Integer- Arithmetic-Only Inference • https://arxiv.org/abs/1712.05877 • Quantizing deep convolutional networks for efficient inference: A whitepaper • https://arxiv.org/abs/1806.08342 • Post training 4-bit quantization of convolutional networks for rapid- deployment • https://arxiv.org/abs/1810.05723 TensorFlow whitepaper NeurIPS 2019
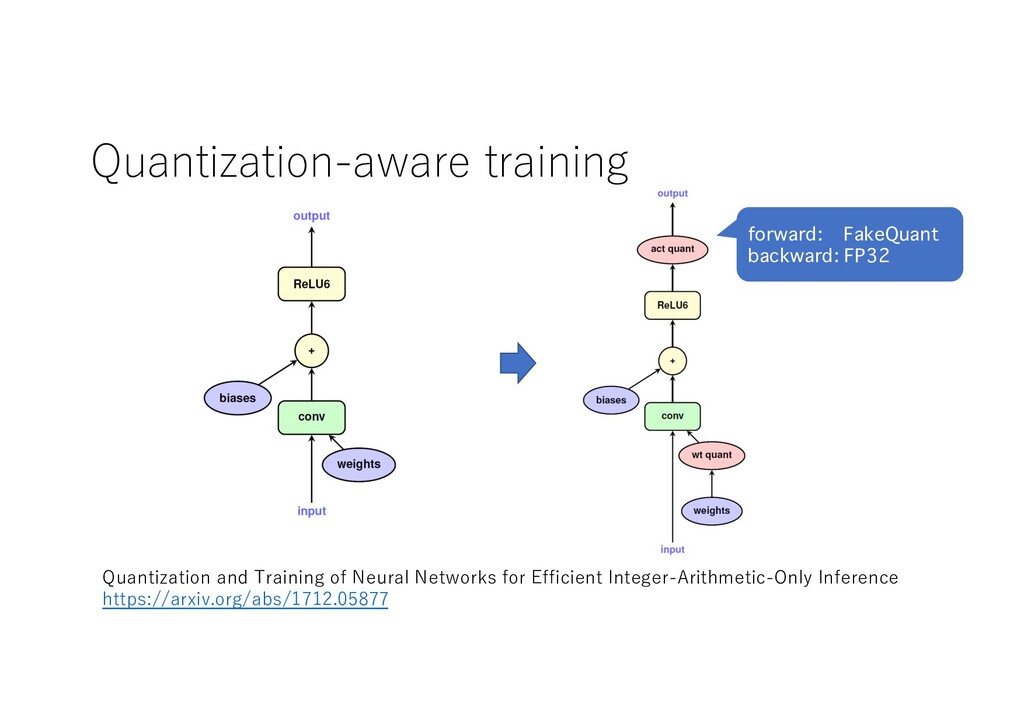
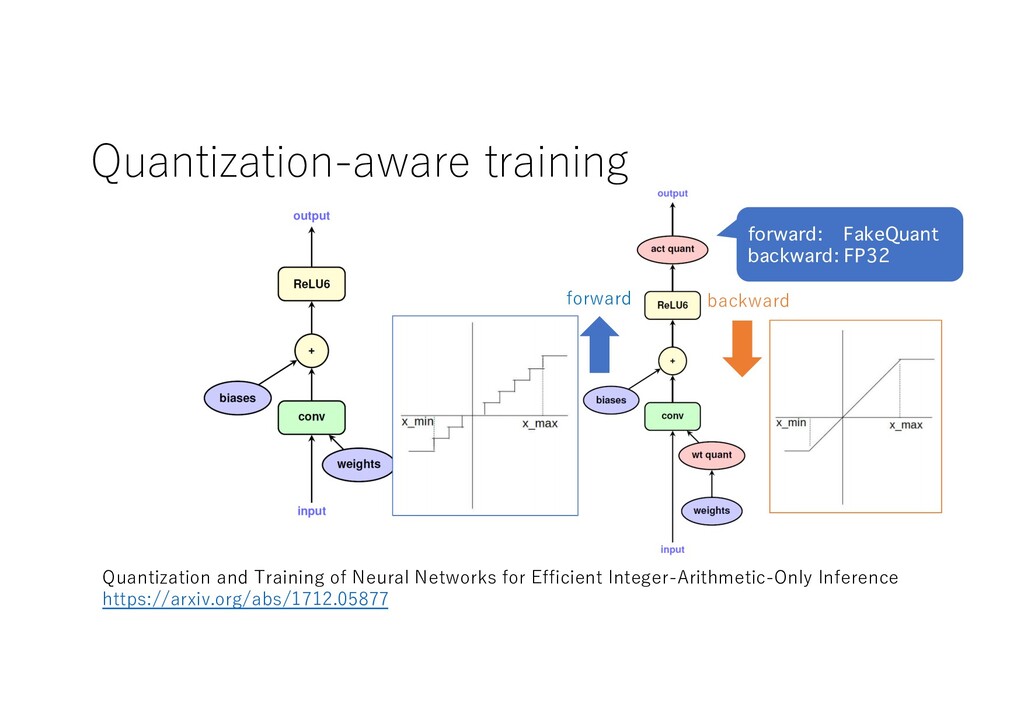
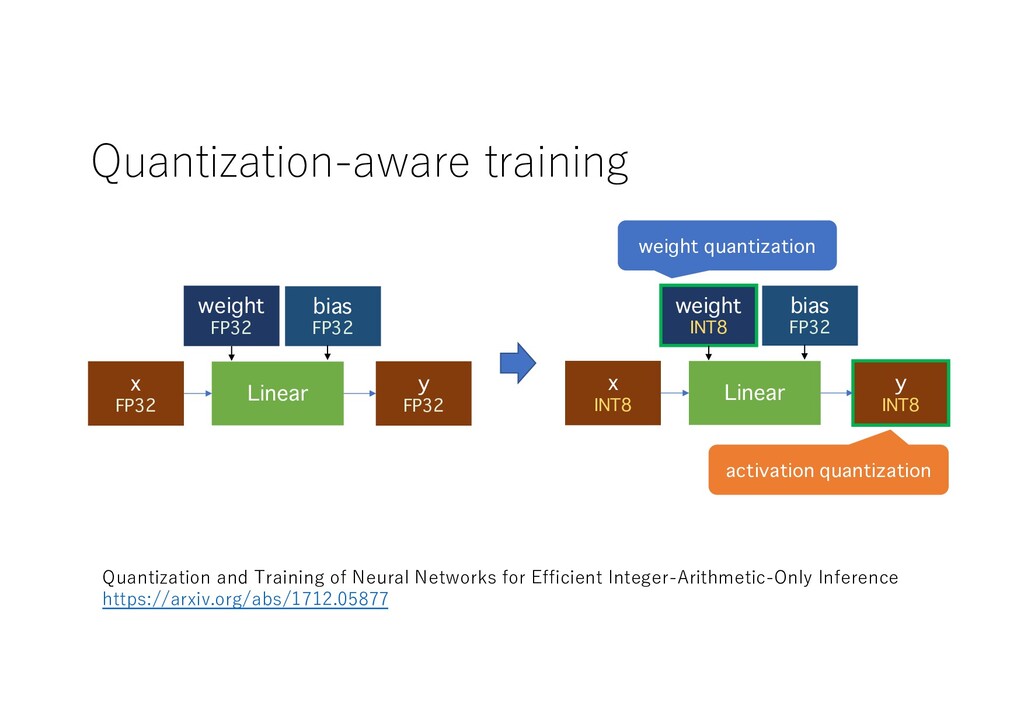
FP32 Linear weight INT8 bias FP32 x INT8 y INT8 weight quantization activation quantization Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference https://arxiv.org/abs/1712.05877
Inference https://arxiv.org/abs/1712.05877 • TFLiteConverterによる変換 • Whitepaperでは3種類(a,b,d) • TensorFlow 2.xドキュメントでは4種類(a,b,c,d) • Approaches 1. Post Training Quantization a. Weight Quantization: Dataset不要 b. Full integer quantization: Datasetで分布調整 c. Float16 quantization: 半精度 2. Quantization-Aware Training d. weight + activation: Datasetによるfine-tuning
Inference https://arxiv.org/abs/1712.05877 • TFLiteConverterによる変換 • Whitepaperでは3種類(a,b,d) • TensorFlow 2.xドキュメントでは4種類(a,b,c,d) • Approaches 1. Post Training Quantization a. Weight Quantization: Dataset不要 b. Full integer quantization: Datasetで分布調整 c. Float16 quantization: 半精度 2. Quantization-Aware Training d. weight + activation: Datasetによるfine-tuning
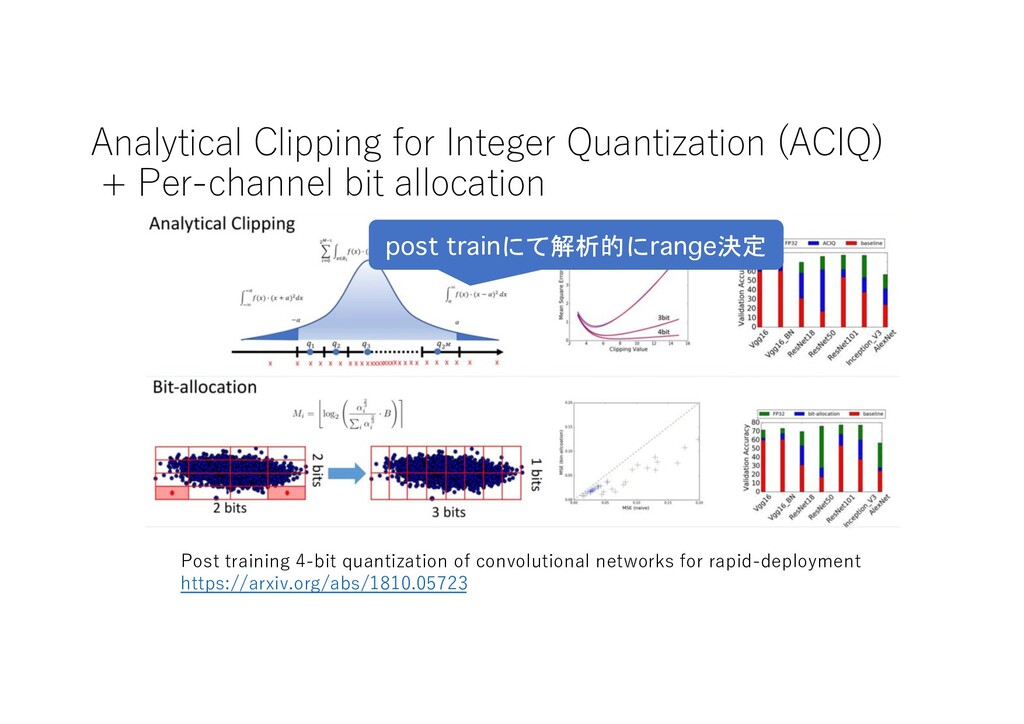
Post training 4-bit quantization of convolutional networks for rapid-deployment https://arxiv.org/abs/1810.05723 ResNet Post Training • weight 4bit • activation 4bit
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TVM TensorCore INT4/INT1対応 [CODEGEN] Support cuda tensorcore subbyte int data](https://files.speakerdeck.com/presentations/1cffe3b00aa3478ebedb22a2767e0633/slide_23.jpg){kind=link}
![TVM TensorCore INT4/INT1対応 [CODEGEN] Support cuda tensorcore subbyte int data](https://files.speakerdeck.com/presentations/1cffe3b00aa3478ebedb22a2767e0633/slide_24.jpg){kind=link}
{kind=link}