priority INT UNSIGNED NOT NULL, status ENUM('ready', 'doing', 'done', 'stop') NOT NULL, PRIMARY KEY (page_id), KEY (status, priority) ) ENGINE=MEMORY; -- クエリ: SELECT page_id FROM crawl_queue WHERE status='ready' ORDER BY priority LIMIT 1
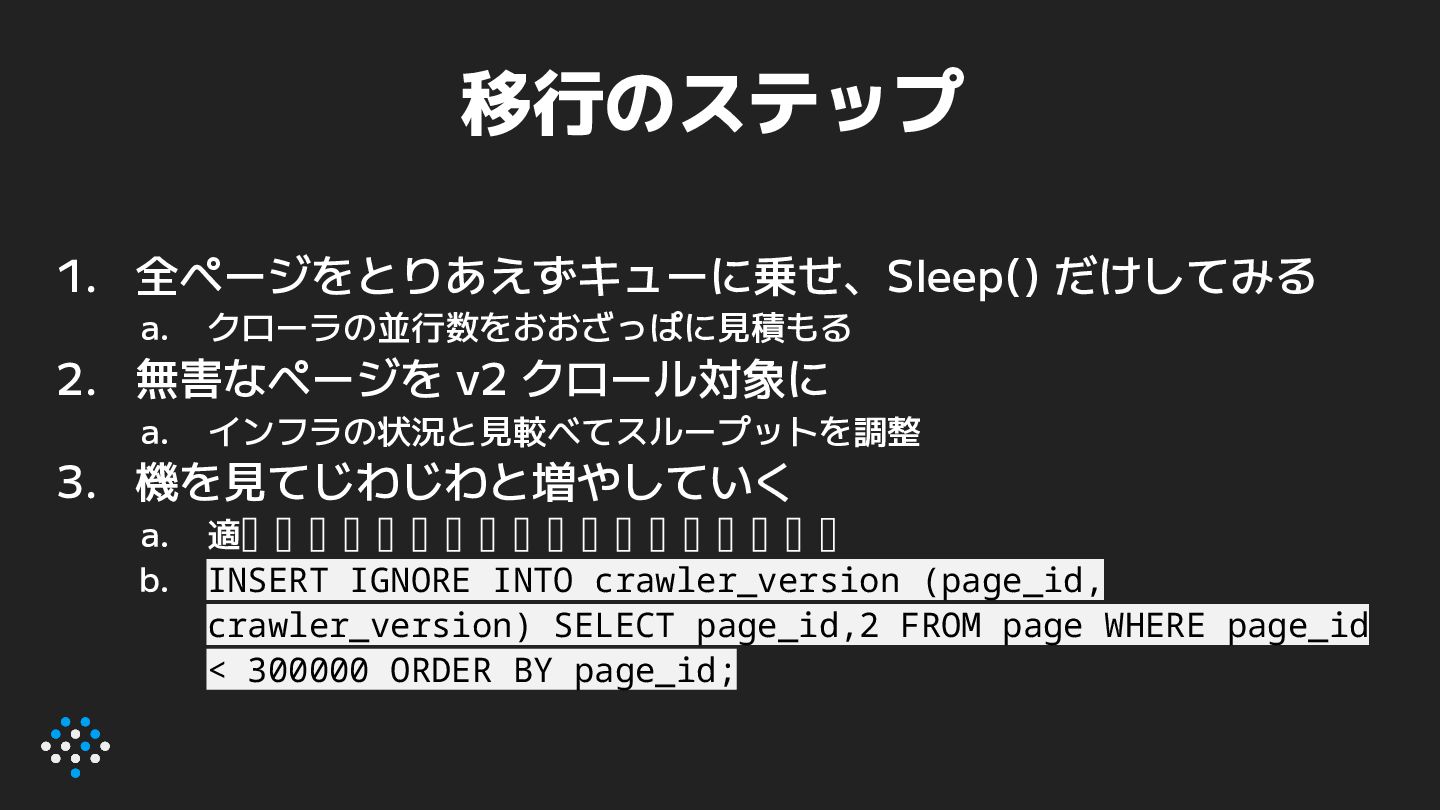
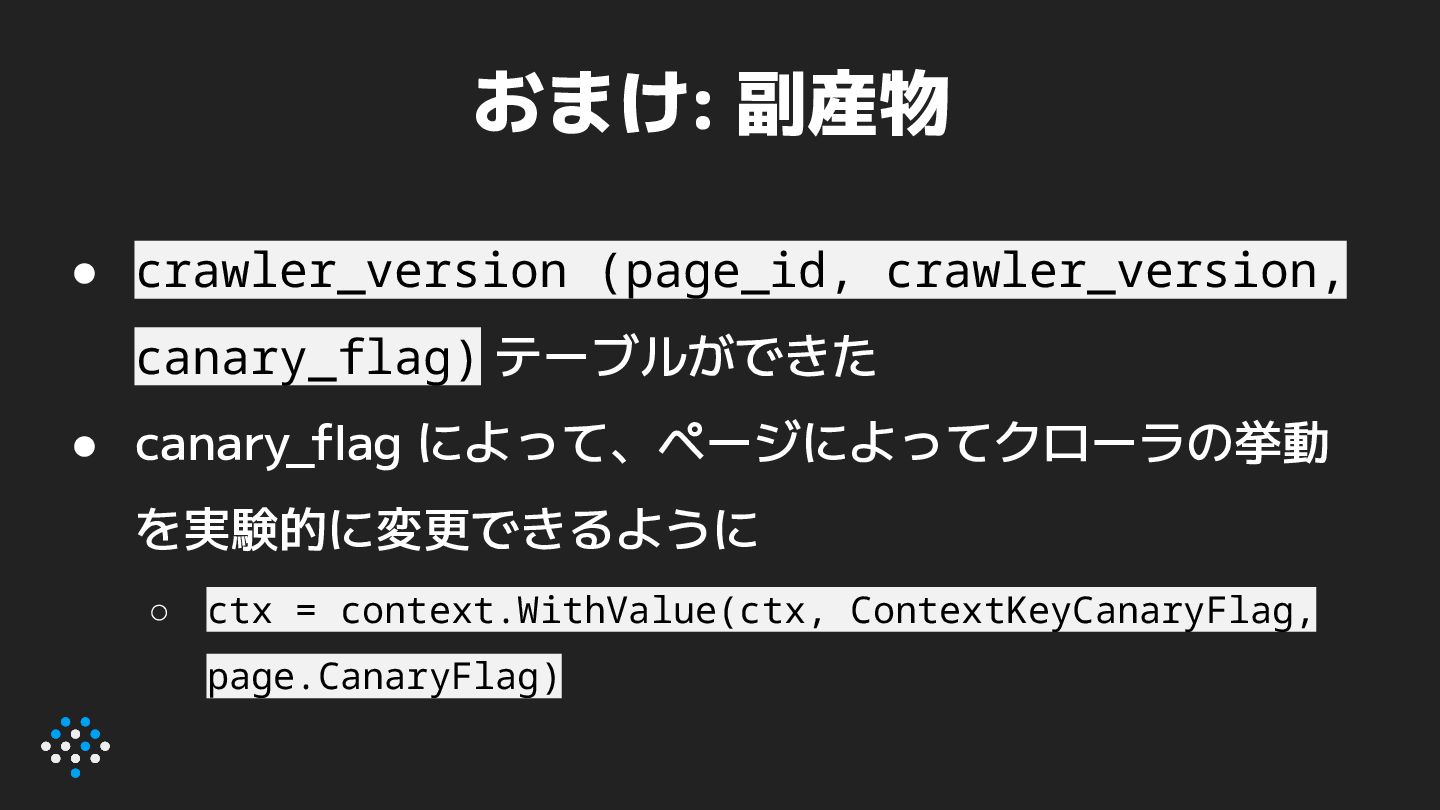
a. インフラの状況と見較べてスループットを調整 3. 機を見てじわじわと増やしていく a. 適当なタイミングで、新規登録ページも v2 対象に b. INSERT IGNORE INTO crawler_version (page_id, crawler_version) SELECT page_id,2 FROM page WHERE page_id < 300000 ORDER BY page_id;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
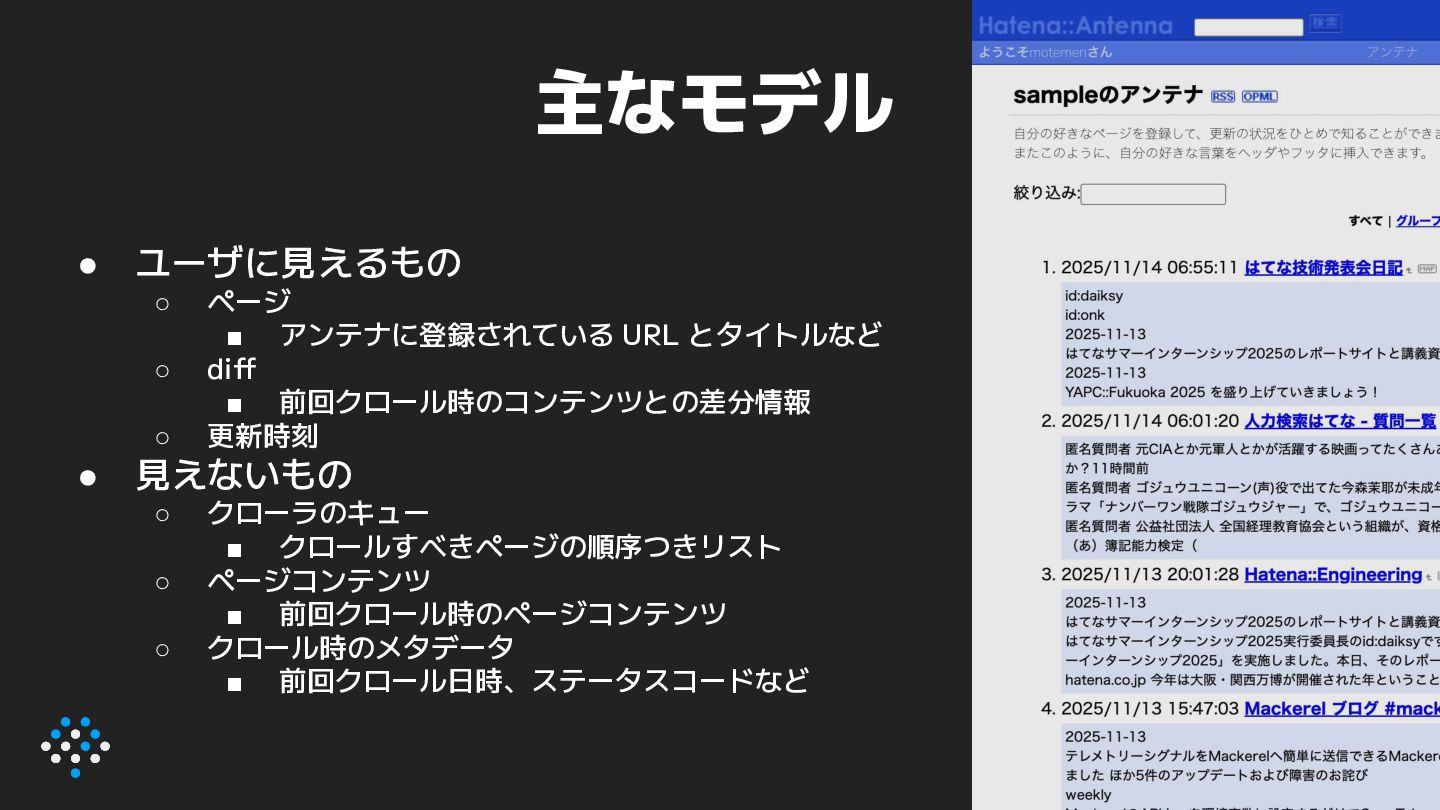{kind=link}
{kind=link}
{kind=link}
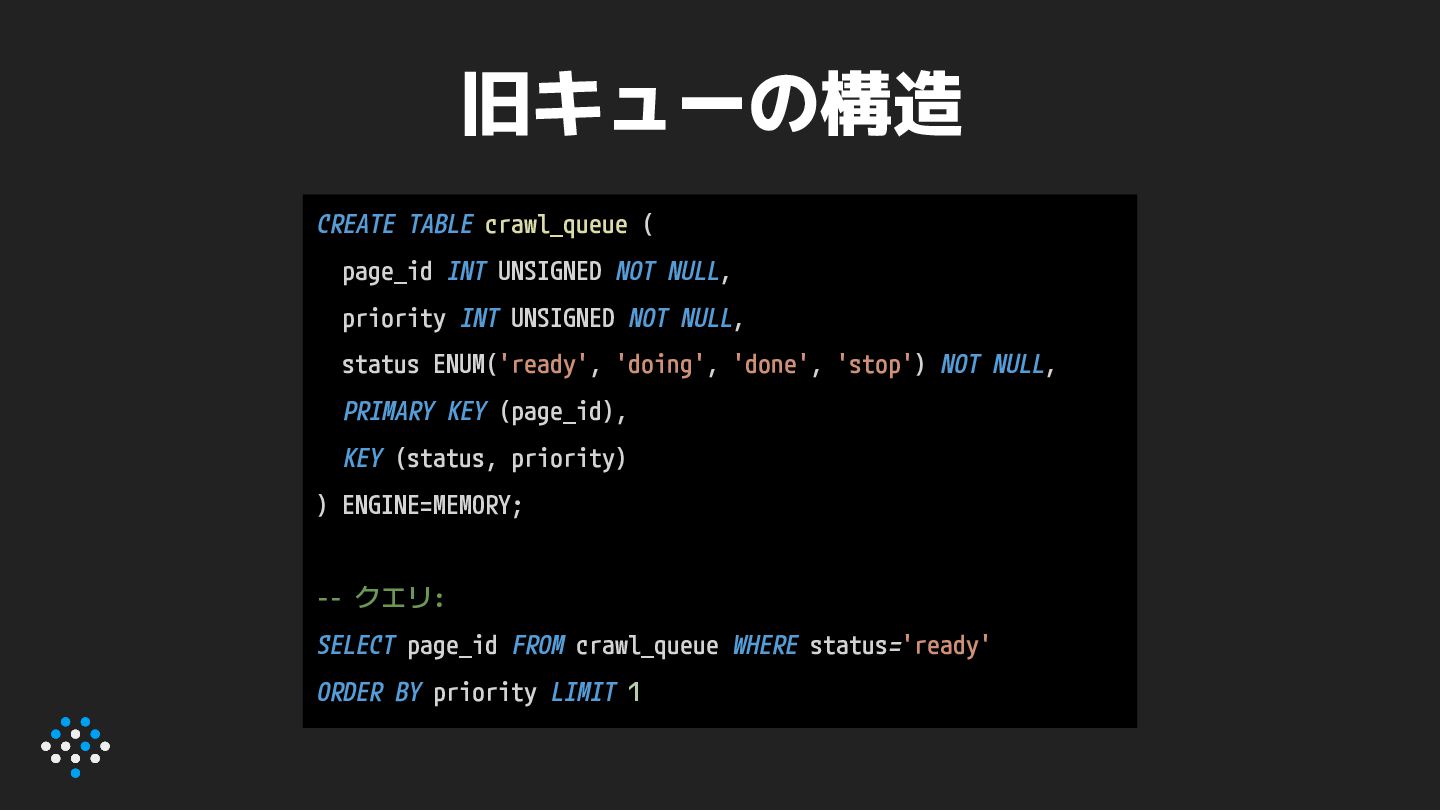{kind=link}
{kind=link}
{kind=link}
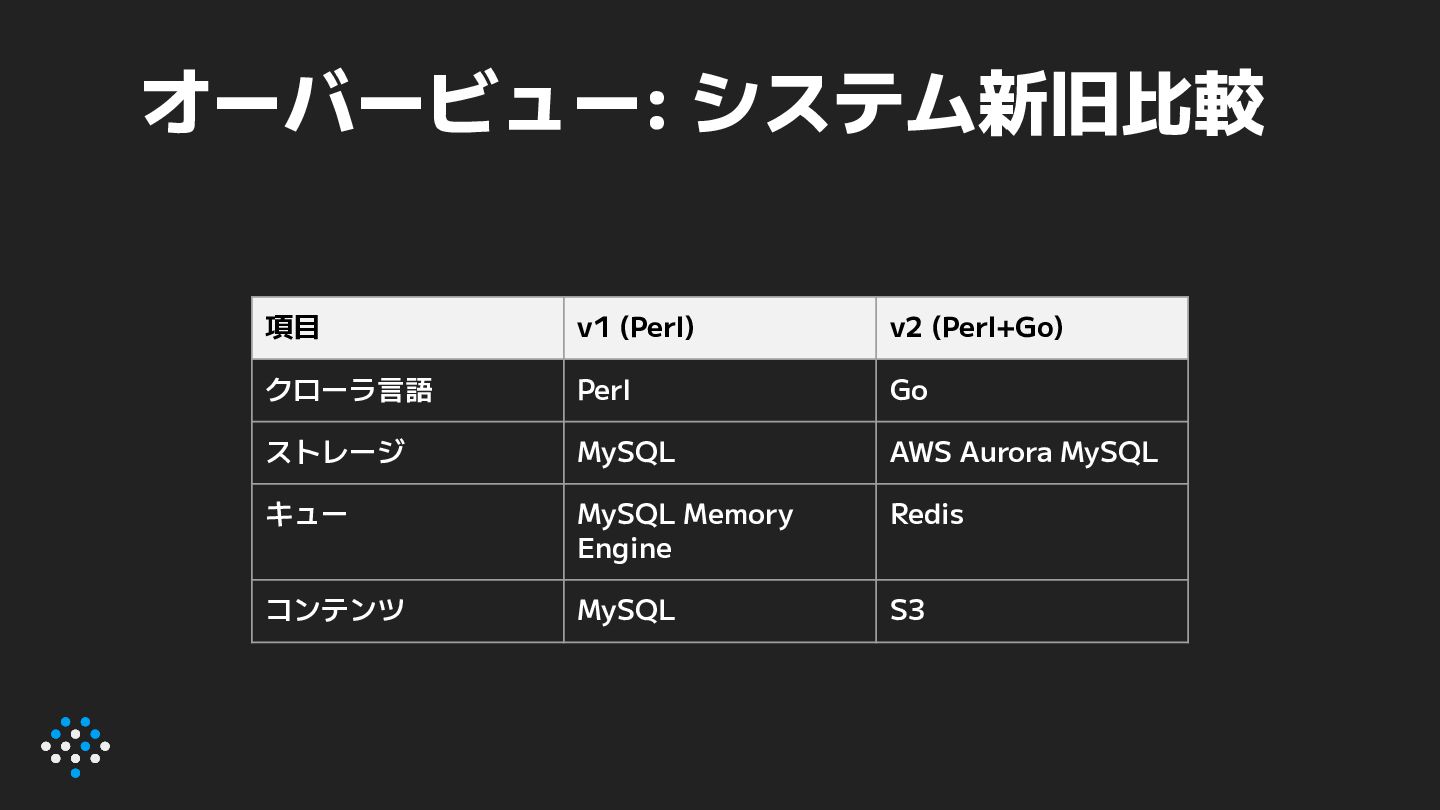{kind=link}
{kind=link}
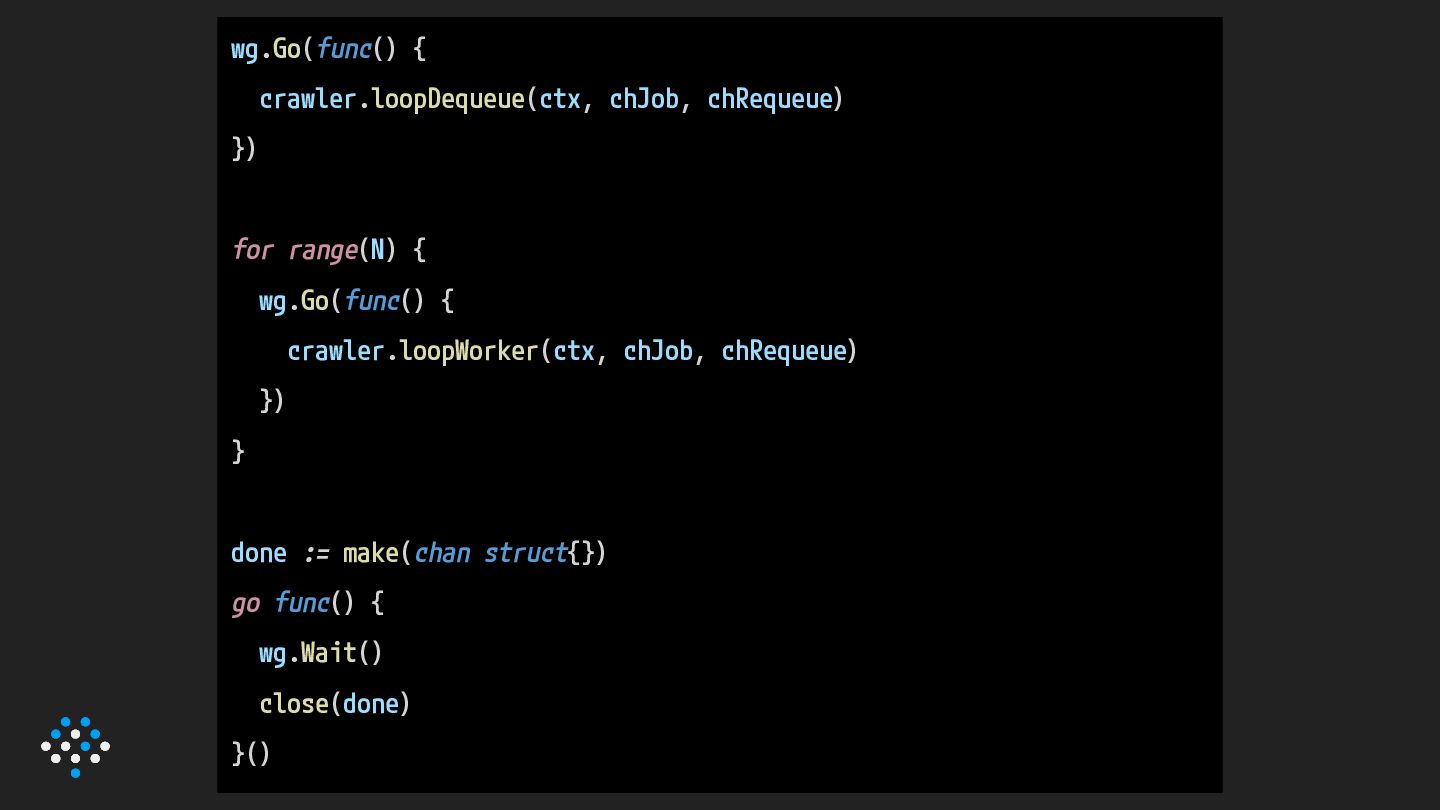{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}