section, we're going to get dirty • Systems Programming • Files, I/O, file-system • Text parsing, data decoding • Processes and IPC • Threads and concurrency • Networking 2
Python is a fantastic tool for systems programming. • Modules provide access to most of the major system libraries I used to access via C • No enforcement of "morality" • Good performance • It just "works" and it feels right. 3
and hard about how I would present this part of the class. • A reference manual approach is just going to be long and very boring. • So instead, we're going to focus on building something more in tune with the times. 4
Write some Python programs that can quietly monitor Firefox browser caches to find out who has been spending their day reading Slashdot instead of working on their TPS reports. • Oh yeah, and be a real sneaky bugger about it. 5
a real-world system and data • Firefox already installed on your machine (?) • Cross platform (Linux, Mac, Windows) • Many opportunities for tool building • Related to a variety of practical problems • A good tour of "Python in Action" 6
involved in browser forensics (or spyware for that matter). • I am in no way affiliated with Firefox/Mozilla nor have I ever seen Firefox source code • I have never worked with the cache data prior to preparing this tutorial • I have never used any third-party tools for looking at this data. 7
the code in this tutorial works with a standard Python installation • No third party modules. • All code is cross-platform • Code samples are available online at 8 http://www.dabeaz.com/lisa/ • Please look at that code and follow along
a review of systems concepts • You should be generally familiar with background material (files, filesystems, file formats, processes, threads, networking, protocols, etc.) • You can "extrapolate" from the material presented here to construct more advanced Python applications. 9
system and environment • Data processing (text and binary) • File encoding/decoding • Interprocess communication • Networking • Concurrency • Distributed computing 10
Find the Firefox cache Write a program findcache.py that takes a directory name as input and recursively scans that directory and all subdirectories looking for Firefox/Mozilla cache directories. 12 • Example: % python findcache.py /Users/beazley /Users/beazley/Library/.../qs1ab616.default/Cache /Users/beazley/Library/.../wxuoyiuf.slt/Cache % • Use case: Searching on the filesystem.
scan a directory looking for # Firefox/Mozilla cache directories import sys import os if len(sys.argv) != 2: print >>sys.stderr,"Usage: python findcache.py dirname" raise SystemExit(1) caches = (path for path,dirs,files in os.walk(sys.argv[1]) if '_CACHE_MAP_' in files) for name in caches: print name 13
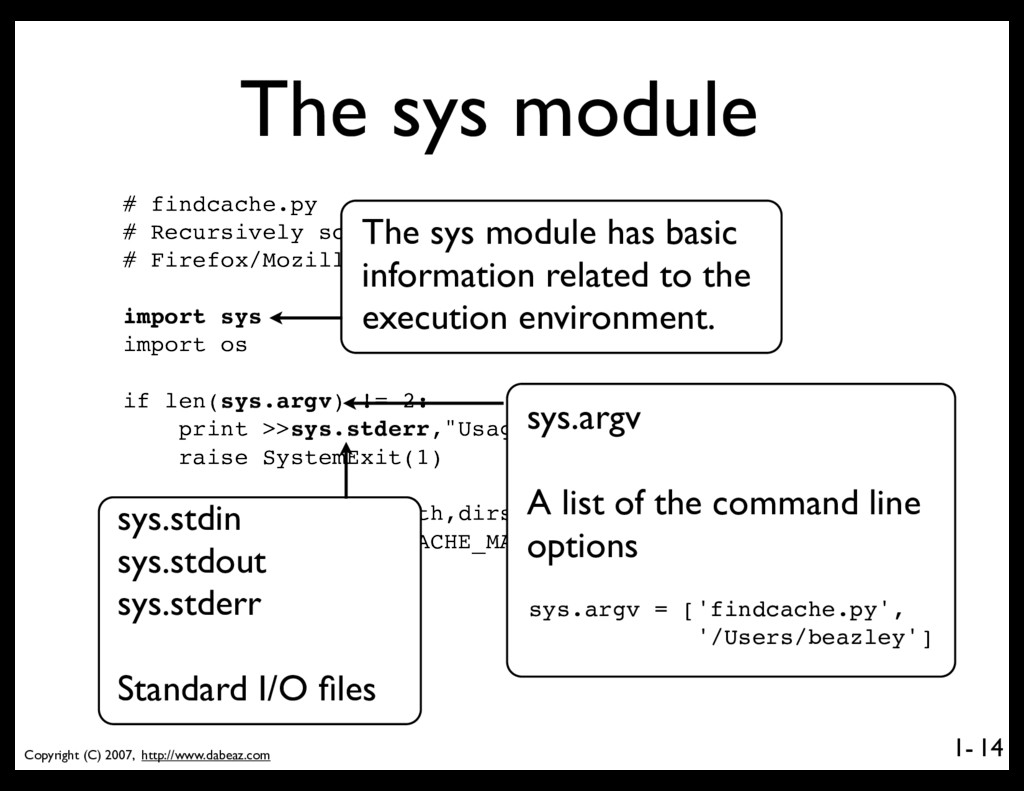
# Recursively scan a directory looking for # Firefox/Mozilla cache directories import sys import os if len(sys.argv) != 2: print >>sys.stderr,"Usage: python findcache.py dirname" raise SystemExit(1) caches = (path for path,dirs,files in os.walk(sys.argv[1]) if '_CACHE_MAP_' in files) for name in caches: print name 14 The sys module has basic information related to the execution environment. sys.argv A list of the command line options sys.stdin sys.stdout sys.stderr Standard I/O files sys.argv = ['findcache.py', '/Users/beazley']
Recursively scan a directory looking for # Firefox/Mozilla cache directories import sys import os if len(sys.argv) != 2: print >>sys.stderr,"Usage: python findcache.py dirname" raise SystemExit(1) caches = (path for path,dirs,files in os.walk(sys.argv[1]) if '_CACHE_MAP_' in files) for name in caches: print name 15 SystemExit exception Forces Python to exit. Value is return code.
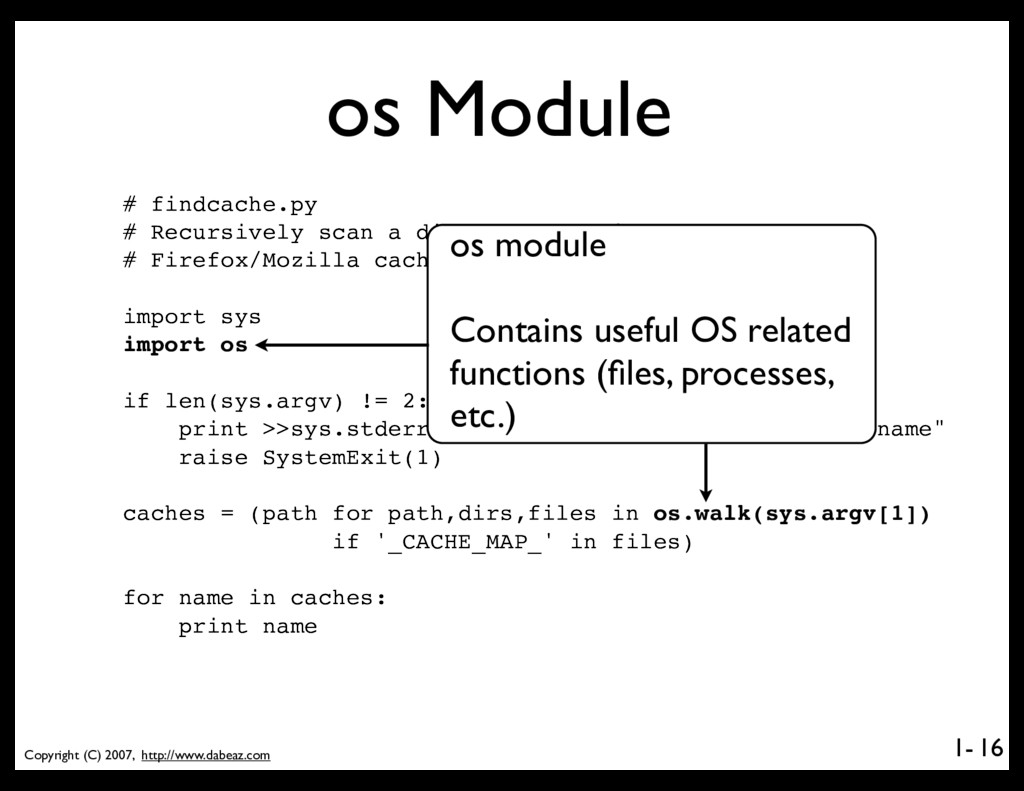
Recursively scan a directory looking for # Firefox/Mozilla cache directories import sys import os if len(sys.argv) != 2: print >>sys.stderr,"Usage: python findcache.py dirname" raise SystemExit(1) caches = (path for path,dirs,files in os.walk(sys.argv[1]) if '_CACHE_MAP_' in files) for name in caches: print name 16 os module Contains useful OS related functions (files, processes, etc.)
scan a directory looking for # Firefox/Mozilla cache directories import sys import os if len(sys.argv) != 2: print >>sys.stderr,"Usage: python findcache.py dirname" raise SystemExit(1) caches = (path for path,dirs,files in os.walk(sys.argv[1]) if '_CACHE_MAP_' in files) for name in caches: print name 17 os.walk(topdir) Recursively walks a directory tree and generates a sequence of tuples (path,dirs,files) path = The current directory name dirs = List of all subdirectory names in path files = List of all regular files (data) in path
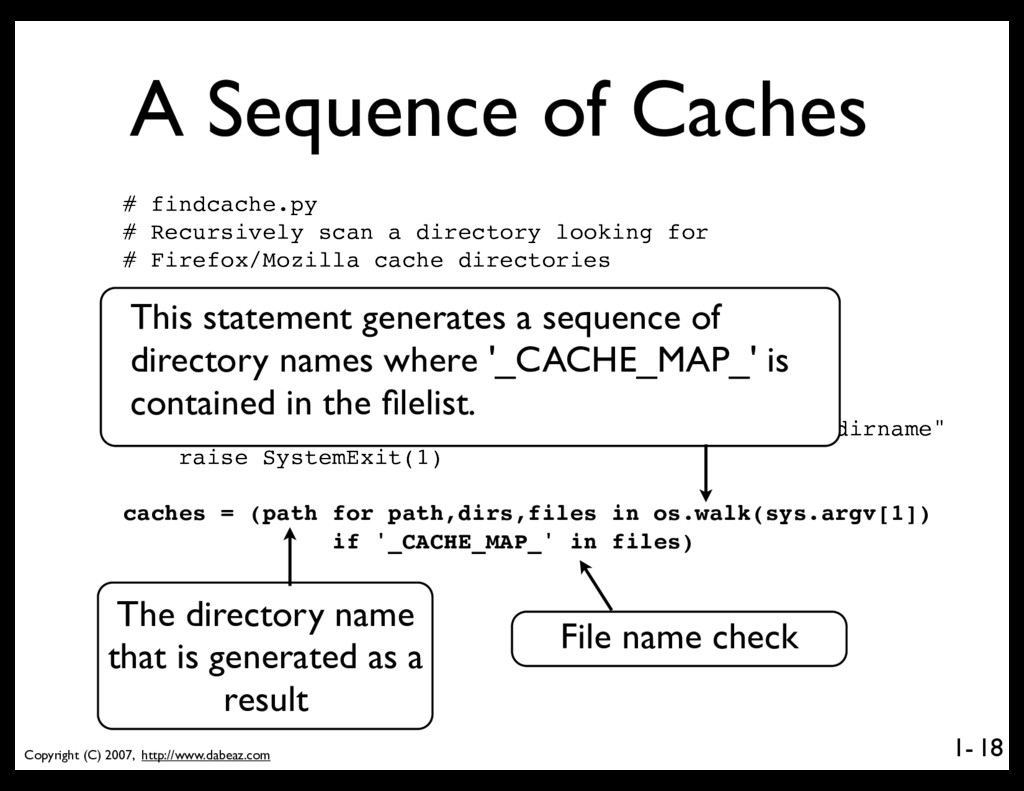
findcache.py # Recursively scan a directory looking for # Firefox/Mozilla cache directories import sys import os if len(sys.argv) != 2: print >>sys.stderr,"Usage: python findcache.py dirname" raise SystemExit(1) caches = (path for path,dirs,files in os.walk(sys.argv[1]) if '_CACHE_MAP_' in files) for name in caches: print name 18 This statement generates a sequence of directory names where '_CACHE_MAP_' is contained in the filelist. The directory name that is generated as a result File name check
# Recursively scan a directory looking for # Firefox/Mozilla cache directories import sys import os if len(sys.argv) != 2: print >>sys.stderr,"Usage: python findcache.py dirname" raise SystemExit(1) caches = (path for path,dirs,files in os.walk(sys.argv[1]) if '_CACHE_MAP_' in files) for name in caches: print name 19 This prints the sequence of cache directories that are generated. Note: Output produced immediately as caches are found.
strongly based on a "declarative" programming style (again) • We simply write out a sequence of operations that produce what we want • Not focused on the underlying mechanics of how to traverse all of the directories. 20
sys.argv # List of command line options sys.stdin # Standard input sys.stdout # Standard output sys.stderr # Standard error sys.executable # Full path of Python executable sys.exc_info() # Information on current exception • os module os.walk(dir) # Recursively walk dir producing a # sequence of tuples (path,dlist,flist) os.listdir(dir) # Return a list of all files in dir • SystemExit exception raise SystemExit(n) # Exit with integer code n
a command-line tool 23 python [opts] cacheinfo.py dir1 dir2 ... dirn Recursively searches the directories dir1, ... dirn for Firefox browser caches and prints out information. Options: -s Print total size of directory contents -t Print last modification time -sortby=[size|time] Sort results by size or time • Use case : Development of command-line oriented tools and utilities.
import optparse p = optparse.OptionParser() p.add_option('-s',action="store_true",dest="size", help="Show total size of each directory") p.add_option('-t',action="store_true",dest="time", help="Show last modification date") p.add_option('--sortby',action="store",dest="sortby", type="choice",choices=["size","time"], help="Sort by 'time' or 'date'") opt,args = p.parse_args() 24
optparse p = optparse.OptionParser() p.add_option('-s',action="store_true",dest="size", help="Show total size of each directory") p.add_option('-t',action="store_true",dest="time", help="Show last modification date") p.add_option('--sortby',action="store",dest="sortby", type="choice",choices=["size","time"], help="Sort by 'time' or 'date'") opt,args = p.parse_args() 25 optparse. A module for parsing Unix-style command line options. A problem that sounds simple, but which is not in practice. Rule of thumb: Python comes with modules that deal with common programming problems.
optparse p = optparse.OptionParser() p.add_option('-s',action="store_true",dest="size", help="Show total size of each directory") p.add_option('-t',action="store_true",dest="time", help="Show last modification date") p.add_option('--sortby',action="store",dest="sortby", type="choice",choices=["size","time"], help="Sort by 'time' or 'date'") opt,args = p.parse_args() 26 Create an OptionParser object and configure it with the available options.
-f /Users Usage: cacheinfo.py [options] cacheinfo.py: error: no such option: -f % python cacheinfo.py -s --sortby=owner /Users Usage: cacheinfo.py [options] cacheinfo.py: error: option --sortby: invalid choice: 'owner' (choose from 'size', 'time') % python cacheinfo.py -h Usage: cacheinfo.py [options] Options: -h, --help show this help message and exit -s Show total size of each directory -t Show last modification date --sortby=SORTBY Sort by 'time' or 'date' 28
... opt,args = p.parse_args() import os cacheinfo = [] for dirname in args: for path, dirs, files in os.walk(dirname): if '_CACHE_MAP_' in files: fnames = [os.path.join(path,name) for name in files] size = sum(os.path.getsize(name) for name in fnames) mtime = max(os.path.getmtime(name) for name in fnames) cacheinfo.append((path,size,mtime)) 29
... opt,args = p.parse_args() import os cacheinfo = [] for dirname in args: for path, dirs, files in os.walk(dirname): if '_CACHE_MAP_' in files: fnames = [os.path.join(path,name) for name in files] size = sum(os.path.getsize(name) for name in fnames) mtime = max(os.path.getmtime(name) for name in fnames) cacheinfo.append((path,size,mtime)) 30 General idea: • Walk over a sequence of directories as before. • For each cache directory, get total size of all files and the most recent modification date • Store the information in a list of tuples cacheinfo = [ (dirname, bytes, mtime), (dirname, bytes, mtime), ... ]
opt,args = p.parse_args() import os cacheinfo = [] for dirname in args: for path, dirs, files in os.walk(dirname): if '_CACHE_MAP_' in files: fnames = [os.path.join(path,name) for name in files] size = sum(os.path.getsize(name) for name in fnames) mtime = max(os.path.getmtime(name) for name in fnames) cacheinfo.append((path,size,mtime)) 31 os.path has portable file related functions os.path.join(name1,name2,...) # Join path names os.path.getsize(filename) # Get the file size os.path.getmtime(filename) # Get modification date There are many more functions, but this is the preferred module for basic filename handling
= p.parse_args() import os cacheinfo = [] for dirname in args: for path, dirs, files in os.walk(dirname): if '_CACHE_MAP_' in files: fnames = [os.path.join(path,name) for name in files] size = sum(os.path.getsize(name) for name in fnames) mtime = max(os.path.getmtime(name) for name in fnames) cacheinfo.append((path,size,mtime)) 32 Creates a fully-expanded pathname path = '/foo/bar' files = ['file1','file2',...] fnames = ['/foo/bar/file1','/foo/bar/file2',...] [os.path.join(path,name) for name in files] Note: Use of os.path solves cross-platform issues related to pathnames ('/' vs. '\')
opt,args = p.parse_args() import os cacheinfo = [] for dirname in args: for path, dirs, files in os.walk(dirname): if '_CACHE_MAP_' in files: fnames = [os.path.join(path,name) for name in files] size = sum(os.path.getsize(name) for name in fnames) mtime = max(os.path.getmtime(name) for name in fnames) cacheinfo.append((path,size,mtime)) 33 Performing reductions across the list of filenames fnames = ['/foo/bar/file1','/foo/bar/file2',...] size = sum([os.path.getsize('/foo/bar/file1'), os.path.getsize('/foo/bar/file2'), ...]) The argument looks funny, but it's really just generating a sequence of values as input.
opt,args = p.parse_args() import os cacheinfo = [] for dirname in args: for path, dirs, files in os.walk(dirname): if '_CACHE_MAP_' in files: fnames = [os.path.join(path,name) for name in files] size = sum(os.path.getsize(name) for name in fnames) mtime = max(os.path.getmtime(name) for name in fnames) cacheinfo.append((path,size,mtime)) 34 Collecting data as a list of tuples: cacheinfo = [ (dirname, bytes, mtime), (dirname, bytes, mtime), ... ]
use of declarative style to collect data. 35 size = sum(os.path.getsize(name) for name in fnames) • Compare to this: size = 0 for name in fnames: total += os.path.getsize(name) • The choice of programming style is mostly a matter of personal preference • I personally tend to prefer the first approach
cacheinfo = [] ... if opt.sortby == 'size': cacheinfo.sort(key=lambda x: x[1]) elif opt.sortby == 'time': cacheinfo.sort(key=lambda x: x[2]) import time for path, size, mtime in cacheinfo: if opt.size: print size, if opt.time: tm = time.localtime(mtime) print time.strftime("%m/%d/%Y %H:%M",tm), print path 37 Here we are sorting based on an optional command line option (--sortby=[size|time]). .sort() sorts a list "in place."
# cacheinfo.py ... cacheinfo = [] ... if opt.sortby == 'size': cacheinfo.sort(key=lambda x: x[1]) elif opt.sortby == 'time': cacheinfo.sort(key=lambda x: x[2]) import time for path, size, mtime in cacheinfo: if opt.size: print size, if opt.time: tm = time.localtime(mtime) print time.strftime("%m/%d/%Y %H:%M",tm), print path 38 Supplies a function that will be used to supply the keys used when comparing elements in the sort. lambda Creates a function from a single expression. .sort(key=lambda x: x[2]) def keyfunc(x): return x[2] .sort(key=keyfunc)
... cacheinfo = [] ... if opt.sortby == 'size': cacheinfo.sort(key=lambda x: x[1]) elif opt.sortby == 'time': cacheinfo.sort(key=lambda x: x[2]) import time for path, size, mtime in cacheinfo: if opt.size: print size, if opt.time: tm = time.localtime(mtime) print time.strftime("%m/%d/%Y %H:%M",tm), print path 39 lambda is used to create small anonymous functions. Almost always reserved for simple callbacks. def add(x,y): return x+y add = lambda x,y : x+y These statements are equivalent lambda is used sparingly
cacheinfo = [] ... if opt.sortby == 'size': cacheinfo.sort(key=lambda x: x[1]) elif opt.sortby == 'time': cacheinfo.sort(key=lambda x: x[2]) import time for path, size, mtime in cacheinfo: if opt.size: print size, if opt.time: tm = time.localtime(mtime) print time.strftime("%m/%d/%Y %H:%M",tm), print path 42 time module Contains functions related to system time values (e.g., seconds since 1970). time.localtime(s) # Make time structure time.time() # Get current time time.strftime(tm) # Time string format time.clock() # CPU clock time.sleep(s) # Sleep for s seconds ...
os.path.join(s1,s2,...) # Join pathname parts together os.path.getsize(path) # Get file size of path os.path.getmtime(path) # Get modify time of path os.path.getatime(path) # Get access time of path os.path.getctime(path) # Get creation time of path os.path.exists(path) # Check if path exists os.path.isfile(path) # Check if regular file os.path.isdir(path) # Check if directory os.path.islink(path) # Check if symbolic link os.path.basename(path) # Return file part of path os.path.dirname(path) # Return dir part of os.path.abspath(path) # Get absolute path • time module time.time() # Current time (seconds) time.localtime([s]) # Turn seconds into a structure # of different parts (hour,min,etc.) time.ctime([s]) # Time as an string time.strftime(fmt,tm) # Time string formatting
far, we have been exploring some of the basic machinery for building tools • Program environment (sys module) • Filesystem (os, os.path module) • Command line processing (optparse) • A lot of this would provide the basic framework for more advanced applications 44
Extract all requests in the cache Write a program cachecontents.py that scans the contents of the _CACHE_00n_ files and prints a list of URLs for documents stored in the cache. 45 • Example: % python cachecontents.py /Users/.../qs1ab616.default/Cache http://www.yahoo.com/ http://us.js2.yimg.com/us.yimg.com/a/1-/java/promotions/js/ad_eo_1 http://us.i1.yimg.com/us.yimg.com/i/ww/atty_hsi_free.gif http://us.i1.yimg.com/us.yimg.com/i/ww/thm/1/search_1.1.png ... % • Use case: Searching files for text or specific data patterns
cache directory holds two types of data • Metadata (URLs, headers, etc.). • Raw data (HTML, JPEG, PNG, etc.) • This data is stored in two places • Cryptic files in the Cache directory • Blocks inside the _CACHE_00n_ files 46
The _CACHE_00n_ files are encoded in a binary format, but URLs are embedded inside: 47 \x00\x01\x00\x08\x92\x00\x02\x18\x00\x00\x00\x13F\xff\x9f \xceF\xff\x9f\xce\x00\x00\x00\x00\x00\x00H)\x00\x00\x00\x1a \x00\x00\x023HTTP:http://slashdot.org/\x00request-method\x00 GET\x00request-User-Agent\x00Mozilla/5.0 (Macintosh; U; Intel Mac OS X; en-US; rv:1.8.1.7) Gecko/20070914 Firefox/2.0.0.7\x00 request-Accept-Encoding\x00gzip,deflate\x00response-head\x00 HTTP/1.1 200 OK\r\nDate: Sun, 30 Sep 2007 13:07:29 GMT\r\n Server: Apache/1.3.37 (Unix) mod_perl/1.29\r\nSLASH_LOG_DATA: shtml\r\nX-Powered-By: Slash 2.005000176\r\nX-Fry: How can I live my life if I can't tell good from evil?\r\nCache-Control: • Maybe the requests could just be ripped using a regular expression.
import re import os import sys cachedir = sys.argv[1] cachefiles = [ '_CACHE_001_', '_CACHE_002_', '_CACHE_003_' ] # A regex for URL strings request_pat = re.compile('(http:|https:)//.*?\x00') # Loop over all files and search for URLs for name in cachefiles: data = open(os.path.join(cachedir,name),"rb").read() for m in request_pat.finditer(data): print m.group() 48
import re import os import sys cachedir = sys.argv[1] cachefiles = [ '_CACHE_001_', '_CACHE_002_', '_CACHE_003_' ] # A regex for URL strings request_pat = re.compile('(http:|https:)//.*?\x00') # Loop over all files and search for URLs for name in cachefiles: data = open(os.path.join(cachedir,name),"rb").read() for m in request_pat.finditer(data): print m.group() 49 re module Contains all functionality related to regular expression pattern matching, searching, replacing, etc. Features are strongly influenced by Perl, but regexs are not directly integrated into the Python language.
re import os import sys cachedir = sys.argv[1] cachefiles = [ '_CACHE_001_', '_CACHE_002_', '_CACHE_003_' ] # A regex for URL strings request_pat = re.compile('(http:|https:)//.*?\x00') # Loop over all files and search for URLs for name in cachefiles: data = open(os.path.join(cachedir,name),"rb").read() for m in request_pat.finditer(data): print m.group() 50 Patterns are first specified as strings and compiled into a regex object. pat = re.compile(pattern [,flags]) The pattern syntax is "standard" pat* pat+ pat? (pat) . pat1|pat2 [chars] [^chars] pat{n} pat{n,m}
re import os import sys cachedir = sys.argv[1] cachefiles = [ '_CACHE_001_', '_CACHE_002_', '_CACHE_003_' ] # A regex for URL strings request_pat = re.compile('(http:|https:)//.*?\x00') # Loop over all files and search for URLs for name in cachefiles: data = open(os.path.join(cachedir,name),"rb").read() for m in request_pat.finditer(data): print m.group() 51 All subsequent operations are methods of the compiled regex pattern m = pat.match(data) # Check for match m = pat.search(data) # Search for match newdata = pat.sub(data, repl) # Pattern replace allmatches = pat.findall(data) # Find all matches for m in pat.finditer(data): ... # Iterate over matches
re import os import sys cachedir = sys.argv[1] cachefiles = [ '_CACHE_001_', '_CACHE_002_', '_CACHE_003_' ] # A regex for URL strings request_pat = re.compile('(http:|https:)//.*?\x00') # Loop over all files and search for URLs for name in cachefiles: data = open(os.path.join(cachedir,name),"rb").read() for m in request_pat.finditer(data): print m.group() 52 Regex matches are represented by a MatchObject m.group([n]) # Text matched by group n m.start([n]) # Starting index of group n m.end([n]) # End index of group n prints the matched text of the entire pattern
regex approach is mostly a hack for this particular application. • Reads entire cache files into memory as strings (may be quite large) • Only finds URLs, no other metadata • Returns false positives since the cache also contains data (e.g., HTML pages which would contained embedded URL links) 53
using re 54 datepat = re.compile(r'(\d+)/(\d+)/(\d+)') m = datepat.search(data) if m: fulltext = m.group() # Text of complete match month = m.group(1) # Text of specific groups day = m.group(2) year = m.group(3) • Replacement Example def euro_date(m): month = m.group(1) day = m.group(2) year = m.group(3) return "%d/%d/%d" % (day,month,year) newdata = datepat.sub(euro_date,data)
Extract the cache data (for real) Write a module ffcache.py that contains a set of functions for reading Firefox cache data into useful data structures that can be used by other programs. Capture all available information including URLs, timestamps, sizes, locations, etc. 55 • Use case: Blood and guts Writing programs that can process foreign file formats. Processing binary encoded data. Creating code for later reuse.
are four critical files 56 _CACHE_MAP_ # Cache index _CACHE_001_ # Cache data _CACHE_002_ # Cache data _CACHE_003_ # Cache data • All files are binary-encoded • _CACHE_MAP_ is used by Firefox to locate data, but it is not updated until Firefox exits. • We will ignore _CACHE_MAP_ since I want to observe caches of live Firefox sessions.
entry: • A maximum of 4 cache blocks • Can either be data or metadata • If >16K, written to a file instead 58 • Notice how all the "cryptic" files are >16K -rw------- beazley 111169 Sep 25 17:15 01CC0844d01 -rw------- beazley 104991 Sep 25 17:15 01CC3844d01 -rw------- beazley 47233 Sep 24 16:41 021F221Ad01 ... -rw------- beazley 26749 Sep 21 11:19 FF8AEDF0d01 -rw------- beazley 58172 Sep 25 18:16 FFE628C6d01
Parsing Metadata Headers • Part 2: Getting request information • Part 3: Scanning each cache file • Part 4: Collecting cache data from an entire cache directory 60
• Write a function that can parse the metadata header and return the data in a useful format • Add some checks that can bail out if the data does not look like a valid header. 61
This function parses a cache metadata header into a dict # of named fields (listed in _headernames below) _headernames = ['magic','location','fetchcount', 'fetchtime','modifytime','expiretime', 'datasize','requestsize','infosize'] def parse_meta_header(headerdata,maxsize): head = struct.unpack(">9I",headerdata) magic = head[0] rsize = head[7] isize = head[8] if magic != 0x00010008 or (rsize + isize + 36) > maxsize: return None meta = dict(zip(_headernames,head)) return meta 62
This function parses cache metadata into a dictionary # of named fields (listed in _headernames below) _headernames = ['magic','location','fetchcount', 'fetchtime','modifytime','expiretime', 'datasize','requestsize','infosize'] def parse_meta_header(headerdata,maxsize): head = struct.unpack(">9I",headerdata) magic = head[0] rsize = head[7] isize = head[8] if magic != 0x00010008 or (rsize + isize + 36) > maxsize: return None meta = dict(zip(_headernames,head)) return meta 64 Parses binary encoded data into Python objects. You would use this module to pack/unpack raw binary data from Python strings. Sample format codes 'i' int 'I' unsigned int 'h' short 'H' unsigned short 'd' double ... '>' Big endian '<' Little endian '!' Network 'n' Repetition
This function parses a metadata header into a dict # of named fields (listed in _headernames below) _headernames = ['magic','location','fetchcount', 'fetchtime','modifytime','expiretime', 'datasize','requestsize','infosize'] def parse_meta_header(headerdata,maxsize): head = struct.unpack(">9I",headerdata) magic = head[0] rsize = head[7] isize = head[8] if magic != 0x00010008 or (rsize + isize + 36) > maxsize: return None meta = dict(zip(_headernames,head)) return meta 65 Unpacked data is a tuple A check that sees if the unpacked data looks valid head = (n,n,n,n,n,n,n,n,n)
This function parses a cache metadata header into a dict # of named fields (listed in _headernames below) _headernames = ['magic','location','fetchcount', 'fetchtime','modifytime','expiretime', 'datasize','requestsize','infosize'] def parse_meta_header(headerdata,maxsize): head = struct.unpack(">9I",headerdata) magic = head[0] rsize = head[7] isize = head[8] if magic != 0x00010008 or (rsize + isize + 36) > maxsize: return None meta = dict(zip(_headernames,head)) return meta 66 zip(s1,s2) makes a list of tuples zip(_headernames,head) [('magic',head[0]), ('location',head[1]), ('fetchcount',head[2]) ... ] Make a dictionary
• Write a function that will read the request string and request information • Request String : A Null-terminated string 68 • Request Info : A sequence of Null-terminated key-value pairs (like a dictionary)
dictionary of header information and a file, # this function extracts the request data from a cache # metadata entry and saves it in the dictionary. Returns # True or False depending on success. def read_request_data(meta,f): request = f.read(meta['requestsize']).strip('\x00') infodata = f.read(meta['infosize']).strip('\x00') # Validate request and infodata here (nothing now) # Turn the infodata into a dictionary parts = infodata.split('\x00') info = dict(zip(parts[::2],parts[1::2])) meta['request'] = request.split(':',1)[1] meta['info'] = info return True 69
header information and a file, # this function extracts the request data from a cache # metadata entry and saves it in the dictionary. Returns # True or False depending on success. def read_request_data(meta,f): request = f.read(meta['requestsize']).strip('\x00') infodata = f.read(meta['infosize']).strip('\x00') # Validate request and infodata here (nothing now) # Turn the infodata into a dictionary parts = infodata.split('\x00') info = dict(zip(parts[::2],parts[1::2])) meta['request'] = request.split(':',1)[1] meta['info'] = info return True String Stripping 71 Here, we just read the request string followed by the request info string. Both end with a NULL which we strip off.
header information and a file, # this function extracts the request data from a cache # metadata entry and saves it in the header. Returns # True or False depending on success. def read_request_data(header,f): request = f.read(header['requestsize']).strip('\x00') infodata = f.read(header['infosize']).strip('\x00') # Validate request and infodata here (nothing now) # Turn the infodata into a dictionary parts = infodata.split('\x00') info = dict(zip(parts[::2],parts[1::2])) meta['request'] = request.split(':',1)[1] meta['info'] = info return True String Splitting 72 The request info is a string of key/value pairs: infodata = 'key\x00value\x00key\x00value\x00key\x00value\' .split('\x00') parts = ['key','value','key','value','key','value']
header information and a file, # this function extracts the request data from a cache # metadata entry and saves it in the header. Returns # True or False depending on success. def read_request_data(header,f): request = f.read(header['requestsize']).strip('\x00') infodata = f.read(header['infosize']).strip('\x00') # Validate request and infodata here (nothing now) # Turn the infodata into a dictionary parts = infodata.split('\x00') info = dict(zip(parts[::2],parts[1::2])) meta['request'] = request.split(':',1)[1] meta['info'] = info return True Advanced List Slicing 73 We can slice a list with a stride parts = ['key','value','key','value','key','value'] parts[::2] ['key','key','key'] parts[1::2] ['value','value','value'] zip(parts[::2],parts[1::2]) [('key','value'), ('key','value') ('key','value')] Makes a dictionary
header information and a file, # this function extracts the request data from a cache # metadata entry and saves it in the dictionary. Returns # True or False depending on success. def read_request_data(header,f): request = f.read(header['requestsize']).strip('\x00') infodata = f.read(header['infosize']).strip('\x00') # Validate request and infodata here (nothing now) # Turn the infodata into a dictionary parts = infodata.split('\x00') info = dict(zip(parts[::2],parts[1::2])) meta['request'] = request.split(':',1)[1] meta['info'] = info return True Fixing the Request 74 Cleaning up the request string request = "HTTP:http://www.google.com" .split(':',1) ['HTTP','http://www.google.com'] [1] 'http://www.google.com'
has very powerful list manipulation primitives • Indexing • Slicing • List comprehensions • Etc. • Knowing how to use these leads to rapid development and compact code 75
Write a function that scans a cache file and produces a sequence of records containing all of the cache metadata. • This is just one more of our building blocks • The goal is to hide some of the nasty bits 76
cache file from beginning to end, producing a # sequence of dictionaries with metadata information def scan_cachefile(f,blocksize): maxsize = 4*blocksize # Maximum size of an entry f.seek(4096) # Skip the bit-map while True: headerdata = f.read(36) if not headerdata: break header = parse_meta_header(headerdata,maxsize) if header and read_request_data(header,f): yield header # Move the file pointer to the next block fp = f.tell() if (fp % blocksize): f.seek(blocksize - (fp % blocksize),1) 77
f = open("Cache/_CACHE_001_","rb") >>> for meta in scan_cache_file(f,256) ... print meta['request'] ... http://www.yahoo.com/ http://us.js2.yimg.com/us.yimg.com/a/1-/java/promotions/ http://us.i1.yimg.com/us.yimg.com/i/ww/atty_hsi_free.gif ... 78 • Usage of the scan function • We can just open up a cache file and write a for-loop to iterate over all of the metadata entries.
from beginning to end, producing a # sequence of dictionaries with metadata information def scan_cachefile(f,blocksize): maxsize = 4*blocksize # Maximum size of an entry f.seek(4096) # Skip the bit-map while True: headerdata = f.read(36) if not headerdata: break header = parse_meta_header(headerdata,maxsize) if header and read_request_data(header,f): yield header # Move the file pointer to the next block fp = f.tell() if (fp % blocksize): f.seek(blocksize - (fp % blocksize),1) Python File I/O 79 File Objects Modeled after ANSI C. Files are just bytes. File pointer keeps track. f.read() # Read bytes f.tell() # Current fp f.seek(n,off) # Move fp
from beginning to end, producing a # sequence of dictionaries with metadata information def scan_cachefile(f,blocksize): maxsize = 4*blocksize # Maximum size of an entry f.seek(4096) # Skip the bit-map while True: headerdata = f.read(36) if not headerdata: break header = parse_meta_header(headerdata,maxsize) if header and read_request_data(header,f): yield header # Move the file pointer to the next block fp = f.tell() if (fp % blocksize): f.seek(blocksize - (fp % blocksize),1) Using Earlier Code 80 Here we are using our header parsing functions written in previous parts.
from beginning to end, producing a # sequence of dictionaries with metadata information def scan_cachefile(f,blocksize): maxsize = 4*blocksize # Maximum size of an entry f.seek(4096) # Skip the bit-map while True: headerdata = f.read(36) if not headerdata: break header = parse_meta_header(headerdata,maxsize) if header and read_request_data(header,f): yield header # Move the file pointer to the next block fp = f.tell() if (fp % blocksize): f.seek(blocksize - (fp % blocksize),1) Generating Results 81 We are using yield to produce data for a single metadata entry. If someone uses a for-loop, they will get all of the entries. Note: This allows us to process the cache without reading all of the data into memory.
function that can scan a single _CACHE_00n_ file and produce a sequence of dictionaries with metadata. • It's still somewhat low-level • Just need to package it a little better 82
Cache • Write a function that takes the name of a Firefox cache directory, scans all of the cache files for metadata, and produces a useful sequence of results. • Make it real easy to extract data 83
Given the name of a Firefox cache directory, the function # scans all of the _CACHE_00n_ files for metadata. A sequence # of dictionaries containing metadata is returned. import os def scan_cache(cachedir): n = 1 blocksize = 256 while n <= 3: cname = "_CACHE_00%d_" % n cfile = open(os.path.join(cachedir,cname),"rb") for meta in scan_cachefile(cfile,blocksize): meta['cachedir'] = cachedir meta['cachefile'] = cname yield meta cfile.close() n += 1 blocksize *= 4 84
Given the name of a Firefox cache directory, the function # scans all of the _CACHE_00n_ files for metadata. A sequence # of dictionaries containing metadata is returned. import os def scan_cache(cachedir): n = 1 blocksize = 256 while n <= 3: cname = "_CACHE_00%d_" % n cfile = open(os.path.join(cachedir,cname),"rb") for meta in scan_cachefile(cfile,blocksize): meta['cachedir'] = cachedir meta['cachefile'] = cname yield meta cfile.close() n += 1 blocksize *= 4 85 General idea: We loop over the three _CACHE_00n_ files and produce a sequence of the metadata dictionaries
name of a Firefox cache directory, the function # scans all of the _CACHE_00n_ files for metadata. A sequence # of dictionaries containing metadata is returned. import os def scan_cache(cachedir): n = 1 blocksize = 256 while n <= 3: cname = "_CACHE_00%d_" % n cfile = open(os.path.join(cachedir,cname),"rb") for meta in scan_cachefile(cfile,blocksize): meta['cachedir'] = cachedir meta['cachefile'] = cname yield meta cfile.close() n += 1 blocksize *= 4 86 By using yield here, we are chaining together the results obtained from all three cache files into one big long sequence of results. The underlying mechanics and implementation details are hidden (user doesn't care)
name of a Firefox cache directory, the function # scans all of the _CACHE_00n_ files for metadata. A sequence # of dictionaries containing metadata is returned. import os def scan_cache(cachedir): n = 1 blocksize = 256 while n <= 3: cname = "_CACHE_00%d_" % n cfile = open(os.path.join(cachedir,cname),"rb") for meta in scan_cachefile(cfile,blocksize): meta['cachedir'] = cachedir meta['cachefile'] = cname yield meta cfile.close() n += 1 blocksize *= 4 87 Adding path and file information to the dictionary (May be useful later)
for meta in scan_cache("Cache/"): ... print meta['request'] ... http://www.yahoo.com/ http://us.js2.yimg.com/us.yimg.com/a/1-/java/promotions/ http://us.i1.yimg.com/us.yimg.com/i/ww/atty_hsi_free.gif ... 88 • Usage of the scan function • Given the name of a cache directory, we can just loop over all of the metadata. Trivial! • With work, could perform various kinds of queries and processing of the data
in scan_cache("Cache/"): ... if 'slashdot' in meta['request']: ... print meta['request'] ... http://www.slashdot.org/ http://images.slashdot.org/topics/topiccommunications.gif http://images.slashdot.org/topics/topicstorage.gif http://images.slashdot.org/comments.css?T_2_5_0_176 ... 89 • Find all requests related to Slashdot • Well, that was pretty easy.
programs • findcache.py. A program that locates Firefox cache directories on file system • ffcache.py. A set of utility functions for extracting cache metadata. • Have taken a moderately complex data processing problem and simplified it. • < 100 lines of code. 90
information 91 All documents on the Internet have some type, encoding, and character set. For example, a 'text/ html' file that uses the 'UTF-8' character set and is encoded using gzip compression. • Your problem: Write a function add_content_info(m) that inspects the cache metadata and adds additional information concerning the content type, encoding, and charset.
a metadata dictionary, this function adds additional # fields related to the content type, charset, and encoding import email def add_content_info(meta): info = meta['info'] if 'response-head' not in info: content = None encoding = None charset = None else: rhead = info.get('response-head').split("\n",1)[1] m = email.message_from_string(rhead) content = m.get_content_type() encoding = m.get('content-encoding',None) charset = m.get_content_charset() meta['content-type'] = content meta['content-encoding'] = encoding meta['charset'] = charset 94 Python has a vast assortment of internet data handling modules. email. Parsing of email messages, MIME headers, etc.
cache scanning function that adds the content # information to the metadata returned. def scan_cache_withcontent(cachedir): for meta in scan_cache(cachedir): add_content_info(meta) yield meta 95 Add content info
(meta for meta in scan_cache_withcontent("Cache/") if meta['content-type'] == 'image/jpeg' and meta['datasize'] > 100000) >>> for j in jpegs: ... print j['request'] ... http://images.salon.com/ent/video_dog/comedy/2007/09/27/cereal/ story.jpg http://images.salon.com/ent/video_dog/ifc/2007/09/28/ apocalypse/story.jpg http://www.lakesideinns.com/images/fallroadphoto2006.jpg ... >>> 96 • Find all large JPEG images in the cache • That was also pretty easy
Documents 97 Add a function getdata(m) to ffcache.py that takes a metadata dictionary and attempts to return the actual data that's stored in the cache. If the data has been compressed or encoded in some manner, decode it before returning. • Big Picture More file I/O, but with the added problem of dealing with various data encoding issues.
cache metadata does not encode the location of the corresponding data. • It is only stored in _CACHE_MAP_ • _CACHE_MAP_ is only updated when Firefox terminates (held in memory). • So, we won't be able to accurately pull data from a live session. 98
for cache files that have the same file size as that encoded in the metadata. • If there are duplicates, pick the one that has a modification date closest to that in the metadata. • If none of this works, don't worry about it. 99
Attempt to locate the matching cache file (if possible) import glob def getcandidate(meta): datasize = meta['datasize'] filepat = os.path.join(meta['cachedir'],'[0-9A-F]*') filelist = glob.glob(filepat) # Get all files that are the same size samesize = [name for name in filelist if os.path.getsize(name) == datasize] if not samesize: return "" # Get file with closest modification time mtime = meta['modifytime'] delta,filename = min((abs(mtime-os.path.getmtime(name)), name) for name in samesize) return filename 100
locate the matching cache file (if possible) import glob def getcandidate(meta): datasize = meta['datasize'] filepat = os.path.join(meta['cachedir'],'[0-9A-F]*') filelist = glob.glob(filepat) # Get all files that are the same size samesize = [name for name in filelist if os.path.getsize(name) == datasize] if not samesize: return "" # Get file with closest modification time mtime = meta['modifytime'] delta,filename = min((abs(mtime-os.path.getmtime(name)), name) for name in samesize) return filename 101 glob module. Returns a list of filenames matching a pattern
to locate the matching cache file (if possible) import glob def getcandidate(meta): datasize = meta['datasize'] filepat = os.path.join(meta['cachedir'],'[0-9A-F]*') filelist = glob.glob(filepat) # Get all files that are the same size samesize = [name for name in filelist if os.path.getsize(name) == datasize] if not samesize: return "" # Get file with closest modification time mtime = meta['modifytime'] delta,filename = min((abs(mtime-os.path.getmtime(name)), name) for name in samesize) return filename 102 Get all files with the correct size. Get file with closest modification time
Given a metadata entry, this attempts to read the associated # data (assuming it can be located) import gzip, codecs def getdata(meta): filename = getcandidate(meta) if not filename: return "" encoding = meta.get("content-encoding","") if encoding == 'gzip': f = gzip.open(filename) else: f = open(filename,"rb") charset = meta.get("charset",None) if charset: reader = codecs.getreader(charset)(f) else: reader = f try: data = reader.read() except (IOError,ValueError): return "" return data 103
this attempts to read the associated # data (assuming it can be located) import gzip, codecs def getdata(meta): filename = getcandidate(meta) if not filename: return "" encoding = meta.get("content-encoding","") if encoding == 'gzip': f = gzip.open(filename) else: f = open(filename,"rb") charset = meta.get("charset",None) if charset: reader = codecs.getreader(charset)(f) else: reader = f try: data = reader.read() except (IOError,ValueError): return "" return data Internet Data Encoding 104 When working with foreign data, it is critical to be able to work with different encodings. gzip. Read/write gzip encoded files. codecs. Read/write different character encodings (UTF-8, UTF-16, Big5, etc.) There are many similar modules.
this attempts to read the associated # data (assuming it can be located) import gzip, codecs def getdata(meta): filename = getcandidate(meta) if not filename: return "" encoding = meta.get("content-encoding","") if encoding == 'gzip': f = gzip.open(filename) else: f = open(filename,"rb") charset = meta.get("charset",None) if charset: reader = codecs.getreader(charset)(f) else: reader = f try: data = reader.read() except (IOError,ValueError): return "" return data Reading gzip Files 105 If the file is encoded as 'gzip', we'll open it using the gzip module. Otherwise, open it as a normal file.
this attempts to read the associated # data (assuming it can be located) import gzip, codecs def getdata(meta): filename = getcandidate(meta) if not filename: return "" encoding = meta.get("content-encoding","") if encoding == 'gzip': f = gzip.open(filename) else: f = open(filename,"rb") charset = meta.get("charset",None) if charset: reader = codecs.getreader(charset)(f) else: reader = f try: data = reader.read() except (IOError,ValueError): return "" return data Character Encoding 106 The codecs module is used to deal with special character encodings such as UTF-8. Here, we are putting a codecs "reader" around the file if a charset was specified. Otherwise, just use the original file.
Python has full support for Unicode • Unicode strings 107 • An advanced (and painful) topic • For internet applications, you should assume that text data will always be encoded according to some standard codecs (Latin-1, ISO-8859-1, UTF-8, Big5, etc.) pepper = u'Jalape\xf1o'
findcache.py. A program that can locate Firefox cache directories. (10 lines) • ffcache.py. A module that can read cache metadata, determine content encoding, and read files from the cache (assuming they can be located). (140 lines) 108
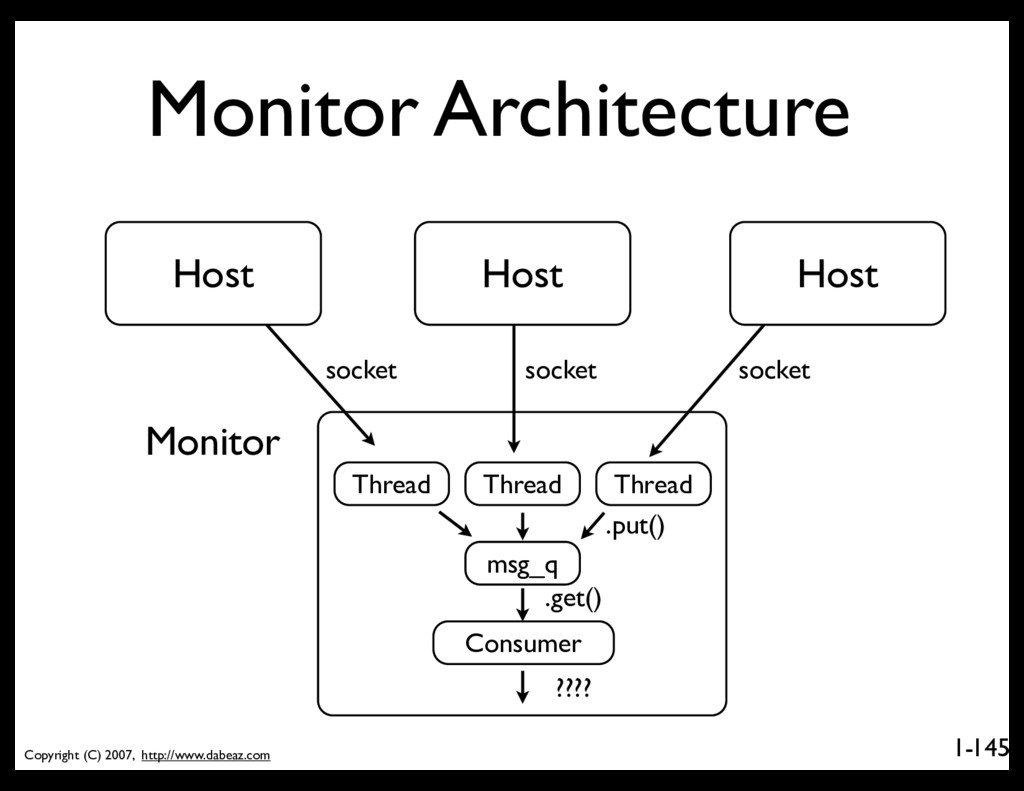
Brother (make an evil sound here) 109 Write a program that first locates all of the Firefox cache directories under a given directory. Then have that program run forever as a network server, waiting for connections. On each connection, send back all of the current cache metadata. • Big Picture We're going to write a daemon that will find and quietly monitor browser caches.
Program • Find all Firefox cache directories • Didn't we already write that code? • Yes. Let's run that program as a subprocess and collect its output. • Problem: How to run other processes? 110
the findcache.py program as a subprocess and # collect the output. import popen2 import sys def findcaches(topdir): cmd = sys.executable + " findcache.py " + topdir out,inp = popen2.popen2(cmd) inp.close() # No input to subprocess caches = [line.strip() for line in out] return caches 111
findcache.py program as a subprocess and # collect the output. import popen2 import sys def findcaches(topdir): cmd = sys.executable + " findcache.py " + topdir out,inp = popen2.popen2(cmd) inp.close() # No input to subprocess caches = [line.strip() for line in out] return caches 112 popen2 Contains functions for launching subprocesses and creating pipes.
findcache.py program as a subprocess and # collect the output. import popen2 import sys def findcaches(topdir): cmd = sys.executable + " findcache.py " + topdir out,inp = popen2.popen2(cmd) inp.close() # No input to subprocess caches = [line.strip() for line in out] return caches 113 We create a full shell command and execute it. cmd = "/usr/local/bin/python2.5 findcache.py topdir" sys.executable Full path of python intepreter.
>>> caches ['/Users/beazley/Library/Caches/Firefox/Profiles/ qs1ab616.default/Cache', '/Users/beazley/Library/Mozilla/ Profiles/default/wxuoyiuf.slt/Cache'] >>> 114 • Usage of the findcaches function • Commentary. Using pipes might be overkill for this. This is mostly just to illustrate.
has extensive support for processes • os module (pipes, fork, exec, spawnv, wait, exit, system, ttys) • popen2 (pipes) • subprocess (high level subprocess API) • signal (signal handling) • Almost any C-level program written using POSIX calls can be implemented in Python 115
not have built-in support for controlling interactive subprocesses (e.g., "Expect") • Must install third party modules for this • Example: pexpect • http://pexpect.sourceforge.net 116
SocketServer, ffcache cachelist = findcaches(sys.argv[1]) def dump_cache(f): for dir in cachelist: for meta in ffcache.scan_cache_withcontent(dir): pickle.dump(meta,f) class SpyHandler(SocketServer.BaseRequestHandler): def handle(self): f = self.request.makefile() dump_cache(f) f.close() SocketServer.TCPServer.allow_reuse_address = True serv = SocketServer.TCPServer(("",31337),SpyHandler) print "CacheSpy running on port 31337" serv.serve_forever() 118
SocketServer, ffcache cachelist = findcaches(sys.argv[1]) def dump_cache(f): for dir in cachelist: for meta in ffcache.scan_cache_withcontent(dir): pickle.dump(f,meta) class SpyHandler(SocketServer.BaseRequestHandler): def handle(self): f = self.request.makefile() dump_cache(f) f.close() SocketServer.TCPServer.allow_reuse_address = True serv = SocketServer.TCPServer(("",31337),SpyHandler) print "CacheSpy running on port 31337" serv.serve_forever() 119 SocketServer A module for easily creating low-level internet applications using sockets.
SocketServer, ffcache cachelist = findcaches(sys.argv[1]) def dump_cache(f): for dir in cachelist: for meta in ffcache.scan_cache_withcontent(dir): pickle.dump(meta,f) class SpyHandler(SocketServer.BaseRequestHandler): def handle(self): f = self.request.makefile() dump_cache(f) f.close() SocketServer.TCPServer.allow_reuse_address = True serv = SocketServer.TCPServer(("",31337),SpyHandler) print "CacheSpy running on port 31337" serv.serve_forever() 120 You define a simple class that implements handle(). This implements the server logic.
SocketServer, ffcache cachelist = findcaches(sys.argv[1]) def dump_cache(f): for dir in cachelist: for meta in ffcache.scan_cache_withcontent(dir): pickle.dump(meta,f) class SpyHandler(SocketServer.BaseRequestHandler): def handle(self): f = self.request.makefile() dump_cache(f) f.close() SocketServer.TCPServer.allow_reuse_address = True serv = SocketServer.TCPServer(("",31337),SpyHandler) print "CacheSpy running on port 31337" serv.serve_forever() 121 Next, you just create a Server object, hook the handler up to it, and run the server.
SocketServer, ffcache cachelist = findcaches(sys.argv[1]) def dump_cache(f): for dir in cachelist: for meta in ffcache.scan_cache_withcontent(dir): pickle.dump(meta,f) class SpyHandler(SocketServer.BaseRequestHandler): def handle(self): f = self.request.makefile() dump_cache(f) f.close() SocketServer.TCPServer.allow_reuse_address = True serv = SocketServer.TCPServer(("",31337),SpyHandler) print "CacheSpy running on port 31337" serv.serve_forever() 122 Here, we are turning a socket into a file and dumping cache data on it. socket corresponding to client that connected.
SocketServer, ffcache cachelist = findcaches(sys.argv[1]) def dump_cache(f): for dir in cachelist: for meta in ffcache.scan_cache_withcontent(dir): pickle.dump(meta,f) class SpyHandler(SocketServer.BaseRequestHandler): def handle(self): f = self.request.makefile() dump_cache(f) f.close() SocketServer.TCPServer.allow_reuse_address = True serv = SocketServer.TCPServer(("",31337),SpyHandler) print "CacheSpy running on port 31337" serv.serve_forever() 123 The pickle module takes any Python object and serializes it. There are really only two ops: pickle.dump(obj,f) # Dump object obj = pickle.load(f) # Load object
cachespy.py /Users CacheSpy running on port 31337 124 • Example: • Server is just sitting there waiting • You can try connecting with telnet % telnet localhost 31337 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. (dp0 S'info' p1 ... bunch of cryptic data ...
evil overload (bwahahahahaha!) 125 Write a program cachemon.py that contains a function for retrieving the cache contents from a remote machine. • Big Picture Writing network clients. Programs that make outgoing connections to internet services.
def scan_remote_cache(host): s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(host) f = s.makefile() try: while True: meta = pickle.load(f) meta['host'] = host # Add host to metadata yield meta except EOFError: pass f.close() s.close() Unpickling a Sequence 128 Here we use pickle to repeatedly load objects. We use yield to generate a sequence of received objects.
scan_remote_cache(("localhost",31337)) >>> jpegs = (meta for meta in rcache ... if meta['content-type'] == 'image/jpeg' ... and meta['datasize'] > 100000) >>> for j in jpegs: ... print j['request'] ... http://images.salon.com/ent/video_dog/comedy/2007/09/27/ cereal/story.jpg http://images.salon.com/ent/video_dog/ifc/2007/09/28/ apocalypse/story.jpg http://www.lakesideinns.com/images/fallroadphoto2006.jpg ... 129 • Example: Find all JPEG images > 100K on a remote machine • Very similar to old code!
a whole cluster of machines 130 Write a function that can easily scan the caches of an entire list of remote hosts. • Big Picture Collecting data from a group of machines on the network.
host in hostlist: try: for meta in scan_remote_cache(host): yield meta except (EnvironmentError,socket.error): pass Solution : Cachemon 131 A bit of exception handling to deal with dead machines, and other problems (might need to be expanded)
[('host1',31337),('host2',31337),...] >>> rcaches = scan_caches(hosts) >>> jpegs = (meta for meta in rcache ... if meta['content-type'] == 'image/jpeg' ... and meta['datasize'] > 100000) >>> for j in jpegs: ... print j['request'] ... ... 132 • Example: Find all JPEG images > 100K on a set of remote machines • Think about the abstraction of "iteration" here. Query code is exactly the same.
from a large set of machines 133 In the last section, we wrote a function that scanned an entire list of hosts, one at a time. Modify that function to scan a set of hosts using concurrent network connections. • Big Picture Breaking a task up into concurrently executing parts. Programming with threads.
full support for threads • They are real threads (pthreads, system threads, etc.) • The only catch: The Python run-time interpreter is protected by a global interpreter lock. So, no true concurrency across multiple CPUs.
class ScanThread(threading.Thread): def __init__(self,host,msg_q): threading.Thread.__init__(self) self.host = host self.msg_q = msg_q def run(self): try: for meta in scan_remote_cache(self.host): self.msg_q.put(meta) except (EnvironmentError,socket.error): pass threading Module 136 threading module. Contains most functionality related to threads.
class ScanThread(threading.Thread): def __init__(self,host,msg_q): threading.Thread.__init__(self) self.host = host self.msg_q = msg_q def run(self): try: for meta in scan_remote_cache(host): self.msg_q.put(meta) except (EnvironmentError,socket.error): pass Thread Base Class 137 Threads are defined by inheriting from the Thread base class.
class ScanThread(threading.Thread): def __init__(self,host,msg_q): threading.Thread.__init__(self) self.host = host self.msg_q = msg_q def run(self): try: for meta in scan_remote_cache(self.host): self.msg_q.put(meta) except (EnvironmentError,socket.error): pass Thread Execution 139 run() method Contains code that executes in the thread.
You create a thread object and launch it t1 = ScanThread(("host1",31337),msg_q) t1.start() t2 = ScanThread(("host2",31337),msg_q) t2.start() • .start() starts the thread and calls .run()
commonly used to implement variations of producer/consumer problems. • Data is produced by one or more producers (e.g., Each remote client) • Consumed by one or more consumers (e.g., a centralized function). • You could try to coordinate this with locks and other synchronization.
Queue module. Provides a thread-safe queue. import Queue msg_q = Queue.Queue() • Queue insertion msg_q.put(obj) • Queue removal obj = msg_q.get() • Queue can be shared by as many threads as you want without worrying about locking.
class ScanThread(threading.Thread): def __init__(self,host,msg_q): threading.Thread.__init__(self) self.host = host self.msg_q = msg_q def run(self): try: for meta in scan_remote_cache(self.host): self.msg_q.put(meta) except (EnvironmentError,socket.error): pass Use of a Queue Object 143 A Queue object. Where incoming objects are placed. Get data from the remote machine and put in the Queue
144 • You create a queue, then launch the thread msg_q = Queue.Queue() t1 = ScanThread(("host1",31337),msg_q) t1.start() t2 = ScanThread(("host2",31337),msg_q) t2.start() while True: meta = msg_q.get() # Get metadata
def launch_scanners(hostlist,msg_q): tlist = [] for host in hostlist: thr = ScanThread(host,msg_q) thr.start() tlist.append(thr) for thr in tlist: thr.join() msg_q.put(None) # Sentinel def scan_caches(hostlist): msg_q = Queue.Queue() thr = threading.Thread(target=launch_scanners, args=(hostlist,msg_q)) thr.start() while True: meta = msg_q.get() if meta: yield meta else: break 147 The above function is a thread that launches ScanThreads. It then waits for the threads to terminate by joining with them. After all threads have terminated, a sentinel is dropped in the Queue.
def launch_scanners(hostlist,msg_q): tlist = [] for host in hostlist: thr = ScanThread(host,msg_q) thr.start() tlist.append(thr) for thr in tlist: thr.join() msg_q.put(None) # Sentinel def scan_caches(hostlist): msg_q = Queue.Queue() thr = threading.Thread(target=launch_scanners, args=(hostlist,msg_q)) thr.start() while True: meta = msg_q.get() if meta: yield meta else: break 148 The function below creates a Queue and launches a thread to launch all of the scanning threads. It then produces a sequence of cache data until the sentinel (None) is pulled off of the queue.
There are many more issues to thread programming that we could discuss. • All issues concerning locking, synchronization, event handling, and race conditions apply to Python. • Because of global interpreter lock, threads are not a way to achieve higher performance (generally).
module has various primitives Lock() # Mutex Lock RLock() # Reentrant Mutex Lock Semaphore(n) # Semaphore • Example use: x = value # Some kind of shared object x_lock = Lock() # A lock associated with x ... x_lock.acquire() # Modify or do something with x (critical section) ... x_lock.release()
Wrote a program findcache.py that located cache directories (~ 10 lines) • Wrote a module ffcache.py that parsed contents of caches (~140 lines) • Wrote cachespy.py that allows caches to be retrieved (~30 lines) • Wrote a concurrent monitor for getting that data (~50 lines)
In none of our programs have we read the entire contents of the Firefox cache into memory. • In cachespy.py, the contents are read iteratively and piped through a socket (not stored in memory) • In cachemon.py, contents are received and routed through message queues. Processed iteratively (no temporary lists of results).
every connection, cachespy sends the entire contents of the Firefox cache metadata back to the client. • However, mostly we're just performing various kinds of queries on the data and filtering. • Question: Could we do any of this work remotely?
work 154 Modify the cachespy program so that some of the mapping and filtering work can be performed remotely on each of the machines. Only send back a subset of the data to the monitor program. • Big Picture Distributed computation. Massive security problem.
to accept an optional filter specification. Pass this on to the remote machine and use it to process the data remotely before returning reults. 155 filter = """ if meta['content-type'] == 'image/jpeg' and meta['datasize'] > 100000 """ rcache = scan_remote_cache(host,filter)
cachemon.py def scan_remote_cache(host,filter=""): s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(host) f = s.makefile() pickle.dump(filter,f) f.flush() try: while True: meta = pickle.load(f) meta['host'] = host yield meta except EOFError: pass 156 Send the filter to the remote host
... def dump_cache(f,filter): valuegen = """(meta for dir in cachelist for meta in ffcache.scan_cache_withcontent(dir) %s)""" % filter try: for meta in eval(valuegen): pickle.dump(meta,f) except: pickle.dump({'error': traceback.format_exc()},f) 160
... def dump_cache(f,filter): valuegen = """(meta for dir in cachelist for meta in ffcache.scan_cache_withcontent(dir) %s)""" % filter try: for meta in eval(valuegen): pickle.dump(meta,f) except: pickle.dump({'error': traceback.format_exc()},f) 161 Filter added and used to create an expression string. filter = "if meta['datasize'] > 100000" valuegen = """(meta for dir in cachelist for meta in ffcache.scan_cache_withcontent(dir) if meta['datasize'] > 100000)"""
dump_cache(f,filter): valuegen = """(meta for dir in cachelist for meta in ffcache.scan_cache_withcontent(dir) %s)""" % filter try: for meta in eval(valuegen): pickle.dump(meta,f) except: pickle.dump({'error': traceback.format_exc()},f) 162 eval(s). Evaluates s as a Python expression. A bit error of handling. traceback module creates stack traces for exceptions.
Have create some interesting machinery 164 # Find all of those slashdot slackers import cachemon hosts = [('host1',31337),('host2',31337), ('host3',31337),...] filter = "if 'slashdot' in meta['request']" rcaches = scan_caches(hosts,filter) for meta in rcaches: print meta['request'] print meta['host'],meta['cachedir'] print
Queries run remotely on all the hosts • Only data of interest is sent back • No temporary lists or large data structures • Concurrent execution on monitor • Concurrency is hidden from user 165
Loop over all entries in a cache file: 166 for meta in scan_cache_file(f,256): ... • Loop over all entries in a cache directory for meta in scan_cache(dirname): ... • Loop over all cache entries on remote host for meta in scan_remote_cache(host): ... • Loop over all cache entries on many hosts for meta in scan_caches(hostlist): ...
of material has been presented • Again, the goal was to do something interesting with Python, not to be just a reference manual. • This is only a small taste of what's possible • And it's only a small taste of why people like programming in Python 167
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}