https://2016.codefest.ru/lecture/1070
Мир данных непрерывно меняется — они становятся разнообразнее, все чаще встречается требования онлайн-работы с терабайтами данных и одновременной
работы большого числа сервисов. Уже сейчас основными потребителями и производителями данных являются машины, а не человек. Мы спокойно говорим
про BigData, многоядерные машины с терабайтами памяти, объединенные в кластеры и петабайтные хранилища. Мир баз данных тоже меняется, появились
сотни новых баз данных и это говорит о том, что традиционные СУБД не успевают за новыми требованиями. В тоже время, традиционные универсальные СУБД являются проверенным и надежным инструментом для работы с данными,
поэтому они также вступили в гонку за потребителя.
Мы расскажем о том, как разработчики PostgreSQL видят его будущее и что уже сейчас он может предложить архитекторам новых приложений.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![commit 8aa6e97805a79eb30ac9c36acb1126280c2ffbdfESC[m Author: Robert Haas <[email protected]> Date: Wed Mar 23](https://files.speakerdeck.com/presentations/87b930fa68a7464d930263744e52252d/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
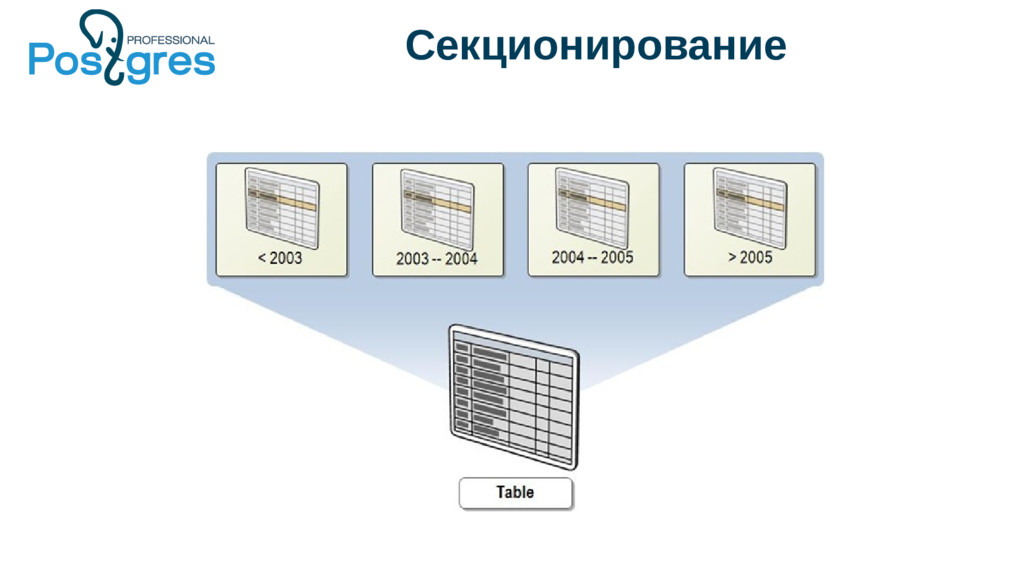{kind=link}
{kind=link}
{kind=link}
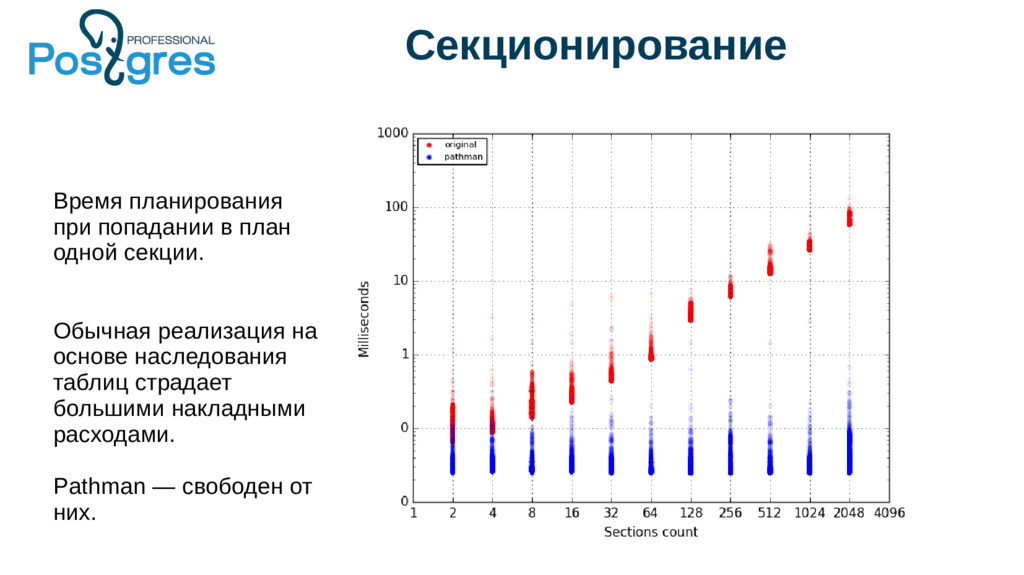{kind=link}
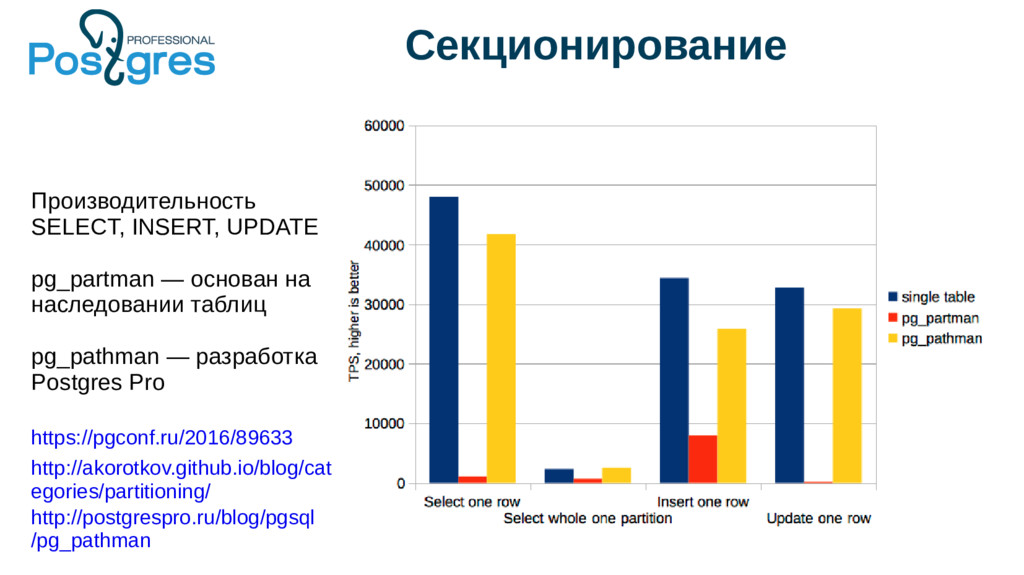{kind=link}
{kind=link}
{kind=link}
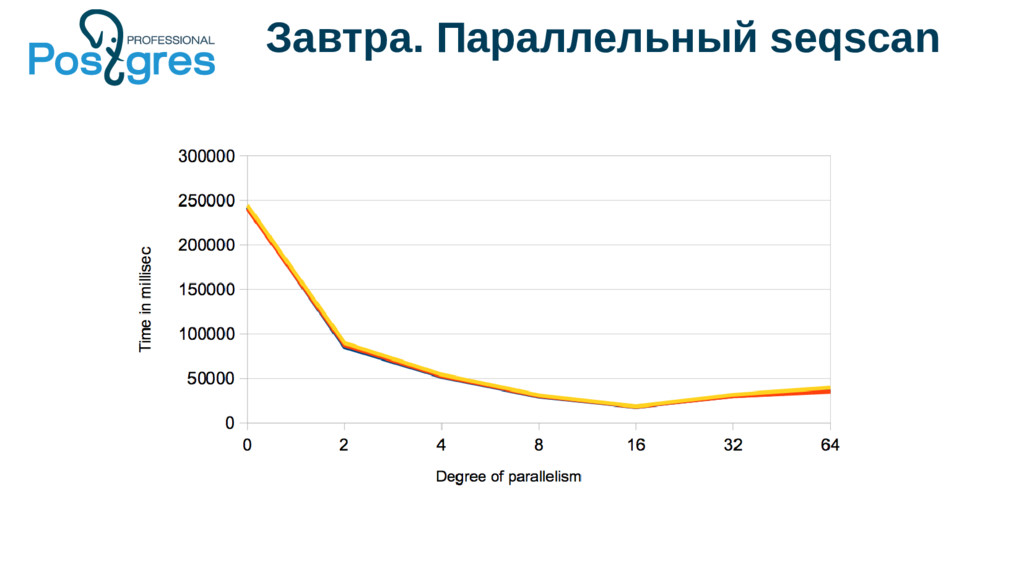{kind=link}
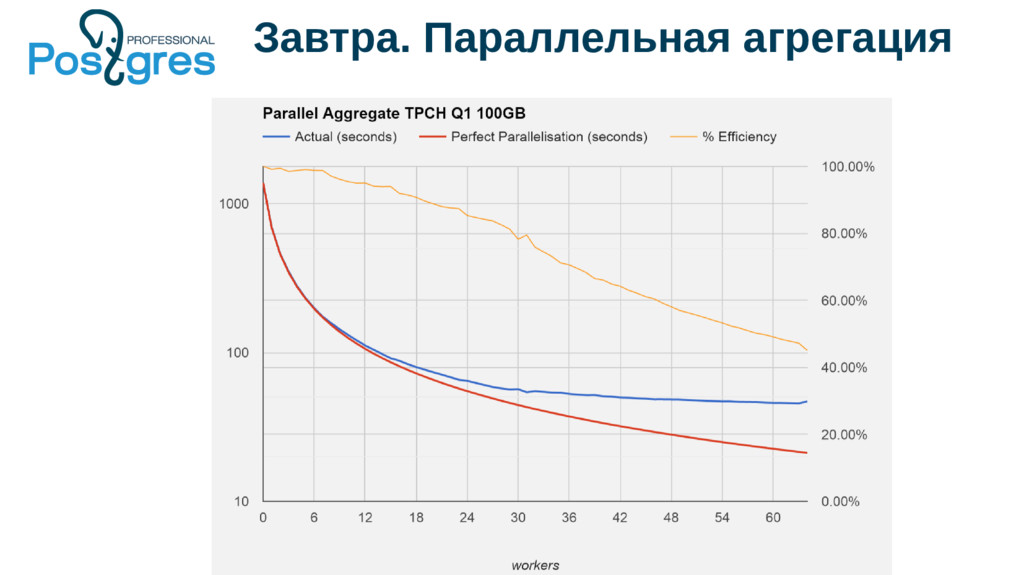{kind=link}
{kind=link}
{kind=link}
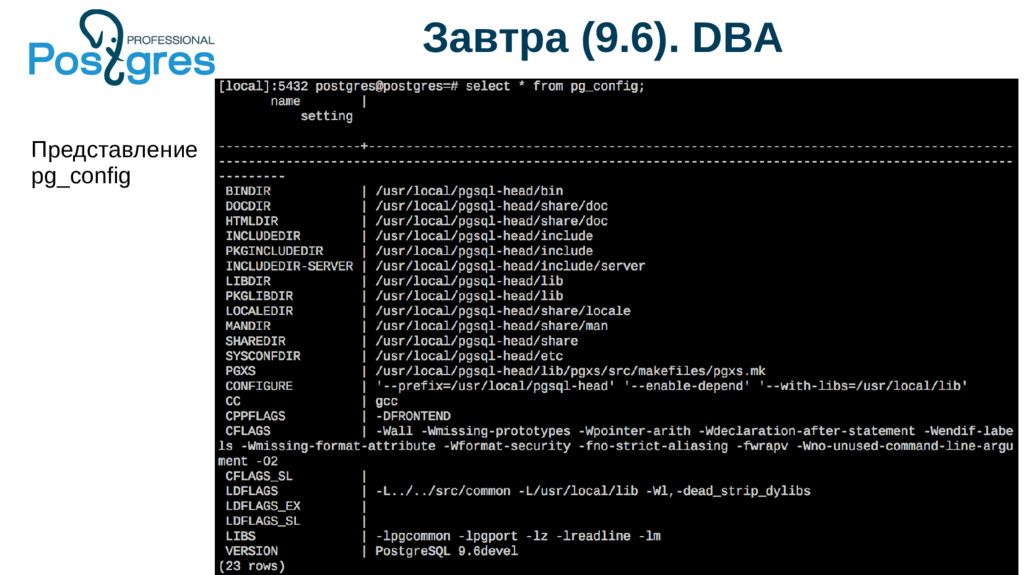{kind=link}
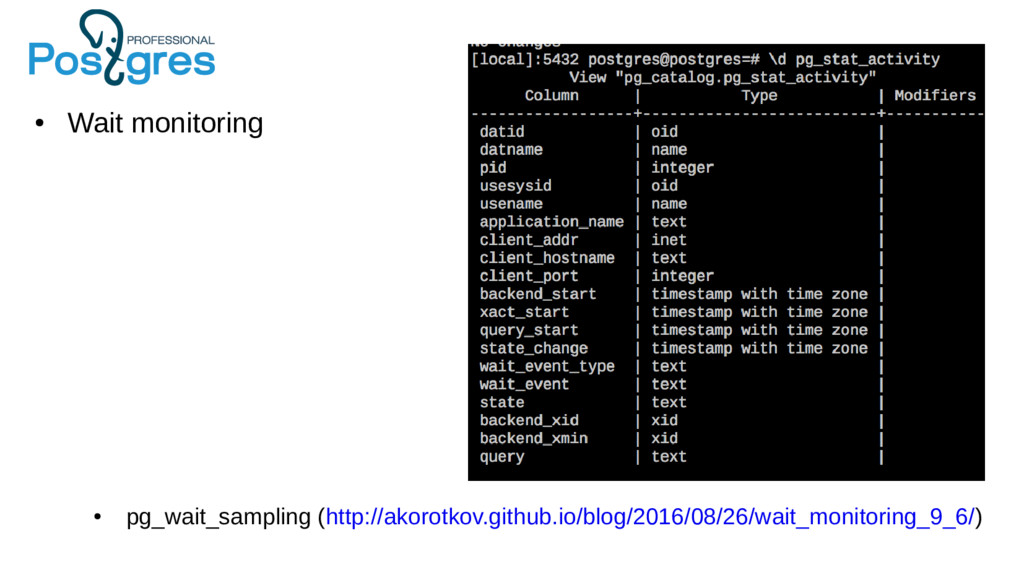{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![СПАСИБО ЗА ВНИМАНИЕ ! [email protected] [email protected] [email protected] www.postgrespro.ru](https://files.speakerdeck.com/presentations/87b930fa68a7464d930263744e52252d/slide_47.jpg){kind=link}