Transfer learning has been proven to be a tremendous success in computer vision—a result of the ImageNet competition. In the past few months, there have been several breakthroughs in natural language processing with transfer learning, namely ELMo, OpenAI Transformer, and ULMFit. Pretrained models derived from these techniques have been proven in achieving state-of-the-art results on a wide range of NLP problems. The use of pretrained models has come a long way since the introduction of word2vec and GloVe, and these two approaches are considered shallow in comparison.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
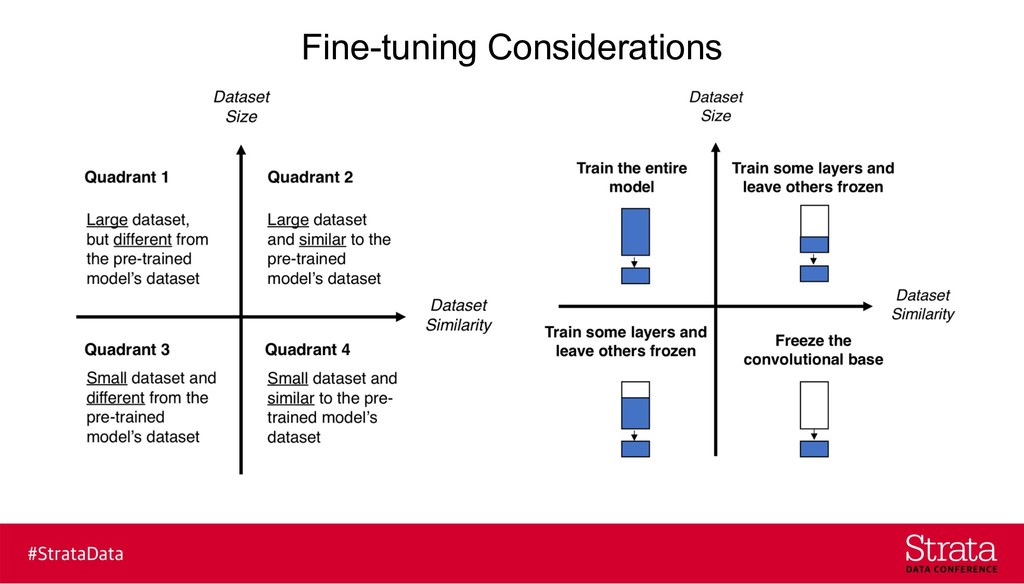{kind=link}
{kind=link}
{kind=link}
{kind=link}
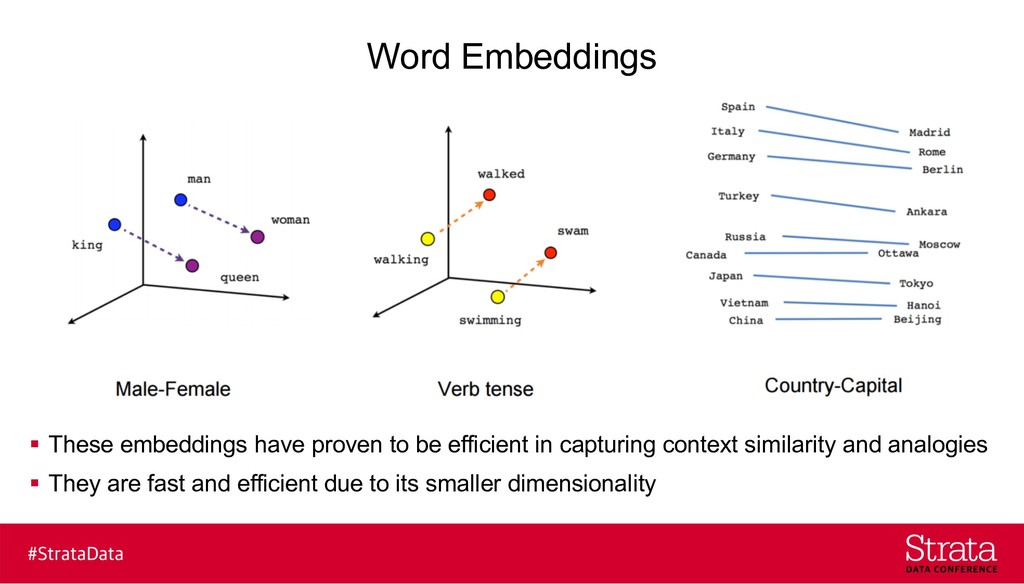{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
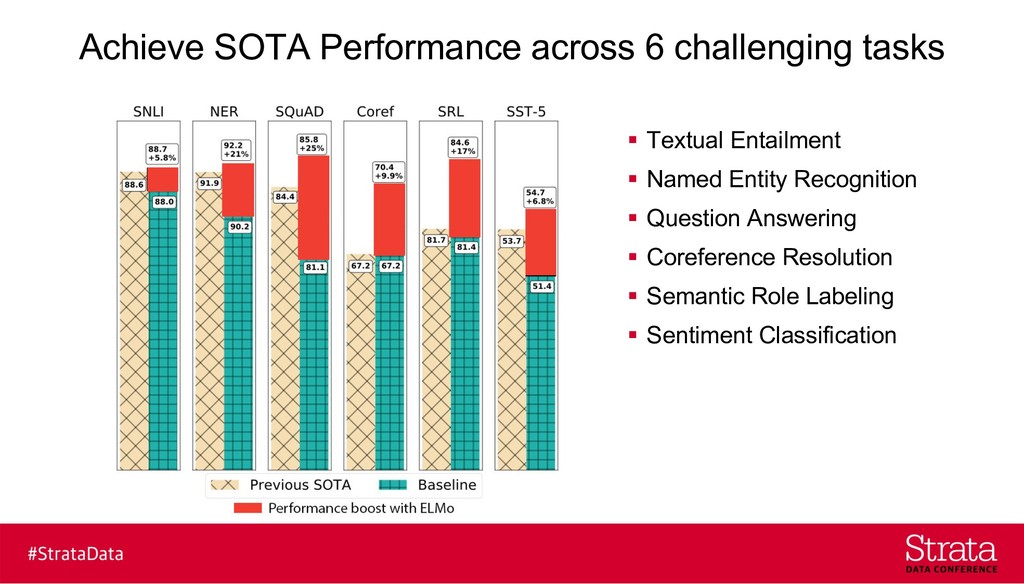{kind=link}
{kind=link}
{kind=link}
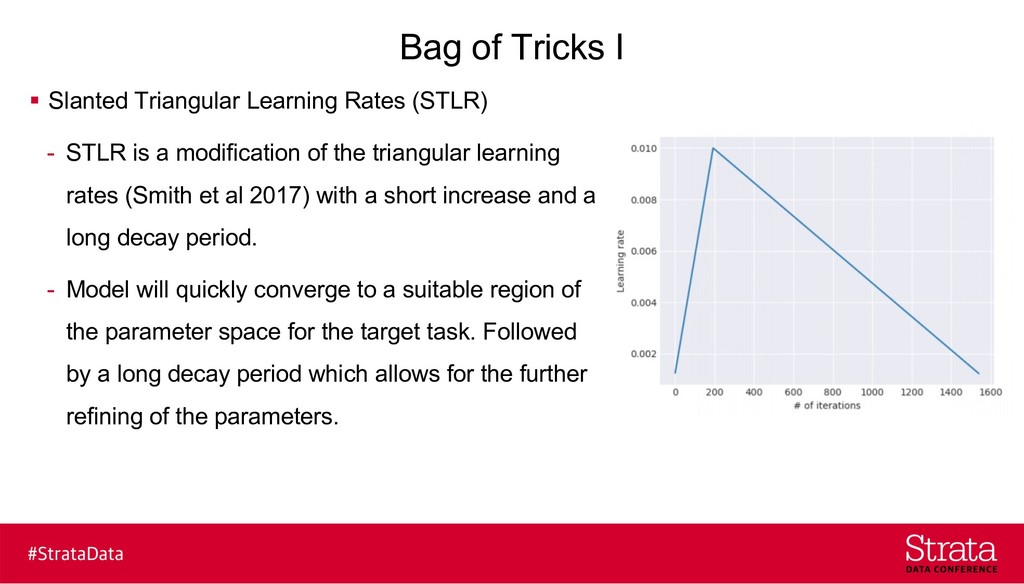{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}