Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
「O(n log(n))のパフォーマンス」の意味がわかるようになろう
Search
dhirabayashi
November 14, 2025
Technology
530
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
「O(n log(n))のパフォーマンス」の意味がわかるようになろう
JJUG CCC 2025 Fall
dhirabayashi
November 14, 2025
More Decks by dhirabayashi
See All by dhirabayashi
Javaエンジニアのための低コストKotlin入門
dhirabayashi
0
2k
JVM言語でもできる、競技プログラミング
dhirabayashi
0
580
Other Decks in Technology
See All in Technology
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
950
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
910
キャリアLT会#3
beli68
0
170
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
240
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
2
440
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
980
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
300
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
470
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.6k
そのドキュメント、自動化しませんか?
yuksew
1
360
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
360
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.5k
Featured
See All Featured
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.3k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
How to make the Groovebox
asonas
2
2.3k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
410
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Transcript
「O(n log(n))のパフォーマンス」の意味がわかるようになろう JJUG CCC 2025 Fall Daiki Hirabayashi
2 自己紹介 平林 大輝 JJUG CCC歴 • 2016年頃から参加 • 登壇は3回目
JavaとかKotlinを使った開発 をしています
3 目指すこと • 「O(n log(n))のパフォーマンス」の意味がわかるようになる • 計算量という概念についてざっくり理解する
4 目指さないこと • 計算量について厳密に理解すること • ほんらいは数式を使って厳密にやるべき内容だが、今回はざっくりとし た理解を目指す • とっつきやすさを優先していて厳密に正しくない内容あり
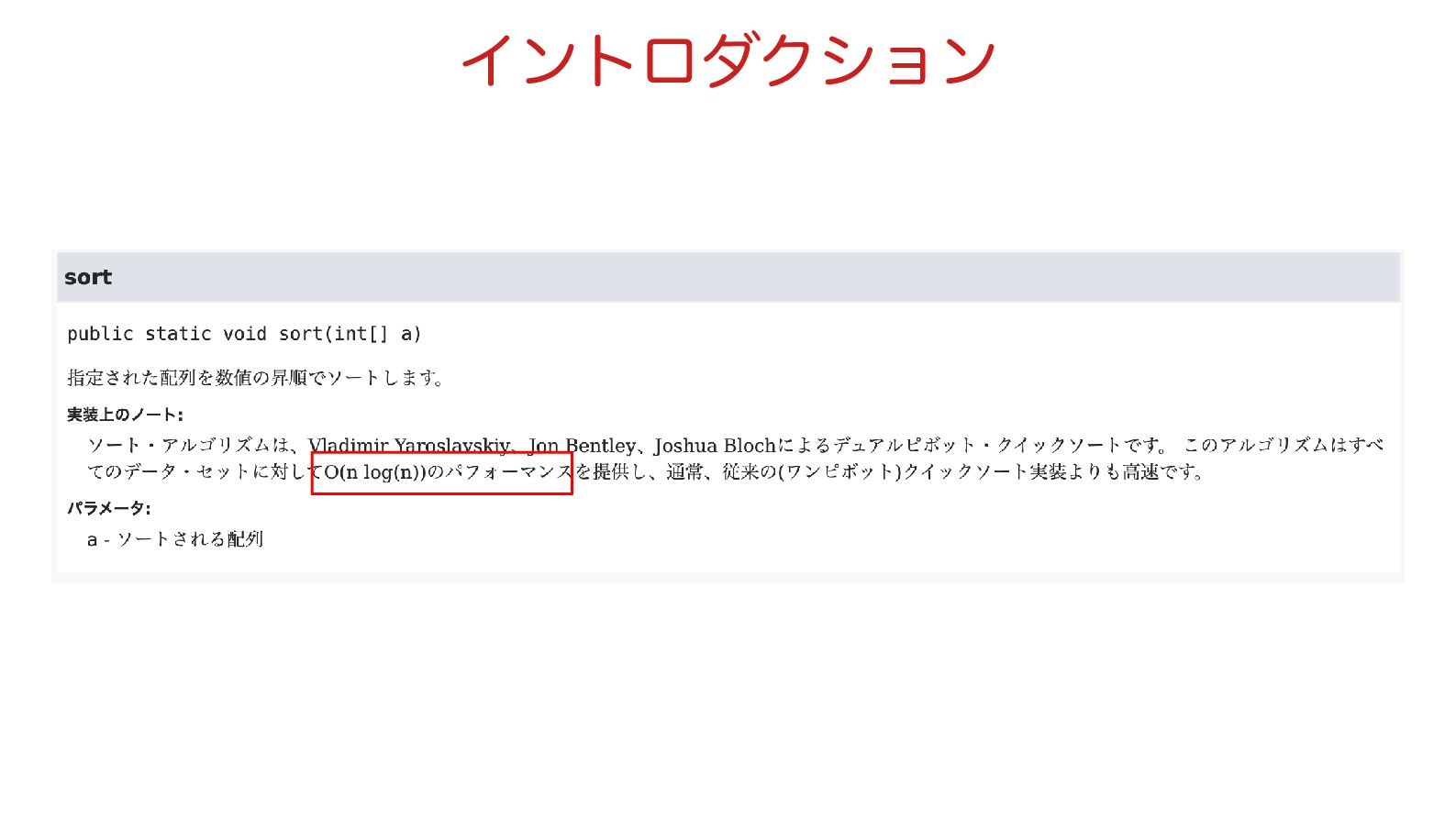
5 イントロダクション • 突然ですが、java.util.Arrays(int[])のJavaDocを見てみましょう • https://docs.oracle.com/javase/jp/24/docs/api/java.base/java/util/ Arrays.html#sort(int%5B%5D)
6 イントロダクション
7 イントロダクション
8 イントロダクション • O(n log(n))のパフォーマンス • 「パフォーマンス」なので速さの話をしているのはわかる • Oって何? •
nって何? • log(n)って何?
9 O(なんとか)という記法 • 処理対象データ量が増えた場合に、処理時間がどれくらい伸 びるかを示す • たとえば処理対象データ量が10倍になった場合、処理時間 は何倍になるか?
10 データ量に対する処理時間の伸び方 • データ量が10倍なら処理時間も10倍ではないか? • →そうとも限らない
11 データ量に対する処理時間の伸び方 • たとえば配列の要素を全て見る処理があるとする • この場合はたしかにデータ量が10倍なら処理時間も10倍に なりそう
12 データ量に対する処理時間の伸び方 • では、以下のようなコードでは? • この場合、処理回数(処理時間)はデータ量の2乗になる • データ量が10倍なら処理時間は100倍、100倍なら10000倍
13 データ量に対する処理時間の伸び方 • このように、データ量が増えたときの処理時間の伸び方は 実装によって大きく変わる • これらの区別をつけて表現するのがO(なんとか)という表現
14 O(なんとか)という表現 • こちらの実装の場合、O(n)と表現する(配列の要素数がn)
15 O(なんとか)という表現 • こちらの実装の場合、O(n2)と表現する(配列の要素数がn)
16 O(なんとか)という表現 • データ数がnの場合、処理時間は「なんとか」に比例して増 える • O(n)の場合、nに比例して増える • データ量がn倍になったら処理時間は概ねn倍 •
O(n2)の場合、n2に比例して増える • データ量がn倍になったら処理時間は概ねn2倍
17 O(n log(n))とは • データ数がnの場合、処理時間は「なんとか」に比例して増 える • O(n log(n))の場合、n log(n)に比例して増える
• データ量がn倍になったら処理時間は概ねn log(n)倍
18 n log(n)とは • n log(n)はn × log(n)という意味 • log(n)とは
• 高校数学で習うやつ(計算量の文脈では底は通常2) • 厳密ではないが、nを2で何回割れるかという数とだいたい一致する • つまりlog(n)は元のnよりずっと小さい数になる • O(log(n))の場合、処理時間の増加が非常に緩やかになる • 雑に言えば爆速 • データ量が2倍になっても処理回数が1回増えるだけ • データ量が42億件でも処理回数は32回とかそれくらい
19 O(n log(n))の処理時間 • O(n log(n))の場合、O(n) × 爆速(O(log n)) •
O(n)よりは遅いがかなり近い • データ量が増えると差が緩やかに広がる • 少なくともO(n2)よりははるかに速い
20 計算量 • ここまで説明してきた概念は「計算量」と呼ばれている • 計算量には処理時間を扱う「時間計算量」とメモリ使用量を扱う 「空間計算量」がある • 単に「計算量」と言った場合は時間計算量を指すことが多い
21 計算量 • 計算量はデータ量が増えたときに処理時間がどれくらい伸びるか でアルゴリズムの性能を示すもの • 「このアルゴリズムの計算量はO(n)である」みたいな言い方をす る
22 「O(n log(n))のパフォーマンス」 • ここまでの説明により「O(n log(n))のパフォーマンス」とは • このアルゴリズムの計算量がO(n log(n))である •
これはループで配列を全件見るようなO(n)のアルゴリズ ムにかなり近い性能 • 少なくともO(n2)とは比較にならないくらい良い性能
23 「O(n log(n))のパフォーマンス」 • ポイントは、O(n2)よりは格段に良い性能という点 • そもそもO(n2)がどれくらいの性能なのか知る必要がある
24 O(n2)の遅さ • たとえば、以下のようなアルゴリズムを考えてみる
25 O(n2)の遅さ • これは選択ソートの実装 • 計算量はO(n2) • 二重ループ
26 O(n2)の遅さ • 私の端末で100万件の配列をソートした結果… • 前述の選択ソート: 236095ms(236秒) • O(n2)はデータ量が多いと非常に遅い •
IOはない純粋な計算でこの遅さ • ちなみにArrays.sort(int[])だと78msだった
27 とはいえ注意点 • 計算量は実際の実行時間とは切り離された概念 • 実行時間は環境に依存するので、O(n2)だから遅いとは言い切れな い • 今回のは同じ環境での比較なので一応成り立つ
28 ソートの計算量の補足 • 比較によるソートアルゴリズムの計算量はO(n log(n))より速 くできないことが知られている • 比較によらないソートでもっと速いのはあるが、特定の ケースでしか使えない •
そのためArrays.sort(int[])に限らず、標準ライブラリのソート アルゴリズムは計算量がO(n log(n))であることが普通
29 つまりO(n log(n))のパフォーマンスとは • 計算量がO(n log(n))である • O(n)よりは遅い • O(n2)よりは格段に良い性能
• ソートアルゴリズムとしては一般的かつ最良の計算量である • 一般的なソートがどれくらいの速さかはみんな経験的に知って る…はず
30 計算量の見積もり方 • データ量をnとして、nを使って処理回数を表す • 2nとかn/2になった場合、単純にnと評価する • 係数を捨てる • 最も大きい、ボトルネックとなる箇所以外は捨てる
• O(求められた式)が計算量の評価となる
32 計算量の見積もりの例 • こちらはarrayの要素数をnとして、計算量はO(n) • 代入や組み込み演算子の計算量はO(1)
33 計算量の見積もりの例 • こちらの計算量はprocess()の計算量次第で変わる • process()の計算量がO(1)ならO(n) • process()の計算量がO(log(n))ならO(n log(n)) •
process()の計算量がO(n)ならO(n2)
34 計算量の見積もりの例 • これの計算量はO(n) • O(3n)ではない • データ量が10倍になったら処理時間はおよそ10倍(30倍では なく)
36 計算量の見積もりの例 • process()の計算量がO(1)とした場合、これの計算量はO(n2) • ボトルネックとなる箇所以外は捨てるため、二重ループのほう に引きずられる
37 O(n)のループを無視する理由 • データ量が増えた場合、O(n)は順当に遅くなるがO(n2)は凄 まじい勢いで遅くなる • データ量が非常に大きい場合、O(n2)のほうによる性能劣化が すごすぎてO(n)のほうは無視していいレベルになる
38 とはいえ… • どう考えても右のほうが遅いのに計算量はどっちもO(n2)で 区別がつかない • 計算量だけ見ても実行時間が正確にはわからない
40 計算量はなんのためにある? • 処理時間で評価するのがイメージしやすいが、環境に強く 依存するため適切ではない • JavaDocに計算量ではなく特定環境での実行時間が書かれて いても評価できない • 処理時間の伸び方に着目することによってこそアルゴリズムの
本質がわかる • データ量が少ないときに速いのは当たり前なので、データ量 が多い時の性能こそ重要
41 計算量から何を読み取るか? • 計算量から「これは測るまでもなくダメだろ」というケース を検知できる • 最もネックになる部分に着目しているので、計算量的にダメな らどうあがいてもダメ • O(n2)くらいになるとだいたい厳しい
• 競技プログラミングだと、O(n2)だと遅すぎて不正解になる 問題が多かったりする • O(n)とかO(n log(n))まで計算量を落とすことを要求される
42 計算量から何を読み取るか? • 計算量的にはいけるはずだけど測ったら遅かったということは 当然ある • 計算量においては無視する箇所も、現実的な性能評価、性能改 善では影響する • とはいえ計算量的にダメならどうあがいてもダメ
• 計算量を落とすのが優先
43 計算量から何を読み取るか? • 実際のアプリケーションだと、性能問題が出たらDBでインデッ クスを付与するとかの対処になるかもしれない • しかし、それも実は計算量の問題 • 一般的なRDBMSだとフルスキャンはO(n)、インデックスを使った検 索はO(log(n))
• インデックスを使って高速化するのは計算量の改善そのもの
44 まとめ • O(n log(n))のパフォーマンスとはソートアルゴリズムとして一般 的かつ実用的な速さ • 計算量を見積もることで、明らかにダメなケースをある程度は 検知できる •
データ量が多い場合、O(n2)とかになるとおそらくNG
45 セッションアンケート 全体アンケート
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![5 イントロダクション • 突然ですが、java.util.Arrays(int[])のJavaDocを見てみましょう • https://docs.oracle.com/javase/jp/24/docs/api/java.base/java/util/ Arrays.html#sort(int%5B%5D)](https://files.speakerdeck.com/presentations/af50201901d04a399d3539c9757d6cf0/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}