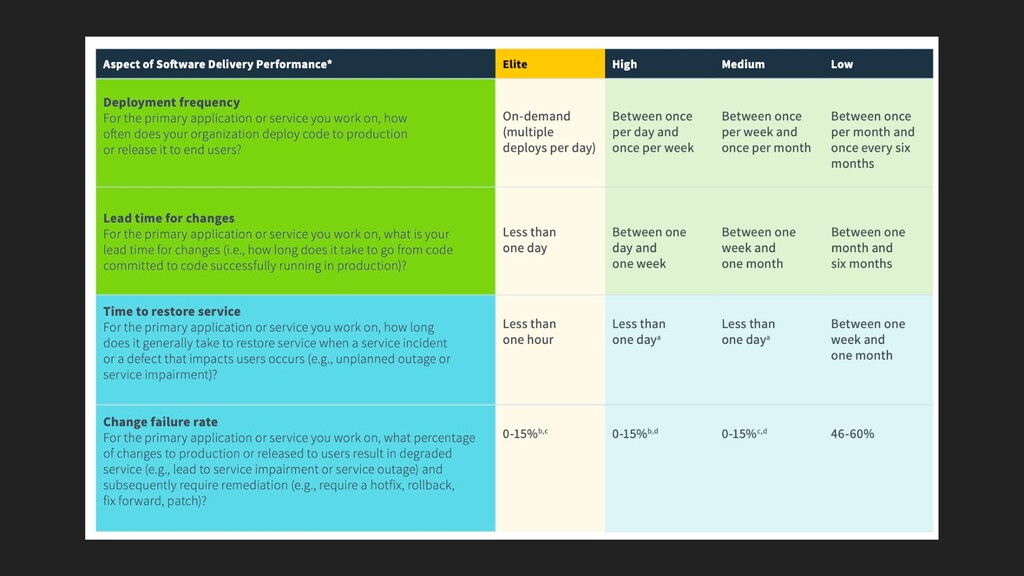
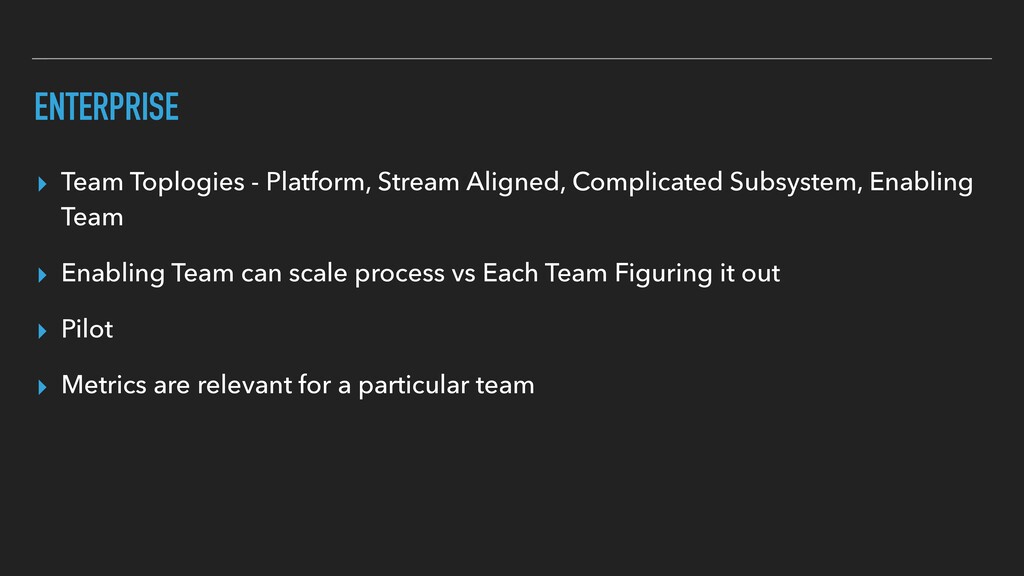
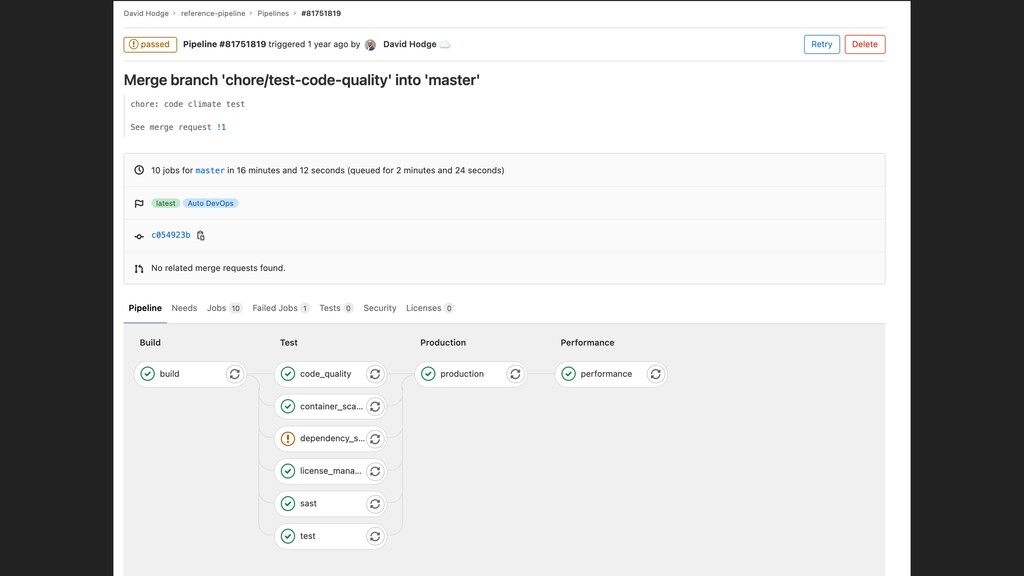
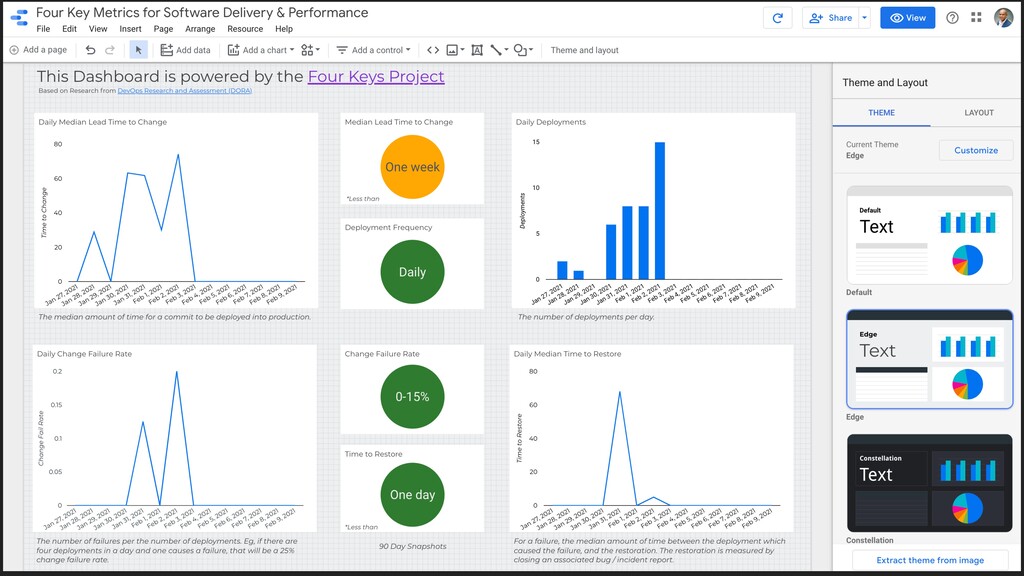
After years of research and data from over 30,000 professionals, the DevOps Research and Assessment (DORA) team identified four key metrics that separate elite teams. In this talk, David Hodge, Google Cloud Certified Architect, will discuss the four key metrics and one way to measure them. More importantly, we will discuss how organizations can adopt the mindset of measuring the metrics and potential pitfalls.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QUESTIONS/FEEDBACK ▸ [email protected] ▸ Of fi ce Hours - https://calendly.com/david-](https://files.speakerdeck.com/presentations/5ffb30bee62f44ce84dcf138047edeb3/slide_27.jpg){kind=link}