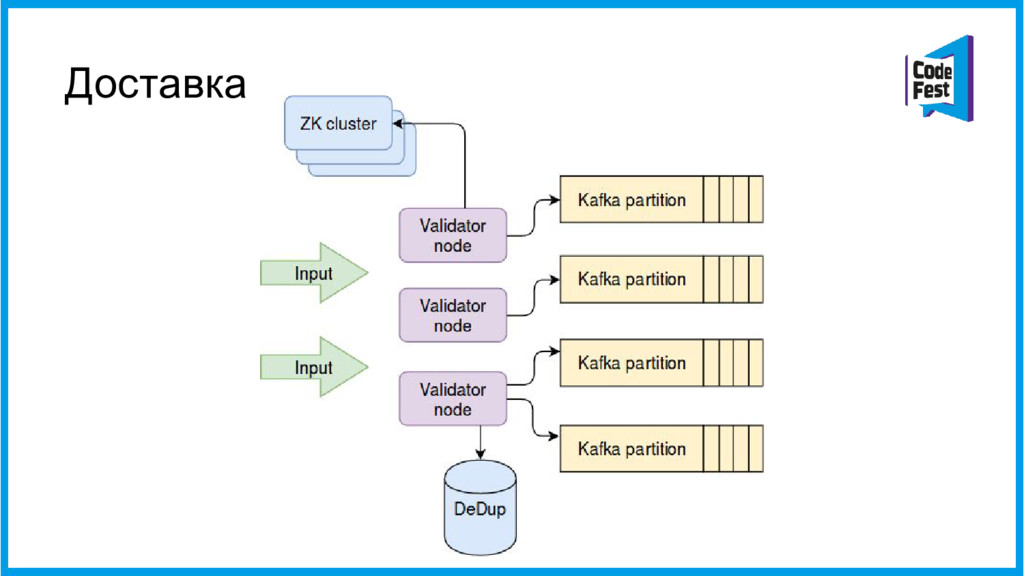{kind=link}
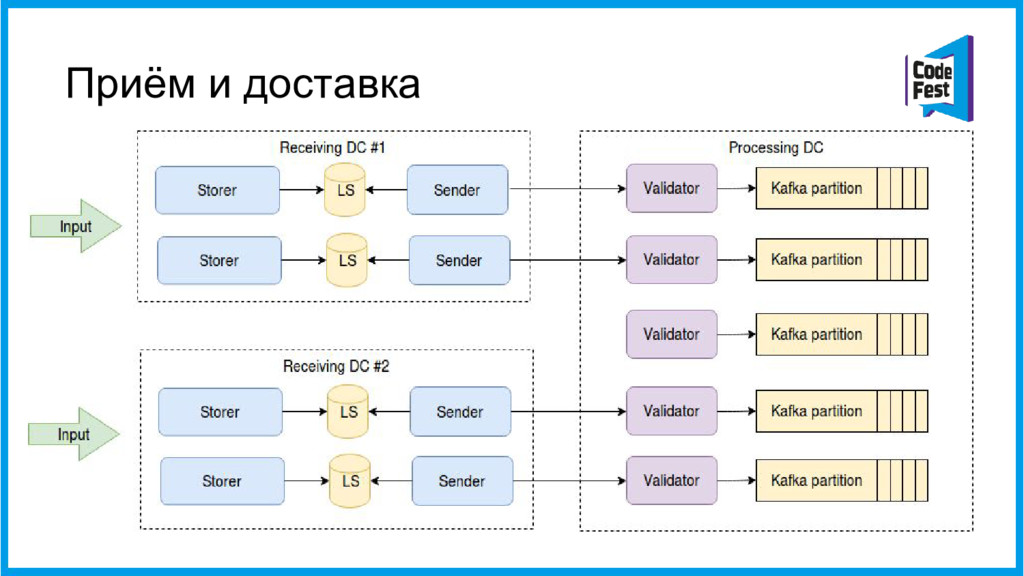{kind=link}
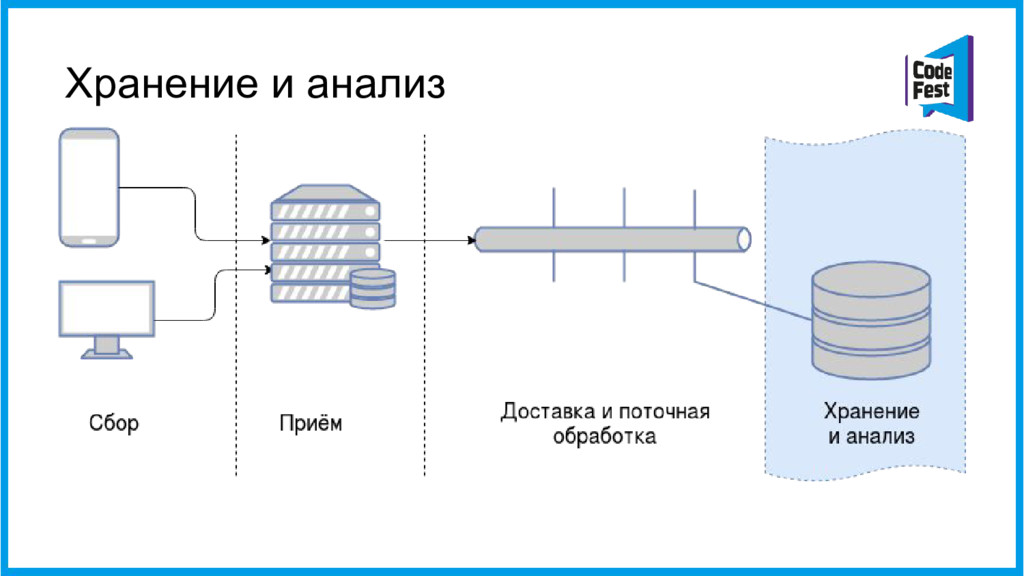{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@dronnix Вопросы? [email protected] Андрей Лузин Backend developer](https://files.speakerdeck.com/presentations/4ec6e5dc2e0c49cfa976c44b382e7d63/slide_47.jpg){kind=link}