Original title in Spanish: Desambiguación de Palabras Polisémicas mediante Aprendizaje Semi-supervisado
Date: November 19, 2012
Venue: Córdoba, Argentina. Project on Word Sense Disambiguation for the MSc Specialization Course "Artificial Intelligence" at FaMAF, UNC (Faculty of Mathematics, Astronomy, Physics and Computation, National University of Córdoba)
Video: https://www.youtube.com/watch?v=qv9qZaBw-Qw
Please cite, link to or credit this presentation when using it or part of it in your work.
#ML #MachineLearning #NLP #NaturalLanguageProcessing #SemiSupervisedLearning #WordSenseDisambiguation #WSD
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[…] En este caso, la causa de los movimientos sísmicos](https://files.speakerdeck.com/presentations/45e3aa271dea4451a5355ea9b3b1dd88/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
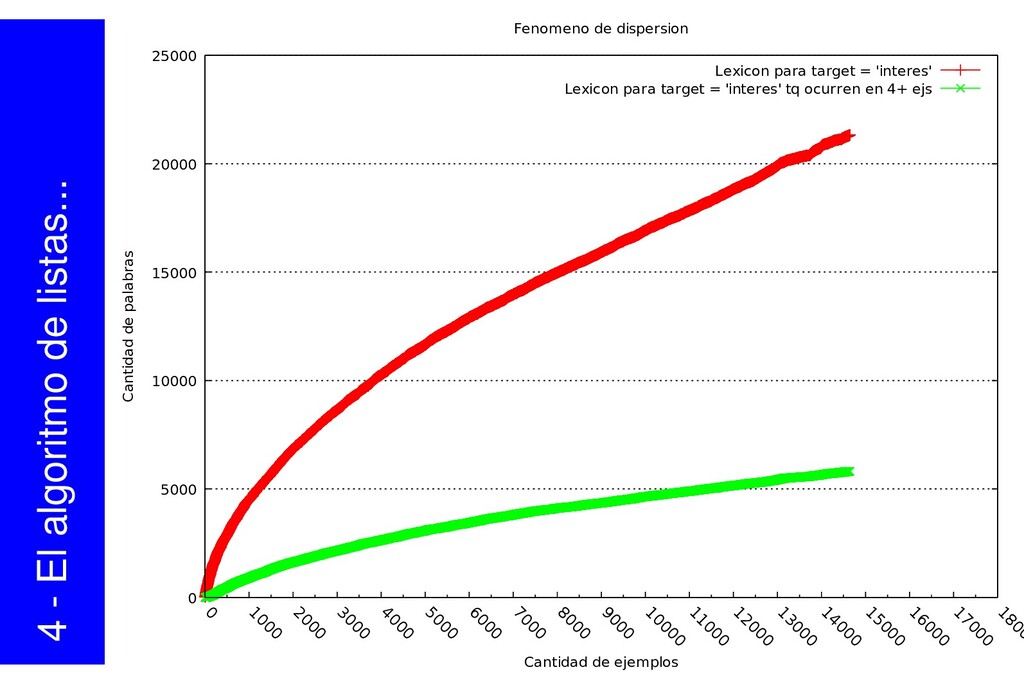{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
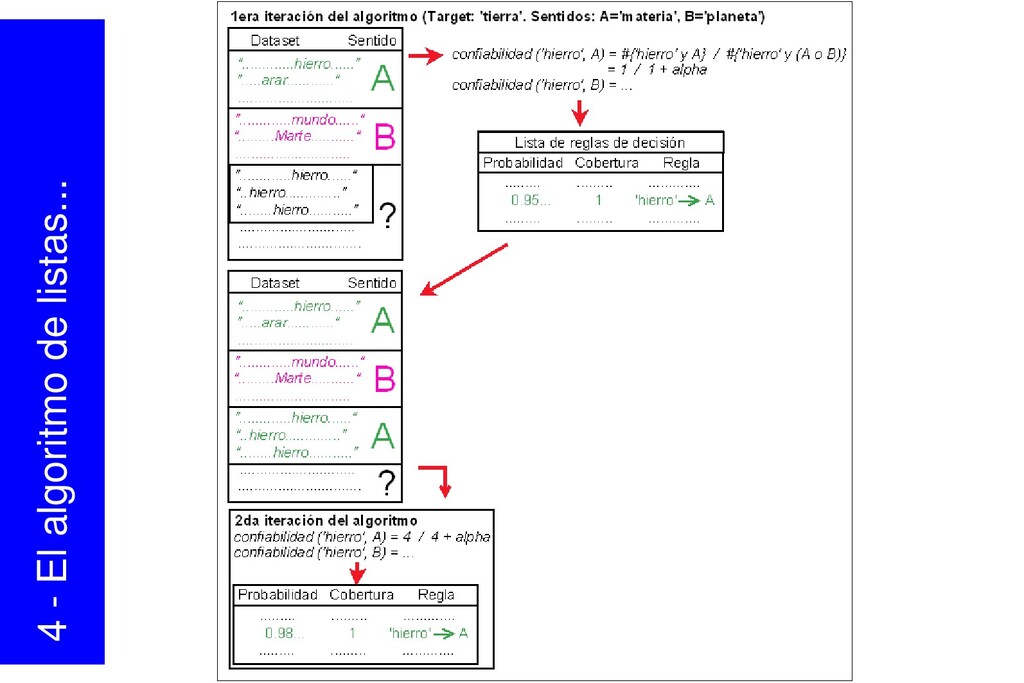{kind=link}
{kind=link}
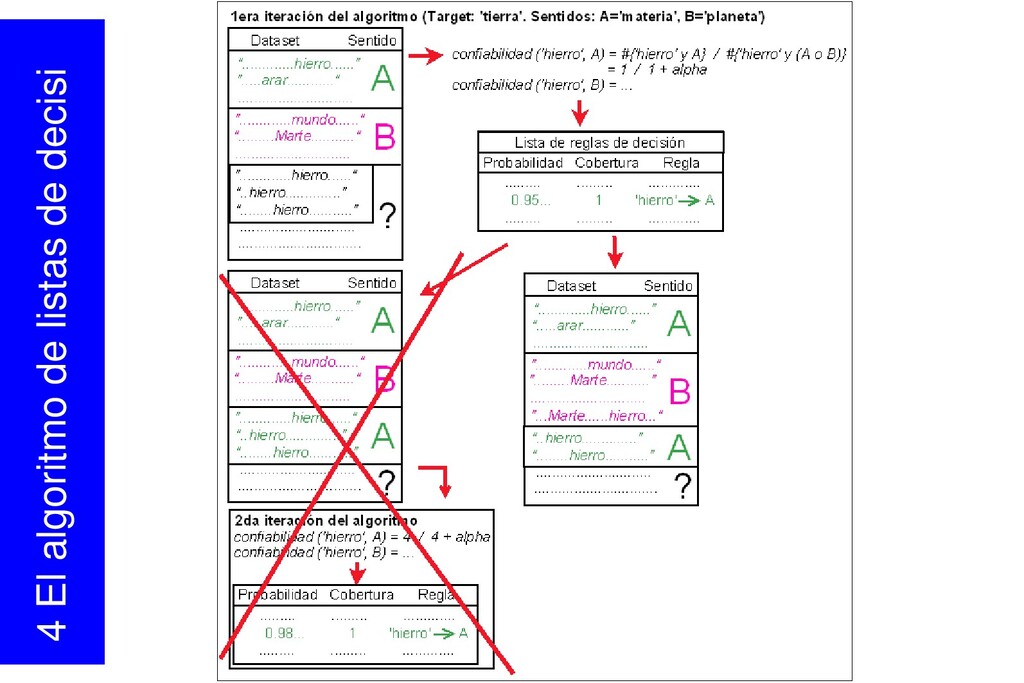{kind=link}
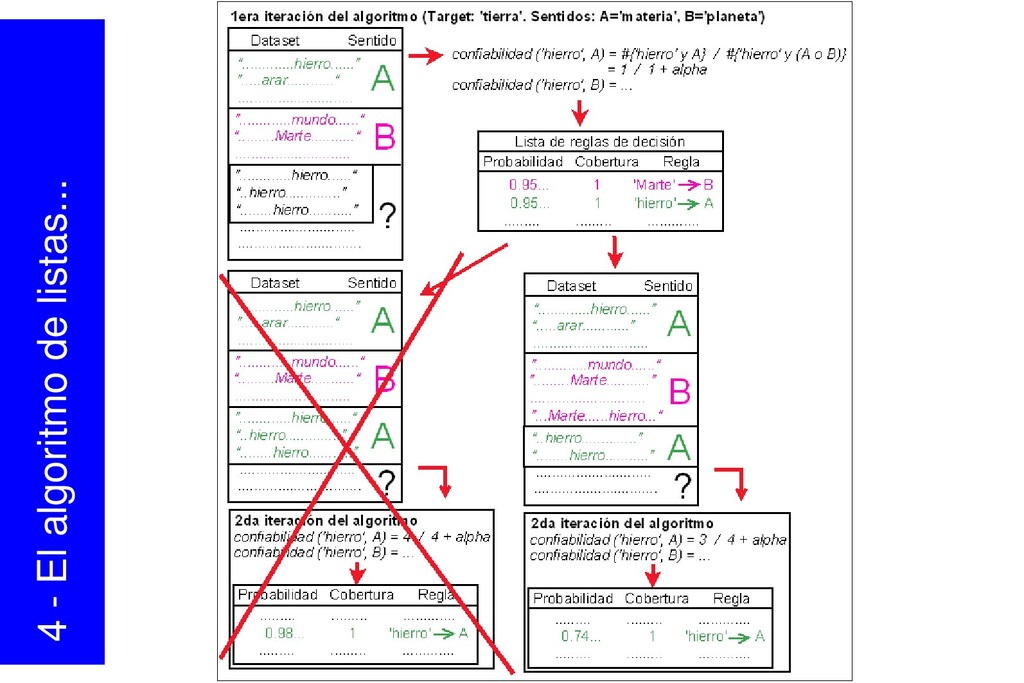{kind=link}
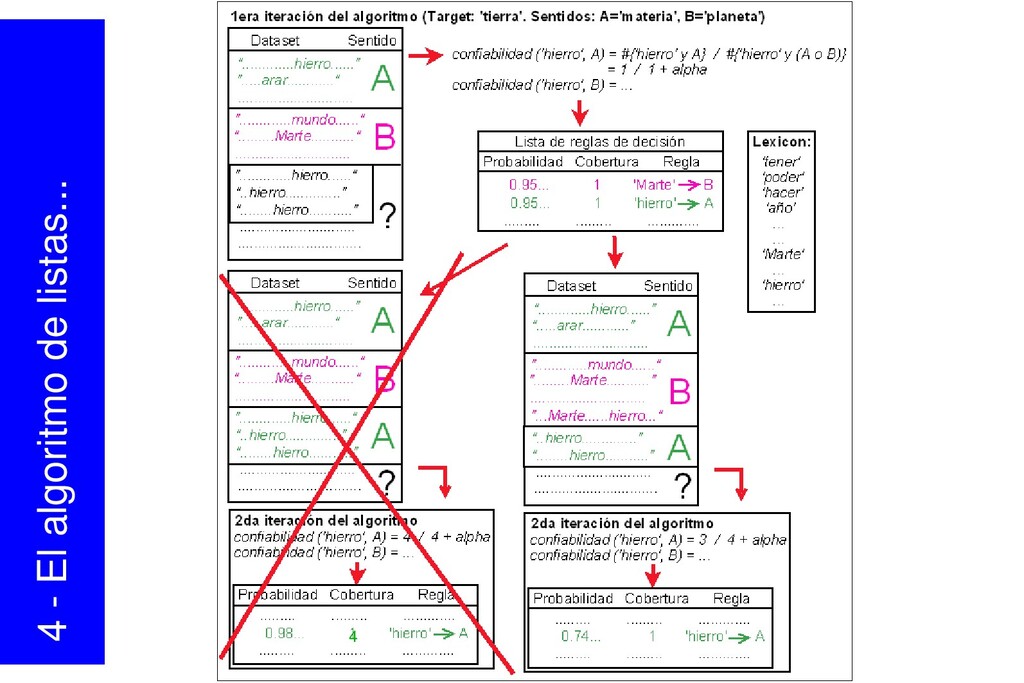{kind=link}
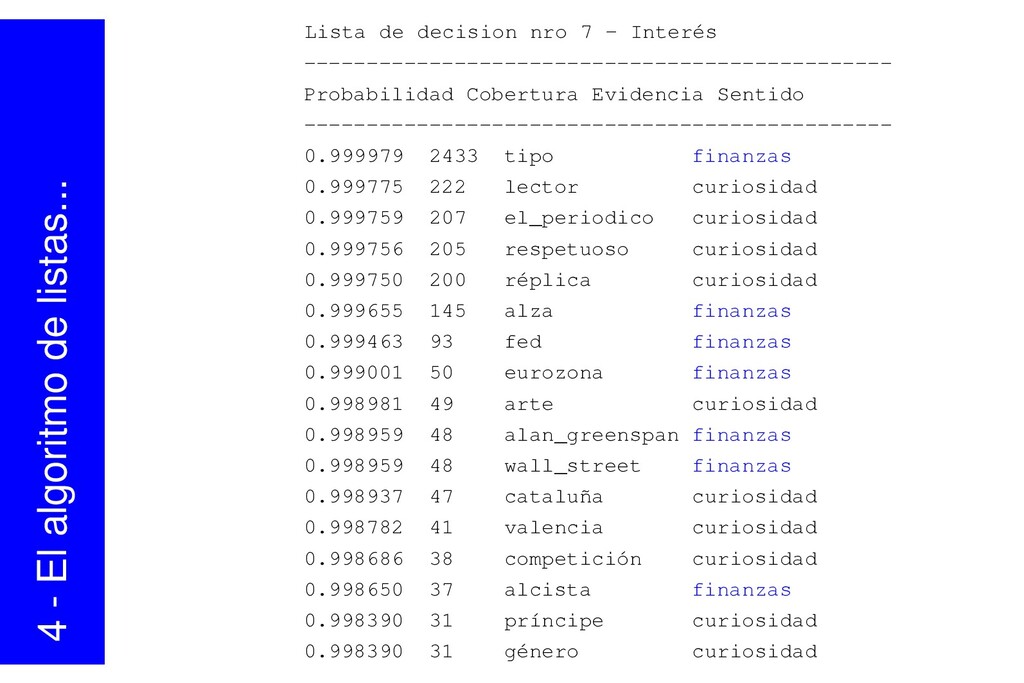{kind=link}
{kind=link}
{kind=link}
{kind=link}
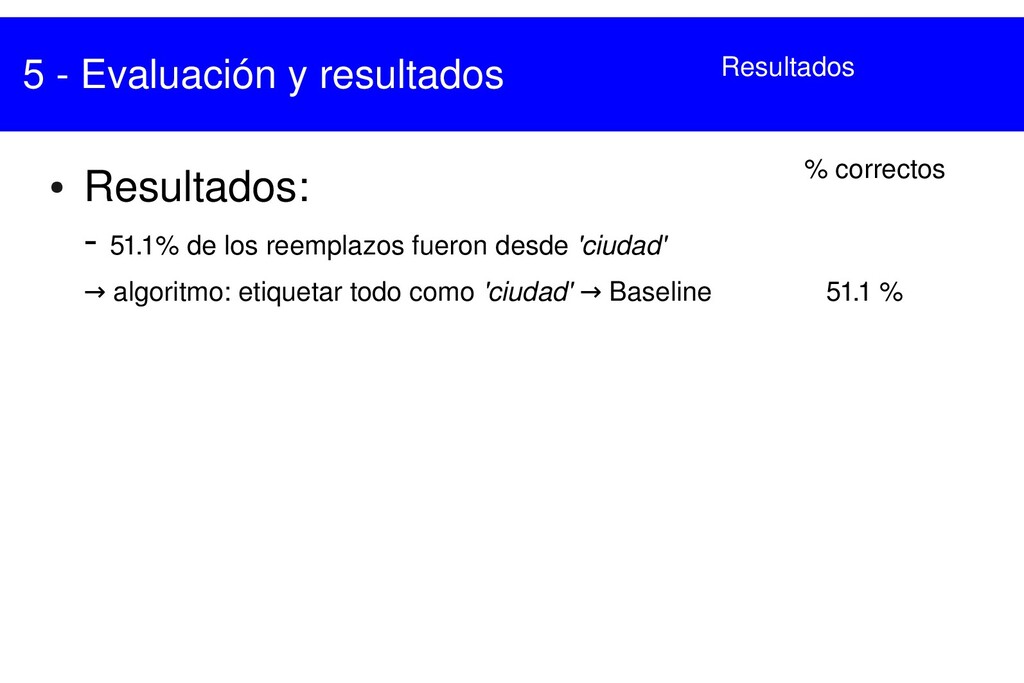{kind=link}
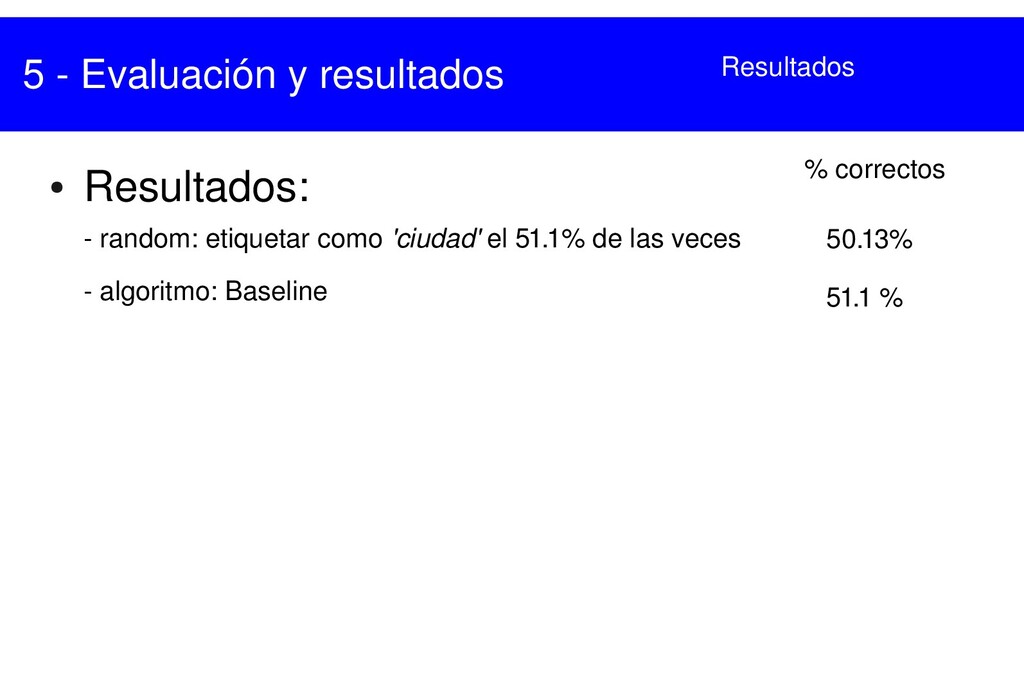{kind=link}
{kind=link}
{kind=link}