(2018) "On the loss landscape of a class of deep neural networks with no bad local valleys" において以下が示されている: 我々は、標準的な活性化関数とクロスエントロピー損失を用いた過剰パラメータ化され た深層ニューラルネットワークの一クラスを特定する。このクラスのネットワークは、 悪 い局所的な谷(bad local valley)を持たないことが厳密に示される。ここでいう意味 は、パラメータ空間内の任意の点から出発して、損失が単調に増加しない連続的な 経路が存在し、その経路上でクロスエントロピー損失を任意に 0に近づけることができ る、ということである。 つまり現代の NN においては、勾配に従って SGD で損失関数を減らしていけば、「悪い局 所解」にはまることなく大域局所解に到達でき る (という傾向がある) → このNNパラメータの探索空間の性質 が通常の最適化問題との最も大きな差 と言える
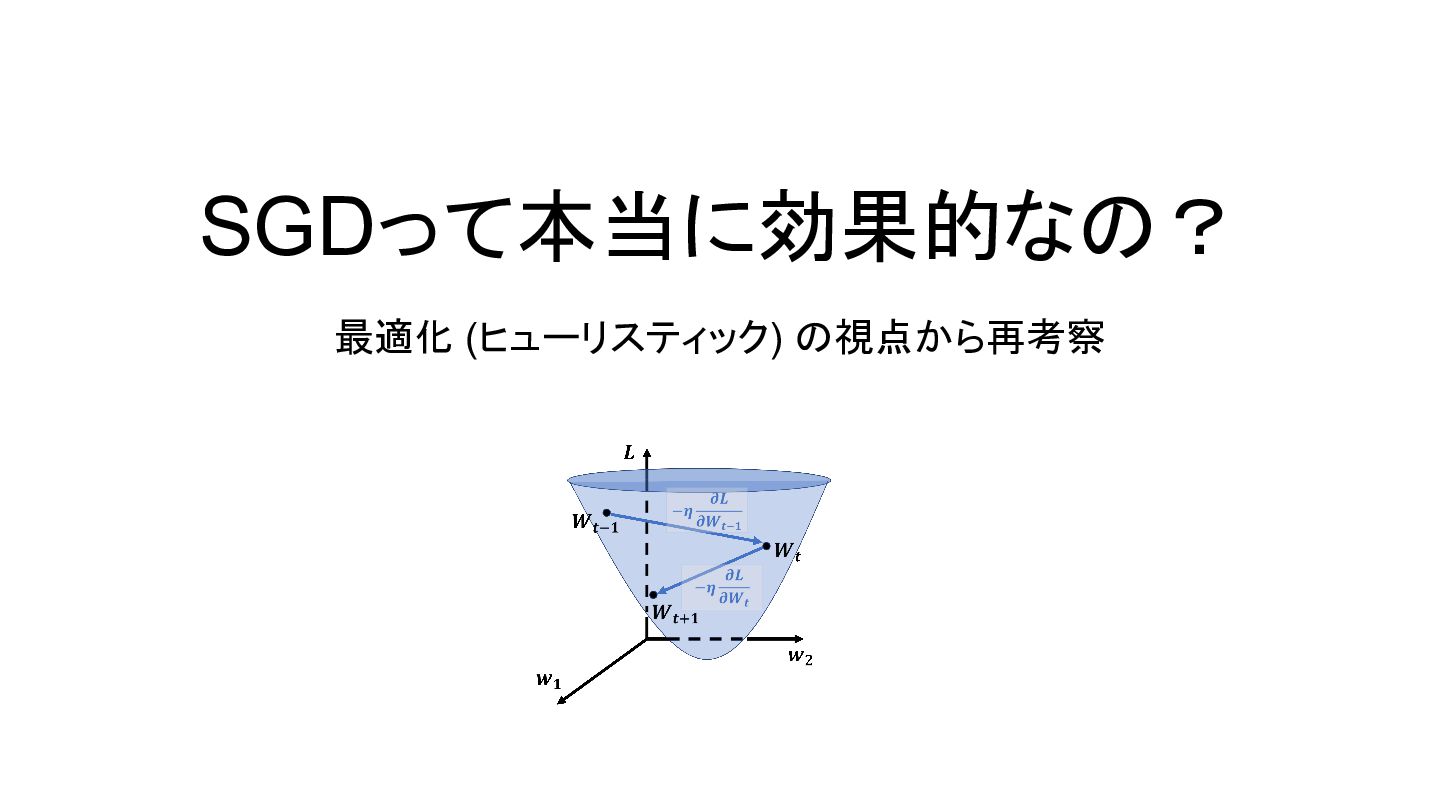{kind=link}
{kind=link}
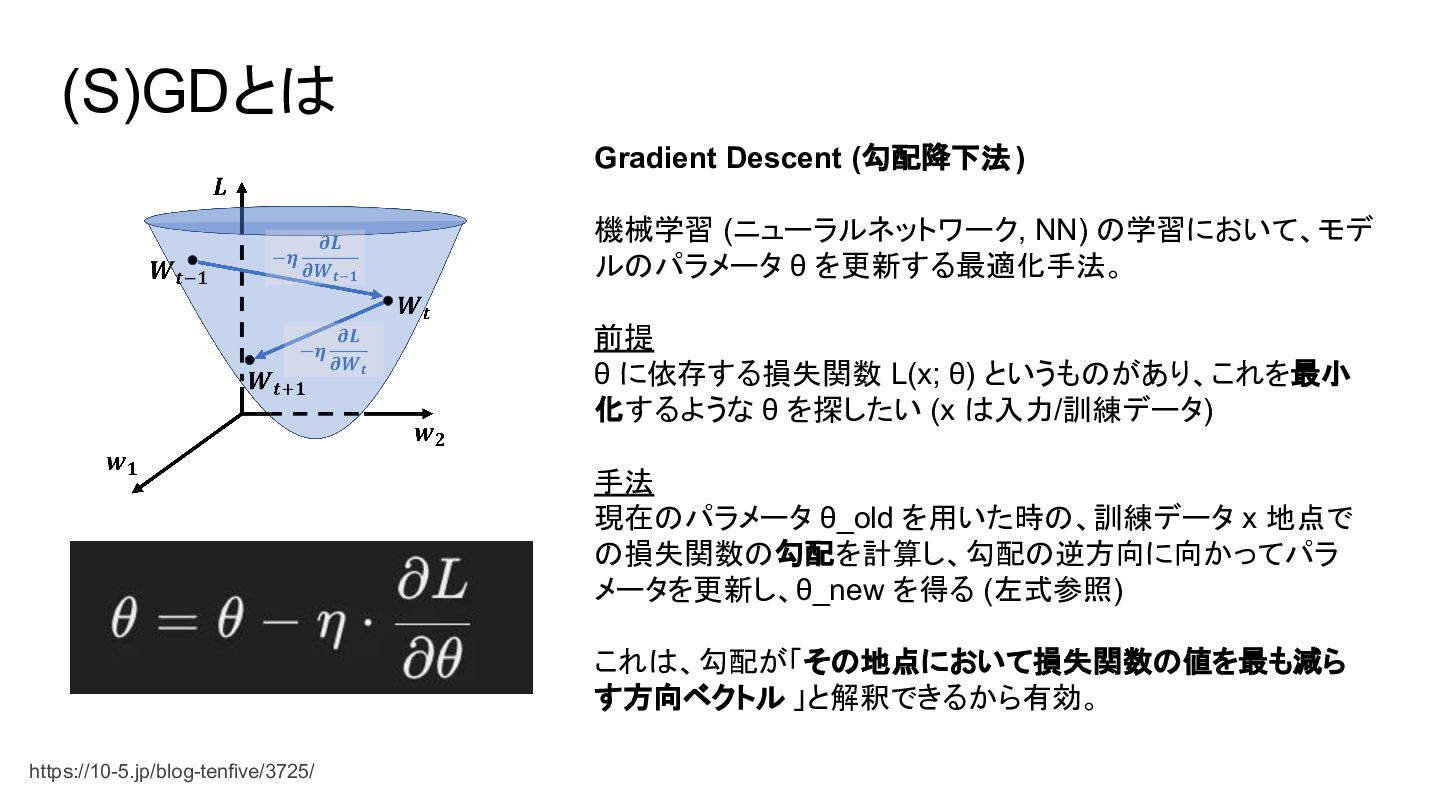{kind=link}
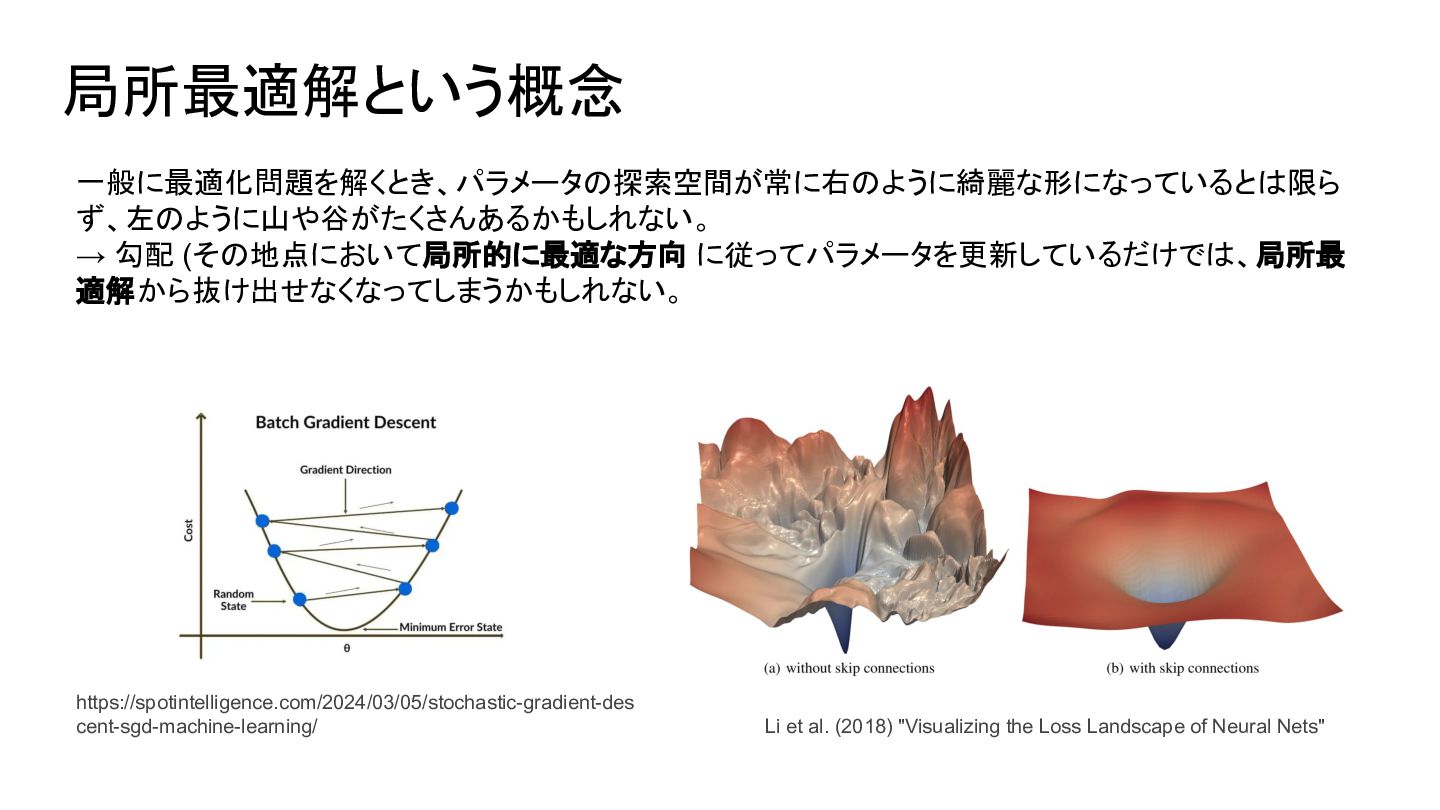{kind=link}
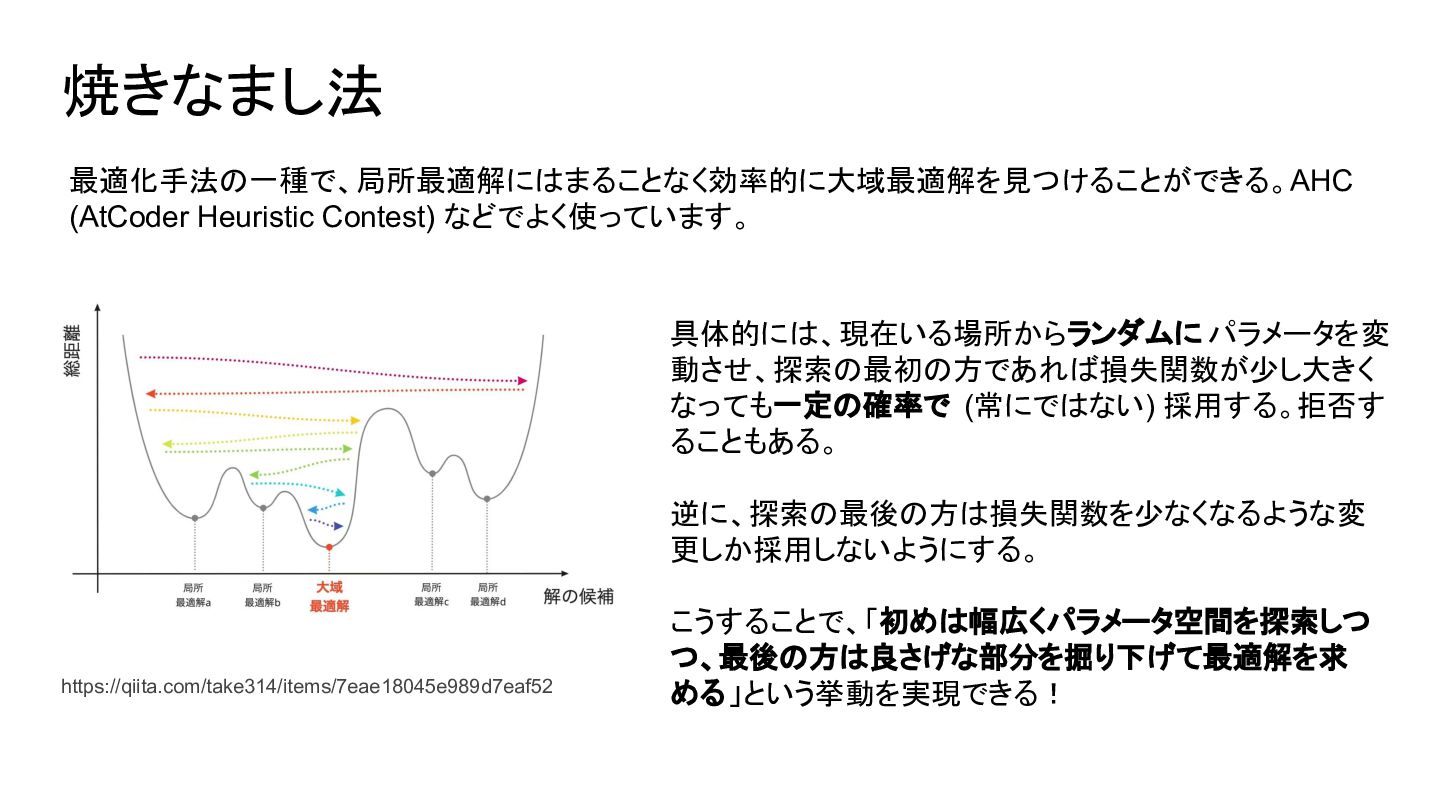{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}