Heapcon: How we built our Analytics platform with JHipster and OSS technologies
This talk will focus on the experience of using JHipster in building the newest DevOps product from XebiaLabs. I will talk about the architecture, how JHipster is used and about some issues faced and how we overcome them.
Java web applications and microservices ▪ 11k+ stars on GitHub ▪ 1.3M+ installations & 20k+ app generations per month ▪ 250k+ overall users ▪ 450+ contributors & 23 core team members ▪ 250+ companies using JHipster ▪ 70+ plugins Hel s e s!
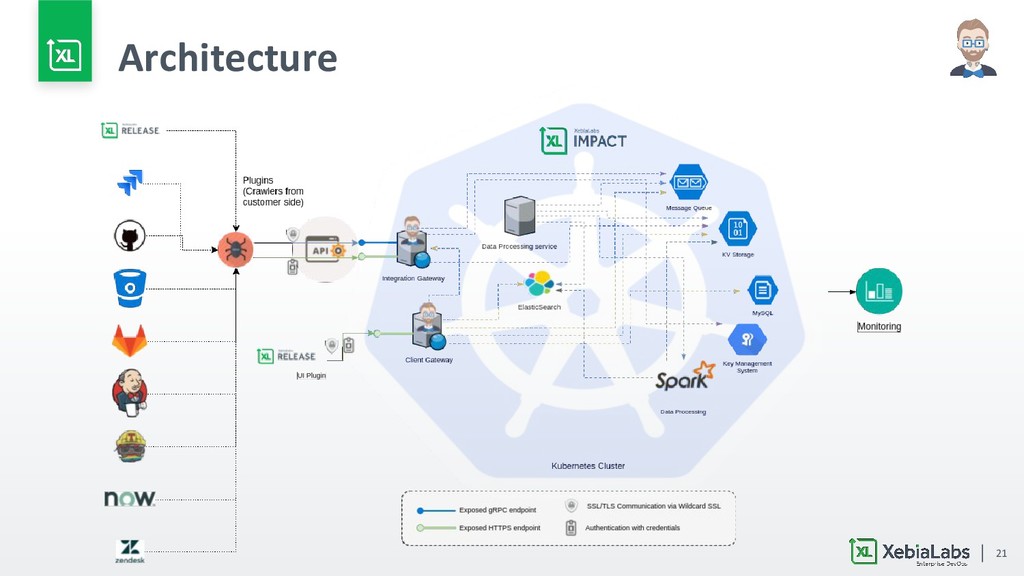
write performance ▪ Kafka sync issues ▪ On demand Spark clusters on Kubernetes ▪ Orchestration of Infra, services and crawlers to multiple environments(single tenant architecture) ▪ ES high availability on Kubernetes(no dynamic volume resizing)
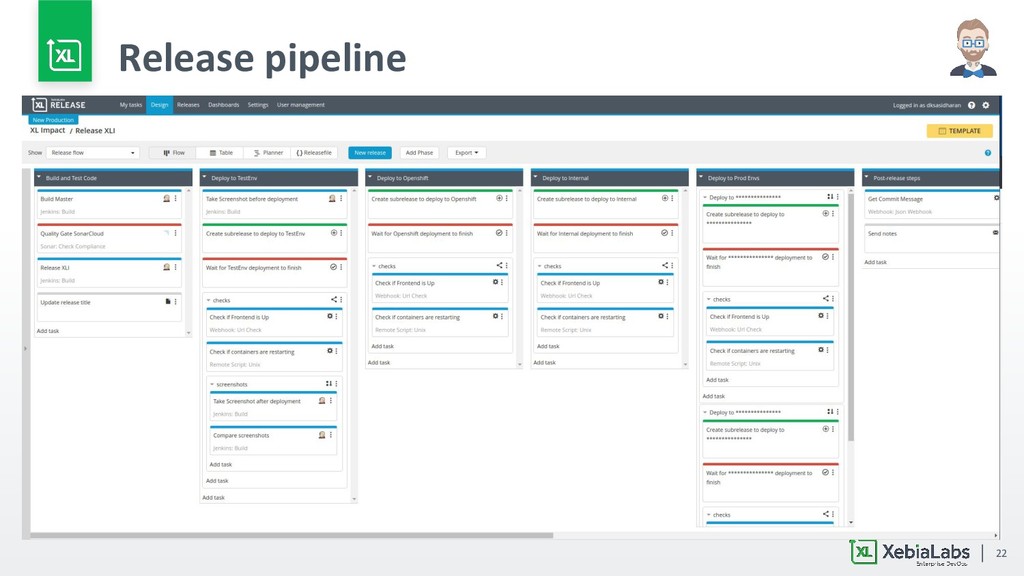
discovery API ▪ ElasticSearch write performance − SSD + Memory + lot of swearing ▪ Kafka reliability issues − Moved to Google PubSub ▪ On demand Spark clusters on Kubernetes − Custom images with lot of tweaks ▪ Orchestration of Infra, services and crawlers − XL Release + XL Deploy ▪ ES high availability on Kubernetes − Still not implemented
{kind=link}
{kind=link}
{kind=link}
![4 About XebiaLabs dev test uat prod [Cloud] Orchestration Stack](https://files.speakerdeck.com/presentations/9c3d27d32ea54bcebca5443eb320259a/slide_3.jpg){kind=link}
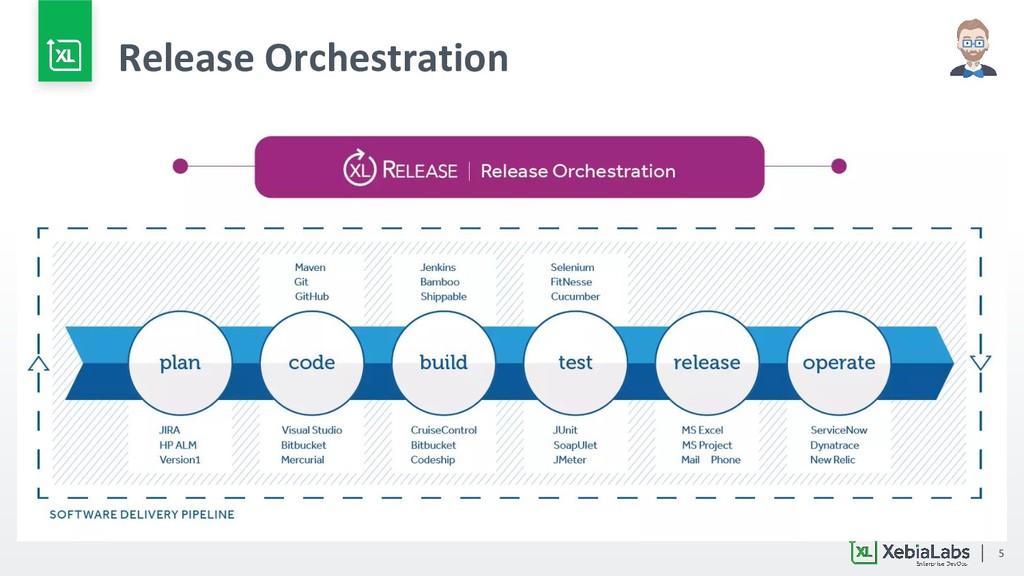{kind=link}
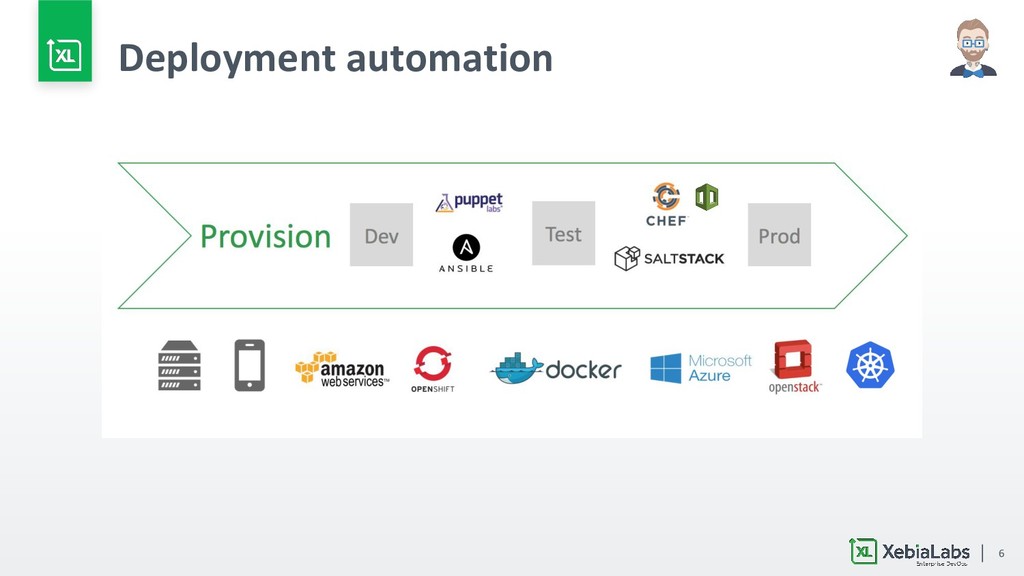{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
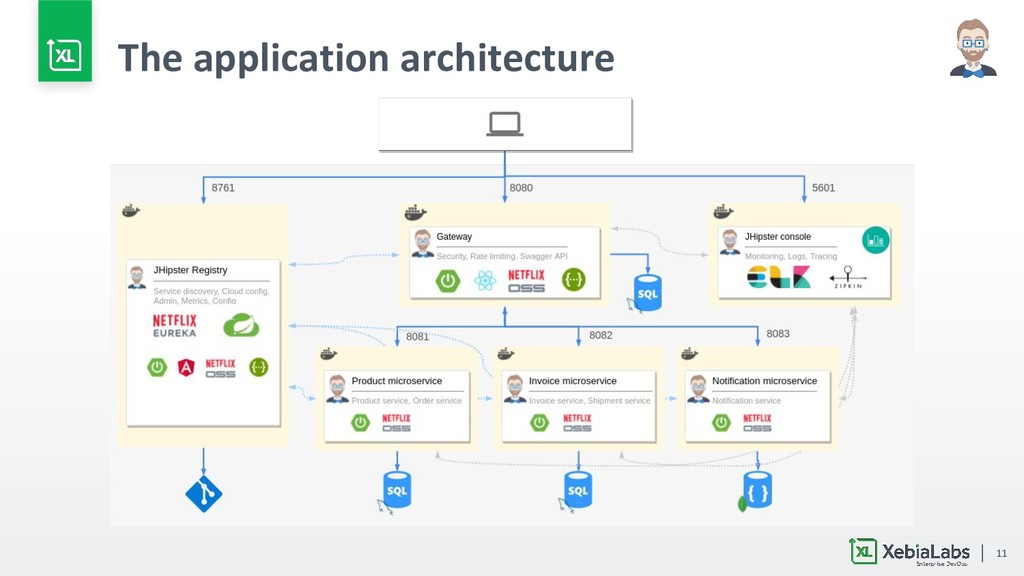{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}