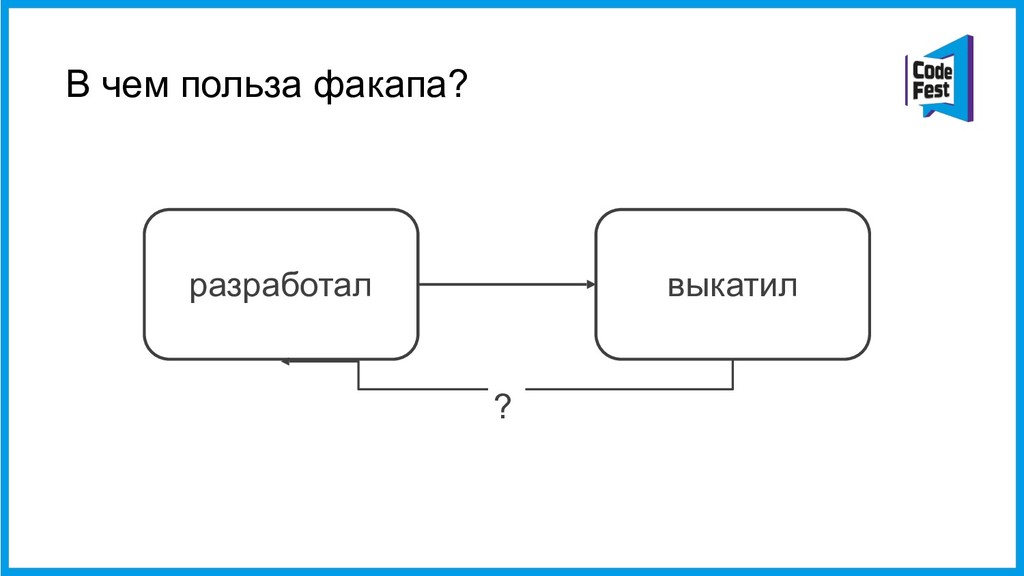
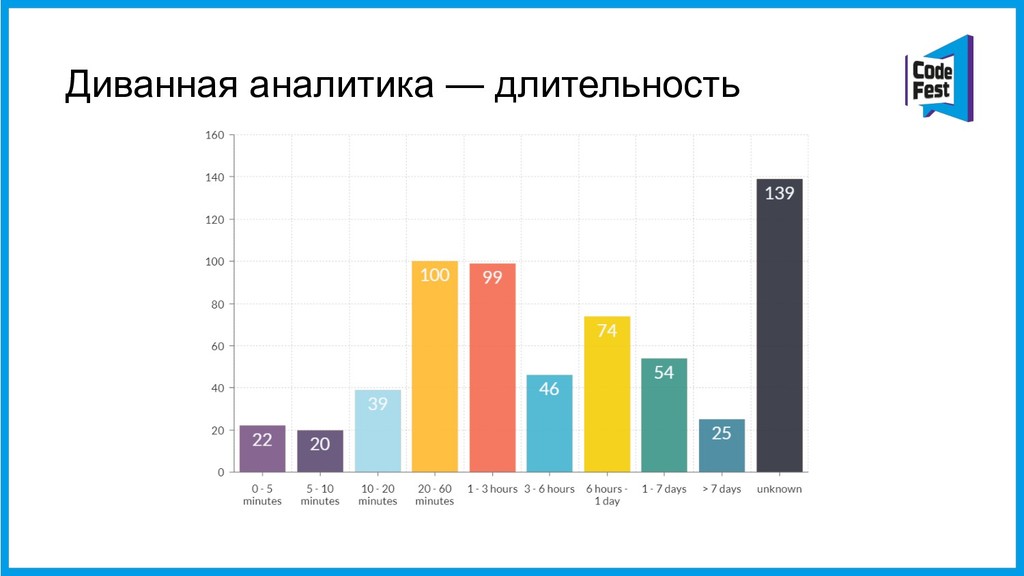
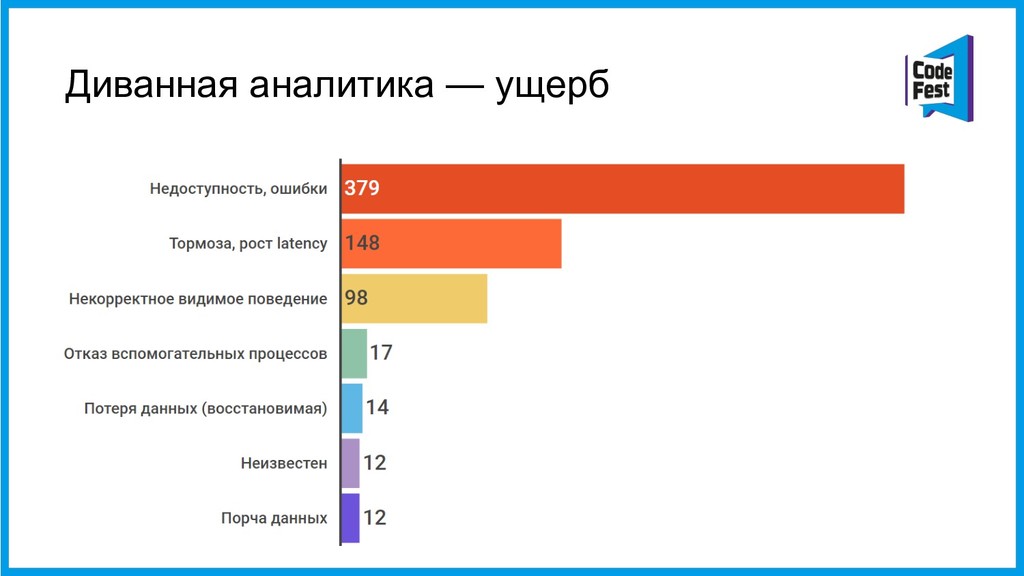
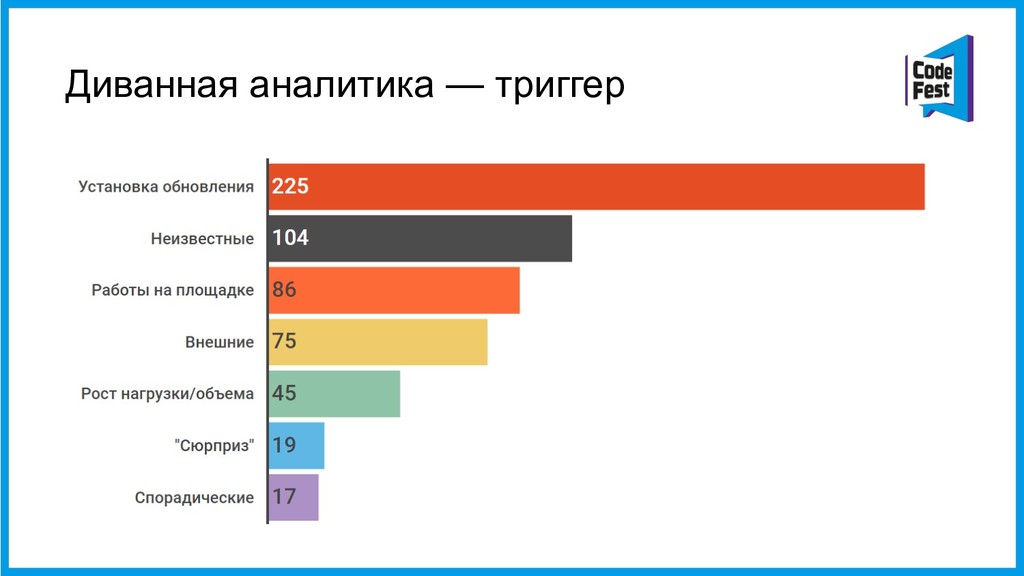
За три последних года в Контуре произошло примерно 1000 факапов разной степени эпичности. Среди них, например, 36% были вызваны выкатыванием некачественного релиза в продакшен, а 14% — работами по обслуживанию железа в дата-центре.
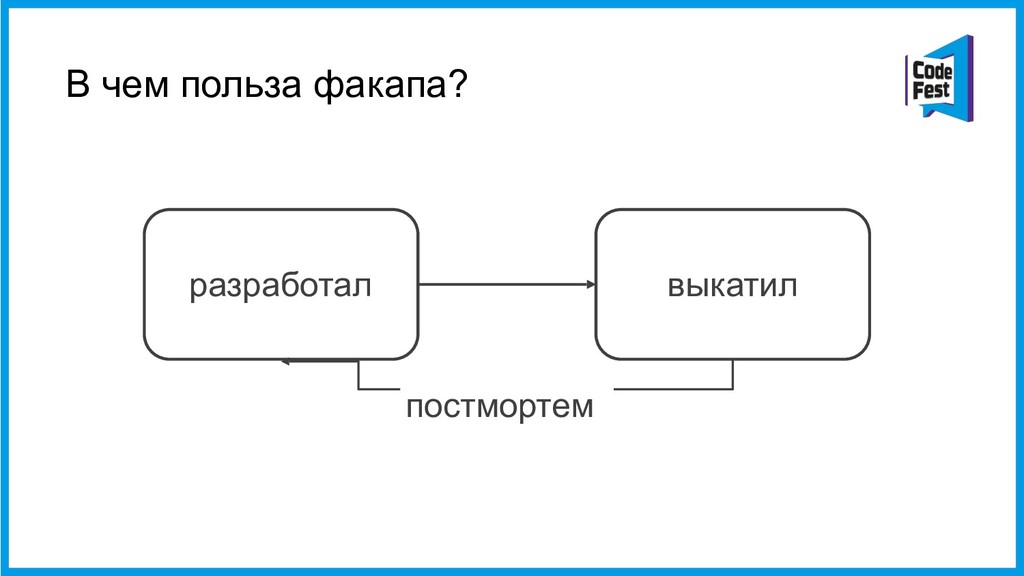
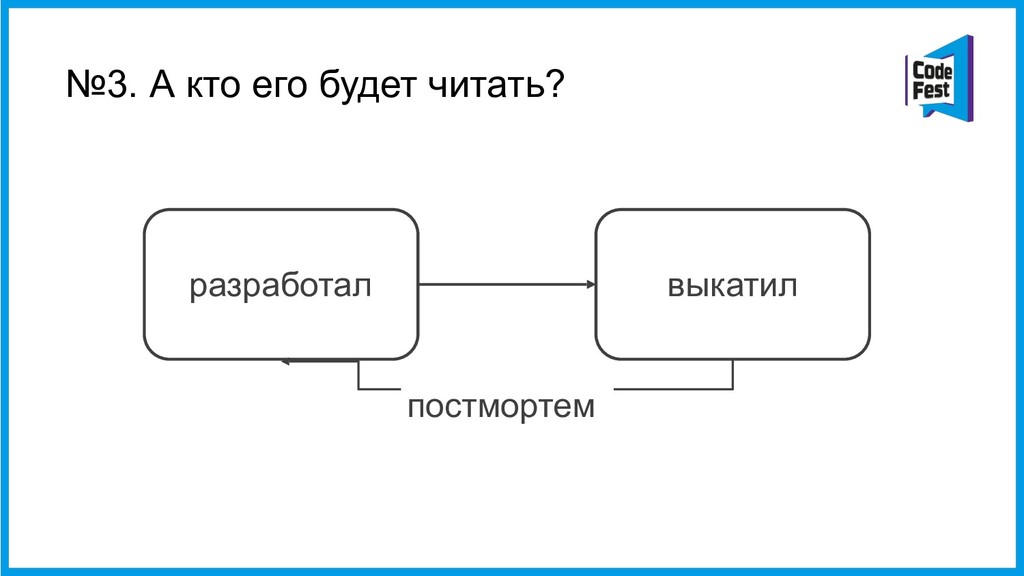
Откуда я все это знаю? Из архива отчетов, которые мы называем постмортемами. Постмортемы пишут дежурные инженеры, которые отреагировали на уведомление об аварии и первыми начали разбираться в её причинах.
Зачем нашей команде этот архив? Зачем мы заставляем инженера, который несколько часов без сна чинил сложную систему, ещё и написать несколько страниц текста об этом? Эти знания помогают нам двигать инфраструктурную разработку в правильном направлении. Чем нужно заняться прямо сейчас — улучшать систему сбора метрик или отбирать у разработчиков админские права на серверах? От чего будет больше пользы— нового инструмента для нагрузочного тестирования или внедрения канареечного деплоя?
В докладе я расскажу о том, как написать полезный постмортем: кто должен его писать, что обязательно нужно упомянуть и как внедрять эту сложную DevOps-практику в большой компании, где еще несколько лет назад никто ни о каких постмортемах даже не слышал. Разберём пару примеров настоящих факапов — признайтесь, вы же любите слушать истории о том, как кто-то облажался :)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Алексей Кирпичников Контур Вопросы? tech.kontur.ru [email protected]](https://files.speakerdeck.com/presentations/b49fd1617e7541ce86a8b1783210e6d5/slide_82.jpg){kind=link}